1. Introduction
With the development and popularization of the Internet and related mobile devices, social networks became an important part of people’s lives. A large number of people share their lives, work, or exchange information with each other on multiple social networking platforms to meet their different social requirements. For example, a user can either share their daily life on Facebook or express their opinion on Twitter. Although multiple social networks greatly enrich people’s lives, there are many problems involving the joint research and analysis of multiple networks, and the problem of user alignment across social networks came into being. This problem aims to combine multiple social networks to analyze the relationships between nodes and construct a high-quality cross-social network user alignment model to connect the same person on different social networks. This model can be widely used in various fields, such as cross-network recommendation [
1], cross-domain information diffusion [
2,
3], link prediction [
4], and network dynamics analysis [
5].
For user alignment across social networks, some researchers proposed a user alignment method based on user location information. Riederer et al. [
6] utilized the rich user position information in location-based social networks (LBSNs) to propose a POIS algorithm, which started from the user’s trajectory data, analyzed the similarity of user pairs, and designed a general and self-tunable algorithm to align users between two LBSNs. Chen et al. [
7] used kernel density estimation (KDE) to alleviate the data sparsity in measuring user similarity, and further organized location data based on the structure of the grid. Then, they pruned and reduced the search space to improve the efficiency of user alignment.
At the same time, some researchers proposed a large number of cross-social network user alignment methods based on user profile information [
8,
9,
10,
11]. This information includes a variety of profile information about users in two networks, such as usernames, educational experiences, cities of residence, and personal descriptions. It showed that the cross-social network user alignment model based on user profile information is feasible and effective for some social networks. Zhang et al. [
11] proposed MOBIUS, where user similarity between different social networks is measured by extracting some user characteristics, such as prefixes, suffixes, the rarity of usernames, and user habits. Zhao et al. [
12] proposed a BP neural network mapping for social network alignment, which used the BP neural network to obtain the mapping between user name vectors across social networks, changed the classification problem into a mapping problem between vectors, and improved the accuracy of social network alignment. However, in the actual social network scenario, the user’s profile information is difficult to obtain, which involves the user’s privacy. Many user profile information cannot be accessed, and many users will imitate others or forge personal information for various purposes, making the user alignment method based on user profile information difficult to work.
Aiming at the user alignment model based on user profiles, some researchers believed that the same person has a similar structure in different social networks, so they proposed cross-social network user alignment methods based on the user’s local social structure [
13,
14], and user-based local and global social structure [
15]. However, the actual situation is that due to the different service functions of different social networks, the same person has different social network structures in different social networks. In this regard, some researchers applied network embedding representations to cross-social network user alignment. Feng et al. [
16] proposed a hypergraph neural network (HGNN) framework for data representation learning, which encodes higher-order data correlations in the hypergraph structure, and a hyperedge convolution operation to process these correlations achieves good results. On this basis, Chen et al. [
17] proposed a multi-layer graph convolutional network (MGCN) that jointly considers the local network structure and hypergraph structure. In addition, a two-stage spatial coordination mechanism is proposed to efficiently align users across different large-scale social networks. Although user alignment models based on network embedding were proven to be effective, the problem of “too close” representation of network embedding is also unavoidable, which greatly affects the accuracy of the model. Yan et al. [
18] introduced pseudo-anchors to make the distribution of user embedding representations more uniform and proposed a meta-learning algorithm to guide the update of pseudo-anchors, which effectively solved the problem that the network embedding representations are too close. In sparse networks, user network structural similarities are small and difficult to identify. Li et al. [
19] proposed a triple-layer attention mechanism-based network embedding (TANE) method, which learns latent structural information by using the weighted structural similarity of the first-order and second-order neighbors to reduce network sparsity, and fully mines the network structure to identify users. He et al. [
20] proposed a heuristic algorithm based on the attention mechanism HDyNA, which obtained the local importance weight of new nodes in a single network through the attention mechanism. It used the anchor node as supervision information and heuristically learned the local influence driven by the alignment task of new nodes to improve the performance of model alignment across dynamic networks. To reduce the expression of noise edges for structural consistency across social networks, Liu et al. [
21] proposed a network structure denoising framework, which learned the user network topology and removes noise edges by iterative learning through a parameter sharing encoder and graph neural network (GNN) to improve the structural similarity across networks. Zheng et al. [
22] considered the influence of distribution differences between different networks on model performance, and a periodically consistent adversarial mapping model (CAMU) was proposed, which learned the mapping function across potential representation spaces and solved the representation distribution difference through adversarial training between the mapping function and discriminator. In addition, periodic consistency training can alleviate the overfitting problem and reduce the number of labeled users required. The comparisons of the user alignment models are listed in
Table 1. Most of the existing models did not assign weight and some of them assigned local weight and had the problem of “over-smooth”.
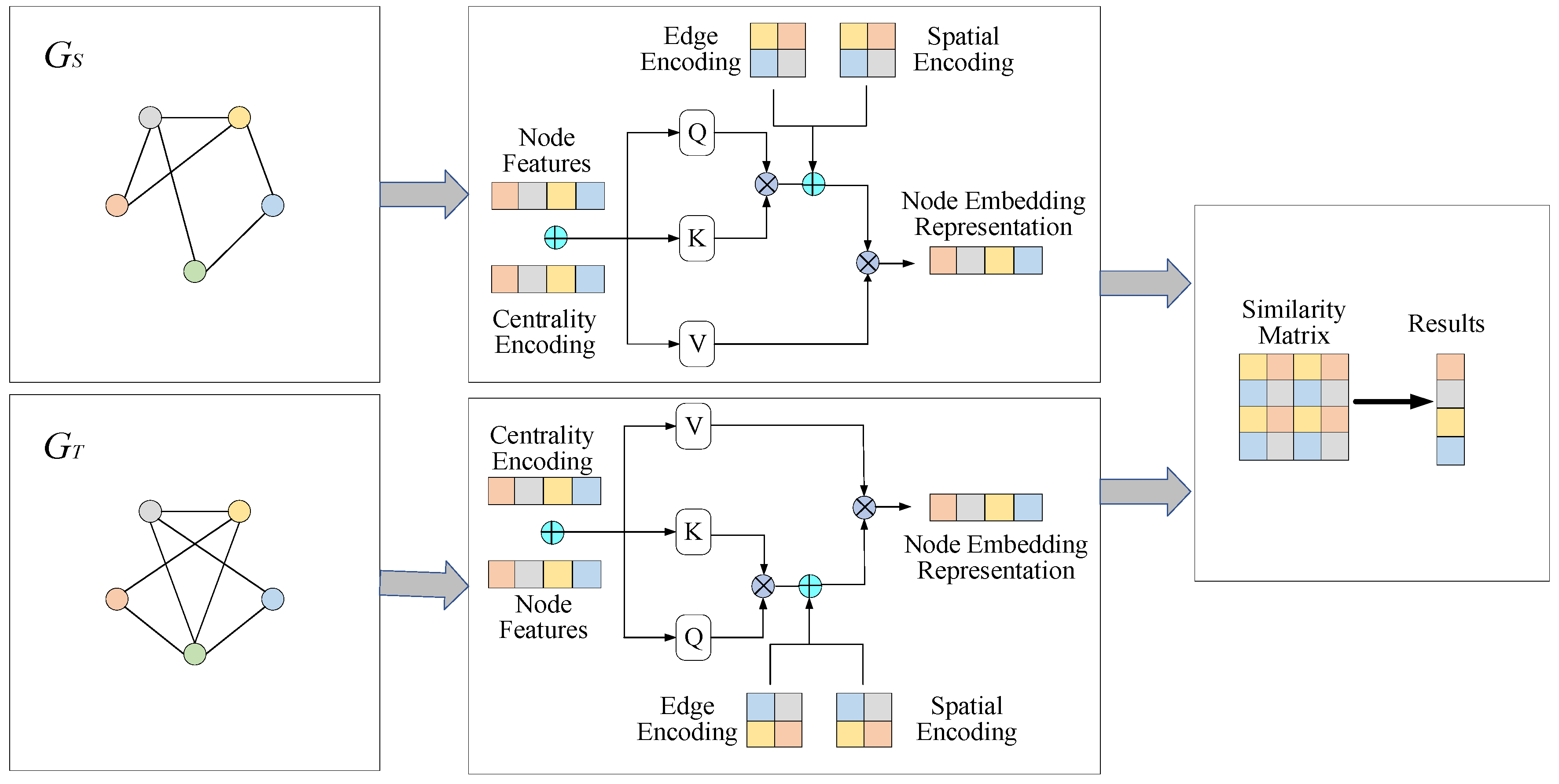
However, the above methods based on GNN to mine user network structure information will appear “over-smooth” with the deepening of the number of network layers. That is to say, the characteristics of all nodes in the same connected component tend to be consistent after multiple convolution operations, resulting in an extreme decrease in the effect of the model. Inspired by Yin et al. [
23], graph structure information is encoded into the model via Transformer. To fill the research gaps, a Transformer-based user alignment model (TUAM) across social networks is proposed in this paper, which accurately imports the graph structure information into the model through three encoding methods, calculates the semantic similarity between cross-social network nodes, and obtains the accurate expression of network nodes to solve the problem of “over-smooth”.
The main conclusions and novelties of this paper can be summarized as follows: First, a Transformer-based user alignment model (TUAM) is proposed to model node embeddings in social networks. This method transforms the graph structure data into a sequence data type that is convenient for Transformer learning through three novel graph structure encoding methods, which effectively avoids the phenomenon of “over-smooth” of GNN. Second, TUAM can assign the weight of different users’ influence and network structure, accurately model the embedding vector of users, and improve the accuracy of social network alignment. Third, experiments on real datasets Facebook–Twitter and Weibo–Douban show that the results of the proposed model are superior to existing models.
4. Datasets and Experiments
4.1. Datasets
The datasets used in the experiment are two real-world datasets from Cao [
40]: Facebook–Twitter and Weibo–Douban. Both datasets are collected from public information in the social network, so there is no privacy breach.
Table 2 lists this data and some basic information.
Facebook–Twitter: Facebook and Twitter are both social networking platforms with large numbers of users, and the dataset was collected through third-party platforms dedicated to linking users, collecting a total of 1,107,695 accounts, of which 422,291 accounts were related to Facebook, 669,198 accounts were related to Twitter, and 328,224 pairs of users were associated between the two datasets.
Weibo–Douban: Weibo and Douban are China’s largest microblogging sites and movie rating sites, respectively. For the Douban dataset, there are 1,694,399 active users, of which 141,614 are associated with Weibo users. In addition to having social relationships in Weibo’s network with Douban, the dataset also collects user-generated content, such as Douban’s movie rating history and Weibo’s blog history. The average user has 287 blogs and 120 rating histories. Here, we only use the information of social connections.
In
Table 2,
|V| is the number of users,
|E| is the number of edges, and
|CV| is the number of associated users in the two social networks.
4.2. Comparable Models
DeepWalk: uses random walks to sample the node sequence, and then uses the word2vec model to learn the node embedding.
GCN: extracts features from graph data through GNN for node representation learning, which is widely used in node classification, graph classification, and link prediction.
HGCN: bases on hypergraph convolutional networks for network embedding.
MGCN: combines graph convolutional networks (GCN) and hypergraph convolutional networks to jointly learn network vertex representations at different levels of granularity.
GAT: introduces an attention mechanism based on graph convolution to the weighted summing of the features of neighboring nodes and learning node representation.
4.3. Evaluation Metric
To evaluate the performance of the models, we use the most commonly used evaluation metric: accuracy@K (ACC@K), which is defined as
where
indicates whether the source social network user
corresponds to the user in the target social network
exists in the top
k users, and
N is the total number of test users in the source social network. In addition,
is defined as
4.4. Analysis of Experimental Results
Table 3 and
Table 4 show the experimental results on the Facebook–Twitter and Weibo–Douban datasets, showing that the proposed model outperforms the comparable methods on both datasets.
In this table, the ACC@K, K = 1, 10, 20, and 50 of the existing and proposed user alignment models on the Facebook–Twitter dataset are compared. The results show that the proposed TUAM performs better than other models.
According to
Table 3 and
Table 4, it is illustrated that the TUAM model outperforms other comparable models in the two datasets. When K equals to 10 or 20, the performance of TUAM has the most significant improvement compared to other models. When K = 10, the accuracy rate ACC@10 in Facebook–Twitter and Weibo–Douban improved by 11.61% and 16.53% compared to GAT, respectively. The DeepWalk model embeds nodes by random walk, but this process does not map the node features of the two networks to the same vector space, but directly performs user alignment, which severely reduces the accuracy of the model. GCN model can effectively aggregate the surrounding neighbor information, but it does not consider the importance of each neighbor node, which limits the learning ability of the features of network nodes. HGCN and MGCN are based on GCN, which greatly benefits from the nonlinearity of neural networks, but the modeling of hyperedge is very redundant for non-hypergraph problems, which not only has no benefit to the model, but also reduces the accuracy of the model. The attention mechanism in GAT perfectly solves the problem of GCN, making GAT perform better than GCN in the two datasets, but it is still limited by the “over-smooth” problem and cannot mine the characteristics of network nodes at a deeper level. However, the three encodings of TUAM can learn network structure information as well as GNN, or even better, and will not be limited by the “over-smooth” problem, can mine network node features at a deeper level, and TUAM’s global receptive field makes the model learn higher-level structural features better, so it performs better than other models. The accuracy rates of these models on two datasets are shown in
Figure 2 and
Figure 3.
In
Figure 2 and
Figure 3, it is obvious that the accuracy of TUAM on two datasets is higher than other existing models, especially when K = 50. The ablation experiments on the importance of the three encodings are conducted in TUAM across the Facebook–Twitter and the Weibo–Douban datasets. The ablation results are shown in
Table 4 and
Table 5. The best results are indicated in bold font.
According to
Table 5 and
Table 6, the experimental results show that for the TUAM without centrality coding, spatial coding, or edge coding, the effectiveness of the TUAM decreases. This is because the centrality encoding module can effectively encode the information of different nodes into Transformers to improve the accuracy of model recognition. At the same time, the spatial encoding module and edge encoding can effectively capture the spatial information and structural information of nodes, which is more conducive to the expression of the structural characteristics of the Transformer learning network. The three kinds of encoding methods can effectively convert the graph topology information into sequence data information that is conducive to Transformer learning. TUAM does not need to consider the “over-smooth” phenomenon caused by too-deep layers, such as GCN, and has a larger global receptive field, efficiently learns topology structure features, and improves model performance. The trends of accuracy on Facebook–Twitter and Weibo–Douban datasets of ablation experiments are shown in
Figure 4 and
Figure 5.
It is shown that TUMA with three encoding methods has better performance on accuracy on two datasets compared to the model without one of the three encodings.
5. Conclusions
In this paper, user alignments across social networks were described. The research received a lot of attention in both academia and industry, and was involved in many social network-related applications, such as link prediction, interest recommendation, etc. A Transformer-based user alignment model based on network topology information was proposed to learn the structural information between nodes in the networks. The proposed model is different from the traditional GCN through graph convolution to obtain network structure information from neighbor nodes, but through a specific encoding method to express the graph structure information in the form of sequence data. Experiment results show that the proposed method can better describe the association relationship between node neighbors, has a more accurate vector representation of nodes, and can improve the accuracy of user association matching.
While our approach has certain advantages, there are also some drawbacks. Our work only makes use of the structural information of the network, which is less informative. If additional attribute information is considered, it will be helpful to improve the performance of the model. At the same time, the proposed model cannot be adapted to large-scale graph datasets. Therefore, the future research direction is to build a framework for integrating social network structure information and attribute information on the basis of this user alignment model. In addition, it is necessary to reduce the cost of model calculation to make it suitable for large-scale alignment across social networks.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}