Voice-Controlled Intelligent Personal Assistant for Call-Center Automation in the Uzbek Language


Abstract
:1. Introduction
1.1. Research Context and Motivation
1.2. Research Aims and Contributions
- ➢
- A significant reduction in waiting time (handling time) reduces work costs.
- ➢
- Reducing call time by 1.5–2 times by reducing the time the operator enters the information.
- ➢
- Reduction in operators’ working time for complex calls owing to the ability to automatically answer simple questions.
- ➢
- Creating the ability to work with customers 24/7 (even on holidays).
- ➢
- Verifying customers’ voices by answering one or two simple questions is especially important in the banking sector to protect against theft of personal cards and confidential documents.
- ➢
- Ability to work with a large number of short calls (in bookmakers call centers).
- ➢
- The ability to replace a complex and error-prone IVR system operating in tone mode.
- ➢
- The ability to use speech recognition as a source of additional information not only during conversations but also during further analysis of the call. In particular, this analysis helped increase the main indicator of first call resolution (FCR).
- ➢
- Problem resolution in one call. This leads to a reduction in callbacks and, simultaneously, an increase in customer satisfaction, which in turn results in lower operating costs.
- Speaker recognition in varied environments: The study tested a speaker recognition module in different environments, observing the accuracy of the module under varying conditions. For example, we achieved an impressive 96.4% accuracy in real-time tests with 56 participants.
- Use of the Deep Speech 2 model: we used the Deep Speech 2 model for extracting MFCC features from utterances.
- Automatic speech recognition (ASR) model: The ASR model used in the study converts consumer speech into text. It was trained using an RNN-based end-to-end speech recognition architecture on large Uzbek-automatic speech recognition training data (USC).
- Sentence summarizing: The system includes a sentence summarizing component that uses the BERT sentence transformer for embedding sentences and search queries, achieving an average accuracy of 85.27%.
- Database management: The system incorporates three types of databases—personal information database (PID), generic information database (GID), and credential information database (CID), which play crucial roles in managing user data and queries.
- Development and implementation of an Uzbek speech synthesizer rooted in natural voice for call centers:
- ✧
- Objective: To seamlessly integrate a speech synthesizer calibrated to the phonetic intricacies of the Uzbek language into the telephonic interfaces of call centers.
- ✧
- Operational mechanism: Upon receiving a call, the synthesized voice mechanism initiates a dialogue with the caller, efficiently garnering the requisite information, and thus minimizing the preliminary conversational stages traditionally facilitated by human operators.
- ✧
- Anticipated impact: The incorporation of this synthesizer is projected to considerably alleviate the operational burdens shouldered by call center representatives, rendering the process more streamlined and expeditious.
- Challenges and practical implications of speech recognition in public service call centers:
- ✧
- Context: The burgeoning integration of speech synthesizers into public service-oriented call centers is challenging. Their primary function often pivots on vocalizing the results stemming from voice-initiated queries, such as ascertaining the status of administrative applications.
- ✧
- Technical nuances: While the conceptual frameworks of these systems are undeniably innovative, it is imperative to comprehend the intricacies associated with their seamless operation, ranging from linguistic variations to background noise interference.
- ✧
- Operational benefits: Despite the potential obstacles, the judicious deployment of such systems can increase the efficacy of voice response mechanisms, thereby ensuring that callers receive precise and timely information.
- Enhancing call center efficiency through automated speech recognition and synthesis:
- ✧
- Premise: The swift and accurate resolution of client inquiries is at the heart of contemporary call center dynamics. Therefore, automated speech recognition and synthesis are of paramount importance.
- ✧
- Research scope: This study delves into the ramifications of implementing these speech technologies, particularly in contexts that require simple procedural updates, such as tracking the status of an application.
- ✧
- Projected outcomes: Preliminary data suggest that astute deployment of these systems could precipitate a reduction in manual operator involvement by a substantial 20–25%. Furthermore, it paves the way for uninterrupted 24/7 customer service, bolstering operational efficiency and augmenting customer satisfaction.
1.3. Structure of the Paper
2. Related Work
3. Methodology
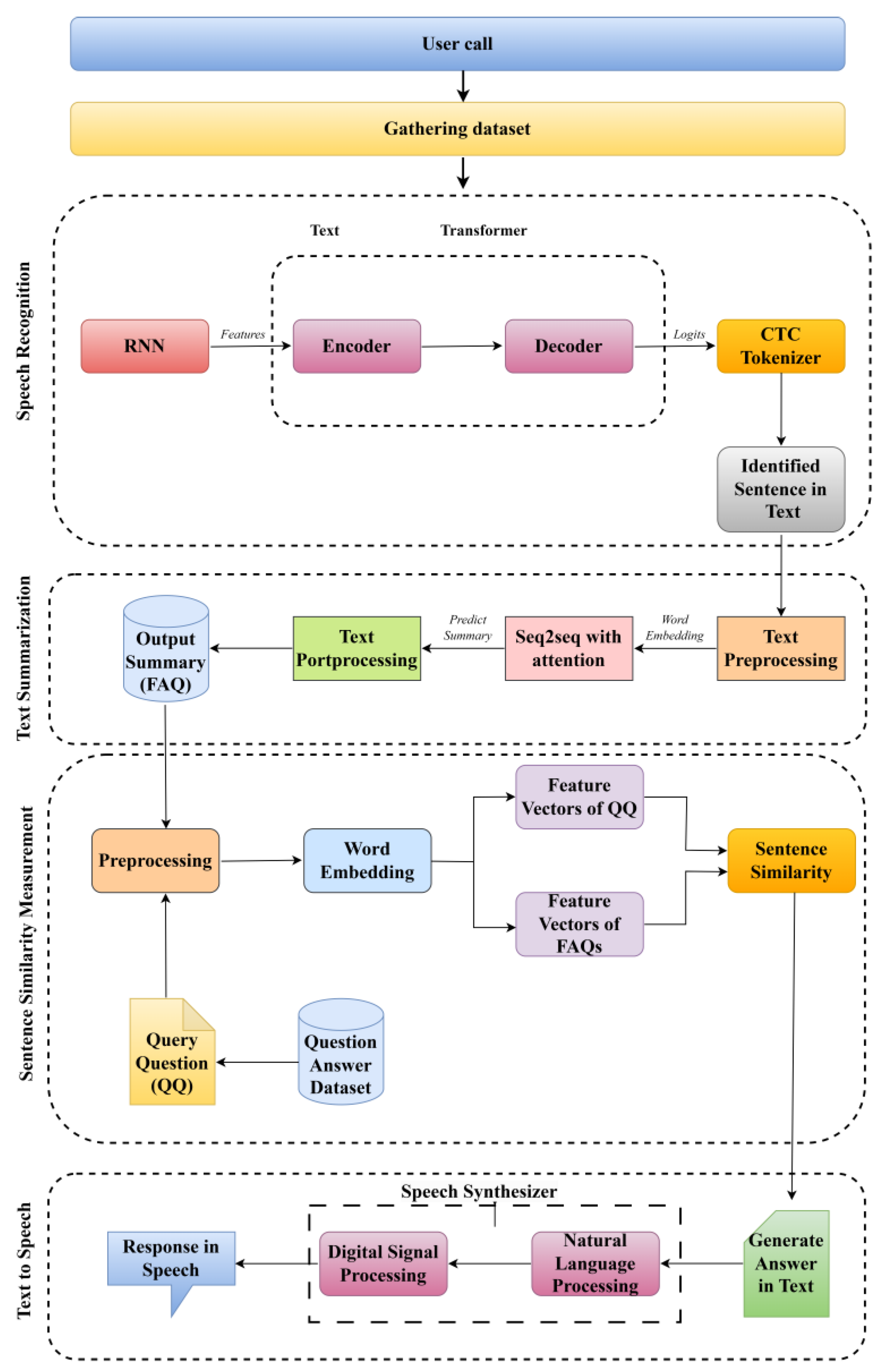
3.1. Workflow
3.2. Recognition of Speakers
3.3. Automatic Speech Recognition
3.4. Summarization of Sentences
- (1)
- Data Collection and Processing Techniques
- (2)
- Model Architecture
3.5. Text-to-Speech Synthesis
3.6. Database
4. Experiment and Result Analysis
4.1. WaveNet Model Accuracy
4.2. Seq2Seq Model-Based Summary Prediction
4.3. Text Summarization Using the Seq2Seq Model
5. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guzman, A.L. Voices in and of the machine: Source orientation toward mobile virtual assistants. Comput. Hum. Behav. 2018, 90, 343–350. [Google Scholar] [CrossRef]
- McCue, T.J. Okay Google: Voice Search Technology and the Rise of Voice Commerce. Forbes Online. 2018. Available online: https://www.forbes.com/sites/tjmccue/2018/08/28/okay-google-voice-search-technology-and-the-rise-of-voice-commerce/#57eca9124e29 (accessed on 28 January 2018).
- Juniper Research. Voice Assistants Used in Smart Homes to Grow 1000%, Reaching 275 Million by 2023, as Alexa Leads the Way. 2018. Available online: https://www. juniperresearch.com/press/press-releases/voice-assistants-used-in-smart-homes (accessed on 25 June 2018).
- Gartner. “Digital Assistants will Serve as the Primary Interface to the Connected Home” Gartner Online. 2016. Available online: https://www.gartner.com/newsroom/id/3352117 (accessed on 12 September 2016).
- Hoy, M.B. Alexa, Siri, Cortana, and more: An introduction to voice assistants. Med. Ref. Serv. Q. 2018, 37, 81–88. [Google Scholar] [CrossRef] [PubMed]
- Sergey, O. Listens and Understands: How Automatic Speech Recognition Technology Works [Electronic Resource]. Available online: https://mcs.mail.ru/blog/slushaet-i-ponimaet-kak-rabotaet-tehnologija-avtomaticheskogo-raspoznavanija-rechi (accessed on 3 April 2023).
- Mukhamadiyev, A.; Khujayarov, I.; Djuraev, O.; Cho, J. Automatic Speech Recognition Method Based on Deep Learning Approaches for Uzbek Language. Sensors 2022, 22, 3683. [Google Scholar] [CrossRef] [PubMed]
- Mukhamadiyev, A.; Mukhiddinov, M.; Khujayarov, I.; Ochilov, M.; Cho, J. Development of Language Models for Continuous Uzbek Speech Recognition System. Sensors 2023, 23, 1145. [Google Scholar] [CrossRef] [PubMed]
- Ochilov, M. Social network services-based approach to speech corpus creation. TUIT News 2021, 1, 21–31. [Google Scholar]
- Musaev, M.; Mussakhojayeva, S.; Khujayorov, I.; Khassanov, Y.; Ochilov, M.; Varol, H.A. USC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments. In Proceedings of the Speech and Computer 23rd International Conference, SPECOM 2021, St. Petersburg, Russia, 27–30 September 2021. [Google Scholar]
- Khujayarov, I.S.; Ochilov, M.M. Analysis of methods of acoustic modeling of speech signals based on neural networks. TUIT News 2020, 2, 2–15. [Google Scholar]
- Musaev, M.; Khujayorov, I.; Ochilov, M. Image approach to speech recognition on CNN. In Proceedings of the 2019 International Conference on Frontiers of Neural Networks (ICFNN 2019), Rome, Italy, 26–28 July 2019; pp. 1–6. [Google Scholar]
- Sundar, S.S.; Jung, E.H.; Waddell, F.T.; Kim, K.J. Cheery companions or serious assistants? Role and demeanour congruity as predictors of robot attraction and use intentions among senior citizens. Int. J. Hum. Comput. Stud. 2017, 97, 88–97. [Google Scholar] [CrossRef]
- Balakrishnan, J.; Dwivedi, Y.K. Conversational commerce: Entering the next stage of AI-powered digital assistants. Ann. Oper. Res. 2021, 290, 1–35. [Google Scholar] [CrossRef]
- Liao, Y.; Vitak, J.; Kumar, P.; Zimmer, M.; Kritikos, K. Understanding the role of privacy and trust in intelligent personal assistant adoption. In Proceedings of the 14th International Conference, iConference, Washington, DC, USA, 31 March–3 April 2019. [Google Scholar]
- Moriuchi, E. Okay, Google!: An empirical study on voice assistants on consumer engagement and loyalty. Psychol. Mark. 2019, 36, 489–501. [Google Scholar] [CrossRef]
- McLean, G.; Osei-Frimpong, K. Hey Alexa… examine the variables influencing the use of artificial intelligent in-home voice assistants. Comput. Hum. Behav. 2019, 99, 28–37. [Google Scholar] [CrossRef]
- Pantano, E.; Pizzi, G. Forecasting artificial intelligence on online customer assistance: Evidence from chatbot patents analysis. J. Retail. Consum. Serv. 2020, 55, 102096. [Google Scholar] [CrossRef]
- Smith, S. Voice Assistants Used in Smart homes to Grow 1000%, Reaching 275 Million by 2023, as Alexa Leads th. Juniper Research. 2018. Available online: https://www.juniperresearch.com/press/voice-assis tants-in-smart-homes-reach-275m-2023 (accessed on 25 June 2018).
- Goasduff, L. Chatbots will Appeal to Modern Workers. Gartner. 2019. Available online: https://www.gart ner.com/smarterwithgartner/chatbots-will-appeal-to-modern-workers (accessed on 31 July 2019).
- Swoboda, C. COVID-19 Is Making Alexa And Siri A Hands-Free Necessity. Forbes. 2020. Available online: https://www.forbes.com/sites/chuckswoboda/2020/04/06/covid-19-is-making-alexa-and-siri-a-hands-free-necessity/?sh=21a1fe391fa7 (accessed on 6 April 2020).
- Barnes, S.J. Information management research and practice in the post-COVID19 world. Int. J. Inf. Manag. 2020, 55, 102175. [Google Scholar] [CrossRef] [PubMed]
- Carroll, N.; Conboy, K. Normalising the “new normal”: Changing tech-driven work practices under pandemic time pressure. Int. J. Inf. Manag. 2020, 55, 102186. [Google Scholar] [CrossRef] [PubMed]
- Papagiannidis, S.; Harris, J.; Morton, D. WHO led the digital transformation of your company? A reflection of IT related challenges during the pandemic. Int. J. Inf. Manag. 2020, 55, 102166. [Google Scholar] [CrossRef]
- Marikyan, D.; Papagiannidis, S.; Alamanos, E. A systematic review of the smart home literature: A user perspective. Technol. Forecast. Soc. Chang. 2019, 138, 139–154. [Google Scholar] [CrossRef]
- Abbet, C.; M’hamdi, M.; Giannakopoulos, A.; West, R.; Hossmann, A.; Baeriswyl, M.; Musat, C. Churn intent detection in multilingual chatbot conversations and social media. In Proceedings of the 22nd Conference on Computational Natural Language Learning, CoNLL 2018, Brussels, Belgium, 31 October–1 November 2018; Korhonen, A., Titov, I., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 161–170. [Google Scholar]
- Benbya, H.; Davenport, T.H.; Pachidi, S. Artificial intelligence in organizations: Current state and future opportunities. MIS Q. Exec. 2020, 19, 9–21. [Google Scholar] [CrossRef]
- Fernandes, T.; Oliveira, E. Understanding consumers’ acceptance of automated technologies in service encounters: Drivers of digital voice assistants adoption. J. Bus. Res. 2021, 122, 180–191. [Google Scholar] [CrossRef]
- Hamet, P.; Tremblay, J. Artificial intelligence in medicine. Metabolism 2017, 69, S36–S40. [Google Scholar] [CrossRef]
- Li, B.-H.; Hou, B.-C.; Yu, W.-T.; Lu, X.-B.; Yang, C.-W. Applications of artificial intelligence in intelligent manufacturing: A review. Front. Inf. Technol. Electron. Eng. 2017, 18, 86–96. [Google Scholar] [CrossRef]
- Olshannikova, E.; Ometov, A.; Koucheryavy, Y.; Olsson, T. Visualizing Big Data with augmented and virtual reality: Challenges and research agenda. J. Big Data 2015, 2, 22. [Google Scholar] [CrossRef]
- Young, A.G.; Majchrzak, A.; Kane, G.C. Organizing workers and machine learning tools for a less oppressive workplace. Int. J. Inf. Manag. 2021, 59, 102353. [Google Scholar] [CrossRef]
- Kane, G.C.; Young, A.G.; Majchrzak, A.; Ransbotham, S. Avoiding an oppressive future of machine learning: A design theory for emancipatory assistants. MIS Q. 2021, 45, 371–396. [Google Scholar] [CrossRef]
- Schwenk, H.; Gauvain, J.L. Training neural network language models on very large corpora. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 201–208. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Interspeech; Johns Hopkins University: Baltimore, MD, USA, 2010; Volume 3, pp. 1045–1048. [Google Scholar]
- Huang, Z.; Zweig, G.; Dumoulin, B. Cache Based Recurrent Neural Network Language Model Inference for First Pass Speech Recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 6354–6358. [Google Scholar]
- Sundermeyer, M.; Oparin, I.; Gauvain, J.L.; Freiberg, B.; Schlüter, R.; Ney, H. Comparison of Feedforward and Recurrent Neural Network Language Models. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 8430–8434. [Google Scholar]
- Morioka, T.; Iwata, T.; Hori, T.; Kobayashi, T. Multiscale Recurrent Neural Network Based Language Model. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; ISCA Speech: Dublin, Ireland, 2015. [Google Scholar]
- Hardy, H.; Strzalkowski, T.; Wu, M. Dialogue Management for an Automated Multilingual Call Center. State Univ Of New York at Albany Inst for Informatics Logics and Security Studies. 2003. Available online: https://aclanthology.org/W03-0704.pdf (accessed on 1 January 2003).
- Zweig, G.; Siohan, O.; Saon, G.; Ramabhadran, B.; Povey, D.; Mangu, L.; Kingsbury, B. Automated quality monitoring for call centers using speech and NLP technologies. In Proceedings of the Human Language Technology Conference of the NAACL, New York, NY, USA, 4–6 June 2006; Companion Volume: Demonstrations. [Google Scholar]
- McLean, G.; Osei-Frimpong, K. Examining satisfaction with the experience during a live chat service encounter-implications for website providers. Comput. Hum. Behav. 2017, 76, 494–508. [Google Scholar] [CrossRef]
- Warnapura, A.K.; Rajapaksha, D.S.; Ranawaka, H.P.; Fernando, P.S.S.J.; Kasthuriarachchi, K.T.S.; Wijendra, D. Automated Customer Care Service System for Finance Companies. In Research and Publication of Sri Lanka Institute of Information Technology (SLIIT)’; NCTM: Reston, VA, USA, 2014; p. 8. [Google Scholar]
- Mansurov, B.; Mansurov, A. Uzbert: Pretraining a bert model for uzbek. arXiv 2021, arXiv:2108.09814. [Google Scholar]
- Ren, Z.; Yolwas, N.; Slamu, W.; Cao, R.; Wang, H. Improving Hybrid CTC/Attention Architecture for Agglutinative Language Speech Recognition. Sensors 2022, 22, 7319. [Google Scholar] [CrossRef] [PubMed]
- Mamatov, N.S.; Niyozmatova, N.A.; Abdullaev, S.S.; Samijonov, A.N.; Erejepov, K.K. November. Speech Recognition Based on Transformer Neural Networks. In Proceedings of the 2021 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 3–5 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of theInternational Conference on Machine Learning, Beijing, China, 22–24 June 2014; PMLR: Westminster, UK, 2014; pp. 1188–1196. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Khamdamov, U.; Mukhiddinov, M.; Akmuradov, B.; Zarmasov, E. A Novel Algorithm of Numbers to Text Conversion for Uzbek Language TTS Synthesizer. In Proceedings of the 2020 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 4–6 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Q.; Tu, D.; Xu, S.; Shao, H.; Meng, Q. Natural human-robot interaction for elderly and disabled healthcare application. In Proceedings of the 2014 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Belfast, UK, 2–5 November 2014; IEEE: Piscataway, NJ, USA; pp. 39–44. [Google Scholar]
- Yan, H.; Ang, M.H.; Poo, A.N. A survey on perception methods for human–robot interaction in social robots. Int. J. Soc. Robot. 2014, 6, 85–119. [Google Scholar] [CrossRef]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; PMLR: Westminster, UK, 2016; pp. 173–182. [Google Scholar]
- Sultana; Mariyam; Chakraborty, P.; Choudhury, T. Bengali Abstractive News Summarization Using Seq2Seq Learning with Attention; Cyber Intelligence and Information Retrieval; Springer: Singapore, 2022; pp. 279–289. [Google Scholar]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Okamoto, T.; Toda, T.; Shiga, Y.; Kawai, H. TacotronBased Acoustic Model Using Phoneme Alignment for Practical Neural Text-to-Speech Systems. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 214–221. [Google Scholar]
- Bishop, C.M. Mixture density networks. Tech. Rep. 1994, 1–26. Available online: https://research.aston.ac.uk/en/publications/mixture-density-networks (accessed on 6 April 2020).
- Quatieri, T.F. Discrete-Time Speech Signal Processing: Principles and Practice; Pearson Education India: Noida, India, 2006. [Google Scholar]
- Tamamori, A.; Hayashi, T.; Kobayashi, K.; Takeda, K.; Toda, T. Speaker-dependent WaveNet vocoder. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 1118–1122. [Google Scholar]
- Song, E.; Soong, F.K.; Kang, H.-G. Effective Spectral and Excitation Modeling Techniques for LSTM-RNN-Based Speech Synthesis Systems. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 2152–2161. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Full Name | National ID (NID) Number | Birth Date | Text Format of Recorded Response | GMM-Model Utilized | Call Time |
|---|---|---|---|---|---|
| Abror Salimov | 32007914010096 | 20 July 1991 | Hisob ochish uchun (To open an account)… | Person1.gmm | 13 August 2023, 06:41 p.m. |
| Zafar Odilov | 32806884050115 | 28 June 1988 | Kartadan pul yechish (Withdraw money from the card)… | Person2.gmm | 14 August 2023, 06:56 p.m. |
| … | … | … | … | … | … |
| User Response | Solution |
|---|---|
| Karta PIN kodini unutdim? (Forgot your card PIN?) | Karta ochilgan bank filialiga shaxsingizni tasdiqlovchi hujjat bilan murojaat qilishingiz lozim (You should apply to the branch of the bank where the card was opened with an identity document). |
| SMS-xabarnoma xizmatini ulash (Connect the SMS notification service) | Milliy valyutadagi plastik kartasi uchun sms-xabarnomani infokiosk orqali ulash mumkin(An SMS notification for a plastic card in national currency can be connected through an infokiosk) |
| Bank xizmatlaridan qaysi kunlarda foydalanish mumkin? (On what days can bank services be used?) | Bayram kunlaridan tashqari haftaning dushanbadan juma kunigacha foydalanishingiz mumkin. (You can use it from Monday to Friday, except holidays) |
| . . . | . . . |
| User Response | Domain | Predefined Questions from the System Based on Specific Domain |
|---|---|---|
| Bu bankda mening hisob raqamim bor. Men hisobimdagi oxirgi balansni bilmoqchiman. (I have an account with this bank. I want to know the last balance of my account) | Balance issue |
|
| Mening kartam yo’qolgan. Men nima qilishim mumkin? (My card is lost. What can I do?) | Card issue |
|
| … | … | … |
| Step | Training Loss | Validation Loss | CER |
|---|---|---|---|
| 400 | 6.319100 | 3.322290 | 0.970519 |
| 800 | 2.128300 | 0.678408 | 0.207603 |
| 1200 | 0.879500 | 0.433805 | 0.141339 |
| 1600 | 0.736400 | 0.364600 | 0.121398 |
| … | … | … | … |
| 17,600 | 0.108070 | 0.337852 | 0.065240 |
| 18,000 | 0.106200 | 0.334034 | 0.065009 |
| 18,400 | 0.105120 | 0.332718 | 0.064907 |
| Sample Inputs | Hours of Training | Loss during Training | Loss during Validation | Character Error Rate (CER) |
|---|---|---|---|---|
| 10,000 | 20 | 1.830201 | 1.340452 | 0.840124 |
| 15,000 | 30 | 0.880291 | 0.64385 | 0.306281 |
| 25,000 | 50 | 0.105120 | 0.332718 | 0.064907 |
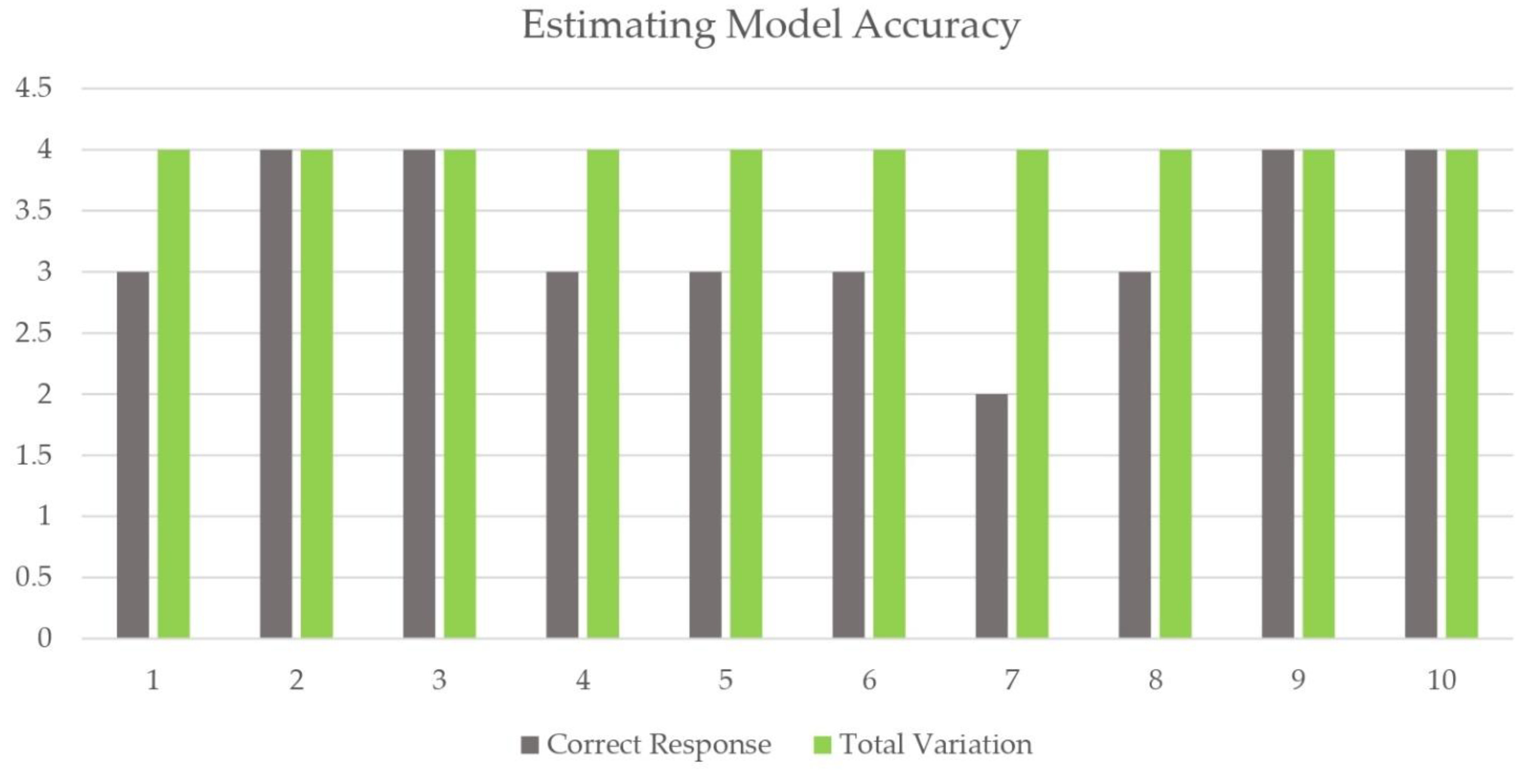
| Sample Question: Siz Kredit Berasizmi? (Do You Give Credit?) | ||
|---|---|---|
| Variations | Response | Correct/Incorrect |
| Sizlarda qanday kredit turlari mavjud? (What types of loans do you have?) | Siz banklardan avtokredit, mikroqarz, iste’mol kreditlari, ipoteka kreditlaridan foydalanishingiz mumkin. (You can use auto loans, microloans, consumer loans, and mortgage loans from banks) | Correct |
| Mikroqarzni qanday rasmiylashtirsam bo’ladi? (How can I formalize a microloan?) | Mikroqarzni rasmiylashtirish uchun kredit menejeriga murojaat etish, kreditni rasmiylashtirishga ariza yozish va bank tomonidan talab etiladigan barcha zarur hujjatlarni taqdim etish lozim. (In order to issue a microloan, it is necessary to contact the credit manager, write an application for issuing a loan and submit all the necessary documents required by the bank). | Correct |
| Kreditingiz haqida bilmoqchimisiz? (Want to know about your credit?) | Agar bizning bankda hisob raqamingiz bo’lsa, siz debit karta ochishga ariza berishingiz mumkin. (If you have an account number in our bank, you can apply for opening a debit card) | Incorrect |
| Kredit to’lovini bankka bormay amalga oshirsam bo’ladimi? (Can I pay the loan without going to the bank?) | Albatta! Identifikatsiyadan o’tkazilgan ilova orqali mijozlar kredit to’lovlarini amalga oshirishi hamda monitoring qilib borishi mumkin. (Of course! Through the authenticated application, customers can make and monitor loan payments.) | Correct |
| Sample Question: Karta Ochishim Uchun Nima Qilishim Kerak? (What Do I Need to Do to Open a Card?) | ||
|---|---|---|
| Variations | Response | Correct/Incorrect |
| Kartaga sms xabarnoma yoqish tartibi qanday? (What is the procedure for enabling SMS notifications on the card?) | Uzcard kartasi sms xabarnomasi bankomat orqali yoqish mumkun. Humo kartasining sms xabarnomasi karta ochilgan filial orqali yoqiladi. (It is possible to activate the Uzcard card SMS notification through the ATM. SMS notification of Humo card is enabled through the branch where the card was opened.) | Correct |
| Karta PIN kodini unutganda nima qilishim kerak? (What should I do if I forget my card PIN?) | Agar Siz kartangizning PIN-kodini unutgan bo’lsangiz karta ochilgan bank filialiga shaxsingizni tasdiqlovchi hujjat bilan murojaat qilishingiz lozim. (If you have forgotten the PIN code of your card, you should contact the branch of the bank where the card was opened with your identity document.) | Correct |
| Karta yo’qotilganda qanday bloklash mumkin? (How to block when the card is lost?) | Kartani blokdan chiqarish uchun karta ochilgan filialga shaxsingizni tasdiqlovchi hujjat bilan murojaat etishingiz lozim. (To unblock the card, you need to contact the branch where the card was opened with your identity document.) | Incorrect |
| Bank filiallariga bormasdan kartaga onlayn buyurtma berish imkoni mavjudmi? (Is it possible to order a card online without going to bank branches?) | Milliy va xorijiy valyutadagi barcha kartalarga Milliy ilova yordamida masofadan turib buyurtma berishingiz mumkin. (You can order all cards in national and foreign currency remotely using the National application.) | Correct |
| Dataset | Accuracy (%) |
|---|---|
| Our USC dataset | 91.29 |
| CC100-uzbek | 88.96 |
| voice-recognition-Uzbek | 78.62 |
| xls-r-uzbek-cv8 | 82.24 |
| Model | LM | AN | SP | SA | Valid | Test | ||
|---|---|---|---|---|---|---|---|---|
| CER | WER | CER | WER | |||||
| E2E-BLSTM | ⨯ | ⨯ | ⨯ | ⨯ | 13.9 | 43.2 | 15.1 | 44.7 |
| ✓ | ⨯ | ⨯ | ⨯ | 14.8 | 30.1 | 15.2 | 31.9 | |
| ✓ | ✓ | ⨯ | ⨯ | 13.8 | 27.7 | 15.5 | 31.2 | |
| ✓ | ✓ | ✓ | ⨯ | 12.7 | 24.8 | 12.3 | 27.8 | |
| ✓ | ✓ | ✓ | ✓ | 10.6 | 22.6 | 11.5 | 23.9 | |
| DNN-CTC | ⨯ | ⨯ | ⨯ | ⨯ | 13.1 | 35.1 | 10.9 | 32.7 |
| ✓ | ⨯ | ⨯ | ⨯ | 10.9 | 21.3 | 9.0 | 25.4 | |
| ✓ | ✓ | ⨯ | ⨯ | 7.3 | 19.4 | 8.1 | 23.9 | |
| ✓ | ✓ | ✓ | ⨯ | 7.2 | 20.2 | 8.7 | 25.4 | |
| ✓ | ✓ | ✓ | ✓ | 6.0 | 17.1 | 6.5 | 21.9 | |
| E2E-Conformer | ⨯ | ⨯ | ⨯ | ⨯ | 9.3 | 40.5 | 12.6 | 44.2 |
| ✓ | ⨯ | ⨯ | ⨯ | 8.2 | 32.6 | 10.3 | 28.6 | |
| ✓ | ✓ | ⨯ | ⨯ | 8.1 | 30.3 | 9.9 | 27.2 | |
| ✓ | ✓ | ✓ | ⨯ | 7.9 | 24.1 | 9.2 | 24.4 | |
| ✓ | ✓ | ✓ | ✓ | 7.6 | 23.1 | 8.9 | 22.3 | |
| Deep Speech 2 | ⨯ | ⨯ | ⨯ | ⨯ | 12.0 | 36.7 | 10.2 | 34.6 |
| ✓ | ⨯ | ⨯ | ⨯ | 11.3 | 26.4 | 9.3 | 25.9 | |
| ✓ | ✓ | ⨯ | ⨯ | 8.9 | 20.6 | 7.1 | 20.7 | |
| ✓ | ✓ | ✓ | ⨯ | 7.2 | 17.5 | 5.9 | 16.9 | |
| ✓ | ✓ | ✓ | ✓ | 5.4 | 15.1 | 5.22 | 13.8 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhamadiyev, A.; Khujayarov, I.; Cho, J. Voice-Controlled Intelligent Personal Assistant for Call-Center Automation in the Uzbek Language. Electronics 2023, 12, 4850. https://doi.org/10.3390/electronics12234850
Mukhamadiyev A, Khujayarov I, Cho J. Voice-Controlled Intelligent Personal Assistant for Call-Center Automation in the Uzbek Language. Electronics. 2023; 12(23):4850. https://doi.org/10.3390/electronics12234850
Chicago/Turabian StyleMukhamadiyev, Abdinabi, Ilyos Khujayarov, and Jinsoo Cho. 2023. "Voice-Controlled Intelligent Personal Assistant for Call-Center Automation in the Uzbek Language" Electronics 12, no. 23: 4850. https://doi.org/10.3390/electronics12234850
APA StyleMukhamadiyev, A., Khujayarov, I., & Cho, J. (2023). Voice-Controlled Intelligent Personal Assistant for Call-Center Automation in the Uzbek Language. Electronics, 12(23), 4850. https://doi.org/10.3390/electronics12234850