
Techniques and Challenges of Image Segmentation: A Review

 , ,
, , 
Abstract
:1. Introduction
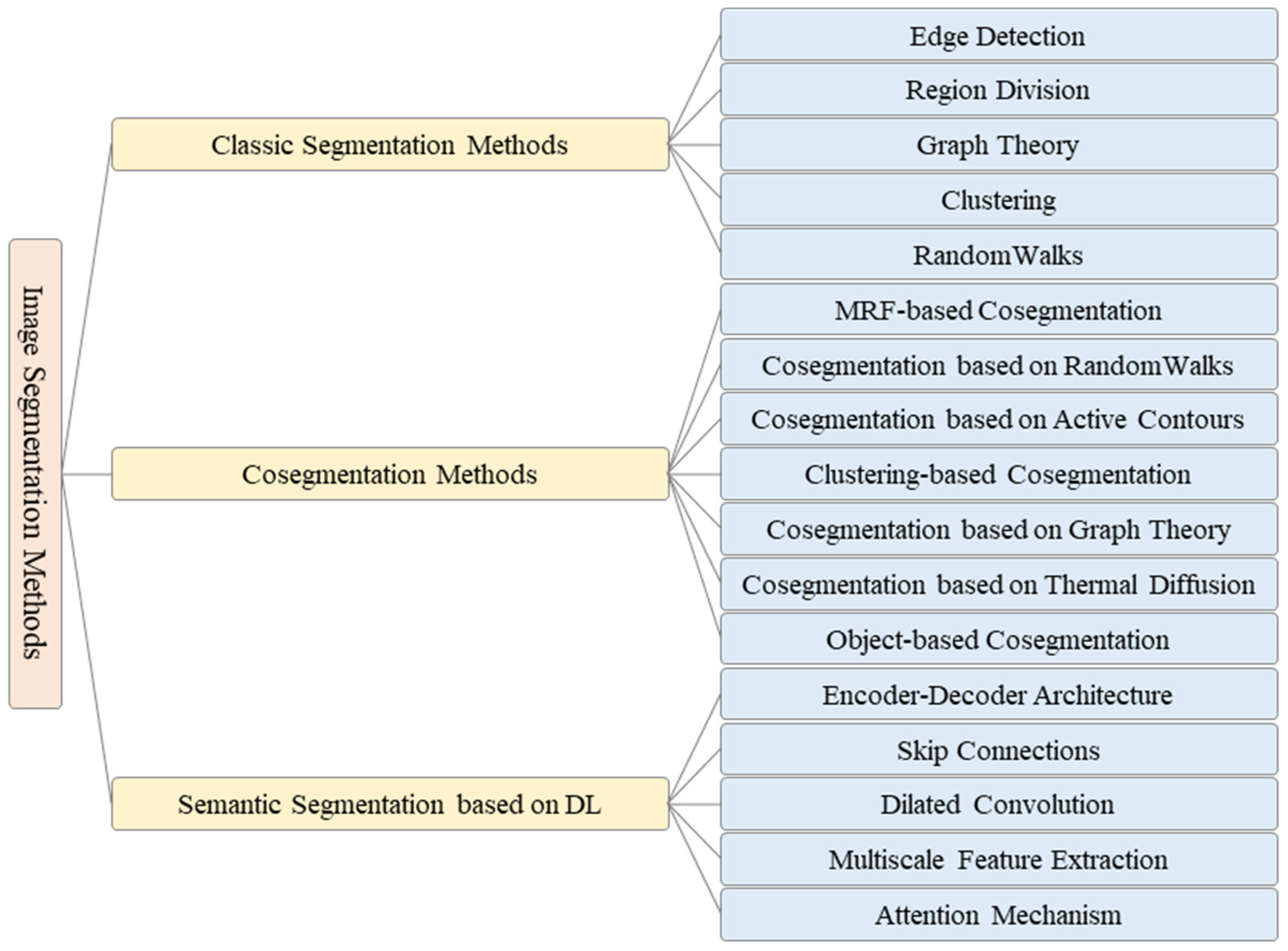
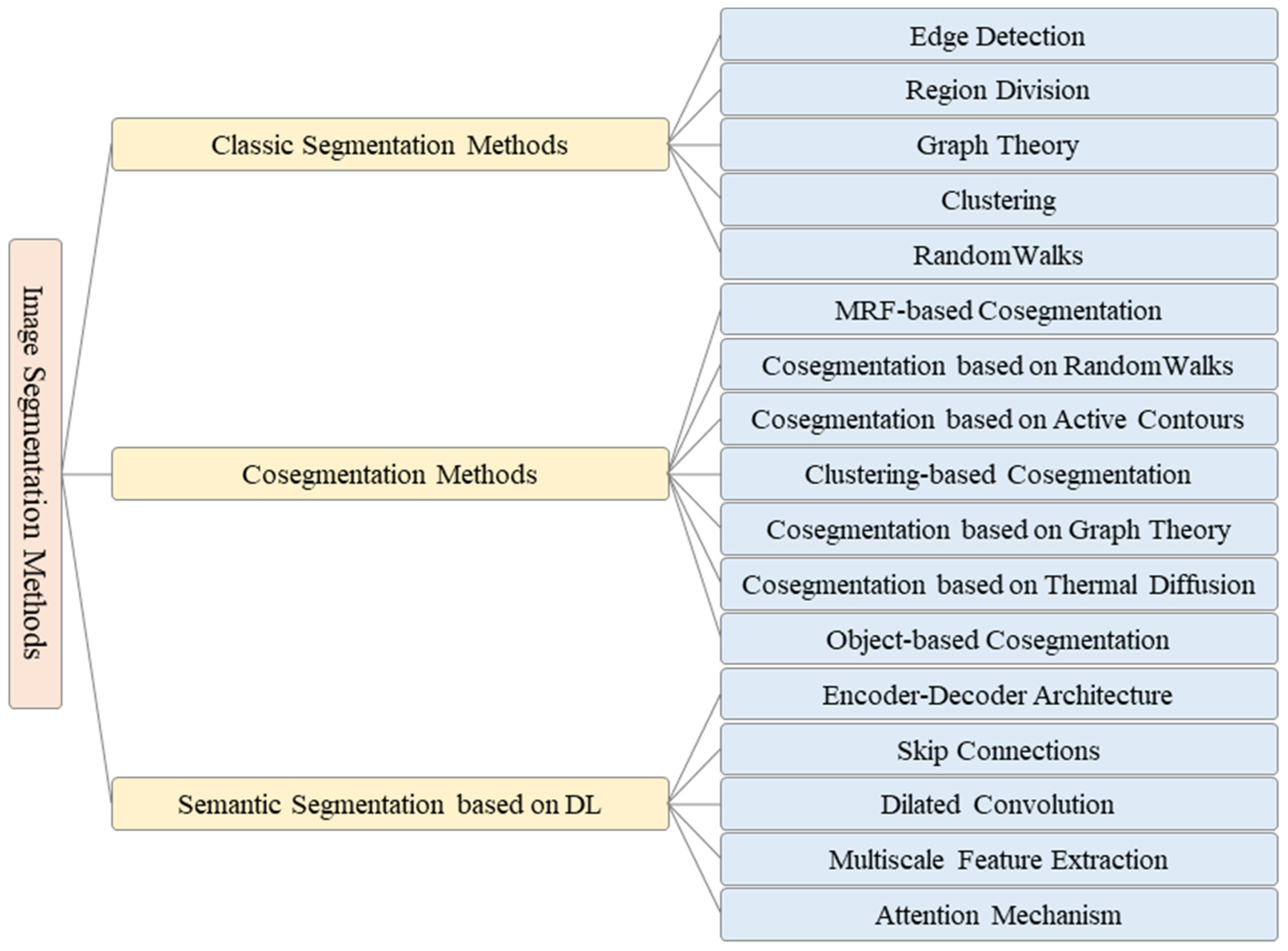
2. Classic Segmentation Methods
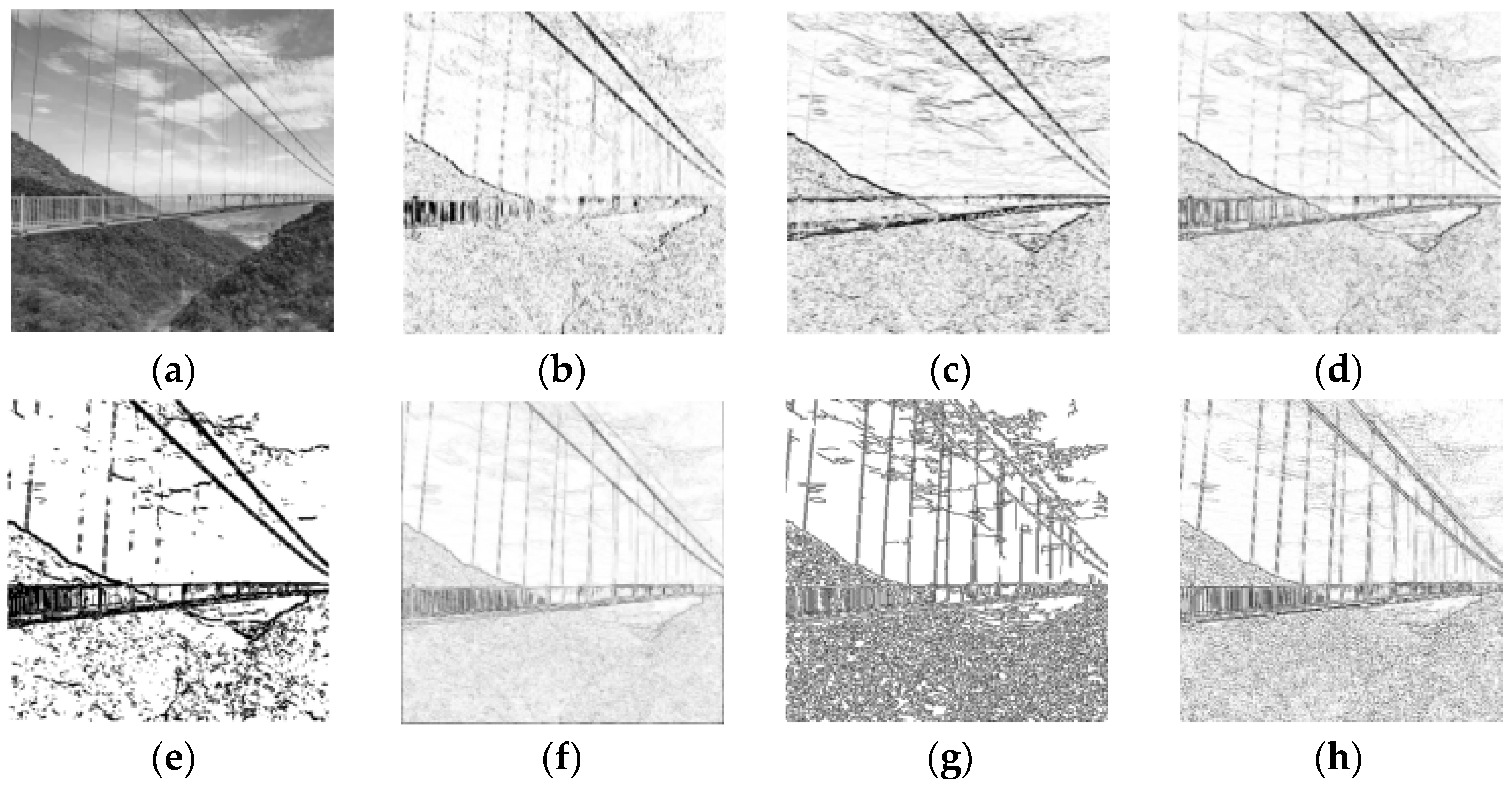
2.1. Edge Detection
2.2. Region Division
2.3. Graph Theory
2.4. Clustering Method
2.5. Random Walks
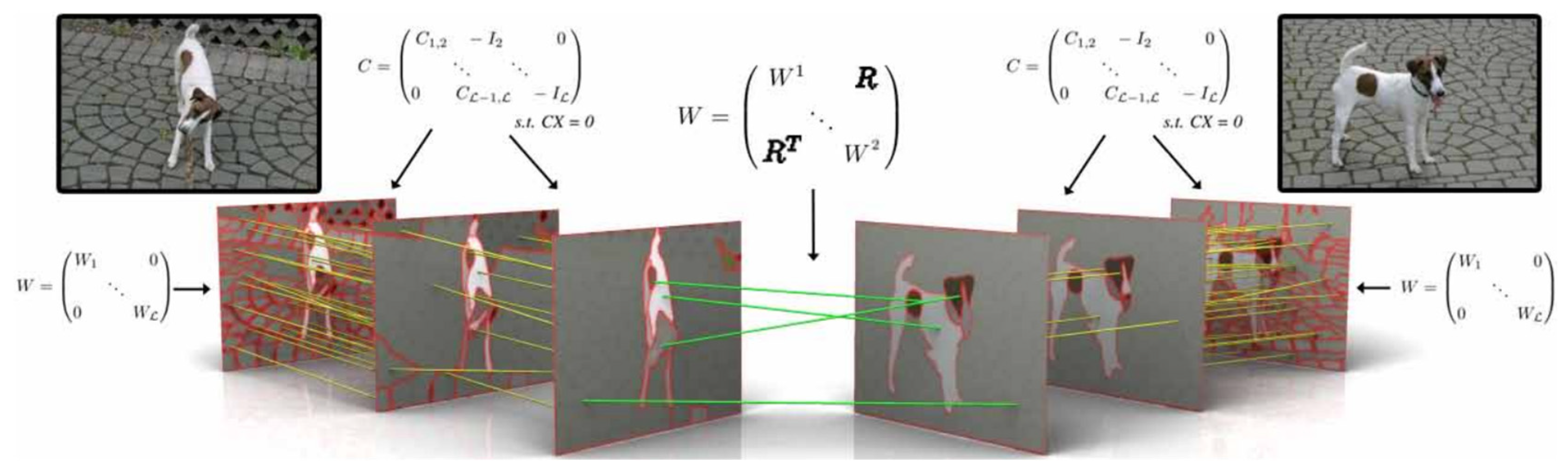
3. Co-Segmentation Methods
3.1. MRF-Based Co-Segmentation
3.2. Co-Segmentation Based on Random Walks
3.3. Co-Segmentation Based on Active Contours
3.4. Clustering-Based Co-Segmentation
3.5. Co-Segmentation Based on Graph Theory
3.6. Co-Segmentation Based on Thermal Diffusion
3.7. Object-Based Co-Segmentation
4. Semantic Segmentation Based on Deep Learning
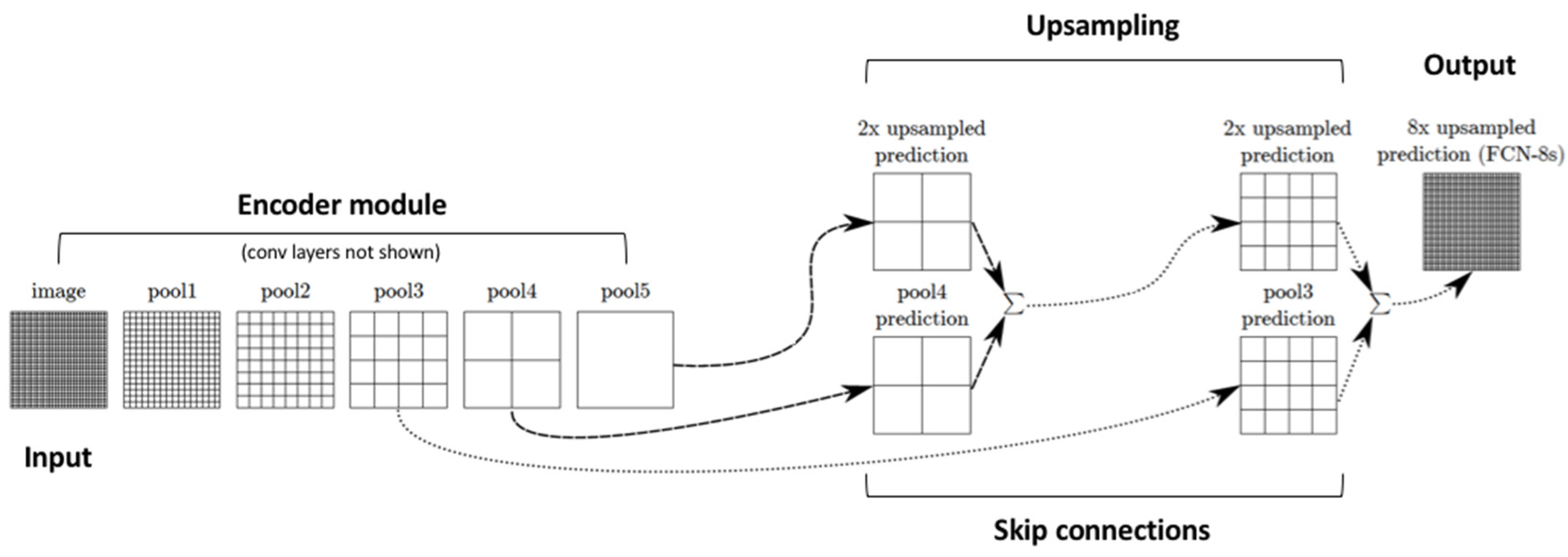
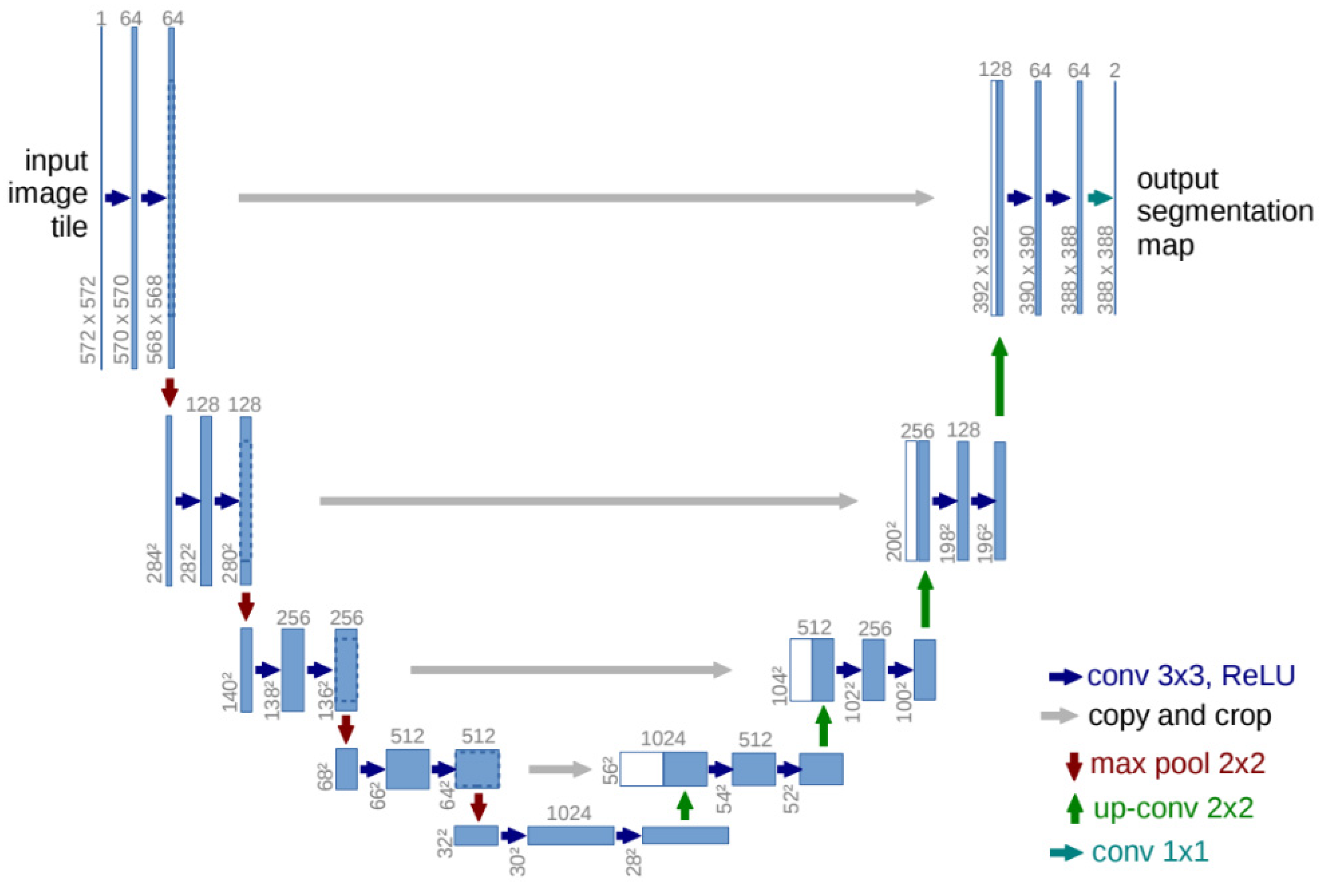
4.1. Encoder–Decoder Architecture
- The interpolation method uses a specified interpolation strategy to insert new elements between the pixels of the original image, thereby expanding the size of the image and achieving the effect of up-sampling. Interpolation does not require training parameters and is often used in early up-sampling tasks;
- The FCN adopts deconvolution for up-sampling. Deconvolution, also known as transposed convolution, reverses the parameters of the original convolution kernel upside down and flipped horizontally, and fills the spaces between and around the elements of the original image;
- SegNet [61] adopts the up-sampling method of unpooling. Unpooling represents the inverse operation of max-pooling in the CNN. During maximum pooling, not only the maximum value of the pooling window, but also the coordinate position of the maximum values should be recorded; in the case of unpooling, the maximum value of this position is activated, and the values in other positions are all set to 0;
- Wang et al. [62] proposed a dense up-sampling convolution (DUC), the core idea of which is to convert the label mapping in the feature map into smaller label mapping with multiple channels. This transformation can be achieved by directly using convolutions between the input feature map and the output label map, without the need to interpolate extra values during the up-sampling process.
4.2. Skip Connections
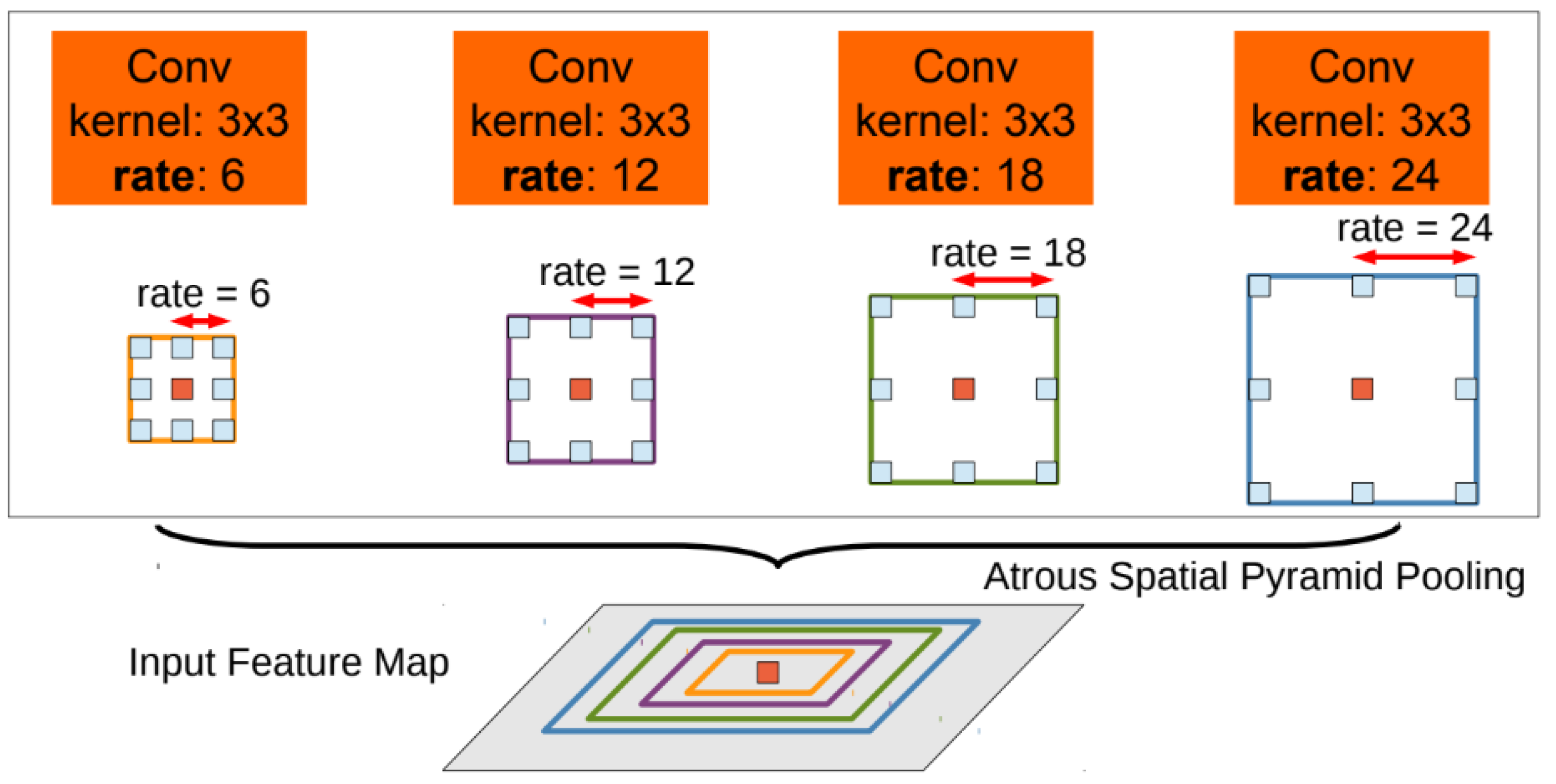
4.3. Dilated Convolution
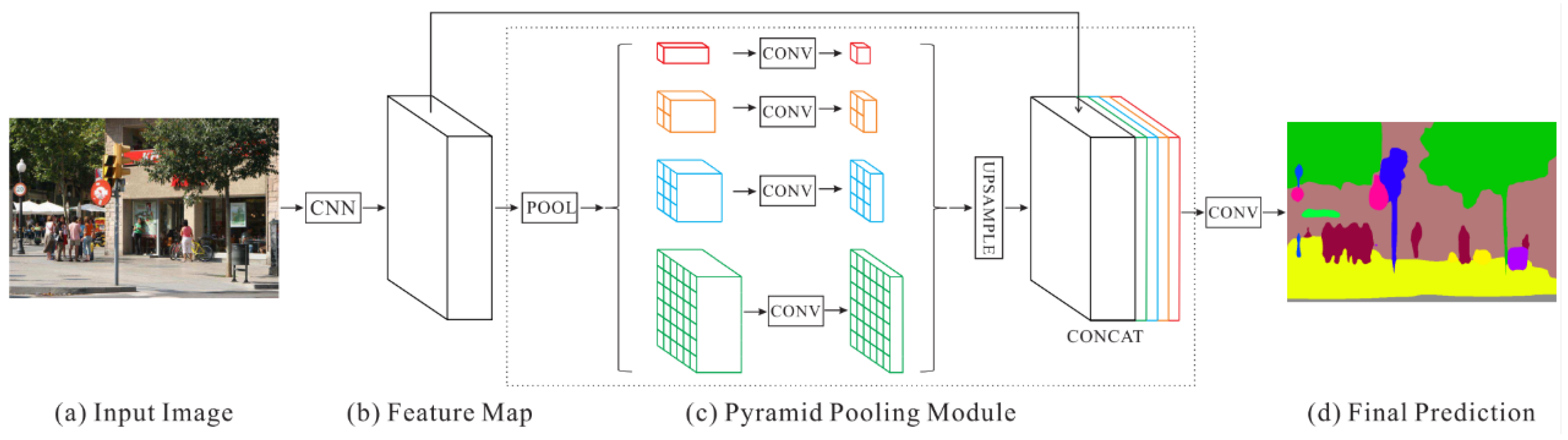
4.4. Multiscale Feature Extraction
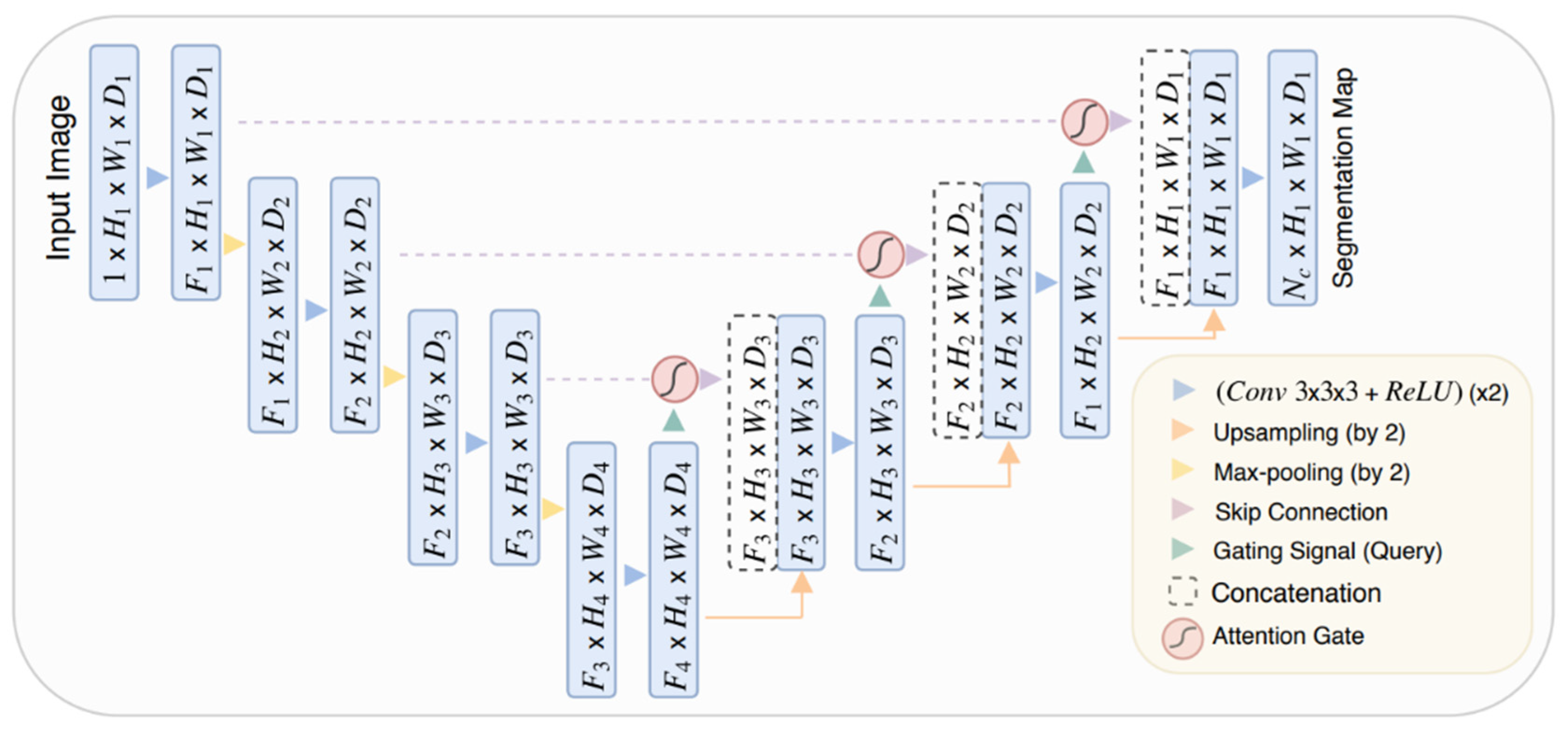
4.5. Attention Mechanisms


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithms | Pub. Year | Backbone | Experiments | Major Contributions | |
|---|---|---|---|---|---|
| Datasets | mIoU (%) | ||||
| FCN [54] | 2015 | VGG-16 | PASCAL VOC 2011 | 62.7 | The forerunner for end-to-end semantic segmentation |
| NYUDv2 | 34.0 | ||||
| U-Net [64] | 2015 | VGG-16 | PhC-U373 | 92.03 | Encoder–decoder structure, skip connections |
| DIC-HeLa | 77.56 | ||||
| SegNet [61] | 2016 | VGG-16 | CamVid | 60.4 | Transferred the max-pooling indices to the decoder |
| SUN RGBD | 28.27 | ||||
| DeepLabv1 [65] | 2016 | VGG-16 | PASCAL VOC 2012 | 71.6 | Atrous convolution, fully connected CRFs |
| MSCA [88] | 2016 | VGG-16 | PASCAL VOC 2012 | 75.3 | Dilated convolutions, multi-scale context aggregation, front-end context module |
| LRR [73] | 2016 | ResNet/VGG-16 | PASCAL VOC 2011 | 77.5 | Reconstruction up-sampling module, Laplacian pyramid refinement |
| Cityscapes | 69.7 | ||||
| ReSeg [79] | 2016 | VGG-16 & ReNet | CamVid | 91.6 | Extension of ReNet to semantic segmentation |
| Oxford Flowers | 93.7 | ||||
| CamVid | 58.8 | ||||
| DRN [70] | 2017 | ResNet-101 | Cityscapes | 70.9 | Modified Conv4/5 of ResNet, dilated convolution |
| PSPNet [72] | 2017 | ResNet50 | PASCAL VOC 2012 | 85.4 | Spatial pyramid pooling (SPP) |
| Cityscapes | 80.2 | ||||
| DeepLab V2 [66] | 2017 | VGG-16/ResNet-101 | PASCAL VOC 2012 | 79.7 | Atrous spatial pyramid pooling (ASPP), fully connected CRFs |
| Cityscapes | 70.4 | ||||
| DeepLab V3 [67] | 2017 | ResNet-101 | PASCAL VOC 2012 | 86.9 | Cascaded or parallel ASPP modules |
| Cityscapes | 81.3 | ||||
| DeepLab V3+ [68] | 2018 | Xception | PASCAL VOC 2012 | 89.0 | A new encoder–decoder structure with DeepLab V3 as an encoder |
| Cityscapes | 82.1 | ||||
| DUC-HDC [62] | 2018 | ResNet-101/ResNet-152 | PASCAL VOC 2012 | 83.1 | HDC (hybrid dilation convolution) was proposed to solve the gridding caused by dilated convolutions |
| Cityscapes | 80.1 | ||||
| Attention U-Net [83] | 2018 | VGG-16 with AGs | multi-class abdominal CT-150 | -- | A novel self-attention gating (AGs) filter, skip connections |
| TCIA Pancreas CT-82 | -- | ||||
| PSANet [85] | 2018 | ResNet-101 | ADE20K | 81.51 | Point-wise spatial attention maps from two parallel branches, bi-direction information propagation model |
| PASCAL VOC 2012 | 85.7 | ||||
| Cityscapes | 81.4 | ||||
| APCNet [75] | 2019 | ResNet-101 | PASCAL VOC 2012 | 84.2 | Multi-scale, global-guided local affinity (GLA), adaptive context modules (ACMs) |
| PASCAL Context | 54.7 | ||||
| ADE20K | 45.38 | ||||
| DANet [86] | 2019 | ResNet-101 | Cityscapes | 81.5 | Dual attention: position attention module and channel attention module |
| PASCAL VOC 2012 | 82.6 | ||||
| PASCAL Context | 52.6 | ||||
| COCO Stuff | 39.7 | ||||
| CARAFE [87] | 2019 | ResNet-50 | ADE20k | 42.23 | Pyramid pooling module (PPM), feature pyramid network (FPN), multi-level feature fusion (FUSE) |
| EFPN [76] | 2021 | VGG-16 | PASCAL VOC 2012 | 86.4 | PPM, multi-scale feature fusion module with a parallel branch |
| Cityscapes | 82.3 | ||||
| PASCAL Context | 53.9 | ||||
| CARAFE++ [88] | 2021 | ResNet-101 | ADE20k | 43.94 | PPM, FPN, FUSE, adaptive kernels on-the-fly |
| Swin Transformer [93] | 2021 | Swin-L | Swin-L | 53.5 | A novel shifted windowing scheme, a general backbone network for computer vision |
| Attention UW-Net [84] | 2022 | ResNet50 | NIH Chest X-ray | -- | Skip connections, an intermediate layer that combines the feature maps of the fourth-layer encoder with the feature maps of the last-layer encoder layer, attention mechanism |
| FPANet [77] | 2022 | ResNet18 | Cityscapes | 75.9 | Bilateral directional FPN, lightweight ASPP, feature pyramid fusion module (FPFM), border refinement module (BRM) |
| CamVid | 74.7 | ||||
5. Conclusions
- Semantic segmentation, instance segmentation, and panoramic segmentation are still the research hotspots of image segmentation. Instance segmentation predicts the pixel regions contained in each instance; panoramic segmentation integrates both semantic segmentation and instance segmentation, and assigns a category label and an instance ID to each pixel of the image. Especially in panoramic segmentation, countable, or uncountable instances are difficult to recognize in a single workflow, so it is a challenging task to build an effective network to simultaneously identify both large inter-category differences and small intra-category differences;
- With the popularization of image acquisition equipment (e.g., LiDAR cameras), RGB-depth, 3D-point clouds, voxels, and mesh segmentation have gradually become research hotspots, which have a wide requirement in face recognition [95], autonomous vehicles, VR, AR, architectural modeling, etc. Although there has been some progress in the research of 3D image segmentation, e.g., region growth, random walks, and clustering in classic algorithms, and SVM, random forest, and AdaBoost in machine learning algorithms, the representation and processing of 3D data, which are unstructured, redundant, disordered, and unevenly distributed, remain a major challenge;
- In some fields, it is difficult to use supervised learning algorithms to train the network due to a lack of datasets or fine-grained annotations. Semi-supervised and unsupervised semantic segmentation can be selected in these cases, where the network can be trained on the benchmark dataset first, and the lower-level parameters of the network can then be fixed, and the fully connected layer or some high-level parameters can be trained on the small-sample dataset. This is transfer learning, that does not require abundant labeled samples. Reinforcement learning is also a possible solution, but it is rarely studied in the field of image segmentation. In addition, few-shot image semantic segmentation is also a hot research direction;
- Deep learning networks require a significant amount of computing resources in the training process, that also illustrates the computational complexity of the deep neural network. Real-time (or near real-time) segmentation is required in many fields, e.g., video processing to meet the human vision mechanism of at least 25 fps, and most current networks are far below this frame rate. Some lightweight networks have improved the speed of the segmentation to a certain extent, but there is still a large amount of room for improvement in the balance of model accuracy and real-time performance.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anwesh, K.; Pal, D.; Ganguly, D.; Chatterjee, K.; Roy, S. Number plate recognition from enhanced super-resolution using generative adversarial network. Multimed. Tools Appl. 2022, 1–17. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Deep Facial Diagnosis: Deep Transfer Learning from Face Recognition to Facial Diagnosis. IEEE Access 2020, 8, 123649–123661. [Google Scholar] [CrossRef]
- Zhao, M.; Liu, Q.; Jha, R.; Deng, R.; Yao, T.; Mahadevan-Jansen, A.; Tyska, M.J.; Millis, B.A.; Huo, Y. VoxelEmbed: 3D Instance Segmentation and Tracking with Voxel Embedding based Deep Learning. In Proceedings of the International Workshop on Machine Learning in Medical Imaging, Strasbourg, France, 27 September 2021; Volume 12966, pp. 437–446. [Google Scholar] [CrossRef]
- Yao, T.; Qu, C.; Liu, Q.; Deng, R.; Tian, Y.; Xu, J.; Jha, A.; Bao, S.; Zhao, M.; Fogo, A.B.; et al. Compound Figure Separation of Biomedical Images with Side Loss. In Proceedings of the Deep Generative Models, and Data Augmentation, Labelling, and Imperfections, Strasbourg, France, 1 October 2021; Volume 13003, pp. 173–183. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.; Porikli, F.; Plaza, A.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Yao, Q.A.; Zhao, J.; Jin, Z.J.; Feng, Y.C. Image Semantic Segmentation Based on Fully Convolutional Neural Network. Comput. Eng. Appl. 2022, 44, 45–57. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Wu, W.; Liu, T. A Survey of Evaluation Metrics and Methods for Semantic Segmentation. Comput. Eng. Appl. 2023; online preprint. [Google Scholar]
- Lankton, S.; Tannenbaum, A. Localizing Region-Based Active Contours. IEEE Trans. Image Process. 2008, 17, 2029–2039. [Google Scholar] [CrossRef] [Green Version]
- Freedman, D.; Tao, Z. Interactive Graph Cut based Segmentation with Shape Priors. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 755–762. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Huttenlocher, D.P. Efficient Graph-Based Image Segmentation. Int. J. Comput. Vis. 2004, 59, 167–181. [Google Scholar] [CrossRef]
- Leordeanu, M.; Hebert, M. A Spectral Technique for Correspondence Problems using Pairwise Constraints. In Proceedings of the 10th IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 2, pp. 1482–1489. [Google Scholar] [CrossRef] [Green Version]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach Toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef] [Green Version]
- Chuang, K.S.; Tzeng, H.L.; Chen, S.; Wu, J.; Chen, T.J. Fuzzy C-means Clustering with Spatial Information for Image Segmentation. Comput. Med. Imaging Graph. Off. J. Comput. Med. Imaging Soc. 2006, 30, 9–15. [Google Scholar] [CrossRef] [Green Version]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Su-perpixel Method. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Chen, J. Superpixel Segmentation using Linear Spectral Clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1356–1363. [Google Scholar] [CrossRef]
- Pan, W.; Lu, X.Q.; Gong, Y.H.; Tang, W.M.; Liu, J.; He, Y.; Qiu, G.P. HLO: Half-kernel Laplacian Operator for Sur-face Smoothing. Comput. Aided Des. 2020, 121, 102807. [Google Scholar] [CrossRef] [Green Version]
- Chen, H.B.; Zhen, X.; Gu, X.J.; Yan, H.; Cervino, L.; Xiao, Y.; Zhou, L.H. SPARSE: Seed Point Auto-Generation for Random Walks Segmentation Enhancement in medical inhomogeneous targets delineation of morphological MR and CT images. J. Appl. Clin. Med. Phys. 2015, 16, 387–402. [Google Scholar] [CrossRef] [PubMed]
- Drouyer, S.; Beucher, S.; Bilodeau, M.; Moreaud, M.; Sorbier, L. Sparse Stereo Disparity Map Densification using Hierarchical Image Segmentation. In Mathematical Morphology and Its Applications to Signal and Image Processing; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; Volume 1022. [Google Scholar] [CrossRef]
- Grady, L. Random Walks for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1768–1783. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, W.; Cai, J.; Zheng, J.; Luo, J. User-Friendly Interactive Image Segmentation Through Unified Combinatorial User Inputs. IEEE Trans. Image Process. 2010, 19, 2470–2479. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.K.; Hu, S.M.; Martin, R.R.; Rosin, P.L. Fast Mesh Segmentation using Random Walks. In Proceedings of the 2008 ACM Symposium on Solid and Physical Modeling, New York, NY, USA, 2 June 2008; pp. 183–191. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Wu, C.; Cai, J.; Zheng, J.; Tai, X. Mesh Snapping: Robust Interactive Mesh Cutting using Fast Geodesic Curvature Flow. Comput. Graph. Forum 2010, 29, 517–526. [Google Scholar] [CrossRef]
- Rother, C.; Minka, T.P.; Blake, A.; Kolmogorov, V. Cosegmentation of Image Pairs by Histogram Matching—Incorporating a Global Constraint into MRFs. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 993–1000. [Google Scholar] [CrossRef]
- Vicente, S.; Kolmogorov, V.; Rother, C. Cosegmentation Revisited: Models and Optimization. Lecture Notes in Computer Science. In Proceedings of the Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 465–479. [Google Scholar] [CrossRef] [Green Version]
- Mukherjee, L.; Singh, V.; Dyer, C.R. Half-integrality-based Algorithms for Cosegmentation of Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2028–2035. [Google Scholar] [CrossRef]
- Hochbaum, D.S.; Singh, V. An Efficient Algorithm for Co-segmentation. In Proceedings of the 12th IEEE International Con-ference on Computer Vision (ICCV), Kyoto, Japan, 29 September–2 October 2009; pp. 269–276. [Google Scholar] [CrossRef] [Green Version]
- Rubio, J.C.; Serrat, J.; López, A.; Paragios, N. Unsupervised Co-segmentation through Region Matching. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 749–756. [Google Scholar] [CrossRef]
- Chang, K.; Liu, T.; Lai, S. From Co-saliency to Co-segmentation: An Efficient and Fully Unsupervised Energy Minimization Model. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 2129–2136. [Google Scholar] [CrossRef] [Green Version]
- Yu, H.; Xian, M.; Qi, X. Unsupervised Co-segmentation based on a New Global GMM Constraint in MRF. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 4412–4416. [Google Scholar] [CrossRef]
- Wang, C.; Guo, Y.; Zhu, J.; Wang, L.; Wang, L. Video Object Co-Segmentation via Subspace Clustering and Quadratic Pseudo-Boolean Optimization in an MRF Framework. IEEE Trans. Multimed. 2014, 16, 903–916. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, L.; Gao, J.; Yang, R. Spatial-Temporal Fusion for High Accuracy Depth Maps using Dynamic MRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 899–909. [Google Scholar] [CrossRef]
- Collins, M.D.; Xu, J.; Grady, L.; Singh, V. Random Walks based Multi-image Segmentation: Quasiconvexity Results and GPU-based Solutions. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1656–1663. [Google Scholar] [CrossRef] [Green Version]
- Fabijanska, A.; Goclawski, J. The Segmentation of 3D Images using the Random Walking Technique on a Randomly Created Image Adjacency Graph. IEEE Trans. Image Process. 2015, 24, 524–537. [Google Scholar] [CrossRef]
- Dong, X.P.; Shen, J.B.; Shao, L.; Gool, L.V. Sub-Markov Random Walk for Image Segmentation. IEEE Trans. Image Process. 2016, 25, 516–527. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Wang, W.M.; Zhang, J.; Yin, B.C.; Liu, X.P. 3D shape segmentation using multiple random walkers. J. Comput. Appl. Math. 2018, 329, 353–363. [Google Scholar] [CrossRef]
- Dong, C.; Zeng, X.; Lin, L.; Hu, H.; Han, X.; Naghedolfeizi, M.; Aberra, D.; Chen, Y.W. An Improved Random Walker with Bayes Model for Volumetric Medical Image Segmentation. J. Healthc. Eng. 2017, 2017, 6506049. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meng, F.; Li, H.; Liu, G. Image Co-segmentation via Active Contours. In Proceedings of the 2012 IEEE International Symposium on Circuits and Systems (ISCAS), Seoul, Republic of Korea, 20–23 May 2012; pp. 2773–2776. [Google Scholar] [CrossRef]
- Zhang, T.; Xia, Y.; Feng, D.D. A Deformable Cosegmentation Algorithm for Brain MR Images. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 3215–3218. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, X.; Soomro, N.Q.; Abou-El-Hossein, K. An Efficient Image Co-segmentation Algorithm based on Active Contour and Image Saliency. In Proceedings of the 2016 7th International Conference on Mechanical, Industrial, and Manufacturing Technologies (MIMT 2016), Cape Town, South Africa, 1–3 February 2016; Volume 54, p. 08004. [Google Scholar] [CrossRef] [Green Version]
- Joulin, A.; Bach, F.; Ponce, J. Discriminative Clustering for Image Co-segmentation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 1943–1950. [Google Scholar] [CrossRef] [Green Version]
- Kim, E.; Li, H.; Huang, X. A Hierarchical Image Clustering Cosegmentation Framework. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 686–693. [Google Scholar] [CrossRef]
- Joulin, A.; Bach, F.; Ponce, J. Multi-class Cosegmentation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 542–549. [Google Scholar] [CrossRef]
- Meng, F.; Li, H.; Liu, G.; Ngan, K.N. Object Co-Segmentation Based on Shortest Path Algorithm and Saliency Model. IEEE Trans. Multimed. 2012, 14, 1429–1441. [Google Scholar] [CrossRef]
- Meng, F.M.; Li, H.; Liu, G.H. A New Co-saliency Model via Pairwise Constraint Graph Matching. In Proceedings of the International Symposium on Intelligent Signal Processing and Communications Systems, Tamsui, Taiwan, 4–7 November 2012; IEEE Computer Society Press: Los Alamitos, CA, USA, 2012; pp. 781–786. [Google Scholar] [CrossRef]
- Kim, G.; Xing, E.P.; Li, F.F.; Kanade, T. Distributed Cosegmentation via Submodular Optimization on Anisotropic Diffusion. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 169–176. [Google Scholar] [CrossRef]
- Kim, G.; Xing, E.P. On Multiple Foreground Cosegmentation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 837–844. [Google Scholar] [CrossRef]
- Alexe, B.; Deselaers, T.; Ferrari, V. What Is an Object? In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 73–80. [Google Scholar] [CrossRef]
- Vicente, S.; Rother, C.; Kolmogorov, V. Object cosegmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar] [CrossRef]
- Meng, F.; Cai, J.; Li, H. Cosegmentation of Multiple Image Groups. Comput. Vis. Image Underst. 2016, 146, 67–76. [Google Scholar] [CrossRef]
- Johnson, M.; Shotton, J.; Cipolla, R. Semantic Texton Forests for Image Categorization and Segmentation. In Decision Forests for Computer Vision and Medical Image Analysis, Advances in Computer Vision and Pattern Recognition; Criminisi, A., Shotton, J., Eds.; Springer: London, UK, 2013. [Google Scholar] [CrossRef] [Green Version]
- Lindner, C.; Thiagarajah, S.; Wilkinson, J.M.; The arcOGEN Consortium; Wallis, G.A.; Cootes, T.F. Fully Automatic Segmentation of the Proximal Femur using Random Forest Regression Voting. IEEE Trans. Med. Imaging 2013, 32, 1462–1472. [Google Scholar] [CrossRef]
- Li, H.S.; Zhao, R.; Wang, X.G. Highly Efficient Forward and Backward Propagation of Convolutional Neural Networks for Pixelwise Classification. arXiv 2014, arXiv:1412.4526. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Karen, S.; Andrew, Z. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Visio. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Seg-mentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.H.; Hou, X.D.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2017, arXiv:1606.00915. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Proceeding of the European conference on computer vision (ECCV). arXiv 2018, arXiv:1802.02611. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V.; Funkhouser, T. Dilated Residual Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 636–644. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Jia, J.Y. Pyramid Scene Parsing Network. arXiv 2017, arXiv:1612.01105v2. [Google Scholar] [CrossRef]
- Ghiasi, G.; Fowlkes, C. Laplacian Pyramid Reconstruction and Refinement for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. 32. [Google Scholar]
- He, J.; Deng, Z.; Zhou, L.; Wang, Y.; Qiao, Y. Adaptive Pyramid Context Network for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7511–7520. [Google Scholar] [CrossRef]
- Ye, M.; Ouyang, J.; Chen, G.; Zhang, J.; Yu, X. Enhanced Feature Pyramid Network for Semantic Segmentation. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 3209–3216. [Google Scholar] [CrossRef]
- Wu, Y.; Jiang, J.; Huang, Z.; Tian, Y. FPANet: Feature pyramid aggregation network for real-time semantic segmentation. Appl. Intell. 2022, 52, 3319–3336. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent Models of Visual Attention. In Proceedings of the 27th International Conference on Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; Volume 2, pp. 2204–2212. [Google Scholar]
- Visin, F.; Romero, A.; Cho, K.; Matteucci, M.; Ciccone, M.; Kastner, K.; Bengio, Y.; Courville, A. ReSeg: A Recurrent Neural Network-Based Model for Semantic Segmentation. arXiv 2015, arXiv:1511.07053. [Google Scholar]
- Visin, F.; Kastner, K.; Cho, K.; Matteucci, M.; Courville, A.; Bengio, Y. ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks. arXiv 2015, arXiv:1505.00393. [Google Scholar]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene labeling with LSTM recurrent neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3547–3555. [Google Scholar] [CrossRef]
- Liang, X.; Shen, X.; Feng, J.; Lin, L.; Yan, S. Semantic Object Parsing with Graph LSTM. In Computer Vision—ECCV 2016, Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar] [CrossRef] [Green Version]
- Oktay, O.; Schlemper, J.; Folgoc, L.; Lee, M.; Heinrich, M.P.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.; Kainz, B.; et al. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Pal, D.; Reddy, P.B.; Roy, S. Attention UW-Net: A fully connected model for automatic segmentation and annotation of chest X-ray. Comput. Biol. Med. 2022, 150, 106083. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-wise Spatial Attention Network for Scene Parsing. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [CrossRef] [Green Version]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE++: Unified Content-Aware ReAssembly of FEatures. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4674–4687. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Weissenborn, D.; Täckström, O.; Uszkoreit, J. Scaling Autoregressive Video Models. arXiv 2020, arXiv:1906.02634. [Google Scholar]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the Relationship between Self-Attention and Convolutional Layers. arXiv 2020, arXiv:1911.03584. [Google Scholar]
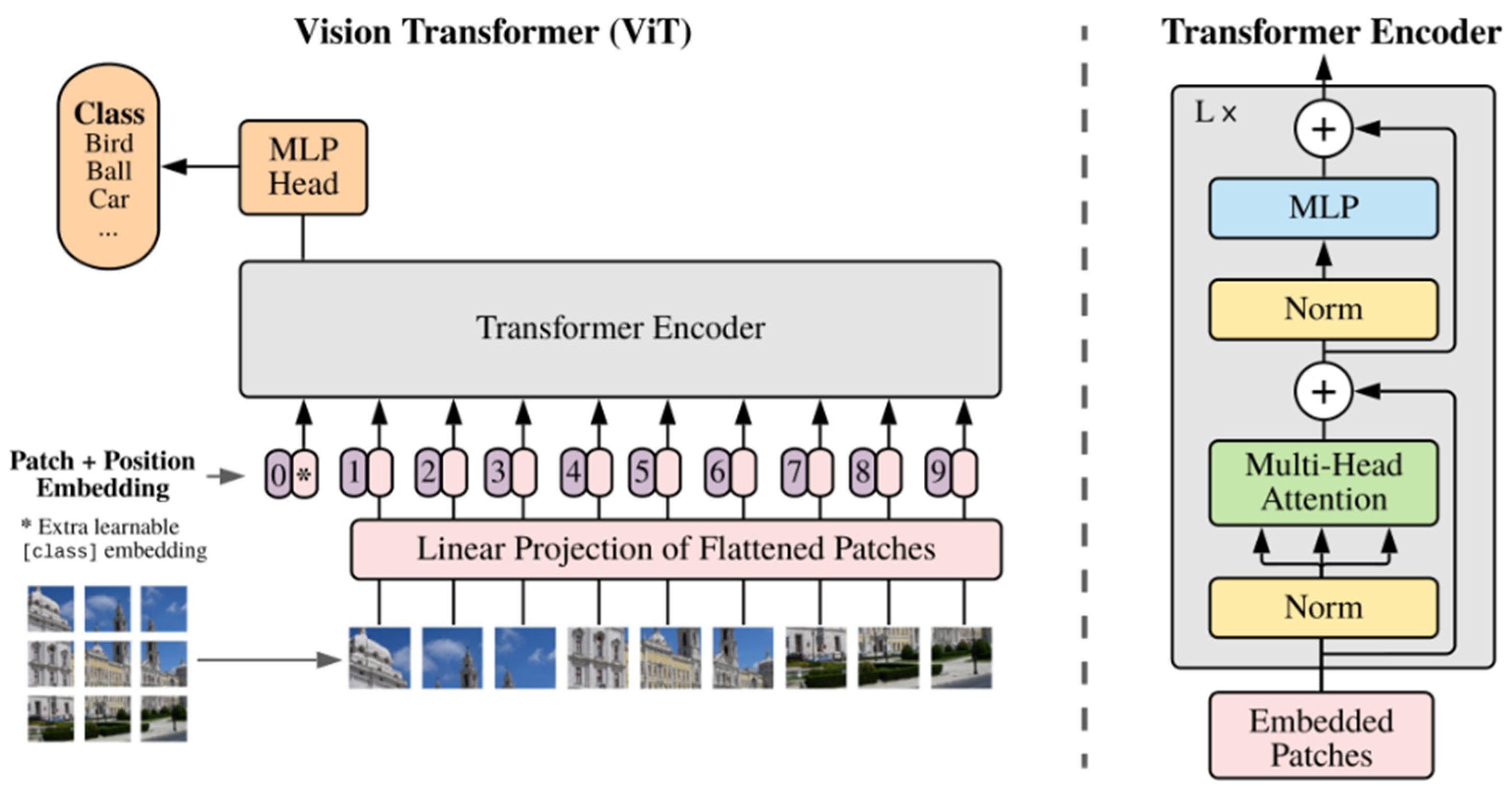
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar] [CrossRef]
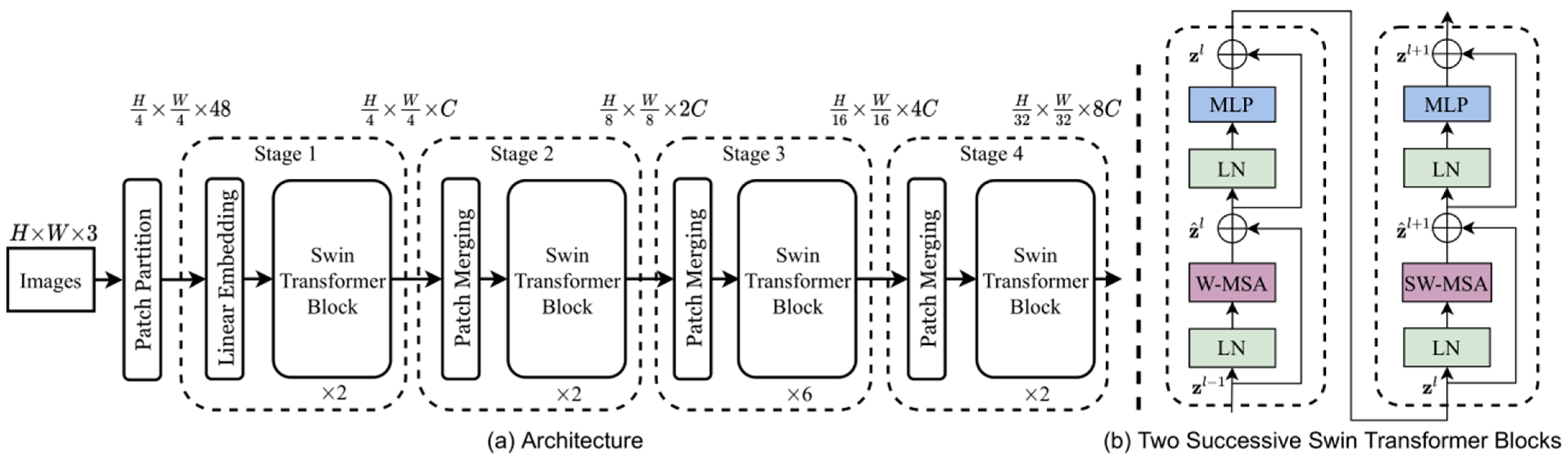
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Zheng, Q.; Yang, M.; Yang, J.; Zhang, Q.; Zhang, X. Improvement of Generalization Ability of Deep CNN via Implicit Regularization in Two-Stage Training Process. IEEE Access 2018, 6, 15844–15869. [Google Scholar] [CrossRef]
- Jin, B.; Cruz, L.; Gonçalves, N. Pseudo RGB-D Face Recognition. IEEE Sens. J. 2022, 22, 21780–21794. [Google Scholar] [CrossRef]












| Methods | Ref. | Foreground Feature | Co-Information | Optimization |
|---|---|---|---|---|
| MRF-Based Co-Segmentation | [24] | color histogram | norm | graph cuts |
| [26] | color histogram | norm | quadratic pseudo-Boolean | |
| [27] | color and texture histograms | reward model | maximum flow | |
| [25] | color histogram | Boykov–Jolly model | dual decomposition | |
| [46] | color and SIFT features | region matching | graph cuts | |
| [29] | SIFT feature | K-means + | graph cuts | |
| [48] | SIFT feature | Gaussian mixture model (GMM) constraint | graph cuts | |
| Co-Segmentation Based on Random Walks | [33] | color and texture histograms | improved random walk global term | gradient projection and conjugate gradient (GPCG) |
| [34] | intensity and gray difference | improved random walk global term | graph size reduction | |
| [35] | label prior from user scribbles | GMMs | minimize the average reaching probability | |
| Co-Segmentation Based on Active Contours | [38] | color histogram | reward model | level set function |
| [39] | co-registered atlas and statistical features | k-means | level set function | |
| [40] | saliency information | improved Chan–Vese (C-V) model | level set function | |
| Clustering-Based Co-Segmentation | [41] | SIFT, Gabor filter, color histogram | Chi-square distance | low-rank |
| [43] | color and location information | discriminant clustering | expectation maximization (EM) | |
| [42] | pyramid of LAB colors, HOG textures, SURF features histogram | hierarchical clustering | normalized cut criterion | |
| Co-Segmentation based on Graph Theory | [44] | color histogram | built digraphs according to region similarity and saliency | shortest path |
| [45] | color and shape information | build global items based on digraphs and saliency | shortest path | |
| Co-Segmentation Based on Thermal Diffusion | [46] | lab space color and texture information | Gaussian consistency | Sub-modularity optimization |
| [47] | color and texture histograms | GMM & SPM (spatial pyramid matching) | dynamic programming | |
| Object-Based Co-Segmentation | [48] | multi-scale saliency, color contrast, edge density and superpixels straddling | Bayesian framework | maximizing the posterior probability |
| [49] | 33 types of features | random forest classifier | A-star search algorithm |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and Challenges of Image Segmentation: A Review. Electronics 2023, 12, 1199. https://doi.org/10.3390/electronics12051199
Yu Y, Wang C, Fu Q, Kou R, Huang F, Yang B, Yang T, Gao M. Techniques and Challenges of Image Segmentation: A Review. Electronics. 2023; 12(5):1199. https://doi.org/10.3390/electronics12051199
Chicago/Turabian StyleYu, Ying, Chunping Wang, Qiang Fu, Renke Kou, Fuyu Huang, Boxiong Yang, Tingting Yang, and Mingliang Gao. 2023. "Techniques and Challenges of Image Segmentation: A Review" Electronics 12, no. 5: 1199. https://doi.org/10.3390/electronics12051199