



Object Recognition System for the Visually Impaired: A Deep Learning Approach using Arabic Annotation

Abstract
1. Introduction
2. Related Work
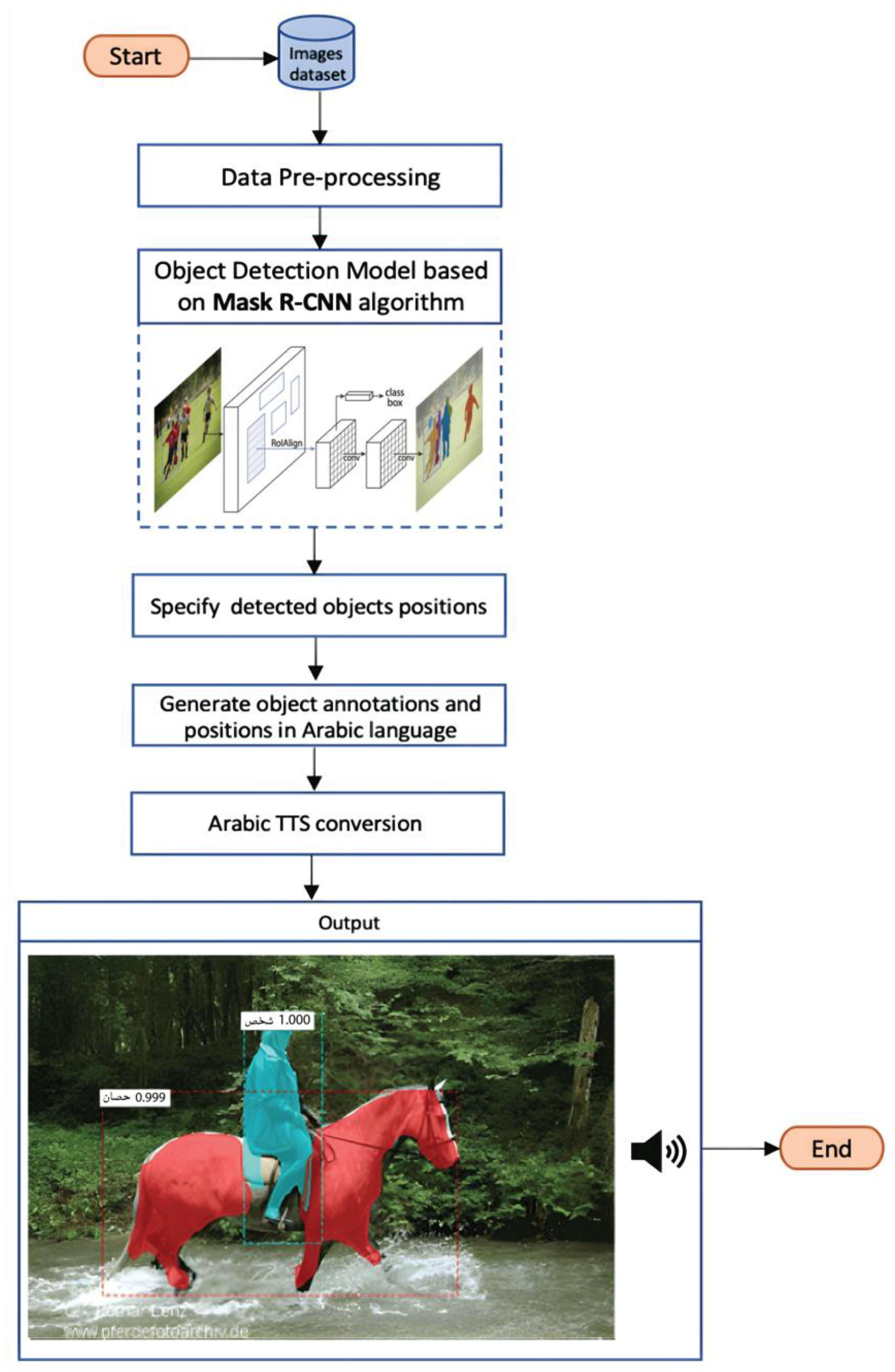
3. Proposed Method
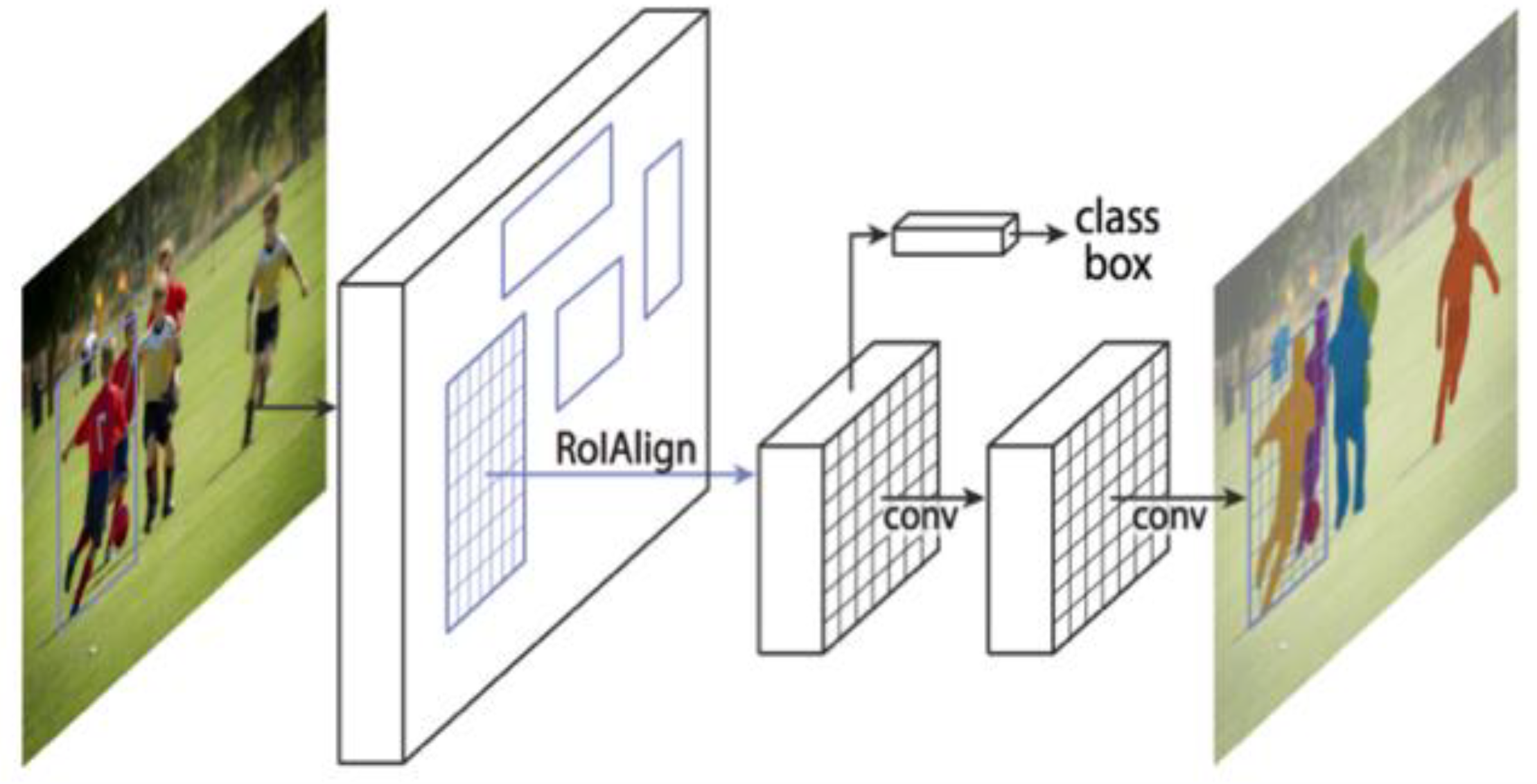
3.1. Mask R-CNN Algorithm
- The backbone: This is a standard CNN, which is responsible for feature extraction. The initial layers of the network detect low-level features such as edges and corners, while subsequent layers detect high-level features such as car or person. The backbone network converts the input image into a feature map and passes it to the next module.
- Region proposal network (RPN): This is a lightweight neural network that uses a sliding window mechanism to scan the feature map and extracts regions that contain objects, known as regions of interest (ROIs). ROIs are fed to the RoIAlign method to generate fixed-sized ROIs and precisely locate the regions. The RPN produces two outputs for each ROI: the class (i.e., if the region is background or foreground) and the bounding box refinement.
- ROI classifier and bounding box regressor: ROIs are passed through two different processes, the ROI classifier and the bounding box regressor. The ROI classifier is responsible for classifying the object in the ROI to a specific class, such as person or chair, while the bounding box regressor is responsible for predicting the bounding box for the ROI.
- Segmentation masks: The mask branch is a fully convolutional network (FCN), which is mainly responsible for assigning object masks to each detected object, i.e., the positive regions selected by the ROI classifier.
- Mask R-CNN has several advantages, especially in terms of training simplicity. First, it enhances Faster R-CNN by increasing its speed while adding only minor overhead. Furthermore, the mask branch allows for faster systems and more rapid testing with only minor computational overhead. Moreover, Mask R-CNN can be easily adapted to various tasks. Human pose estimation, for instance, can be easily accomplished with Mask R-CNN using the same framework. Such techniques are key to assisting people with visual impairment in understanding image content. Mask R-CNN has also been widely used in different domains to produce segmented masks; possible uses in the computer vision field are video surveillance, autonomous car systems, and tumor detection. On the other hand, a prevalent issue in Mask R-CNN is that it ignores part of the background and marks it as foreground, resulting in target segmentation inaccuracy.
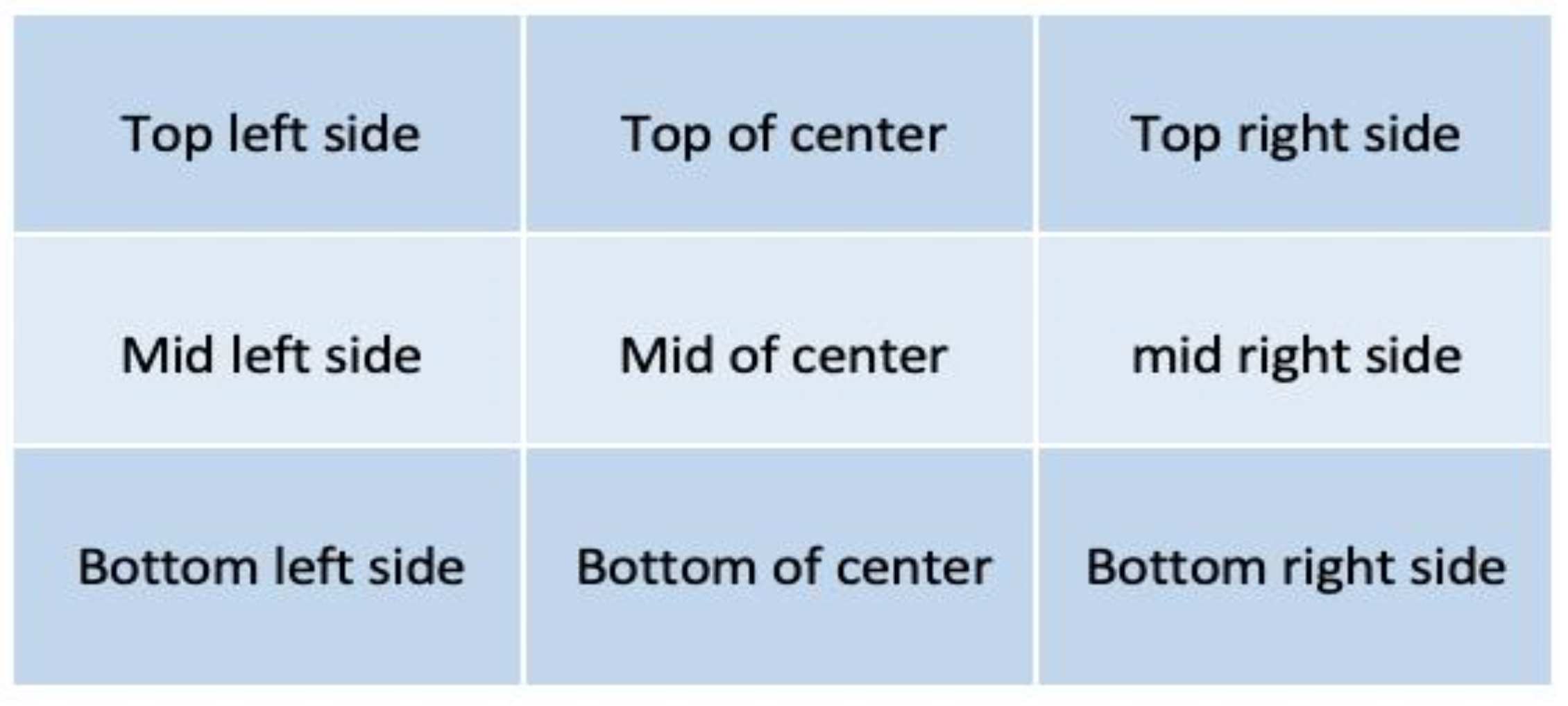
3.2. Specifying Positions of the Detected Objects
3.3. Generating the Annotations and Positions in the Arabic Language
3.4. Text-to-Speech Conversion
4. Materials and Methods
4.1. Experimental Environment
4.2. Dataset Acquisition
4.3. Transfer Learning
4.4. Parameter Settings
4.5. Evaluation Index
- Average precision (AP):
- Mean average precision (mAP):
5. Experimental Results and Analysis
5.1. The Object Detection and Segmentation Model Experiments
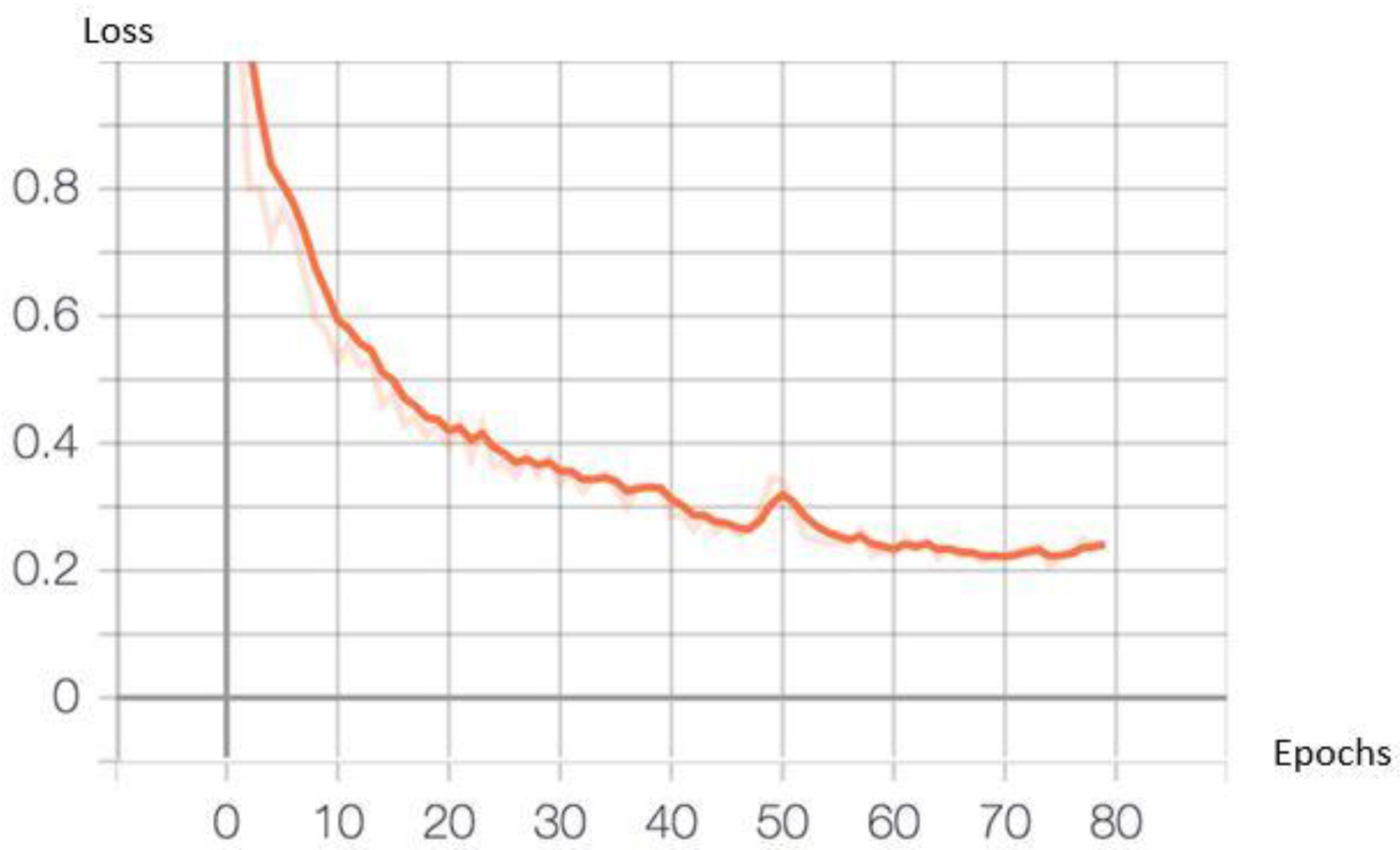
5.1.1. Training and Evaluating the Model
- rpn_class_loss: the extent to which the region proposal network (RPN) succeeds in separating the background with objects.
- rpn_bbox_loss: the degree to which the RPN succeeds in localizing objects.
- mrcnn_bbox_loss: the degree to which the Mask RPN succeeds in localizing objects.
- mrcnn_class_loss: the extent to which Mask R-CNN succeeds in identifying the class for each object.
- mrcnn_mask_loss: the extent to which Mask R-CNN succeeds in attempting to segment objects.
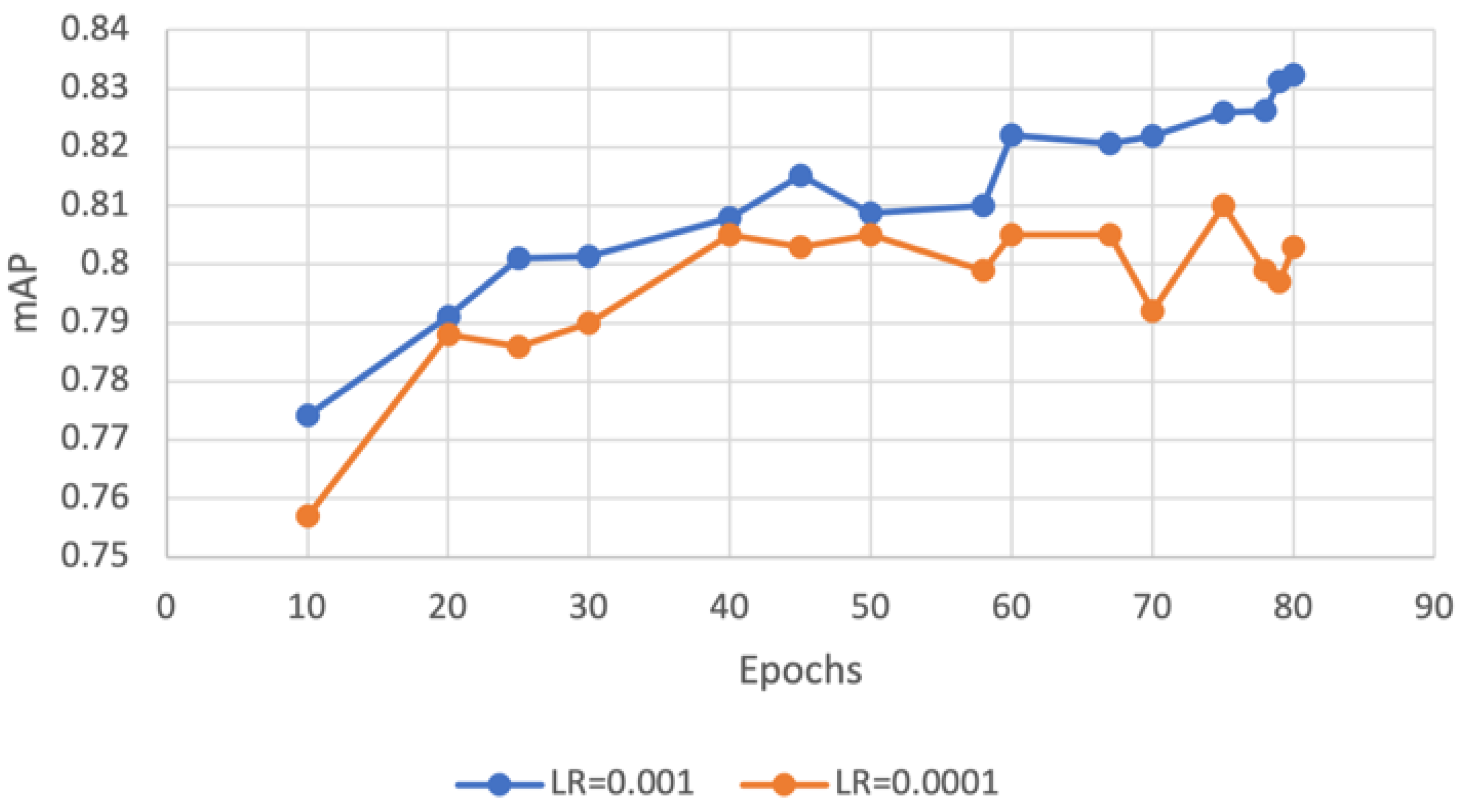
- As is evident in Figure 6, the general training loss decreased dramatically for the first 50 epochs, after which it changed very slowly. Each epoch took 14 min approximately; thus, the overall training process took 17 h, 30 min, and 28 s to complete 80 epochs, resulting in a final training loss of 0.2402.
5.1.2. Testing the Model
5.1.3. Ablation Experiments
5.1.4. Comparison with Previous State-of-the-Art Object Detection Models
5.2. The Arabic Annotations, Objects Positions, and TTS Experiments
- (1)
- The accuracy of the predicted object’s position within an image, where the judge was asked to use the map illustrated in Figure 3 as a reference and indicate if the detected object’s position was in the expected position within the map.
- (2)
- The accuracy of the translated label of the predicted object, where the judge was responsible for indicating whether the translated Arabic label was “accurate” or “inaccurate”.
- (3)
- The accuracy of the translated position of the predicted object, where the judge was also responsible for indicating if the translated Arabic position was “accurate” or “inaccurate”.
- (4)
- The Arabic speech of the predicted object label with its position, where the judge was responsible for deciding whether the spoken object’s name and its position were “clear” or “unclear”.
5.3. Discussion of Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Pathak, A.R.; Pandey, M.; Rautaray, S. Application of Deep Learning for Object Detection. Procedia Comput. Sci. 2018, 132, 1706–1717. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Wang, J.; Hu, X. Convolutional Neural Networks with Gated Recurrent Connections. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3421–3436. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision-ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You Only Learn One Representation: Unified Network for Multiple Tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Bourne, R.R.A.; Flaxman, S.R.; Braithwaite, T. Magnitude, Temporal Trends, and Projections of the Global Prevalence of Blindness and Distance and near Vision Impairment: A Systematic Review and Meta-Analysis. Lancet Glob. Health 2017, 5, e888–e897. [Google Scholar] [CrossRef]
- Zeried, F.M.; Alshalan, F.A.; Simmons, D.; Osuagwu, U.L. Visual Impairment among Adults in Saudi Arabia. Clin. Exp. Optom. 2020, 103, 858–864. [Google Scholar] [CrossRef] [PubMed]
- Al-muzaini, H.A.; Al-yahya, T.N.; Benhidour, H. Automatic Arabic Image Captioning Using RNN-LSTM-Based Language Model and CNN. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 67–73. [Google Scholar] [CrossRef]
- Jindal, V. Generating Image Captions in Arabic Using Root-Word Based Recurrent Neural Networks and Deep Neural Networks. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Workshop, New Orleans, LA, USA, 2–4 June 2018; pp. 144–151. [Google Scholar] [CrossRef]
- Zhou, G.; Zhang, W.; Chen, A.; He, M.; Ma, X. Rapid Detection of Rice Disease Based on FCM-KM and Faster R-CNN Fusion. IEEE Access 2019, 7, 143190–143206. [Google Scholar] [CrossRef]
- Kavitha Lakshmi, R.; Savarimuthu, N. DPD-DS for Plant Disease Detection Based on Instance Segmentation. J. Ambient. Intell. Humaniz. Comput. 2021. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, D.; Jia, W.; Ji, W.; Ruan, C.; Sun, Y. Cucumber Fruits Detection in Greenhouses Based on Instance Segmentation. IEEE Access 2019, 7, 139635–139642. [Google Scholar] [CrossRef]
- Zhang, Q.; Chang, X.; Bian, S.B. Vehicle-Damage-Detection Segmentation Algorithm Based on Improved Mask RCNN. IEEE Access 2020, 8, 6997–7004. [Google Scholar] [CrossRef]
- de Vries, E.; Schoonvelde, M.; Schumacher, G. No Longer Lost in Translation: Evidence That Google Translate Works for Comparative Bag-of-Words Text Applications. Polit. Anal. 2018, 26, 417–430. [Google Scholar] [CrossRef]
- Cambre, J.; Colnago, J.; Maddock, J.; Tsai, J.; Kaye, J. Choice of Voices: A Large-Scale Evaluation of Text-to-Speech Voice Quality for Long-Form Content. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–13. [Google Scholar]
- Mawdoo3 AI. Available online: https://ai.mawdoo3.com/ (accessed on 10 October 2022).
- Google Colaboratory. Available online: https://colab.research.google.com/notebooks/intro.ipynb (accessed on 15 September 2022).
- Project Jupyter. Available online: https://www.jupyter.org (accessed on 18 October 2022).
- The PASCAL Visual Object Classes Homepage. Available online: http://host.robots.ox.ac.uk/pascal/VOC/index.html (accessed on 15 July 2022).
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. In GitHub Repository; Github: San Francisco, CA, USA, 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Kelleher, J.D.; Namee, B.M.; D’Arcy, A. Fundamentals of Machine Learning for Predictive Data Analytics, Second Edition: Algorithms, Worked Examples, and Case Studies; MIT Press: Cambridge, MA, USA, 2020. [Google Scholar]
- TensorBoard. TensorFlow. Available online: https://www.tensorflow.org/tensorboard (accessed on 25 July 2022).
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Termritthikun, C.; Jamtsho, Y.; Ieamsaard, J.; Muneesawang, P.; Lee, I. EEEA-Net: An Early Exit Evolutionary Neural Architecture Search. Eng. Appl. Artif. Intell. 2021, 104, 104397. [Google Scholar] [CrossRef]
- Cao, J.; Pang, Y.; Han, J.; Li, X. Hierarchical Shot Detector. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9704–9713. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Localize to Classify and Classify to Localize: Mutual Guidance in Object Detection. arXiv 2020, arXiv:2009.14085. [Google Scholar]
- Alsudais, A. Image Classification in Arabic: Exploring Direct English to Arabic Translations. IEEE Access 2019, 7, 122730–122739. [Google Scholar] [CrossRef]
- Spina, C. WCAG 2.1 and the Current State of Web Accessibility in Libraries. Weav. J. Libr. User Exp. 2019, 2. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| LEARNING_RATE | 0.001 |
| LEARNING_MOMENTUM | 0.9 |
| DETECTION_MIN_CONFIDENCE | 0.7 |
| NUM_CLASSES | 21 |
| VALIDATION_STEPS | 50 |
| STEPS_PER_EPOCH | 1405 |
| Method | Backbone | mAP | Aero | Bicycle | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | TV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mask R-CNN | Resnet-50 | 68.9% | 0.69 | 0.79 | 0.82 | 0.67 | 0.59 | 0.65 | 0.75 | 0.89 | 0.65 | 0.76 | 0.65 | 0.73 | 0.78 | 0.59 | 0.57 | 0.66 | 0.65 | 0.65 | 0.62 | 0.62 |
| CN-Mask | Resnet101 | 82.2% | 0.94 | 0.34 | 0.96 | 0.92 | 0.88 | 0.8 | 0.97 | 0.98 | 0.9 | 0.87 | 0.9 | 0.93 | 0.94 | 0.4 | 0.62 | 0.45 | 0.88 | 0.92 | 0.97 | 0.87 |
| CC-Mask | Resnet101 | 80.7% | 0.92 | 0.11 | 0.87 | 0.85 | 0.8 | 0.98 | 0.97 | 0.97 | 0.6 | 0.77 | 0.98 | 0.83 | 0.88 | 0.99 | 0.98 | 0.34 | 0.76 | 0.82 | 0.94 | 0.73 |
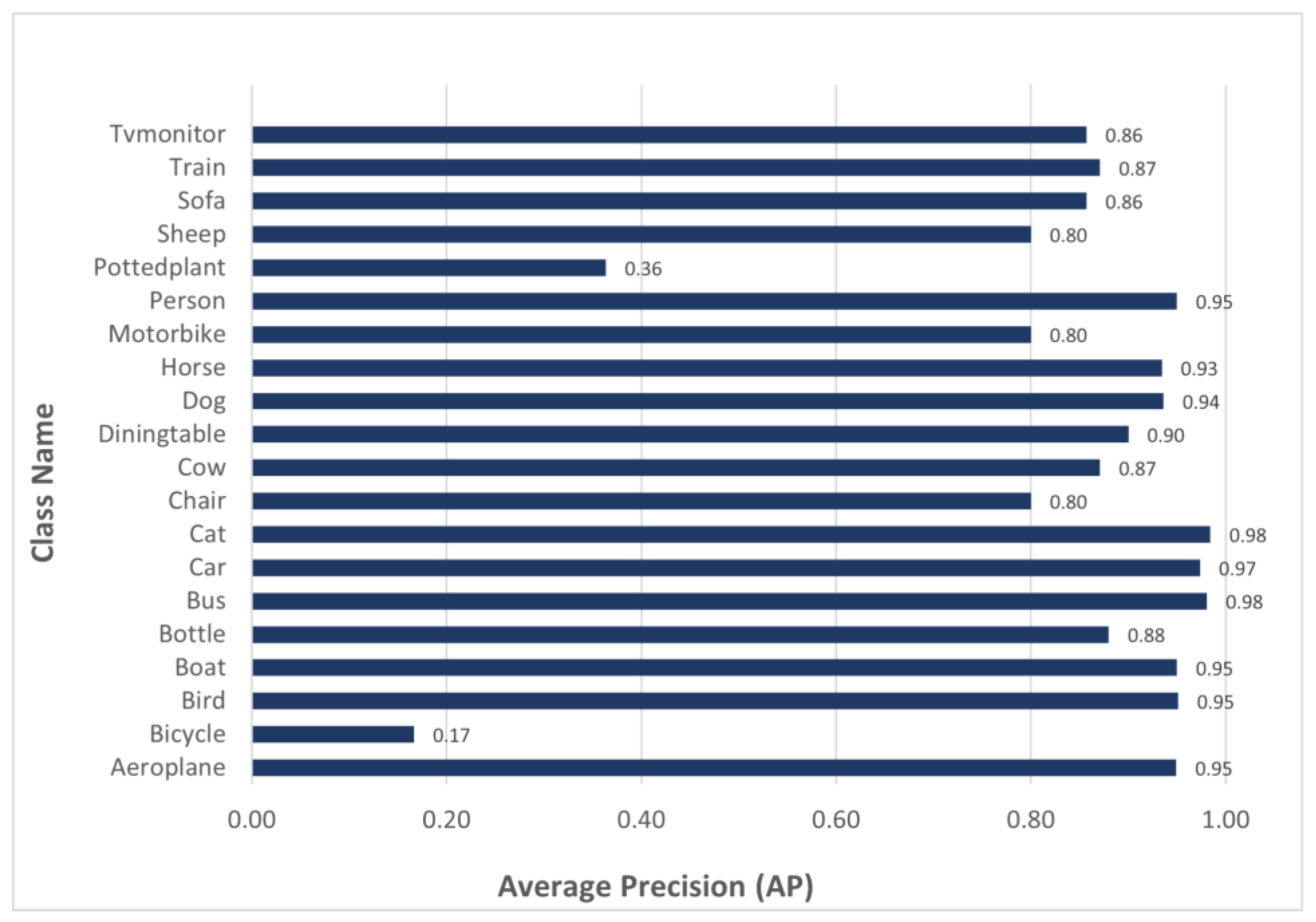
| Proposed Model | Resnet101 | 83.9% | 0.94 | 0.16 | 0.95 | 0.95 | 0.88 | 0.98 | 0.97 | 0.98 | 0.8 | 0.87 | 0.9 | 0.93 | 0.93 | 0.8 | 0.95 | 0.36 | 0.8 | 0.85 | 0.87 | 0.85 |
| Detection Models | Trained on | mAP |
|---|---|---|
| Faster R-CNN [5] | 07 + 12 + COCO | 78.8% |
| SSD 300 [9] | 07 + 12 + COCO | 79.6% |
| SSD 512 [9] | 07 + 12 + COCO | 81.6% |
| YOLOv2 [31] | 07 + 12 | 78.6% |
| EEEA-Net-C2 [32] | 07 + 12 | 81.8% |
| HSD [33] | 07 + 12 | 81.7% |
| Localize [34] | 07 + 12 | 81.5% |
| The proposed model | 07 + 12 | 83.9% |
| Sample | Original Image | Image with the Detected Objects with Arabic Annotations | Names and Positions of Detected Objects |
|---|---|---|---|
| A |  |  | شخص في الجزء العلوي من الجانب الأيمن ، شخص في منتصف الجانب الأيسر ، كرسي في منتصف الجانب الأيسر ، طاولة الطعام في الجزء السفلي من المركز |
| B |  |  | شخص في منتصف المركز ، الكلب في الجزء السفلي من الجانب الأيسر ، دراجة في الجزء السفلي من مركز |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzahrani, N.; Al-Baity, H.H. Object Recognition System for the Visually Impaired: A Deep Learning Approach using Arabic Annotation. Electronics 2023, 12, 541. https://doi.org/10.3390/electronics12030541
Alzahrani N, Al-Baity HH. Object Recognition System for the Visually Impaired: A Deep Learning Approach using Arabic Annotation. Electronics. 2023; 12(3):541. https://doi.org/10.3390/electronics12030541
Chicago/Turabian StyleAlzahrani, Nada, and Heyam H. Al-Baity. 2023. "Object Recognition System for the Visually Impaired: A Deep Learning Approach using Arabic Annotation" Electronics 12, no. 3: 541. https://doi.org/10.3390/electronics12030541
APA StyleAlzahrani, N., & Al-Baity, H. H. (2023). Object Recognition System for the Visually Impaired: A Deep Learning Approach using Arabic Annotation. Electronics, 12(3), 541. https://doi.org/10.3390/electronics12030541