
Engineering, Emulators, Digital Twins, and Performance Engineering


Abstract
:1. Introduction
2. Methodology: The Design and Analysis of Emulators
2.1. Design of Emulators of Systems
2.2. Computer Experiments from Simulations
2.3. Optimising Products and Processes
- Modelling: This can be derived from the results of an initial experiment, purely on theoretical grounds, or by a combination of the two.
- Uncertainty: Characterising uncertainty in the system is describing how the input factors vary.
- Computer experiment design: Plan a computer experimental design of the input factors.
- Generate simulated data: Apply the noise distributions in the computer experimental design.
- Stochastic emulator: Construct a model that relates response variables to the design factor settings.
- Optimisation: Determine a setup that ensures optimisation of both target performance and robustness.
2.4. Other Methods
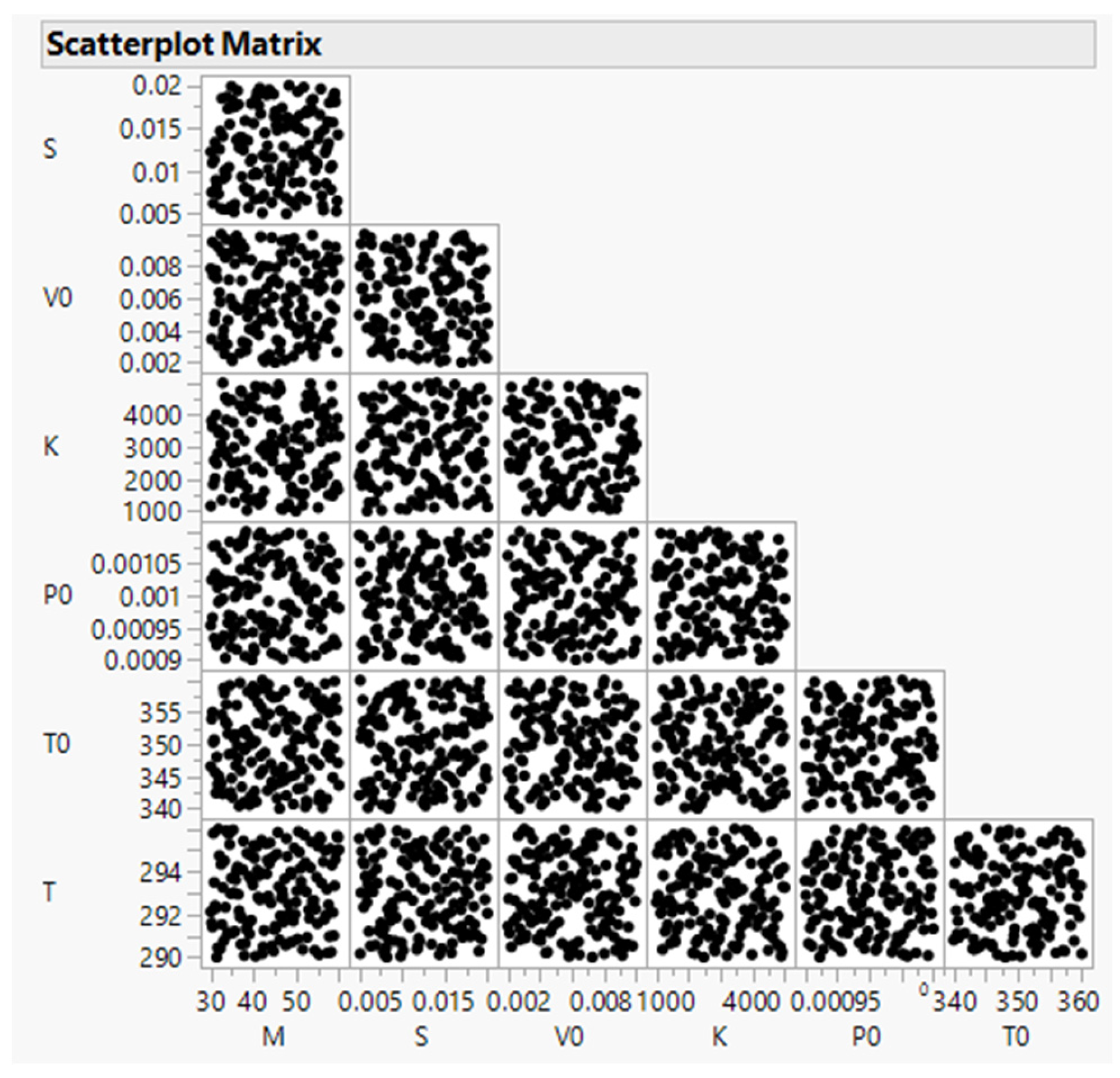
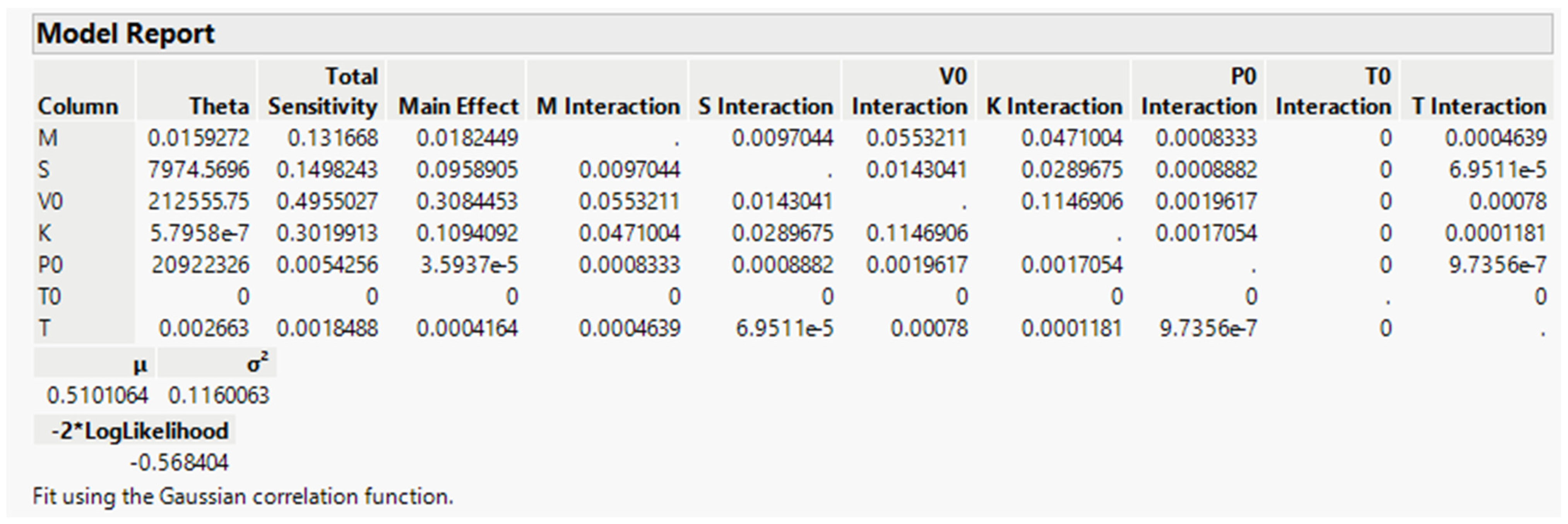
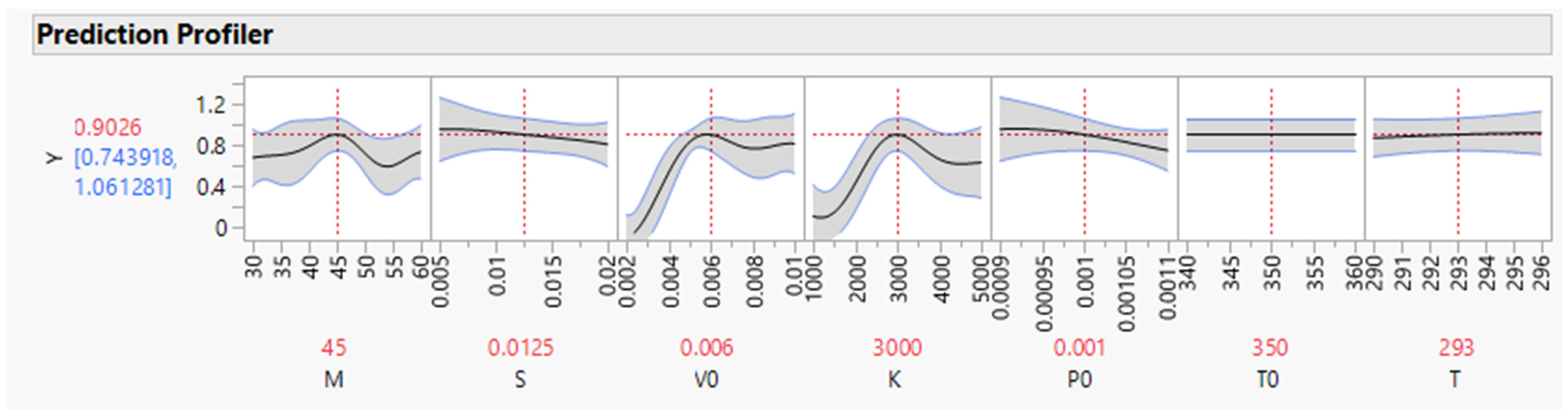
3. Case Study 1: The Piston Simulator
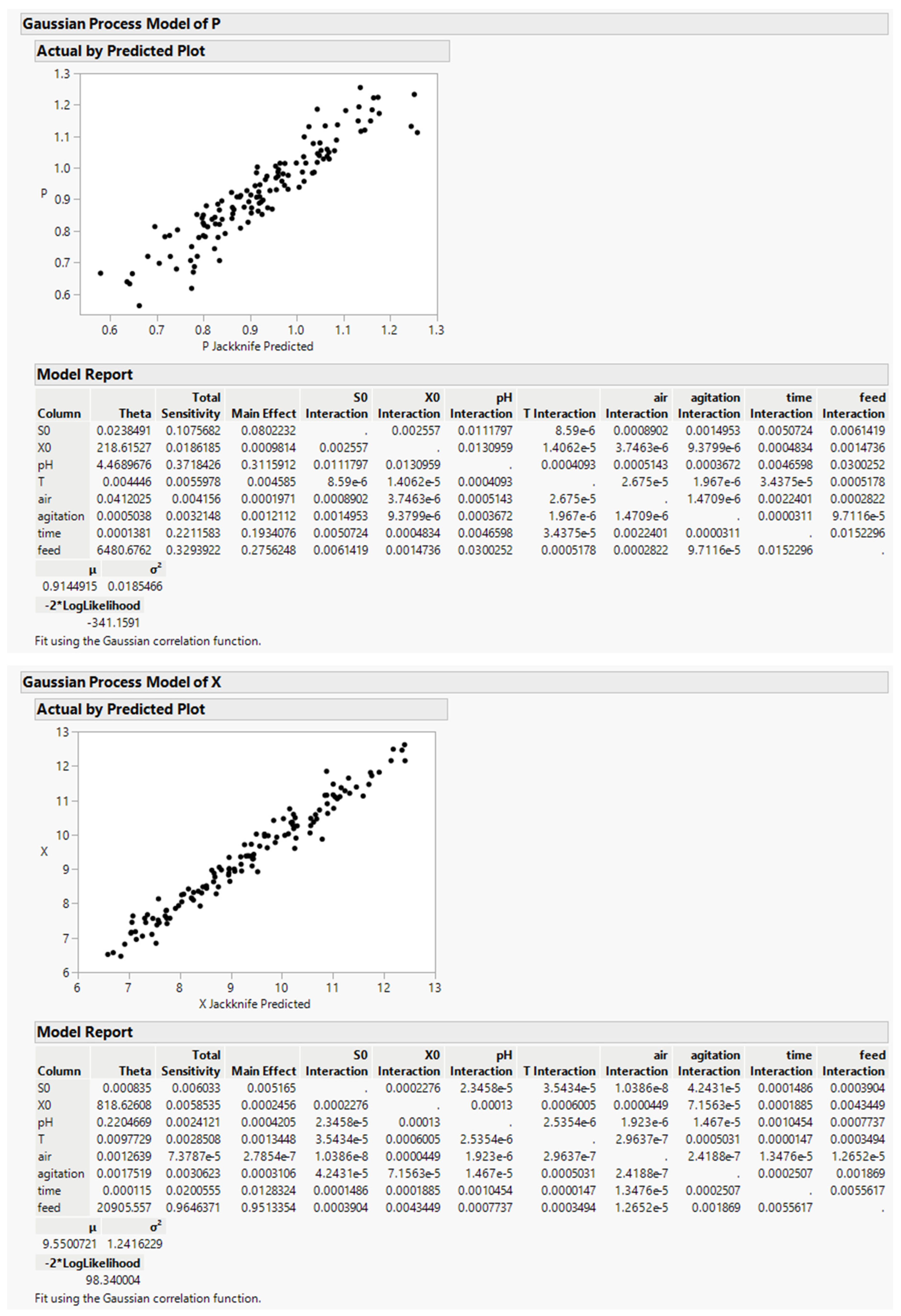
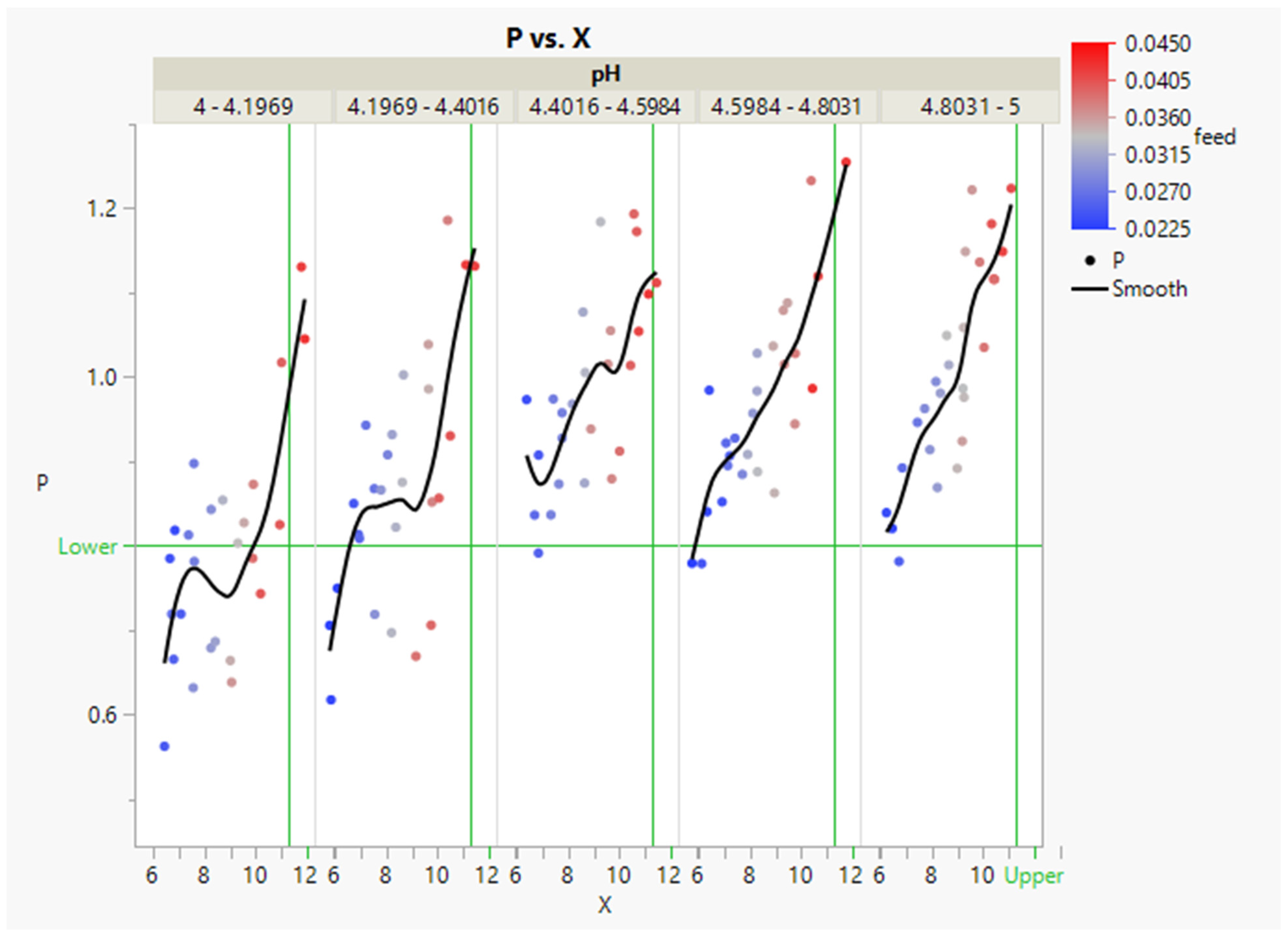
4. Case Study 2: The PENSIM Simulator
5. Discussion and Conclusions
- A description of emulators that can be derived from computationally intensive models using Gaussian processes.
- Consideration of hybrid models combining physical and simulations-based data.
- Applications of emulators for enhanced monitoring and diagnostics.
- Incorporation of emulators in digital twin platforms.
- An introduction of stochastic emulators to optimise performance and robustness.
- Case studies demonstrating the above.
Funding
Data Availability Statement
Conflicts of Interest
References
- Kenett, R.S.; Bortman, J. The digital twin in Industry 4.0: A wide-angle perspective. Qual. Reliab. Eng. Int. 2022, 38, 1357–1366. [Google Scholar] [CrossRef]
- Chinesta, F.; Cueto, E.; Abisset-Chavanne, E.; Duval, J.L.; El Khaldi, F. Virtual, Digital and Hybrid Twins: A New Paradigm in Data-Based Engineering and Engineered Data. Arch. Comput. Methods Eng. 2018, 27, 105–134. [Google Scholar] [CrossRef]
- Gabriel, D.; Bortman, J.; Kenett, R.S. Development of an Operational Digital Twin of a Locomotive Parking Brake for Fault Diagnosis. Sci. Rep. 2023, 13, 17959. [Google Scholar]
- Grieves, M. Digital twin: Manufacturing excellence through virtual factory replication. White Pap. 2014, 1, 1–7. [Google Scholar]
- Van der Valk, H.; Haße, H.; Möller, F.; Arbter, M.; Henning, J.L.; Otto, B. A Taxonomy of Digital Twins. In Proceedings of the AMCIS, Virtual, 10–14 August 2020. [Google Scholar]
- Zienkiewicz, O.C. The Finite Element Methods in Engineering Science; McGraw-Hill: New York, NY, USA, 1971. [Google Scholar]
- Kenett, R.S.; Zacks, S.; Gedeck, P. Modern Statistics: A Computer-Based Approach with Python; Birkhäuser: Basel, Switzerland, 2022. [Google Scholar]
- Kenett, R.S.; Zacks, S.; Gedeck, P. Industrial Statistics: A Computer-Based Approach with Python; Springer Nature: New York, NY, USA, 2023. [Google Scholar]
- Simon Fraser Virtual Lab. Available online: https://www.sfu.ca/~ssurjano/emulat.html (accessed on 20 May 2023).
- Birol, I.; Undey, C.; Birol, G.; Cinar, A. A web-based simulator for penicillin fermentation. Int. J. Eng. Simul. 2001, 2, 24–30. [Google Scholar]
- Birol, G.; Ündey, C.; Çinar, A. A modular simulation package for fed-batch fermentation: Penicillin production. Comput. Chem. Eng. 2002, 26, 1553–1565. [Google Scholar] [CrossRef]
- Santner, T.J.; Williams, B.J.; Notz, W.I.; Williams, B.J. The Design and Analysis of Computer Experiments; Springer: New York, NY, USA, 2003; Volume 1. [Google Scholar]
- Kenett, R.S.; Vicario, G. Challenges and opportunities in simulations and computer experiments in industrial statistics: An industry 4.0 perspective. Adv. Theory Simul. 2021, 4, 2000254. [Google Scholar] [CrossRef]
- Vakayil, A.; Joseph, V.R. A Global-Local Approximation Framework for Large-Scale Gaussian Process Modeling. Technometrics 2024, 66, 295–305. [Google Scholar] [CrossRef]
- Sack, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and analysis of computer experiments (with discussion). Stat. Sci. 1989, 4, 409–423. [Google Scholar]
- Roustant, O.; Joucla, J.; Probst, P. Kriging as an alternative for a more precise analysis of output parameters in nuclear safety—Large break LOCA calculation. Appl. Stoch. Models Bus. Ind. 2010, 26, 565–576. [Google Scholar] [CrossRef]
- Stein, M.L. Interpolation of Spatial Data: Some Theory for Kriging; Springer Science & Business Media: New York, NY, USA, 2012. [Google Scholar]
- Huang, D.; Allen, T.T. Design and analysis of variable fidelity experimentation applied to engine valve heat treatment process design. J. R. Stat. Soc. Ser. C Appl. Stat. 2005, 54, 443–463. [Google Scholar] [CrossRef]
- Reese, C.S.; Wilson, A.G.; Hamada, M.; Martz, H.F.; Ryan, K.J. Integrated analysis of computer and physical experiments. Technometrics 2004, 46, 153–164. [Google Scholar] [CrossRef]
- Stinstra, E.; Hertog, D.D. Robust optimization using computer experiments. Eur. J. Oper. Res. 2008, 191, 816–837. [Google Scholar] [CrossRef]
- Krige, D.G. A statistical approach to some basic mine valuation problems on the Witwatersrand. J. South. Afr. Inst. Min. Metall. 1951, 52, 119–139. [Google Scholar]
- Zhang, Q.; Qiao, P.; Wu, Y. A novel kriging-improved high-dimensional model representation metamodelling technique for approximating high-dimensional problems. Eng. Optim. 2024, 1–24. [Google Scholar] [CrossRef]
- Jones, D.R.; Schonlau, M.; Welch, W.J. Efficient global optimization of expensive black-box functions. J. Glob. Optim. 1998, 13, 455–492. [Google Scholar] [CrossRef]
- Allen, T.T.; Bernshteyn, M.A.; Kabiri-Bamoradian, K. Constructing meta-models for computer experiments. Qual. Control. Appl. Stat. 2004, 49, 321–322. [Google Scholar] [CrossRef]
- Stinstra, E.; Hertog, D.D.; Stehouwer, P.; Vestjens, A. Constrained maximin designs for computer experiments. Technometrics 2003, 45, 340–346. [Google Scholar] [CrossRef]
- Kennedy, M.C.; O’Hagan, A. Predicting the output from a complex computer code when fast approximations are available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef]
- Ahmad, A.; Samad, N.A.F.A.; Wei, C.A. Mathematical Modelling and Analysis of Dynamic Behaviour of a Fed-batch Penicillin G Fermentation Process. In Proceedings of the International Conference on Chemical and Bioprocess Engineering, Kota Kinabalu, Sabah, 27–29 August 2003; Volume 2, pp. 387–394. [Google Scholar]
- PENSIM v2. Available online: http://www.industrialpenicillinsimulation.com/ (accessed on 20 May 2023).
- Stark, R.; Fresemann, C.; Lindow, K. Development and operation of Digital Twins for technical systems and services. CIRP Ann. 2019, 68, 129–132. [Google Scholar] [CrossRef]
- Burczyński, T.; Skrzypczyk, J. Theoretical and computational aspects of the stochastic boundary element method. Comput. Methods Appl. Mech. Eng. 1999, 168, 321–344. [Google Scholar] [CrossRef]
- Girolami, M.; Febrianto, E.; Yin, G.; Cirak, F. The statistical finite element method (statFEM) for coherent synthesis of observation data and model predictions. Comput. Methods Appl. Mech. Eng. 2021, 375, 113533. [Google Scholar] [CrossRef]
- Sharma, A.; Kosasih, E.; Zhang, J.; Brintrup, A.; Calinescu, A. Digital twins: State of the art theory and practice, challenges, and open research questions. J. Ind. Inf. Integr. 2022, 30, 100383. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Factor | Lower Level | Higher Level |
|---|---|---|
| S0 | 5 | 15 |
| X0 | 0.05 | 0.1 |
| pH | 4 | 5 |
| T | 293 | 298 |
| air | 6 | 8.6 |
| agitation | 15 | 29.9 |
| time | 250 | 350 |
| feed | 0.0226 | 0.0426 |
| S0 | X0 | pH | T | Air | Agitation | Time | Feed |
|---|---|---|---|---|---|---|---|
| 9.9994526 | 0.0778006 | 4.8308467 | 297.99973 | 7.2998112 | 15.000027 | 350 | 0.0417674 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kenett, R.S. Engineering, Emulators, Digital Twins, and Performance Engineering. Electronics 2024, 13, 1829. https://doi.org/10.3390/electronics13101829
Kenett RS. Engineering, Emulators, Digital Twins, and Performance Engineering. Electronics. 2024; 13(10):1829. https://doi.org/10.3390/electronics13101829
Chicago/Turabian StyleKenett, Ron S. 2024. "Engineering, Emulators, Digital Twins, and Performance Engineering" Electronics 13, no. 10: 1829. https://doi.org/10.3390/electronics13101829
APA StyleKenett, R. S. (2024). Engineering, Emulators, Digital Twins, and Performance Engineering. Electronics, 13(10), 1829. https://doi.org/10.3390/electronics13101829