
A Multi-Modal Story Generation Framework with AI-Driven Storyline Guidance


Abstract
:1. Introduction
2. Related Work
2.1. Neural Story Generation
2.2. Controllable Story Generation
2.3. Story Visualization
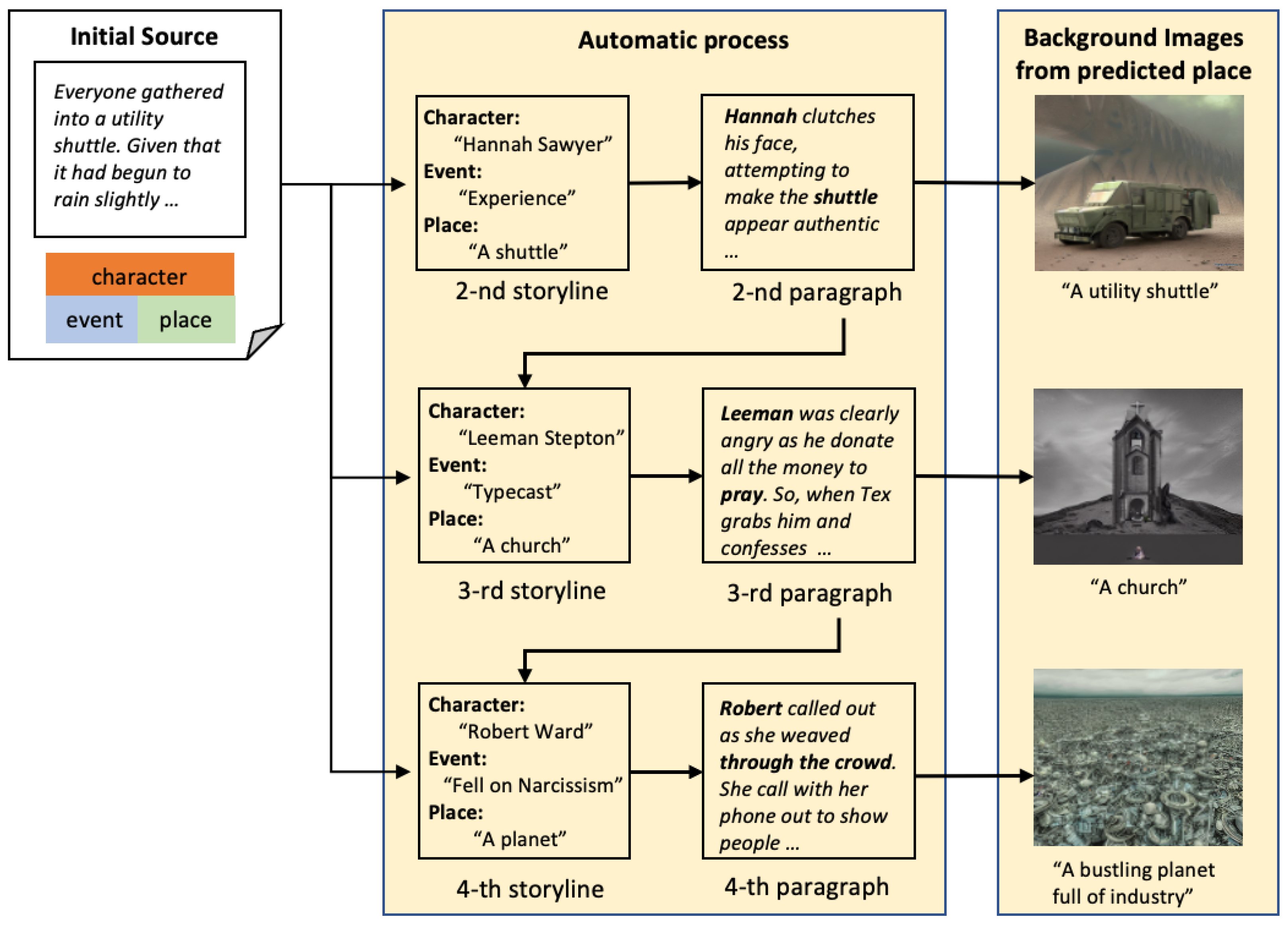
3. Methods
3.1. Task Definition and Our Framework Overview
3.2. Storyline Guidance Model
3.3. Story Generation Model
3.4. Story Visualization Model
4. Experiments
4.1. Dataset
4.2. Experimental Settings
4.3. Metrics
4.3.1. Automatic Evaluation
4.3.2. Human Evaluation
4.4. Storyline Guidance Model
4.5. Story Generation Model
4.6. Story Visualization Model
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics(ACL), Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Amodei, D. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Online, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 140. [Google Scholar]
- Xu, F.; Wang, X.; Ma, Y.; Tresp, V.; Wang, Y.; Zhou, S.; Du, H. Controllable Multi-Character Psychology-Oriented Story Generation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management(CKIM), Online, 19–23 October 2020; pp. 1675–1684. [Google Scholar]
- Zhang, Z.; Wen, J.; Guan, J.; Huang, M. Persona-Guided Planning for Controlling the Protagonist’s Persona in Story Generation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies(NAACL), Seattle, WA, USA, 10–15 July 2022; pp. 3346–3361. [Google Scholar]
- Yao, L.; Peng, N.; Weischedel, R.; Knight, K.; Zhao, D.; Yan, R. Plan-and-write: Towards better automatic storytelling. In Proceedings of the AAAI Conference on Artificial Intelligence, Holololu, HI, USA, 27 January–1 February 2019; pp. 7378–7385. [Google Scholar]
- Alhussain, A.I.; Azmi, A.M. Automatic story generation: A survey of approaches. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Tang, C.; Guerin, F.; Li, Y.; Lin, C. Recent Advances in Neural Text Generation: A Task-Agnostic Survey. arXiv 2022, arXiv:2203.03047. [Google Scholar]
- Tang, C.; Zhang, Z.; Loakman, T.; Lin, C.; Guerin, F. NGEP: A graph-based event planning framework for story generation. In Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Online, 20–23 November 2022; pp. 186–193. [Google Scholar]
- Xu, P.; Patwary, M.; Shoeybi, M.; Puri, R.; Fung, P.; Anandkumar, A.; Catanzaro, B. MEGATRON-CNTRL: Controllable story generation with external knowledge using large-scale language models. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 2831–2845. [Google Scholar]
- Ji, H.; Ke, P.; Huang, S.; Wei, F.; Zhu, X.; Huang, M. Language generation with multi-hop reasoning on commonsense knowledge graph. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 725–736. [Google Scholar]
- Hua, X.; Wang, L. PAIR: Planning and iterative refinement in pre-trained transformers for long text generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 781–793. [Google Scholar]
- Tan, B.; Yang, Z.; AI-Shedivat, M.; Xing, E.P.; Hu, Z. Progressive generation of long text with pretrained language models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), Online, 6–11 June 2021; pp. 4313–4324. [Google Scholar]
- Akoury, N.; Wang, S.; Whiting, J.; Hood, S.; Peng, N.; Iyyer, M. STORIUM: A Dataset and evaluation platform for machine-in-the-loop story generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6470–6484. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Maharana, A.; Hannan, D.; Bansal, M. Improving generation and evaluation of visual stories via semantic consistency. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies(NAACL), Online, 6–11 June 2021; pp. 2427–2442. [Google Scholar]
- Li, Y.; Gan, Z.; Shen, Y.; Liu, J.; Cheng, Y.; Wu, Y.; Carin, L.; Carlson, D.; Gao, J. Storygan: A sequential conditional gan for story visualization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 6329–6338. [Google Scholar]
- Maharana, A.; Hannan, D.; Bansal, M. Storydall-e: Adapting pretrained text-to-image transformers for story continuation. In Proceedings of the European Conference on Computer Vision(ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 70–87. [Google Scholar]
- Zeng, G.; Li, Z.; Zhang, Y. PororoGAN: An improved story visualization model on Pororo-SV dataset. In Proceedings of the 2019 3rd International Conference on Computer Science and Artificial Intelligence, Normal, IL, USA, 6–8 December 2019; pp. 155–159. [Google Scholar]
- Wu, Y.; Ma, Y.; Wan, S. Multi-scale relation reasoning for multi-modal Visual Question Answering. Signal Process. Image Commun. 2021, 96, 116319. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the 34th International Conference on Machine Learning(ICML), Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Rashkin, H.; Celikyilmaz, A.; Choi, Y.; Gao, J. Plotmachines: Outline-conditioned generation with dynamic plot state tracking. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing(EMNLP), Online, 16–20 November 2020; pp. 4274–4295. [Google Scholar]
- Guan, J.; Huang, F.; Zhao, Z.; Zhu, X.; Huang, M. A knowledge-enhanced pretraining model for commonsense story generation. Trans. Assoc. Comput. Linguist. 2020, 8, 93–108. [Google Scholar] [CrossRef]
- Goldfarb-Tarrant, S.; Chakrabarty, T.; Weischedel, R.; Peng, N. Content planning for neural story generation with aristotelian rescoring. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4319–4338. [Google Scholar]
- Clark, E.; Smith, N.A. Choose your own adventure: Paired suggestions in collaborative writing for evaluating story generation models. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies(NAACL), Online, 6–11 June 2021; pp. 3566–3575. [Google Scholar]
- Ji, Y.; Tan, C.; Martschat, S.; Choi, Y.; Smith, N.A. Dynamic entity representations in neural language models. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 7–11 September 2017; pp. 1830–1839. [Google Scholar]
- Clark, E.; Ji, Y.; Smith, N.A. Neural text generation in stories using entity representations as context. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), New Orleans, LA, USA, 1–6 June 2018; pp. 2250–2260. [Google Scholar]
- Fan, A.; Lewis, M.; Dauphin, Y. Hierarchical neural story generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 889–898. [Google Scholar]
- Guan, J.; Mao, X.; Fan, C.; Liu, Z.; Ding, W.; Huang, M. Long text generation by modeling sentence-level and discourse-level coherence. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (ACL-IJCNLP), online, 2–5 August 2021; pp. 6379–6393. [Google Scholar]
- Martin, L.; Ammanabrolu, P.; Wang, X.; Hancock, W.; Singh, S.; Harrison, B.; Riedl, M. Event representations for automated story generation with deep neural nets. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [CrossRef]. [Google Scholar]
- Fan, A.; Lewis, M.; Dauphin, Y. Strategies for structuring story generation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics(ACL), Florence, Italy, 28 July–2 August 2019; pp. 2650–2660. [Google Scholar]
- Wu, Y.; Cao, H.; Yang, G.; Lu, T.; Wan, S. Digital twin of intelligent small surface defect detection with cyber-manufacturing systems. ACM Trans. Internet Technol. 2022; accepted. [Google Scholar]
- Pascual, D.; Egressy, B.; Meister, C.; Cotterell, R.; Wattenhofer, R. A plug-and-play method for controlled text generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3973–3997. [Google Scholar]
- Kybartas, B.; Bidarra, R. A survey on story generation techniques for authoring computational narratives. IEEE Trans. Comput. Intell. AI Games 2016, 9, 239–253. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; Weston, J. Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL), Melbourne, Australia, 15–20 July 2018; pp. 2204–2213. [Google Scholar]
- Brahman, F.; Petrusca, A.; Chaturvedi, S. Cue me in: Content-inducing approaches to interactive story generation. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing (AACL), Suzhou, China, 4–7 December 2020; pp. 588–597. [Google Scholar]
- Wu, Y.; Zhang, L.; Berretti, S.; Wan, S. Medical image encryption by content-aware dna computing for secure healthcare. IEEE Trans. Ind. Inform. 2022, 19, 2089–2098. [Google Scholar] [CrossRef]
- Ullah, U.; Lee, J.S.; An, C.H.; Lee, H.; Park, S.Y.; Baek, R.H.; Choi, H.C. A Review of Multi-Modal Learning from the Text-Guided Visual Processing Viewpoint. Sensors 2022, 22, 6816. [Google Scholar] [CrossRef] [PubMed]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1316–1324. [Google Scholar]
- Qiao, T.; Zhang, J.; Xu, D.; Tao, D. Mirrorgan: Learning text-to-image generation by redescription. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1505–1514. [Google Scholar]
- Maharana, A.; Bansal, M. Integrating Visuospatial, Linguistic and Commonsense Structure into Story Visualization. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 6772–6786. [Google Scholar]
- Song, Y.Z.; Rui Tam, Z.; Chen, H.J.; Lu, H.H.; Shuai, H.H. Character-preserving coherent story visualization. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 18–33. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; CHen, M.; Sutskever, I. Zero-shot text-to-image generation. In Proceedings of the 38th International Conference on Machine Learning (ICML), online, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Wolf, T.; Sanh, V.; Chaumond, J.; Delangue, C. Transfertransfo: A transfer learning approach for neural network based conversational agents. arXiv 2019, arXiv:1901.08149. [Google Scholar]
- Badros, G.J.; Borning, A.; Stuckey, P.J. The Cassowary linear arithmetic constraint solving algorithm. ACM Trans.-Comput.-Hum. Interact. (TOCHI) 2001, 8, 267–306. [Google Scholar] [CrossRef] [Green Version]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–23 June 2022; pp. 10684–10695. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Gal, R.; Alaluf, Y.; Atzmon, Y.; Patashnik, O.; Bermano, A.H.; Chechik, G.; Cohen-Or, D. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv 2022, arXiv:2208.01618. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. arXiv 2022, arXiv:2208.12242. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML), online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Chen, J.; Chen, J.; Yu, Z. Incorporating structured commonsense knowledge in story completion. In Proceedings of the AAAI Conference on Artificial Intelligence, Honololu, HI, USA, 27 January–1 February 2019; pp. 6244–6251. [Google Scholar]
- Schuhmann, C.; Vencu, R.; Beaumont, R.; Kaczmarczyk, R.; Mullis, C.; Katta, A.; Coombes, T.; Jitsev, J.; Komatsuzaki, A. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv 2021, arXiv:2111.02114. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics(ACL), Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Shao, Z.; Huang, M.; Wen, J.; Xu, W.; Zhu, X. Long and diverse text generation with planning-based hierarchical variational model. arXiv 2019, arXiv:1908.06605. [Google Scholar]
- Zhang, T.; Kishore, V.; Wu, F.; Weinberger, K.Q.; Artzi, Y. Bertscore: Evaluating text generation with bert. In Proceedings of the International Conference on Learning Representations (ICLR) Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Field | Recall@1 | Recall@2 |
|---|---|---|
| Character | 0.32 | 0.54 |
| Event | 0.67 | 0.88 |
| Place | 0.54 | 0.82 |
| Model | PPL↓ | B-2↑ | B-3↑ | B-4↑ | LR-5↓ |
|---|---|---|---|---|---|
| Storium-GPT2 [15] | 0.224 | 0.176 | 0.106 | 0.041 | 0.549 |
| Ours | 0.198 | 0.154 | 0.111 | 0.064 | 0.407 |
| Model | BS-r↑ | BS-c↑ |
|---|---|---|
| Storium-GPT2 [15] | 15.7 | 15.2 |
| Ours | 15.1 | 22.2 |
| Model | Fluency | Coherence | Relevance | Likability | ||||
|---|---|---|---|---|---|---|---|---|
| Rating | Rating | Rating | Rating | |||||
| Storium-GPT2 [15] | 3.21 | 0.34 | 2.57 | 0.53 | 3.11 | 0.51 | 2.94 | 0.42 |
| Ours | 3.32 | 0.31 | 3.48 | 0.62 | 3.55 | 0.54 | 3.06 | 0.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Heo, Y.; Yu, H.; Nang, J. A Multi-Modal Story Generation Framework with AI-Driven Storyline Guidance. Electronics 2023, 12, 1289. https://doi.org/10.3390/electronics12061289
Kim J, Heo Y, Yu H, Nang J. A Multi-Modal Story Generation Framework with AI-Driven Storyline Guidance. Electronics. 2023; 12(6):1289. https://doi.org/10.3390/electronics12061289
Chicago/Turabian StyleKim, Juntae, Yoonseok Heo, Hogeon Yu, and Jongho Nang. 2023. "A Multi-Modal Story Generation Framework with AI-Driven Storyline Guidance" Electronics 12, no. 6: 1289. https://doi.org/10.3390/electronics12061289