
Improving Sentiment Prediction of Textual Tweets Using Feature Fusion and Deep Machine Ensemble Model

 ,
,  , ,
, ,  , , , and
, , , and 
Abstract
:1. Introduction
2. Related Work
3. Methods and Techniques
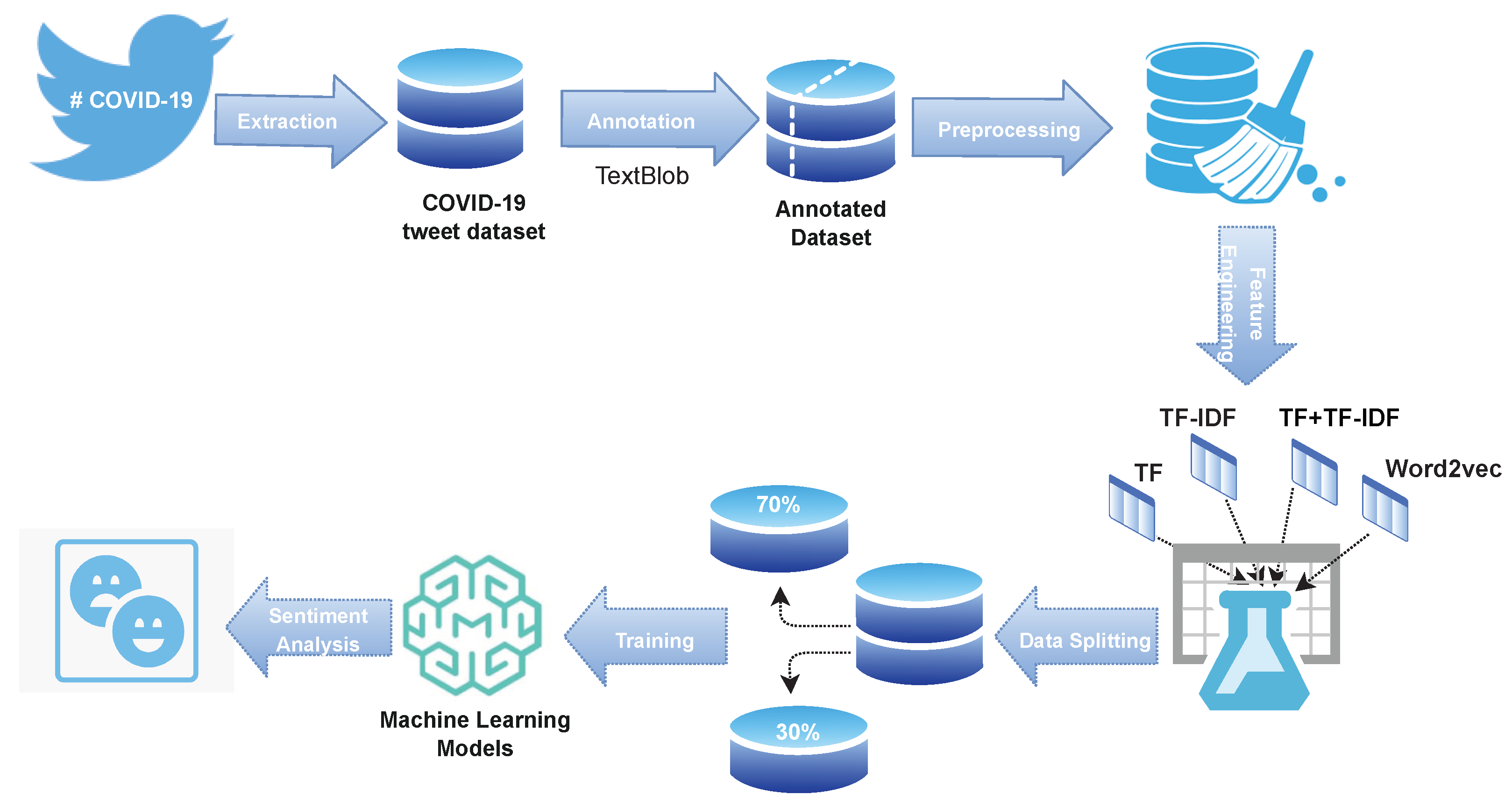
3.1. Overview of the Proposed Methodology
3.2. Dataset Description
3.3. Annotating Tweets
3.4. Data Preprocessing
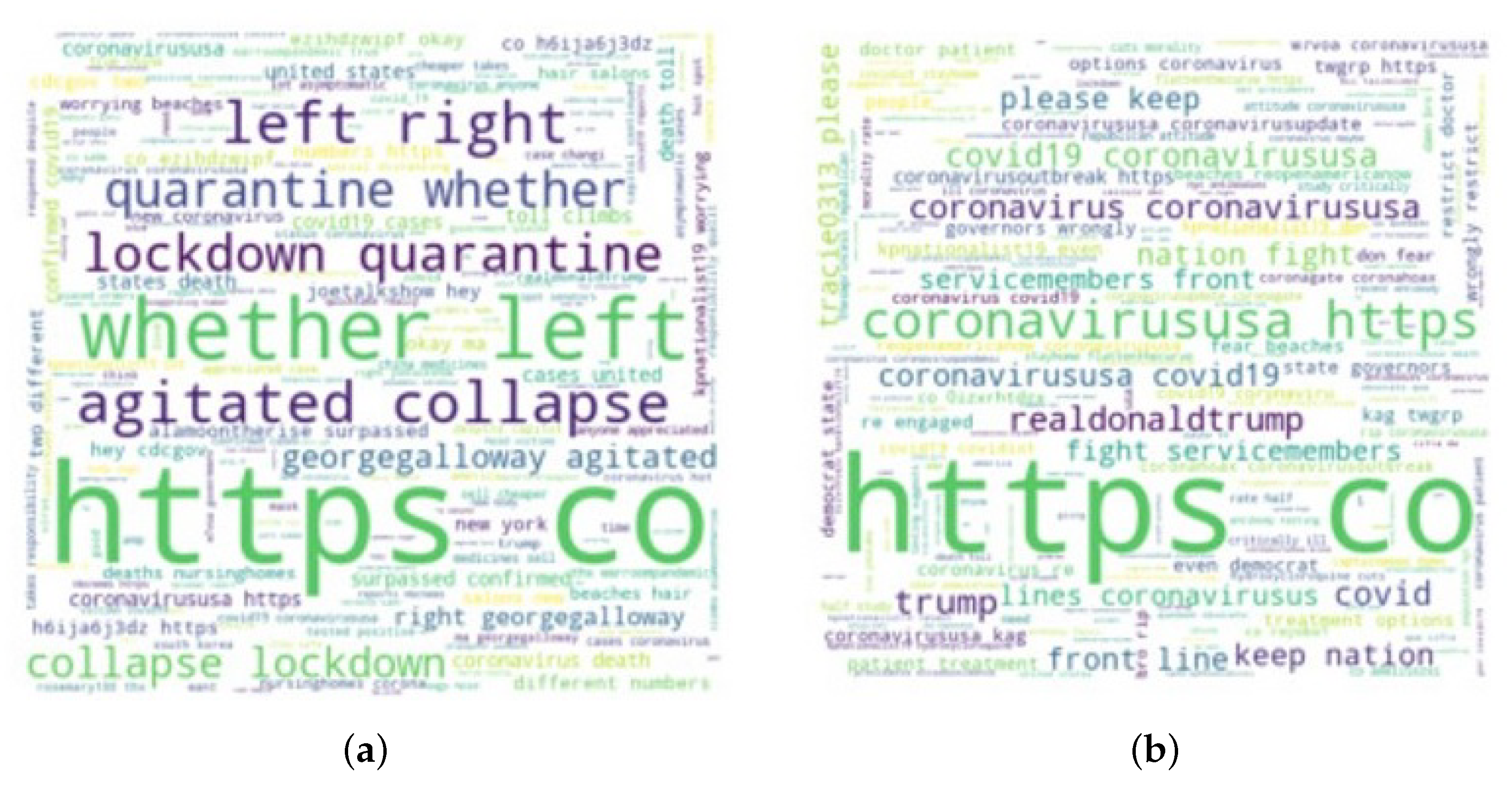
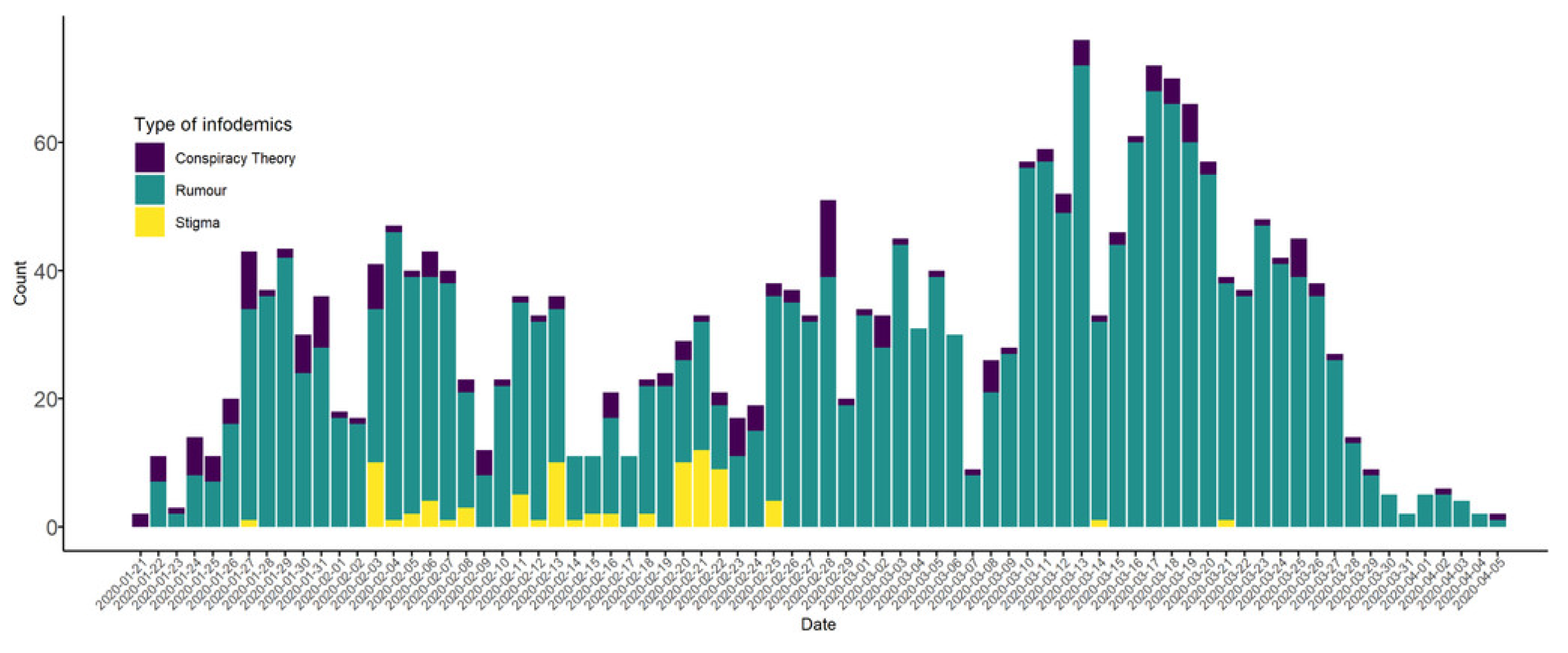
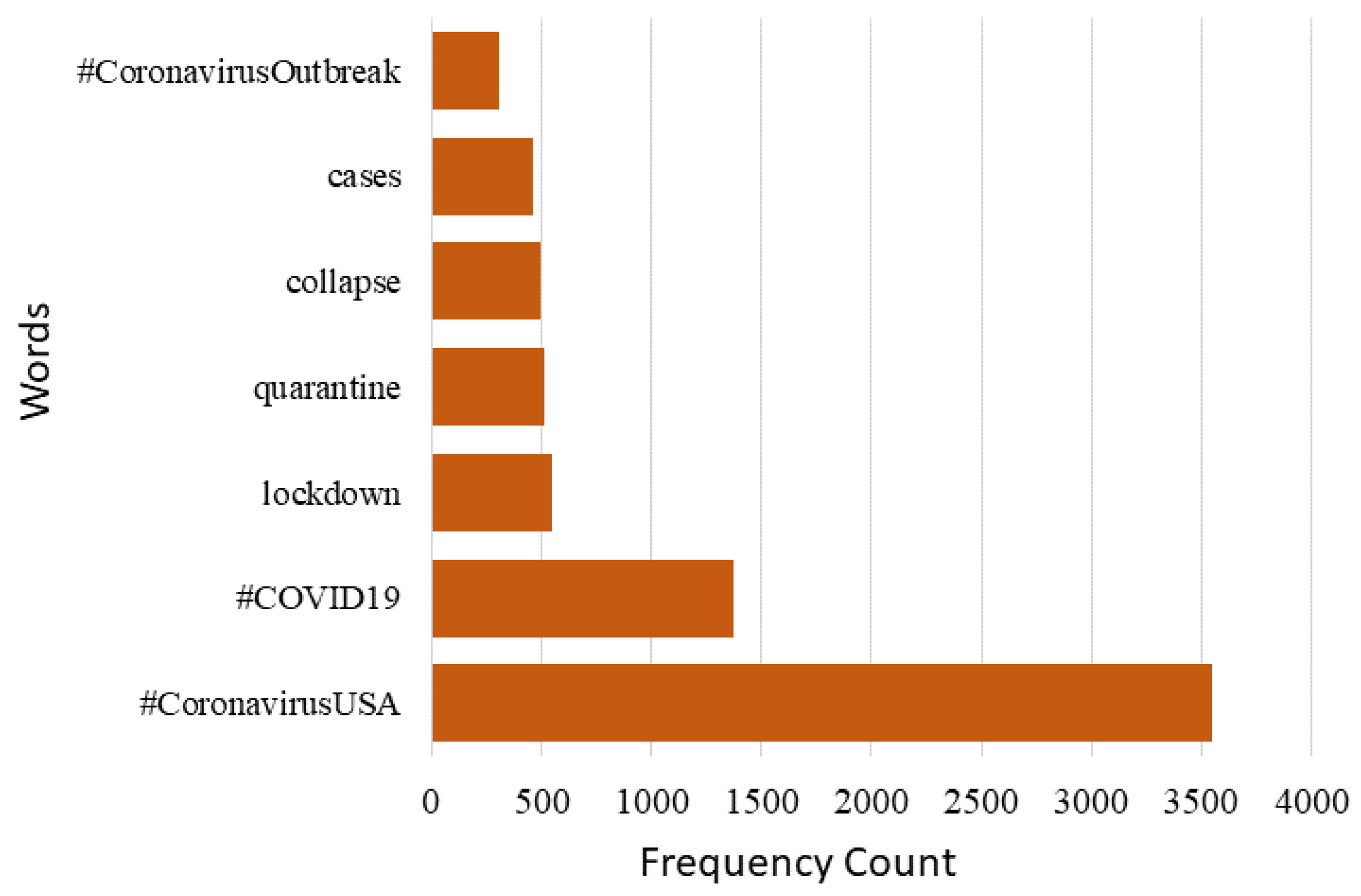
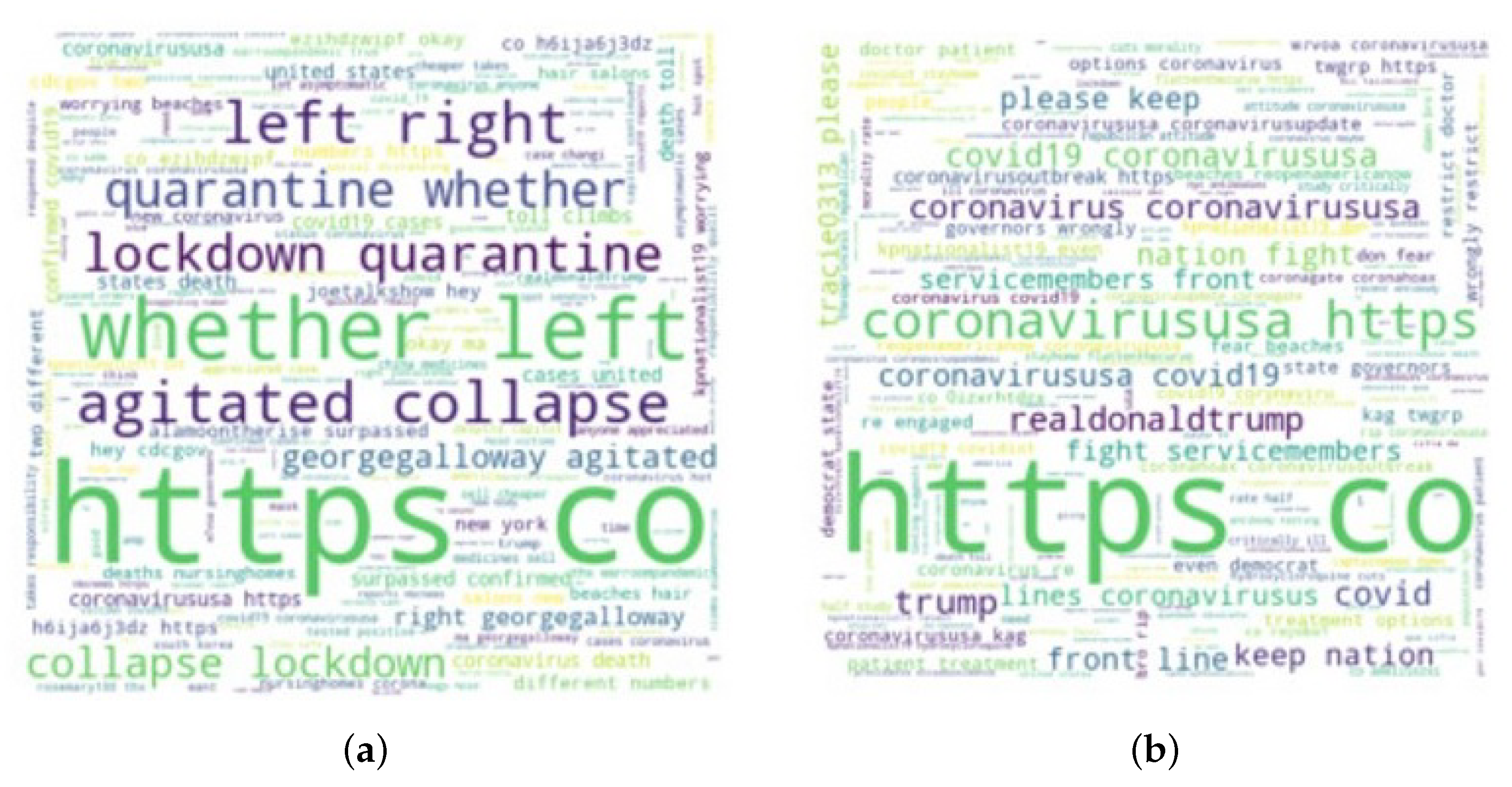
3.5. Graphical Representation of Data
3.6. Feature Extraction Techniques
3.7. Data Splitting
3.8. Classifiers
3.8.1. Random Forest
3.8.2. Gradient Boosting Machine
3.8.3. Extra Tree Classifier
3.8.4. Logistic Regression
3.8.5. Naive Bayes
3.8.6. Stochastic Gradient Descent
3.8.7. Multilayer Percetron
3.8.8. Recurrent Neural Network
3.8.9. Long Short Term Memory
3.8.10. Convolutional Neural Network
3.8.11. Voting Classifiers
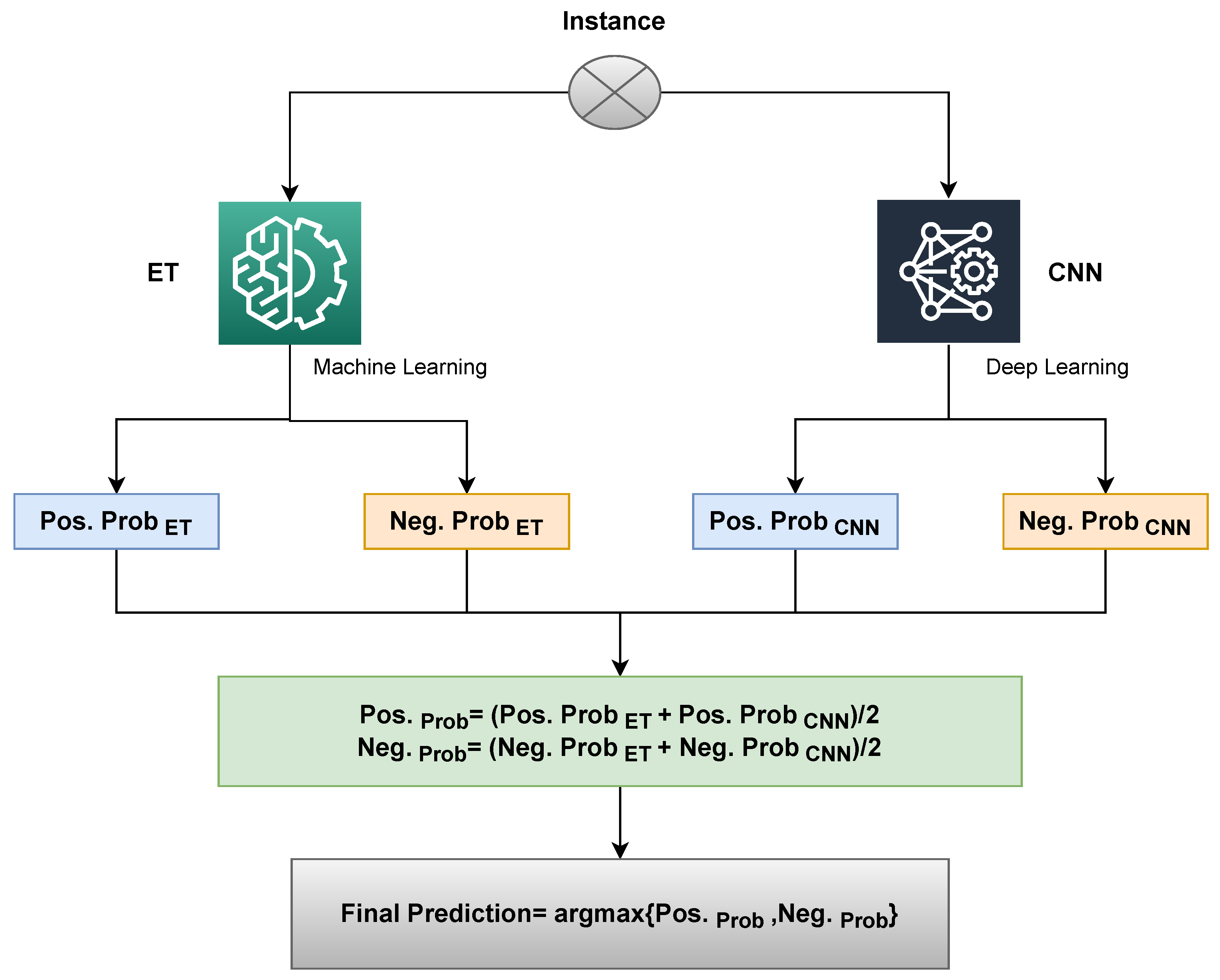
3.9. Proposed Framework
| Algorithm 1 Ensembling of ETC and CNN as VC(ETC+CNN). |
| Input: input data = Trained_ ETC = Trained_ CNN fordo if then end if Return final label end for |
4. Results and Discussion
4.1. Performance Evaluation Matrices
- True Positive (TP): it refers to correctly classified positive instances;
- True Negativity (TN): it refers to correctly classified negative instances;
- False Positive (FP): it refers to misclassified positive instances;
- False Negative (FN): it refers to misclassified negative instances.
4.2. Comparison of Classifiers Using TF
4.3. Comparison of Classifiers Using TF-IDF
4.4. Comparison of Classifiers Using Word2vec
4.5. Performance Comparison of Classifiers Using Feature Fusion
4.6. Performance Comparison
4.7. Results of Cross-Validation
4.8. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bai, Y.; Yao, L.; Wei, T.; Tian, F.; Jin, D.Y.; Chen, L.; Wang, M. Presumed asymptomatic carrier transmission of COVID-19. JAMA 2020, 323, 1406–1407. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lades, L.K.; Laffan, K.; Daly, M.; Delaney, L. Daily emotional well-being during the COVID-19 pandemic. Br. J. Health Psychol. 2020, 25, 902–911. [Google Scholar] [CrossRef]
- Depoux, A.; Martin, S.; Karafillakis, E.; Preet, R.; Wilder-Smith, A.; Larson, H. COVID-19 Coronavirus/Death Toll. 2021. Available online: https://www.worldometers.info/coronavirus/coronavirus-death-toll/ (accessed on 5 November 2022).
- Donthu, N.; Gustafsson, A. Effects of COVID-19 on business and research. J. Bus. Res. 2020, 117, 284–289. [Google Scholar] [CrossRef] [PubMed]
- Staszkiewicz, P.; Chomiak-Orsa, I.; Staszkiewicz, I. Dynamics of the COVID-19 Contagion and Mortality: Country Factors, Social Media, and Market Response Evidence From a Global Panel Analysis. IEEE Access 2020, 8, 106009–106022. [Google Scholar] [CrossRef]
- Guo, Y.R.; Cao, Q.D.; Hong, Z.S.; Tan, Y.Y.; Chen, S.D.; Jin, H.J.; Tan, K.S.; Wang, D.Y.; Yan, Y. The origin, transmission and clinical therapies on coronavirus disease 2019 (COVID-19) outbreak—An update on the status. Mil. Med. Res. 2020, 7, 11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittal, M.; Battineni, G.; Goyal, L.M.; Chhetri, B.; Oberoi, S.V.; Chintalapudi, N.; Amenta, F. Cloud-based framework to mitigate the impact of COVID-19 on seafarers’ mental health. Int. Marit. Health 2020, 71, 213–214. [Google Scholar] [CrossRef]
- Garcia, L.P.; Duarte, E. Infodemic: Excess Quantity to the Detriment of Quality of Information about COVID-19. Epidemiol. Serv. Saude 2020, 29, e2020186. [Google Scholar] [CrossRef]
- Hung, M.; Lauren, E.; Hon, E.S.; Birmingham, W.C.; Xu, J.; Su, S.; Hon, S.D.; Park, J.; Dang, P.; Lipsky, M.S. Social network analysis of COVID-19 Sentiments: Application of artificial intelligence. J. Med. Internet Res. 2020, 22, e22590. [Google Scholar] [CrossRef]
- Apuke, O.D.; Omar, B. Fake news and COVID-19: Modeling the predictors of fake news sharing among social media users. Telemat. Inform. 2021, 56, 101475. [Google Scholar] [CrossRef]
- Al-Zaman, M. COVID-19-Related social media fake news in India. J. Media 2021, 2, 100–114. [Google Scholar] [CrossRef]
- Depoux, A.; Martin, S.; Karafillakis, E.; Preet, R.; Wilder-Smith, A.; Larson, H. The Pandemic of Social Media Panic Travels Faster than the COVID-19 Outbreak. J. Travel Med. 2020, 27, taaa031. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, J.; Zheng, P.; Jia, Y.; Chen, H.; Mao, Y.; Chen, S.; Wang, Y.; Fu, H.; Dai, J. Mental health problems and social media exposure during COVID-19 outbreak. PLoS ONE 2020, 15, e0231924. [Google Scholar]
- Ahmad, A.R.; Murad, H.R. The impact of social media on panic during the COVID-19 pandemic in Iraqi Kurdistan: Online questionnaire study. J. Med. Internet Res. 2020, 22, e19556. [Google Scholar] [CrossRef] [PubMed]
- Stats, I.L. Twitter Usage Statistics. Available online: https://www.internetlivestats.com/twitter-statistics/?_ga=2.265985167.1893892026.1661193312-937589960.1661193312 (accessed on 24 July 2022).
- Chakraborty, K.; Bhatia, S.; Bhattacharyya, S.; Platos, J.; Bag, R.; Hassanien, A.E. Sentiment Analysis of COVID-19 tweets by Deep Learning Classifiers—A study to show how popularity is affecting accuracy in social media. Appl. Soft Comput. 2020, 97, 106754. [Google Scholar] [CrossRef] [PubMed]
- Shahsavari, S.; Holur, P.; Tangherlini, T.R.; Roychowdhury, V. Conspiracy in the time of corona: Automatic detection of COVID-19 conspiracy theories in social media and the news. arXiv 2020, arXiv:2004.13783. [Google Scholar] [CrossRef]
- Islam, M.S.; Sarkar, T.; Khan, S.H.; Kamal, A.H.M.; Hasan, S.M.; Kabir, A.; Yeasmin, D.; Islam, M.A.; Chowdhury, K.I.A.; Anwar, K.S.; et al. COVID-19–related infodemic and its impact on public health: A global social media analysis. Am. J. Trop. Med. Hyg. 2020, 103, 1621. [Google Scholar] [CrossRef]
- Havey, N.F. Partisan public health: How does political ideology influence support for COVID-19 related misinformation? J. Comput. Soc. Sci. 2020, 3, 319–342. [Google Scholar] [CrossRef]
- Huynh, T.L. The COVID-19 risk perception: A survey on socioeconomics and media attention. Econ. Bull. 2020, 40, 758–764. [Google Scholar]
- Naseem, U.; Razzak, I.; Eklund, P.; Musial, K. Towards improved deep contextual embedding for the identification of irony and sarcasm. In Proceedings of the 2020 IEEE International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Naseem, U.; Khan, S.K.; Razzak, I.; Hameed, I.A. Hybrid words representation for airlines sentiment analysis. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Adelaide, SA, Australia, 2–5 December 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 381–392. [Google Scholar]
- Aggarwal, C.C.; Reddy, C.K. Data Clustering: Algorithms and Applications; Chapman and Hall: Boca Raton, FL, USA, 2013. [Google Scholar]
- Barkur, G.; Vibha, G.B.K. Sentiment analysis of nationwide lockdown due to COVID 19 outbreak: Evidence from India. Asian J. Psychiatry 2020, 51, 102089. [Google Scholar] [CrossRef]
- Li, S.; Wang, Y.; Xue, J.; Zhao, N.; Zhu, T. The impact of COVID-19 epidemic declaration on psychological consequences: A study on active Weibo users. Int. J. Environ. Res. Public Health 2020, 17, 2032. [Google Scholar] [CrossRef] [Green Version]
- Samuel, J.; Ali, G.; Rahman, M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Zhu, T. Twitter discussions and concerns about COVID-19 pandemic: Twitter data analysis using a machine learning approach. arXiv 2020, arXiv:2005.12830. [Google Scholar]
- Kleinberg, B.; van der Vegt, I.; Mozes, M. Measuring emotions in the COVID-19 real world worry dataset. arXiv 2020, arXiv:2004.04225. [Google Scholar]
- Li, I.; Li, Y.; Li, T.; Alvarez-Napagao, S.; Garcia-Gasulla, D.; Suzumura, T. What Are We Depressed about When We Talk about COVID-19: Mental Health Analysis on Tweets Using Natural Language Processing. In International Conference on Innovative Techniques and Applications of Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 358–370. [Google Scholar]
- Feng, Y.; Zhou, W. Is working from home the new norm? An observational study based on a large geo-tagged COVID-19 Twitter dataset. arXiv 2020, arXiv:2006.08581. [Google Scholar]
- Drias, H.H.; Drias, Y. Mining Twitter Data on COVID-19 for Sentiment analysis and frequent patterns Discovery. medRxiv 2020. [Google Scholar] [CrossRef]
- Balahur, A. Sentiment analysis in social media texts. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Atlanta, GA, USA, 14 June 2013; pp. 120–128. [Google Scholar]
- Leskovec, J. Social media analytics: Tracking, modeling and predicting the flow of information through networks. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 277–278. [Google Scholar]
- Wirawan, N.C.; Indriati, P.P.A. Analisis Sentimen Dengan Query Expansion Pada Review Aplikasi M-Banking Menggunakan Metode Fuzzy K-Nearest Neighbor (Fuzzy k-NN). J. Pengemb. Teknol. Inf. Dan Ilmu Komput. 2018, 2548, 964X. [Google Scholar]
- Rachman, F.H. Twitter Sentiment Analysis of COVID-19 Using Term Weighting TF-IDF In addition, Logistic Regresion. In Proceedings of the 2020 6th IEEE Information Technology International Seminar (ITIS), Surabaya, Indonesia, 14–16 October 2020; pp. 238–242. [Google Scholar]
- Chintalapudi, N.; Battineni, G.; Amenta, F. Sentimental Analysis of COVID-19 Tweets Using Deep Learning Models. Infect. Dis. Rep. 2021, 13, 329–339. [Google Scholar] [CrossRef]
- Carvalho, J.P.; Rosa, H.; Brogueira, G.; Batista, F. MISNIS: An intelligent platform for Twitter topic mining. Expert Syst. Appl. 2017, 89, 374–388. [Google Scholar] [CrossRef] [Green Version]
- Lopez, C.E.; Vasu, M.; Gallemore, C. Understanding the perception of COVID-19 policies by mining a multilanguage Twitter dataset. arXiv 2020, arXiv:2003.10359. [Google Scholar]
- Prabhakar Kaila, D.; Prasad, D.A. Informational flow on Twitter–Corona virus outbreak–topic modelling approach. Int. J. Adv. Res. Eng. Technol. (IJARET) 2020, 11, 128–134. [Google Scholar]
- Han, X.; Wang, J.; Zhang, M.; Wang, X. Using social media to mine and analyze public opinion related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naseem, U.; Razzak, I.; Khushi, M.; Eklund, P.W.; Kim, J. COVIDSenti: A Large-Scale Benchmark Twitter Data Set for COVID-19 Sentiment Analysis. IEEE Trans. Comput. Soc. Syst. 2021, 8, 1003–1015. [Google Scholar] [CrossRef] [PubMed]
- Lamsal, R. Design and analysis of a large-scale COVID-19 tweets dataset. Appl. Intell. 2021, 51, 2790–2804. [Google Scholar] [CrossRef] [PubMed]
- Umer, M.; Ashraf, I.; Mehmood, A.; Ullah, S.; Choi, G.S. Predicting numeric ratings for Google apps using text features and ensemble learning. ETRI J. 2021, 43, 95–108. [Google Scholar] [CrossRef]
- Bow, S.T. Pattern Recognition and Image Preprocessing; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]
- Sriram, B.; Fuhry, D.; Demir, E.; Ferhatosmanoglu, H.; Demirbas, M. Short text classification in Twitter to improve information filtering. In Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Geneva, Switzerland, 19–23 July 2010; ACM: New York, NY, USA, 2010; pp. 841–842. [Google Scholar]
- Scikit Learn. Scikit-Learn Feature Extraction with countVectorizer. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.Count/ (accessed on 5 April 2019).
- Scikit Learn. Scikit-Learn Feature Extraction with TF/IDF. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.text.Tfidf/ (accessed on 5 April 2019).
- Hackeling, G. Mastering Machine Learning with Scikit-Learn; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Scikit Learn. Scikit-Learn Classification and Regression Models. Available online: http://scikitlearn.org/stable/supervised_learning.html (accessed on 10 April 2019).
- Araque, O.; Corcuera-Platas, I.; Sanchez-Rada, J.F.; Iglesias, C.A. Enhancing deep learning sentiment analysis with ensemble techniques in social applications. Expert Syst. Appl. 2017, 77, 236–246. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Sharaff, A.; Gupta, H. Extra-tree classifier with metaheuristics approach for email classification. In Advances in Computer Communication and Computational Sciences; Springer: Berlin/Heidelberg, Germany, 2019; pp. 189–197. [Google Scholar]
- Genkin, A.; Lewis, D.D.; Madigan, D. Large-scale Bayesian logistic regression for text categorization. Technometrics 2007, 49, 291–304. [Google Scholar] [CrossRef] [Green Version]
- Perez, A.; Larranaga, P.; Inza, I. Supervised classification with conditional Gaussian networks: Increasing the structure complexity from naive Bayes. Int. J. Approx. Reason. 2006, 43, 1–25. [Google Scholar] [CrossRef] [Green Version]
- Gardner, W.A. Learning characteristics of stochastic-gradient-descent algorithms: A general study, analysis, and critique. Signal Process. 1984, 6, 113–133. [Google Scholar] [CrossRef]
- Almaghrabi, M.; Chetty, G. Improving sentiment analysis in Arabic and English languages by using multi-layer perceptron model (MLP). In Proceedings of the 2020 IEEE 7th International Conference on Data Science and Advanced Analytics (DSAA), Sydney, NSW, Australia, 6–9 October 2020; pp. 745–746. [Google Scholar]
- Sharfuddin, A.A.; Tihami, M.N.; Islam, M.S. A deep recurrent neural network with bilstm model for sentiment classification. In Proceedings of the 2018 IEEE International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 21–22 September 2018; pp. 1–4. [Google Scholar]
- Jin, N.; Wu, J.; Ma, X.; Yan, K.; Mo, Y. Multi-task learning model based on multi-scale CNN and LSTM for sentiment classification. IEEE Access 2020, 8, 77060–77072. [Google Scholar] [CrossRef]
- Anderson, J.L. A method for producing and evaluating probabilistic forecasts from ensemble model integrations. J. Clim. 1996, 9, 1518–1530. [Google Scholar] [CrossRef]
- Stein, R.A.; Jaques, P.A.; Valiati, J.F. An analysis of hierarchical text classification using word embeddings. Inf. Sci. 2019, 471, 216–232. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for Covid-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Methods | Dataset | Findings |
|---|---|---|---|
| [24] | Wordcloud | 24,000 tweets extracted using hashtags | Positive sentiments were prominent. |
| [27] | LDA | 4 million tweets extracted using hashtags | Identified topics, themes and sentiments |
| [28] | Linear regression models using TF-IDF | Real World Worry Dataset | Introduced ground truth dataset |
| [16] | Fuzzy logic based model | 226,668 tweets (December 2019 to May 2020) | The proposed model achieved 79% accuracy to perform sentiment analysis |
| [35] | LR and TF-IDF | COVID-19 tweets collected at 30 April 2020 | The proposed model achieved 84.71% accuracy in performing sentiment analysis |
| [36] | BERT, LR, LSTM and SVM | 3090 tweets extracted on 12 January 2021 | BERT outperformed with 89% accuracy in classifying Indian tweets. |
| [26] | NB, KNN and LR | COVID-19 tweets February–March 2020 | NB achieved 91% accuracy in finding fear-sentiment progress during COVID-19 |
| [38] | NLP tool | Tweets collected from 22 January to 13 March 2020 | Authors introduced the multilingual dataset |
| [39] | LDA Analysis | Random sample of 18,000 tweets | This study concluded that Twitter contains mostly accurate information related to coronavirus. |
| [40] | LDA and RF | Weibo texts (Sina-Weibo) | This study performed spatial and temporal analysis of COVID-19 related social media text. |
| [41] | SVM, NB, DT, RF, CNN, and BiLSTM | COVIDSENTI dataset | Authors analyzed public behavior during COVID-19 and introduced a new dataset. |
| Technique | Positive | Negative | Total |
|---|---|---|---|
| TextBlob | 7876 | 3982 | 11,858 |
| Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| RF | 92.52% | 93% | 93% | 92% |
| ETC | 94.06% | 94% | 94% | 94% |
| GBM | 86.03% | 88% | 86% | 85% |
| LR | 92.49% | 93% | 92% | 92% |
| NB | 87.88% | 88% | 88% | 87% |
| SGD | 93.79% | 94% | 94% | 94% |
| MLP | 83.62% | 81% | 85% | 83% |
| RNN | 87.72% | 84% | 89% | 86% |
| LSTM | 90.21% | 85% | 91% | 88% |
| CNN | 93.99% | 94% | 94% | 94% |
| VC(LR+SGD) | 92.41% | 93% | 92% | 92% |
| VC(ETC+CNN) | 96.62% | 96% | 96% | 96% |
| Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| RF | 91.99% | 92% | 92% | 92% |
| ETC | 94.74% | 95% | 95% | 95% |
| GBM | 86.53% | 88% | 87% | 86% |
| LR | 89.91% | 91% | 90% | 89% |
| NB | 88.92% | 89% | 89% | 88% |
| SGD | 94.01% | 94% | 94% | 94% |
| MLP | 85.25% | 79% | 84% | 83% |
| RNN | 89.77% | 88% | 91% | 90% |
| LSTM | 90.11% | 89% | 92% | 91% |
| CNN | 95.65% | 96% | 96% | 96% |
| VC(LR+SGD) | 90.02% | 91% | 90% | 90% |
| VC(ETC+CNN) | 96.89% | 96% | 94% | 95% |
| Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| RF | 87.44% | 88% | 87% | 87% |
| ETC | 88.64% | 90% | 89% | 88% |
| GBM | 84.45% | 85% | 84% | 84% |
| LR | 82.21% | 82% | 82% | 82% |
| NB | 68.94% | 72% | 69% | 70% |
| SGD | 83.36% | 83% | 83% | 83% |
| MLP | 80.44% | 79% | 85% | 82% |
| RNN | 85.56% | 82% | 84% | 83% |
| LSTM | 89.37% | 83% | 87% | 85% |
| CNN | 90.23% | 92% | 94% | 93% |
| VC(LR+SG) | 82.41% | 82% | 82% | 82% |
| VC(ETC+CNN) | 89.22% | 91% | 91% | 91% |
| Model | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| RF | 90.83% | 91.34% | 91.65% | 90.49% |
| ETC | 91.93% | 92.10% | 92.23% | 92.15% |
| GBM | 85.49% | 86.47% | 85.34% | 84.40% |
| LR | 92.07% | 92.22% | 92.34% | 92.28% |
| NB | 88.39% | 88.61% | 88.56% | 88.58% |
| SGD | 92.18% | 92.21% | 92.45% | 92.33% |
| MLP | 93.65% | 91.41% | 95.77% | 93.56% |
| RNN | 91.22% | 90.34% | 90.48% | 90.41% |
| LSTM | 92.59% | 91.87% | 95.97% | 93.92% |
| CNN | 97.77% | 96.14% | 98.37% | 97.29% |
| VC(LR+SGD) | 92.10% | 92.55% | 92.62% | 92.58% |
| VC(ETC+CNN) | 99.99% | 99.99% | 99.96% | 99.98% |
| Reference | Model | Accuracy |
|---|---|---|
| [62] | RF | 92% |
| [62] | XGboost | 92% |
| [62] | SVC | 89% |
| [62] | ETC | 93% |
| [62] | DT | 91% |
| [16] | SVM | 79% |
| Proposed | VC(ETC+CNN) | 99% |
| K-Folds | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| 1st-Fold | 0.994 | 0.994 | 0.994 | 0.999 |
| 2nd-Fold | 0.998 | 0.992 | 0.995 | 0.993 |
| 3rd-Fold | 0.992 | 0.993 | 0.996 | 0.994 |
| 4th-Fold | 0.991 | 0.994 | 0.994 | 0.999 |
| 5th-Fold | 0.998 | 0.999 | 0.992 | 0.995 |
| 6th-Fold | 0.999 | 0.993 | 0.991 | 0.997 |
| 7th-Fold | 0.999 | 0.998 | 0.984 | 0.991 |
| 8th-Fold | 0.999 | 0.995 | 0.992 | 0.993 |
| 9th-Fold | 0.994 | 0.999 | 0.991 | 0.995 |
| 10th-Fold | 0.992 | 0.993 | 0.991 | 0.997 |
| Average | 0.995 | 0.995 | 0.992 | 0.995 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madni, H.A.; Umer, M.; Abuzinadah, N.; Hu, Y.-C.; Saidani, O.; Alsubai, S.; Hamdi, M.; Ashraf, I. Improving Sentiment Prediction of Textual Tweets Using Feature Fusion and Deep Machine Ensemble Model. Electronics 2023, 12, 1302. https://doi.org/10.3390/electronics12061302
Madni HA, Umer M, Abuzinadah N, Hu Y-C, Saidani O, Alsubai S, Hamdi M, Ashraf I. Improving Sentiment Prediction of Textual Tweets Using Feature Fusion and Deep Machine Ensemble Model. Electronics. 2023; 12(6):1302. https://doi.org/10.3390/electronics12061302
Chicago/Turabian StyleMadni, Hamza Ahmad, Muhammad Umer, Nihal Abuzinadah, Yu-Chen Hu, Oumaima Saidani, Shtwai Alsubai, Monia Hamdi, and Imran Ashraf. 2023. "Improving Sentiment Prediction of Textual Tweets Using Feature Fusion and Deep Machine Ensemble Model" Electronics 12, no. 6: 1302. https://doi.org/10.3390/electronics12061302
APA StyleMadni, H. A., Umer, M., Abuzinadah, N., Hu, Y.-C., Saidani, O., Alsubai, S., Hamdi, M., & Ashraf, I. (2023). Improving Sentiment Prediction of Textual Tweets Using Feature Fusion and Deep Machine Ensemble Model. Electronics, 12(6), 1302. https://doi.org/10.3390/electronics12061302