This section provides an overview of the design aspects and architecture of the proposed processor core. As illustrated in
Figure 2, the processor is implemented with a five-stage pipelined organization, consisting of the following stages: (a) Instruction Fetch and Instruction Decode (IF and ID), (b) Instruction Issue (IS), (c) Execution (EX), (d) Memory Access (MEM), and (e) Write Back (WB). All stages of the processor pipeline are in order. The subsequent discussion will delve into the specific module design of each stage within the pipeline.
3.1. Instruction Fetch and Decode (IF and ID)
The IF and ID stage of the microprocessor pipeline is mainly responsible for the fetching and decoding of the instructions. The processed instructions are sent to the lower-level issue module, which then distributes them to each logic unit in the execution stage. In the proposed processor core, the completion of the IF and ID stage is orchestrated by two distinguished functional modules: “FETCH” and “DECODE”.
In this design, the “FETCH” module is mainly responsible for executing the operation of fetching instructions from the instruction memory. Since there are two configurable modes of low power consumption and high performance in the proposed architecture, the “FETCH” module has two different connection methods. In the low-power configuration, the ITCM will serve as the instruction memory of the proposed processor to which the “FETCH” module is directly connected. In the high-performance mode, the “FETCH” module will be connected to the MMU to support ICACHE. In fact, the difference in the above connection methods does not impact the functional realization of the “FETCH” module. Therefore, the following explanation will take the case equipped with ITCM as an example to explain the implementation of the “FETCH” module in the proposed architecture.
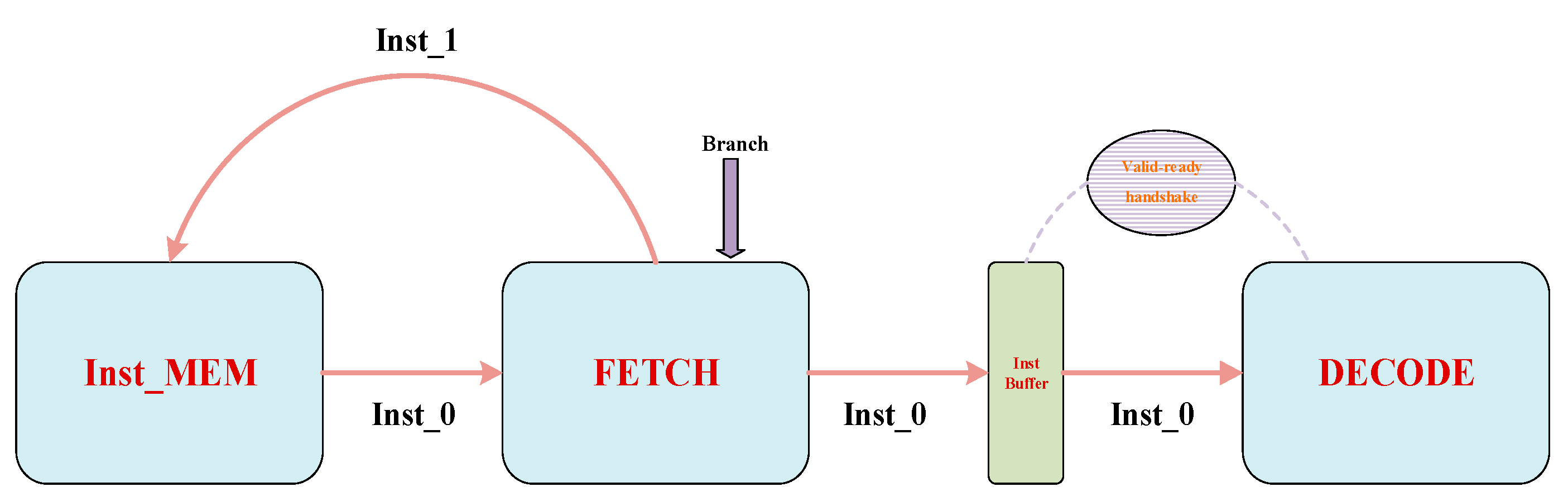
As illustrated in
Figure 2, the “FETCH” module is mainly responsible for fetching instructions from the ITCM and transmitting them to the “DECODE” module for decoding.
In addition, the “FETCH” module also needs to be responsible for the interruption and abnormal operation of the “FETCH & DECODE STAGE”, which is embodied as the branch request from the “CSR” module and the “EXEC” module in the proposed architecture. The workflow of the proposed “FETCH” module is shown in
Figure 3. In one clock cycle, if the data paths of the “FETCH” module are clear, the “FETCH” module will send a read request (referred to as Inst_1) to the instruction memory while simultaneously receiving the instruction (Inst_0) requested in the previous cycle from the instruction memory. The “FTECH” module then transfers Inst_0 to the “DECODE” module using the valid-ready handshake mechanism.
If the data path is not always clear, it can be blocked in the following situations: (1) the instruction memory fails to promptly return the instruction requested by the “FETCH” module in the previous cycle, as seen in
Figure 4a; (2) the “DECODE” module is not ready yet, unable to handshake with the “FETCH” module, as seen in
Figure 4b. For situation (1), the “FETCH” module enters the stalling state, during which no data transmission occurs along the entire data path, extending from the instruction memory to the “DECODE” module, which can be seen in cycle 1 of
Figure 4a. When the instruction memory successfully returns the instruction in a certain clock cycle, the “FETCH” module restarts and continues to fetch instructions in order, which can be seen in cycles 2 and 3 of
Figure 4a. As seen in
Figure 4a, there is no data loss during the entire suspension of situation (1). For situation (2), the “FETCH” module also enters the stalling state. However, if the instruction memory returns the instruction in this clock cycle, there exists data transmission along the data path, which extends from the instruction memory to the “FETCH” module, as seen in cycle 1 of
Figure 4b. As depicted in cycle 2 of
Figure 4b, there will be data loss if the entire data path is restored in the cycle. To avert such a situation, the proposed “FETCH” module incorporates an “Inst-buffer” component, which is shown in
Figure 4b. When situation (2) arises, the “Inst-buffer” stores the returned data from the instruction memory. Upon data path restoration, it is transmitted to the “DECODE” module through a handshake, ensuring that data integrity is maintained.
As mentioned earlier, another important responsibility of the “FETCH” module is to process the branch signals from the “CSR” module and the “EXEC” module in the proposed architecture. The branch signals from the above two modules are generated at the third stage of the pipeline (EXEC STAGE). This means that the “FETCH” module should fetch the target instruction in the third cycle after receiving the branch signal to ensure the orderly execution of tasks on the pipeline.
In the proposed architecture, the “FETCH” module will deliver the retrieved instructions to the “DECODE” module to generate the corresponding control information. The “DECODE” module is tasked with the responsibility of decoding the instructions stored in memory. Its primary function is to furnish the system with the essential information necessary for the accurate execution of the code, while also identifying illegal instructions. As illustrated in
Figure 1, the fields in the RISC-V ISA are always encoded in the same place inside the instruction body, which makes the decoding fairly straightforward. The “DECODE” module is entirely realized by combinational logic, wherein the instruction type is ascertained through the utilization of masks specifically tailored for different RISC-V instructions. In addition to the identification and legality judgment of specific instructions, the “DECODE” module also integrates the functionality of the instruction classification. This capability allows for the rough categorization of instructions, enabling the determination of the appropriate post-level functional module to which the instruction should be directed. To sum up, the “DECODE” module will send the generated corresponding information to the “ISSUE” module, in which the information will be used to control the transmission of instructions.
3.2. Instruction Issue (IS)
Upon completion of the IF and ID stage, the decoded instructions are fed into the Instruction Issue (IS) stage. The core focus of this stage is to achieve instruction arbitration and allocation, while also implementing data flow control across the entire pipeline. In the proposed processor core, the completion of the IS stage is orchestrated by the “ISSUE” module.
As shown in
Figure 5, the “ISSUE” module consists of two main functional units: the “pipeline ctrl” module and the general register file, along with the branch request generate logic. The “pipeline ctrl” module is invoked by the “ISSUE” module in the proposed architecture. It is responsible for storing the control information emitted by the top-level “ISSUE” module, receiving the information returned by the instructions in the “EXEC”, “MEM”, and “WB” stages. It tracks the status of the instructions and issues signals to squash or stall the pipeline according to the above control signals. The “pipeline ctrl” module primarily achieves the tracking of pipeline states from two aspects: control flow and status flow. In the data flow, the “pipeline ctrl” module receives the computation results returned by instructions at different stages of the pipeline and stores them in registers, which can be seen in
Figure 6a. Then, the computation result will be uniformly recorded back to the general register file and CSR register file during the WB (write back) stage. Furthermore, in the proposed architecture, configurable bypass support has been added for the LOAD and MUL operations to enhance the efficiency of the pipeline execution. This feature is implemented in the data path of the “pipeline ctrl” through data coverage. If the bypass configuration of the processor is valid, the results of the MUL or LOAD operations will be directly forwarded to the data output path within the same cycle instead of being stored until the WB stage. The addition of the bypass avoids the situation that the results are already calculated in the pipeline and that will affect the subsequent instruction issue due to the output delay, which leads to a more efficient data flow and improves the overall throughput of the pipeline.
Based on the description of
Figure 6b, the control flow objectives of the “pipeline ctrl” module mainly involve the following two tasks:
- (1)
Handling Exceptions and Generating Pipeline Flush Requests (“Squash”):
The module receives and processes exceptional signals returned by instructions at different stages of the pipeline. When an exception occurs, the “pipeline ctrl” generates pipeline flush requests, also known as “Squash,” to clear or invalidate the instructions in the pipeline, preventing incorrect or corrupted results from being committed.
- (2)
Generating Pipeline Stall Requests (“Stall”):
The “pipeline ctrl” module generates pipeline stall requests, also referred to as “Stall”, based on the processing progress of various modules in the lower stages of the pipeline. These stall requests are used to pause the advancement of new instructions into the pipeline temporarily, ensuring that the pipeline’s stages have sufficient time to complete their current operations before accepting new instructions.
It is worth noting that the data flow and control flow of the pipeline control module described above are interleaved in some cases. This situation mainly exists in the process of writing back to the CSR. For the CSR, an exception is not just a control signal but also data information that needs to be stored, so the exception signal in the control flow needs to be interleaved into the data flow in the write-back stage and then stored in the CSR.
As illustrated in
Figure 5, the pipeline control module will deliver the returned control flow and data flow results to the register control logic and pipeline control signal generation logic. Among these components, the “pipeline_ctrl_gen” logic is responsible for broadcasting flush or stall signals to the entire pipeline. On the other hand, the register control logic is tasked with determining whether the corresponding operand register is active, based on the control flow information returned by the “pipeline ctrl” module. Simultaneously, it stores the content of the data flow into the target register. In the proposed architecture, the access control of the general-purpose register file is built around a simple score-boarding mechanism, which keeps track of the status of each physical register. The score board has a total of 32 entries, one for each physical register. It keeps track of each register’s usage as well as the location of the latest data.
Alongside the “pipeline ctrl” module and the general-purpose register file, another crucial component of the “ISSUE” module is the “branch request generate logic”. This logic is implemented using pure combinational logic. Under its control, the “ISSUE” module receives branch requests from both the “EXEC” module and the “CSR” module. Simultaneously, it forwards the target PC address and target privilege level required for the branch jump.
3.3. Back-End [Execution (EXEC)/Memory Access (MEM)/Write Back (WB)]
In the “ISSUE” stage, the instructions are distributed to the functional modules of the subsequent stages in an orderly manner. Since the running time of these functional modules spans the last three stages of the entire pipeline, explaining according to the pipeline stages will lead to the separation of the functional modules. To provide a clearer understanding of the pipeline’s working mechanism in the proposed architecture, the last three stages of the five-stage pipeline (“EXEC” stage, “MEM” stage, and “WB” stage) are consolidated into the “back-end” for explanation.
In the proposed architecture, the back-end consists of five distinct functional units, which will be explained in the following sections.
3.3.1. EXEC Module
In the proposed architecture, the “EXEC” module is responsible for the following two functions:
Executing integer computational instructions in the RISC-V ISA.
Resolving all branch instructions and generating the target address and target privilege level of the branch jump.
For the first function, an Arithmetic Logic Unit (ALU) is integrated into the “EXEC” module. In order to maintain the consistency of the pipeline, the results calculated by ALU through combinational logic will be stored for one beat and then sent to the data path. For the second function, the “EXEC” module directly implements the received branch instruction with combinational logic and issues the result in the current cycle, thereby reducing the number of invalid instruction fetches and improving pipeline efficiency.
3.3.2. MUL Module
In the proposed architecture, the “MUL” module is responsible for implementing the “M” standard extension for integer multiplication of the RISC-V ISA. Without any beating processing, the “MUL” module will return the calculation result within one cycle. In order to match the pipeline, the result will be delayed by two cycles and then delivered to the data path. This module is configurable, allowing it to be removed from the design when pursuing objectives such as a small area and low power consumption. Moreover, the proposed processor offers bypass support for this module, ensuring smoother data flow and minimizing pipeline stalls.
3.3.3. DIV Module
In the proposed architecture, the “DIV” module is responsible for implementing the “M” standard extension for integer division of the RISC-V ISA. In the proposed processor, the “DIV” module is implemented using a standard shift-divider, which means that the division operation takes 2–34 cycles. Therefore, the division operation in the proposed processor is completed out of the pipeline. In other words, when a division instruction is encountered, the pipeline temporarily stalls and awaits completion of the operation by the “DIV” module.
As shown in
Figure 7, in the proposed architecture, the divider employs a standard pipelined shifting method for implementation. As the divisor is shifted, and if it becomes less than or equal to the dividend during the shifting process, the shifting pointer maps its current position to the result. Simultaneously, subtraction operations are performed between “dividend-compare” and “divisor-compare” to obtain the remainder. Additionally, the proposed divider includes combinatorial logic for distinguishing between signed and unsigned operations as well as for handling both remainder and division operations.
3.3.4. LSU Module
The LSU (Load Storage Unit) is mainly used as a control module for memory access in the processor. In the proposed architecture, this unit is responsible for implementing the Load and Store instructions of RV32I and the CSR operations on the memory. As shown in
Figure 8, the workflow of the LSU is pipelined by three stages in the proposed architecture. The following text will discuss the limit case of the pipeline in which the LSU receives memory access instructions in three consecutive cycles. As depicted in
Figure 8, there is some overlap between the three-stage pipeline of the LSU and the five-stage pipeline of the processor. In the “ISSUE” stage, the LSU receives data and control signals from the “ISSUE” module, which includes instruction types, operands, etc. The information will be registered to the next cycle and generate an access request to the memory in the “EXEC” stage. Additionally, in the EXEC stage, the LSU stores the control information corresponding to the memory access request initiated at this time into the ctrl-fifo. The information will be used in the “MEM” stage to cut and replace the bit width of the result returned by the memory. In the “MEM” stage, the LSU receives the memory access result and performs a return value judgment and exception generation.
The resulting judgment mentioned above mainly occurs when the memory reports an access error. At this point, the returned result needs to be replaced with the memory address where the error occurred. In addition, there is backpressure between each stage of the three-stage pipeline in the LSU. The LSU is designed to automatically wait for one cycle to increase redundancy when the correct memory access result is not received in the “MEM” stage.
3.3.5. CSR Module
In the proposed architecture, the “CSR” module is responsible for handling the exceptions and interrupts of the entire system. Whether it is an exception from inside the processor or an interruption from outside the processor, it will be delivered to the “CSR” module during the “ISSUE” stage or the “WB” stage of the pipeline. As illustrated in
Figure 9, the internal workflow of the “CSR” module can be primarily segmented into two main parts:
The update of the csr-regfile: this part is completed by more complex timing logic, and the updating of the csr-register occurs under the following five conditions:
- (1)
Interrupt
- (2)
Exception-return
- (3)
Exception handled in super privilege level
- (4)
Exception handled in machine privilege level
- (5)
CSR register write
Interrupt signals and branch signals are generated according to the data stored in the csr-regfile in the current cycle.
Figure 9.
The internal architecture diagram of the “CSR” module.
Figure 9.
The internal architecture diagram of the “CSR” module.
It is worth noting that the write instruction for the CSR does not write data to the csr-regfile during the cycle received by the “CSR” module. These data will be returned to the “pipeline-ctrl” module for storage, and then they are written back to the csr-regfile until the “WB” stage. Since the logic of the “CSR” module is relatively complex and is closely related to the pipeline of the entire processor, the pipeline will be stalled while the “CSR” module is running in order to avoid errors.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}