
3D Point Cloud Stitching for Object Detection with Wide FoV Using Roadside LiDAR

Abstract
:1. Introduction
- The detection range of base model is further extended. Roadside Lidar’s FoV could not be restrained by camera and can search targets in the whole 3D space;
- The omnidirectional detection results can be processed in parallel and generated by a 90° training model. There is no increased cost in the model training time and each result group is integrated into the same coordinate system;
- Overlapping object estimation and removal method are developed for point cloud switching, which can avoid false detections of the same object and offer accurate results.
2. Related Work
2.1. 2D Stitching Methods
2.2. 3D Stitching Methods
2.3. 3D Object Detection Methods
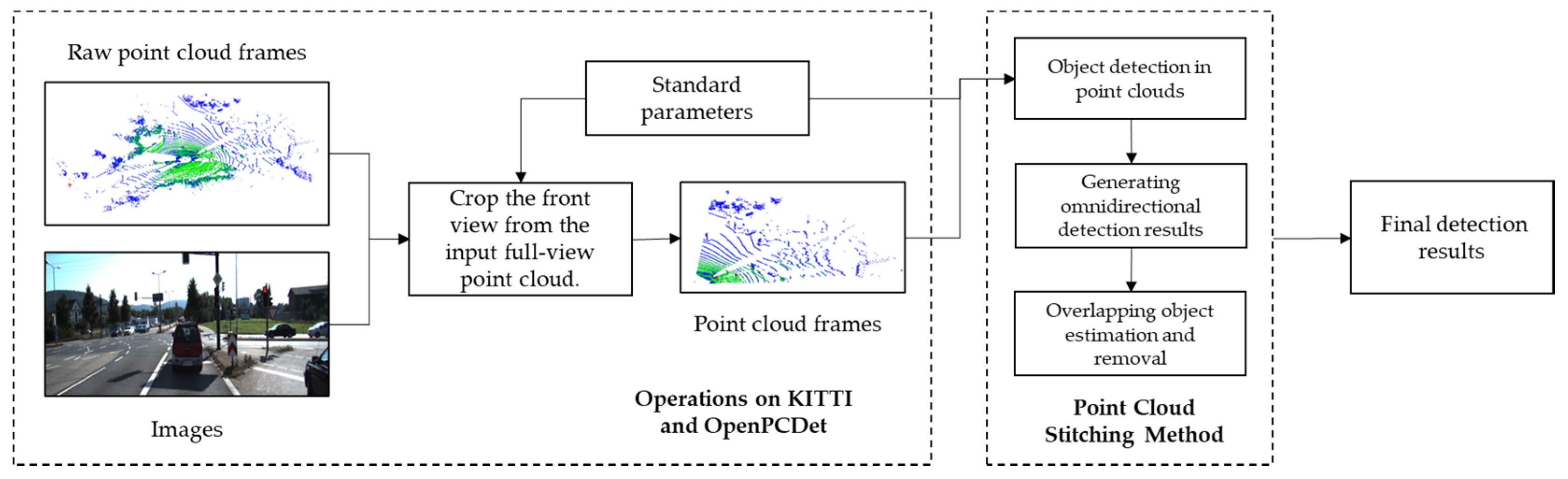
3. Methods
3.1. 3D Object Detection in Point Clouds
3.2. Generating Omnidirectional Detection Results
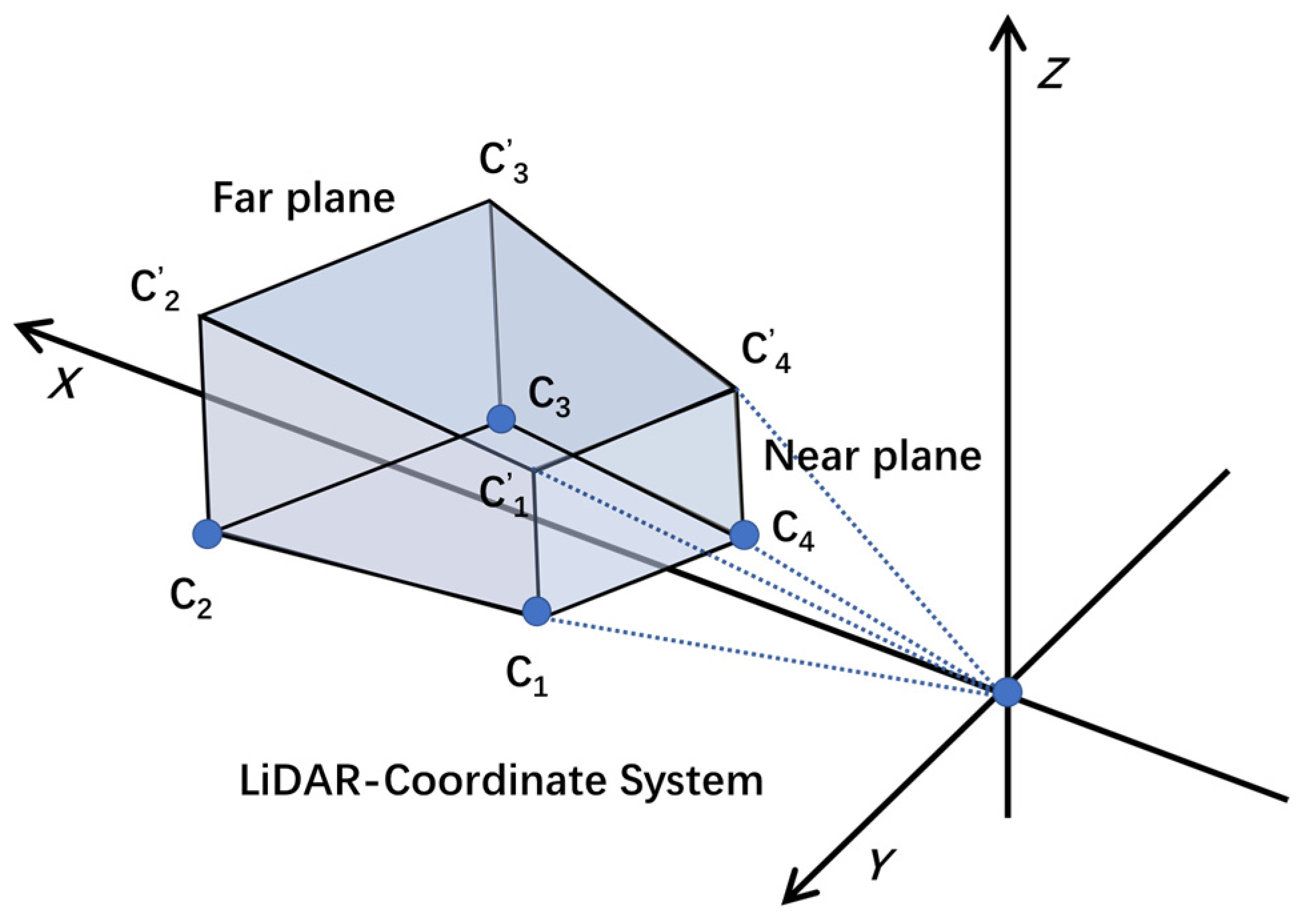
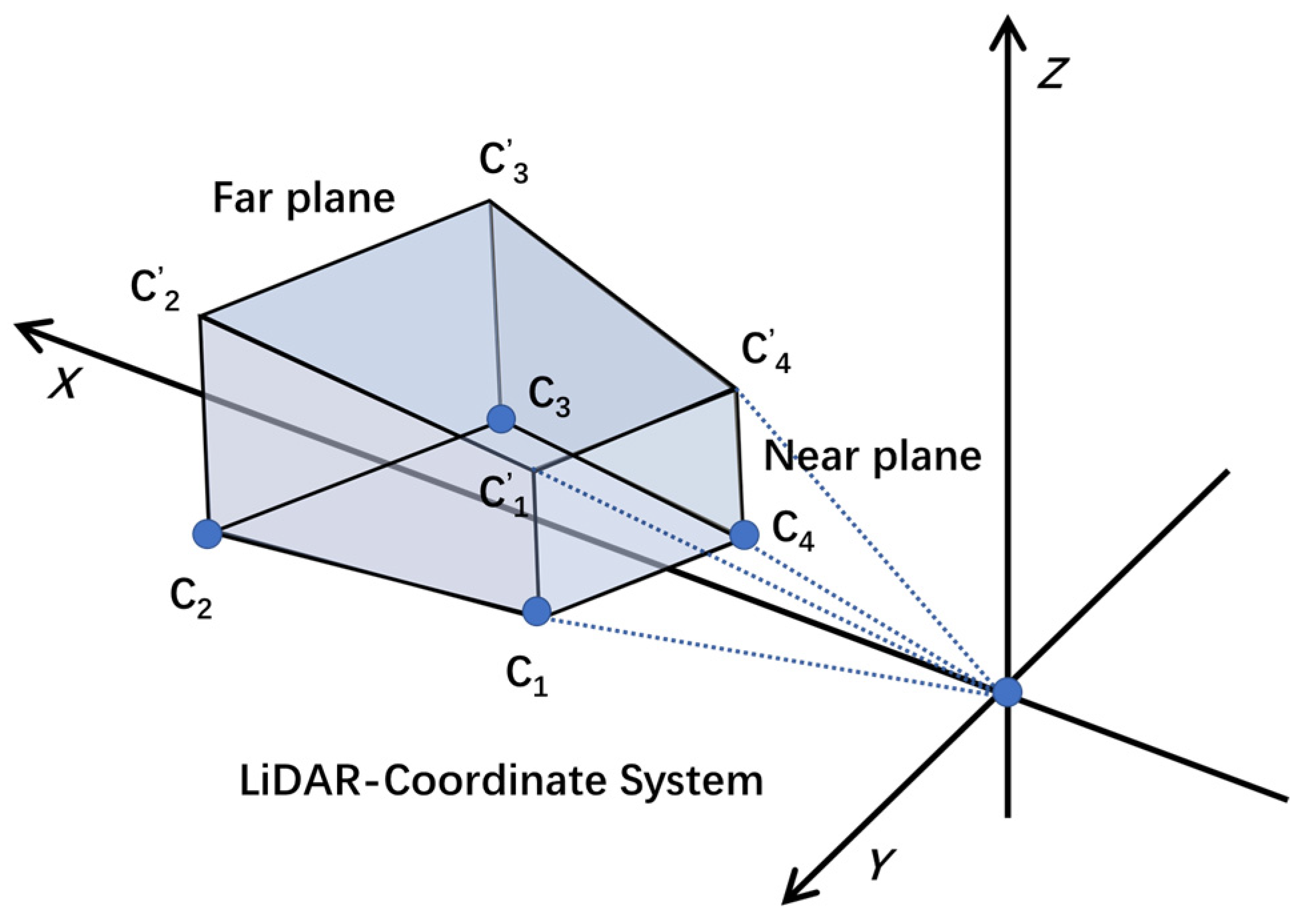
- Projecting the quadrangular prism to the plane coordinate system O-XY. The purpose of this is to simplify the origin model;
- Projecting the corners in far plane to Y-axis and the corresponding points are expressed as V1 and V2, as shown in Figure 3;
- According to location of 90° FoV, delimiting the rectangular FoV R-V1C2C3V2 to get the object attributes within the perspective range;
- Re-adjustment of the FoV is undertaken to optimize the detection range based on the voxel size. Extracting the Xmin, Ymin, Xmax and Ymax from R-V1C2C3V2 and setting the difference divided by the voxel size is a multiple of 16.
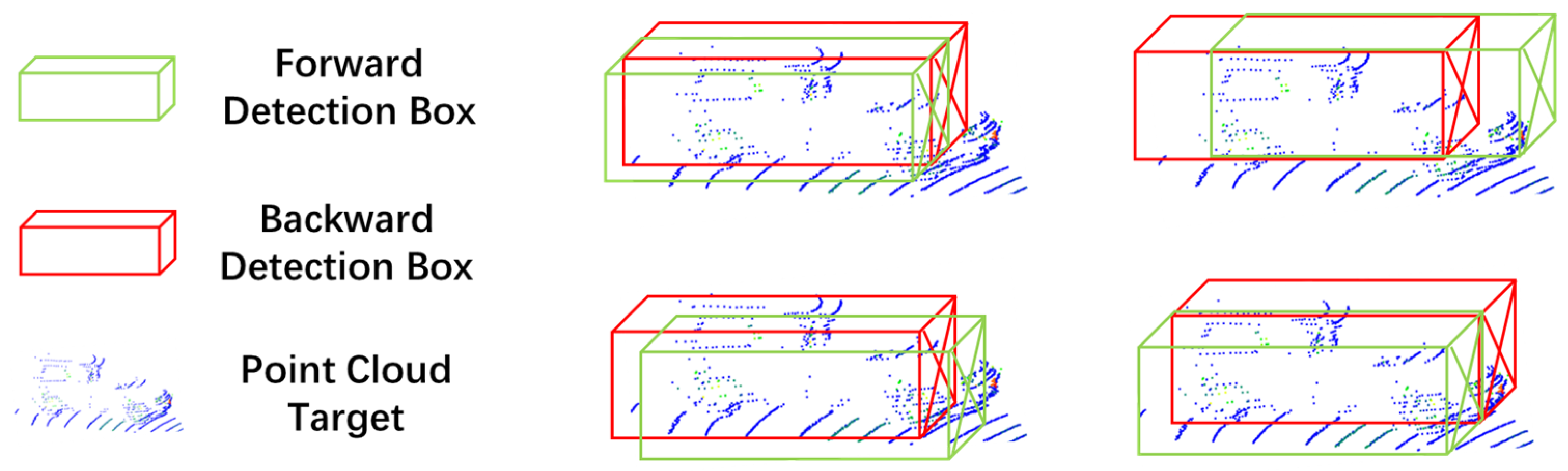
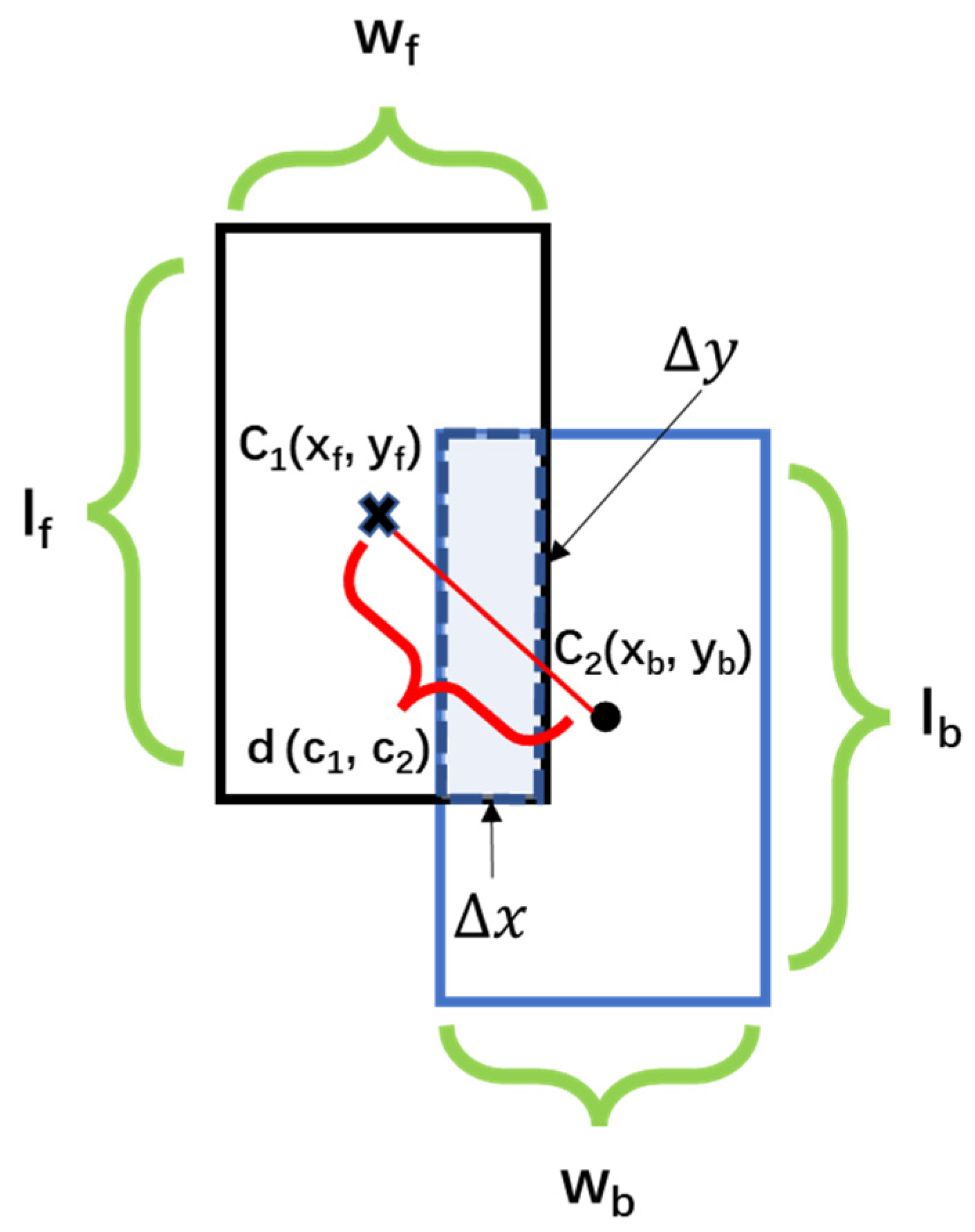
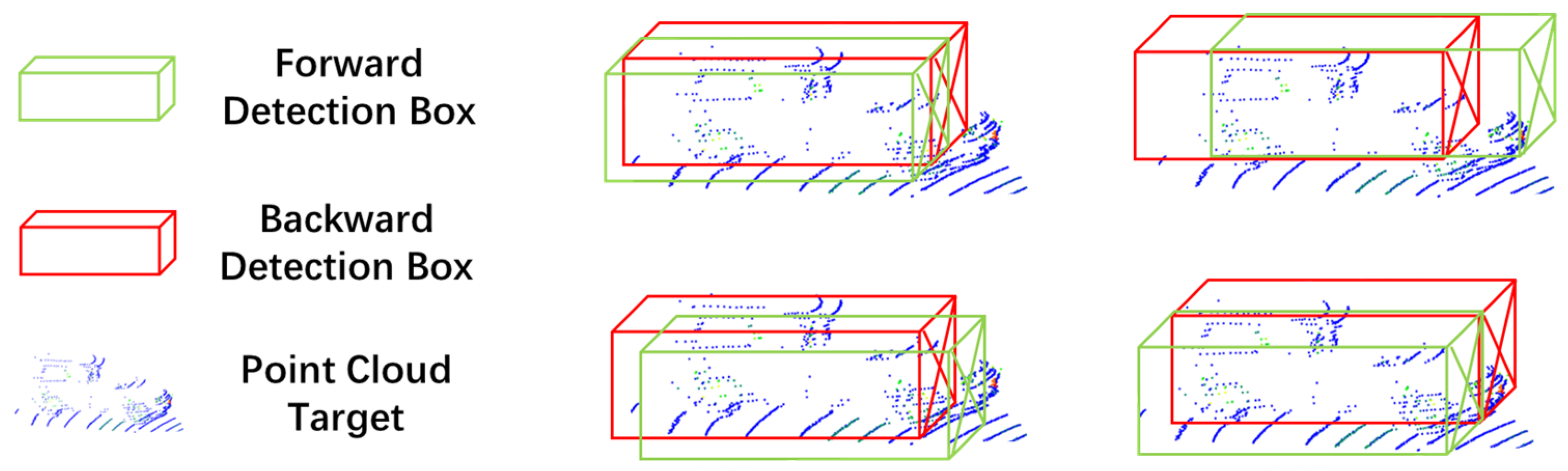
3.3. Overlapping Object Estimation and Removal
| Algorithm 1 Duplicate target estimation and removal |
| input: Detection result sets S1 (the front frames set) and S2 (the back frames set). |
| output: A non-repeated data set S3 with 360°. |
| 1 for the cycle in length(S1) do: 2 for the single frame detection result s in S1 and S2 do: Build empty lists S1_frame and S2_frame to save each frame data. 3 if s[frame] = cycle do: set the uniform data format for s; add s to S1_frame or S2_frame. 4 end for |
| 5 Build an empty list del_list to store the indexes of duplicate targets. |
| 6 for each target s1 in S1 do: 7 for each target s2 in S2 do: Calculating CDIoU(s1,s2) 8 if CDIoU(s1,s2) ≤ 1 do: s1 and s2 overlap. Select the index of Min[score(s1), score(s2)] to save in the del_list. 9 else do: No overlap between s1 and s2. 10 end for 11 Remove multiple elements in the del_list. 12 end for |
| 13 Delete elements in the del_list from S1 and S2. |
| 14 S3 = S1 + S2 15 end for 16 return S3. |
4. Experiments
4.1. KITTI Dataset
4.2. Model Evaluation
4.3. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Wu, J.; Xu, H.; Zheng, Y.; Zhang, Y.; Lv, B.; Tian, Z. Automatic vehicle classification using roadside LiDAR data. Transp. Res. Rec. 2019, 2673, 153–164. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef]
- Tang, H.; Liu, Z.; Li, X.; Lin, Y.; Han, S. Torchsparse: Efficient point cloud inference engine. Proc. Mach. Learn. Syst. 2022, 4, 302–315. [Google Scholar]
- Zimmer, W.; Ercelik, E.; Zhou, X.; Ortiz, X.J.D.; Knoll, A. A survey of robust 3d object detection methods in point clouds. arXiv 2022, arXiv:2204.00106. [Google Scholar]
- Wu, J.; Tian, Y.; Xu, H.; Yue, R.; Wang, A.; Song, X. Automatic ground points filtering of roadside LiDAR data using a channel-based filtering algorithm. Opt. Laser Technol. 2019, 115, 374–383. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [Green Version]
- Qian, R.; Lai, X.; Li, X. 3d object detection for autonomous driving: A survey. arXiv 2021. [Google Scholar] [CrossRef]
- Mao, J.; Shi, S.; Wang, X.; Li, H. 3d object detection for autonomous driving: A review and new outlooks. arXiv 2022, arXiv:2206.09474. [Google Scholar]
- Li, J.; Hu, Y. Dpointnet: A density-oriented pointnet for 3d object detection in point clouds. arXiv 2021, arXiv:2102.03747. [Google Scholar]
- Zhao, J.; Xu, H.; Liu, H.; Wu, J.; Zheng, Y.; Wu, D. Detection and tracking of pedestrians and vehicles using roadside LiDAR sensors. Transp. Res. Part C Emerg. Technol. 2019, 100, 68–87. [Google Scholar] [CrossRef]
- Wu, J. An automatic procedure for vehicle tracking with a roadside LiDAR sensor. Inst. Transp. Eng. ITE J. 2018, 88, 32–37. [Google Scholar]
- Wu, J.; Xu, H.; Tian, Y.; Pi, R.; Yue, R. Vehicle detection under adverse weather from roadside LiDAR data. Sensors 2020, 20, 3433. [Google Scholar] [CrossRef]
- Wu, J.; Xu, H.; Zhao, J. Automatic lane identification using the roadside LiDAR sensors. IEEE Intell. Transp. Syst. Mag. 2020, 12, 25–34. [Google Scholar] [CrossRef]
- Wu, J.; Xu, H.; Lv, B.; Yue, R.; Li, Y. Automatic ground points identification method for roadside LiDAR data. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 140–152. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. NuScenes: A multimodal dataset for autonomous driving. arXiv 2020, arXiv:1903.11027. [Google Scholar]
- Liao, Y.; Xie, J.; Geiger, A. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d. IEEE Trans. Pattern Anal. Mach. Intell. 2022. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, ELECTR NETWORK, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Xiang, T.-Z.; Xia, G.-S.; Bai, X.; Zhang, L. Image stitching by line-guided local warping with global similarity constraint. Pattern Recognit. 2018, 83, 481–497. [Google Scholar] [CrossRef] [Green Version]
- Zaragoza, J.; Tat-Jun, C.; Tran, Q.H.; Brown, M.S.; Suter, D. As-projective-as-possible image stitching with moving DLT. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1285–1298. [Google Scholar]
- Li, N.; Liao, T.; Wang, C. Perception-based seam cutting for image stitching. Signal Image Video Process. 2018, 12, 967–974. [Google Scholar] [CrossRef]
- Chen, X.; Yu, M.; Song, Y. Optimized seam-driven image stitching method based on scene depth information. Electronics 2022, 11, 1876. [Google Scholar] [CrossRef]
- Shi, Z.; Wang, P.; Cao, Q.; Ding, C.; Luo, T. Misalignment-eliminated warping image stitching method with grid-based motion statistics matching. Multimed. Tools Appl. 2022, 81, 10723–10742. [Google Scholar] [CrossRef]
- Zakaria, M.A.; Kunjunni, B.; Peeie, M.H.B.; Papaioannou, G. Autonomous shuttle development at university Malaysia Pahang: LiDAR point cloud data stitching and mapping using iterative closest point cloud algorithm. In Towards Connected and Autonomous Vehicle Highways; Umar, Z.A.H., Fadi, A., Eds.; Springer: Cham, Switzerland, 2021; pp. 281–292. [Google Scholar]
- Ibisch, A.; Stümper, S.; Altinger, H.; Neuhausen, M.; Tschentscher, M.; Schlipsing, M.; Salinen, J.; Knoll, A. Towards autonomous driving in a parking garage: Vehicle localization and tracking using environment-embedded LiDAR sensors. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Gold Coast, Australia, 23–26 June 2013; pp. 829–834. [Google Scholar]
- Sun, H.; Han, J.; Wang, C.; Jiao, Y. Aircraft model reconstruction with image point cloud data. In Proceedings of the 2018 IEEE 3rd International Conference on Cloud Computing and Big Data Analysis (ICCCBDA), Chengdu, China, 20–22 April 2018; pp. 322–325. [Google Scholar]
- Wu, J.; Song, X. Review on development of simultaneous localization and mapping technology. J. Shandong Univ. (Eng. Sci.) 2021, 51, 16–31. [Google Scholar]
- Yao, S.; AliAkbarpour, H.; Seetharaman, G.; Palaniappan, K. City-scale point cloud stitching using 2d/3d registration for large geographical coverage. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; pp. 32–45. [Google Scholar]
- Lv, B.; Xu, H.; Wu, J.; Tian, Y.; Tian, S.; Feng, S. Revolution and rotation-based method for roadside LiDAR data integration. Opt. Laser Technol. 2019, 119, 105571. [Google Scholar] [CrossRef]
- Wu, J.; Xu, H.; Zheng, Y.; Tian, Z. A novel method of vehicle-pedestrian near-crash identification with roadside LiDAR data. Accid. Anal. Prev. 2018, 121, 238–249. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, H.; Wu, J. An automatic background filtering method for detection of road users in heavy traffics using roadside 3-d LiDAR sensors with noises. IEEE Sens. J. 2020, 20, 6596–6604. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, ELECTR NETWORK, Seattle, WA, USA, 13–19 June 2020; pp. 1711–1719. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10529–10538. [Google Scholar]
- Wang, S.; Pi, R.; Li, J.; Guo, X.; Lu, Y.; Li, T.; Tian, Y. Object tracking based on the fusion of roadside LiDAR and camera data. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 770–779. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems 30; Curran Associates, Inc.: Long Beach, CA, USA, 2017. [Google Scholar]
- OpenPCDet Development Team. Openpcdet: An Open-Source Toolbox for 3D Object Detection from Point Clouds. 2020. Available online: https://github.com/open-mmlab/OpenPCDet (accessed on 1 December 2022).
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Luo, Y.; Qin, H. 3D Object Detection Method for Autonomous Vehicle Based on Sparse Color Point Cloud. Automot. Eng. 2021, 43, 492–500. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-iou loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Liu, L.; He, J.; Ren, K.; Xiao, Z.; Hou, Y. A LiDAR–camera fusion 3d object detection algorithm. Information 2022, 13, 169. [Google Scholar] [CrossRef]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; López-Antequera, M.; Kontschieder, P. Disentangling monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1991–1999. [Google Scholar]
- Shi, S.; Wang, Z.; Shi, J.; Wang, X.; Li, H. From points to parts: 3d object detection from point cloud with part-aware and part-aggregation network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2647–2664. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Location | Name | Example |
|---|---|---|
| 1 | type | Car |
| 2 | truncated | 0 |
| 3 | occluded | 1 |
| 4 | alpha | 1.55 |
| 5–8 | bbox | (357.33, 133.24, 441.52, 216.2) |
| 9–11 | dimensions | (1.57, 1.32, 3.55) |
| 12–14 | location | (1.00, 1.75, 13.22) |
| 15 | rotation_y | 1.62 |
| 16 | score | 1.38 |
| Easy (Imin = 0.70) | Moderate (Imin = 0.70) | Hard (Imin = 0.70) | Easy (Imin = 0.70) | Moderate (Imin = 0.50) | Hard (Imin = 0.50) | ||
|---|---|---|---|---|---|---|---|
| APR11 (Car) | bbox | 90.7746 | 89.6528 | 89.1511 | 90.7746 | 89.6528 | 89.1511 |
| bev | 90.0448 | 87.2562 | 86.4370 | 90.7395 | 89.8508 | 89.5665 | |
| 3d | 88.9404 | 78.6675 | 77.8114 | 90.7395 | 89.8258 | 89.5203 | |
| aos | 90.76 | 89.55 | 88.98 | 90.76 | 89.55 | 88.98 | |
| APR40 (Car) | bbox | 96.4271 | 92.8655 | 90.5181 | 96.4271 | 92.8655 | 90.5181 |
| bev | 93.1580 | 88.9119 | 86.7579 | 96.4536 | 95.1651 | 92.9492 | |
| 3d | 91.3287 | 80.5840 | 78.1417 | 96.4313 | 95.0479 | 92.8361 | |
| aos | 96.41 | 92.74 | 90.34 | 96.41 | 92.74 | 90.34 |
| Easy (Imin = 0.50) | Moderate (Imin = 0.50) | Hard (Imin = 0.50) | Easy (Imin = 0.50) | Moderate (Imin = 0.25) | Hard (Imin = 0.25) | ||
|---|---|---|---|---|---|---|---|
| APR11 (Pedestrian) | bbox | 73.5689 | 66.1255 | 62.2895 | 73.5689 | 66.1255 | 62.2895 |
| bev | 67.1253 | 58.8610 | 53.3021 | 82.0378 | 74.9234 | 67.0553 | |
| 3d | 61.8900 | 54.4388 | 50.1242 | 81.9940 | 74.7333 | 66.9421 | |
| aos | 70.86 | 63.01 | 59.00 | 70.86 | 63.01 | 59.00 | |
| APR40 (Pedestrian) | bbox | 74.8557 | 67.7918 | 61.0786 | 74.8557 | 67.7918 | 61.0786 |
| bev | 66.1146 | 58.1660 | 51.4365 | 82.8676 | 76.0780 | 68.8326 | |
| 3d | 62.8512 | 54.9202 | 47.9085 | 82.7933 | 74.8970 | 67.6176 | |
| aos | 71.85 | 64.21 | 57.60 | 71.85 | 64.21 | 57.60 |
| Easy (Imin = 0.50) | Moderate (Imin = 0.50) | Hard (Imin = 0.50) | Easy (Imin = 0.50) | Moderate (Imin = 0.25) | Hard (Imin = 0.25) | ||
|---|---|---|---|---|---|---|---|
| APR11 (Cyclist) | bbox | 89.6212 | 76.3985 | 70.1547 | 89.6212 | 76.3985 | 70.1547 |
| bev | 85.7266 | 71.9324 | 66.3024 | 88.4910 | 74.5981 | 68.5349 | |
| 3d | 85.0175 | 66.8832 | 64.3491 | 88.4910 | 74.5981 | 68.5349 | |
| aos | 89.54 | 75.90 | 69.74 | 89.54 | 75.90 | 69.74 | |
| APR40 (Cyclist) | bbox | 94.9042 | 77.2506 | 72.8562 | 94.9042 | 77.2506 | 72.8562 |
| bev | 90.3609 | 71.2446 | 68.1587 | 93.5190 | 75.2005 | 70.8290 | |
| 3d | 87.6985 | 68.6195 | 64.1195 | 93.5190 | 75.2005 | 70.8290 | |
| aos | 94.82 | 76.71 | 72.33 | 94.82 | 76.71 | 72.33 |
| PointRCNN (Base) | PV-RCNN | SECOND | Part-A2-Free | Ours | |
|---|---|---|---|---|---|
| Training time | 3 h | 5 h | 1.7 h | 3.8 h | 3 h |
| Running time | 120.548 s | 102.653 s | 50.595 s | 93.343 s | 121.469 s |
| Detection range | Front FoV | Front FoV | Front FoV | Front FoV | 360° FoV |
| AP | 88.9404 | 89.3476 | 88.6137 | 89.1192 | 88.9404 |
| Output objects | 4306 | 6094 | 8051 | 6259 | 7628 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, X.; Wang, C.; Lv, B.; Li, J.; Zhang, M.; Zhang, Z. 3D Point Cloud Stitching for Object Detection with Wide FoV Using Roadside LiDAR. Electronics 2023, 12, 703. https://doi.org/10.3390/electronics12030703
Lan X, Wang C, Lv B, Li J, Zhang M, Zhang Z. 3D Point Cloud Stitching for Object Detection with Wide FoV Using Roadside LiDAR. Electronics. 2023; 12(3):703. https://doi.org/10.3390/electronics12030703
Chicago/Turabian StyleLan, Xiaowei, Chuan Wang, Bin Lv, Jian Li, Mei Zhang, and Ziyi Zhang. 2023. "3D Point Cloud Stitching for Object Detection with Wide FoV Using Roadside LiDAR" Electronics 12, no. 3: 703. https://doi.org/10.3390/electronics12030703
APA StyleLan, X., Wang, C., Lv, B., Li, J., Zhang, M., & Zhang, Z. (2023). 3D Point Cloud Stitching for Object Detection with Wide FoV Using Roadside LiDAR. Electronics, 12(3), 703. https://doi.org/10.3390/electronics12030703