
CBCS: A Scalable Consortium Blockchain Architecture Based on World State Collaborative Storage


Abstract
:1. Introduction
- (1)
- A business world state database update method is designed based on sparse Merkle multiproofs, where collaborative storage of world state is realized under the premise of mutual isolation of ledger between business domains.
- (2)
- A world state consistency verification method based on the rank B+ tree is designed to verify the consistency of the business world state in business domain by the checking sidechain, and a main-side chain cross-anchoring structure is designed to realize secure anchoring of the mainchain and the checking sidechain.
- (3)
- Considering the demand that business nodes may need complete blockchain transactions, the main-side chain cross-anchoring structure is used to design the blockchain transaction trusted tracing method based on two-level certification to support business nodes’ access to blockchain transactions.
- (4)
- The feasibility and efficiency of the proposed architecture to address the storage scalability issue of consortium blockchain is verified through experiments.
2. Related Work
3. Preliminaries
3.1. Consortium Blockchain
3.2. B+ Tree
4. Execution Framework
4.1. World State Collaborative Storage Method
4.1.1. Collaborative Storage Architecture
4.1.2. Business World State Database Update Method Based on Sparse Merkle Multiproofs
- Multiproofs Auxiliary Information Generation;
- Block Broadcasting;
- Business World State Database Update.
4.2. World State Consistency Verification Method Based on Rank B+ Tree
4.2.1. Rank B+ Tree
4.2.2. Main-Side Chain Cross-Anchoring Structure
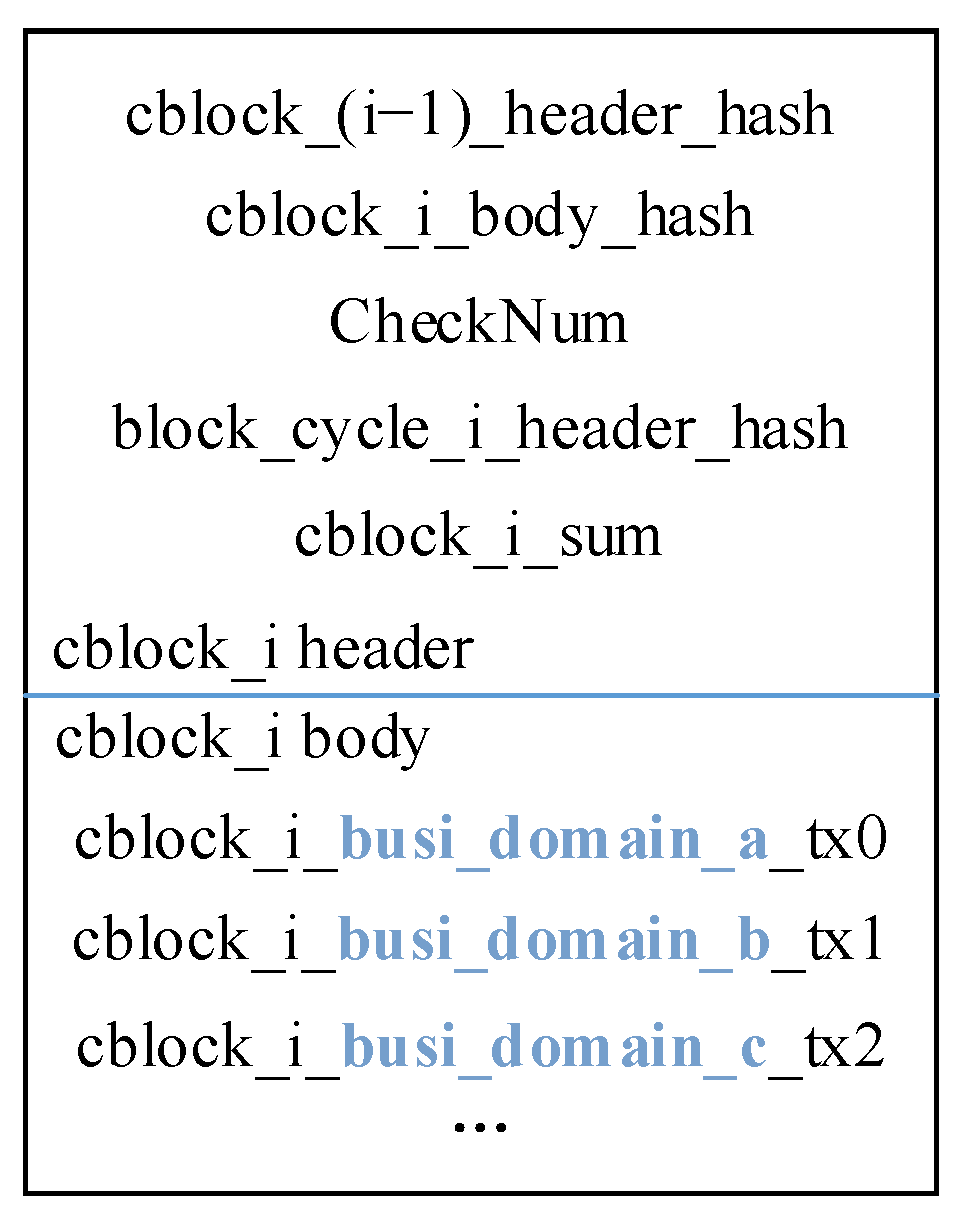
4.2.3. Checking Block Generation and Consistency Matching
4.3. Blockchain Transaction Trusted Tracing Method Based on Two-Level Certification
4.3.1. Block-Level Proof and Interval-Level Proof
- Generation of block_prove;
- Generation of block_prove.
4.3.2. Blockchain Transactions Verification
5. Security Analysis
5.1. Business World State Database Security Isolation and Synchronization
5.2. Business World State Database Consistency Security
5.3. Main-Side Chain Cross-Anchoring Structure Safety
6. Experimental Evaluations
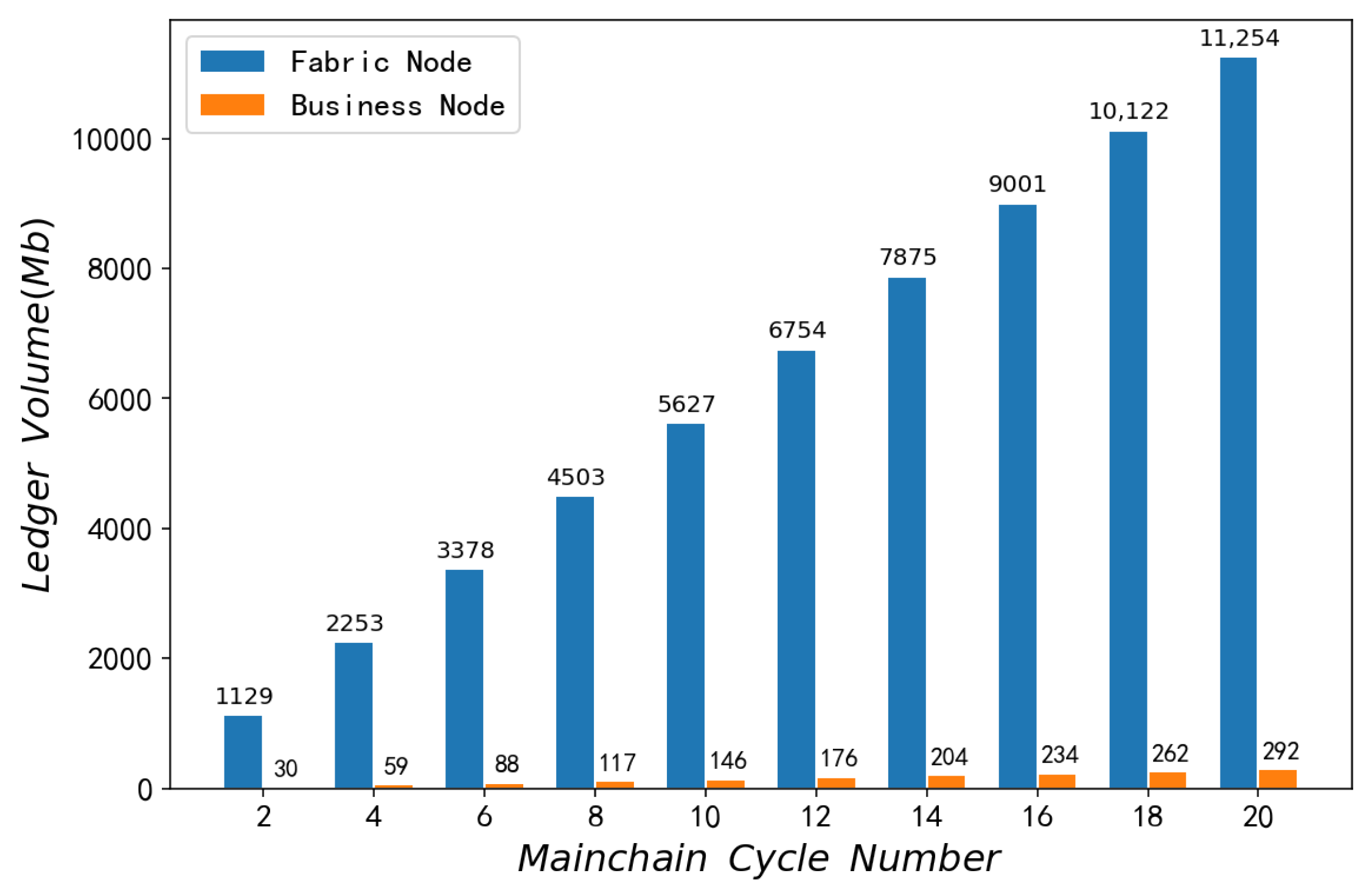
6.1. Ledger Data Volume Test
6.2. Transaction Type Impact Test
6.3. Sidechain Data Impact Test
6.4. Efficiency Test of Retrieving State Data
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Berdik, D.; Otoum, S.; Schmidt, N.; Porter, D.; Jararweh, Y. A survey on blockchain for information systems management and security. Inf. Process. Manag. 2021, 58, 102397. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 16 September 2022).
- Sun, Z.; Zhang, X.; Xiang, F.; Chen, L. Survey of storage scalability on blockchain. J. Softw. 2021, 32, 1–20. [Google Scholar]
- Zheng, Z.; Xie, S.; Dai, H.N.; Chen, X.; Wang, H. Blockchain challenges and opportunities: A survey. Int. J. Web Grid Serv. 2018, 14, 352–375. [Google Scholar] [CrossRef]
- Dib, O.; Brousmiche, K.L.; Durand, A.; Thea, E.; Hamida, E.B. Consortium blockchains: Overview, applications and challenges. Int. J. Adv. Telecommun. 2018, 11, 51–64. [Google Scholar]
- Gorenflo, C.; Lee, S.; Golab, L.; Keshav, S. FastFabric: Scaling hyperledger fabric to 20,000 transactions per second. Int. J. Netw. Manag. 2020, 30, e2099. [Google Scholar] [CrossRef]
- Zhang, A.; Lin, X. Towards secure and privacy-preserving data sharing in e-health systems via consortium blockchain. J. Med. Syst. 2018, 42, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Gao, Z.; Cao, L.; Du, X. Data right confirmation mechanism based on blockchain and locality sensitive hashing. In Proceedings of the 2020 3rd International Conference on Hot Informationcentric Networking (HotICN), Hefei, China, 12–14 December 2020. [Google Scholar]
- Nyaletey, E.; Parizi, R.M.; Zhang, Q.; Choo, K.K.R. BlockIPFS-blockchain-enabled interplanetary file system for forensic and trusted data traceability. In Proceedings of the 2019 IEEE International Conference on Blockchain (Blockchain), Atlanta, GA, USA, 14–17 July 2019. [Google Scholar]
- Chen, X.; Zhang, K.; Liang, X.; Qiu, W.; Zhang, Z.; Tu, D. HyperBSA: A high-performance consortium blockchain storage architecture for massive data. IEEE Access. 2020, 8, 178402–178413. [Google Scholar] [CrossRef]
- Androulaki, E.; Barger, A.; Bortnikov, V.; Cachin, C.; Christidis, K.; De Caro, A.; Yellick, J. Hyperledger fabric: A distributed op-erating system for permissioned blockchains. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018. [Google Scholar]
- Yu, G.; Wang, X.; Yu, K.; Ni, W.; Zhang, J.A.; Liu, R.P. Survey: Sharding in blockchains. IEEE Access 2020, 8, 14155–14181. [Google Scholar] [CrossRef]
- Gao, Z.; Zhang, D.; Zhang, J. A security problem caused by the state database in Hyperledger Fabric. In Proceedings of the International Conference on Frontiers in Cyber Security, Tianjin, China, 15–17 November 2020; pp. 361–372. [Google Scholar]
- Sharma, P.; Jindal, R.; Borah, M.D. Blockchain technology for cloud storage: A systematic literature review. ACM Comput. Surv. (CSUR) 2020, 53, 1–32. [Google Scholar] [CrossRef]
- Benet, J. Ipfs-Content Addressed, Versioned, p2p File System. Available online: https://arxiv.org/abs/1407.3561 (accessed on 16 September 2022).
- Zheng, Q.; Li, Y.; Chen, P.; Dong, X. An innovative IPFS-based storage model for blockchain. In Proceedings of the 2018 IEEE/WIC/ACM International Conference on Web Intelligence (WI), Santiago, Chile, 3–6 December 2018; pp. 704–708. [Google Scholar]
- He, G.; Su, W.; Gao, S. Chameleon: A scalable and adaptive permissioned blockchain architecture. In Proceedings of the 2018 1st IEEE International Conference on Hot Information-Centric Networking (HotICN), Shenzhen, China, 15–17 August 2018; pp. 87–93. [Google Scholar]
- Xu, C.; Zhang, C.; Xu, J.; Pei, J. SlimChain: Scaling blockchain transactions through off-chain storage and parallel processing. Proc. VLDB Endow. 2021, 14, 2314–2326. [Google Scholar] [CrossRef]
- Suratkar, S.; Shirole, M.; Bhirud, S. Cryptocurrency wallet: A review. In Proceedings of the 2020 4th International Conference on Computer, Communication and Signal Processing (ICCCSP), Chennai, India, 28–29 September 2020. [Google Scholar]
- Nauman, A.; Qadri, Y.A.; Amjad, M.; Zikria, Y.B.; Afzal, M.K.; Kim, S.W. Multimedia Internet of Things: A comprehensive survey. IEEE Access 2020, 8, 8202–8250. [Google Scholar] [CrossRef]
- Chakravarty, M.M.; Chapman, J.; MacKenzie, K.; Melkonian, O.; Peyton Jones, M.; Wadler, P. The extended UTXO model. In Proceedings of the International Conference on Financial Cryptography and Data Security, Kota Kinabalu, Malaysia, 14 February 2020; pp. 525–539. [Google Scholar]
- Palai, A.; Vora, M.; Shah, A. Empowering light nodes in blockchains with block summarization. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Paris, France, 26–28 February 2018. [Google Scholar]
- Kim, T.; Noh, J.; Cho, S. SCC: Storage compression consensus for blockchain in lightweight IoT network. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019. [Google Scholar]
- De Angelis, S.; Aniello, L.; Baldoni, R.; Lombardi, F.; Margheri, A.; Sassone, V. PBFT vs proof-of-authority: Applying the CAP theorem to permissioned blockchain. In Proceedings of the Italian Conference on Cyber Security, Milan, Italy, 6 February 2018. [Google Scholar]
- Liu, Y.; Wang, K.; Lin, Y.; Xu, W. LightChain: A lightweight blockchain system for industrial internet of things. IEEE Trans. Ind. Inform. 2019, 15, 3571–3581. [Google Scholar] [CrossRef]
- Qi, X.; Zhang, Z.; Jin, C.; Zhou, A. BFT-Store: Storage partition for permissioned blockchain via erasure coding. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 1926–1929. [Google Scholar]
- Guo, Z.; Gao, Z.; Liu, Q.; Chakraborty, C.; Hua, Q.; Yu, K.; Wan, S. RNS-based adaptive compression scheme for the block data in the blockchain for IIoT. IEEE Trans. Ind. Inform. 2022, 18, 9239–9249. [Google Scholar] [CrossRef]
- Valueva, M.V.; Nagornov, N.N.; Lyakhov, P.A.; Valuev, G.V.; Chervyakov, N.I. Application of the residue number system to reduce hardware costs of the convolutional neural network implementation. Math. Comput. Simul. 2020, 177, 232–243. [Google Scholar] [CrossRef]
- Chen, X.; Lin, X.; Yu, N. Compression of bitcoin blockchain. Chin. J. Netw. Inf. Secur. 2021, 7, 76–83. [Google Scholar]
- Xu, Z.; Han, S.; Chen, L. CUB, a consensus unit-based storage scheme for blockchain system. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 173–184. [Google Scholar]
- Chen, L.; Zhang, X.; Sun, Z. Scalable Blockchain Storage Model Based on DHT and IPFS. KSII Trans. Internet Inf. Syst. 2022, 16, 2286–2304. [Google Scholar]
- Morris, R.; Kaashoek, M.F.; Karger, D.; Balakrishnan, H.; Stoica, I.; Liben-Nowell, D.; Dabek, F. Chord: A scalable peer-to-peer look-up protocol for internet applications. IEEE/ACM Trans. Netw. 2003, 11, 17–32. [Google Scholar]
- Xie, J.; Li, Z.; Jin, J.; Zhang, B.; Hua, Y. Research on Blockchain Storage Extension Based on DHT. In Proceedings of the 2021 4th International Con-ference on Big Data Technologies, Zibo, China, 24–26 September 2021; pp. 79–85. [Google Scholar]
- Marandi, A.; Sehat, H.; Lucani, D.E.; Mousavifar, S.; Jacobsen, R.H. Network Coding-based Data Storage and Retrieval for Kademlia. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021. [Google Scholar]
- Tolmach, P.; Li, Y.; Lin, S.W.; Liu, Y.; Li, Z. A survey of smart contract formal specification and verification. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Zhou, W.; Lu, J.; Luan, Z.; Wang, S.; Xue, G.; Yao, S. SNB-index: A SkipNet and B+ tree based auxiliary Cloud index. Clust. Comput. 2014, 17, 453–462. [Google Scholar] [CrossRef]
- Sousa, J.; Bessani, A.; Vukolic, M. A byzantine fault-tolerant ordering service for the hyperledger fabric blockchain platform. In Proceedings of the 2018 48th annual IEEE/IFIP international conference on dependable systems and networks (DSN), Luxembourg, 25–28 June 2018; pp. 51–58. [Google Scholar]
- Mizrahi, A.; Koren, N.; Rottenstreich, O. Optimizing Merkle proof size for blockchain transactions. In Proceedings of the 2021 International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 5–9 January 2021; pp. 299–307. [Google Scholar]
- Ramabaja, L.; Avdullahu, A. Compact merkle multiproofs. arXiv 2020, arXiv:2002.07648. [Google Scholar]
- Potdar, A.M.; Narayan, D.G.; Kengond, S.; Mulla, M.M. Performance evaluation of docker container and virtual machine. Procedia Comput. Sci. 2020, 171, 1419–1428. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Main Technology | Storage Location of Ledger Data | Query Method | Compression Rate |
|---|---|---|---|---|
| Liu et al. [25] | filter transactions | on-chain | local retrieval | 56.65% |
| Guo et al. [27] | encode blocks | on-chain | encode fragments | 20% |
| Zheng et al. [16] | storage in IPFS | off-chain + on-chain | ask from off-chain | 8.17% |
| Xu et al. [30] | collaborative storage | on-chain | local retrieval or ask from others | 5% |
| Xu et al. [18] | storage in off-chain nodes | off-chain + on-chain | ask from off-chain | 3~1% |
| Ours | collaborative storage | on-chain | local retrieval | 0.95% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, J.; Wang, N.; Liu, A.; Wang, W.; Du, X. CBCS: A Scalable Consortium Blockchain Architecture Based on World State Collaborative Storage. Electronics 2023, 12, 735. https://doi.org/10.3390/electronics12030735
Zhou J, Wang N, Liu A, Wang W, Du X. CBCS: A Scalable Consortium Blockchain Architecture Based on World State Collaborative Storage. Electronics. 2023; 12(3):735. https://doi.org/10.3390/electronics12030735
Chicago/Turabian StyleZhou, Jiashun, Na Wang, Aodi Liu, Wenjuan Wang, and Xuehui Du. 2023. "CBCS: A Scalable Consortium Blockchain Architecture Based on World State Collaborative Storage" Electronics 12, no. 3: 735. https://doi.org/10.3390/electronics12030735