1. Introduction
Accurate car orientation prediction is a critical problem in various computer vision (CV) applications, particularly autonomous driving. Understanding the precise angle at which a car is positioned relative to the observer is essential for building intelligent systems capable of making informed decisions in dynamic traffic scenarios. Successful prediction of car orientation can positively impact the performance of tasks such as lane detection, path planning, object detection, and overall safety in autonomous vehicles.
Having the angle information of vehicles in an image can enhance the performance of machine learning (ML) models for many CV tasks. For example, it can be used to refine predictions of detection models by skewing the bounding box according to the car’s angle. The information on orientation can also be used as an additional feature in tracking moving vehicles by predicting the future position as well as searching for similar car angles in consecutive frames. In the case of vehicle classification based on manufacturer and model, knowing the angle of the car is crucial, as some distinctive features can only be seen from certain perspectives. For the segmentation of cars, the orientation encodes information about what parts are visible and need to be delimited.
In addition to improving the predictions of CV models, the angle information of vehicles can be important in deep learning (DL) pipelines. It can filter images based on specific tasks—for example, when working only with images of cars from the front and rear views, all images containing other angles can be removed. The angle annotation can ensure that the training images encompass a diverse range of perspectives, mitigating any potential data imbalance. Moreover, it can be used for training CV models with a curriculum [
1] by initially using samples with normal orientations and progressively adding training images with more unusual angles.
Traditional approaches to car orientation prediction rely heavily on handcrafted features and heuristic-based methods, which may not generalize well to complex real-world scenarios. With the advent of deep neural architectures such as convolutional neural networks (CNNs) and vision transformers, a paradigm shift in CV was observed. Deep neural networks have demonstrated noteworthy capabilities in learning complex patterns and representations directly from raw image data, making them the most effective architectures for various vision tasks.
However, DL models require large and diverse datasets for training to achieve optimal performance and generalization. Existing car angle datasets are often limited in their scope, containing only a limited set of angles and lacking diversity observed in real-world scenarios.
Current Study Objective
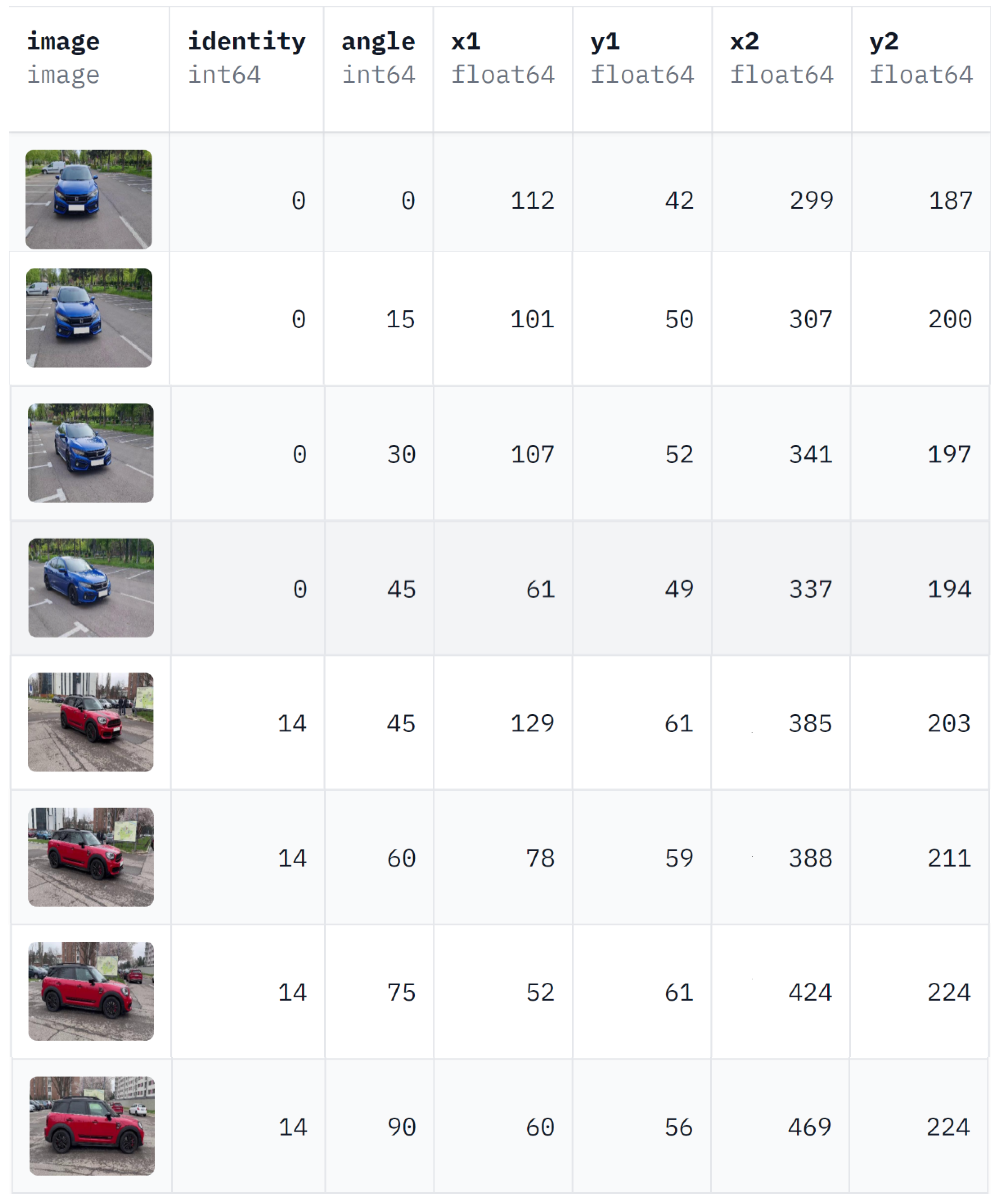
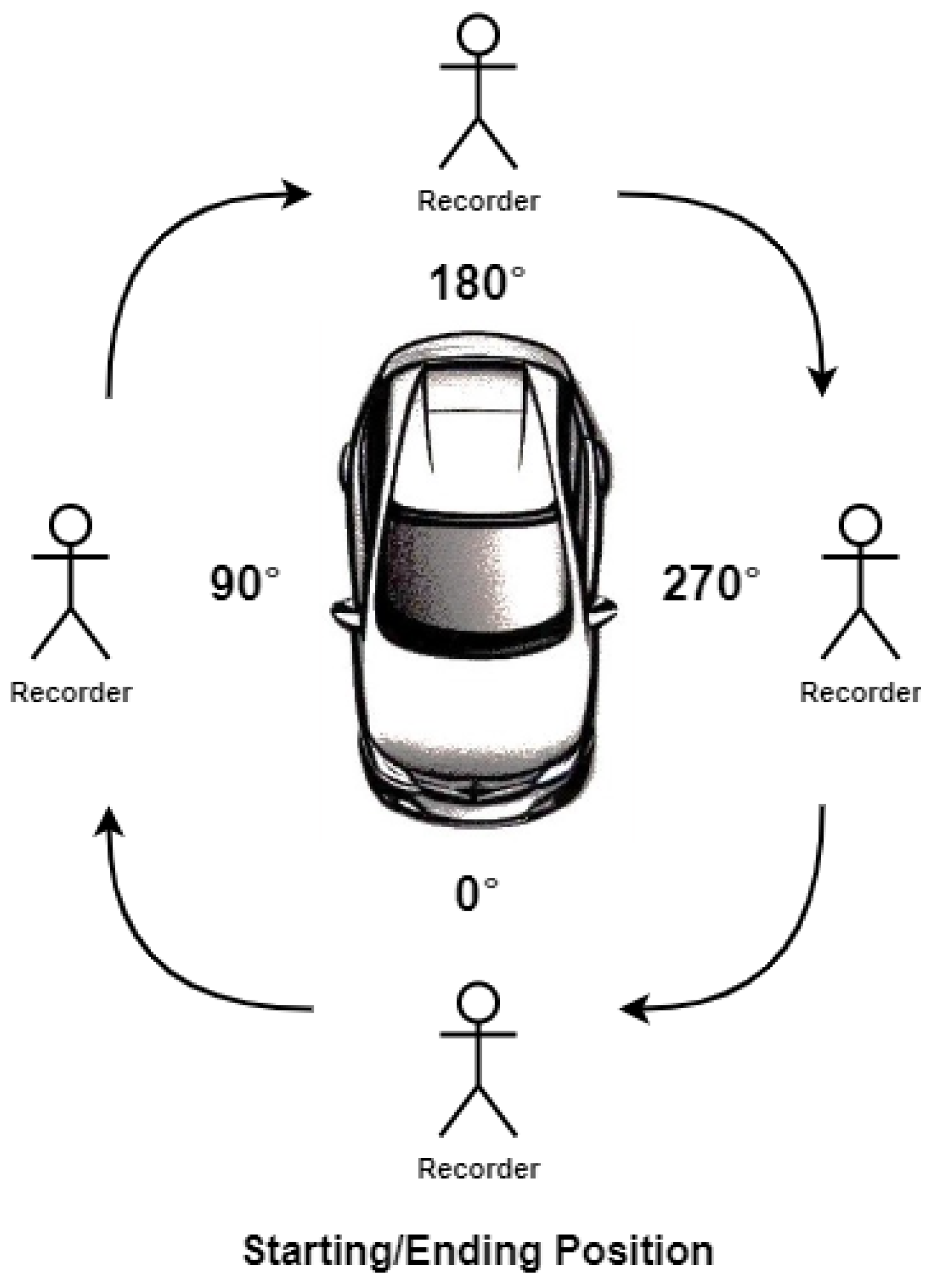
To address the previous limitation of existing datasets that do not specifically tackle car orientation, we introduce the Car Full View (CFV) dataset, a unique and comprehensive collection of images with accurately annotated car angles. Our dataset is meticulously obtained by recording individual cars from all possible angles by circling the vehicle, starting from the front and walking clockwise until returning to the initial position. To ensure diversity and representation of the full range of car orientations, we leverage advanced annotation techniques and proximity-based inference to automatically annotate images in-between the manually annotated angles.
In this work, we introduce the construction and characteristics of our CFV dataset and argue for its utility by training and evaluating a strong baseline of DL models with different backbones (i.e., ResNet [
2], ConvNext [
3], and Swin Transformer [
4]) for car orientation prediction. Through extensive experimentation, we showcase the effectiveness of our dataset in improving model performance and generalization.
The main contributions of our work are as follows:
We present the CFV dataset, a novel dataset with fine-grained annotations for the orientation of vehicles in images collected from a wide range of settings.
We study the performance of state-of-the-art CV models on the proposed dataset and analyze the importance of training loss, initialization, and training-time augmentation, obtaining a circular mean absolute error of 3.39° and an accuracy of 93.97% with the top-performing architecture.
We showcase the importance of having labels for orientation by utilizing them to refine the predicted license plate bounding boxes. Our approach reduces the amount of relevant visual information lost after anonymization.
We argue for the effectiveness and generalization capabilities of our proposed dataset by using the top-performing model to annotate images from two different car datasets: Stanford Cars and Autovit.
2. Related Work
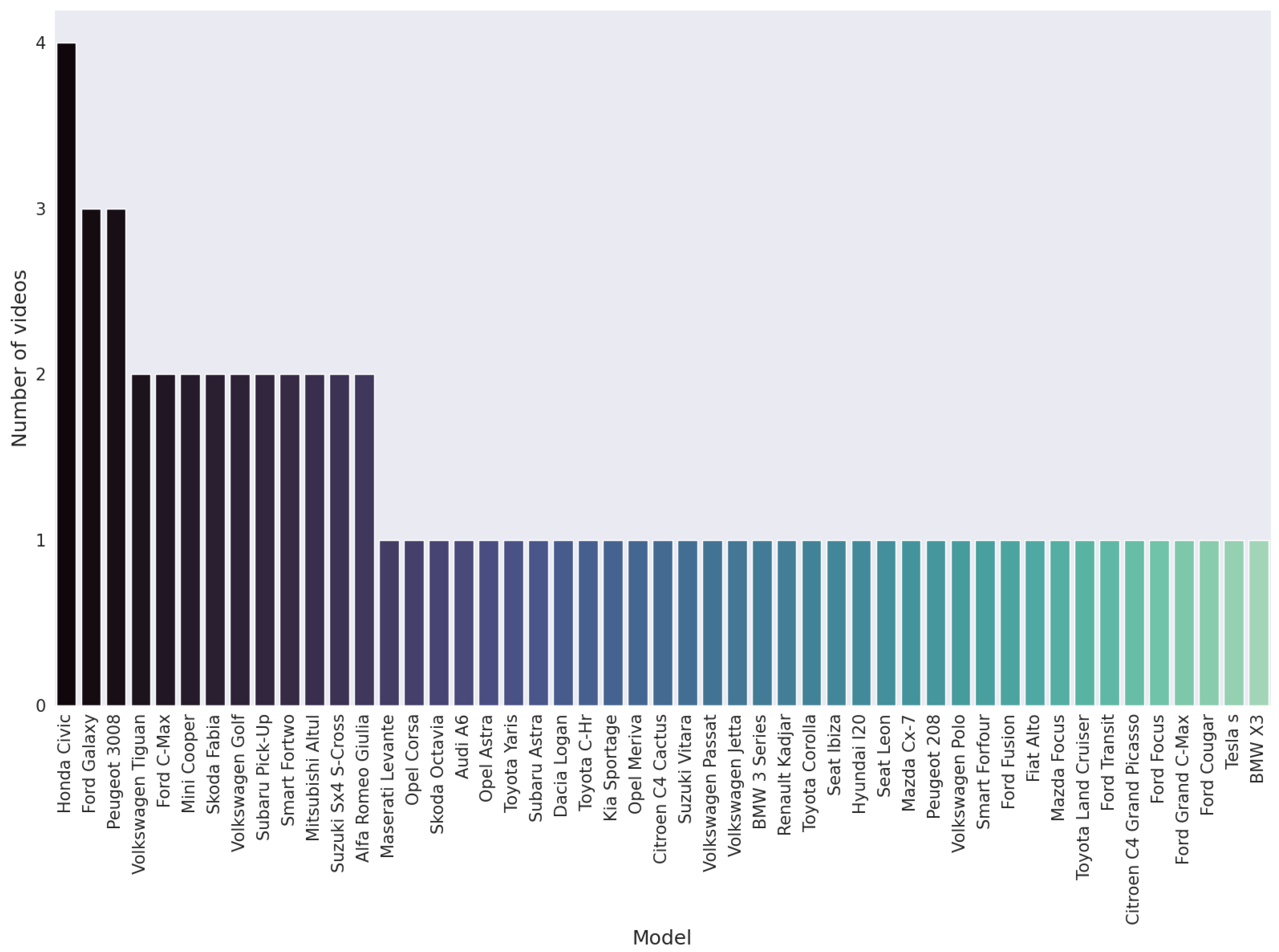
Image-based datasets of cars are relatively scarce and often constrained in scale, posing challenges to CV researchers. Collecting diverse and extensive datasets of cars can be challenging due to the complexity of real-world driving scenarios, variations in car models, orientations, and the need for precise annotations. Many researchers have turned to 3D simulations to generate synthetic data for training and testing their algorithms. While 3D simulations have proven valuable for advancing the field, good performance on synthetic data may not translate to good performance in realistic settings. Because of this, there is a need for more comprehensive, real-world image datasets to bridge the gap between simulated and real-world applications, ensuring that CV models can effectively handle the intricacies of actual road environments.
The task of predicting car orientation has been approached from aerial images, a context that can be relevant for traffic monitoring. The EAGLE dataset [
5] consists of high-resolution images taken from an aerial view for orientation-informed vehicle detection. It contains 8280 high-resolution images with a total of over 215k vehicle instances. Wang et al. [
6] proposed a method for detecting vehicles from unmanned aerial vehicle videos. Their architecture disentangles appearance information from orientation and scale, which makes the predictions robust to such variations. Tang et al. [
7] presented an approach that not only detects vehicles from aerial images but also predicts the orientation, which is utilized to refine the bounding boxes. In contrast to these approaches, our dataset is designed for fine-grained orientation estimation from close-up images of vehicles.
The KITTI dataset [
8] was constructed with the purpose of advancing autonomous driving research and contains data obtained from a moving vehicle in traffic with multiple sensors such as an RGB camera, LiDAR, and GPS. Based on this data, the authors obtain annotations for multiple tasks such as 3D object detection, 3D tracking, depth estimation, and optical flow. Multiple approaches have been introduced for the task of 3D object detection. Kim et al. [
9] utilized a multi-modal approach for predicting the 3D bounding boxes based on both RGB and LiDAR data. Zheng et al. [
10] proposed a teacher–student architecture that leveraged the point clouds obtained by the LiDAR sensor to obtain the 3D bounding boxes. Zhang et al. [
11] attempted to solve the problem of occluded objects by generating multiple possible ground truths with the help of a variational auto-encoder.
Stanford Cars [
12] is a dataset for fine-grained classification of vehicles in terms of make, model, and manufacturing year. The dataset consists of 196 vehicle classes and contains over 16,000 images annotated with the help of crowd-sourcing and majority voting. For the fine-grained classification task on Stanford Cars, multiple methods that achieve high performance have been proposed. Jia et al. [
13] utilized a noisy large-scale dataset to pretrain their ALIGN model in a contrastive manner on text and image data and fine-tune the image encoder for classification. Ridnik et al. [
14] proposed an attention-based classification head that scales better to a large number of classes than classic approaches while providing good efficiency. Liu et al. [
15] proposed a CNN-based approach in which intermediary layers are treated as “experts” specialized in detecting certain discriminative regions. These layers pass on a prediction and an attention map with relevant information to the next layers, enabling more flexibility and creating diversity in the training data with augmentation based on the attention maps.
Dutulescu et al. [
16] constructed a dataset for second-hand car price estimation based on one of the largest platforms for selling vehicles in the Romanian market. The dataset contained the text description of the car, vehicle specifications, information about add-ons, images of the car provided by the seller, and the listed price. The authors of the dataset provided a comprehensive study in which they determined the most relevant features for predicting an accurate price of the car. In a subsequent study [
17], the authors explored the usage of neural networks for determining the car price and expanded their study to the car market of Germany, constructing a dataset from the mobile.de platform for selling cars. In our study, we utilize the Stanford Cars and Autovit datasets to analyze the performance of our models in scenarios and perspectives that differ from those encountered in the training set.
The nuScenes dataset [
18] is a resource for advancing autonomous vehicle technology, offering a comprehensive sensor suite including six cameras, five radars, and one Lidar, providing a 360-degree field of view. It includes 1000 scenes, each with 20 s of data, annotated with 3D bounding boxes for 23 object classes and 8 attributes. With seven times more annotations and 100 times more images than KITTI [
8], nuScenes [
18] introduced novel 3D detection and tracking metrics, along with dataset analysis and baselines for Lidar and image-based methods. Yin et al. [
19] introduced CenterPoint, a 3D object representation and detection framework in point-cloud data. CenterPoint focused on the challenges posed by 3D object orientations and employed a key point-based approach for object center detection. The proposed CenterPoint framework achieves state-of-the-art performance on the nuScenes benchmark for both 3D object detection and tracking. Yang et al. [
20] proposed 3DSSD, a lightweight point-based 3D single-stage object detector that departs from prevalent voxel-based methods. Unlike point-based approaches, it eliminates upsampling layers and the refinement stage, opting for a fusion sampling strategy during downsampling for efficient detection of less representative points.
The Audi Autonomous Driving dataset (A2D2) [
21] is a dataset that contains both recording of images and 3D point clouds, complemented by a rich array of annotations, including 3D bounding boxes, semantic segmentation, instance segmentation, and data derived from the automotive bus. The sensor suite of A2D2 [
21] comprises six cameras and five LiDAR units, providing complete 360-degree coverage and enabling a comprehensive perception of the environment. This dataset encompasses 41,277 frames annotated with semantic segmentation images and point cloud labels. Notably, 12,497 frames within this collection also feature 3D bounding box annotations for objects within the frontal camera’s field of view. Zhang et al. [
22] propose PolarNet, a Lidar-specific segmentation algorithm that distinguishes itself by employing a unique polar bird’s-eye-view representation. This representation efficiently balanced points across grid cells in a polar coordinate system, aligning the segmentation network’s attention with the challenging long-tailed distribution of points along the radial axis. Zhang et al. [
23] introduced a multimodal fusion method designed to assess the contributions of different feature channels from sensors, particularly in the context of Lidar camera fusion networks. This method incorporated a channel attention module that enhanced cross-channel local interaction and assigned weights to feature channels, representing their contributions.
ApolloScape [
24] is a dataset for autonomous driving research, addressing the need for large-scale data to train and evaluate perception models. It includes rich annotations, including semantic dense point clouds, semantic labeling, instance segmentation, and accurate location data across diverse driving scenarios. ApolloScape supports the development of algorithms that jointly consider multiple tasks, fostering advancements in multi-sensor fusion and multi-task learning in CV. It facilitates sensor fusion by integrating camera videos, GPS/IMU data, and a 3D semantic map, enhancing self-localization and semantic segmentation for autonomous driving. Li et al. [
25] addressed the critical issue of ensuring the safety of autonomous driving cars by focusing on motion prediction, a core function of such vehicles. The authors previously introduced GRIP [
26], a scheme designed for efficient trajectory prediction of traffic agents near autonomous cars, significantly improving prediction accuracy compared to state-of-the-art solutions. Chandra et al. [
27] introduced an innovative approach to traffic forecasting in urban scenarios, combining spectral graph analysis with DL. Their model predicted both low-level information (future trajectories) and high-level information (road-agent behavior) using the trajectory data of each road agent.
4. Results
This section presents quantitative and qualitative results for the proposed models on the test set of the CFV dataset. We present the results for the classification approach, regression approach, and finally for multi-task setting.
Table 1 shows the results of the classification models in terms of accuracy for orientation prediction based on the 8 defined classes. The ConvNeXt architecture overfits and cannot capture meaningful features when initialized randomly due to its extensive parameter count in relation to the limited training samples. In the case of weights pretrained on ImageNet, all architectures improve classification accuracy as opposed to random initialization, showing that the learned features extracted by early and intermediary layers are relevant to the prediction of orientation. ResNet obtains the highest classification accuracy in the random initialization scenario as it has the lowest amount of trainable parameters, making it more likely to fit the data. The ResNet and ConvNeXt models obtain the highest accuracy when fine-tuned from pretrained weights, proving that a convolutional backbone is more effective for this classification task.
Table 2 shows the experimental results of the regression architectures for car orientation estimation from images. The ConvNeXt architecture with weak augmentations obtains the smallest circular mean absolute error of 3.58°. For random initialization, we only show the results of the ResNet as it was the only model among the three capable of learning and not overfitting due to its smaller size. For the ConvNeXt and Swin Transformer, we only show the results of the models when starting from pretrained weights because they would require a larger amount of training data to be trained in the random initialization scenario.
The results argue that incorporating augmentation in the training process improves the overall performance of the models on new samples. The weak augmentation setting obtains better results than the custom version of RandAugment for all the regression models. This probably happens because the RandAugment algorithm introduces too much noise to the training samples which makes the model learn a slightly different distribution of the data. In contrast, the weak augmentation setting achieves a balance between introducing diversity in the training samples and avoiding excessive noise that might alter the true data distribution. The top performance obtained by the ConvNeXt model is to be expected since the architecture is an upgraded version of the ResNet model with more efficient modules. Furthermore, convolutional networks usually require less training data than vision transformers to generalize [
37], which explains why the ConvNeXt model outperforms the Swin Transformer.
Figure 8 shows example predictions from the top-performing model in our experiments on the testing set. The trained model manages to generalize to cars that were not seen in the training set and makes predictions very close to the ground truth. For certain cases where the label is slightly incorrect, it even makes better predictions.
Table 3 shows the results of the three models trained with multi-task learning for car angle prediction. In the case of random initialization, only the ResNet architecture manages to learn relevant features and does not overfit. However, none of the models obtained a better performance for this initialization setting than in the case of single-task learning. This probably happens because of the difficulty of the task combined with the relatively small number of samples in comparison to the number of trainable parameters of the model. For initialization with ImageNet pretrained weights, the accuracy shows a slight improvement for all models in comparison to the single-task setting. Furthermore, the CMAE metric is improved compared to the exclusive regression task for all models in the case of fine-tuning pretrained weights. The ConvNeXt model obtains the top result with a CMAE value of 3.39°, which surpasses the previous best model by 0.19°.
5. Discussion
This section starts with a comparison of our dataset to other existing datasets introduced in the Related Work section. Next, we perform an analysis of our top-performing model trained for orientation prediction and discuss its limitations when considering test samples with the highest errors. Afterward, we study the performance of our top-performing model on images from different datasets that contain images of cars from more unusual perspectives. We showcase a real-world application of the orientation model by refining bounding box predictions of license plates based on the estimated car angle. Finally, we explore the reasons behind the predictions, arguing that the model takes global information into account and does not focus on local visual features.
5.1. Comparison to Existing Datasets
Table 4 compares the proposed CFV dataset with other vehicle image datasets. In contrast to the EAGLE dataset, which provides aerial images of vehicles, the CFV dataset is composed of images of cars taken from a close distance. The tasks of 3D detection and trajectory estimation are closely linked with the task of predicting the orientation of vehicles from images. However, while KITTI, nuScenes, A2D2, and ApolloScape focus on the diversity of objects and environments, our proposed dataset focuses on the diversity of angles, providing the full range of possible car orientations.
5.2. Limitations
We investigate the test images in which the orientation model makes the largest error compared to the ground truth.
Figure 9 shows the samples with the highest CMAE, indicating the lowest performance of the orientation model.
A shared characteristic in five of the six samples from the figure is the presence of other vehicles in the background. This could explain the wrong prediction as the early and intermediary layers of the convolutional model extract relevant features of both the main and the background cars. When all the features are combined to make the prediction by the last layers, they may also consider the features extracted from background cars, which affect the output.
The presence of background cars, which impacts the prediction of the orientation model, could theoretically be decreased by cropping the image based on the bounding box obtained by the car detection model. However, we chose not to do so for multiple reasons. First, the YOLOv7 model could not detect the main car in all images from the CFV dataset. Second, cropping the image can result in a loss of context, which might make the orientation model focus on specific local features such as the headlights, license plates, or doors for the prediction instead of looking at the whole vehicle. Third, background cars would still not be fully eliminated as the main bounding box can contain a lot of background information from certain perspectives. Finally, only a small percentage of images with background cars actually impact the orientation prediction, and the samples in
Figure 9, along with their adjacent angles, are the only ones that result in slightly large errors.
5.3. Cross-Dataset Testing
Our proposed models and training techniques achieve great performance and generalization on the testing samples of the proposed dataset. Because of these results, we test the models in more challenging cases on car images coming from other datasets that contain different data distributions and more unusual angles.
Stanford Cars [
12] is a public dataset for fine-grained classification with 196 different classes of vehicles. A class is differentiated based on the make, model, or year of fabrication. However, it does not contain labels for the car’s orientation, which can be impactful in making a correct classification. This dataset has a large intra-class variation as the same car can differ significantly when visualized from another angle.
We also test our orientation prediction model on the Autovit dataset [
16], which is a dataset consisting of car listings from the Autovit website, one of the most prominent platforms for selling cars in Romania. The dataset includes images, prices, and other vehicle-related information. Similarly to the previous example of Stanford Cars, this dataset does not include labels for the vehicle’s orientation in images.
To analyze the generalization capabilities of our proposed dataset, we train the multi-task models on CFV and test them on the Stanford and Autovit datasets. As the datasets do not contain orientation labels, we construct two testing sets by manually annotating 100 images from each dataset. The testing samples were randomly selected to ensure diversity in terms of vehicle models and orientation.
Table 5 shows the performance of the models for cross-dataset testing. The Swin Transformer obtains the highest performance on both testing sets with a CMAE value of 12.12° on Stanford Cars and 5.15° on Autovit. The fact that the Swin Transformer outperforms the ConvNeXt model shows that a slightly better performance on the CFV test set does not necessarily imply a better performance on images outside the training distribution. Despite this, the small CMAE values on these test sets prove that models trained on the CFV dataset have strong generalization capabilities and can estimate the orientation for vehicle models not seen during training.
The difference in performance between the Stanford Cars and Autovit datasets can be attributed to two factors: more unusual perspectives and greater disparity between car bodies. Because the Autovit dataset was collected from a car listing website, it contains vehicle images captured by the car owners in a similar manner to our data collection procedure—photos around the car from a natural height. On the other hand, Stanford Cars was collected from various online sources and can contain vehicle images captured from an unusual height. In terms of car bodies, both Autovit and CFV contain vehicle models prevalent in Europe. In contrast, Stanford Cars contains a majority of vehicle models mostly seen in North America. Hence, there is a larger discrepancy in terms of car bodies between the CFV dataset and Stanford Cars.
Figure 10 shows the qualitative results of our model tested on the Stanford Cars dataset. We observe that most predictions are close to the real orientation. This argues that our dataset has enough diversity, and the proposed training settings aid the model in generalizing to realistic images.
Figure 11 displays examples of predictions of our model on images from the Autovit dataset. As in the previous example, our model obtains results close to the real orientation. This further argues that our model is suited for realistic tasks and can be used to annotate datasets with helpful information.
5.4. Anonymization of Car Plates
As shown in
Figure 7, we can refine the bounding boxes of license plates based on ground truth angle values obtained in the dataset development phase. However, we are interested in the capability of refining license plate detections when there are unlabeled images of cars.
To analyze this, we experiment with car images from the Autovit dataset and utilize the same license plate detection model based on YOLOv5 [
28]. This model detects coarse bounding boxes that contain a lot of car-related visual information apart from the license plate. Removing large parts of the car image can hinder the training process of the image processing architectures. To refine the predicted bounding boxes, we utilize our ConvNeXt multi-task model trained on the CFV dataset to obtain angle predictions on each image. The bounding boxes are modified in the same manner as in
Section 3.1.3, by skewing them according to Equation (
1).
Figure 12 shows examples of anonymized car images from Autovit with our proposed method. Our refinement approach obtains improved bounding box predictions, which have the advantage of not removing as much visual information as the initial detections. This can make training deep learning models on anonymized images more robust as only the necessary pixels are removed while minimizing the lost visual data.
5.5. Explainability
We were also interested in understanding the reasons behind the predictions of the neural network and what features are the most relevant. As such, we utilize gradient-weighted class activation mapping (GradCAM) [
38] to obtain explanations for the predictions of the model, which highlights the regions in the image that contributed most to the decision of the neural network.
Figure 13 displays the GradCAM activations of the ConvNeXt model for five different samples per class from the testing set. The results show that the whole car region determines the class prediction. This is important as looking for specific cues, such as license plates or headlights, can prove problematic in images where only a part of the car can be seen. Furthermore, the model might make incorrect predictions for cars not seen in the training set if it only looks at local visual information and not at the whole vehicle. This behavior is obtained because of the random crop augmentation, which can output images where the full car is not visible in the image, and the model must learn to look for other relevant features.
In addition, the deep learning model mostly focuses on the corner of the car and pays little attention to the full vehicle for certain images showing the vehicle at a diagonal angle. This probably happens because the model has learned to detect the specific shape and contour of the car when seen diagonally. However, this behavior does not always happen for images with cars at a diagonal angle, which may indicate that the contour and shape become important cues for cars not seen in the training set. Another possible explanation for this behavior could be the unusual vertical (pitch) angle. As we keep the pitch angle mostly constant and only vary the yaw angles, images with unusual vertical perspectives may generate unpredictable behavior for the model.
6. Conclusions and Future Work
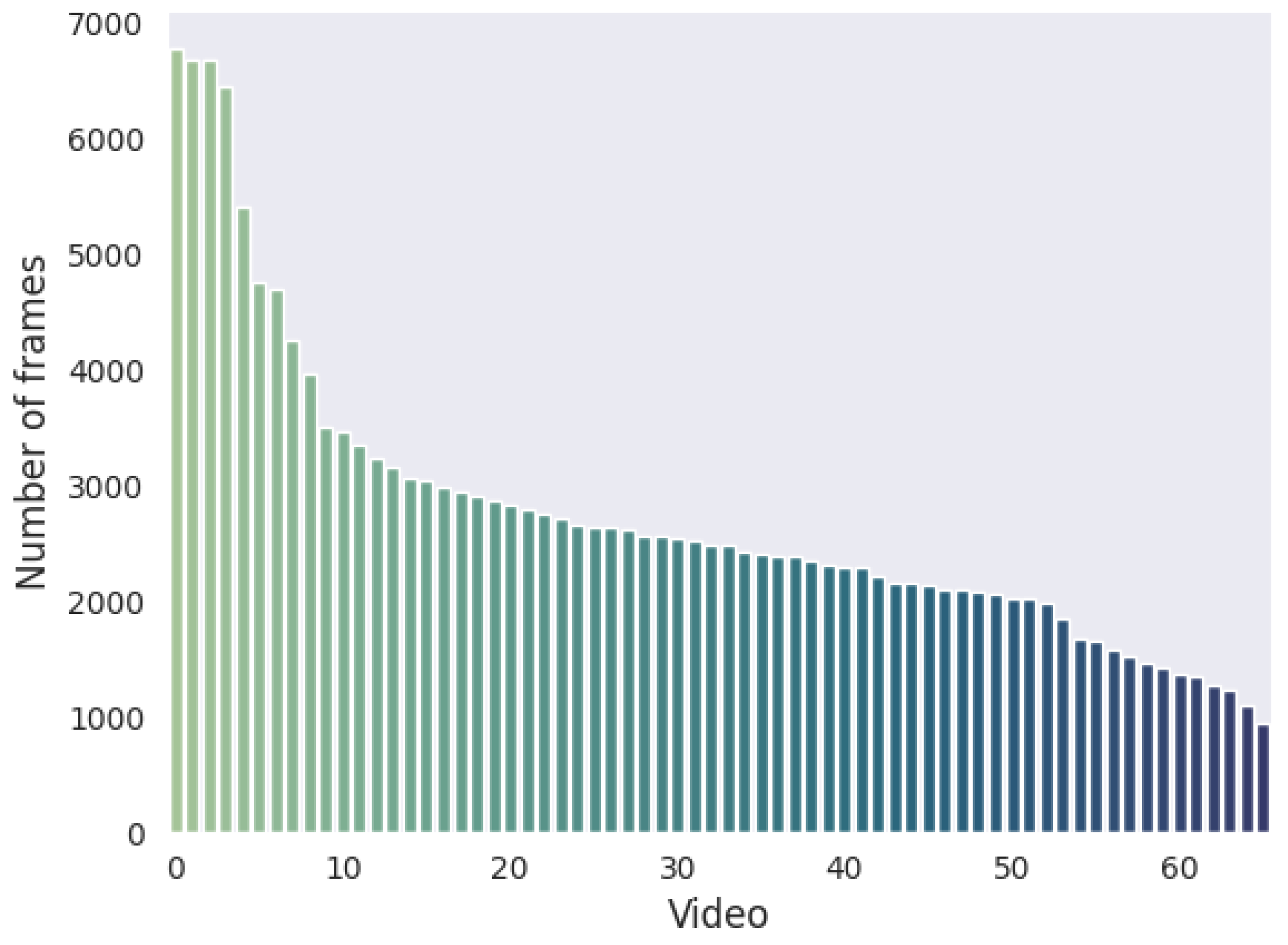
This work presents CFV, a novel dataset for estimating car orientation from images. We collected 66 videos of vehicles recorded by walking around the car in order to capture all possible angles. We annotate all the video frames by leveraging the manual annotations of the key angle frames and the speed of the recording person. Our dataset consists of over 23,000 labeled images that capture cars in diverse backgrounds, lighting, and weather conditions. Using state-of-the-art detection models and the proposed refinement of bounding boxes based on fine-grained angle annotations, we anonymize the images in the dataset by removing the license plates.
We experimented with three popular deep-learning architectures designed for image processing: ResNet, ConvNext, and Swin Transformer. We studied three different approaches to predicting the orientation of cars: first, a classification problem in which the model makes coarse predictions; second, a regression task where the model makes fine-grained predictions, and finally, a multi-objective problem where the model conditions the fine-grained estimation based on the coarse prediction. The best approach employing the ConvNeXt model obtained a CMAE of 3.39°, arguing that a coarse-to-fine approach is the most efficient strategy for predicting the fine-grained angle.
We studied the impact of two initialization approaches for our models: random initialization and initialization from pretrained weights on ImageNet. The results showed that initializing from pretrained weights and fine-tuning the models on our proposed dataset improved performance. For this reason, our dataset should be utilized for fine-tuning on the downstream task of orientation prediction and not for training from scratch.
We analyzed the impact of data augmentation techniques during training for the regression task. We first trained our models without any augmentation, then with weak augmentations that employed random cropping and color jittering, and finally with a custom version of RandAugment from which we removed rotation-based image transforms that affected the overall angle annotation. The results argued that the weak augmentation setting was the most effective as it struck a balance in terms of diversity in the training samples and excessively distorting the images.
We assessed the performance of our trained architectures in cross-dataset settings, where the models were tested on different car images than the ones obtained in our dataset. The qualitative results on Stanford Cars and Autovit datasets showed that the proposed training techniques on the CFV dataset produced models that generalize to realistic settings containing vehicles and perspectives not seen during training.
Our study lays the foundation for other tasks in the automotive domain dependent on object orientation, such as classification, detection, segmentation, and trajectory estimation. In terms of future work, we aim to use the predicted angle on images as an additional supervisory signal for improving the training of computer vision models for other tasks. One of our objectives is to incorporate angle prediction as a task for classification models that estimate the body type, manufacturer, and model of the car. Having angle prediction as an additional task can help the models identify distinctive features exclusive to specific areas of the vehicle. For instance, the manufacturer’s logo appears only on the front or back of the car.
Furthermore, we aim to incorporate the angle annotation obtained by a car orientation model to improve the performance of vehicle part segmentation models. By utilizing the angle and body information obtained from the image, we want to construct a graph of visible vehicle parts to be given as input to the segmentation model along with the image. The graph input enables the segmentation model to only look for visible parts that actually need to be segmented instead of searching for all known classes.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}