


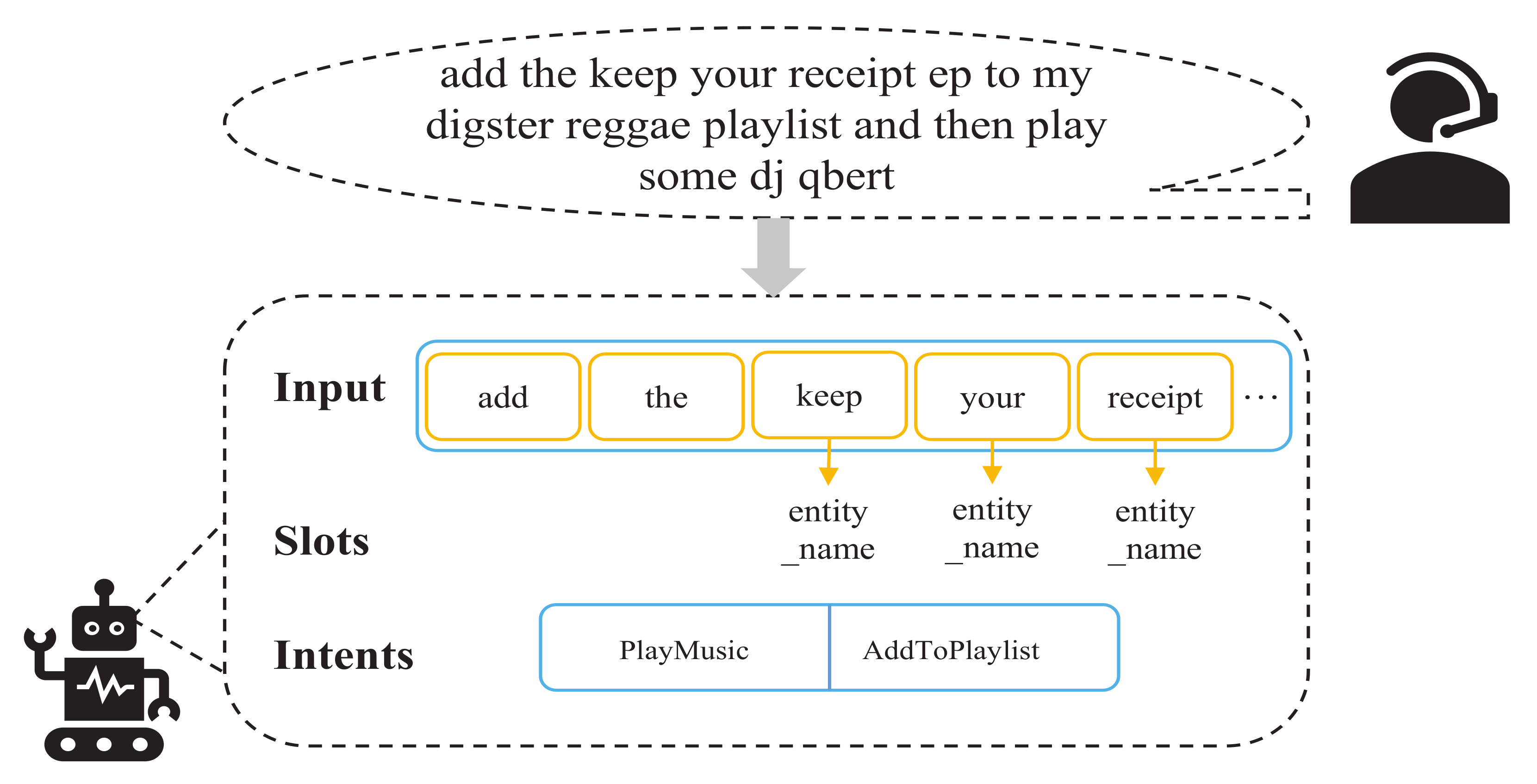
A Unified Approach to Nested and Non-Nested Slots for Spoken Language Understanding


Abstract
1. Introduction
- (1)
- The above model either does not have high enough performance or the inference rate is not fast enough;
- (2)
- The above model did not adequately consider the implied correlation between intentions and slots by filtering the information;
- (3)
- At this stage, all the above models model slot filling as a non-nested task, so none of them can solve the slot nesting problem.
- As far as we know, we have made the first attempt to explore a joint multiple ID and SF method with a global pointer, which can solve not only the nested and non-nested slots problem, but also the slot incoherence problem;
- By constructing a multi-dimensional type-slot label interaction network, which can enhance the implicit association between intents and slots, to ensure the integrity of intent–slot information;
- Our proposed new architecture achieves SOAT on multiple metrics on both public datasets, while having faster inference rates than other baseline models. While doing so, we carried out more in-depth ablation tests to examine the effects of various components on overall performance and serve as a guide for future model development.
2. Related Work
2.1. Intent Detection
2.2. Slot Filling
2.3. Joint Model for Intent Detection and Slot Filling
3. Approach
3.1. Problem Definition
3.2. BERT Encoder
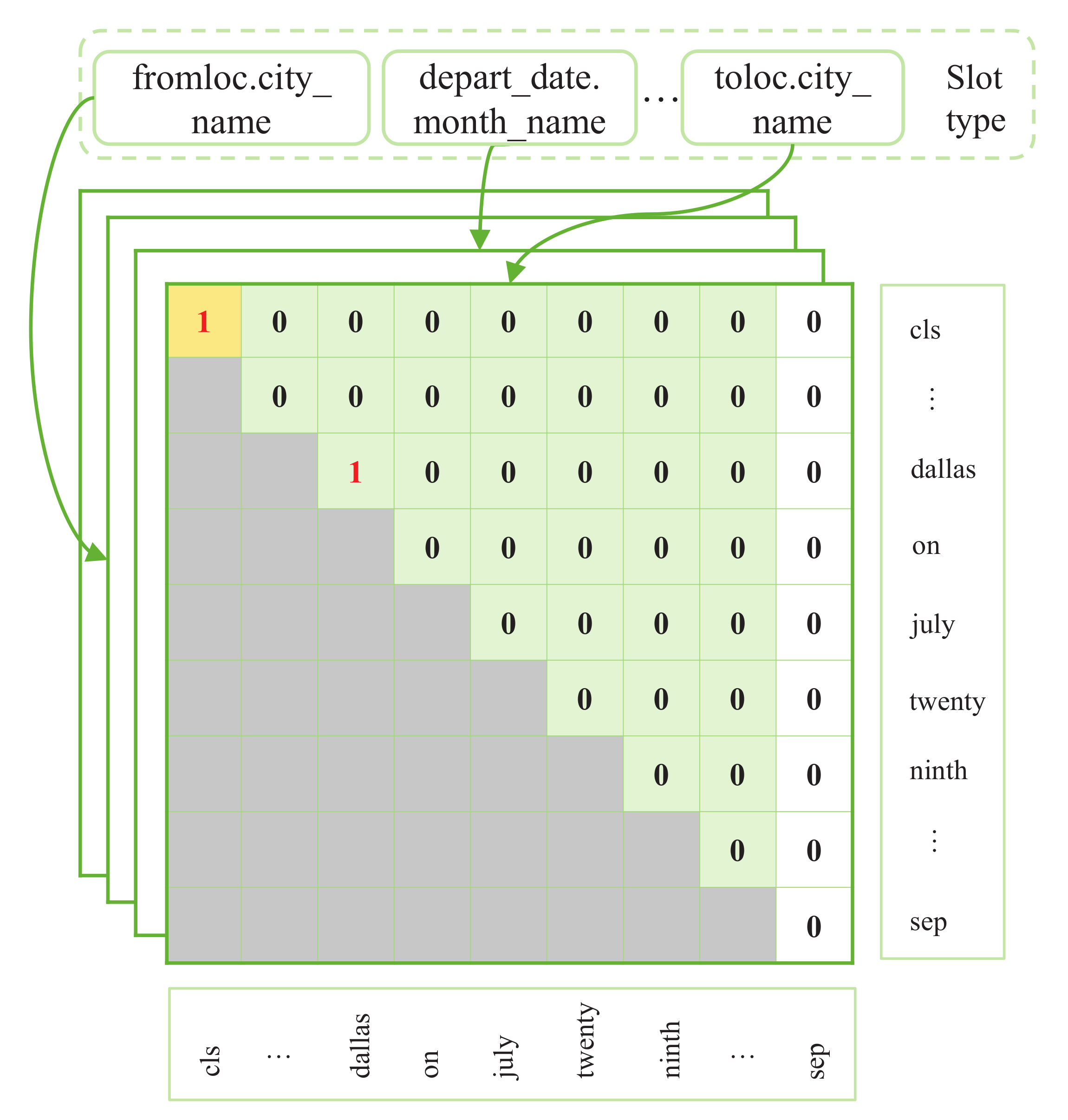
3.3. Multi-Dimensional Type-Slot Label Interaction Network
3.4. Intent Decoding
3.5. Slot Decoding
3.6. Joint Optimization
4. Experimental and Analysis
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Settings
4.4. Baselines
4.5. Main Results
4.6. Analysis
4.6.1. Speedup
4.6.2. Ablation Experiments
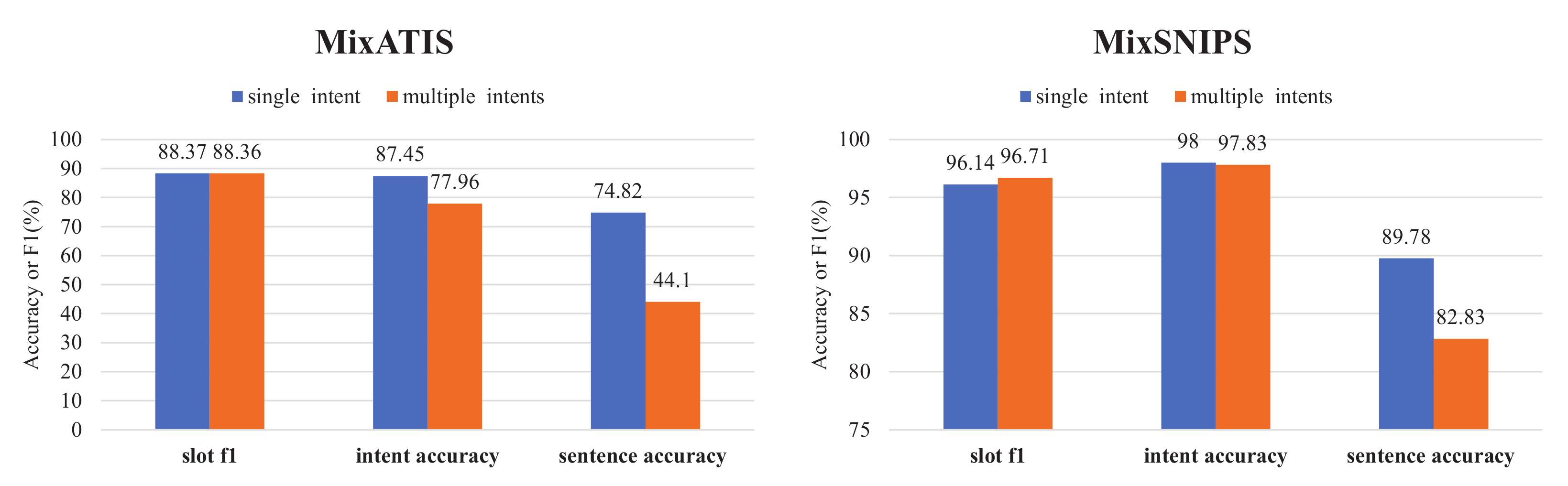
4.6.3. Single-Intent and Multi-Intent Analysis
4.6.4. Error Analysis
- The data set is limited and the distribution of categories is unbalanced. Some slot types are not present in the training set, but appear frequently in the test set. Meanwhile, out of vocabulary (OOV) appears in the test set;
- The second reason is the annotation error. As shown in Table 5, the intent of the first sample was manually marked as “aircraft”. Nevertheless, we note that the question refers to the number of different aircraft types. By observation, the red word in the second sample should be labeled “”, but it was marked as “”. Meanwhile, the results predicted by the MTLN-GP model are generally consistent with the actual observations;
- Irrelevant information can mislead the prediction results. As shown in Table 5, the proposed model is misled by the slot information and therefore outputs the wrong intention. The actual content of the sentence is “what days of the week”.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tur, G.; de Mori, R. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; JohnWiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Wu, J.; Harris, I.G.; Zhao, H. Spoken Language Understanding for Task-oriented Dialogue Systems with Augmented Memory Networks. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2021), Online, 6–11 June 2021; pp. 797–806. [Google Scholar]
- Zhang, X.; Wang, H. A joint model of intent determination and slot filling for spoken language understanding. Int. Jt. Conf. Artif. Intell. 2016, 16, 2993–2999. [Google Scholar]
- Liu, B.; Lane, I. Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling. Interspeech 2016, 2016, 685–689. [Google Scholar]
- Goo, C.W.; Gao, G.; Hsu, Y.K.; Huo, C.L.; Chen, T.C.; Hsu, K.W.; Chen, Y.N. Slot-gated modeling for joint slot filling and intent prediction. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2, pp. 753–757. [Google Scholar]
- Wang, Y.; Shen, Y.; Jin, H. A Bi-Model Based RNN Semantic Frame Parsing Model for Intent Detection and Slot Filling. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2, pp. 309–314. [Google Scholar]
- Haihong, E.; Niu, P.; Chen, Z.; Song, M. A Novel Bi-directional Interrelated Model for Joint Intent Detection and Slot Filling. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL2019), Florence, Italy, 28 July–2 August 2019; pp. 5467–5471. [Google Scholar]
- Qin, L.; Che, W.; Li, Y.; Wen, H.; Liu, T. A Stack-Propagation Framework with Token-Level Intent Detection for Spoken Language Understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 2078–2087. [Google Scholar]
- Chen, Q.; Zhuo, Z.; Wang, W. Bert for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Pang, Y.; Yu, P.; Zhang, Z. A Typed Iteration Approach for Spoken Language Understanding. Electronics 2022, 11, 2793. [Google Scholar] [CrossRef]
- He, T.; Xu, X.; Wu, Y.; Wang, H.; Chen, J. Multitask learning with knowledge base for joint intent detection and slot filling. Appl. Sci. 2021, 11, 4887. [Google Scholar] [CrossRef]
- Wu, D.; Ding, L.; Lu, F.; Xie, J. SlotRefine: A Fast Non-Autoregressive Model for Joint Intent Detection and Slot Filling. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 1932–1937. [Google Scholar]
- Qin, L.; Liu, T.; Che, W.; Kang, B.; Zhao, S.; Liu, T. A co-interactive transformer for joint slot filling and intent detection. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 8193–8197. [Google Scholar]
- Li, C.; Li, L.; Qi, J. A self-attentive model with gate mechanism for spoken language understanding. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3824–3833. [Google Scholar]
- Liu, Y.; Meng, F.; Zhang, J.; Zhou, J.; Chen, Y.; Xu, J. CM-Net: A Novel Collaborative Memory Network for Spoken Language Understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1051–1060. [Google Scholar]
- Hakkani-Tür, D.; Tür, G.; Celikyilmaz, A. Multi-domain joint semantic frame parsing using bi-directional rnn-lstm. Interspeech 2016, 2016, 715–719. [Google Scholar]
- Sun, C.; Lv, L.; Liu, T.; Li, T. A joint model based on interactive gate mechanism for spoken language understanding. Appl. Intell. 2022, 52, 6057–6064. [Google Scholar] [CrossRef]
- Tang, H.; Ji, D.; Zhou, Q. End-to-end masked graph-based CRF for joint slot filling and intent detection. Neurocomputing 2020, 413, 348–359. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, Y.; Shou, L.; Gong, M.; Wang, H.; Zeng, M. A joint and domain-adaptive approach to spoken language understanding. arXiv 2021, arXiv:2107.11768. [Google Scholar]
- Qin, L.; Wei, F.; Ni, M.; Zhang, Y.; Che, W.; Li, Y.; Liu, T. Multi-domain spoken language understanding using domain-and task-aware parameterization. Trans. Asian -Low-Resour. Lang. Inf. Process. 2022, 21, 1–17. [Google Scholar] [CrossRef]
- Lee, J.; Sarikaya, R.; Kim, Y.B. Locale-agnostic Universal Domain Classification Model in Spoken Language Understanding. arXiv 2019, arXiv:1905.00924. [Google Scholar]
- Gangadharaiah, R.; Narayanaswamy, B. Joint multiple intent detection and slot labeling for goal-oriented dialog. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 564–569. [Google Scholar]
- Chen, L.; Zhou, P.; Zou, Y. Joint multiple intent detection and slot filling via self-distillation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7612–7616. [Google Scholar]
- Qin, L.; Xu, X.; Che, W.; Liu, T. AGIF: An Adaptive Graph-Interactive Framework for Joint Multiple Intent Detection and Slot Filling. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; pp. 1807–1816. [Google Scholar]
- Qin, L.; Wei, F.; Xie, T.; Xu, X.; Liu, T. GL-GIN: Fast and Accurate Non-Autoregressive Model for Joint Multiple Intent Detection and Slot Filling. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual Conference, 1–6 August 2021; Volume 1, pp. 178–188. [Google Scholar]
- Huang, B.; Carley, K.M. Syntax-Aware Aspect Level Sentiment Classification with Graph Attention Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5469–5477. [Google Scholar]
- Su, J.; Murtadha, A.; Pan, S.; Hou, J.; Sun, J.; Huang, W.; Liu, Y. Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition. arXiv 2022, arXiv:2208.03054. [Google Scholar]
- Schapire, R.E.; Singer, Y. BoosTexter: A boosting-based system for text categorization. Mach. Learn. 2000, 39, 135–168. [Google Scholar] [CrossRef]
- Ravuri, S.; Stolcke, A. Recurrent neural network and LSTM models for lexical utterance classification. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Zhang, Y.; Wallace, B.C. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; Volume 1, pp. 253–263. [Google Scholar]
- Chen, Y. Convolutional Neural Network for Sentence Classification. Master’s Thesis, University of Waterloo, Waterloo, ON, Canada, 2015. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 17th Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 26–28 October 2014; pp. 1532–1543. [Google Scholar]
- Caselles-Dupré, H.; Lesaint, F.; Royo-Letelier, J. Word2vec applied to recommendation: Hyperparameters matter. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 352–356. [Google Scholar]
- Kim, J.K.; Tur, G.; Celikyilmaz, A.; Cao, B.; Wang, Y.Y. Intent detection using semantically enriched word embeddings. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 414–419. [Google Scholar]
- Srivastava, H.; Varshney, V.; Kumari, S. A novel hierarchical BERT architecture for sarcasm detection. In Proceedings of the Second Workshop on Figurative Language Processing, Online, 9 July 2020; pp. 93–97. [Google Scholar]
- Raymond, C.; Riccardi, G. Generative and discriminative algorithms for spoken language understanding. In Proceedings of the Interspeech 2007—8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007. [Google Scholar]
- Wu, Y.; Jiang, L.; Yang, Y. Switchable novel object captioner. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1162–1173. [Google Scholar] [CrossRef] [PubMed]
- Simonnet, E.; Camelin, N.; Deléglise, P.; Esteve, Y. Exploring the use of attention-based recurrent neural networks for spoken language understanding. In Proceedings of the Machine Learning for Spoken Language Understanding and Interaction NIPS 2015 Workshop (SLUNIPS 2015), Montreal, QC, Canada, 11 December 2015. [Google Scholar]
- Saha, T.; Saha, S.; Bhattacharyya, P. Exploring deep learning architectures coupled with crf based prediction for slot-filling. In Neural Information Processing, Proceedings of the 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 214–225. [Google Scholar]
- Cai, F.; Zhou, W.; Mi, F. SLIM: Explicit slot–intent Mapping with BERT for Joint Multi-Intent Detection and Slot Filling. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 7607–7611. [Google Scholar]
- Su, J.; Lu, Y.; Pan, S.; Murtadha, A.; Wen, B.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. arXiv 2021, arXiv:2104.09864. [Google Scholar]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS spoken language systems pilot corpus. In Speech and Natural Language: Proceedings of the Workshop Held at Hidden Valley, Jefferson Township, PA, USA, 24–27 June 1990; Morgan Kaufmann Publishers, Inc.: San Mateo, CA, USA, 1990. [Google Scholar]
- Coucke, A.; Saade, A.; Ball, A.; Bluche, T.; Caulier, A.; Leroy, D.; Doumouro, C.; Gisselbrecht, T.; Caltagirone, F.; Lavril, T.; et al. Snips voice platform: An embedded spoken language understanding system for private-by-design voice interfaces. arXiv 2018, arXiv:1805.10190. [Google Scholar]
- Zhang, Z.; Zhang, Z.; Chen, H.; Zhang, Z. A joint learning framework with bert for spoken language understanding. IEEE Access 2019, 7, 168849–168858. [Google Scholar] [CrossRef]
- Girija, S.S. Tensorflow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 20 June 2021).
- Miyato, T.; Dai, A.M.; Goodfellow, I. Adversarial training methods for semi-supervised text classification. arXiv 2016, arXiv:1605.07725. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | MixATIS | MixSNIPS |
|---|---|---|
| Training | 13,162 | 39,776 |
| Validation | 759 | 2198 |
| testing | 828 | 2199 |
| Intent | 18 | 7 |
| Slot | 78 | 39 |
| Vocabulary size | 827 | 9632 |
| Model | MixATIS | MixSNIPS | ||||
|---|---|---|---|---|---|---|
| Slot(F1) | Intent(Acc) | Overall(Acc) | Slot(F1) | Intent(Acc) | Overall(Acc) | |
| Attention BiRNN [4] | 86.4 | 74.6 | 39.1 | 89.4 | 95.4 | 59.5 |
| Slot-Gated [5] | 87.7 | 63.9 | 35.3 | 87.9 | 94.6 | 55.4 |
| Bi-Model [6] | 83.9 | 70.3 | 34.4 | 90.7 | 95.6 | 63.4 |
| SF-ID [7] | 87.4 | 66.2 | 34.9 | 90.6 | 95.0 | 59.9 |
| Stack-ropagation [8] | 87.8 | 72.1 | 40.1 | 94.2 | 96.0 | 72.9 |
| Joint Multiple ID-SF [22] | 84.6 | 73.4 | 36.1 | 90.6 | 95.1 | 62.9 |
| AGIF [24] | 86.7 | 74.4 | 40.8 | 94.2 | 95.1 | 74.2 |
| GL-GIN [25] | 88.3 | 76.3 | 43.5 | 94.9 | 95.6 | 75.4 |
| SDJN [23] | 88.2 | 77.1 | 44.6 | 94.4 | 96.5 | 75.7 |
| SDJN+BERT [23] | 87.5 | 78.0 | 46.3 | 95.4 | 96.7 | 79.3 |
| Joint BERT [9] | 86.1 | 74.8 | 44.8 | 95.6 | 96.2 | 79.8 |
| MTLN-GP (ours) | 88.4 * | 79.6 * | 49.4 * | 96.7 * | 97.9 * | 84.3 * |
| Model | Decode Latency(s) | Speedup |
|---|---|---|
| Stack-propagation [8] | 34.5 | 1.4× |
| Joint Multiple ID-SF [22] | 45.3 | 1.1× |
| AGIF [24] | 48.5 | 1.0× |
| GL-GIN [25] | 4.2 | 11.5× |
| Joint BERT [9] | 2.3 | 21.1× |
| MTLN-GP | 3.1 | 15.6× |
| Model | MixATIS | MixSNIPS | ||||
|---|---|---|---|---|---|---|
| Slot(F1) | Intent(Acc) | Overall(Acc) | Slot(F1) | Intent(Acc) | Overall(Acc) | |
| Joint BERT [9] | 86.1 | 74.8 | 44.8 | 95.6 | 96.2 | 79.8 |
| MSLN-GP | 88.2 | 78.3 | 47.2 | 95.9 | 97.1 | 82.6 |
| MTLN-GP | 87.9 | 78.4 | 47.8 | 96.3 | 97.4 | 83.3 |
| MTLN-GP by Max Pooling | 88.2 | 79.3 | 48.9 | 96.7 | 97.6 | 84.1 |
| MTLN-GP by Mean Pooling | 88.1 | 79.4 | 49.1 | 96.6 | 97.6 | 83.9 |
| MTLN-GP | 88.4 | 79.6 | 49.4 | 96.7 | 97.9 | 84.3 |
| Model | Golden Slots | Golden Intent |
|---|---|---|
| Text | at the charlotte airport how many different types of aircraft are there for us air | |
| Golden | ★★ city_name city_name ★ ★ ★ ★ ★ ★ ★ ★ ★ airline_name airline_name | atis_aircraft |
| MTLN-GP | ★★ city_name city_name ★ ★ ★ ★ ★ ★ ★ ★ ★ airline_name airline_name | atis_quantity |
| Text | list the distance in miles from boston airport to downtown boston | |
| Golden | ★★★★★★ fromloc.airport_name fromloc.airport_name ★ ★ city_name | atis_distance |
| MTLN-GP | ★★★★★★ fromloc.airport_name fromloc.airport_name ★ ★ toloc.city_name | atis_distance |
| Text | what days of the week do flights from san jose to nashville fly on | |
| Golden | ★★★★★★★★ fromloc.city_name fromloc.city_name ★ toloc.city_name ★ ★ | atis_day_name |
| MTLN-GP | ★★★★★★★★ fromloc.city_name fromloc.city_name ★ toloc.city_name ★ ★ | atis_flight |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wan, X.; Zhang, W.; Huang, M.; Feng, S.; Wu, Y. A Unified Approach to Nested and Non-Nested Slots for Spoken Language Understanding. Electronics 2023, 12, 1748. https://doi.org/10.3390/electronics12071748
Wan X, Zhang W, Huang M, Feng S, Wu Y. A Unified Approach to Nested and Non-Nested Slots for Spoken Language Understanding. Electronics. 2023; 12(7):1748. https://doi.org/10.3390/electronics12071748
Chicago/Turabian StyleWan, Xue, Wensheng Zhang, Mengxing Huang, Siling Feng, and Yuanyuan Wu. 2023. "A Unified Approach to Nested and Non-Nested Slots for Spoken Language Understanding" Electronics 12, no. 7: 1748. https://doi.org/10.3390/electronics12071748
APA StyleWan, X., Zhang, W., Huang, M., Feng, S., & Wu, Y. (2023). A Unified Approach to Nested and Non-Nested Slots for Spoken Language Understanding. Electronics, 12(7), 1748. https://doi.org/10.3390/electronics12071748