1. Introduction
The past decade has witnessed the astonishing evolution of deep learning techniques. The success of deep learning models, especially convolutional neural networks (CNNs) [
1,
2], has dramatically facilitated the advancement of computer vision and graphics, making CNNs the primary tool within the community of computational visual media. To date, CNNs have made remarkable achievements across a wide range of vision tasks and applications such as person identification [
3], object detection [
4], action recognition [
5], and image classification [
6].
However, although the performance of CNNs has pushed the limits, the runtime overhead is another critical factor to take into consideration in practice. Generally, the remarkable achievements of CNNs come from the huge model sizes and the tremendous number of parameters. Typical modern CNNs involve billions of FLOPs, leading to high latency, significant resource requirements, and substantial energy consumption. This makes it impractical for CNNs to execute various real-time vision tasks on edge or mobile platforms with limited resources. With the ever-increasing number of embedded and mobile devices that require vision or graphics processing, the CNN deployment challenge has risen to the forefront.
To address this challenge, a large number of studies on model compression techniques have emerged, such as efficient model architecture design [
7], network pruning [
8], knowledge distillation [
9], and quantization [
10]. Among these approaches, quantization, which aims to leverage low-bit values to encode the original full-precision parameters and/or features of CNN models, has shown great success and is attracting increasing interest.
A host of quantization methods have been studied to achieve compression and acceleration of CNNs, which can typically be divided into two categories: uniform quantization and non-uniform quantization. Most existing methods like [
11,
12] focus on uniform quantization because they encode data using hardware-friendly fixed-point integers [
10]. However, uniformly spaced quantization levels lead to a noticeable decline in accuracy because of the non-uniform distributions of the data of CNNs. To mitigate this problem, research on non-uniform quantization has emerged. Works like [
13,
14,
15] suggest achieving quantization by encoding the target data utilizing multiple binary encodes together with the corresponding coefficients. Such an encoding scheme endows the quantized data with a stronger representation capability and makes the quantization levels fit the data distribution better. Therefore, these methods can usually achieve higher accuracy compared to uniform quantization methods. However, the integer optimization involved in these methods makes the quantization problem NP-hard. They leverage an alternating updating strategy to train the binary encodes and corresponding coefficients, incurring heavy computational loads during training. Additionally, the trained floating-point coefficients also introduce extra computational overheads in the inference procedure.
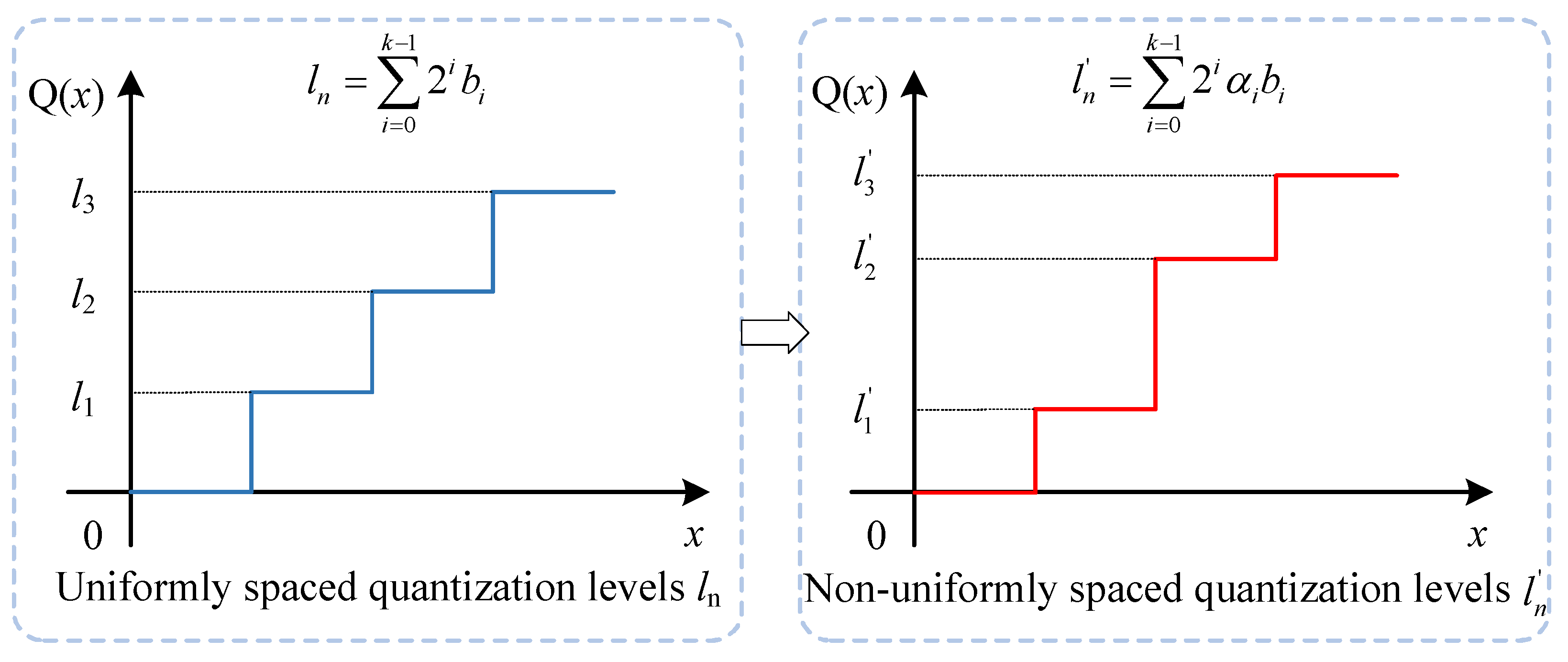
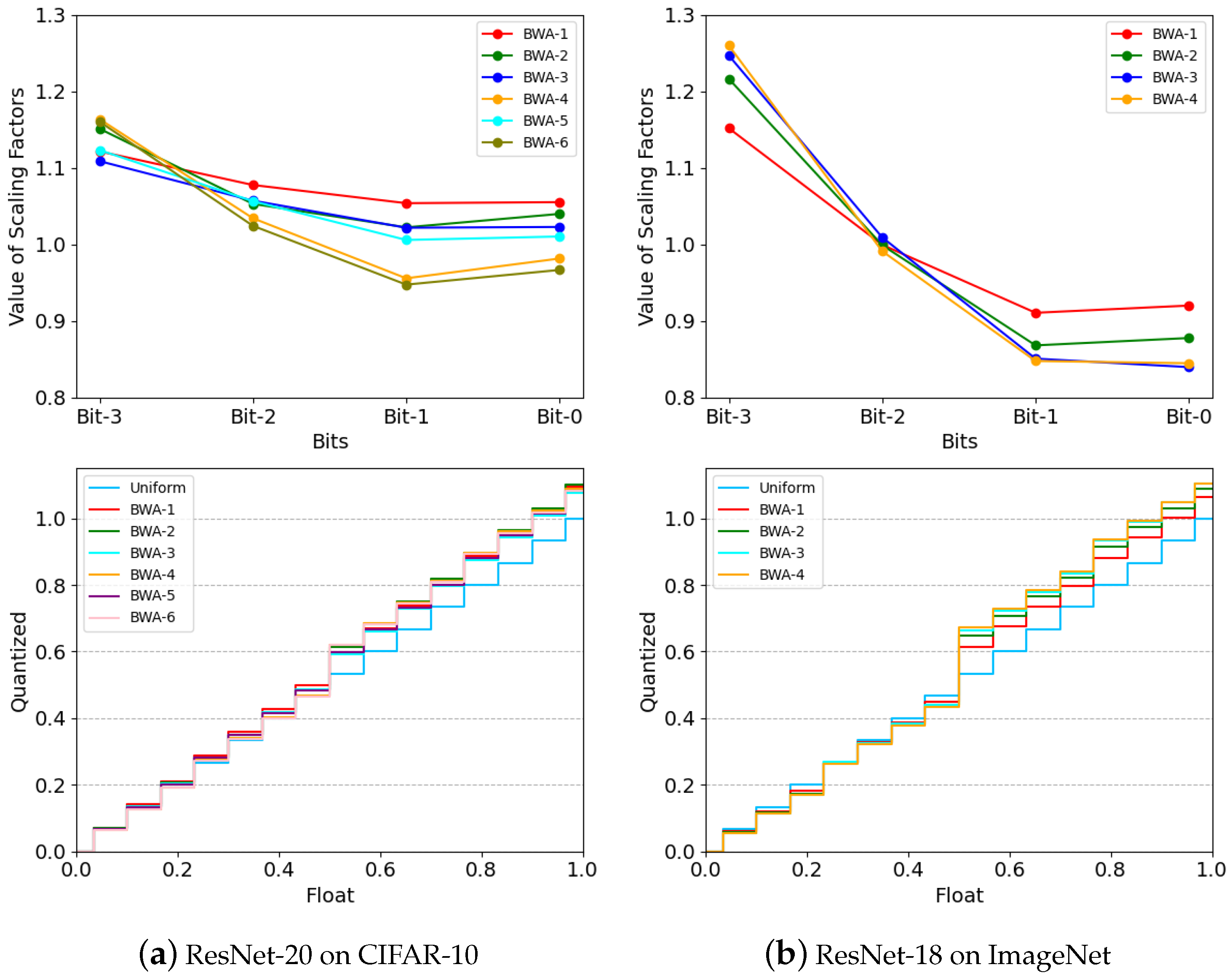
In this paper, we introduce a novel bit-weight adjustment (BWA) module to learn the best quantization schemes for each layer to boost the performance of quantized models. The BWA module builds on the idea that quantization levels can be optimized by adjusting the weight of each bit. As shown in
Figure 1, the BWA module transforms uniformly spaced quantization levels into non-uniformly spaced forms by simply introducing a trainable scaling factor
to each bit
. With the BWA module, we can easily obtain the best quantization schemes for different layers through end-to-end training. In contrast to prior research that attempted to reduce reconstruction errors [
13,
14], we derive the optimal scaling factors of each BWA module by directly minimizing the task loss, which assists in retaining model accuracy after quantization [
15,
16]. Additionally, in order to benefit from both the hardware friendliness of uniform quantization and the high performance of non-uniform quantization, we propose to combine uniform quantization and non-uniform quantization in a single network. Specifically, we only apply the BWA module to the last few quantization layers of a neural network. The remaining layers are quantized using simple uniform quantization.
The contributions of this paper can be summarized as follows:
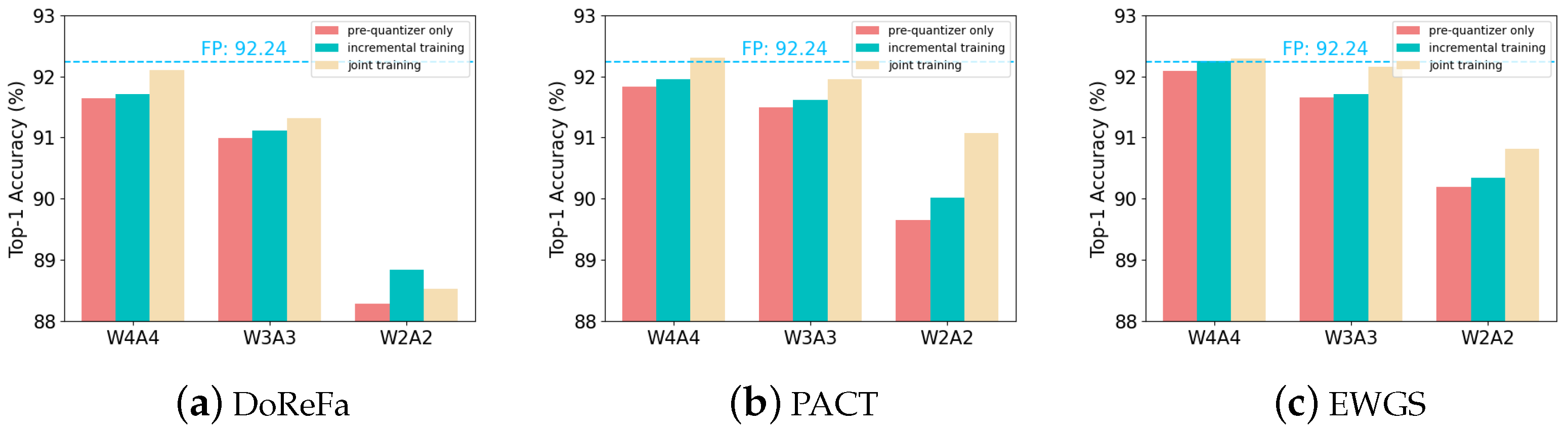
We introduce the BWA module to learn the best quantization schemes for each layer, which can be easily optimized through end-to-end training using two different training strategies: incremental training and joint training.
We combine uniform and non-uniform quantization to benefit from both the hardware friendliness of uniform quantization and the high performance of non-uniform quantization.
Numerous experiments are performed to verify the performance of our proposed quantization technique. Specifically, our approach sets a new state of the art on the standard benchmark datasets ImageNet [
17] and CIFAR-10 [
18].
2. Related Works
Research on quantization is an emerging topic and shows great potential for the deployment of CNNs on resource-limited devices. A large number of quantization techniques to achieve model compression have emerged. These methods adopt either uniform quantization schemes or non-uniform quantization schemes. In this section, we review some representative works that have recently been published on the topic of both uniform and non-uniform quantization.
Uniform quantization, which linearly maps floating-point data to some integers, is the most commonly used quantization scheme. Zhou et al. [
10] designed DoReFa-Net to achieve arbitrary bit widths in weights, activations, and gradients. In their work, the weights and activations of models are quantized with deterministic quantization, whereas the low-bit-width gradients are obtained through stochastic quantization. Choi et al. [
11] concentrated on the quantization of activations and parameterized the activation clipping upper bound to reduce the quantization error through training. They obtained 4-bit quantized models that are comparable to full-precision models in terms of accuracy. Gong et al. [
12] proposed to approximate standard uniform quantization with a series of hyperbolic tangent functions. This made the quantization process differentiable, and it could thus mitigate the mismatch of gradients. Dong et al. [
19] allocated different bit widths to different layers to boost model performance. Specifically, they leveraged the average Hessian trace to measure the quantization sensitivity to determine the bit width of each layer. Lee et al. [
20] attempted to address the quantization problem from the aspect of backpropagation and tried to eliminate the mismatch of gradients using the Taylor approximation.
For non-uniform quantization methods, the intervals between adjacent quantization levels can be different. In [
21,
22,
23,
24,
25], model weights and activations were coded using logarithmic quantizers. The base-2 logarithmic representation was used due to its compatibility with the bit-shift operation. However, these approaches focused too much on near-zero regions and ignored other regions, thus suffering from a decline in accuracy. Another branch of non-uniform quantization is multi-bit quantization, where the target data are quantized using multiple binary codes. For example, Zhang et al. [
13] proposed training quantization levels together with model parameters to minimize quantization errors. Lin et al. [
14] proposed obtaining the quantization scheme by minimizing the least-square error. Qu et al. [
15] leveraged an iterative optimization strategy to learn the quantization strategy. Xu et al. [
26] used an alternating minimization strategy to tackle the quantization problem in LSTM. Li et al. [
27] proposed performing recursive residual quantization to obtain a series of binary codes. Owing to their stronger representation capability, these methods usually exhibited better performance compared to uniform quantization methods. However, the floating-point coordinates used in these methods introduced extra computational overhead compared to uniform quantization.
Unlike the methods mentioned above, our work combines uniform and non-uniform quantization to pursue higher accuracy while reducing computational complexity.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}