
Research on a Lip Reading Algorithm Based on Efficient-GhostNet
Abstract
:1. Introduction
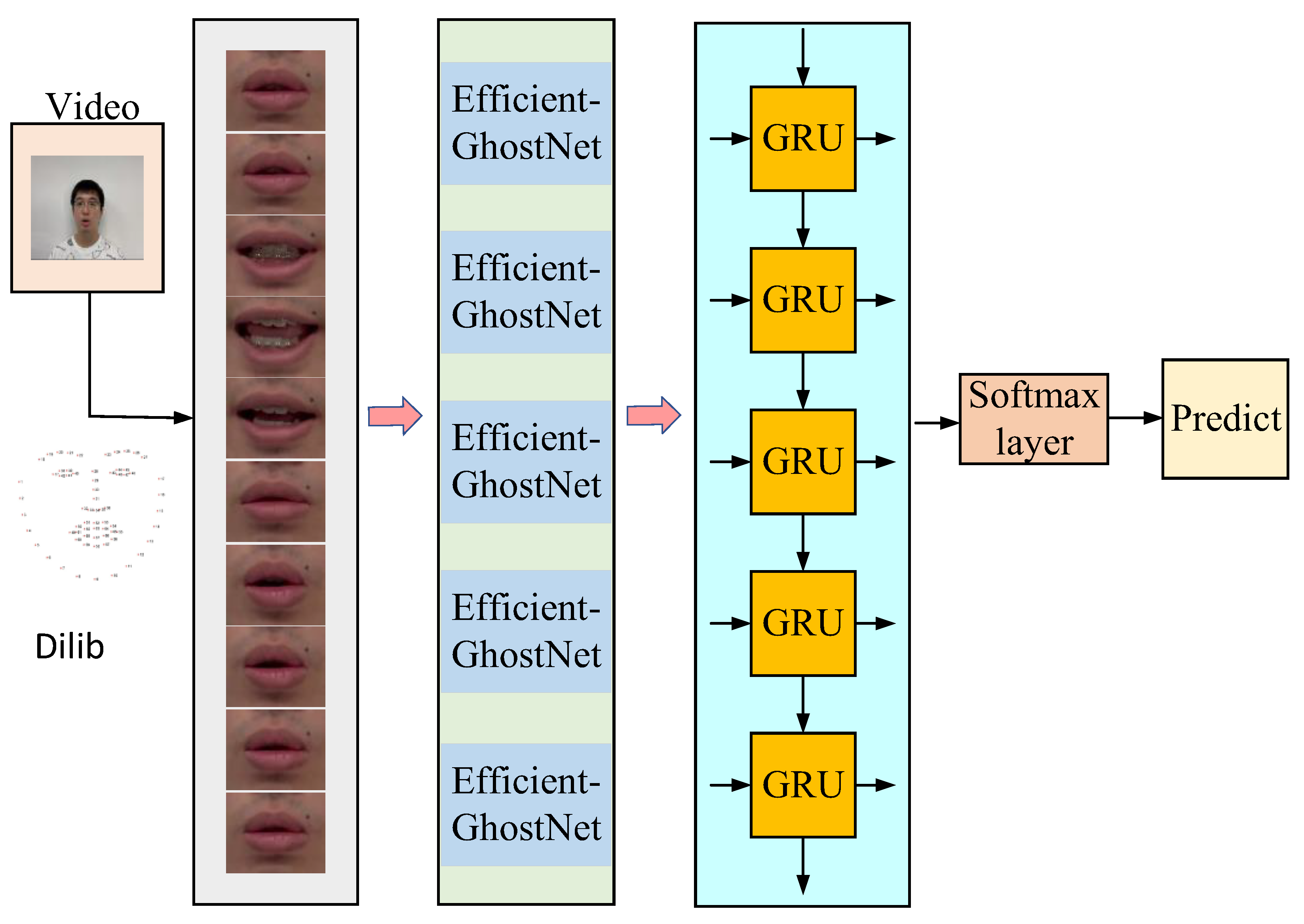
2. Framework
2.1. Image Feature Extraction-GhostNet
2.1.1. Ghost Module
2.1.2. Ghost Bottleneck
2.1.3. Efficient-GhostNet
2.1.4. Efficient Channel Attention
2.2. Gated Recurrent Unit (GRU)
3. Results and Discussion
3.1. Dataset
3.2. Results
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sumby, W.H. Visual Contribution to Speech Intelligibility in Noise. J. Acoust. Soc. Am. 1954, 26, 212–215. [Google Scholar] [CrossRef] [Green Version]
- Kastaniotis, D.; Tsourounis, D.; Koureleas, A.; Peev, B.; Theoharatos, C.; Fotopoulos, S. Lip Reading in Greek words at unconstrained driving scenario. In Proceedings of the 2019 10th International Conference on Information, Intelligence, Systems and Applications (IISA), Patras, Greece, 15–17 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Abrar, M.A.; Islam, A.N.M.N.; Hassan, M.M.; Islam, M.T.; Shahnaz, C.; Fattah, S.A. Deep Lip Reading-A Deep Learning Based Lip-Reading Software for the Hearing Impaired. In Proceedings of the 2019 IEEE R10 Humanitarian Technology Conference (R10-HTC) (47129), Depok, West Java, Indonesia, 12–14 November 2019; pp. 40–44. [Google Scholar] [CrossRef]
- Scanlon, P.; Reilly, R. Feature analysis for automatic speechreading. In Proceedings of the 2001 IEEE Fourth Workshop on Multimedia Signal Processing (Cat. No.01TH8564), Cannes, France, 3–5 October 2001; pp. 625–630. [Google Scholar] [CrossRef]
- Aleksic, P.S.; Katsaggelos, A.K. Comparison of low- and high-level visual features for audio-visual continuous automatic speech recognition. In Proceedings of the 2004 IEEE International Conference on Acoustics, Speech, and Signal Processing, Montreal, QC, Canada, 17–21 May 2004; p. V-917. [Google Scholar] [CrossRef]
- Minotto, V.P.; Lopes, C.B.O.; Scharcanski, J.; Jung, C.R.; Lee, B. Audiovisual Voice Activity Detection Based on Microphone Arrays and Color Information. IEEE J. Sel. Top. Signal Process. 2013, 7, 147–156. [Google Scholar] [CrossRef]
- Assael, Y.M.; Shillingford, B.; Whiteson, S. LipNet: End-to-end sentence-level lipreading. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2016. [Google Scholar] [CrossRef]
- Burton, J.; Frank, D.; Saleh, M.; Navab, N.; Bear, H.L. The speaker-independent lipreading play-off; a survey of lipreading machines. In Proceedings of the 2018 IEEE International Conference on Image Processing, Applications and Systems (IPAS), Sophia Antipolis, France, 12–14 December 2018; pp. 125–130. [Google Scholar] [CrossRef]
- Chen, X.; Du, J.; Zhang, H. Lipreading with DenseNet and resBi-LSTM. Signal Image Video Process. 2020, 14, 981–989. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar] [CrossRef]
- Gabbay, A.; Shamir, A.; Peleg, S. Visual speech enhancement. arXiv 2017, arXiv:1711.08789. [Google Scholar]
- Hou, J.C.; Wang, S.S.; Lai, Y.H.; Tsao, Y.; Chang, H.W.; Wang, H.M. Audio-visual speech enhancement based on multimodal deep convolutional neural network. arXiv 2017, arXiv:1703.10893. [Google Scholar]
- Zhu, D.; Lu, S.; Wang, M.; Lin, J.; Wang, Z. Efficient Precision-Adjustable Architecture for Softmax Function in Deep Learning. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 3382–3386. [Google Scholar] [CrossRef]
- Wang, Z.; Li, C.; Wang, X. Convolutional Neural Network Pruning with Structural Redundancy Reduction. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14908–14917. [Google Scholar] [CrossRef]
- Liang, T.; Glossner, J.; Wang, L.; Shi, S.; Zhang, X. Pruning and quantization for deep neural network acceleration: A survey. Neurocomputing 2021, 461, 370–403. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, B.; Lin, W.; Chen, Y.; Li, K.; Ou, J.; Fan, C. MCCP: Multi-Collaboration Channel Pruning for Model Compression. Neural Process. Lett. 2022. [Google Scholar] [CrossRef]
- Xu, C.; Gao, W.; Li, T.; Bai, N.; Li, G.; Zhang, Y. Teacher-student collaborative knowledge distillation for image classification. Appl. Intel. 2023, 53, 1997–2009. [Google Scholar] [CrossRef]
- Andrew, G.H.; Zhu, M.; Chen, B.; Kalenichenko, D. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.0486. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Wang, L.; Luo, L.; Li, S.; Guo, S.; Wang, S. Bactran: A Hardware Batch Normalization Implementation for CNN Training Engine. IEEE Embed. Syst. Lett. 2021, 13, 29–32. [Google Scholar] [CrossRef]
- Liu, B.; Liang, Y. Optimal function approximation with ReLU neural networks. Neurocomputing 2021, 435, 216–227. [Google Scholar] [CrossRef]
- Boob, D.; Dey, S.S.; Lan, G. Complexity of training ReLU neural network. Discret. Optim. 2022, 44, 100620. [Google Scholar] [CrossRef]
- Miled, M.; Messaoud, M.A.B.; Bouzid, A. Lip reading of words with lip segmentation and deep learning. Multimed Tools Appl 2023, 82, 551–571. [Google Scholar] [CrossRef]
- El-Bialy, R.; Chen, D.; Fenghour, S.; Hussein, W.; Xiao, P.; Karam, O.H.; Li, B. Developing phoneme-based lip-reading sentences system for silent speech recognition. CAAI Trans. Intell. Technol. 2022, 1–10. [Google Scholar] [CrossRef]
- Wand, M.; Schmidhuber, J. Improving Speaker-Independent Lipreading with Domain-Adversarial Training. In Proceedings of the INTERSPEECH 2017, Stockholm, Sweden, 20–24 August 2017; pp. 3662–3666. [Google Scholar] [CrossRef] [Green Version]
- Zhao, G.Y.; Barnard, M.; Pietikäinen, M. Lipreading with local spatiotemporal descriptors. IEEE Trans. Multimed. 2009, 11, 1254–1265. [Google Scholar] [CrossRef]
- Chung, J.S.; Zisserman, A. Lip Reading in the Wild; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef]
- Zeng, D.; Yu, Y.; Oyama, K. Deep Triplet Neural Networks with Cluster-CCA for Audio-Visual Cross-Modal Retrieval. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–23. [Google Scholar] [CrossRef]
- Sato, T.; Sugano, Y.; Sato, Y. Self-Supervised Learning for Audio-Visual Relationships of Videos with Stereo Sounds. IEEE Access 2022, 10, 94273–94284. [Google Scholar] [CrossRef]
- Wand, M.; Koutník, J.; Schmidhuber, J. Lipreading with long short-term memory. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 6115–6119. [Google Scholar]
- Jha, A.; Namboodiri, V.P.; Jawahar, C.V. Word spotting in silent lip videos. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Wand, M.; Schmidhuber, J.; Vu, N.T. Investigations on End-to-End Audiovisual Fusion. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 3041–3045. [Google Scholar]
- Xu, K.; Li, D.; Cassimatis, N.; Wang, X. LCANet: End-to-end lipreading with cascaded attention-CTC. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 548–555. [Google Scholar]
- Liu, J.; Ren, Y.; Zhao, Z.; Zhang, C.; Yuan, J. FastLR: Nonautoregressive lipreading model with integrate-and-fire. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | FLOPs (M) | Top-1 Acc. (%) |
|---|---|---|
| MobileNetV2 0.3× GhostNet 0.5× Efficient-GhostNet 0.5× | 41 42 40 | 54.7 55.6 56.2 |
| MobileNetV2 0.6× GhostNet 1.0× Efficient-GhostNet 1.0× | 141 141 138 | 65.6 66.4 67.8 |
| MobileNetV2 1.0× GhostNet 1.3× Efficient-GhostNet 1.3× | 299 266 251 | 72.4 74.7 76.3 |
| Models | Params./M | Time/s | Acc./% |
|---|---|---|---|
| VGG16 + LSTM | 139 | 16.3 | 91.4 |
| Resnet50 + LSTM | 25 | 5.7 | 87.8 |
| MobileNet + GRU | 5.4 | 3.1 | 88.6 |
| GhostNet + GRU | 5.1 | 2.9 | 88.7 |
| Efficient-GhostNet + GRU | 3.8 | 2.2 | 88.8 |
| MODEL | Recognition Task | Rec. Rate/% |
|---|---|---|
| HOG + SVM [36] | Phrases | 71.2 |
| CNN [37] | Phrases | 64.8 |
| Feed-forward + LSTM [38] | Phrases | 84.7 |
| 3D-CNN + highway + Bi-GRU + attention [39] | Phrases | 97.1 |
| STCNN [40] | Phrases | 95.5 |
| MobileNet + GRU | Phrases | 92.8 |
| Efficient-GhostNet + GRU | Phrases | 94.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Lu, Y. Research on a Lip Reading Algorithm Based on Efficient-GhostNet. Electronics 2023, 12, 1151. https://doi.org/10.3390/electronics12051151
Zhang G, Lu Y. Research on a Lip Reading Algorithm Based on Efficient-GhostNet. Electronics. 2023; 12(5):1151. https://doi.org/10.3390/electronics12051151
Chicago/Turabian StyleZhang, Gaoyan, and Yuanyao Lu. 2023. "Research on a Lip Reading Algorithm Based on Efficient-GhostNet" Electronics 12, no. 5: 1151. https://doi.org/10.3390/electronics12051151