Abstract
Hand hygiene is obligatory for all healthcare workers and vital for patient care. During COVID-19, adequate hand washing was among recommended measures for preventing virus transmission. A general hand-washing procedure consisting several steps is recommended by World Health Organization for ensuring hand hygiene. This process can vary from person to person and human supervision for inspection would be impractical. In this study, we propose computer vision-based new methods using 12 different neural network models and 4 different data models (RGB, Point Cloud, Point Gesture Map, Projection) for the classification of 8 universally accepted hand-washing steps. These methods can also perform well under situations where the order of steps is not observed or the duration of steps are varied. Using a custom dataset, we achieved 100% accuracy with one of the models, and 94.23% average accuracy for all models. We also developed a real-time robust data acquisition technique where RGB and depth streams from Kinect 2.0 camera were utilized. Results showed that with the proposed methods and data models, efficient hand hygiene control is possible.
1. Introduction
Almost all of our interactions with objects in daily life occurs through our hands. In three- dimensional space, we use our hands to move, transform, and use all kinds of objects. In addition, we use hands for communication and expression of our feelings. Computers, mobile devices, and the like, which have been part of our lives for some time, are mostly designed to be controlled by hands. Human–Computer Interaction (HCI) is an entire discipline that is dedicated to improve the user’s comfort and experience via hand driven devices and applications.
Defining hand gestures ensuring less physical contact in accordance with computer vision is becoming common for HCI. Interpreting gestures is crucial for touch-free control of devices and accuracy of hand driven procedural works in general. Various methods exist in literature for solving problems of hand gesture recognition; however some problems may still need new approaches or combinations of different methods.
In this study, we aimed to evaluate whether the hand-washing routines of healthcare personnels, which they must perform daily, is compatible with the according procedure. Nosocomial infections, which means infections acquired from a hospital environment, come among the top causes of mortality among patients. During COVID-19 pandemic, the rate of nosocomial infections was as high as 44% [1]. Among the major causes of nosocomial infections, nurses and physicians can be listed [2]. Having to take care of several patients, they are obliged to observe hygiene procedures. One of these procedures is adequate hand washing. When they switch between cases, they are required to wash their hands following a guideline proposed by WHO [3]. However, sometimes this procedure can be neglected. We present an efficient real-time system which ensures required hand-washing steps are performed correctly to reduce the risk of infections in hospitals and improve human health in general. Proposed methods in our study are also valid in many other places where hand hygiene is a must, such as the food industry. In our work, we propose:
- A robust method of acquiring and utilizing RGB and depth data in real-time,
- Combination of different vision data models acquired from RGB and depth images for classification,
- An ideal camera position for hand-washing quality measurement,
- A custom dataset containing different vision-based data models,
- Comparison of 12 different neural network models making use of all the available data.
The structure of this article is detailed in the following. In Section 2, hand-washing studies are reviewed. In Section 3, dataset, hand tracking and gesture recognition methods are explained in detail. In Section 4, classification results are discussed, tables and graphics are given. In Section 5, results are reviewed and future directions are considered.
2. Related Works
Data models used in hand gesture recognition can be grouped under two categories, vision-based and sensor-based. Vision-based models use data from various camera types, such as RGB or depth. Sensor-based models obtain data from devices, such as wristbands, smart watches, and other similar devices. Both approaches were used in previous studies of hand-washing evaluation. In this section, we will briefly review these related works.
2.1. Vision-Based Works
Llorca et al. [4] used skin color and motion analysis to detect hands in washing analysis. They used particle filter and k-Means to detect hands, Histogram of Oriented Gradients (HOG) and Histograms of Oriented Optical Flow (HOF) for feature extraction, and Support Vector Machines (SVM) for classification of six gestures. Xia et al. [5] used Gaussian Expectation Maximization with RGB-D images to detect hand regions for hand-washing quality evaluation. HOG and Principal Component Analysis (PCA) were used together for feature extraction. SVM, Linear Discriminant Analysis (LDA), and Random Forest (RF) were used for classification of 12 gestures. Ivanovs et al. [6] introduced their own dataset in video format for hand-washing classification. MobileNet-V2 and Xception networks were used for classification of 7 gestures. Prakasa and Sugiarto [7] used skin color to detect hands in a 6 gesture hand-washing process. They used a Convolutional Neural Network (CNN) to classify six gestures. Vo et al. [8] classified seven gestures from a custom dataset with RGB images acquired from six different viewpoints. MobileNet-V2, ResNet-18, Inception-V3, and Augmented Multiscale Deep Infomax (AmDim) networks were used for classification. Zhong et al. [9] created a custom dataset with different camera angles. Region of interest areas were labelled manually. They used RGB data as well as optical flow data with ResNet-50, ResNet-50-LSTM and Temporal Relational Network (TRN) for classification of four hygiene gestures. Xie et al. [10] used CNN with a custom video dataset with a feature aggregation module for classification of seven gestures.
2.2. Sensor-Based Works
Mondol and Stankovic [11] used smart watches to determine hand-washing quality. They used various features from the X, Y, and Z axis data of sensors. Decision trees were used for the classification of 7 and 10 washing gestures from two custom datasets. Wang et al. [12] used a Myo armband to collect data for 10 washing steps according to WHO guidelines. A variety of features were extracted from IMU and sEMG data and Extreme Gradient Boosting (XGBoost) was used for classification. Samyoun et al. [13] designed a system involving a smart watch for classifying 10 step hand-washing process. Statistical measures from sensor data were used as features and CNN features along with Long Short-Term Memory (LSTM) were combined for classification. Santos-Gago et al. [14] used smart-watches with SVM, RF, Logistic Regression (LR), and Artificial Neural Network (ANN) for detection of hand washing. Wang et al. [15] proposed a system called UWash, making use of both accelerometer and gyroscope data from smart watches to assess hand-washing quality. They used a customized U-Net architecture to classify nine washing gestures. Zhang et al. [16] used Byteflies sensors on each wrist to collect data from the hand-washing process. Features were extracted in both time and frequency domain. They used k-Nearest Neighbours, XGBoost, SVM, and Feed Forward Neural Network (FFN) classifiers to classify 11 steps of hand washing.
3. Materials and Methods
Hand tracking and gesture recognition can become complex in some cases. Because of hands having many degrees of freedom, they can be in many different shapes and colours at any given situation. Additionally, they can be easily affected by occlusion due to motion or interaction with objects. Assessing hand-washing quality also can be considered as a hand gesture recognition problem. Each washing instruction in the WHO guidelines can be thought as a separate gesture. Additionally, these instructions can be considered independent of each other because the order does not affect the hand washing. Considering these points, in order to achieve a good evaluation, a vision-based system should be able to classify each gesture, either at frame-level or spatio-temporal level.
In this study, we achieved both frame-level and spatio-temporal level classification of 8 hand-washing gestures (Figure 1) using different data models and neural network architectures with a vision-based approach. We used a Kinect 2.0 [17] camera to acquire RGB and depth data simultaneously. In total, 4 different data models (RGB, Point Cloud, Point Gesture Map, and Projection) were used with 12 neural network architectures and classification accuracies were measured.
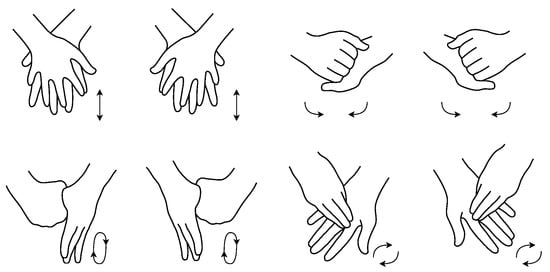
Figure 1.
The 8 hand-washing gestures derived from WHO’s guidelines. First row from left to right: phase1 to phase4. Second row from left to right: phase5 to phase8.
3.1. Camera and Positioning
It is fundamental to have both hands in frame at a useful angle in order to achieve hand gesture recognition. Because hand washing involves hands interacting with water, it is also important to protect camera electronics or lens from possible contact with water. Placing a camera near the faucet could be ineffective, unless an extra measure is taken. The camera could be positioned to the left or right of the person performing hand washing, high enough to not have any contact with water; however, this kind of position will be unable to capture both hands with equal detail, because one of the hands would be occluded constantly by the other hand, and it will require a stand to operate, which may be unsuitable for some places. Some research use egocentric cameras to capture gestures. This approach would require a person to carry a camera when performing the task, which could be not feasible in all cases.
Considering the above points, the most suitable position for the camera would be above the sink. This way, the risk of coming into contact with water is eliminated, and it would be possible to capture hands equally without occlusion. This placement will also provide the minimum distance depth cameras need to operate correctly (Kinect 2.0 depth sensor requires minimum 0.5 m). Additionally, arm positions could provide extra information about the gesture.
There are many cameras available for providing depth information [18], they are also commonly used for hand gesture recognition [19,20]. We have chosen Kinect 2.0 because it provides real-time RGB-D data simultaneously, we utilized depth information for both hand tracking and classification. We can speculate that Kinect 2.0 depth images provides better representation when constructing point clouds (PCD), compared to some other similar purpose cameras [21]. We captured our data in 2 different locations with 2 participants (1 male–1 female), placing the camera on top of the sinks.
3.2. Data Acquisition
Kinect 2.0 is able to provide both RGB and depth images with an additional calculated RGB-depth-aligned image (RDA). It provides depth images in 512 × 424 pixels and RGB images in 1920 × 1080 pixels. Data acquisition was achieved in real-time with RGB and depth data being captured simultaneously. For this purpose, we developed a multi-thread-based system. During data acquisition, three separate threads were run to acquire RGB, depth, and RDA images. A fourth thread was used for tracking time measures, making sure each gesture is recorded for a duration of 5 s. Before every recording, for a duration of 10 s, background images in RGB, depth and RDA were still acquired with no moving object present. RGB images are resized in half (960 × 540) to reduce the computing complexity. Data acquisition steps and stored data types can be seen in Figure 2.
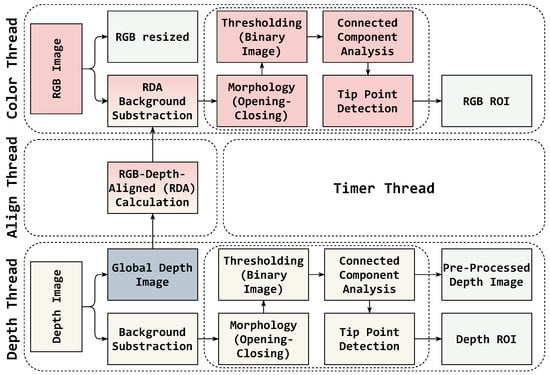
Figure 2.
Simultaneous data acquisition.
Equation (1) shows transforming a world coordinate in a camera to pixels using the intrinsic and extrinsic matrices. Once the world coordinates of a pixel are known, it is possible to calculate new (u, v) coordinates in an image using the intrinsic and extrinsic matrices of another camera. Kinect 2.0, having two separate cameras in itself, internally calculates the RDA image.
Both RGB and depth data were stored as frames, rather than video format. We have chosen not to have video files, since depth information contains 16 bit information, encoding the depth data for a video format would convert it to 8 bits, resulting in data loss. Additionally, frame rate inaccuracies occur due to pre-processing methods consuming CPU, decreasing the standard expected frame rate.
Considering WHO guidelines, a complete hand-washing procedure can be separated to 10 total phases. The first phase is opening the faucet and taking soap in hand; the last phase is rinsing hands together and closing the faucet. In this study, we have chosen 8 phases in-between for gesture recognition, because they would suffice to evaluate washing procedure; excluded steps could differ vastly from person to person, adding unnecessary complexity to the problem. The total amount of data in our dataset can be seen in Table 1. Ideally, hand-washing duration, observing these phases, should be around a minute. If we are to assume that the first and last phases account for 10 s each, making 20 s in total, each hand-washing gesture should take about 5 s. Our dataset was created observing this duration, by using sound signals, the participant was informed about the duration of each hand gesture when recording. The first location had the camera positioned 110 cm above the hand-washing area and the second location had it positioned 90 cm above. Both faucets had the 85 cm height from ground. Both locations can be seen in Figure 3.

Table 1.
Dataset-A (RGB ROI frame counts) and Dataset-B (PCD file and Projection image counts) details.

Figure 3.
Background images of two locations. Depth (left), RGB (middle), and RGB-depth-aligned (RDA) (right).
During the recordings, along with the raw data, pre-processed data were also stored in corresponding folders. All data acquisition was performed using a notebook because of portability (System 4 in Table 2), with PyKinect2 [22], a Python wrapper for Kinect 2.0 SDK. Details of the pre-processing steps and hand tracking are given in the next section.
Table 2.
Specifications of the systems used in training.
3.3. Hand Detection
To detect hands in the hand washing, pre-processed depth images were used. Depth images have many advantages compared to RGB images in this situation, because RGB images are prone to changes, such as environmental lightning or skin color. Depth information, however, does not become affected by these, because depth cameras generally use infrared lights. Kinect 2.0 is a time of flight camera, which determines depth by measuring the reflection time of lights emitted from camera to scene.
A background subtraction method was used with depth and RDA images to separate the subject from background. Only two frames (background and current frame) were used for background subtraction. Since RDA images correspond to exact coordinates with the RGB images, detecting region of interest (ROI) in RDA images automatically results in successful detection of hands in RGB images.
After background subtraction in depth and RDA in each thread of their own, thresholding with a value of 10 was applied and binary images were acquired separately. An opening and closing morphology with a 5 × 5 kernel has given the best results for eliminating small noises in binary images (Figure 4). These steps are represented in Equation (2). is the frame difference, is the background image, and is the current frame. is the threshold image, the is morphology image, is the erosion kernel, and is the dilation kernel. Connected component analysis was performed after morphology to ensure the image only contains the largest object in the image, which is the subject. The resulting binary image is then masked with the original depth images. This pre-processed and background cleaned depth image is stored in the dataset.

Figure 4.
Pre-processing of the depth images. From left to right: raw depth, after background subtraction and thresholding, after morphology, after connected component analysis.
We determine the ROI in an easy and practical way. We introduce tip-point detection for hand tracking. Various methods have been purposed in literature for hand tracking [23], determining tip points is also a common approach for fingers (e.g., [24]). In our situation, the camera is positioned above the sink and subject is always facing upside down in images, we can assume that the tip of hands will always be in the lowest white pixel at y-coordinate of the binary image which was acquired after pre-processing. By using this lowest y-coordinate white pixel, we can draw a ROI rectangle that contains both hands and some portion of the arms. In both depth and RDA images, this point is the center of lower edge of the ROI rectangle. For depth images, a rectangle of 100 × 100 is cropped, for RDA images, a rectangle of 150 × 150 is cropped. In RGB ROI, a 25 pixel zone is left between the detected tip point and the lower edge. With this method, hands in RGB images are detected robustly solely using RDA images, also the motion tracking of hands during washing when the subject leans away from the sink becomes possible. Example ROI images can be seen in Figure 5, different parts of the sink in the background shows motion tracking. All processing mentioned here was performed using OpenCV [25] in Python.

Figure 5.
RGB and depth ROI images. From left to right: phase1 to phase8.
For each gesture, 400 sessions were recorded in two different locations (200 in location-1, 200 in location-2), each having frames recorded equivalent to 5 s. Each participant performed 100 sessions of washing in each location, 3200 sessions were recorded in total. The average frame rate for RGB images was 9.7 and for depth, it was 29.
3.4. Gesture Classification
For classification, we used 4 different vision data models with various neural network architectures. These models are RGB, point cloud (PCD), point cloud gesture maps (PGM), and projection images. PCD data were created from ROI depth images using Open3d library [26]. It is possible to obtain the PCD data from depth images using camera parameters and pixel intensity value (Equation (1)). Figure 6 shows examples from PCDs. Details about projection and PGMs are explained in following sections.
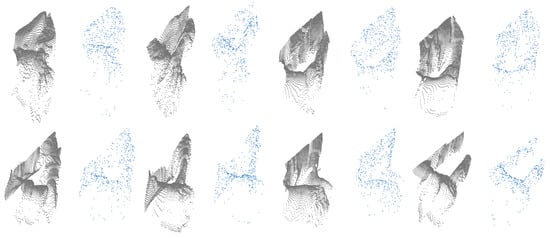
Figure 6.
PCD data sample of gestures. Raw data (gray) and sampled using 512 points (blue). First row from left to right: phase1 to phase4. Second row from left to right: phase5 to phase8.
Our dataset is separated into two sub-datasets. In Dataset-A, RGB-ROI images were used directly for training, depth ROI images were used to create PCD, projection, and PGM data. Dataset-B contains PCD data generated from depth ROI, projection images, and PGMs. Depth ROI image counts are equal with projection and PCD data, because the latter two were created from the first. PGM dataset contains 400 PGM files, for every session in a dataset one PGM is created.
3.4.1. Frame Level Classification
For frame based classification, we used common network architectures; Inception-V3 [27], MobileNet-V1 [28], ResNet-50 [29], PointNet [30], and VGG-16 [31]. Inception-V3 network uses asymmetric convolutional filters (such as 1 × 3 and 3 × 1) which makes it more efficient in terms of performance without causing significant disadvantage on feature extraction. MobileNet-V1 network uses combination of depth-wise and point-wise convolutions, which are aimed to reduce cost of computations making it suitable for mobile devices. ResNet-50 network creates a solution to vanishing gradient problem by introducing shortcuts between non-sequential layers, named residual blocks, which makes it efficient despite having larger number of layers. PointNet network has modules for obtaining all possible combinations and geometrical transformations of PCD data for efficient classification. VGG-16 is a popular network which uses 3 × 3 and 1 × 1 convolutional kernels. It is commonly used for both classification and feature extraction.
RGB images were used with Inception-V3, MobileNet-V1, and ResNet-50 networks. Likewise, projection images were used in the same networks. PCDs as single frames were used with a PointNet network implemented in Keras [32]. Lastly, features from RGB, projection, and PCD data were extracted and fused together with VGG-16 and trained PointNet, classified with a two-layer custom network.
Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11 show the architectures of the models used for frame level classification with custom top layers (Drop-out and Dense). All networks were used with random weights except for VGG-16, which was used for feature extraction with default ImageNet weights.
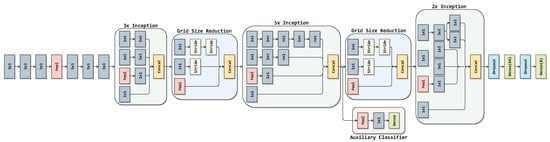
Figure 7.
Inception-V3 architecture.

Figure 8.
MobileNet-V1 architecture.

Figure 9.
ResNet-50 architecture.

Figure 10.
PointNet architecture.
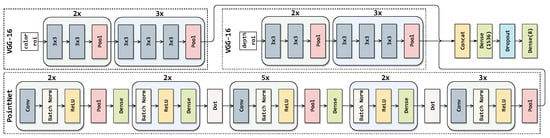
Figure 11.
Fusion-Custom Layers architecture.
Projecting point clouds to acquire 2D information is a method used in various studies [33,34]. A 3D point in space can be represented in a 2D plane using a projection matrix (Equation (1)). In our study, we projected our PCD data to four different viewpoints in space (top, front, left, right), rendering and concatenating the end result using Open3d and OpenCV. Figure 12 shows examples from projection images.

Figure 12.
Projection images. From left to right: phase1 to phase8.
RGB images used in networks were all resized to 96 × 96 pixels. Projection images were likewise resized to 128 × 128. PCDs also need to be sampled with a constant size before being inputs to the network. For this purpose, PCD data were sampled randomly selecting 512 points. Projection images were trained and tested using a customized method. None of the systems were able to handle the memory needed to train the networks using a Python pickle file. Even with large swap spaces in both Linux and Windows operating systems, memory issues were occurred. Thus, dataset was fed into network divided into smaller parts. A set of 4 sessions were used for training and a set of 1 session was used for validation in each epoch. These blocks were shifted through training until all the dataset is covered. In other folds, validation session set was shifted algorithmically to achieve cross-fold validation. Since the training and validation sets were small and shifting, validation errors were high and oscillating, which is natural and expected.
3.4.2. Spatio-Temporal Level Classification
In order to make use of spatio-temporal information, a set of frames from a gesture can be used with LSTM networks [35]. A custom VGG-16 - LSTM network was trained with RGB and projection images. PCD features were extracted from a trained PointNet for PointNet–LSTM network. For LSTM networks, length of the frame stack for RGB images was selected as 40, because this was the most common lowest frame count for 5 s recordings in dataset. For projection and PCDs, it was selected as 120 because of the same reason. In total, 7 sessions in RGB and 13 sessions in depth had a lower amount of frames than the determined thresholds, thus they were ignored during training and testing for LSTM networks. LSTM networks has structures called cells which contain state information and gate mechanisms. Three different gates (input, forget, output) decide which information will update the cell state and outputs, making it possible to use temporal information. LSTM netwoks can efficiently be combined with CNNs for image-based temporal classifications.
Another data model we use here is PGMs. PGMs are created merging all the PCD data for a gesture in a session. They are stacked together in Z axis and treated as a single object representing the whole gesture by itself. Many studies make use of spatio-temporal features from point clouds [36,37]. However, to the best of our knowledge, treating the sequence as a single object has not been extensively researched for hand-gesture recognition. Figure 13 shows example images from PGMs. PGMs were used with a PointNet network implemented in Keras [32] and they were sampled randomly selecting 12,800 points from the initial stack. PGMs allows capturing the spatio-temporal information that can be used as a single example of a gesture.

Figure 13.
Point Gesture Map (PGM) data sample of gestures. Raw data (gray) and sampled using 12,800 points (blue). First row from left to right: phase1 to phase4. Second row from left to right: phase5 to phase8.
All training and testing were performed using Tensorflow-Keras [38] in Python. Four different systems were used for training. System specifications and average training times can be seen in Table 2 and Table 3. In one of the systems, Plaid-ML framework was used [39]. A 5-Fold Cross Validation method was used for all the models. Training/Validation/Test split of the dataset can be seen in Figure 14. From all datasets, 60 sessions (files for PGM) were split for testing. In total, 340 sessions were used for training and validation. In all datasets, a total of 26 sessions for various gestures which were recorded in location 1 had unwanted issues (such as not being recorded accidentally). They were replaced by extra recordings in location 2. All networks were built with Adam optimizer [40] with a learning rate of 0.001. Batch size for all networks were 32. Figure 15 and Figure 16 show LSTM model architectures used in this study.
Table 3.
Summary of all models.
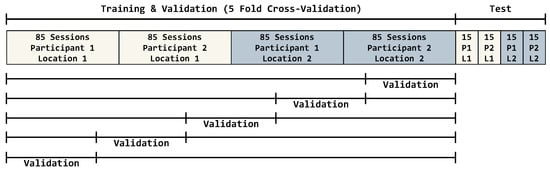
Figure 14.
Training/Validation/Test split of dataset.
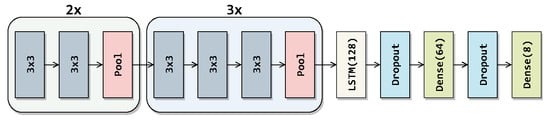
Figure 15.
VGG-16-LSTM architecture.

Figure 16.
PointNet-LSTM architecture.
4. Results
In this study, networks that were used with RGB ROI images were trained with 10 epochs. PointNet with PCDs was also trained with 10 epochs since the dataset was large enough to make the networks converge. Projection images used a special training method due to memory requirements, which was mentioned in the previous section, and was trained with 85 epochs. In PointNet PGM training, 25 epochs were used because there was room for improvement as the network kept converging. LSTM and Fusion networks were easier to train in terms of duration, they were trained with 50 epochs. Average accuracies of all 5-fold models of each architecture can be seen in Table 3. All accuracies and losses for each epoch in 5-fold models were averaged to obtain an average graphic. In some folds, validation error spikes were higher than the others, thus it reflected the average graphics. Figure 17, Figure 18, Figure 19, Figure 20, Figure 21, Figure 22, Figure 23, Figure 24, Figure 25, Figure 26, Figure 27 and Figure 28 show average confusion matrices of test data and average training accuracies/losses of 5-fold models. The greatest accuracy was achieved with the PointNet-LSTM model with 100% classification performance. Inception-V3 RGB model followed this with 99.87% and MobileNet-V1 RGB model became third with 99.75%. The least accurate model was ResNet-50 projection with 81.37%. The greatest inaccuracy among steps was seen with phase8 in the Resnet-50 projection model (Figure 22). As can be seen from the results, all models achieved acceptable performance. We could speculate that if projection images were trained with a greater amount of validation and training partitions, their accuracy would be higher too. It can also be speculated that including arms had a positive effect on classification accuracy because in each gesture they have a distinct posture.
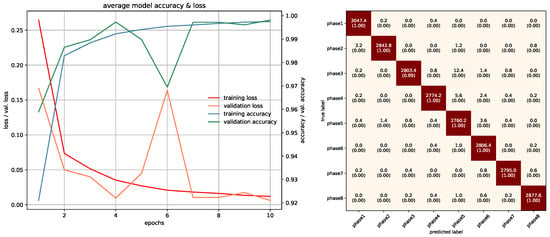
Figure 17.
Training/Testing results of Inception-V3 RGB model.
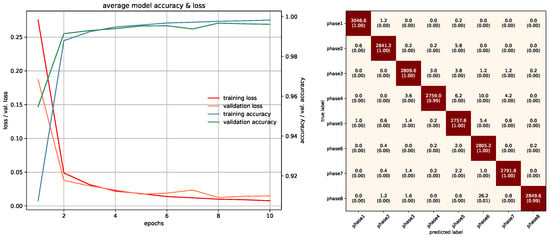
Figure 18.
Training/Testing results of MobileNet-V1 RGB model.
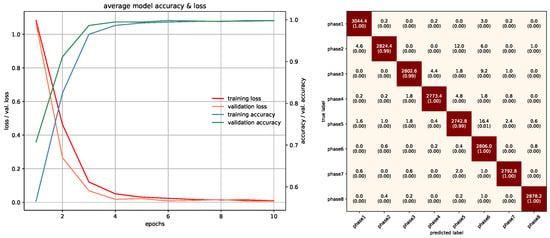
Figure 19.
Training/Testing results of ResNet-50 RGB model.
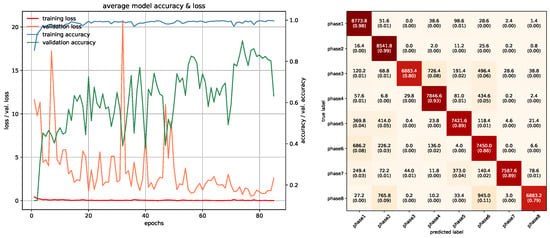
Figure 20.
Training/Testing results of Inception-V3 Projection model.
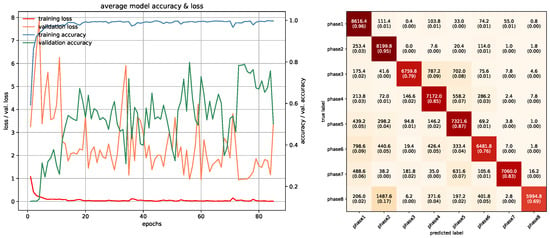
Figure 21.
Training/Testing results of Mobilenet-V1 Projection model.
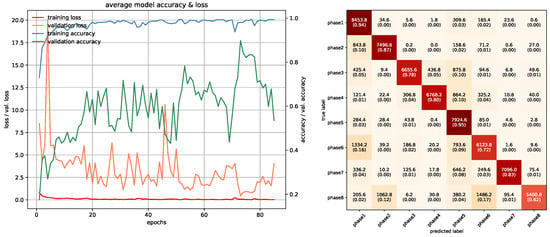
Figure 22.
Training/Testing results of ResNet-50 Projection model.
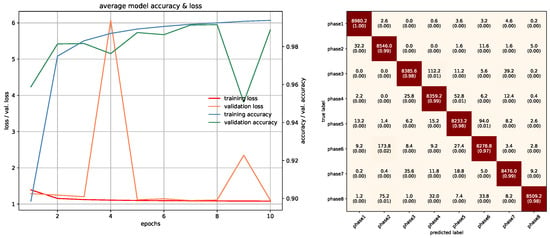
Figure 23.
Training/Testing results of PointNet PCD model.
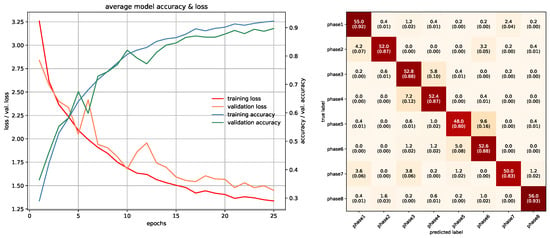
Figure 24.
Training/Testing results of PointNet PGM model.
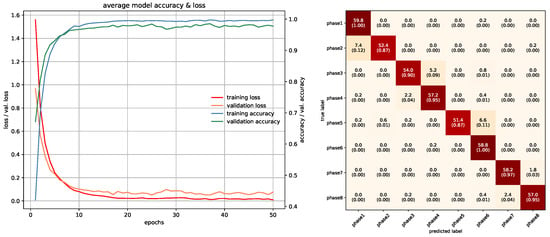
Figure 25.
Training/Testing results of VGG-16-LSTM RGB model.
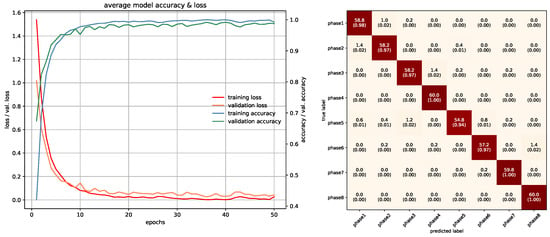
Figure 26.
Training/Testing results of VGG-16-LSTM Projection model.
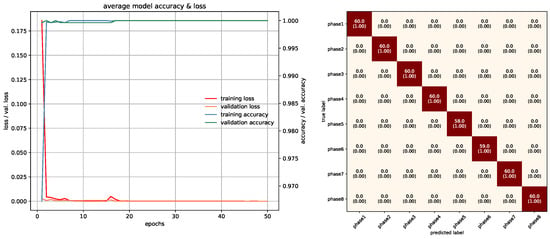
Figure 27.
Training/Testing results of PointNet-LSTM model.
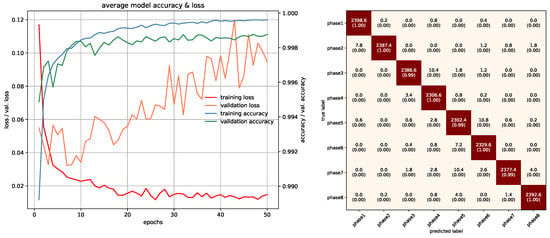
Figure 28.
Training/Testing results of Fusion-Custom Layers model.
A brief list of previous research in this area is summarized in Table 4. A direct comparison is impracticable due to different datasets and gesture amounts.
Table 4.
List of related research with gesture amounts and approaches.
5. Discussion
In our study, we classified 8 hand gestures from hand-washing guidelines recommended by WHO, with 12 different neural network models and 4 different data models (RGB, PCD, PGM, Projection) proposed. The average accuracy of all methods was 94.23%, the highest being PointNet combined with LSTM successfully classifying all samples without any error. Gestures were symmetrical of each other and they contained both hands. Our results showed that:
- It is possible to classify gestures of hand-washing procedure with high accuracy when both hands are captured in a single frame and treated as a single object rather than separate objects.
- We demonstrated that our introduced idea of using projection images and PGMs can be effectively used for hand-washing evaluation.
- Suggested camera positioning is efficient for data acquisition and robust hand tracking.
For further research, this study can be expanded with additional datasets, with trajectory information that can be easily obtained using a central point on hands with PCDs. Additionally, PCDs can include color information which may increase classification performance and PCDs can be clipped to eliminate noise, leaving only the hand–arm information.
Author Contributions
Conceptualization, supervision, E.G.; investigation, methodology, validation, formal analysis, writing, R.Ö. and E.G.; software, visualization, data curation, resources, R.Ö. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Zhou, Q.; Gao, Y.; Wang, X.; Liu, R.; Du, P.; Wang, X.; Zhang, X.; Lu, S.; Wang, Z.; Shi, Q.; et al. Nosocomial infections among patients with COVID-19, SARS and MERS: A rapid review and meta-analysis. Ann. Transl. Med. 2020, 8, 629. [Google Scholar] [CrossRef] [PubMed]
- Wiener-Well, Y.; Galuty, M.; Rudensky, B.; Schlesinger, Y.; Attias, D.; Yinnon, A.M. Nursing and physician attire as possible source of nosocomial infections. Am. J. Infect. Control 2011, 39, 555–559. [Google Scholar] [CrossRef] [PubMed]
- WHO’s Hand Washing Guidelines. Available online: https://www.who.int/multi-media/details/how-to-handwash-and-handrub (accessed on 15 February 2023).
- Llorca, D.F.; Parra, I.; Sotelo, M.Á.; Lacey, G. A vision-based system for automatic hand washing quality assessment. Mach. Vis. Appl. 2011, 22, 219–234. [Google Scholar] [CrossRef]
- Xia, B.; Dahyot, R.; Ruttle, J.; Caulfield, D.; Lacey, G. Hand hygiene poses recognition with rgb-d videos. In Proceedings of the 17th Irish Machine Vision and Image Processing Conference, Dublin, Ireland, 26–28 August 2015; pp. 43–50. [Google Scholar]
- Ivanovs, M.; Kadikis, R.; Lulla, M.; Rutkovskis, A.; Elsts, A. Automated quality assessment of hand washing using deep learning. arXiv 2020, arXiv:2011.11383. [Google Scholar]
- Prakasa, E.; Sugiarto, B. Video Analysis on Handwashing Movement for the Completeness Evaluation. In Proceedings of the 2020 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Serpong, Indonesia, 18–20 November 2020; pp. 296–301. [Google Scholar]
- Vo, H.Q.; Do, T.; Pham, V.C.; Nguyen, D.; Duong, A.T.; Tran, Q.D. Fine-grained hand gesture recognition in multi-viewpoint hand hygiene. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 1443–1448. [Google Scholar]
- Zhong, C.; Reibman, A.R.; Mina, H.A.; Deering, A.J. Designing a Computer-Vision Application: A Case Study for Hand-Hygiene Assessment in an Open-Room Environment. J. Imaging 2021, 7, 170. [Google Scholar] [CrossRef] [PubMed]
- Xie, T.; Tian, J.; Ma, L. A vision-based hand hygiene monitoring approach using self-attention convolutional neural network. Biomed. Signal Process. Control 2022, 76, 103651. [Google Scholar] [CrossRef]
- Mondol, M.A.S.; Stankovic, J.A. Harmony: A hand wash monitoring and reminder system using smart watches. In Proceedings of the 12th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services on 12th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, Coimbra, Portugal, 22–24 July 2015; pp. 11–20. [Google Scholar]
- Wang, C.; Sarsenbayeva, Z.; Chen, X.; Dingler, T.; Goncalves, J.; Kostakos, V. Accurate measurement of handwash quality using sensor armbands: Instrument validation study. JMIR mHealth uHealth 2020, 8, e17001. [Google Scholar] [CrossRef] [PubMed]
- Samyoun, S.; Shubha, S.S.; Mondol, M.A.S.; Stankovic, J.A. iWash: A smartwatch handwashing quality assessment and reminder system with real-time feedback in the context of infectious disease. Smart Health 2021, 19, 100171. [Google Scholar] [CrossRef] [PubMed]
- Santos-Gago, J.M.; Ramos-Merino, M.; Álvarez-Sabucedo, L.M. Identification of free and WHO-compliant handwashing moments using low cost wrist-worn wearables. IEEE Access 2021, 9, 133574–133593. [Google Scholar] [CrossRef]
- Wang, F.; Wu, X.; Wang, X.; Chi, J.; Shi, J.; Huang, D. You Can Wash Better: Daily Handwashing Assessment with Smartwatches. arXiv 2021, arXiv:2112.06657. [Google Scholar]
- Zhang, Y.; Xue, T.; Liu, Z.; Chen, W.; Vanrumste, B. Detecting hand washing activity among activities of daily living and classification of WHO hand washing techniques using wearable devices and machine learning algorithms. Healthc. Technol. Lett. 2021, 8, 148. [Google Scholar] [CrossRef] [PubMed]
- Microsoft’s Kinect-2.0 Camera. Available online: https://developer.microsoft.com/en-us/windows/kinect/ (accessed on 15 February 2023).
- Depth Cameras. Available online: https://rosindustrial.org/3d-camera-survey (accessed on 13 April 2023).
- Cheng, H.; Yang, L.; Liu, Z. Survey on 3D hand gesture recognition. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1659–1673. [Google Scholar] [CrossRef]
- Caputo, A.; Giachetti, A.; Soso, S.; Pintani, D.; D’Eusanio, A.; Pini, S.; Borghi, G.; Simoni, A.; Vezzani, R.; Cucchiara, R.; et al. SHREC 2021: Skeleton-based hand gesture recognition in the wild. Comput. Graph. 2021, 99, 201–211. [Google Scholar] [CrossRef]
- Youtube Comparison of Depth Cameras. Available online: https://youtu.be/NrIgjK_PeQU (accessed on 15 February 2023).
- PyKinect2. Available online: https://github.com/Kinect/PyKinect2 (accessed on 15 February 2023).
- Oudah, M.; Al-Naji, A.; Chahl, J. Hand gesture recognition based on computer vision: A review of techniques. J. Imaging 2020, 6, 73. [Google Scholar] [CrossRef] [PubMed]
- Jian, C.; Li, J. Real-time multi-trajectory matching for dynamic hand gesture recognition. IET Image Process. 2020, 14, 236–244. [Google Scholar] [CrossRef]
- OpenCV Library. Available online: https://opencv.org/ (accessed on 15 February 2023).
- Open3d Library. Available online: http://www.open3d.org/ (accessed on 15 February 2023).
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- PointNet-Keras Implementation. Available online: https://keras.io/examples/vision/pointnet/ (accessed on 15 February 2023).
- Liang, C.; Song, Y.; Zhang, Y. Hand gesture recognition using view projection from point cloud. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 4413–4417. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3d hand pose estimation in single depth images: From single-view cnn to multi-view cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3593–3601. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Yan, M.; Bohg, J. Meteornet: Deep learning on dynamic 3d point cloud sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9246–9255. [Google Scholar]
- Chen, J.; Meng, J.; Wang, X.; Yuan, J. Dynamic graph cnn for event-camera based gesture recognition. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Virtual, 10–21 October 2020; pp. 1–5. [Google Scholar]
- Tensorflow-Keras Library. Available online: https://keras.io/about/ (accessed on 15 February 2023).
- Plaid-ML Compiler. Available online: https://github.com/plaidml/plaidml (accessed on 15 February 2023).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]




























Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).