

Development of Apple Detection System and Reinforcement Learning for Apple Manipulator


Abstract
:1. Introduction
2. Related Works
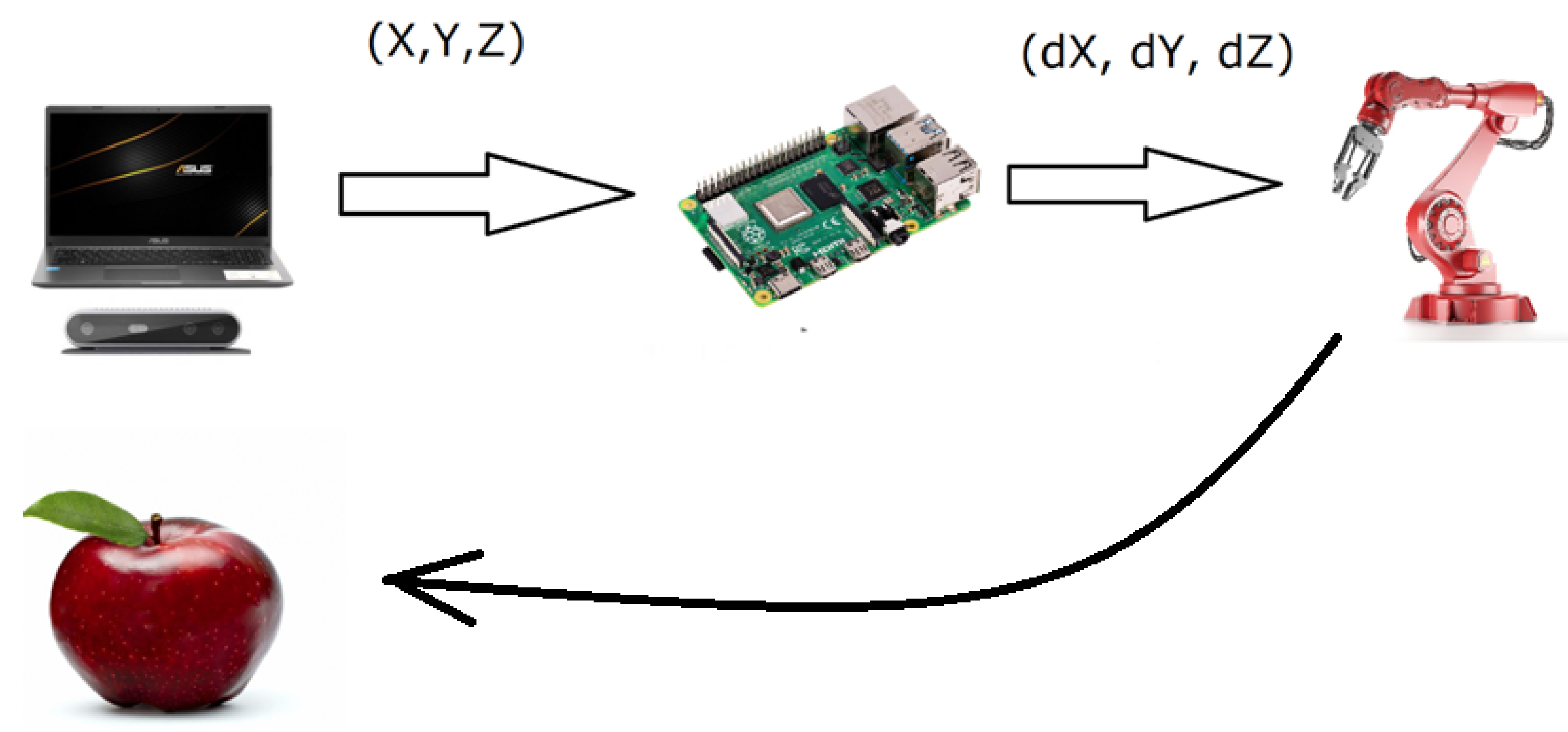
3. Materials and Methods
4. Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ran, Y.; Tang, H.; Li, B.; Wang, G. Self-Supervised Video Representation and Temporally Adaptive Attention for Audio-Visual Event Localization. Appl. Sci. 2022, 12, 12622. [Google Scholar] [CrossRef]
- Qu, Z.; Tongqiang, H.; Tuming, Y. MFFAMM: A Small Object Detection with Multi-Scale Feature Fusion and Attention Mechanism Module. Appl. Sci. 2022, 12, 8940. [Google Scholar] [CrossRef]
- Andriyanov, N.A. Combining Text and Image Analysis Methods for Solving Multimodal Classification Problems. Pattern Recognit. Image Anal. 2022, 32, 489–494. [Google Scholar] [CrossRef]
- Tsourounis, D.; Kastaniotis, D.; Theoharatos, C.; Kazantzidis, A.; Economou, G. SIFT-CNN: When Convolutional Neural Networks Meet Dense SIFT Descriptors for Image and Sequence Classification. J. Imaging 2022, 8, 256. [Google Scholar] [CrossRef] [PubMed]
- Bernstein, A.V.; Burnaev, E.V.; Kachan, O.N. Reinforcement Learning for Computer Vision and Robot Navigation. In Proceedings of the Machine Learning and Data Mining in Pattern Recognition: 14th International Conference, MLDM 2018, New York, NY, USA, 15–19 July 2018; Volume 10935, pp. 258–272. [Google Scholar]
- Andriyanov, N.; Khasanshin, I.; Utkin, D.; Gataullin, T.; Ignar, S.; Shumaev, V.; Soloviev, V. Intelligent System for Estimation of the Spatial Position of Apples Based on YOLOv3 and Real Sense Depth Camera D415. Symmetry 2022, 14, 148. [Google Scholar] [CrossRef]
- Rolandi, S.; Brunori, G.; Bacco, M.; Scotti, I. The Digitalization of Agriculture and Rural Areas: Towards a Taxonomy of the Impacts. Sustainability 2021, 13, 5172. [Google Scholar] [CrossRef]
- López-Morales, J.A.; Martínez, J.A.; Skarmeta, A.F. Digital Transformation of Agriculture through the Use of an In-teroperable Platform. Sensors 2020, 20, 1153. [Google Scholar] [CrossRef]
- Cho, W.; Kim, S.; Na, M.; Na, I. Forecasting of Tomato Yields Using Attention-Based LSTM Network and ARMA Model. Electronics 2021, 10, 1576. [Google Scholar] [CrossRef]
- United Nations: Population. Available online: https://www.un.org/en/global-issues/population (accessed on 15 January 2023).
- Bahn, R.A.; Yehya, A.K.; Zurayk, R. Digitalization for Sustainable Agri-Food Systems: Potential, Status, and Risks for the MENA Region. Sustainability 2021, 13, 3223. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskii, A.G. Detection of objects in the images: From likelihood relationships towards scalable and efficient neural networks. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Andriyanov, N. Estimating Object Coordinates Using Convolutional Neural Networks and Intel Real Sense D415/D455 Depth Maps. In Proceedings of the 2022 VIII International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 23–27 May 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Nasiri, M.; Liebchen, B. Reinforcement learning of optimal active particle navigation. arXiv 2022, arXiv:2202.00812. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- YOLOv5 Release. Available online: https://github.com/ultralytics/yolov5 (accessed on 31 December 2022).
- Titov, V.S.; Spevakov, A.G.; Primenko, D.V. Multispectral optoelectronic device for controlling an autonomous mobile platform. Comput. Opt. 2021, 45, 399–404. [Google Scholar] [CrossRef]
- Info. D415 Camera. Available online: https://www.intelrealsense.com/depth-camera-d415/ (accessed on 31 December 2022).
- Info. ZED-2 Camera. Available online: https://www.stereolabs.com/zed-2/ (accessed on 31 December 2022).
- Sumanas, M.; Petronis, A.; Bucinskas, V.; Dzedzickis, A.; Virzonis, D.; Morkvenaite-Vilkonciene, I. Deep Q-Learning in Robotics: Improvement of Accuracy and Repeatability. Sensors 2022, 22, 3911. [Google Scholar] [CrossRef]
- Păvăloaia, V.-D.; Husac, G. Tracking Unauthorized Access Using Machine Learning and PCA for Face Recognition Developments. Information 2023, 14, 25. [Google Scholar] [CrossRef]
- Darabant, A.S.; Borza, D.; Danescu, R. Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study. Mathematics 2021, 9, 195. [Google Scholar] [CrossRef]
- Tan, M.; Chao, W.; Cheng, J.-K.; Zhou, M.; Ma, Y.; Jiang, X.; Ge, J.; Yu, L.; Feng, L. Animal Detection and Classification from Camera Trap Images Using Different Mainstream Object Detection Architectures. Animals 2022, 12, 1976. [Google Scholar] [CrossRef]
- Villa, A.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. Ecol. Inform. 2017, 41, 24–32. [Google Scholar] [CrossRef]
- Rupinder, K.; Jain, A.; Saini, P.; Kumar, S. A Review Analysis Techniques of Flower Classification Based on Machine Learning Algorithms. ECS Trans. 2022, 107, 9609. [Google Scholar]
- Zhenzhen, S.; Longsheng, F.; Jingzhu, W.; Zhihao, L.; Rui, L.; Yongjie, C. Kiwifruit detection in field images using Faster R-CNN with VGG16. IFAC-Pap. 2019, 52, 76–81. [Google Scholar]
- Andriyanov, N.A.; Gavrilina, Y.N. Image Models and Segmentation Algorithms Based on Discrete Doubly Stochastic Autoregressions with Multiple Roots of Characteristic Equations. CEUR Workshop Proc. 2018, 2076, 1–10. [Google Scholar]
- Vasilev, K.K.; Dementev, V.E.; Andriyanov, N.A. Application of mixed models for solving the problem on restoring and estimating image parameters. Pattern Recognit. Image Anal. 2016, 26, 240–247. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame Stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Brown, M.Z.; Burschka, D.; Hager, G.D. Advances in computational stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 993–1008. [Google Scholar] [CrossRef]
- Tombari, F.; Mattoccia, S.; Stefano, L.D.; Addimanda, E. Classification and evaluation of cost aggregation methods for stereo correspondence. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition (CVPR’08), Anchorage, Alaska, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Lazaros, N.; Sirakoulis, G.C.; Gasteratos, A. Review of stereo vision algorithms: From software to hardware. Int. J. Optomechatronics 2008, 2, 435–462. [Google Scholar] [CrossRef]
- Tombari, F.; Gori, F.; Di Stefano, L. Evaluation of stereo algorithms for 3D object recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV’11), Barcelona, Spain, 6–13 November 2011; pp. 990–997. [Google Scholar]
- Tippetts, B.; Lee, D.J.; Lillywhite, K.; Archibald, J. Review of stereo vision algorithms and their suitability for resourcelimited systems. J. Real-Time Image Process. 2013, 8, 1–21. [Google Scholar]
- Stentoumis, C.; Grammatikopoulos, L.; Kalisperakis, I.; Karras, G.; Petsa, E. Stereo matching based on Census transformation of image gradients. In Proceedings Volume 9528, Videometrics, Range Imaging, and Applications XIII; SPIE: Bellingham, WA, USA, 2015; p. 12210. [Google Scholar]
- Andriyanov, N.A.; Vasiliev, K.K.; Dementiev, V.E. Investigation of Filtering and Objects Detection Algorithms for a Multizone Image Sequence. ISPRS Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2019, XLII-2/W12, 7–10. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Neural Inf. Process. Syst. (NeurIPS) 2012, 2012, 1106–1114. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. Available online: https://arxiv.org/abs/1504.08083 (accessed on 13 January 2023).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Available online: https://arxiv.org/abs/1506.01497 (accessed on 14 January 2023).
- Andriyanov, N.; Papakostas, G. Optimization and Benchmarking of Convolutional Networks with Quantization and OpenVINO in Baggage Image Recognition. In Proceedings of the 2022 VIII International Conference on Information Technology and Nanotechnology (ITNT), Samara, Russia, 23–27 May 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Wu, R.; Guo, X.; Du, J.; Li, J. Accelerating Neural Network Inference on FPGA-Based Platforms—A Survey. Electronics 2021, 10, 1025. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. Available online: https://arxiv.org/abs/1506.02640 (accessed on 31 December 2022).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single Shot MultiBox Detector. Available online: https://arxiv.org/abs/1512.02325 (accessed on 31 December 2022).
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. Available online: https://arxiv.org/abs/1708.02002 (accessed on 31 December 2022).
- DarkNet-53. Available online: https://github.com/pjreddie/darknet (accessed on 31 December 2022).
- Zhang, Y.; Guo, Z.; Wu, J.; Tian, Y.; Tang, H.; Guo, X. Real-Time Vehicle Detection Based on Improved YOLO v5. Sustainability 2022, 14, 12274. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskiy, A.G. Development of a Productive Transport Detection System Using Convolutional Neural Networks. Pattern Recognit. Image Anal. 2022, 32, 495–500. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. Int. Conf. Learn. Represent. 2021, 2021, 1–22. [Google Scholar]
- Kuznetsova, A.; Maleva, T.; Soloviev, V. Using YOLOv3 Algorithm with Pre- and Post-Processing for Apple Detection in Fruit-Harvesting Robot. Agronomy 2020, 10, 1016. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A Real-Time Apple Targets Detection Method for Picking Robot Based on Improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Huang, Z.; Zhang, P.; Liu, R.; Li, D. Immature Apple Detection Method Based on Improved Yolov3. ASP Trans. Internet Things 2021, 1, 9–13. [Google Scholar] [CrossRef]
- Andriyanov, N.A.; Andriyanov, D.A. The using of data augmentation in machine learning in image processing tasks in the face of data scarcity. J. Phys. Conf. Ser. 2020, 1661, 012018. [Google Scholar] [CrossRef]
- Xuan, G. Apple Detection in Natural Environment Using Deep Learning Algorithms. IEEE Access 2020, 8, 216772–216780. [Google Scholar] [CrossRef]
- Itakura, K.; Narita, Y.; Noaki, S.; Hosoi, F. Automatic pear and apple detection by videos using deep learning and a Kalman filter. OSA Contin. 2021, 4, 1688. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, H.; Ge, B. Adaptive Unscented Kalman Filter for Target Tacking with Time-Varying Noise Covariance Based on Multi-Sensor Information Fusion. Sensors 2021, 21, 5808. [Google Scholar] [CrossRef]
- Gómez-Espinosa, A.; Rodríguez-Suárez, J.B.; Cuan-Urquizo, E.; Cabello, J.A.E.; Swenson, R.L. Colored 3D Path Extraction Based on Depth-RGB Sensor for Welding Robot Trajectory Generation. Automation 2021, 2, 252–265. [Google Scholar] [CrossRef]
- Servi, M.; Mussi, E.; Profili, A.; Furferi, R.; Volpe, Y.; Governi, L.; Buonamici, F. Metrological Characterization and Comparison of D415, D455, L515 RealSense Devices in the Close Range. Sensors 2021, 21, 7770. [Google Scholar] [CrossRef] [PubMed]
- Maru, M.B.; Lee, D.; Tola, K.D.; Park, S. Comparison of Depth Camera and Terrestrial Laser Scanner in Monitoring Structural Deflections. Sensors 2021, 21, 201. [Google Scholar] [CrossRef] [PubMed]
- Andriyanov, N. Methods for Preventing Visual Attacks in Convolutional Neural Networks Based on Data Discard and Dimensionality Reduction. Appl. Sci. 2021, 11, 5235. [Google Scholar] [CrossRef]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadji, H.; Ardani, M. Deep Reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857. [Google Scholar]
- Dalal, M.; Pathak, D.; Salakhutdinov, R. Accelerating Robotic Reinforcement Learning via Parameterized Action Primitives. arXiv 2021, arXiv:2110.15360. [Google Scholar]
- Vacaro, J.; Marques, G.; Oliveira, B.; Paz, G.; Paula, T.; Staehler, W.; Murphy, D. Sim-to-Real in Reinforcement Learning for Everyone. In Proceedings of the 2019 Latin American Robotics Symposium (LARS), 2019 Brazilian Symposium on Robotics (SBR) and 2019 Workshop on Robotics in Education (WRE), Rio Grande, Brazil, 23–25 October 2019; pp. 305–310. [Google Scholar]
- Computer Vision Annotation Tool. Available online: https://cvat.org/ (accessed on 16 January 2023).
- Laganiere, R.; Gilbert, S.; Roth, G. Robust object pose estimation from feature-based stereo. IEEE Trans. Instrum. Meas. 2006, 55, 1270–1280. [Google Scholar] [CrossRef]
- Lin, C.-J.; Jhang, J.-Y.; Lin, H.-Y.; Lee, C.-L.; Young, K.-Y. Using a Reinforcement Q-Learning-Based Deep Neural Network for Playing Video Games. Electronics 2019, 8, 1128. [Google Scholar] [CrossRef]
- Q-learning. Available online: https://en.wikipedia.org/wiki/Q-learning (accessed on 15 January 2023).
- Shaohua, W.; Sotirios, G. Faster R-CNN for multi-class fruit detection using a robotic vision system. Comput. Netw. 2020, 168, 107036. [Google Scholar]
- Bhargava, A.; Bansal, A. Fruits and vegetables quality evaluation using computer vision: A review. J. King Saud Univ.-Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Performance (fps) |
|---|---|---|
| YOLOv5 | 86.32% | 6.54 |
| YOLOv3 | 74.85% | 4.75 |
| R-CNN | 69.45% | 1.06 |
| Fast R-CNN | 66.78% | 2.78 |
| Model | mAP | mAP after Fine-Tuning |
|---|---|---|
| Yolov5n (640 px) | 46.42% | 46.47% |
| Yolov5s (640 px) | 53.22% | 53.44% |
| Yolov5m (640 px) | 84.75% | 86.22% |
| Yolov5l (640 px) | 88.92% | 90.13% |
| Yolov5x (640 px) | 90.31% | 94.27% |
| Yolov5x6 (1280 px) | 91.14% | 96.22% |
| Yolov5x6+ (1280 px) | 93.72% | 97.08% |
| Model | mAP Red | mAP Green |
|---|---|---|
| Yolov5n (640 px) | 47.54 % | 46.22% |
| Yolov5s (640 px) | 54.86% | 52.91% |
| Yolov5m (640 px) | 86.78% | 85.42% |
| Yolov5l (640 px) | 91.07% | 88.95% |
| Yolov5x (640 px) | 95.64% | 93.12% |
| Yolov5x6 (1280 px) | 96.92% | 95.05% |
| Yolov5x6+ (1280 px) | 97.96% | 95.38% |
| Camera | RMSE on X (mm) | RMSE on Y (mm) | RMSE on Z (mm) |
|---|---|---|---|
| Intel Real Sense D415 | 7.22 | 6.54 | 16.59 |
| ZED 2 | 6.24 | 4.68 | 13.22 |
| Politics | Time (ms) | Penalties |
|---|---|---|
| Q-learning | 36.85 | 0 |
| Naive (snake) | 124.75 | 5.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andriyanov, N. Development of Apple Detection System and Reinforcement Learning for Apple Manipulator. Electronics 2023, 12, 727. https://doi.org/10.3390/electronics12030727
Andriyanov N. Development of Apple Detection System and Reinforcement Learning for Apple Manipulator. Electronics. 2023; 12(3):727. https://doi.org/10.3390/electronics12030727
Chicago/Turabian StyleAndriyanov, Nikita. 2023. "Development of Apple Detection System and Reinforcement Learning for Apple Manipulator" Electronics 12, no. 3: 727. https://doi.org/10.3390/electronics12030727
APA StyleAndriyanov, N. (2023). Development of Apple Detection System and Reinforcement Learning for Apple Manipulator. Electronics, 12(3), 727. https://doi.org/10.3390/electronics12030727