3.1. Architecture
Figure 2 illustrates an overview of the proposed panoptic segmentation network. In this section, we introduce the proposed center-guided query selection module and transformer decoder with decoupling mask.
Backbone and transformer encoder: The backbone extracts image features from an input image
, and the transformer encoder generates a new feature map
from the image features, where
,
, and
. We employ ResNet50 [
21] for the backbone and the transformer encoder in [
9]. The transformer encoder consists of deformable attention [
10], layer normalization, and a feed forward network (FFN). Feature map
is gradually upsampled to a center embedding
and a mask embedding
through the two sets of convolution layer and bilinear interpolation operation, where
,
. Also,
is fed into the transformer decoder for attention mechanisms with queries.
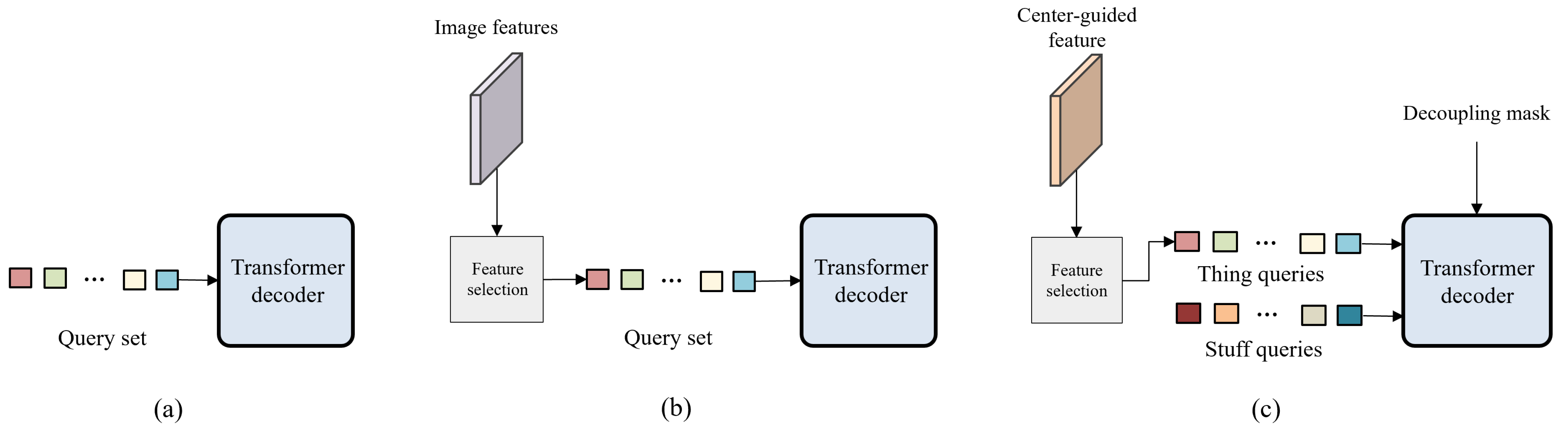
Center-guided query selection: Traditional transformer-based panoptic segmentation models [
6,
8,
9] typically use randomly initialized embeddings to learn queries without distinguishing between things and stuff. The proposed network learns things and stuff separately to prevent thing queries and stuff queries from interrupting each other. Inspired by center-based learning for object detection [
16,
17,
18,
19], we develop the mechanism of center-guided query selection for thing queries. The center regions of individual instances in input images contain the cues to distinguish different instances. Thus, we estimate a center heatmap to guide effective thing query selection.
Figure 3 shows the diagram of the proposed center-guided query selection. Center embedding
passes through the FFN to estimate center heatmap
, which contains the location information of the instances. Then, we obtain center-guided feature
using element-wise multiplication between the estimated center heatmap
and each channel of
. To this end, we employ the feature selection process in [
10,
11] to determine the top
K query features from center-guided feature
.
passes through a linear layer and softmax to obtain class probability map
for things, where
is the number of thing classes. Then, we pick the highest probability from
for each pixel and construct thing query
, where
, by selecting the top
K features from
in terms of the highest probabilities extracted from
. Since center heatmap
has high values on the central parts of the instances,
conveys strong visual patterns related to the instances to obtain effective thing query
. Note that we only perform center-guided query selection for thing queries
, while we simply set stuff queries
as
randomly initialized embeddings.
Transformer decoder with decoupling mask: We need to train queries to inject enough information to derive classes and masks. For this purpose,
and
are concatenated as
and fed to the transformer decoder, which includes self-attention, deformable attention, and the FFN, as in
Figure 4. Considering the different properties between things and stuff, we apply decoupling mask
to self-attention, where
’s element
is defined as
Then, self-attention in the transformer decoder is formulated as
where
,
, and
are the query, key, and value extracted from
through a linear layer, respectively. We prevent interference between thing and stuff queries using decoupling mask
. For the stability of the learning process, we use the residual connection with
and perform layer normalization after the residual connection. After the self-attention process, we use deformable attention to inject
into
, resulting in enhanced query set
.
Estimation: Masks and classes are estimated from enhanced query set . First, masks are computed using the dot product between and mask embedding . Second, passes through a fully connected layer to predict the class probability. Finally, we obtain panoptic segmentation results from mask and class predictions.
3.2. Loss
The proposed network outputs
predictions, including masks and classes. Then, we perform the Hungarian algorithm [
22] to match predictions and ground truths, following [
6,
7,
8,
9]. For each match, we compute the focal loss [
23] between class probability prediction
and ground truth
as follows:
where
,
, and
were experimentally set to 4, 0.25, and 2, respectively. Also, to compare the estimated mask
and ground truth
, we employ the mask loss (
) in [
8], which is composed of per-pixel cross-entropy loss
and dice loss [
24]
:
where
and
were set to 5 and 5, according to [
9]. Additionally, to train the center-guided query selection module, we generate ground-truth heatmap
by applying Gaussian distributions to all instance center points for each image. Then, we compute the focal loss between the predicted center heatmap
and
.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}