
Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects

Abstract
1. Introduction
- By introducing an attention mechanism, enriching shallow scale features, and boosting context interaction, a novel lightweight small object detection algorithm based on a one-stage framework is proposed, which improves the accuracy and efficiency of small object detection;
- We propose a new method for expanding the diversity of small samples in training data in order to increase the network’s ability to learn from small samples. Simultaneously, we utilize self-collected sample data to increase the number of small identifiers in the training data;
- On the embedded ARM platform, the effectiveness of the proposed algorithm is evaluated on Neural Compute Stick (NCS2), and it can serve as a reference for future work.
2. Related Work
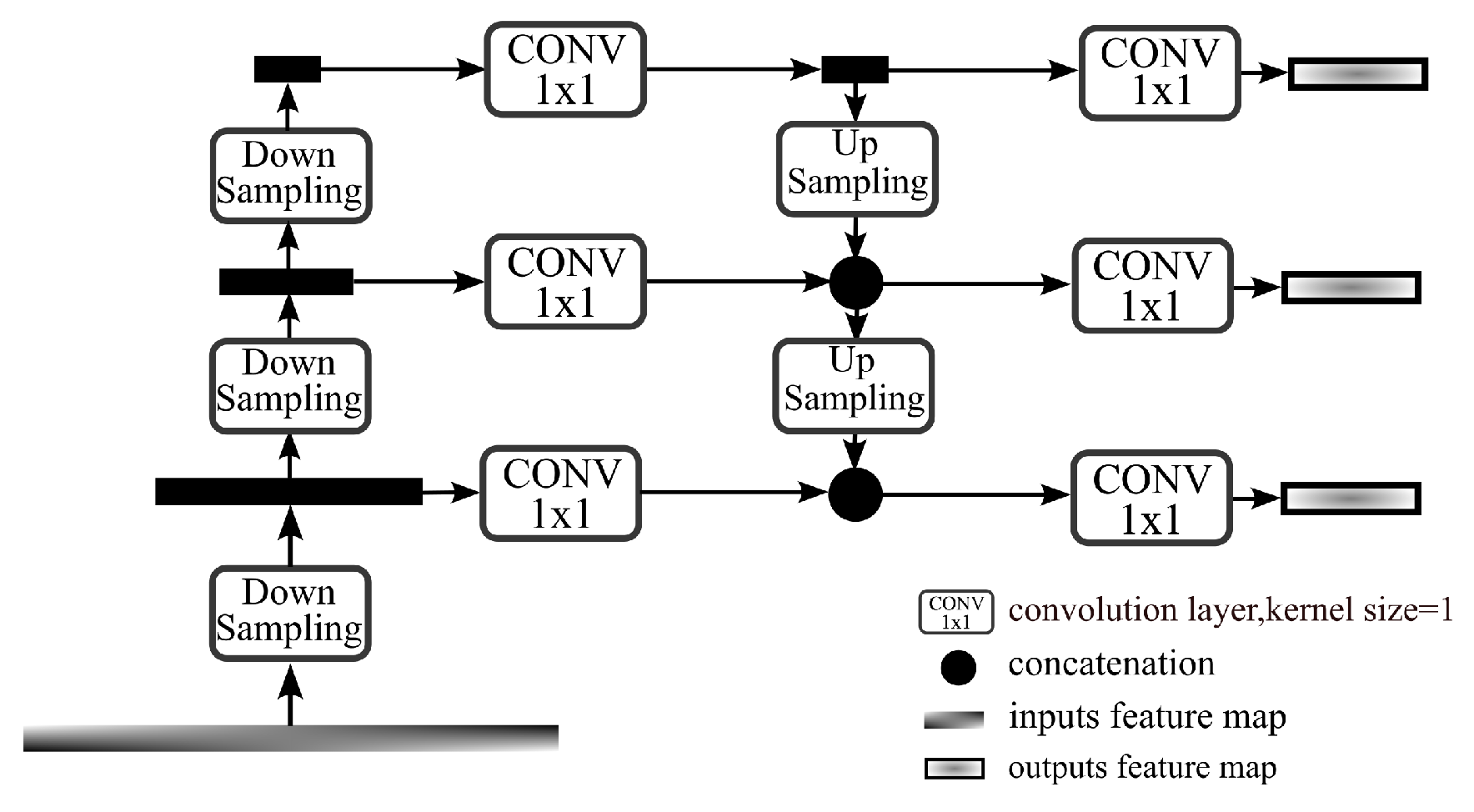
2.1. Multi-Scale Semantic Fusion
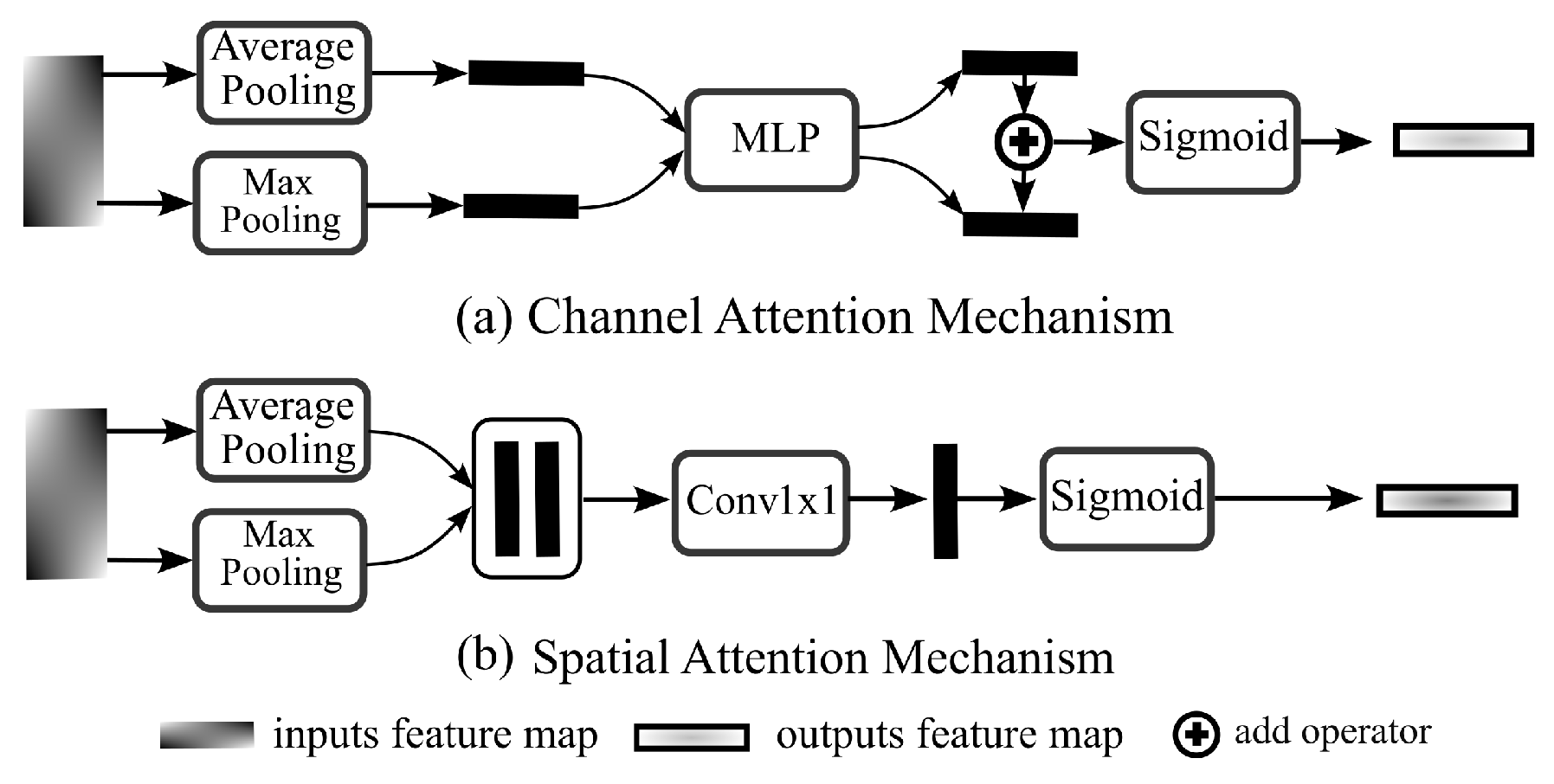
2.2. Attention Mechanism
2.3. Depthwise Separable Convolution and MobileNet
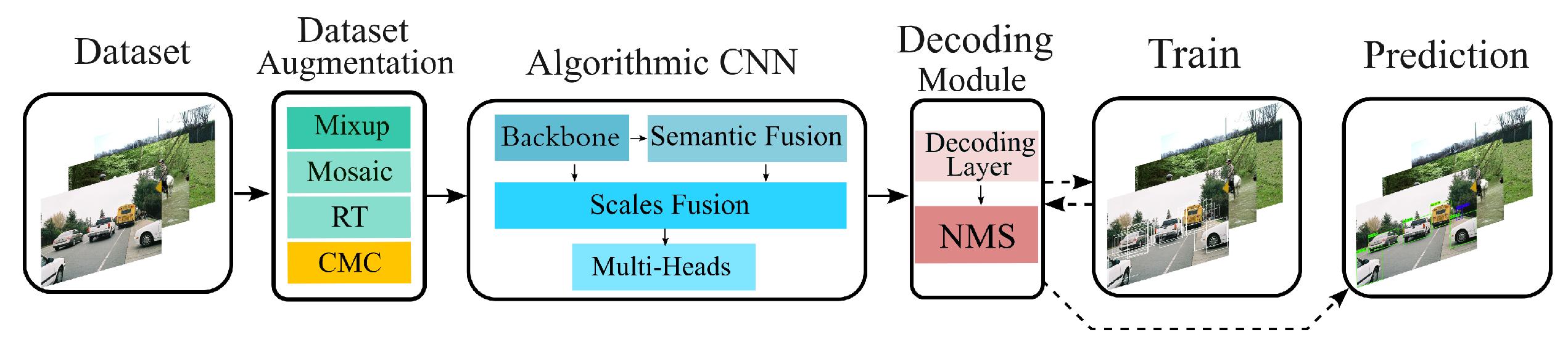
3. Proposed Algorithm
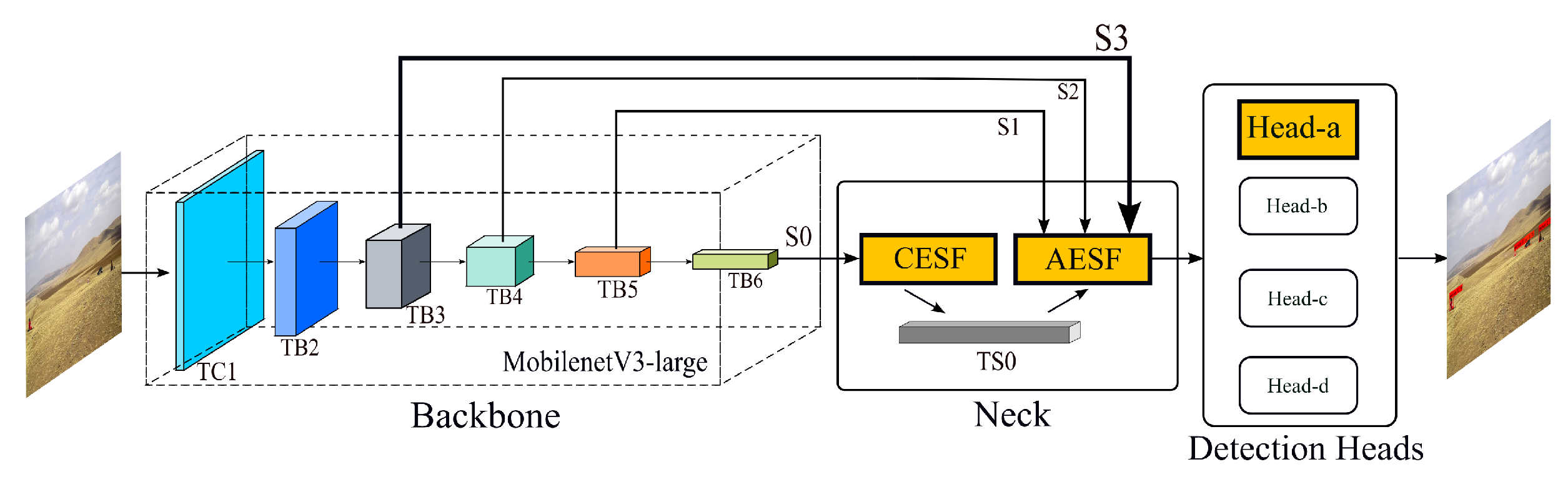
3.1. Overview of Algorithmic Convolutional Neural Network
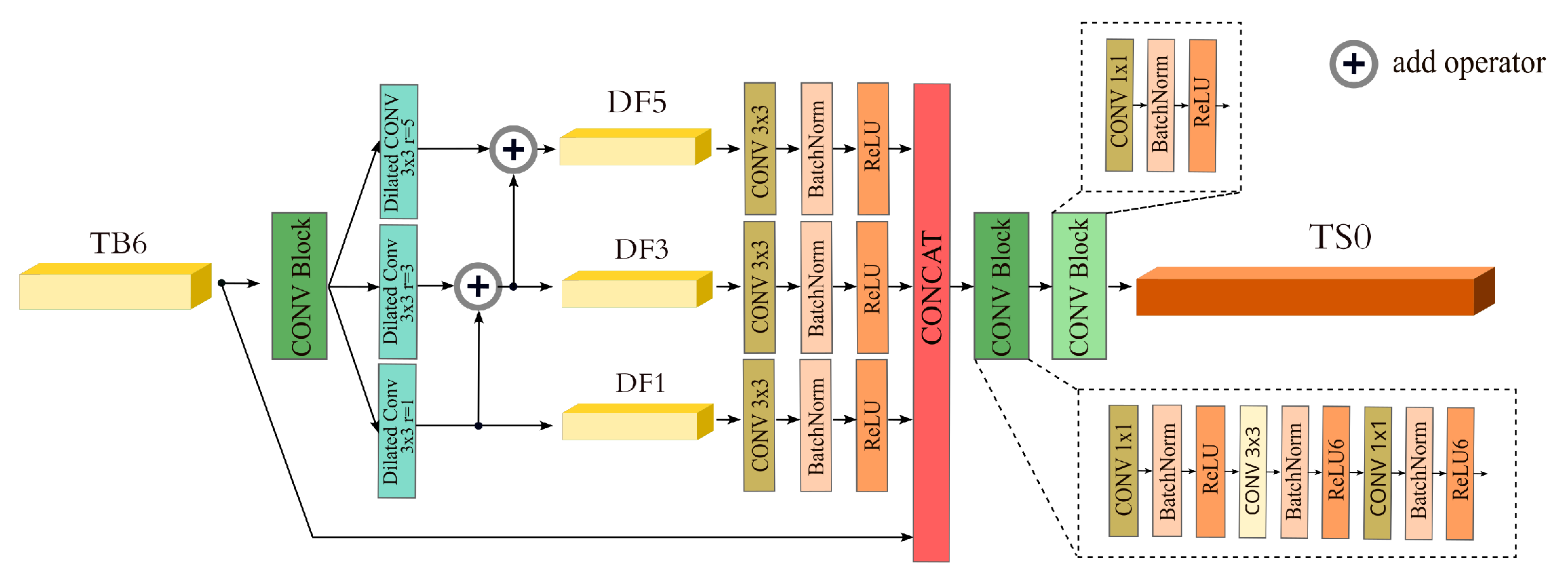
3.2. Efficient Context Enhanced Semantic Fusion
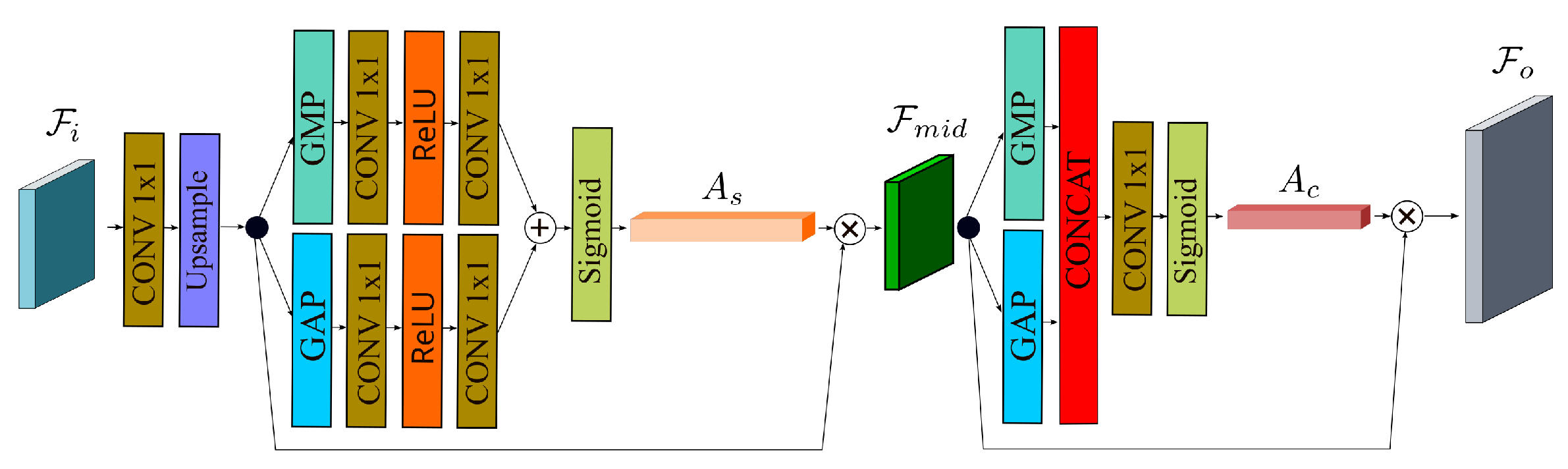
3.3. Attention Enhanced Spatial Scales Fusion
3.4. Data Augmentation
4. Experiments of Training
4.1. Training Environment
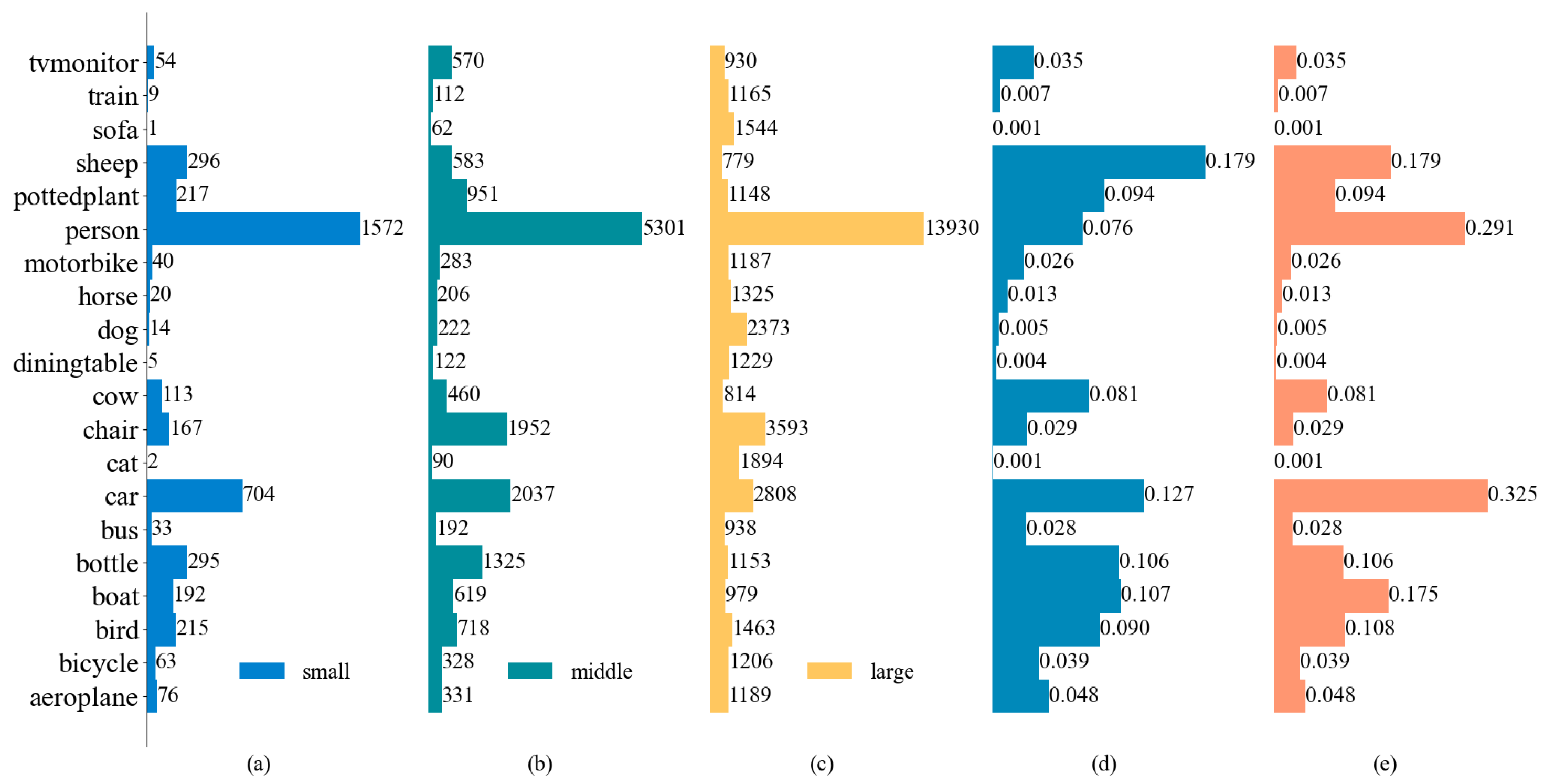
4.2. Training Datasets
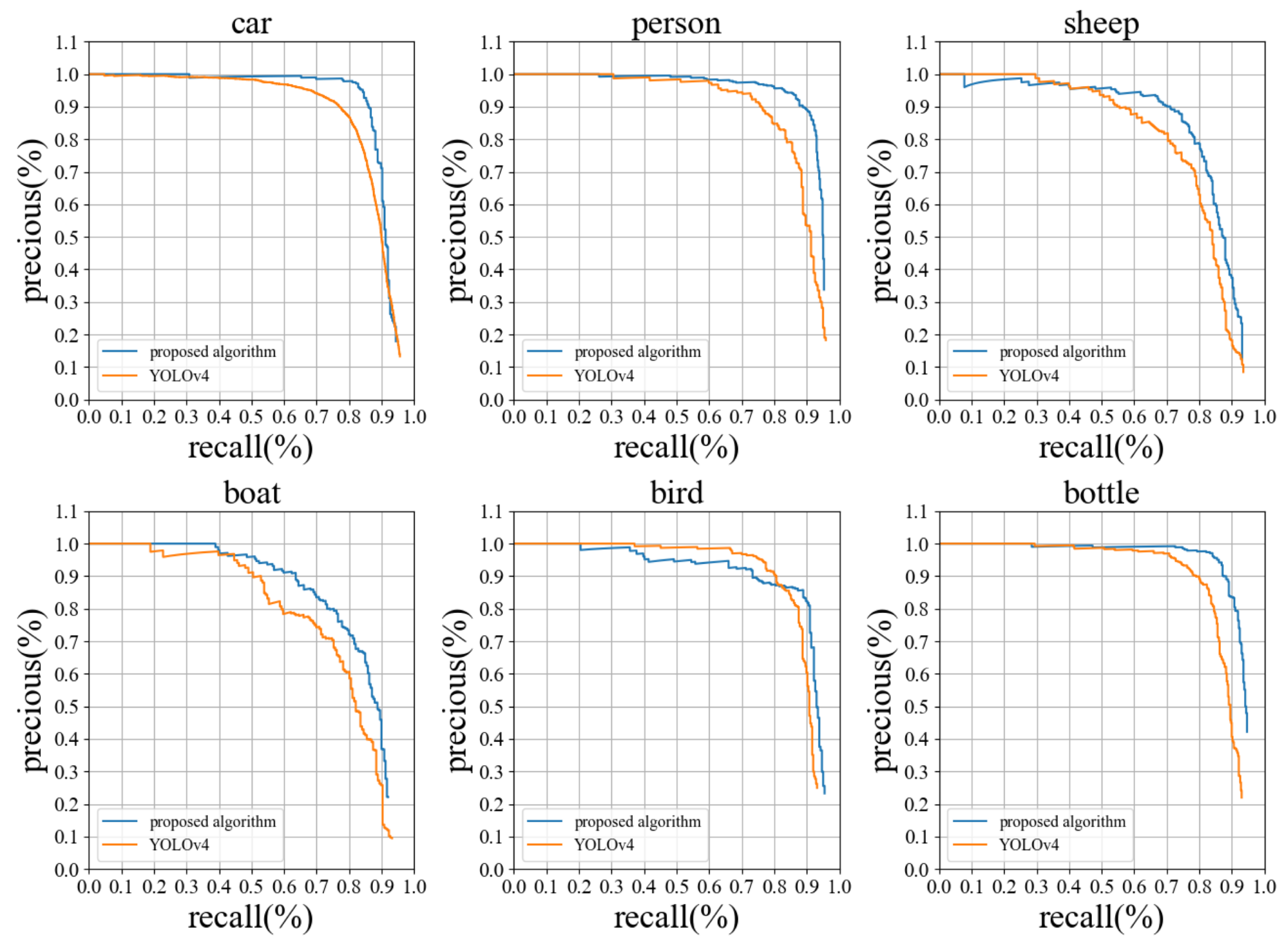
4.3. Performance Evaluation
4.4. Ablation Experiment
5. Deployment Test and Discussion
5.1. Deployment Environment
5.2. Inference Efficiency
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ARM | Advanced RISC Machine |
| CBAM | Convolutional Block Attention Module |
| CFM | Context Fusion Module |
| CMC | Consistent Mixed Cropping |
| CESF | Context Enhanced Semantic Fusion |
| NCS2 | the second generation of Neural Network Stick |
| NMS | Non-Maximum Suppression |
| S2AM | Spatial Scale Attention Module |
| VPU | Video Processing Unit |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
References
- Jawaharlalnehru, A.; Sambandham, T.; Sekar, V.; Ravikumar, D.; Loganathan, V.; Kannadasan, R.; Khan, A.A.; Wechtaisong, C.; Haq, M.A.; Alhussen, A.; et al. Target Object Detection from Unmanned Aerial Vehicle (UAV) Images Based on Improved YOLO Algorithm. Electronics 2022, 11, 2343. [Google Scholar] [CrossRef]
- Haq, M.A. Planetscope Nanosatellites Image Classification Using Machine Learning. Comput. Syst. Sci. Eng. 2022, 42, 1031–1046. [Google Scholar] [CrossRef]
- Haq, M.A. CNN Based Automated Weed Detection System Using UAV Imagery. Comput. Syst. Sci. Eng. 2021, 42, 837–849. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 10, 261–318. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 2016 European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv 2017, arXiv:1712.00960. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar] [CrossRef]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside–Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 1, 1904–1916. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, X.; Gong, Y.; Liu, W.; Shi, H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Muller, J.M.; Manmatha, R. ResNeSt: Split-Attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2022; pp. 2736–2746. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Neubeck, A.; Van, G. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Official Documentation for OpenVINO by Intel. Available online: https://docs.openvino.ai/latest/home.html (accessed on 1 January 2022).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
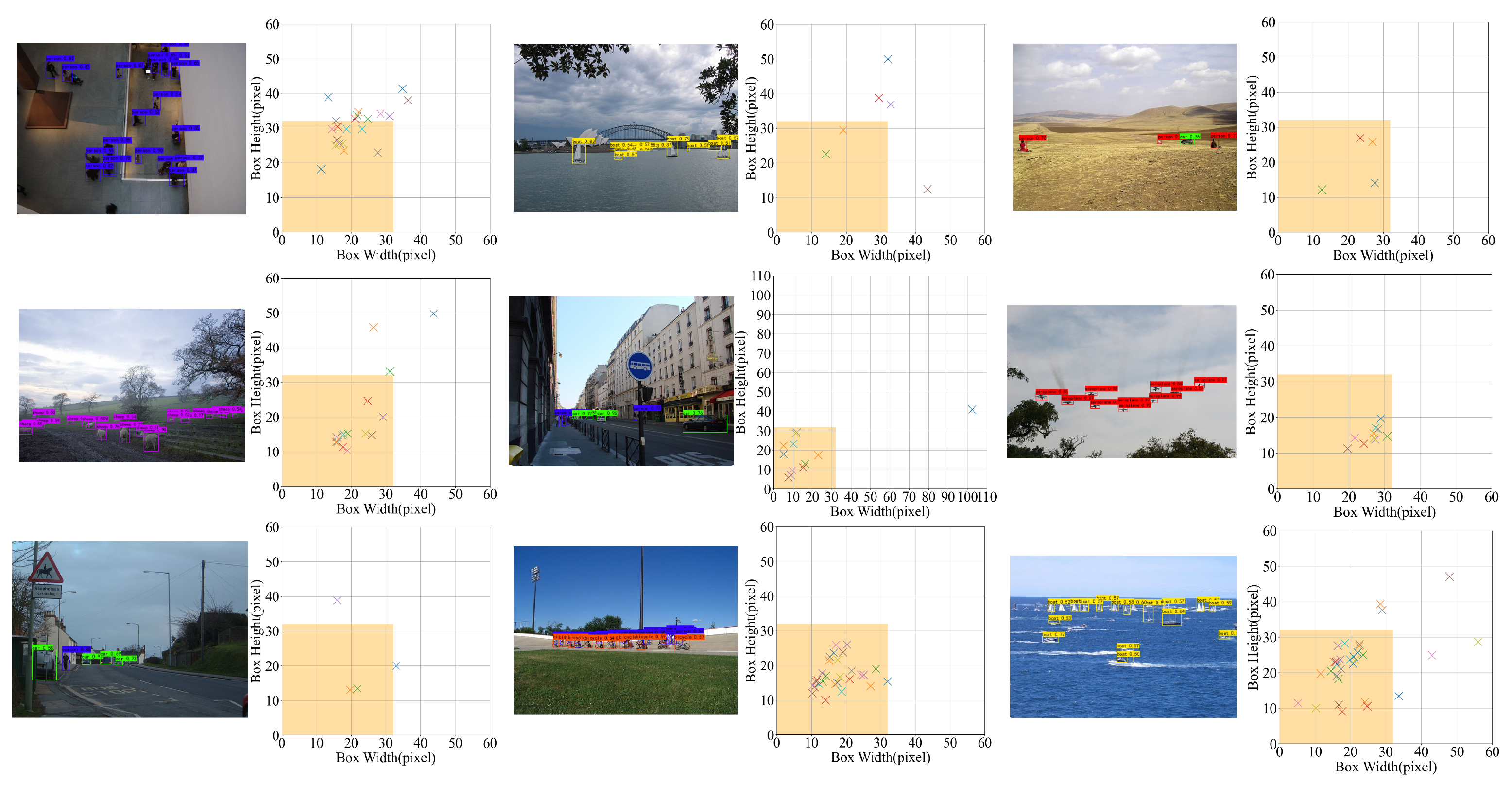{kind=link}
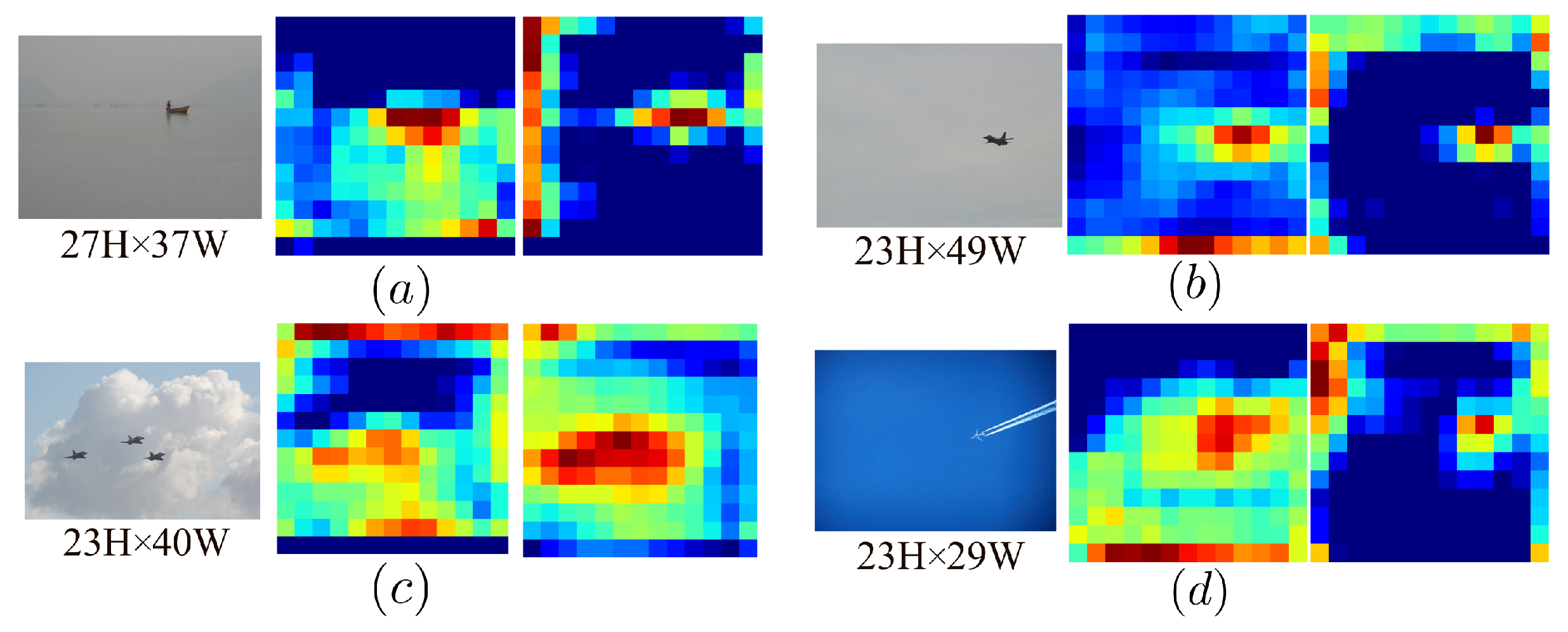{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Backbone | mAP (%) |
|---|---|---|
| FasterR-CNN [8] | VGG16 [32] | 76.5 |
| FasterR-CNN [8] | ResNet101 [33] | 83.8 |
| FastR-CNN [7] | ResNet101 [33] | 71.5 |
| FSSD [13] | VGG16 [32] | 82.0 |
| YOLOv3 [10] | Darknet53 [10] | 76.8 |
| YOLOv4 [11] | CSPDarknet53 [34] | 85.9 |
| SSD [12] | VGG16 [32] | 77.5 |
| proposed | MobilenetV3-Large [14] | 90.5 |
| Category | Percentage | Proposed Algorithm | YOLOv4 | ||||
|---|---|---|---|---|---|---|---|
| 32.5 | 92.69 | 95.55 | 80.40 | 88.57 | 94.51 | 75.77 | |
| 29.1 | 92.13 | 93.83 | 77.67 | 87.34 | 93.82 | 73.25 | |
| 17.9 | 90.35 | 87.93 | 82.93 | 86.44 | 86.67 | 70.73 | |
| 17.4 | 83.10 | 89.69 | 63.54 | 78.01 | 91.95 | 58.39 | |
| 10.8 | 88.61 | 95.29 | 76.78 | 87.36 | 91.43 | 75.83 | |
| 10.6 | 81.49 | 90.10 | 66.54 | 77.77 | 93.33 | 59.92 | |
| Method | mAP (%) |
|---|---|
| MobileNetV3-Large + CFM | 88.0 (2.1↑) |
| MobileNetV3-Large + S2AM | 86.5 (0.6↑) |
| MobileNetV3-Large + CMC | 87.6 (1.7↑) |
| MobileNetV3-Large + CFM+S2AM | 88.9 (3.0↑) |
| MobileNetV3-Large + CFM+CMC | 88.5 (2.6↑) |
| MobileNetV3-Large + S2AM+CMC | 90.2 (4.3↑) |
| proposed algorithm | 90.5 |
| Algorithm | Params (M) | GMAdds | GFLOPs | Runtime (ms) | FPS |
|---|---|---|---|---|---|
| YOLOv4 | 64.5 | 59.8 | 29.9 | 60.6 | 16.5 |
| YOLOv4-tiny | 5.9 | 6.8 | 3.4 | 26.0 | 38.4 |
| proposed | 15.4 | 7.2 | 3.6 | 29.2 | 34.2 |
| Algorithm | Inference Engine | Latency (ms) | FPS | ||||
|---|---|---|---|---|---|---|---|
| Decoding | Preprocessing | Inference | Postprocessing | Rending | |||
| YOLOv4 | VPU | 8.8 | 5.2 | 1778.9 | 104.5 | 0.6 | 0.5 |
| CPU | 4.8 | 1.3 | 554.5 | 12.5 | 0.1 | 1.8 | |
| GPU | 2.7 | 1.6 | 257.6 | 14.6 | 0.2 | 3.6 | |
| YOLOv4-tiny | VPU | 5.6 | 5.6 | 155.6 | 17.1 | <0.1 | 5.6 |
| CPU | 2.8 | 1.1 | 44.9 | 1.9 | <0.1 | 20.7 | |
| GPU | 2.7 | 1.3 | 17.4 | 1.5 | <0.1 | 20.3 | |
| proposed * | VPU | / | / | 146.1 | / | / | 6.5 |
| CPU | / | / | 21.3 | / | / | 28.5 | |
| GPU | / | / | 35.8 | / | / | 18.5 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, N.; Wei, Z.; Li, B. Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects. Electronics 2023, 12, 1607. https://doi.org/10.3390/electronics12071607
Jia N, Wei Z, Li B. Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects. Electronics. 2023; 12(7):1607. https://doi.org/10.3390/electronics12071607
Chicago/Turabian StyleJia, Nan, Zongkang Wei, and Bangyu Li. 2023. "Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects" Electronics 12, no. 7: 1607. https://doi.org/10.3390/electronics12071607
APA StyleJia, N., Wei, Z., & Li, B. (2023). Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects. Electronics, 12(7), 1607. https://doi.org/10.3390/electronics12071607