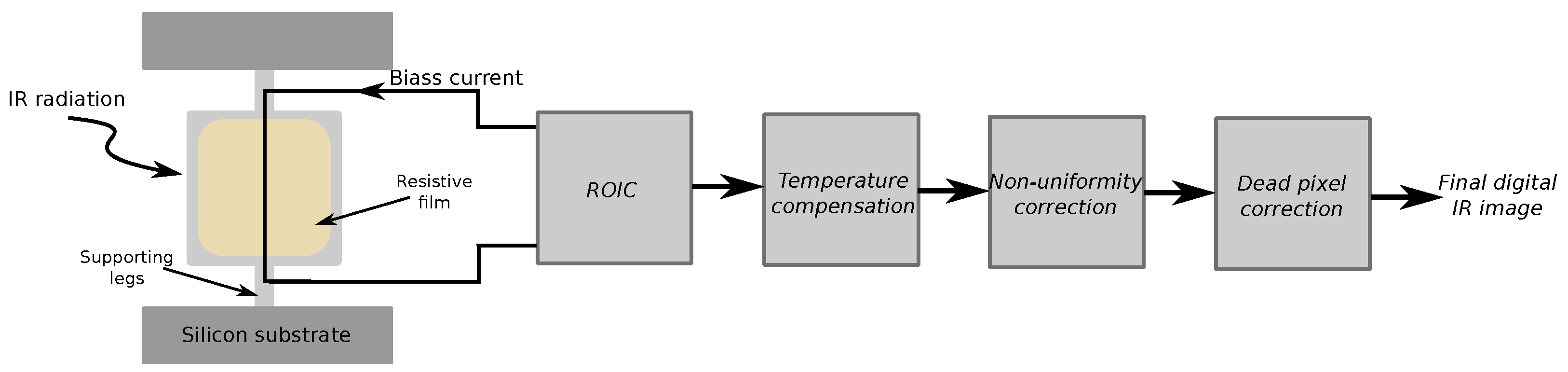
1. Introduction
Infrared (IR) imaging has been extensively used in a variety of different fields [
1,
2] and has undoubtedly solved visible spectrum imaging challenges. Advanced IR camera systems are frequently combined with visible light cameras to advantageously fuse the information from both sensors [
2]. However, the downside of relying on infrared imaging has always been the high cost and complexity of the resulting system [
3]. The correct operation of infrared detectors usually necessitates a thermoelectric heater–cooler for temperature stabilization, which contributes to the price and power consumption of the device. Additionally, IR sensors suffer from fixed pattern noise (FPN) caused by non-uniform responses of detectors. Likewise, ambient and internal temperature variations have an unequal effect on the characteristics of detectors. As a result, the processing unit in the camera system needs to perform several computationally complex correction tasks to recover meaningful information from the raw analog-to-digital converter (ADC) values [
4].
To tackle these challenges, one approach is to leverage the benefits of microbolometer focal plane arrays (FPA), which have the advantage over photon detectors to operate without cooling [
5]. Over the past two decades, continuous advancements in CMOS/MEMS photolithography have been sufficient for fabricating small-pixel microbolometer detectors [
6]. The combination of manufacturing processes and uncooled detector designs has allowed significant performance and yield improvements. Hence, commercially manufacturing high-volume, low-cost and high-operation temperature infrared sensors has become possible. Removing unnecessary thermoelectric parts, in effect, improves reliability and power efficiency and reduces cost, which is crucial in low-cost or power-critical applications where reduced complexity of packaging is decisive.
Although infrared bolometer thermal effects and their respective correction algorithms have been widely studied [
7,
8,
9] and simulated [
10], efficient implementation without introducing a significant delay is critical in real-time applications. In this work, we propose implementing computationally intensive algorithms in a register transfer level (RTL) for field programmable gate array (FPGA)-based uncooled IR imaging system. The proposed approach adopts pipelining design technique and reduces data processing delay for every frame, while ensuring real-time acquisition and thermal effect correction. The presented work follows a research initiative for exploring potential solutions to reduce the costs of IR imaging. The developed prototype is a step towards a potential (processorless) IR camera with low-latency processing suitable for safety-critical applications.
4. Digital Circuit Design
Creating a dedicated infrared FPA preprocessing circuit involves designing a system incorporating several image-processing algorithms and compensating for the different thermal effects. The approach in this work is to exploit the heterogeneous systems-on-chip (HSoC) FPGA architecture by implementing all of the computationally intensive tasks in digital logic and using the microprocessor unit (MPU) for orchestrating data movement to/from FPGA-based accelerators. Notably, before the deployment on a physical system, IR preprocessing algorithm designs were validated using functional simulations and synthetic data [
10].
4.1. Overall System Architecture
In the overall image processing architecture represented in
Figure 2, two parallel AXI-Stream compliant pipelines are implemented for infrared and RGB image processing.
AXI Memory-Mapped to AXI-Stream direct memory access (DMA) controllers transfer images and calibration coefficients from the system memory. Temperature compensation, Non-Uniformity Correction, Defective Pixel Correction and Spatial Image Transformation reside in the first stream, whilst the second stream is responsible for RGB image transformation. The Registration block is necessary to synchronize rectified images from the two streams and place them onto a common coordinate system to enable data enhancement in later processing stages. Bypass data paths permit separate evaluations of every correction algorithm. Each of the custom modules implemented in programmable logic (PL) is configured from the hard processing system (PS), which also initiates data transfers from the shared system memory. The user application running in the Linux operating system uses TCP/IP over Gigabit Ethernet to send the final processed digital image to the visualization application on a host system.
A custom IR Camera Driver interfaces with the QVGA IR Camera to read the raw pixel values and transfer the data to the Memory-Mapped interface. The captured frames are buffered in the system memory since the QVGA IR Camera used in this work operates in a continuous acquisition mode. In this way, the necessity for a large FIFO and the risk of overflowing the FIFO is avoided.
4.2. Temperature Compensation
Temperature compensation utilizes shaded pixels to interpolate temperature-dependent bolometer values for each of the pixels and subtracts them from the illuminated bolometer ADC values.
Figure 3 depicts the temperature dependency correction architecture utilized in this work.
We correct the active microbolometers using the shaded microbolometers in the same row. The chosen sensor has ten shaded bolometers on each side. We store and compute the average values
and
for shaded microbolometers from the beginning and end of the row, respectively. We use these averaged values to define a straight-line function
vs. the pixel location in the row:
Here,
w is a weight factor defined by the distance between the first column and the pixel location:
where
x is the location of the pixel in the row,
is the number of the first column of active pixels and
N is the number of active pixels. Then, the temperature-compensated value
is computed:
Further, we compute the mean values with running average over subsequent frames and make the averaging parameter adjustable (small for high-pass filter, large for low-pass filter) and use these “running”/”filtered” mean values for determining the straight line.
4.3. Non-Uniformity Correction
The infrared image processing pipeline includes a basic two-point non-uniformity correction block shown in
Figure 4.
A calibration procedure is applied to find offset and gain coefficients for every raw pixel. The gain and offset coefficients are applied accordingly to the response of the sensor
to find the non-uniformity corrected value
at the
coordinates:
where
is the offset coefficient and
is the gain coefficient.
Raw pixel values and the coefficients are delivered to the processing unit from the system memory using AXI Memory-Mapped to the AXI-Stream DMA engine. Since data alignment between the streams is not guaranteed, an AXI-Stream synchronizer adjusts simultaneous throttling for all data streams. Apparently, the implementation of a simple two-point algorithm requires only a small amount of logic blocks and memory resources for only two coefficients per pixel. It can be considered a reasonable solution for real-time applications requiring a low hardware footprint.
4.4. Defective Pixel Correction
Defective pixel replacement, as shown in
Figure 5, is based on interpolation using the nearest pixels surrounding the defective pixel. It is a fully pipelined-switched interpolator design capable of arranging data in a moving window and performing bilinear interpolation. The component selectively interpolates only at the coordinates of defective pixels. The defective pixels are identified beforehand at the FPA calibration stage and corresponding coordinates are stored in the memory.
Because of the low amount and sparsely located defective pixels, the pixel coordinates can be transferred over the Memory-Mapped interface beforehand and stored as array constants in Block Memory or Look-Up Tables. The validity information can be further converted into a 1-bit wide AXI-stream. Both streams are synchronized before the dead pixel correction stage receives them.
A 3 × 3 sliding window accumulates the nearest eight neighbors
around the potentially defective pixel
. Four diagonal neighbors
are further used for bilinear interpolation
, which is chosen due to its arithmetic simplicity. The bilinear interpolation core then estimates the intensity value
at the given defective pixel location
. A normalized weighting bilinear interpolation scheme (
Figure 6) consisting of three linear interpolations can be used. The pixels on the vertices of a unit square
construct a new data value inside the square. Assuming the values change linearly between the vertices, we can perform two linear interpolations in the
x direction:
We then interpolate between those interpolated values
in the
y direction to get the result
P:
where
and
are the normalized weight factors, which determine the influence of each neighboring pixel. In this case, the interpolant always resides in the center of the quadrilateral and the weights are equal
.
The candidate pixel is replaced with the interpolation result if the according defective pixel map bit is set. Otherwise, the original pixel value is delayed, and the preserved value is used as the output. Edge pixels are handled by extending the nearest available pixel values. The edge pixel remapping stage checks the current location of the pixel and decides whether rearranging the convolution matrix due to edge proximity is necessary.
4.5. Spatial Image Transformation
The spatial image transformation core, as such, is a sophisticated image processing design, and its detailed description is beyond the scope of this work. Instead, we guide the reader to [
23] and here give a brief overview.
Figure 7 illustrates the architecture of the spatial image transformation component.
It consists of
Read and Write Masters,
Dual-Port Memory Matrix,
Inverse Transformation Computing logic,
Demultiplexing logic and a
Reconstruction block. The spatial transformation accelerator’s working principle relies on the sequential estimation of the consecutive output sample’s location in the input image and reconstructing it using buffered input samples. The solution necessitates computing the inverse transformation and retrieving the corresponding input coordinate pair for the consecutive output coordinates:
where
and
are the input/output image coordinates, and
f is some arbitrary function, expressed as a matrix operator for linear transformations.
Output coordinates for the Inverse Transformation Computation are provided by the Memory Read-Write master. This structure enables simultaneously writing input data to memories and calculating the appropriate read addresses for the output data. Each output pixel can be reconstructed using adjacent pixels in the input image. Dual Port Memory Matrix and Memory Write-Read Masters retrieves the necessary neighboring pixels from the memories. The Demultiplexing logic arranges read pixel data for the Reconstruction, e.g., bilinear or bicubic interpolation. For higher-quality approximation results, we implement bicubic interpolation, which involves retrieving sixteen nearest neighbors and utilizing sixteen buffers in the memory matrix accordingly.
Memory-Mapped interface ensures configuration of the
Inverse Transformation Computing logic. A
Matrix Multiplication core calculates the inverse transformation for any arbitrary linear image transformation, such as translation and rotation. This core also provides the image rectification ability to project IR and RGB images onto a common image plane. Other custom coordinate processors can be used just as well, for example, a processor for calculating a lens distortion correction transformation. In the current configuration,
Matrix Multiplication is cascaded with a
Lens Distortion Correction instance. To correct radially distorted images, we follow the digital circuit architecture for calculating the Barrel distortion correction transformation defined in [
24].
5. Results
The experimental setup depicted in
Figure 8 consists of a combined IR and RGB camera fixture (
Figure 8a) and an electronics evaluation board (
Figure 8b). A Xilinx ZCU102 Evaluation platform was used to implement the system on a Xilinx Ultrascale+ XCZU9EG FPGA. The system was coded using VHDL and synthesized for the target SoC. Fraunhofer IMS infrared bolometer focal plane array
Digital 17 μm
QVGA-IRFPA [
25] with an array of 320 × 240 microbolometer pixels and a pixel pitch of 17 μm × 17 μm constituted the infrared pixel source.
Figure 9 illustrates the control and visualization application residing on a host PC. General controls and configuration of image transformation IP core are implemented in the modular
Dear ImGui GUI building framework [
26].
Table 1 shows the resource utilization of the digital logic design. A complete system utilizes 445 hardware multipliers, 57,474 logic cells, 79,894 registers and 171 BRAM blocks. The high block RAM unit count is associated with pixel buffering in the spatial image transformation core, and the lens distortion correction requires a considerable amount of buffered samples. In the case of highly distorted images, the inverse distortion correction transformation calculates sparse read address inquiries. Hence, sizable internal memory is required. Interpolation cores in the defective pixel correction and both transformation cores and the inverse transformation compute logic contribute to the high usage of DSP units. Spatial image transformation resources are represented separately as “Transformation” and “Undistortion” measurements to distinguish the amount of logic added by the lens distortion correction unit.
Furthermore, the FPGA easily accommodates the design and supports the maximum clock frequency of 99 MHz. The data transfer rates between the custom RTL design unit and hard processing system are sufficient to ensure the 320 × 240 IR and 1024 × 720 RGB image transfer rate of 30 frames per second, which is the maximum operating speed of the infrared camera.
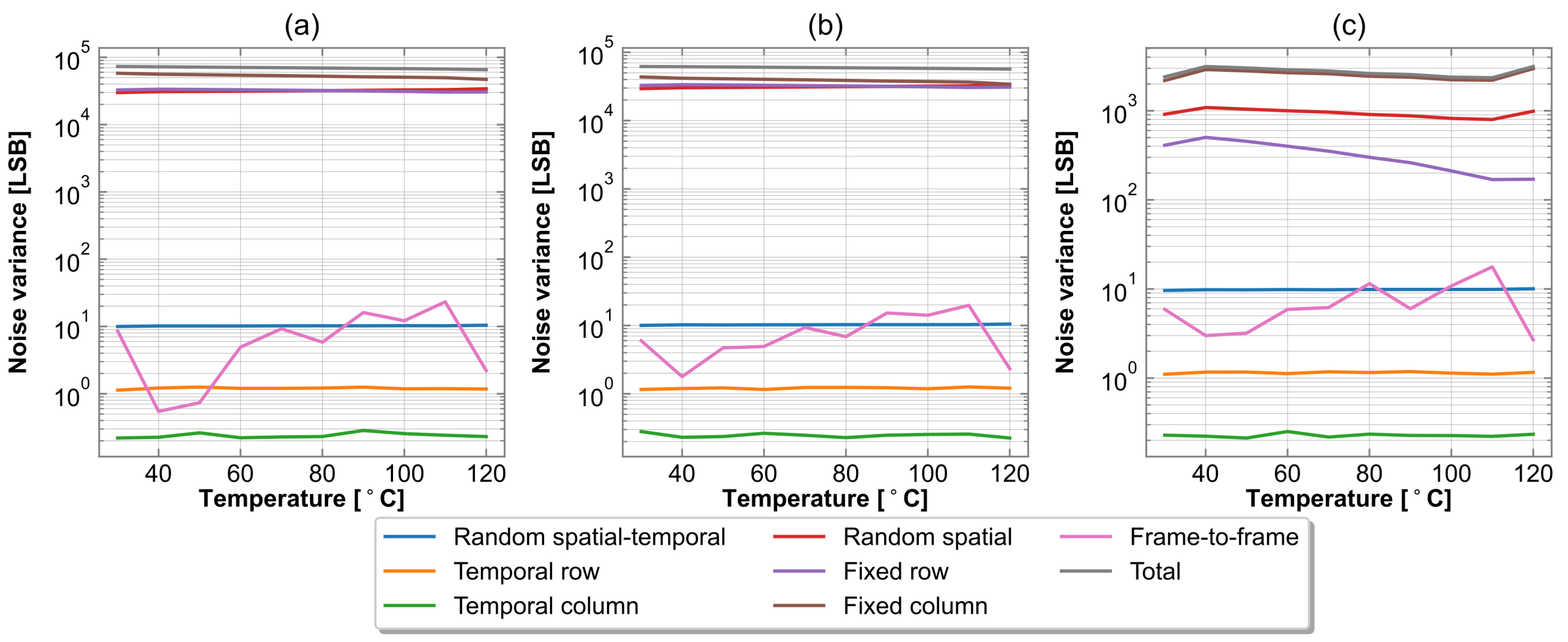
To fully characterize the FPA and the effectiveness of the thermal effect correction algorithms, the 3D-Noise methodology is required [
27]. The method takes a sequence of
t frames with horizontal width
h and vertical height
v and extracts seven orthogonal noise components. Noise components may be static or temporally varying. The noise component measurements are made using a series of directional averaging operators, which extract each noise type and remove that component from the original 3D array. The total measured cube consists of the mean value of the cube and all of the separate noise components:
where
is the mean value of the cube,
are temporally correlated spatial noise components,
are spatially correlated temporal noise components and
is the random spatio-temporal noise. Since the noise components are uncorrelated and independent, the sum of squared variances can be used to estimate the resultant noise variance.
A sequence of 100 frames was acquired while the camera pointed toward a uniform blackbody scene. The temperature of the blackbody was adjusted in the range of 30 to 120 . The 3D-Noise algorithm was applied to extract the noise components from the image array and calculate corresponding variances. The measurement series were repeated, while consecutively enabling correction IPs. In the final experiment, all components were enabled at once.
Figure 10 shows the side-by-side comparison of the variance of the noise components after each of the correction steps. As a baseline, the noise components without any corrections are given in
Figure 10a. The temporally varying noise is visually indistinguishable due to the tendency of the eye to integrate the noise over time; nonetheless, the 3D-Noise analysis reveals that this noise is present. The random spatio-temporal noise
is close to equivalent to thermal resolution defined by noise equivalent temperature difference (NETD). It remains consistent throughout the measurement range reaching the maximum variance of
LSB at 120
. Regardless, the major contribution to the overall noise is the spatially-varying noise components.
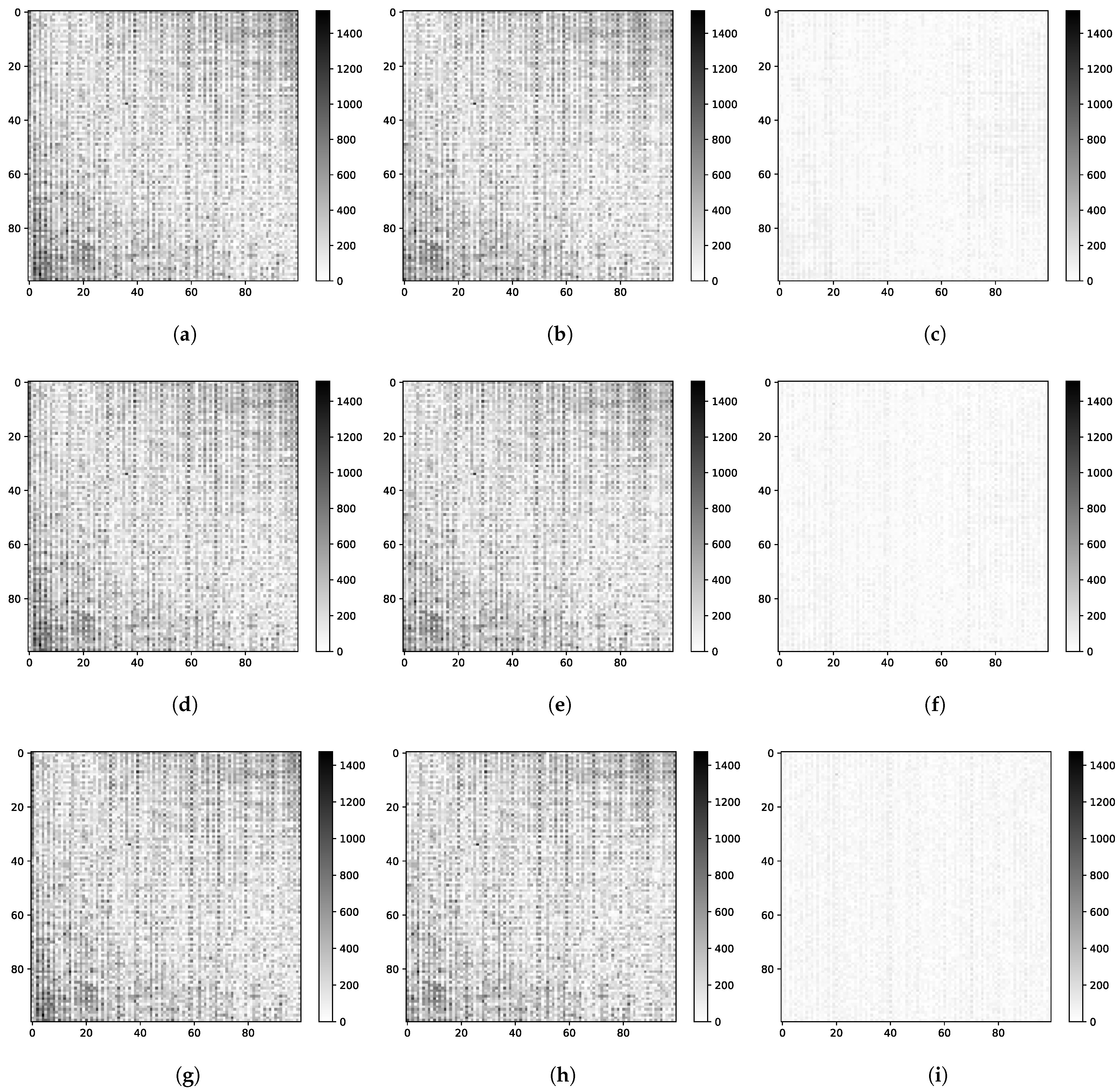
The mean value of the image was calculated and used to find the absolute difference error to emphasise the deviation from the uniform average value:
where
is the time-averaged signal in the VH-plane. Results in
Figure 11 show absolute difference errors in images from the 3D-Noise measurement series before and after each of the corrections at 30
, 70
and 120
. As can be seen from
Figure 11a,b,d, before the correction is applied, variability in pixel sensitivity is clearly visible, especially the fixed pattern noise among the columns. In fact, noise measurements in
Figure 10a confirm that the majority of total noise comes from non-uniform sensitivity in columns. In
Figure 11a, spatial column variance is
LSB from the total variance of
LSB, whereas the spatial row variance is only
LSB.
Figure 11b,e,h depict the infrared image after fixed pattern noise caused by internal temperature variations has been compensated. Variance measurements of spatial noise components reveal that the compensation evenly reduces row, column and random spatial noise components over the measured temperature interval, producing a slightly lower reduction from the total variance of
LSB to
LSB at 120
. Even so, the spatially-varying noise due to uneven detector responsivity remains predominant.
Figure 11c,f,i show the effect of applying the non-uniformity correction. The total variance decreases substantially to
LSB at 30
. The column noise with variance
LSB is still dominant in this case, although it is much less noticeable.
Figure 10c illustrates that the spatial noise levels are mostly reduced in the entire input signal range, while in some measurement intervals, the two-point correction algorithm is not equally effective. At 120
, the combined correction algorithms perform the worst, reaching the total noise variance of
LSB. Computing the maximum ratio of standard deviation to the mean at this point reveals that a 0.35% level of non-uniformity was achieved after FPN correction.
Figure 12a shows a closer inspection of the image captured from the camera while looking at a thermally uniform source. The region includes two defective pixels, which are clearly visible after temperature compensation and non-uniformity correction. The image captured after defective pixel correction is shown
Figure 12b and indicates bilinear interpolation successfully eliminating unresponsive pixels.
As far as we know, this is the only published work encompassing noise correction, geometric transformation, lens distortion correction and image registration in a single FPGA system. Thus, to compare our implementation to other work, we look at closely related solutions, including either one of the processing components. Our implementation in different configurations and existing solutions are summarized in
Table 2. As can be seen, our system with camera control logic, temperature compensation and FPN correction requires more resources than similarly equipped infrared FPA processors. Adding perspective transformation and image undistortion allows observing the impact of these components on the design implementation in comparison to IR/RGB registration in [
28] and lens distortion correction in [
29]. Despite this, the increased size and power of the system are justified since the coordinate transformations are calculated on-the-fly and arbitrary geometric transformations are performed in the programmable logic domain.
The spatial image transformation core is thoroughly evaluated by Novickis et al. [
23] with various practical image manipulations. Contrary to [
21,
28], the module allows mapping one image onto another directly in hardware, while maintaining the native frame rate of the IR camera.
6. Conclusions
The article describes a complete digital circuit design for SoC FPGA-based infrared image acquisition and processing. The system supports data acquisition from a 320 × 240 infrared image sensor and integrates temperature compensation, non-uniformity correction, dead pixel correction cores and spatial image transformation IP cores. The thermal effect pre-processing components ensure correction for different effects related to the infrared bolometer array, whereas the spatial transformation can perform arbitrary geometric transformations. The system encompasses a second image processing branch for images from a 1024 × 720 RGB camera. Data from both cameras are projected onto a common plane utilizing the transformation core and are afterwards used to augment the IR image. The system was implemented on a Xilinx Ultrascale+ XCZU9EG SoC and achieves a maximum throughput of 30 frames per second.
The image processing quality was evaluated using the 3D-Noise method, which separates individual spatial and temporal noise components. Data cubes were captured at different blackbody temperatures to observe any temperature dependence. In the case of the particular system, the spatially-varying noise component was identified as the most significant contribution to the overall noise. The ratio of noise standard deviation to the mean revealed that, at most, a 0.35% level of non-uniformity remains after all FPN correction procedures.
Compared to similar infrared image pre-processing and registration architectures, our work embeds the projective transformation capability directly in the hardware. As such, the system reduces the frame rate restrictions encountered elsewhere. For future research, we intend to employ the proposed system as a low-cost mixed-mode visible and thermal imaging system to produce enhanced infrared images. We plan to use the resulting data with custom perception algorithms for improved object detection.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}