
A Multi-Objective Crow Search Algorithm for Influence Maximization in Social Networks


Abstract
:1. Introduction
- Based on the two conflicting objectives of influence and cost, influence maximization is constructed as a multi-objective optimization problem called LCIM;
- The MOCSA is proposed to solve the LCIM problem. In the MOCSA, the discrete evolutionary rules of the CSA algorithm are redefined to form the discrete search space for the influence maximization problem;
- The parameter setting based on the dynamic control strategy and the random walk strategy based on the black hole are used to improve a balance between the exploration and exploitation of MOCSA;
- The experiments are implemented on various datasets with different characteristics. Numerous results show that the proposed MOCSA obtains satisfactory performance.
2. Related Work
3. Preliminaries
3.1. Influence Maximization
3.2. Diffusion Models
3.3. Crow Search Algorithm
- Crow j does not know that crow i is following it. In this way, crow i will fly to the place where crow j hides its food. At this time, the new location of crow i is updated as follows:where represents a random number between [0, 1], is the flight length of crow i in the iteration.
- Crow j knows that crow i is following it. In order to protect the food hiding place from theft, crow j will create an illusion and randomly move to other locations in the search space.
4. Proposed Method
4.1. Least Cost Influence Maximization
- Maximization sub-objective.According to the definition of maximizing influence in Section 3.1, the mathematical form of this objective is described as:In Equation (4), X is the selected seed set, is formed by nodes activated by the influence spread of X during the iteration process, and is the maximum seed set size.
- Minimization sub-objective.Most of the existing research on influence maximization revolves around problems of how to maximize the influence spread for given k seed nodes, and few works focus on the cost of activating the necessary initial seed nodes. The phenomenon reflected in real social networks is that using influential users for information dissemination requires a certain incentive cost and influence, and incentive cost are positively correlated. We aim to find a seed set that can minimize the cost of the selection of the seed nodes.Therefore, another objective function of LCIM is to minimize seed costs, the mathematical form is defined as follows:where is the set of seed nodes with minimum cost, X is the seed set selected from the node set V, is the total cost of all seed nodes, , is the cost of selecting node i, and .
4.2. Discrete Encoding Scheme
4.3. Parameter Setting Based on Dynamic Control Strategy
4.4. Random Walk Based on Black Hole
| Algorithm 1 RandomWalk |
|
4.5. Framework of MOCSA
- Step 1. Define objective function and related parameters. The objective function and its solution space are defined. And the relevant parameter values used in MOCSA are also assigned, such as the number of crows (N), maximum number of iterations (), bound of flight length ( and ), random number (r).
- Step 2. Initialize the population. According to the discrete encoding scheme, initial position and memory vectors are generated randomly. Each crow is evaluated using a multi-objective function to generate the non-dominated solution for the first iteration.
- Step 3. Global exploration and local exploitation. According to the evolutionary mechanism proposed, the location and memory vectors of the crows are updated, and a balance between exploration and exploitation is achieved using a random walk strategy based on black holes.
- Step 4. Evaluate and update new solutions. Evaluate the objective function of this iteration, the non-dominated solution in the network is selected and updated.
- Step 5. Output the solution. If the number of iterations of the algorithm has reached the maximum, output the optimal solution; otherwise, continue to return to Step 3.
| Algorithm 2 MOCSA for LCIM. |
|
5. Experiments and Analysis
5.1. Datasets
5.2. Comparison Algorithms
5.3. Parameter Configuration of MOCSA
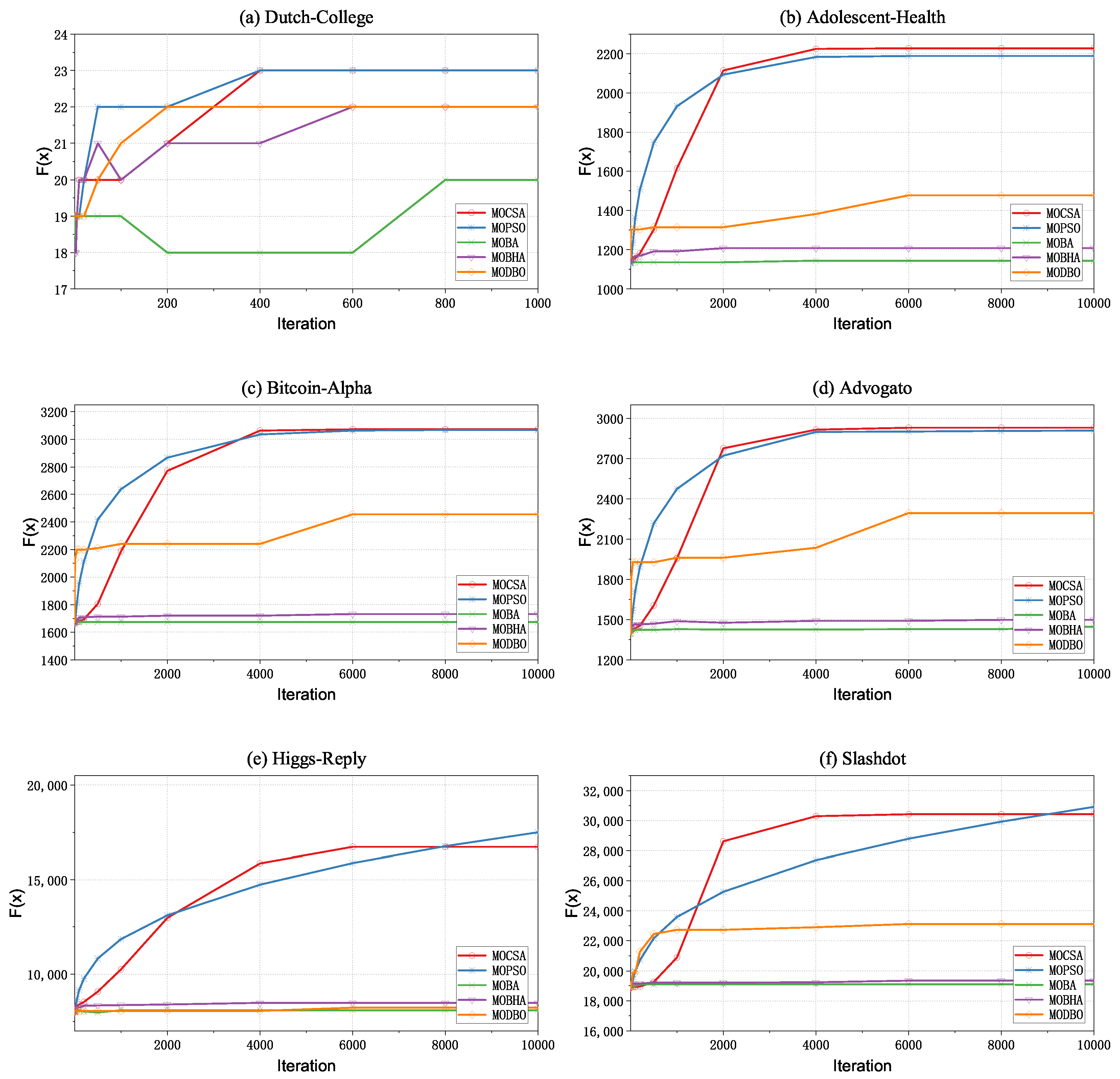
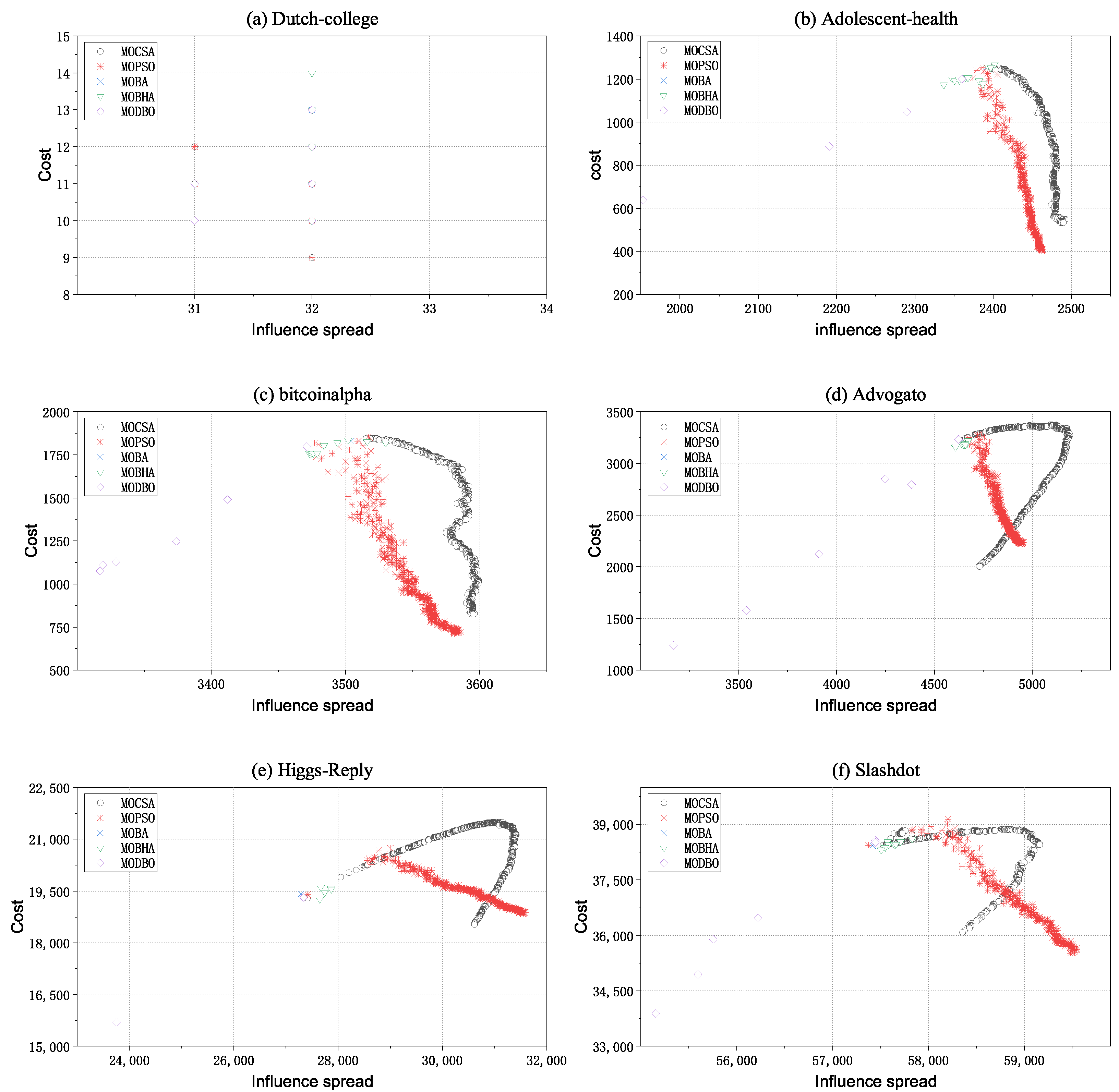
5.4. Result Analysis
5.4.1. The Comparison of the Influence Spread
5.4.2. The Comparison of the Seed Nodes Cost during Diffusion
5.4.3. The Comparison of Fitness Function Optimization Results
5.4.4. The Comparison of Running Time
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Marsden, P.V.; Friedkin, N.E. Network studies of social influence. Sociol. Methods Res. 1993, 22, 127–151. [Google Scholar] [CrossRef]
- Digital 2023 Global Overview Report. 2023. Available online: https://wearesocial.com/us/blog/2023/01/digital-2023/ (accessed on 6 February 2023).
- Li, F.; Du, T.C. The effectiveness of word of mouth in offline and online social networks. Expert Syst. Appl. 2017, 88, 338–351. [Google Scholar] [CrossRef]
- Brown, J.J.; Reingen, P.H. Social ties and word-of-mouth referral behavior. J. Consum. Res. 1987, 14, 350–362. [Google Scholar] [CrossRef]
- Domingos, P.; Richardson, M. Mining the network value of customers. In Proceedings of the 7th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 26–29 August 2001; pp. 57–66. [Google Scholar] [CrossRef]
- Richardson, M.; Domingos, P. Mining knowledge-sharing sites for viral marketing. In Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AL, Canada, 23–36 July 2002; pp. 61–70. [Google Scholar] [CrossRef]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the 4th ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; pp. 135–142. [Google Scholar] [CrossRef]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender systems with social regularization. In Proceedings of the 4th ACM international Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; pp. 287–296. [Google Scholar] [CrossRef]
- Ye, M.; Liu, X.; Lee, W.C. Exploring social influence for recommendation: A generative model approach. In Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, Portland, OR, USA, 12–16 August 2012; pp. 671–680. [Google Scholar] [CrossRef]
- Anstead, N.; O’Loughlin, B. Social media analysis and public opinion: The 2010 UK general election. J. Comput.-Mediat. Commun. 2015, 20, 204–220. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Wang, J.; Zhang, M.; Wang, X. Using social media to mine and analyze public opinion related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar] [CrossRef] [Green Version]
- Rim, H.; Lee, Y.; Yoo, S. Polarized public opinion responding to corporate social advocacy: Social network analysis of boycotters and advocators. Public Relations Rev. 2020, 46, 101869. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef] [Green Version]
- Papadopoulos, S.; Kompatsiaris, Y.; Vakali, A.; Spyridonos, P. Community detection in social media. Data Min. Knowl. Discov. 2012, 24, 515–554. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef] [Green Version]
- Ma, T.; Liu, Q.; Cao, J.; Tian, Y.; Al-Dhelaan, A.; Al-Rodhaan, M. LGIEM: Global and local node influence based community detection. Future Gener. Comput. Syst. 2020, 105, 533–546. [Google Scholar] [CrossRef]
- Zhu, Y.; Lu, Z.; Bi, Y.; Wu, W.; Jiang, Y.; Li, D. Influence and profit: Two sides of the coin. In Proceedings of the 13th International Conference on Data Mining, Dallas, TX, USA, 7–10 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1301–1306. [Google Scholar] [CrossRef]
- Kempe, D.; Kleinberg, J.; Tardos, É. Maximizing the spread of influence through a social network. In Proceedings of the 9th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003; pp. 137–146. [Google Scholar] [CrossRef] [Green Version]
- Goyal, A.; Lu, W.; Lakshmanan, L.V. Celf++ optimizing the greedy algorithm for influence maximization in social networks. In Proceedings of the 20th International Conference Companion on World Wide Web, Hyderabad, India, 28 March–1 April 2011; pp. 47–48. [Google Scholar] [CrossRef]
- Li, W.; Zhong, K.; Wang, J.; Chen, D. A dynamic algorithm based on cohesive entropy for influence maximization in social networks. Expert Syst. Appl. 2021, 169, 114207. [Google Scholar] [CrossRef]
- Kumar, S.; Singhla, L.; Jindal, K.; Grover, K.; Panda, B. IM-ELPR: Influence maximization in social networks using label propagation based community structure. Appl. Intell. 2021, 51, 7647–7665. [Google Scholar] [CrossRef]
- Lotf, J.J.; Azgomi, M.A.; Dishabi, M.R.E. An improved influence maximization method for social networks based on genetic algorithm. Phys. A Stat. Mech. Appl. 2022, 586, 126480. [Google Scholar] [CrossRef]
- Bucur, D.; Iacca, G.; Marcelli, A.; Squillero, G.; Tonda, A. Multi-objective evolutionary algorithms for influence maximization in social networks. In Applications of Evolutionary Computation, Proceedings of the 20th European Conference, EvoApplications 2017, Amsterdam, The Netherlands, 19–21 April 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 221–233. [Google Scholar] [CrossRef]
- Konotopska, K.; Iacca, G. Graph-aware evolutionary algorithms for influence maximization. In Proceedings of the Genetic and Evolutionary Computation Conference Companion, Lille, France, 10–14 July 2021; pp. 1467–1475. [Google Scholar] [CrossRef]
- Gong, H.; Guo, C. Influence maximization considering fairness: A multi-objective optimization approach with prior knowledge. Expert Syst. Appl. 2023, 214, 119138. [Google Scholar] [CrossRef]
- Wang, C.; Ma, L.; Ma, L.; Lai, J.W.; Zhao, J.; Wang, L.; Cheong, K.H. Identification of influential users with cost minimization via an improved moth flame optimization. J. Comput. Sci. 2023, 67, 101955. [Google Scholar] [CrossRef]
- Olivares, R.; Muñoz, F.; Riquelme, F. A multi-objective linear threshold influence spread model solved by swarm intelligence-based methods. Knowl.-Based Syst. 2021, 212, 106623. [Google Scholar] [CrossRef]
- Emery, N.J.; Clayton, N.S. The mentality of crows: Convergent evolution of intelligence in corvids and apes. Science 2004, 306, 1903–1907. [Google Scholar] [CrossRef]
- Emery, N.; Clayton, N. Erratum: Effects of experience and social context on prospective caching strategies by scrub jays. Nature 2002, 416, 349. [Google Scholar] [CrossRef] [Green Version]
- Dally, J.M.; Emery, N.J.; Clayton, N.S. Food-caching western scrub-jays keep track of who was watching when. Science 2006, 312, 1662–1665. [Google Scholar] [CrossRef] [Green Version]
- Askarzadeh, A. A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput. Struct. 2016, 169, 1–12. [Google Scholar] [CrossRef]
- De Souza, R.C.T.; dos Santos Coelho, L.; De Macedo, C.A.; Pierezan, J. A V-shaped binary crow search algorithm for feature selection. In Proceedings of the Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Hatamlou, A. Black hole: A new heuristic optimization approach for data clustering. Inf. Sci. 2013, 222, 175–184. [Google Scholar] [CrossRef]
- Van de Bunt, G.G.; Van Duijn, M.A.; Snijders, T.A. Friendship networks through time: An actor-oriented dynamic statistical network model. Comput. Math. Organ. Theory 1999, 5, 167–192. [Google Scholar] [CrossRef]
- Moody, J. Peer influence groups: Identifying dense clusters in large networks. Soc. Netw. 2001, 23, 261–283. [Google Scholar] [CrossRef]
- Kumar, S.; Spezzano, F.; Subrahmanian, V.; Faloutsos, C. Edge weight prediction in weighted signed networks. In Proceedings of the 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 221–230. [Google Scholar] [CrossRef]
- Kumar, S.; Hooi, B.; Makhija, D.; Kumar, M.; Faloutsos, C.; Subrahmanian, V. Rev2: Fraudulent user prediction in rating platforms. In Proceedings of the 11th ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2018; pp. 333–341. [Google Scholar] [CrossRef] [Green Version]
- Kunegis, J. Konect: The koblenz network collection. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1343–1350. [Google Scholar] [CrossRef]
- Massa, P.; Salvetti, M.; Tomasoni, D. Bowling alone and trust decline in social network sites. In Proceedings of the 8th International Conference on Dependable, Autonomic and Secure Computing, Chengdu, China, 12–14 December 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 658–663. [Google Scholar] [CrossRef]
- De Domenico, M.; Lima, A.; Mougel, P.; Musolesi, M. The anatomy of a scientific rumor. Sci. Rep. 2013, 3, 2980. [Google Scholar] [CrossRef] [Green Version]
- Kunegis, J.; Lommatzsch, A.; Bauckhage, C. The slashdot zoo: Mining a social network with negative edges. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 741–750. [Google Scholar] [CrossRef] [Green Version]
- Coello, C.C.; Lechuga, M.S. MOPSO: A proposal for multiple objective particle swarm optimization. In Proceedings of the Congress on Evolutionary Computation CEC’02 (Cat. No. 02TH8600), Honolulu, HI, USA, 12–17 May 2002; IEEE: Piscataway, NJ, USA, 2002; Volume 2, pp. 1051–1056. [Google Scholar] [CrossRef]
- Yang, X.S. Bat algorithm for multi-objective optimisation. Int. J. Bio-Inspired Comput. 2011, 3, 267–274. [Google Scholar] [CrossRef] [Green Version]
- Ebadifard, F.; Babamir, S.M. Optimizing multi objective based workflow scheduling in cloud computing using black hole algorithm. In Proceedings of the 3th International Conference on Web Research (ICWR), Tehran, Iran, 19–20 April 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 102–108. [Google Scholar] [CrossRef]
- Xue, J.; Shen, B. Dung beetle optimizer: A new meta-heuristic algorithm for global optimization. J. Supercomput. 2022, 79, 7305–7336. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Networks | |V| | |E| | <k> | C | Reference | |
|---|---|---|---|---|---|---|
| Dutch-College | 32 | 3062 | 290 | 191.375 | 0.903 676 | [35] |
| Adolescent-Health | 2539 | 12,969 | 10 | 10.2158 | 0.141888 | [36] |
| Bitcoin-Alpha | 3783 | 24,186 | 490 | 12.7867 | 0.0780074 | [37,38] |
| Advogato | 6541 | 51,127 | 941 | 18 | 0.287089 | [39,40] |
| Higgs-Reply | 38,918 | 32,523 | 1259 | 65.0679 | 0.0058 | [41] |
| Slashdot | 77,357 | 516,575 | 426 | 13.0282 | 0.0549 | [42] |
| Dutch-College | Adolescent-Health | Bitcoin-Alpha | Advogato | Higgs-Reply | Slashdot | ||
|---|---|---|---|---|---|---|---|
| MOCSA | 32 | 2574 | 3741 | 4669 | 30,313 | 48,880 | |
| 9 | 347 | 669 | 1690 | 13,579 | 18,463 | ||
| 23 | 2227 | 3072 | 2979 | 16,734 | 30,417 | ||
| MOPSO | 32 | 2539 | 3784 | 6226 | 34,263 | 61,031 | |
| 9 | 350 | 717 | 3318 | 16,755 | 30,113 | ||
| 23 | 2189 | 3067 | 2908 | 17,508 | 30,918 | ||
| MOBA | 32 | 2392 | 3504 | 4656 | 27,451 | 57,681 | |
| 12 | 1256 | 1830 | 3210 | 19,360 | 38,562 | ||
| 20 | 1136 | 1674 | 1446 | 8091 | 19,119 | ||
| MOBHA | 32 | 2387 | 3524 | 4702 | 28,029 | 57,648 | |
| 10 | 1179 | 1792 | 3205 | 19,551 | 38,304 | ||
| 22 | 1208 | 1732 | 1497 | 8478 | 19,344 | ||
| MODBO | 32 | 1983 | 3288 | 2785 | 18,786 | 47,089 | |
| 10 | 505 | 833 | 490 | 10,560 | 23,956 | ||
| 22 | 1478 | 2455 | 2295 | 8226 | 23,133 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, P.; Zhang, R. A Multi-Objective Crow Search Algorithm for Influence Maximization in Social Networks. Electronics 2023, 12, 1790. https://doi.org/10.3390/electronics12081790
Wang P, Zhang R. A Multi-Objective Crow Search Algorithm for Influence Maximization in Social Networks. Electronics. 2023; 12(8):1790. https://doi.org/10.3390/electronics12081790
Chicago/Turabian StyleWang, Ping, and Ruisheng Zhang. 2023. "A Multi-Objective Crow Search Algorithm for Influence Maximization in Social Networks" Electronics 12, no. 8: 1790. https://doi.org/10.3390/electronics12081790
APA StyleWang, P., & Zhang, R. (2023). A Multi-Objective Crow Search Algorithm for Influence Maximization in Social Networks. Electronics, 12(8), 1790. https://doi.org/10.3390/electronics12081790