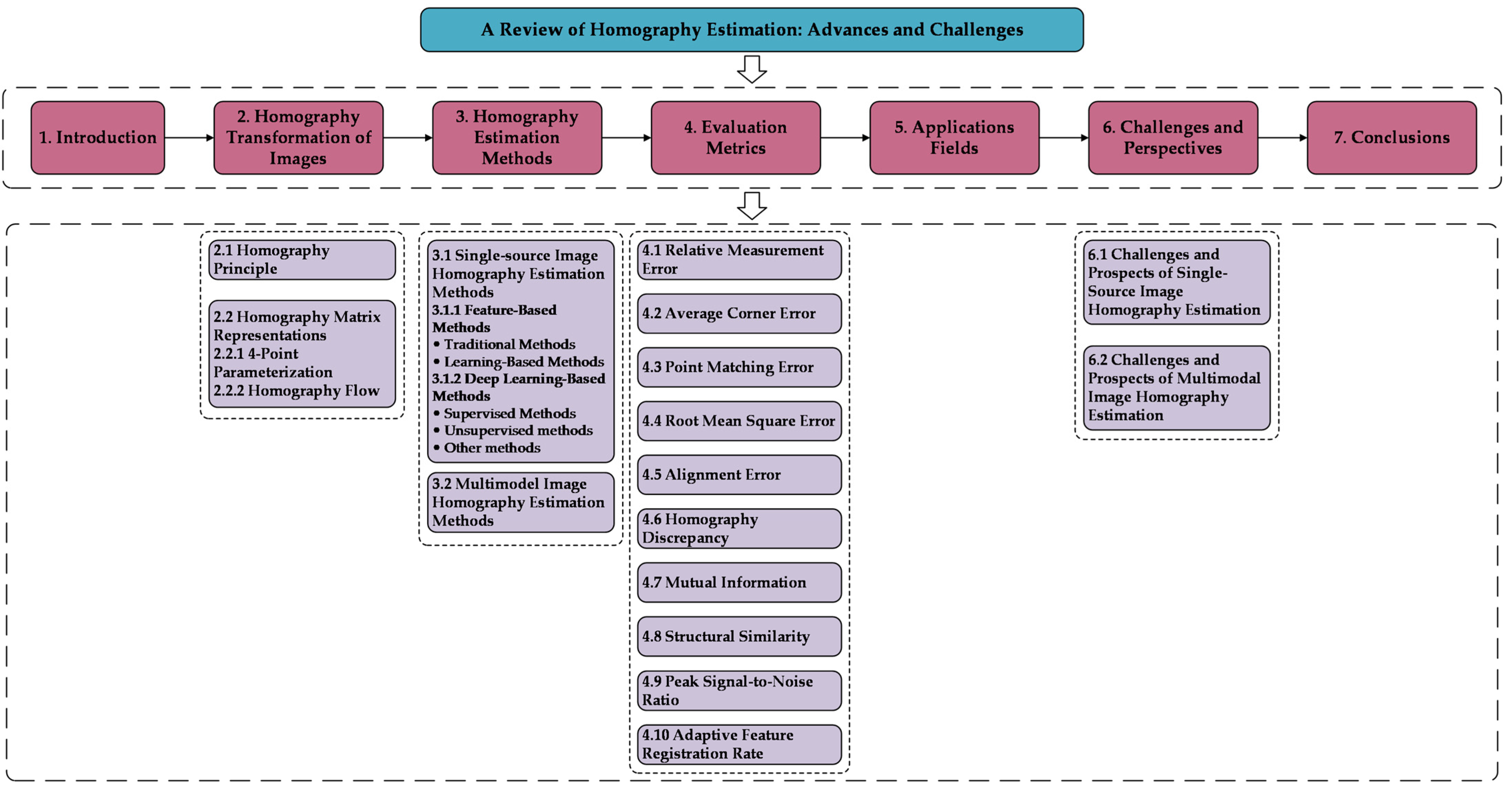
Single-source images are usually acquired by the same equipment from different viewpoints or at different times. These images often show significant geometric variations due to small camera positions or viewing angle changes. To accurately align these images, homography estimation becomes a powerful tool. At this stage, homography estimation algorithms for single-source images can be classified into feature-based and deep learning-based methods.
3.1.1. Feature-Based Methods
The feature-based homography estimation method first detects the feature points in the image by a feature extraction algorithm and computes the similarity metric for matching. Then, utilizing the mapping relationship of the matched feature points, the parameters of the homography matrix are solved [
34]. This procedure is illustrated in
Figure 6. Feature-based methods can be further divided into two categories: traditional methods and learning-based methods.
Traditional Methods. Traditional methods are divided into three main steps: feature detection, feature matching, and homography matrix solving. Firstly, feature extraction algorithms are used to detect feature points in the image and to extract descriptors around these feature points, which are generally represented as vectors. Common methods for extracting features include Scale Invariant Feature Transform (SIFT) [
21], Speeded Up Robust Features (SURF) [
22], Oriented FAST and Rotated BRIEF (ORB) [
23], etc. Similarity measures like the Hamming or Euclidean distance are calculated to provide a criterion for matching feature points. Finally, to improve the estimation’s robustness, e.g., RANSAC or other robust estimation algorithms are usually used to find a consistent subset from these matches and thus estimate the homography matrix.
In recent years, feature point extraction algorithms have received attention and improvement from many researchers. In 2012, Chum et al. [
35] proposed a novel homography matrix estimation method. This method is based on the correspondence between two or more local elliptic features and is estimated using a first-order Taylor expansion. Notable, only one homography model was generated for each pair of elliptic features. This design not only reduces computational costs but also enhances accuracy. In 2014, Liu et al. [
36] proposed BB-Homography, a joint binary feature and bipartite graph matching algorithm for homography estimation. First, BB-Homography employs bipartite Graph Matching (GM) to enhance the matching results of binary descriptors and ascertain the correlation between preliminary keypoint correspondences and homography estimation. Next, GM is iteratively executed to refine the results to obtain more accurate homography estimates. Yan et al. [
37] proposed a Homography Estimation method based on Appearance Similarity and Keypoint correspondence (HEASK), combining the keypoint correspondence and appearance similarity models. In the keypoint correspondence model, the Laplace distribution replaces the Gaussian distribution to represent the distribution of inlier location error. In the appearance similarity model, the Enhanced Correlation Coefficient (ECC) is used to describe image similarity. The combination of these two models makes the results of the homography estimation more robust.
In 2016, Zhao et al. [
38] proposed a feature-based homography estimation method to enhance estimation accuracy and better handle positioning errors. The method introduces the compensation, representation, and weighting methods for localization error based on existing methods to alleviate the problem of degradation of estimation accuracy and robustness caused by localization error. Specifically, it uses High-accurate localized features for SIFT (HALF-SIFT) to compensate for localization errors caused by feature extraction and the covariance matrix to describe localization errors caused by image noise. However, the running time of the method is long. In 2019, Barath et al. [
39] proposed a geometric interpretation of the angles and scales provided by orientation and scale-variant feature detectors such as SIFT. They introduced two new generic constraints for scales and rotations and designed a new solver capable of estimating the single homography matrix from at least two correspondences. Suárez et al. [
40] proposed Boosted Efficient Binary Local Image Descriptor (BEBLID) in 2020. This method is similar to SIFT in accuracy but better in computational efficiency than ORB.
After the SIFT algorithm was proposed, some traditional methods considered tradeoffs in the balance between speed and accuracy. One Improving approach is HALF-SIFT, which aims to improve accuracy. Other algorithms, such as ORB and BEBLID, are developed to balance computation time and accuracy. Therefore, algorithms such as SIFT or HALF-SIFT are better for images with complex scene changes. For cases requiring a higher response speed, it is preferable to use algorithms such as SURF and BEBLID.
Furthermore, besides refining the feature extraction algorithms, some scholars focus on improving the RANSAC outlier suppression algorithm. Examples include FT-RANSAC [
41], MAGSAC++ [
42]. In 2023, Rodríguez et al. [
43] proposed several modifications to the RANSAC algorithm. The method combines affine approximation and an inverse approach to improve the homography estimation between pairs of images. This inverse approach defines estimation robustness and enables adaptive thresholding to differentiate outliers, improving the success rate of image pair recognition.
Notable, most traditional homography estimation algorithms are based on calculating the mapping relationship between feature points to solve the homography matrix, but some scholars hold a different view. They believe that line feature-based homography estimation methods outperform feature point-based methods in terms of performance, mainly because line features are usually more noise-resistant than point features in detection. In 2008, Dubrofsky et al. [
44] proposed an extended normalized direct linear transformation algorithm. The approach integrates the correspondence of line features into the computation of the homography matrix by introducing line normalization equations that are compatible with point normalization. However, Zeng et al. [
45] pointed out that line-based homography estimation can be highly unstable when the image line passes through or near the origin. To tackle this issue, they proposed a novel line normalization method. The approach first performs a normalization transformation on the corresponding line segments of the two sets of images to make their distribution in the images more uniform. Subsequently, the DLT algorithm is employed on this new set of line correspondences to solve the homography matrix. In 2016, Huang et al. [
46] proposed a homography estimation method for ellipses using a common self-polar triangle of two ellipses. The method obtained the correspondence of four lines using the quadratic curves and the self-polar triangles, which provides sufficient computational conditions for homography estimation.
Based on this, some researchers began using the correspondences of point and line features to solve the homography [
47,
48]. In other words, by effectively using all available point and line correspondences, the accuracy of homography estimation can be significantly improved under different measurement conditions. This brings a new direction for further research. However, whether based on point features or line features, the performance of traditional homography estimation methods is still not stable enough in highly noisy or non-texture images. In addition,
Table 1 provides a comprehensive analysis of homography estimates from traditional models.
Learning-Based Methods. Learning-based methods for homography estimation use neural networks to replace the feature extraction or feature matching in traditional algorithms and then use traditional methods to estimate the homography transformation parameters at other steps. Both learning-based and traditional methods involve feature detection, feature matching, and homography matrix solving. The main difference is that traditional methods usually rely on hand-designed feature extractors to detect and match local features, and learning methods use convolutional neural networks to detect or match features.
In 2016, Yi et al. [
49] proposed the Learned Invariant Feature Transform (LIFT) algorithm, which combines local features for detection and description. It does so by integrating three standard pipeline components into a differentiable network and training end-to-end using backpropagation. In 2018, DeTone et al. [
50] presented the Self-Supervised Interest Point Detection and Description (SSIPD) algorithm, known as the SuperPoint algorithm. The algorithm can simultaneously compute pixel-level interest point locations and corresponding descriptors in forward passes by running a fully convolutional model on a full-size image. They further propose a multi-scale, multi-homography method to improve the reproducibility of interest point detection and enable cross-domain adaptation (e.g., from synthetic to real). Notable, the SuperPoint algorithm can identify a wider range of points of interest compared to both the original pre-adapted depth model and other traditional corner detectors. In 2019, Tian et al. [
51] proposed the Similarity Regularization for Local Descriptor Learning (SOS-Net) algorithm, which incorporates second-order similarity into local descriptor learning to achieve more precise outcomes. Zhang et al. [
52] proposed the Order-Aware Networks (OANs) for probabilistic outlier detection and relative pose regression encoded in the underlying matrix. OANs comprise three hierarchical operations. Firstly, the correspondences of unordered inputs are clustered to capture the local context of sparse correspondences by learning soft assignment matrices. These clusters have a canonical order and are independent of input alignment. Second, these clusters relate to each other spatially to form the global context of the correspondences. Finally, the context-encoded clusters are restored to their original size using an upsampling operator.
As feature information extracted by neural networks gradually becomes complex, researchers find that the traditional feature-matching methods have limitations. Thus, they began to use neural networks to replace the feature-matching algorithms [
53,
54,
55]. In 2020, Sarlin et al. [
56] proposed SuperGlue, a local feature-matching network based on Graph Neural Networks (GNN). SuperGlue uses a flexible attention-based context aggregation mechanism to jointly reason about the underlying 3D scene and feature assignments over the complete graph. Moreover, it matches local features via the joint identification of correspondences and rejection of non-matchable points. In 2022, Shi et al. [
57] proposed a Cluster-based Coarse-to-Fine Graph Neural Network (ClusterGNN). Compared to SuperGlue, ClusterGNN integrates a progressive clustering module to decrease redundant connections in the whole graph computation, thus reducing the misclassification of images and improving feature-matching accuracy. Wang et al. [
58] proposed a hierarchical feature extraction and matching transformer called MatchFormer. MatchFormer uses a lightweight decoder similar to Feature Pyramid Network (FPN) to fuse multi-scale features and integrates self-attention and cross-attention to perform feature extraction and feature similarity learning to achieve the best feature matching. These methods show that neural networks have equally powerful capabilities for feature matching.
The feature estimation method’s accuracy has been improved by replacing the feature extraction or matching parts of the traditional method with neural networks. However, since the other processes and outlier suppression still use traditional methods, they still have some shortcomings when faced with challenging image scenarios. Nonetheless, the learning-based methods also bring new insights that influence the development of deep learning-based homography estimation methods. In addition,
Table 2 presents a detailed examination of learning-based homography estimation for single-source images.
3.1.2. Deep Learning-Based Methods
With the development of deep learning techniques, it has achieved excellent results in the field of computer vision, especially in tasks such as image classification, target detection, and semantic segmentation. Notable, more and more scholars have begun to apply deep learning to the research of homography estimation, and significant progress has been achieved. Compared to learning-based methods, deep learning-based methods transform the traditional multi-step feature extraction and matching process into a unified, trainable framework that novelty understands and handles complex image correspondences. This technique dramatically improves the efficiency and quality of feature extraction and opens new ways to improve matching accuracy and robustness.
These deep learning-based homography estimation methods can be mainly classified into two categories: supervised and unsupervised. They usually adopt two forms of homography matrix representation: 4-point parameterization and homography flow. Specifically, the 4-point parameterized form is commonly used in both supervised and unsupervised methods, while the homography flow form is mainly used in unsupervised methods.
Supervised Methods. Supervised homography estimation methods primarily utilize synthetic examples with ground-truth labels to train the network. In 2016, DeTone et al. [
31] pioneered the introduction of deep learning into the field of homography estimation, propounding a 4-point parametric representation of the homography matrix for network training and convergence.
Figure 7 shows their network structure. This research utilizes Convolutional Neural Networks (CNNs) to automatically learn and predict geometric transformations between images from pixel-level data, demonstrating the potential of deep learning in understanding and processing complex geometric relationships between images. Additionally, regarding the importance of pixel analysis in homography estimation, the study by Valjarević et al. [
59] provides a valuable perspective. They conducted a detailed pixel-level analysis of forest change using GIS and remote sensing techniques, illustrating the extraction of useful information from complex environmental data. This showed that pixel-level information can effectively understand and interpret complex spatial relationships in unstructured environments. Incorporating the deep learning approach of DeTone et al. with the pixel analyses of Valjarević et al. can provide a more comprehensive framework for understanding and improving homography estimation techniques. The interdisciplinary integration enriches our understanding of homography estimation methods and highlights the importance and application value of pixel-level analysis when dealing with complex visual data. It suggests potential improvements to current methods and provides new directions for future research.
In 2018, Wang et al. [
60] proposed a ShuffleNet-style compressive neural network for point group convolution and channel shuffling-based homography estimation. This network is only 9.9 MB and achieves robust homography estimation with few parameters. Following the same thought, Chen et al. [
61] developed a scalable compression network for homography estimation based on the ShuffleNetV2 compression unit. The network diminishes the model size to under 9 MB and well balances the accuracy and inference speed of homography estimation. In 2019, Kang et al. [
62] proposed a hybrid framework, HomoNetComb, for homography estimation. The framework first uses a lightweight CNN model, HomoNetSim, to predict the initial homography and then minimizes the masked pixel-level photometric discrepancy between the distorted image and the target image by a gradient descent algorithm to iteratively refine the homography matrix. Due to the small network size of HomoNetSim, the computational time for training and inference is reduced extensively.
In 2020, Le et al. [
63] designed a multi-scale neural network to handle large motion scenes. They integrated a dynamics mask network into the multiscale network to adapt to dynamic scenes, thus developing a dynamically aware homography estimation network capable of both homography and dynamic estimation. This method can robustly estimate homography when dealing with dynamic scenes, blurry artifacts, or challenging scenes lacking texture. Mi et al. [
64] proposed a recurrent convolutional regression network for video homography estimation by combining a CNN with a Recurrent Neural Network (RNN) [
65] with Long Short-Term Memory (LSTM) units [
66]. The network exploited the temporal dynamics between frames in the video to accurately estimate homography between non-adjacent frames. In 2021, Shao et al. [
67] proposed LocalTrans, a local transformer network that embeds a multiscale structure specifically designed to explicitly learn the correspondence between multimodal input images with different resolutions. This network provides a local attention map for each position in the feature. The network can efficiently capture short- and long-range correspondences by combining the local transformer with the multi-scale structure. It accurately aligns images even with a 10× resolution gap and performs excellently on challenging cross-resolution datasets.
In 2022, Cao et al. [
68] proposed the Iterative Homography Network (IHN) based on the iterative concept. Unlike previous methods that utilize network cascades or untrainable iterators for iterative refinement, IHN’s iterators possess tied weights and are entirely trainable. To better address dynamic scenes with moving objects, they designed the IHN-mov. IHN-mov improves the estimation accuracy in moving object scenarios by generating an outlier mask. The iterative structure of IHN can reduce the error by 95% and significantly reduce the number of network parameters. In the following year, Cao et al. [
69] proposed a framework for recurrent homography estimation called RHWF. This framework combines homography-guided image warping and the Focus Transformer (FocusFormer). Image warping improves feature consistency, while FocusFormer employs the attention-focusing mechanism to aggregate the intra-inter correspondence in global, non-local, and local. Compared to previous methods, RHWF has significantly fewer parameters, but homography-guided image warping and attentional manipulation increase the computational cost. Jiang et al. [
70] proposed a supervised training of a homography network using generated realistic data. Initially, they label the unlabeled image data using the pre-estimated principal plane mask, homography, and another ground truth sampled homography. Then, the generated data are used to train the supervised homography network, and the data generation and training are iteratively performed to obtain a highly accurate homography estimation network. This method reduces the effect of moving objects that cannot be aligned by homography. It greatly aligns the central plane objects, making the supervised homography estimation method better adapted to real scenes.
To address the problem of degraded prediction accuracy of overly simple convolutional neural networks when performing homography regression due to ignoring redundant information in the feature map, Li et al. [
71] proposed a deep learning method based on a multi-scale transformer. The method extracts feature maps from different scales using a hierarchical design. It handles the prediction of the matrices separately by using a DFA-T module and a context-sensitive correlation module, which allows the estimation of homography matrices from coarse to fine. DFA-T processes the semantic information of high-level features to achieve coarse-grained alignment, while context-dependent modules are used to achieve more accurate alignment. To address the issue of the limited receptive field in extracting dense features using convolutional networks, Zhou et al. [
14] proposed a staged strategy. They first estimate the projection transformation between the reference image and the target image at a coarse level and then refine it at a finer level. To enhance the features’ relevance and the estimation’s accuracy, they introduced self-attention and cross-attention schemes into the transformer structure. This method shows significant performance advantages in large baseline scenarios.
Specifically, integrating the Transformer into neural networks inspired subsequent researchers, making deep learning-based homography estimation methods no longer limited to CNNs. Whether supervised or unsupervised, the network structures such as Transformer [
72], GAN [
73,
74], and GNN [
75] have been extensively utilized in this technical field. This has led to the discovering of new possibilities for further deep learning-based homography estimation algorithm research. However, while supervised methods have achieved more apparent advantages in terms of performance and accuracy of feature extraction than feature-based methods, a challenge they face is the difficulty in obtaining large training datasets with real labels to train the network. Although synthetic datasets can be utilized in training, the lack of depth differences in realistic scenes in synthetic training data reduce the network’s generalization ability. Therefore, research on deep learning-based homography estimation algorithms gradually turns towards unsupervised methods. Furthermore,
Table 3 presents a thorough examination of supervised deep-learning techniques for image homography estimation.
Unsupervised methods. Unsupervised methods generally acquire the homography matrix by reducing the loss between two images. This is accomplished by training on actual image pairs and transforming the source image to the target image using the Spatial Transform Network (STN) [
76].
In 2021, Ye et al. [
33] proposed a new unsupervised deep homography framework in 2021. They first introduced the idea of a homography flow representation, estimated by a weighted sum of eight predefined homography flow bases. Since homography contains only 8 degrees of freedom, which is far from the rank of the network features, they introduced a Low-Rank Representation (LRR) block. This design retains features related to the dominant motion while excluding irrelevant features. A Feature Identity Loss (FIL) was introduced to improve the model’s efficacy further, which ensured that the learned image features remained unchanged after distortion. In other words, the results should be consistent whether the warping operation or the feature extraction is done first. However, the method may fail in large baseline scenarios, and a single homography output may not be sufficient in real-world scenarios. In 2022, Hong et al. [
77] proposed a new method called HomoGAN, which focuses homography estimation more on the principal plane. HomoGAN first constructs a multi-scale transformer network that predicts the homography from a pyramid of features in the input image in a coarse-to-fine manner. To impose coplanarity constraints, they introduce an unsupervised Generative Adversarial Network (GAN). The generator predicts the masks of the aligned regions, while the discriminator verifies that the two mask feature maps are induced by a single homography. The homography flow form provides a novel solution to homography matrices, which can handle the feature information brought by the dominant motion or related to the principal plane and opens up a new avenue for future research. Otherwise, except for the above two methods that used the homography flow representation of the homography matrix, the other methods used the 4-point parameterization form.
In 2017, Erlik et al. [
78] presented a hierarchy of twin convolutional regression networks to estimate the homography between two images. The networks are stacked sequentially in this framework to reduce the estimation error progressively. Every convolutional network module autonomously extracts features from both images and then fuses these features to estimate the homography. Because of its iterative nature, the method does not require complex models, and a hierarchical arrangement of simple models can achieve high-performance homography estimation, which shows new paths to optimize the balance between complexity and performance. In 2018, Nguyen et al. [
79] trained a neural network using pixel-wise photometric loss, which measures the pixel error between a warped input image and another image. This method allows unsupervised training without real labels. Compared to traditional methods, it is not only faster but also equal or better in accuracy and robustness to light variations. However, it does not fully account for the complexity of dealing with depth differences and moving objects in real-world applications. In 2019, Zhou et al. [
80] proposed a neural network named STN-Homography based on a spatial transform network. The method aims to estimate the normalized homography matrix of image pairs directly. They designed hierarchical STN-homography and sequential STN-homography models with end-to-end training to reduce estimation error. This approach yielded dramatic improvements in accuracy and efficiency, providing new inspiration for unsupervised methods for researchers.
In 2020, Zhang et al. [
81] designed a content-aware, unsupervised homography estimation method for image pairs with small baselines; its network structure is shown in
Figure 8. For robust homography optimization, the method implicitly learns deep alignment features and a content-aware mask that helps the network select only reliable regions for homography estimation. Furthermore, learned features are used to compute the loss, while content-aware masks allow the network to focus on the regions that are important and representable. To optimize this network, they introduced a new triplet loss for unsupervised learning to optimize this network. Specifically, introducing content-aware masks has guided the design of future deep homography estimation networks. Numerous scholars have begun to realize that image masks can improve the performance of networks effectively and have begun to incorporate various types of attentional mechanisms into networks for robust homography estimation [
82,
83,
84].
In 2020, Kharismawati et al. [
85] proposed an unsupervised deep homography estimation method for agricultural aerial imagery. They improved the unsupervised CNN network of Nguyen et al. and used the video of maize nurseries imaged with a freely flown consumer-grade vehicle to train the network. This method can estimate the sequence of planar homography matrices of our corn fields from imagery without using metadata to correct estimation errors. It performs faster than the gold standard ASIFT algorithm while maintaining accuracy comparable to ASIFT. In 2021, Koguciuk et al. [
86] proposed a bidirectional implicit Homography Estimation (biHomE) loss for unsupervised homography estimation. This method distinguishes homography estimation from representation learning for image comparison and enhances the robustness of homography estimation results to variations in illumination by minimizing the distance in feature space between the distorted image and the corresponding image. To combat the lack of robustness of traditional methods in low texture scenarios and the poor performance of deep learning-based methods in low overlap rate scenarios, Nie et al. [
87] proposed a depth-aware multi-grid deep homography estimation network in 2021. This network achieves global to local parallax image alignment, overcoming the limitations of existing deep homography estimation methods. The method also designed a Contextual Correlation Layer (CCL) to extract the matching relationship, making the network better than the cost volume regarding performance, number of parameters, and speed. The method successfully overcomes the lack of robustness of traditional methods in low-texture scenes and the poor performance of deep learning-based methods in low-overlap scenes. However, the network structure and data size may limit the number of meshes for this network.
In 2022, Wu et al. [
88] presented an unsupervised homography estimation algorithm incorporating a correction function. It employs a two-level network cascade structure, an idea similar to iteration. Each level of the network comprises an equivalent number of layers and parameters. The output homography matrix of the next network level is the residual of the true matrix and the sum of the previous output homography matrix. The method compensates the inputs of the next level network with the outputs of the previous level network, leading to the correction of the homography estimate. To tackle mis-correspondence due to appearance changes, relative motion between camera and object, and occlusion challenges, Zhang et al. [
89] proposed a unified convolutional neural network model, HVC-Net. The model combines homography, visibility, and confidence and embeds them all into a Lucas-Kanade tracking pipeline to achieve accurate and robust planar object tracking of planar objects. This method can deal well with mismatches caused by such issues as changes in appearance, relative motion of camera and object, and occlusion, making homography estimation more widely applicable to object recognition and tracking. Nevertheless, due to the limitations of the LK-based method, the method sometimes suffers from the interference of similar occluding object factors.
In 2023, Hou et al. [
30] proposed an unsupervised homography estimation method. Firstly, they constructed an unsupervised homography estimation method based on cascaded CNNs to solve the problem of low accuracy of existing unsupervised homography estimation methods. This method uses a two-stage cascade network structure and predicts the residuals of the overall homography at each stage. It can minimize the pixel intensity error between the two images and implements an unsupervised coarse-to-fine homography estimation. To address the issue of image homography under large parallax, Hou et al. [
90] designed an unsupervised Multiscale Multi-stage based Content-Aware Homography Estimation method (MS2CA-HENet). This method uses images of different sizes as inputs in different stages to deal with different scales of homography transformations between images. Notably, they account for local and global features at each stage via a Self-attention Augmented Convolutional Network (SAC) and minimize the error residual at each stage to estimate the homography of large-displacement image pairs from coarse to fine.
Unlike supervised methods, unsupervised methods do not require labeled data but are more difficult to train and optimize. In particular, they face challenges in optimizing complex network structures and balancing performance. However, unsupervised learning still opens new research directions for deep learning-based homography estimation methods. In addition, a comprehensive analysis of unsupervised deep-learning homography estimation algorithms for single-source images is presented in
Table 4.
Other methods. Besides the supervised and unsupervised methods discussed above, researchers have used other methods (e.g., self-supervised and semi-supervised) to tackle the task of homography estimation. Self-supervised algorithms can self-generate supervised signals for training, i.e., labels are automatically generated from unlabeled input data and used for training iterations. Compared to supervised and unsupervised methods, self-supervised methods effectively reduce the dependence on labeled data while increasing the use of unlabeled data, thus improving the robustness of the model. In 2019, Wang et al. [
91] proposed the Self-Supervised Regression Network (SSR-Net). This method reduces the dependence on actual image annotations and uses a spatial pyramid pooling module to use contextual information to improve the quality of extracted features in each image. Furthermore, they chose the homography matrix representation rather than the 4-point parametrization to exploit reversibility constraints. In 2022, Li et al. [
92] proposed the Self-Supervised Outlier Removal Network (SSORN), which incorporates a novel self-supervised loss function to remove noise in the image, mimicking the traditional outlier removal process. In 2023, Liu [
13] et al. proposed a novel detector-free feature-matching method called Geometrized Transformer (GeoFormer). This method integrates GeoFormer into the LoFTR framework and trains end-to-end in a fully self-supervised manner. It can compute cross-attention diffusion regions in a focused manner and enhance local feature information through the Transformer.
Compared to self-supervised methods, which can automatically generate labeled data, semi-supervised learning requires training with both limited amounts of labeled data and large amounts of unlabeled data and attempts to use structural information in the unlabeled data to augment the learning process. Semi-supervised learning combines the advantages of both supervised and unsupervised methods and is more efficient on large-scale datasets. As a result, network models trained using semi-supervised methods have better generalization ability. In 2023, Jiang et al. [
93] proposed a progressive estimation strategy. The strategy reconstructs the original homography by converting the large baseline homography into multiple intermediate homography terms and cumulatively multiplying these intermediate terms. Meanwhile, the method uses supervised and unsupervised losses to optimize intermediate homography and estimate large baseline homography without photometric losses. The approach effectively copes with the errors in homography estimation for large baselines, especially in the context of low image coverage and limited sensory field. Additionally, a comprehensive analysis of self-supervised and semi-supervised deep-learning homography estimation algorithms for single-source images is presented in
Table 5.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}