1. Introduction
In recent years, language models have been used in many fields. Many applications, such as machine translation [
1], audio recognition [
2], and text classification [
3] adopt language models to improve model performance. The field of software engineering has recently adopted language models to improve the performance of many tasks, such as code smell detection [
4] and software bug detection [
5]. To build a code recommendation system, the source code is parsed into a token sequence and the language model is applied to help recommend code snippets for software engineers. Existing works on subjects such as recurrent language models have contributed to the solution of code completion and have helped software engineers to improve the efficiency of developing software.
However, existing state-of-the-art language models are designed specifically for natural languages. A programming language is very different from natural language, and the direct application of language models designed for natural languages to programming languages faces many challenges. One of the biggest differences between programming languages and natural languages is that programming languages have free naming rules. For a user-defined variable or method in a program, different people have different naming habits and rules. This means that it is impossible to use a fixed vocabulary table or dictionary, to include all of the possible variable names or method names in the programming language. The number of possible words in a programming language is infinite. On the contrary, natural languages often have a fixed vocabulary table, and a dictionary is enough to model all words in such a language. This difference leads to a dilemma when applying language models to code.
Because of the free naming conventions of source code, for different projects, the variable names, method names, or type names in those projects may vary greatly. If the model is trained on one project, it may encounter many unfamiliar words in another project. If the unfamiliar words appear everywhere, the trained language model will be confused and eventually it will not know how to infer the next word. If some words are unfamiliar when making predictions, discrepancies between training and prediction will occur. The discrepancies may gather and explode during a long prediction phase. This phenomenon is also referred to as exponential bias, and is the reason for the rapid decline in prediction effect when there exist data inconsistencies between training and prediction. The data inconsistency problem between training and prediction brings about difficulties in applying code completion technology in large-scale industrial scenarios. According to our statistics, this problem is serious when it comes to source code handling. For two different projects with more than 200 files on GitHub, approximately 70% of the tokens in these two projects are different. Thus, the data inconsistency problem needs to be discussed and resolved. By checking a large amount of source code, we discover that the syntax tree of the source code has hierarchical structures, with strong regularity in different projects, and can be used to combat data inconsistency.
As the abstract syntax tree (AST) of source code has a hierarchical structure, in this paper, we propose a novel Hierarchical Language Model (HLM), to improve the robustness of the state-of-the-art recurrent language model, to gain the ability to deal with data inconsistencies between training and testing. For each hierarchy of the code tree, from the bottom of the tree to the root, we use the state-of-the-art language model to accumulate the information of each tree in each hierarchy. Then, the embedding for each tree in each hierarchy is generated. This procedure is named the encoding procedure. In the next step, the code tree is traversed from the root to the bottom, and the existing state-of-the-art language model is used to decode each encountered tree node. This procedure is named the decoding procedure. The decoding procedure takes the embedding for each hierarchy tree generated during the encoding procedure into consideration. It should be noted, that for traditional language models, only the decoding procedure exists. The proposed framework adds an encoding procedure on the basis of the original decoding procedure, making the model more expressive. The encoding procedure actually takes each tree in each hierarchy as a segment. This can help the model to handle long code context, because when a token sequence is long, grouping that long sequence into segments and predicting the next piece of code based on the generated segments, is often helpful.
In summary, to solve the data inconsistency problem between projects, we propose the Hierarchical Language Model (HLM) to generate the embedding for each sub-tree according to hierarchies in the encoding procedure, and collect the embedding of each sub-tree in context, to predict the next piece of code in the decoding procedure. Experiments on inner-project and cross-project datasets indicate that the newly proposed HLM method performs better than the state-of-the-art recurrent language model in dealing with the data inconsistency between training and testing, and achieves an average improvement in prediction accuracy of 11.2%. The main contributions of this paper include the following:
To the best of our knowledge, this is the first study to specifically discuss the data inconsistency problem of source code and propose a method to specifically solve this problem.
The proposed method uses the tree hierarchical structure of source code to combat the inconsistency of tokens.
The new framework divides the single decoding process of the original language model into the encoding process and the decoding process. This proposed framework can greatly improve the available parameters of the original model and inspire other language models.
A new tree encoding–decoding mechanism is designed and applied to the hierarchical structures of code.
Both inner-project and cross-project evaluations are conducted, to compare the performance of models, and an average improvement of 7% is achieved.
2. Related Work
2.1. Statistical Models for Code Completion
The statistical language model uses the statistical patterns of code to recommend the next piece of code, based on a given code context. The pioneering work in [
6], applied the statistical n-gram model to source code to help predict the next piece of code. SLAMC [
7] assigned topics to each token to predict the next code token based on tokens in the context and the corresponding topics of these tokens. A large-scale investigation [
8] of n-gram models on a large code corpus was conducted and a visualization tool was provided. Cacheca [
9] confirmed the localness of the source code and proposed a cache model to improve the code suggestion performance. The pattern of the common application programming interface (API) calls, with the associated parameter objects, were captured by per-object n-grams [
10]. The Naive Bayes model was applied to a graph [
11] to suggest API usage. A decision tree, together with an n-gram model [
12], was applied to solve the problem of code completion. The code was modeled in the form of DSL [
13]. Based on DSL, the model was trained in such a way that the model continued sampling and validating until the right code was suggested. For statement-level code completion, the authors in [
14] used a self-defined intermediate representation (IR) and a fuzzy search algorithm to search for similar context, to handle the unseen data, in order to improve the n-gram model.
2.2. Deep Learning Models for Code Completion
The pioneering work in [
15], used a deep language model to solve the problem of code completion, based on the RNN model. A long short-term memory (LSTM) network is a kind of recurrent neural network that introduces the gate mechanism, to capture longer dependencies than the RNN model. The LSTM model was applied to solve the problem of code completion [
16,
17], in order to achieve higher accuracy. The attention network [
18] is applied to the LSTM model to further improve the ability to capture the characteristics of the context. A Pointer network [
18], or graph network [
19], is adopted to predict the unseen data. The main difference between the two, is that the work in [
19] adopts a different switch algorithm and separates the parameters between the language model and repetition learning model. This makes the prediction effect of unknown data more obvious. The work in [
20], uses the tree language model with the tree encoding context. To make the token embedding better, the BERT pre-trained method [
21] was proposed, to let the BERT model train the token embedding on three general preset tasks and fine-tune the token embedding on specific multi-tasks [
22]. Based on the recurrent language model, the graph model [
23] was proposed, to capture the long-term dependencies. The already trained GPT2 model [
24] was directly used for code completion. The above works do not handle the data inconsistency and the models are not designed to utilize the code structure hierarchies. The proposed method in this paper can be used as a supplement to the above works.
2.3. Models for Code Synthesis
Code synthesis involves generating a code snippet based on the hint described in natural languages or other forms. The technology used in code synthesis is similar to the technology used in code completion. Models such as Seq2Seq [
25], Seq2Tree [
26], and Tree2Tree [
27] were proposed for the problem of code synthesis. To synthesize the API sequences based on natural languages, the Seq2Seq model [
28,
29] was applied. The neural program translation needs to translate one program to another program. The program is in the form of an abstract syntax tree (AST), and the Tree2Tree [
30] model translates one tree to another tree. It should be noted that the proposed model in this paper could also be used as the decoding module in code synthesis tasks. We will further investigate the performance of the Hierarchical Language Model to be used as the decoding module in code synthesis tasks in future work.
2.4. Models for Code Classification
The purpose of code classification is to generate an embedding for the whole code, and use the generated embedding to perform classification. The code classification model can be used in the encoding procedure of the proposed framework. The tree-based convolution neural network (TBCNN) [
31] applies the general convolution mechanism to the syntax tree of the code, to judge what type of program it is. The convolution-based attention model [
32] was applied to help generate the name of a function. TreeNN [
33] was adopted for producing representations of homogeneous and polynomial expressions. To categorize expressions according to semantics, based on TreeNN, EQNET [
34] additionally adopted an extra abstraction and reconstruction layer, to help capture the semantics of the expressions. Code is organized in statements, and a bi-directional long short-term memory (BiLSTM) model is applied to the embedding of each statement [
35] to generate the representation of a code snippet, in order to help classify it.
2.5. Hierarchical Language Model for Source Code
To the best of our knowledge, the proposed Hierarchical Language Model (HLM) framework is the first to use the hierarchical structure of code to explicitly handle the data inconsistency between training and testing. The proposed framework is also the first to add an explicit encoding procedure to the original decoding procedure of state-of-the-art language model frameworks. The experiments indicate that the newly proposed model indeed has some special properties.
3. Proposed Method
3.1. Preliminary
3.1.1. Abstract Syntax Tree (AST)
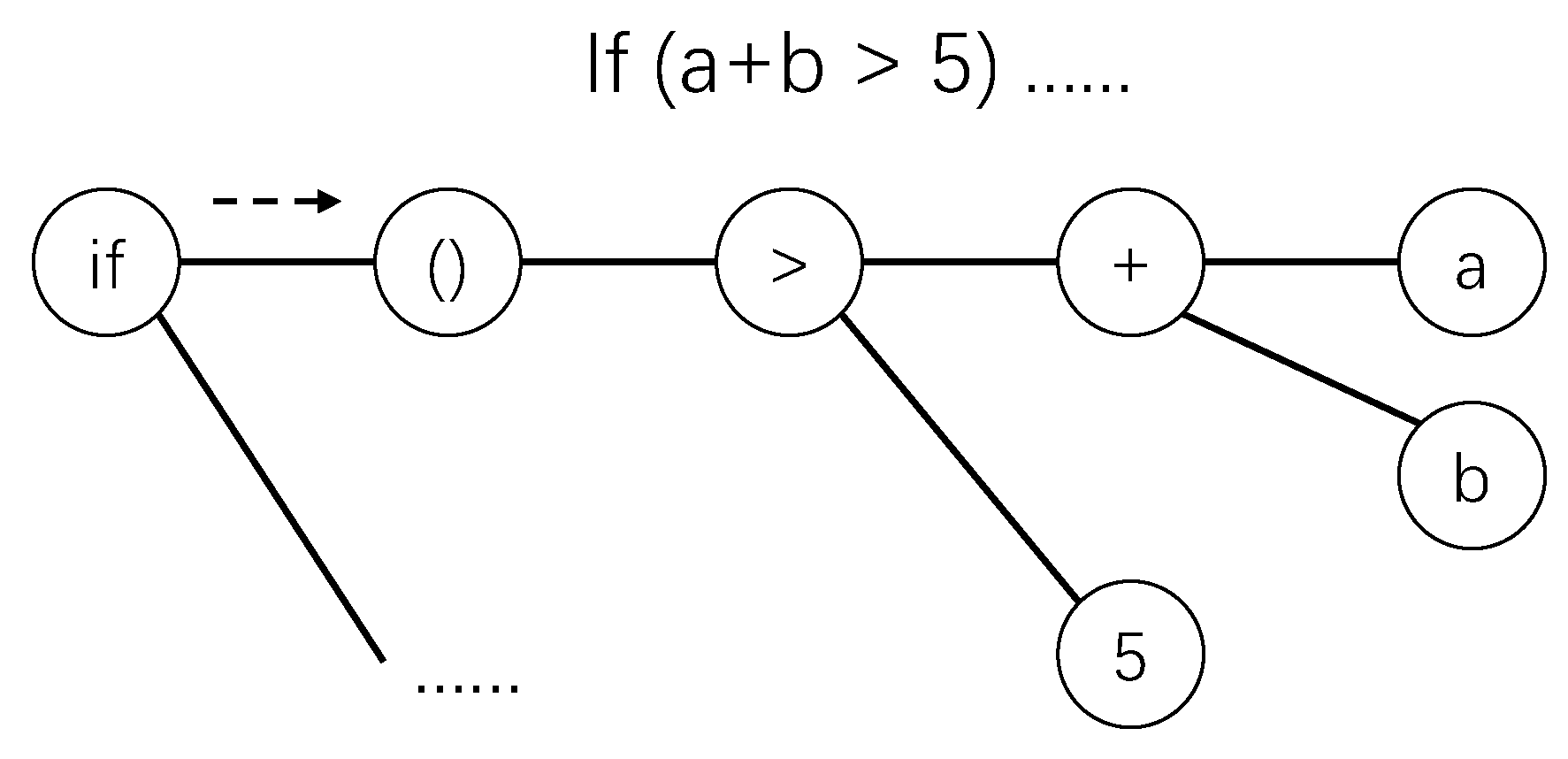
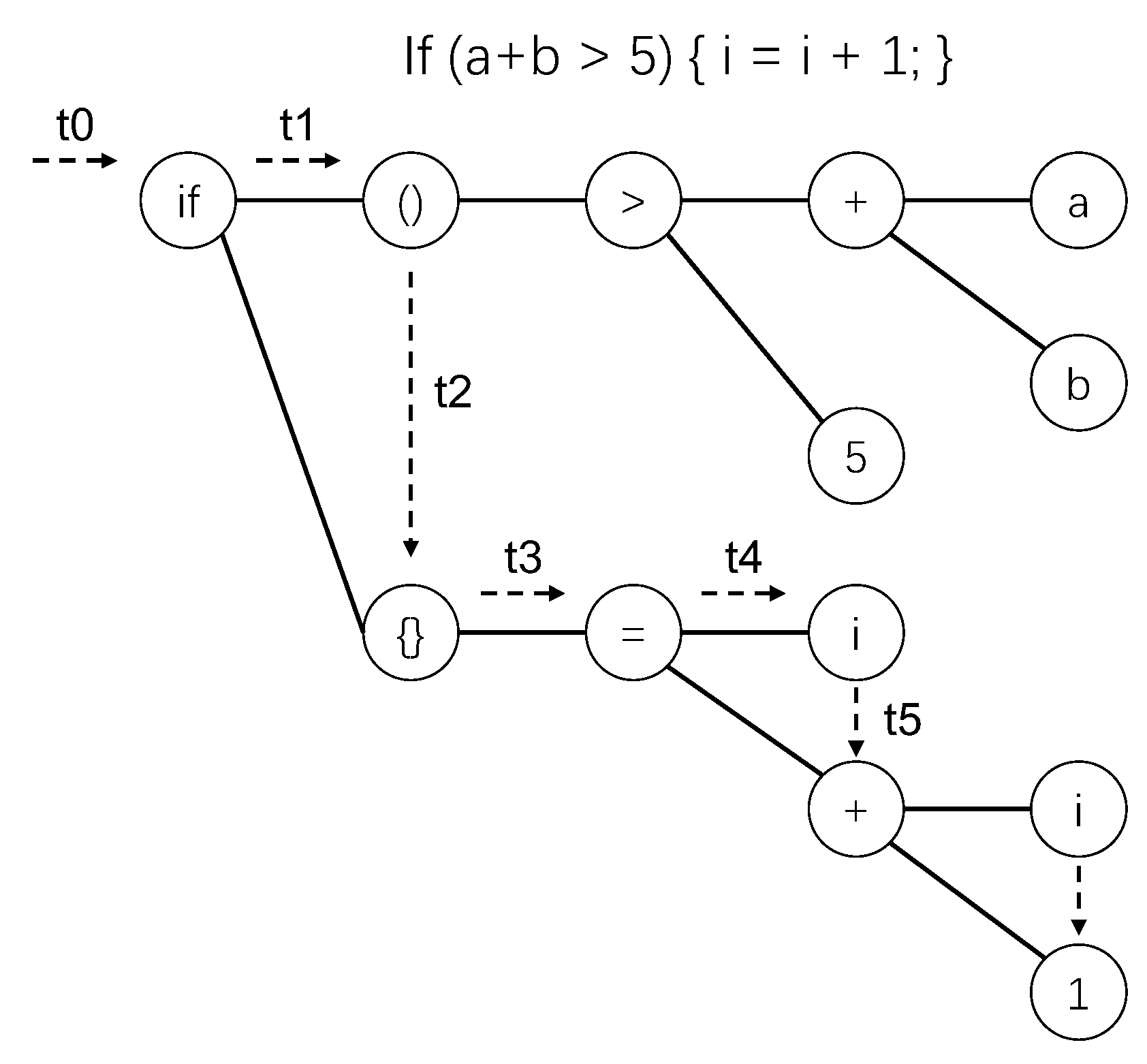
The code snippet “if (
a +
b > 5)” and its corresponding AST, are illustrated in
Figure 1. In this figure, the root is the node with content
and the leaf nodes are node
a, node
b, and node 5. Each node in the AST has a content, which is also called a token. In this paper, each node corresponds to a token, and a token must be the content of a node.
Concepts of an AST: The formal definitions of some concepts of an AST are described here.
3.1.2. State-of-the-Art Code Completion Method
For an AST, the aim of code completion is to complete each node in that AST one by one. As each node must be predicted one by one, the order in which each node is generated must be decided. We observe that when people write a function, the skeleton of that function is often written first. Then, the details in the skeleton of the function are written, and so on. This order in which the code is written is consistent with the pre-order traversal of AST. Thus, when predicting nodes on an AST, we use pre-order traversal to traverse the tree to predict each encountered node.
Traditional Language Model Computation Step for Code Completion. The traditional methods flatten the AST into a token sequence. We assume that the generated token sequence is
,
, …,
. Now, if we want to predict the next token,
, based on the existing token sequence, the traditional methods compute the probability
. Here, we use a simplest recurrent language model to show, in detail, how
is computed. The symbol
is the embedding for token
. The embedding
for token
is just a vector of shape
, where
m is the embedding feature size and is set by a human. The shape
, means that the matrix has 1 row and
m columns, that is, it is just a vector with
m elements. To ease the description, we set
n to
; now, we want to compute
. With the above definition, the output embedding
for predicting
is computed as follows.
is generated using
and
with matrix multiplications. In the above equation,
and
are trainable parameter matrices with shape
.
should be computed recursively until
, which is a preset trainable parameter vector. Then,
is a vector of shape
, which is of the same size as
or
. Then, for predicting token
, we need to compute the probabilities for all possible candidate tokens in the vocabulary. Assuming that there are
v total tokens in the vocabulary, given the output embedding
, the computation step to compute the probabilities for all of these
v tokens is as follows:
In the above equation, U is a trainable parameter matrix and is of shape . P is a vector of shape . Because of the operation, each element in P is between and all elements in P sum to 1. When predicting , we choose the token with the highest probability in the vocabulary, which means if is the highest value, then we should choose the jth token in the vocabulary as the final recommendation. When training, in the actual existing corpus, if is the the jth token in the vocabulary, then should be the highest value. If is not the highest value, we should use the random gradient descent algorithm to update all of the trainable parameters, to maximize the .
3.2. Differences and Insights between Existing Models and the Hierarchical Language Model
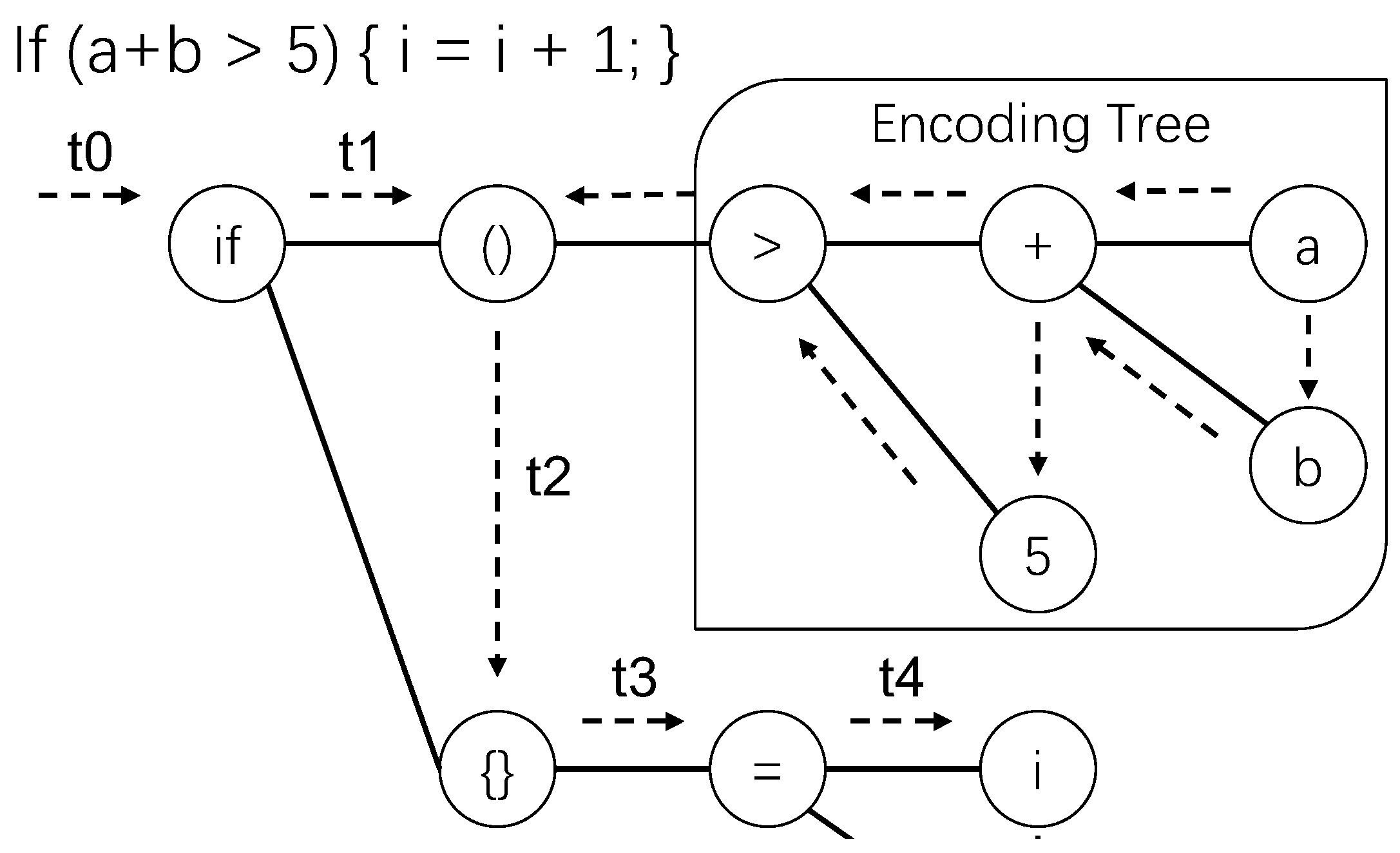
The previous subsection shows that traditional language models handle data points one by one. Even the transformer method still follows the framework described in the previous subsection. The AST shown in
Figure 2 can be taken as an example to show the differences between traditional language models and the proposed HLM. If we want to predict the node
, which is the target of edge
, the traditional language model will handle node
, node
, node >, node +, node
a, node
b, and node 5 sequentially, in order to gather the embedding of the encountered nodes and generate the output embedding for predicting the target node. The following equation records the processing path of nodes:
In the previous subsection, we describe a simple deep language model. However, there are many different language models. Here, we use the abstract symbol
f, to refer to the procedure of a general language model that takes the information of tokens or the already processed information as the input, and outputs the processed embedding. As can be seen from the following equation, the function f, first handles node
and node
. Then, the function f takes the processed embedding generated during the previous step, and the new node >, to generate the new embedding. Repeating the handling nodes in the path, the final output embedding
h will be generated. With the output embedding
h, we can use Equation (
2) to compute probabilities for all candidate tokens in the vocabulary.
An obvious problem is that precious structural information in the AST will be ignored when the AST is handled in this way. Furthermore, if the nodes are processed in this order, the leaf nodes are processed later than the non-leaf nodes. However, the leaf nodes often contain the names of variables or methods, that vary greatly in different projects. All language models have the following characteristic: the closer the token is to the target, the greater the impact on the prediction result of the language model. Thus, we cannot let a token that varies greatly between different projects be processed. The insights of the design of the proposed Hierarchical Language Model, are that the AST should be processed in hierarchies and that it should not be processed last.
Thus, when predicting the node
, which is the target of the edge
, the Hierarchical Language Model (HLM) will traverse the AST and collect the information of complete trees in different hierarchies. For example, node >, node +, node
a, node
b, and node 5 in
Figure 2, make up a complete sub-tree. The models designed especially for trees can be used to generate embedding for that tree. The tree embedding is generated in post-order traversal, meaning that node
a and node
b in the bottom hierarchy are handled first; then, node + and node 5 in the second bottom hierarchy are handled later. It should be noted that if we want to predict the target of edge
in
Figure 2, the target node being predicted is the descendant of node
, so we assume the tree rooted at node
is not complete. Similarly, the target node being predicted is the next sibling of node
, so we also assume the tree rooted at node
is not complete. For nodes which are not in a complete tree, we use the same method as the traditional language model to handle these nodes. So, node
and node
are handled first, in the pre-order traversal of the AST, to generate an embedding, named
. Then, node >, node +, node
a, node
b, and node 5 are handled in post-order traversal of the AST, to generate another embedding, named
. To generate
h, to be used for computing the probabilities of all candidate tokens in the vocabulary in Equation (
2), we can design a function f, such that
. The details will be described in the next subsection. The procedure to generate
is named the decoding procedure. The procedure to generate
is named the encoding procedure. By doing so, the original single decoding procedure is divided into two procedures, and in the encoding procedure, we can use models specifically designed for trees, to generate embedding. The following equation records the processing path of HLM.
3.3. Hierarchical Language Model
The encoding procedure of HLM, is to generate the embedding for each tree (sub-tree) in the AST. The decoding procedure of HLM, is to accumulate the information of context (consists of sub-trees) to predict the next node. For the proposed Hierarchical Language Model (HLM), to predict node n at the specified position, HLM accumulates information based on the of node n.
3.3.1. Encoding Procedure of HLM
We use post-order traversal to traverse the AST, from the leaves to the root, in order to encode a tree. For a leaf node
n, we assume its token embedding is
, and the encoding
of the tree rooted at node
n is computed by Equation (
3). In Equation (
3),
and
are preset trainable parameter vectors.
For a non-leaf node
m, we assume its token embedding is
, and its children are put in a list named
. The encoding
of the tree rooted at node
m is computed with Equation (
4). In Equation (
4),
,
,
, and
are preset trainable parameter vectors.
is the encoding for the tree rooted at the child node
of node
m. It should be noted that
should be generated in the same way as
.
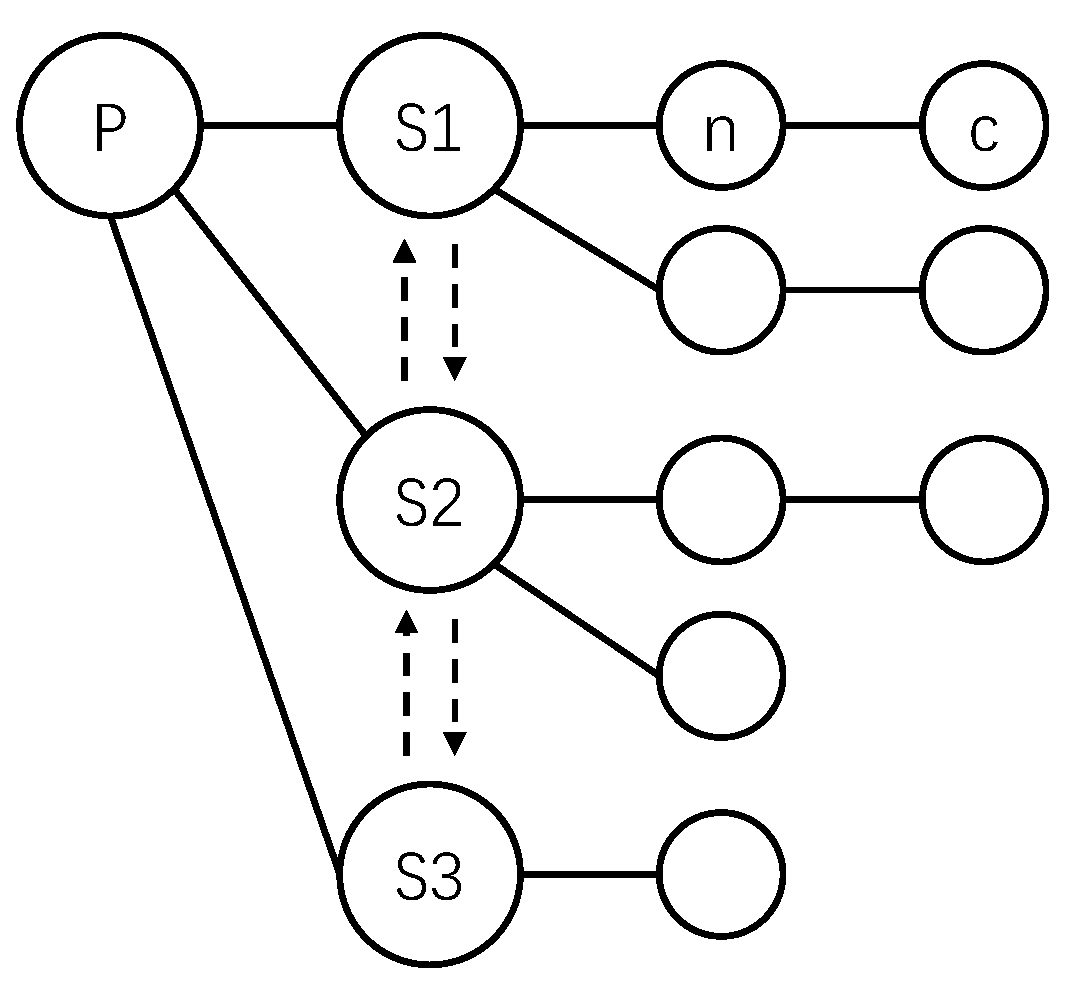
We use the AST in
Figure 3 to show the computation steps for the non-leaf node P, of which the number of children is three.
and
are computed in Equation (
5).
3.3.2. Decoding Procedure of HLM
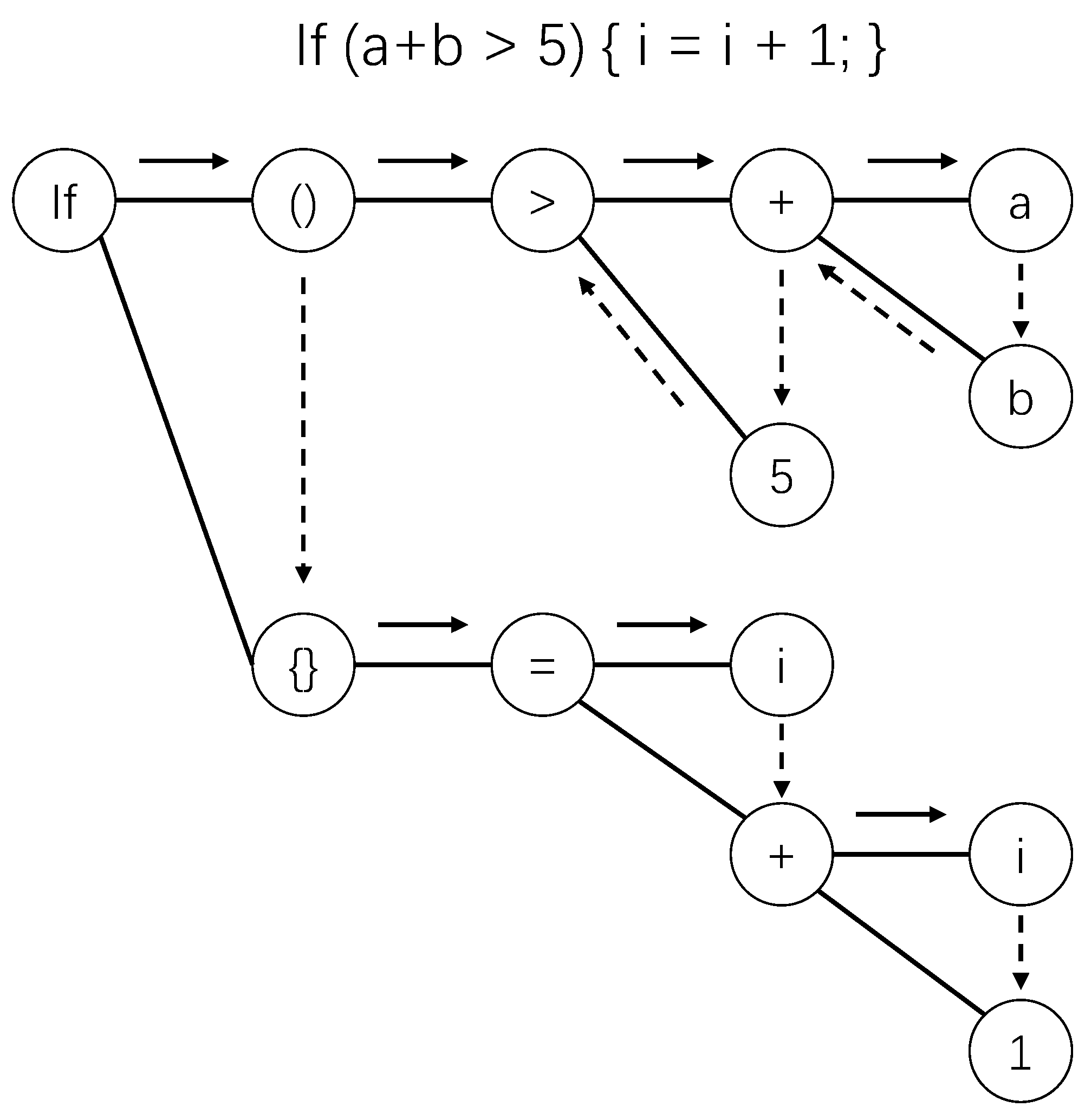
Decoding Path of HLM: The
of HLM, for node n, is the transfer path from the root to node n. From a node, only the first child of that node or the next sibling of that node can be transferred to. Thus, the candidate transfer paths of the AST in
Figure 1 are shown in
Figure 4. In
Figure 4, the solid arrow represents the transition to the first child, and the dotted arrow represents the transition to the next sibling node. Thus, under this definition, a directed acyclic graph (DAG) was generated, and the transfer path from the root to each node was uniquely determined. In detail, from the root node of the tree, if node n is the descendant of the root node, to reach node n, we must transfer from the root node to the first child of the root node. After reaching a new node, then, if node n is the descendant of the newly reached node, we must transfer to the first child of the newly reached node. Otherwise, we must transfer to the next sibling of the newly reached node. If we continue transferring in this way, we finally reach node n. There are two kinds of transitions: transfer to first child and transfer to next sibling.
Transition on Decoding Path of HLM: As described above, the
consists of a sequence of transitions. In
Figure 5, the dotted arrows give an illustration of the path and the transition from the root to node + (the second child of node =). Each transition between nodes on the path is marked as
,
,
, …,
. The information flow of a transition represents the accumulated information of previous transitions before that transition. The information that flows for each transition has a fixed data format: (
);
and
h are two feature vectors of fixed length. The symbols
and
, represent the information on transition
. Note that for each transition
, the source node of that transition is named
, and the target node of that transition is named
. For node
, all descendant nodes are named
.
Detailed Decoding Step of HLM: Then, we iterate the transitions one by one, to compute the accumulated information for predicting node n. At first, the information of transition
:
,
is set to a fixed default value. Then, for each transition
, if
is of the “transfer to the first child” type, we use Equation (
6) to compute the information for transition
. We assume that the token embedding of the source node of the transition
is referred to as
. The information of transition
is computed by
The encoding of the tree rooted at the node
, in the encoding procedure described in the previous subsection, is referred to as
. For the encountered transition
, if
is of the “transfer to the next sibling” type, the information of transition
is computed by
The computed
can be used to predict the target node
of transition
. With the generated
, Equation (
2) can be used to compute the probabilities of all candidate tokens, and the top-k tokens with the highest probabilities are taken as the final results.
4. Experiment
The Hierarchical Language Model can be applied to any programming language that can be parsed into an abstract syntax tree. As the number of projects written in the Java programming language is the largest in Github, in this experiment, famous Java projects are downloaded from Github to enter into the code corpus (dataset) for experiments. The source code of each downloaded project is pre-processed to ensure its quality. For each code corpus, the training set accounted for 60%, the validation set accounted for 15%, and the test set accounted for 25%. In experiments, the validation set is used to prevent over-fitting. Every function is parsed into AST and every AST is regarded as a training example or as a test example. Each node in an AST is predicted. The models in the experiments are trained to predict each node in the AST correctly. The accuracy is the summation of the prediction accuracy of each node in each AST. Some sequential models, such as RNN or LSTM, cannot be directly applied to data in tree structures. IThe tree will be flattened into a sequence, making sequential models applicable.
4.1. UNK Setting
In natural language processing, the least frequently occurring words are marked as unknown word (). In order to avoid being the most frequent words, we set the least frequently appearing words in the training set as . Thus, can still be rare words, but not the most frequent words. In test data, the embedding of non-vocabulary words is replaced with the embedding of , but we do not think is the right word when computing prediction accuracy.
4.2. Datasets
In this experiment, three datasets are generated. Datasets 1 and 2 are the inner-project code corpus. Dataset 3 is the cross-project code corpus.
Table 1 shows the composition of each dataset. Dataset 1 consists of Java files in the main module of project
apache commons lang. The size of Dataset 1 is 2.8 MB. The
apache maven is a famous project; we downloaded the source code from its official website (not on GitHub). The size of the project is 4.4 MB. As observed from open-source projects, many files contain a large amount of Java documents, comments, or small functions, with only one or two statements. Those noisy data should be removed. For generating cross-project datasets, we used the following three steps, to generate high-quality datasets containing long and non-noisy code. The first step was to choose two to four projects from Github at random. The second step was to compute a score for each Java file in each project: the total number of nodes in functions divided by the total number of functions, resulted in the score for a Java file. Given the threshold for the size of the dataset (for example 8 MB), the third step is to select the top Java files with the highest scores in each project, to mix into a dataset until the threshold for the size of the dataset is reached. Dataset 3 contains the top-scored Java files from projects
Gocd (5023 stars),
apache-incubator-joshua (73 stars),
vlc-android-sdk (723 stars), and
locationtech-geowave (344 stars). In all datasets, functions with less than 100 AST nodes or more than 10,000 AST nodes were removed. The evaluation results on Dataset 3 are more convincing, because such results reflect the performance of the model on different projects. The last column in
Table 1, shows the vocabulary size of each dataset.
4.3. Baselines
To evaluate the performance of our model, some baselines needed to be trained. RNN and LSTM were taught to predict the next token based on already predicted tokens in the sequence generated by flattening a tree. RNN and LSTM are classical models for capturing patterns in sequential data. These two models are included in the baseline. Compared with RNN, LSTM has a more powerful ability to capture the long-term dependency in sequential data. Every model in the baseline needs to predict every token, for every function in the dataset.
4.4. Hyperparameters
We used the Adam algorithm to compute the gradients. We trained examples one by one, instead of grouping examples into batches, because different ASTs may have different numbers of nodes. The vector size for the feature vector of one token was 128. All other parameters were decided successively.
4.5. Termination Condition
We used the strategy of early stopping for the termination of model training. The model stopped instantly if the the prediction accuracy on the validation set started to decrease.
4.6. Platform
The experiments were conducted on a desktop computer. The CPU of the computer was i5-8400, the GPU was a Geforce RTX 2070, and the memory size was 32 GB. The implementation of the model was based on TensorFlow.
4.7. Evaluation
The metrics to evaluate the performance of different models in this experiment include top-k (top-1, top-3, top-6, and top-10) accuracy and mrr (mean reciprocal rank). The top-k accuracy is computed by judging whether the right token appears in the first k recommendations of the code completion model. When predicting the token of the next node, if the oracle token appears in the rth recommendation, then the rank of this recommendation (completion) is r and the reciprocal rank of this recommendation is . The mrr is computed by averaging the reciprocal rank of the oracle token for each code recommendation (completion).
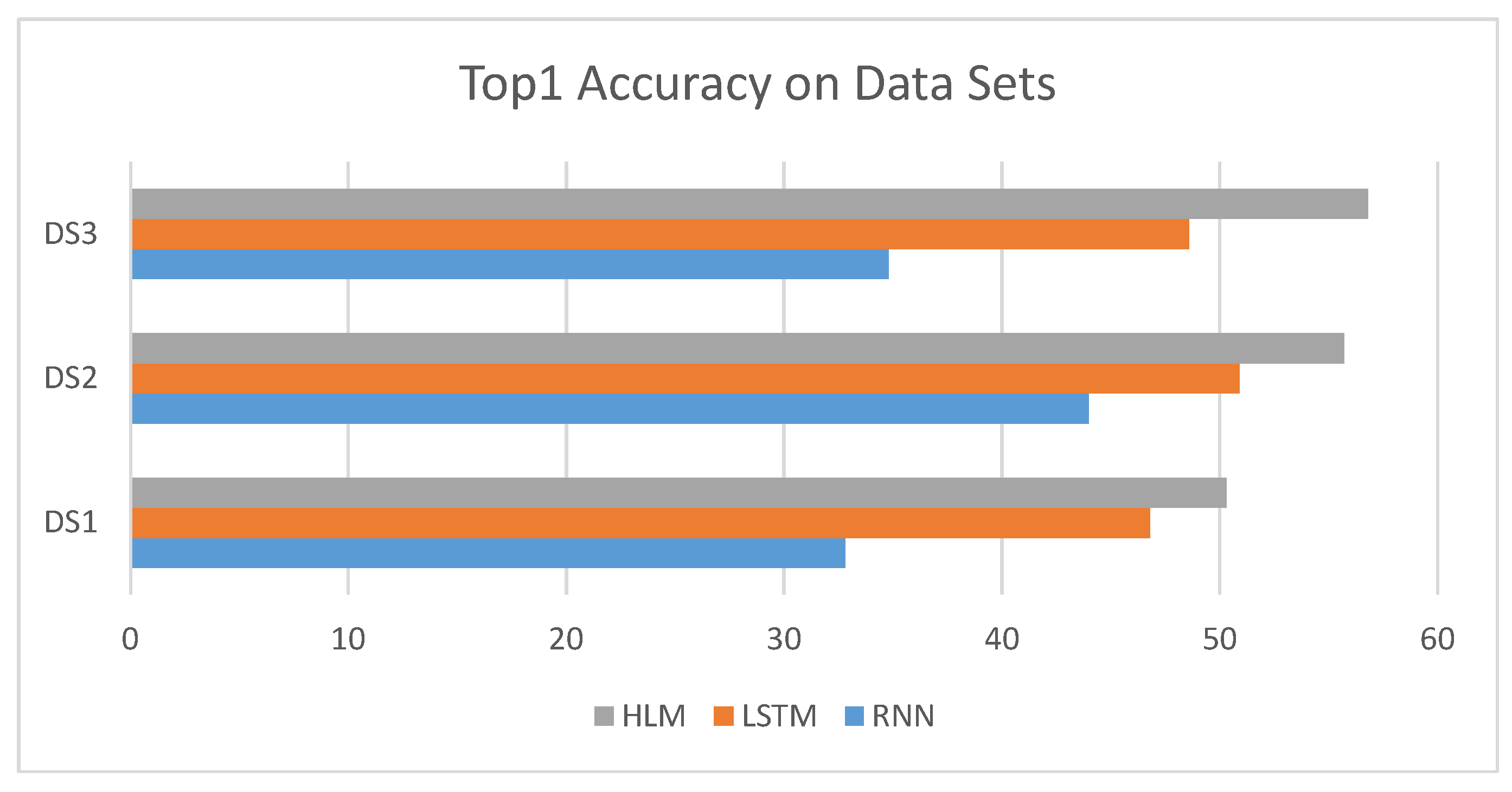
Table 2 shows the top-k accuracy and the mrr evaluated for four datasets. HLM refers to the Hierarchical Language Model. On all three datasets, RNN performs the worst. On small datasets, i.e., Dataset 1 and Dataset 2, HLM achieved, on average, an 8.5% higher top-1 accuracy than LSTM. On large datasets, i.e., Dataset 3, HLM achieved, on average, a 16.9% higher top-1 accuracy than LSTM. After carefully investigating the experimental results, we found that the proposed HLM is good at predicting tokens related to the syntax tree structure. For top-1 accuracy, the different models used in the experiments had a large degree of discrimination. For top-3, top-6, and top-10 accuracy, the distinction between different models became smaller and smaller. This illustrates that the top-1 prediction accuracy is the most convincing. From the perspective of top-1 prediction accuracy, HLM performs better than other models.
Figure 6 shows the top-1 accuracy for different models on different datasets. As can be seen, the proposed HLM achieves the best results for all datasets. This figure intuitively shows the effect of the proposed model.
Table 3 shows the training time for the different models on different datasets. As the proposed model splits the original decoding procedure into encoding procedure and decoding procedure, the training time for one round is twice as long as the baseline model. However, as the proposed model captures the characteristics of code structures, the proposed model is much easier to converge than the baseline model, which does not capture the code hierarchy structures. The number of rounds required for the convergence of the new model is generally one half to one third of that of the baseline model. In total, the proposed framework still uses less time to complete the training procedure than the baseline model.
As can be seen from the experimental results, the proposed model achieves the best results. By introducing more parameters in the proposed framework, the model can fit the data better. Furthermore, in the encoding procedure, the tree model is adopted, to capture the characteristics of the abstract syntax tree (AST) of the code, which also contributes to the improvement. The HLM uses post-order traversal to traverse the AST, to encode all sub-trees. This kind of encoding is good at handling unseen data. As the unseen token is often on the leaf node of the AST, if we continue to abstract important information from the leaves to the root, the impact of unseen data on leaves is often reduced. Meanwhile, the standard LSTM model treats all tokens equally. When encountering unseen tokens, the standard LSTM model handles the unseen token, and information bias appears. The information bias can be accumulated if there are many unseen data in a long sequence. This problem is called . The ability to reduce the impact of the unseen tokens is the key to performance improvement. In summary, the top-1 prediction accuracy on the test set is representative, with HLM performing better in terms of top-1 accuracy than all other models; hence, we can conclude that HLM outperforms state-of-the-art models in handling data inconsistency.
5. Discussion
This paper proposes a new mechanism to generate the embedding for predicting next code tokens. This new mechanism is different from all existing frameworks for language models, and can be used in multi-modal or multi-head mechanism, to integrate the existing old mechanisms together, to improve the model performance. Thus, the newly proposed mechanism is meaningful and can be used as a supplement to existing models. To understand the significance of this work, we need to explain the multi-modal mechanism, or the ensemble learning mechanism, to explain why this newly proposed framework has important significance from a research perspective. In the field of machine learning, ensemble learning has been widely used in various scenarios. For non-deep learning models, they often share different data formats, so they can only be integrated in the final step about voting for the final results. For deep learning models, the data formats in different deep learning models are nearly all the same, that data format is the tensor. Then, the ensemble methods in deep learning systems are more advanced and are called multi-modal, multi-view, or multi-head mechanisms. The multi-modal or multi-head mechanisms have been widely used to improve the model efficiency in deep learning systems. Because the data formats in all deep learning models are tensors, we can easily feed the tensors generated by different deep learning models into a deep neural network, to generate a new tensor, this new tensor can be taken as the embedding generated by combining different deep learning models. The more different the integrated multiple deep learning models are, the more information the resulting tensor contains, which ultimately improves the ability of the model to fit data. Once a different encoding or decoding mechanism is proposed, this new mechanism can be combined with the existing old mechanism, to jointly improve the model efficiency. As the proposed mechanism in this paper is different from all existing mechanisms, thus, it is worthy to spend time to combine the mechanism proposed in this paper with other existing mechanisms, to predict the next code in the future.
The interesting finding for this work is that, through the proposed framework, the tree structure of the source code can be used to reduce the data inconsistency between training and testing. Besides, by capturing the tree structure of code, during training, the number of rounds required to reach the convergence state will also be greatly reduced. The existing works predict tokens one by one. The predicting procedure is also named as the decoding procedure. Even for transformer models, the tokens are also predicted (decoded) one by one. When decoding, the information of already visited tokens will be accumulated in the decoding order. In this paper, we find that the information of already visited tokens can be accumulated in a different order than the traditional decoding order. In fact, based on the tree hierarchy, we use an order opposite to the decoding order to collect information about the nodes that have been visited. The procedure of collecting information of already visited tokens is named as the encoding procedure, and the encoding procedure has been separated from the decoding procedure. This is the key scientific contribution, that the encoding process and the decoding process are separated in a language model. This feature is different from existing language models, including transformers. As far as we know, existing models use the same procedure to encode the sequence and decode the sequence. The framework also shows that the encoding procedure can use tree models, and the decoding procedure can use the traditional sequential model. Note that, the encoding procedure can also use other language models, such as the transformer or the graph model. The decoding procedure can also use other language models, such as the transformer, the graph model, or the tree model. Selecting different models for the encoding procedure and the decoding procedure can have different prediction effects. It is worth performing a lot of experiments to find the best model configuration for the encoding procedure and the decoding procedure, although this will consume a lot of code work. In the future, the pre-training method based on transfer learning could also be combined with the framework proposed in this article, to improve the prediction effect.
6. Conclusions
The Hierarchical Language Model (HLM) is proposed, to handle the hierarchical structure of the code syntax tree. According to our experiments, the use of the HLM results in an improvement of at least 7% in top-1 accuracy, compared with the LSTM model. The proposed HLM method models the tree structure of the code. To be precise, the method takes the brotherhood of nodes, and the parent–child connections between nodes, into consideration. However, there are still other node relationships that need to be considered. For example, the control–flow or data–flow relationships between statements should be considered. A great deal of engineering implementation is required to accurately extract these complex relationships. In future work, we will adopt more advanced program analysis technology to extract the various relationships of the code, and model these relationships in a deep learning system, to further improve the prediction performance.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}