

A Fast VVC Intra Prediction Based on Gradient Analysis and Multi-Feature Fusion CNN

Abstract
:1. Introduction
2. Related Work
2.1. Related Method of HEVC
2.2. Approaches for VVC
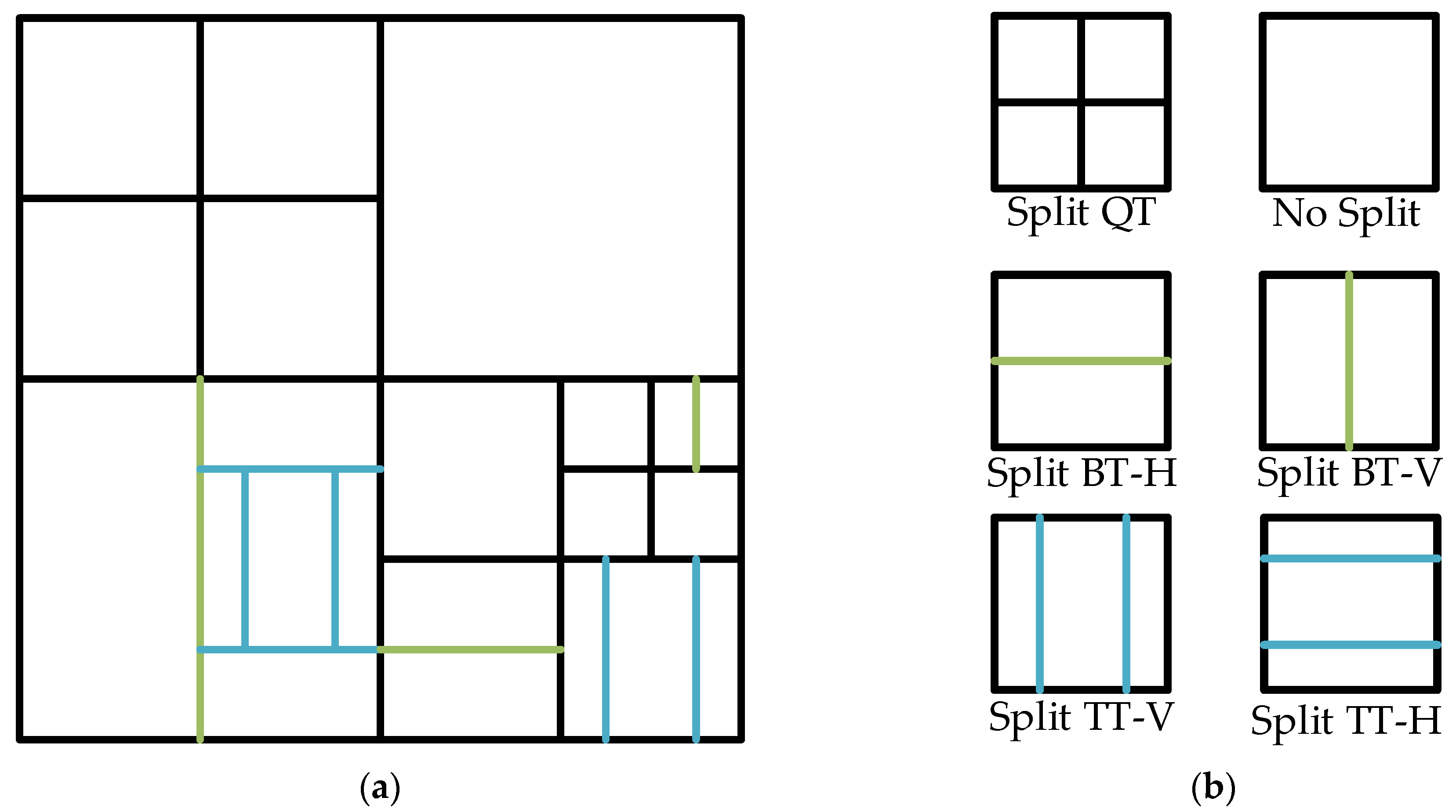
3. The Proposed Algorithm
3.1. Gradient-Based Early Decision Methods
3.2. Calculate Standard Deviation
3.3. Determine the Initial Segmentation Depth of CUs by Prediction Dictionary
3.4. Multi-Feature Fusion CNN
3.5. CNN Training
4. Experimental Results
4.1. Experimental Setup
4.2. Results Presentation and Comparative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Qian, X.; Zeng, Y.; Wang, W.; Zhang, Q. Co-saliency Detection Guided by Group Weakly Supervised Learning. IEEE Trans. Multimed. 2022, 1. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Bross, B.; Chen, J.; Ohm, J.R.; Sullivan, G.J.; Wang, Y.K. Developments in international video coding standardization after avc, with an overview of versatile video coding (vvc). Proc. IEEE 2021, 109, 1463–1493. [Google Scholar] [CrossRef]
- Mercat, A.; Mäkinen, A.; Sainio, J.; Lemmetti, A.; Viitanen, M.; Vanne, J. Comparative rate-distortion-complexity analysis of VVC and HEVC video codecs. IEEE Access 2021, 9, 67813–67828. [Google Scholar] [CrossRef]
- Shen, L.; Zhang, Z.; Liu, Z. Effective CU size decision for HEVC intra coding. IEEE Trans. Image Process. 2014, 23, 4232–4241. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Kim, S.; Lim, K.; Lee, S. A fast CU size decision algorithm for HEVC. IEEE Trans. Circuits Syst. Video Technol. 2014, 25, 411–421. [Google Scholar]
- Bouaafia, S.; Khemiri, R.; Sayadi, F.E.; Atri, M. Fast CU partition-based machine learning approach for reducing HEVC complexity. J. Real-Time Image Process. 2020, 17, 185–196. [Google Scholar] [CrossRef]
- Kuanar, S.; Rao, K.R.; Bilas, M.; Bredow, J. Adaptive CU mode selection in HEVC intra prediction: A deep learning approach. Circuits Syst. Signal Process. 2019, 38, 5081–5102. [Google Scholar] [CrossRef]
- Kuo, Y.T.; Chen, P.Y.; Lin, H.C. A spatiotemporal content-based CU size decision algorithm for HEVC. IEEE Trans. Broadcast. 2020, 66, 100–112. [Google Scholar] [CrossRef]
- Kuang, W.; Chan, Y.L.; Tsang, S.H.; Siu, W.C. Online-learning-based Bayesian decision rule for fast intra mode and CU partitioning algorithm in HEVC screen content coding. IEEE Trans. Broadcast. 2019, 29, 170–185. [Google Scholar] [CrossRef] [PubMed]
- Hari, P.; Jadhav, V.; Rao, B.S. CTU Partition for Intra-Mode HEVC using Convolutional Neural Network. In Proceedings of the 2022 IEEE International Symposium on Smart Electronic Systems (iSES), Warangal, India, 18–22 December 2022; pp. 548–551. [Google Scholar]
- Bakkouri, S.; Elyousfi, A. Machine learning-based fast CU size decision algorithm for 3D-HEVC inter-coding. J. Real-Time Image Process. 2021, 18, 983–995. [Google Scholar] [CrossRef]
- Fu, C.H.; Chen, H.; Chan, Y.L.; Tsang, S.H.; Hong, H.; Zhu, X. Fast depth intra coding based on decision tree in 3D-HEVC. IEEE Access 2019, 7, 173138–173147. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhao, Y.; Jiang, B.; Huang, L.; Wei, T. Fast CU partition decision method based on texture characteristics for H. 266/VVC. IEEE Access 2020, 8, 203516–203524. [Google Scholar] [CrossRef]
- Tang, N.; Cao, J.; Liang, F.; Wang, J.; Liu, H.; Wang, X.; Du, X. Fast CTU partition decision algorithm for VVC intra and inter coding. In Proceedings of the 2019 IEEE Asia Pacific Conference on Circuits and Systems (APCCAS), Bangkok, Thailand, 11–14 November 2019; pp. 361–364. [Google Scholar]
- Fan, Y.; Sun, H.; Katto, J.; Ming’E, J. A fast QTMT partition decision strategy for VVC intra prediction. IEEE Access 2020, 8, 107900–107911. [Google Scholar] [CrossRef]
- Wang, Y.; Dai, P.; Zhao, J.; Zhang, Q. Fast CU Partition Decision Algorithm for VVC Intra Coding Using an MET-CNN. Electronics 2022, 11, 3090. [Google Scholar] [CrossRef]
- Ni, C.T.; Lin, S.H.; Chen, P.Y.; Chu, Y.T. High Efficiency Intra CU Partition and Mode Decision Method for VVC. IEEE Access 2022, 10, 77759–77771. [Google Scholar] [CrossRef]
- Pan, Z.; Zhang, P.; Peng, B.; Ling, N.; Lei, J. A CNN-based fast inter coding method for VVC. IEEE Signal Process. Lett. 2021, 28, 1260–1264. [Google Scholar] [CrossRef]
- Li, Y.; Yang, G.; Song, Y.; Zhang, H.; Ding, X.; Zhang, D. Early intra CU size decision for versatile video coding based on a tunable decision model. IEEE Trans. Broadcast. 2021, 67, 710–720. [Google Scholar] [CrossRef]
- Tang, J.; Sun, S. Optimization of CU Partition Based on Texture Degree in H. 266/VVC. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 402–408. [Google Scholar]
- Jiang, W.; Ma, H.; Chen, Y. Gradient based fast mode decision algorithm for intra prediction in HEVC. In Proceedings of the 2012 2nd international conference on consumer electronics, communications and networks (CECNet), Yichang, China, 21–23 April 2012; pp. 1836–1840. [Google Scholar]
- Zhang, Y.; Han, X.; Zhang, H.; Zhao, L. Edge detection algorithm of image fusion based on improved Sobel operator. In Proceedings of the 2017 IEEE 3rd Information Technology and Mechatronics Engineering Conference (ITOEC), Chongqing, China, 3–5 October 2017; pp. 457–461. [Google Scholar]
- Li, Y.; Liu, Z.; Ji, X.; Wang, D. CNN based CU partition mode decision algorithm for HEVC inter coding. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 993–997. [Google Scholar]
- Khan, M.U.K.; Shafique, M.; Henkel, J. An adaptive complexity reduction scheme with fast prediction unit decision for HEVC intra encoding. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, VIC, Australia, 15–18 September 2013; pp. 1578–1582. [Google Scholar]
- Zhang, Y.; Li, Z.; Li, B. Gradient-based fast decision for intra prediction in HEVC. In Proceedings of the 2012 Visual Communications and Image Processing, San Diego, CA, USA, 27–30 November 2012; pp. 1–6. [Google Scholar]
- Zhang, Y.; Wang, G.; Tian, R.; Xu, M.; Kuo, C.J. Texture-classification accelerated CNN scheme for fast intra CU partition in HEVC. In Proceedings of the 2019 Data Compression Conference (DCC), Snowbird, UT, USA, 26–29 March 2019; pp. 241–249. [Google Scholar]
- Li, T.; Xu, M.; Tang, R.; Chen, Y.; Xing, Q. DeepQTMT: A deep learning approach for fast QTMT-based CU partition of intra-mode VVC. IEEE Trans. Image Process. 2021, 30, 5377–5390. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (%) | Comparison of Different Parameters | Accuracy | ||
|---|---|---|---|---|
| Conv | Kernel | FCL | ||
| Default parameter | 4 | 6 | 2 | 72.30 |
| Kernel comparison | 4 | 8 | 2 | 81.25 |
| 4 | 10 | 2 | 87.65 | |
| Conv comparison | 2 | 6 | 2 | 73.45 |
| 4 | 6 | 2 | 80.26 | |
| FCL comparison | 4 | 6 | 2 | 71.26 |
| 4 | 6 | 3 | 76.51 | |
| Sequence | Class | Resolution |
|---|---|---|
| Kristen AndSara | E | 720 |
| Kimono | B | 1080 |
| CatRobot1 | A | 2160 |
| PartyScene | C | 480 |
| Class | Sequence | Ref. [29], VTM7.0 | Ref. [16], VTM4.0 | Proposed Algorithm | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| BD-BR(%) | TS(%) | TS/BD-BR | BD-BR(%) | TS(%) | TS/BD-BR(%) | BD-BR(%) | TS(%) | TS/BD-BR(%) | ||
| A | Campfire | 2.91 | 59.87 | 20.57 | / | / | / | 1.02 | 34.80 | 34.11 |
| CatRobot1 | 3.28 | 55.99 | 17.07 | / | / | / | 1.06 | 38.71 | 36.52 | |
| B | Kimono | / | / | / | 1.98 | 41.82 | 21.12 | 1.13 | 38.56 | 34.12 |
| MarketPlace | 1.28 | 58.22 | 45.48 | / | / | / | 0.87 | 34.12 | 39.22 | |
| BQTerrace | 1.79 | 56.94 | 31.81 | 1.19 | 29.47 | 24.76 | 0.97 | 33.89 | 47.73 | |
| Cactus | 1.86 | 60.56 | 32.56 | / | / | / | 1.05 | 35.86 | 34.15 | |
| C | BasketballDrill | 2.98 | 52.62 | 17.66 | 1.36 | 28.73 | 21.13 | 1.25 | 38.40 | 51.2 |
| RaceHorsesC | 1.61 | 57.89 | 35.96 | 2.96 | 33.89 | 11.45 | 0.89 | 37.69 | 56.25 | |
| PartyScene | 1.16 | 58.94 | 50.81 | 1.05 | 35.23 | 33.55 | 1.16 | 34.83 | 30.03 | |
| D | BQSquare | 1.33 | 55.16 | 41.47 | 1.19 | 29.47 | 24.76 | 0.94 | 38.93 | 52.61 |
| BlowingBubbles | 1.57 | 53.40 | 34.01 | 0.73 | 21.87 | 29.96 | 1.08 | 34.75 | 32.18 | |
| RaceHorses | 1.88 | 53.34 | 28.37 | 2.96 | 33.89 | 11.45 | 1.34 | 36.03 | 26.89 | |
| E | FourPeople | 2.20 | 59.74 | 27.15 | 1.37 | 26.65 | 19.45 | 1.05 | 37.66 | 44.31 |
| Kristen AndSara | 2.75 | 60.01 | 21.82 | 1.53 | 25.32 | 16.55 | 0.97 | 37.62 | 38.78 | |
| Average | 2.05 | 57.13 | 27.87 | 1.63 | 30.63 | 18.79 | 1.06 | 36.56 | 34.49 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jing, Z.; Zhu, W.; Zhang, Q. A Fast VVC Intra Prediction Based on Gradient Analysis and Multi-Feature Fusion CNN. Electronics 2023, 12, 1963. https://doi.org/10.3390/electronics12091963
Jing Z, Zhu W, Zhang Q. A Fast VVC Intra Prediction Based on Gradient Analysis and Multi-Feature Fusion CNN. Electronics. 2023; 12(9):1963. https://doi.org/10.3390/electronics12091963
Chicago/Turabian StyleJing, Zhiyong, Wendi Zhu, and Qiuwen Zhang. 2023. "A Fast VVC Intra Prediction Based on Gradient Analysis and Multi-Feature Fusion CNN" Electronics 12, no. 9: 1963. https://doi.org/10.3390/electronics12091963
APA StyleJing, Z., Zhu, W., & Zhang, Q. (2023). A Fast VVC Intra Prediction Based on Gradient Analysis and Multi-Feature Fusion CNN. Electronics, 12(9), 1963. https://doi.org/10.3390/electronics12091963