
A High-Performance Non-Indexed Text Search System
 , , , , , , and
, , , , , , and
Abstract
:1. Introduction
- Scalability: The search system could be deployed on various devices and environments, putting different requirements in place. For example, the authors in [6,7] defined the restrictions of the search system on fog computers. Therefore, to exhaust the resources of the devices and satisfy the constraints, the search system needs to be scaled.
- Index independence: The search system must process a large amount of local data collected over time. This means the indexes are updated regularly. In addition, indexing and retrieving a small amount of local data are simple. However, managing extensive indexes and databases over distributed systems requires sophisticated techniques [8]. Some recent studies on indexing techniques have highlighted optimizing the search performance in large datasets with greater efficiency in performance and storage usage [8,9,10]. Besides the existing index-based search algorithms, the non-index search methods, which ignore the index step, should be considered.
- Performance and resource restrictions: The feature of IoT systems is distribution. The nodes in such systems could be spread over a vast space, and they restrict resources, especially storage capacity. Therefore, a robust index and searching method can take time and resources, which may not be available on such devices.
2. Related Work
- A matching algorithm that can be efficiently deployed on hardware to achieve a high level of parallelism. Furthermore, the proposed algorithm can leverage the parallel architecture of HBM, which will be widely applied in a high-performance computing system.
- Text Search Processor (TSP) is the hardware implementation of the proposed parallel matching algorithm. The proposed approach ignores the indexing phase. It relies on the parallel matching algorithm to find multiple search results simultaneously. The complete system is deployed on Field Programmable Gate Arrays (FPGA) and achieves high performance. Upon receiving a command from the host computer, the TSP automatically fetches the reference text, matches the data, generates the results, and then writes back to the host memory. Depending on the readily available hardware, the number of processing cores might have their capacity significantly increased. Our experiments’ findings indicate that we could install 32 thousand processing cores on a Xilinx Alveo U50 while maintaining an operating frequency of over 180 megahertz (MHz).
- The TSP is designed to enable the usage of High Bandwidth Memory (HBM). To our knowledge, few (if not zero) researchers have integrated their FTS system with an effective data access control on HBM.
- A high-performance decoder design can translate thousands of matched positions, indicated by a bit, to matched addresses. The decoder helps reduce the number of results written back after searching, lessening the bottleneck of data exchange between the host computer and the text search system.
3. Background Knowledge
3.1. Text Search System
3.2. High Bandwidth Memory
- Text search is memory-bounded. It requires a significant amount of memory access to retrieve the referencing content. Consequently, a restricted amount of memory bandwidth outside the chip would increase access time, thus reducing overall performance. To overcome this problem, we propose a hardware design that utilizes many HBM channels for the best data transfer efficiency.
- Anticipated and concurrent memory retrieval: The memory retrieval process in text search follows a predictable pattern. Several chunks of reference text are used to compare with the input keyword. The matching step can be utilized for coarse-grained parallelism in a partition-based approach. We present a parallel matching technique and an HBM manager to enhance the parallelism of stacked architecture, thereby mitigating the memory bottleneck and optimizing search efficiency.
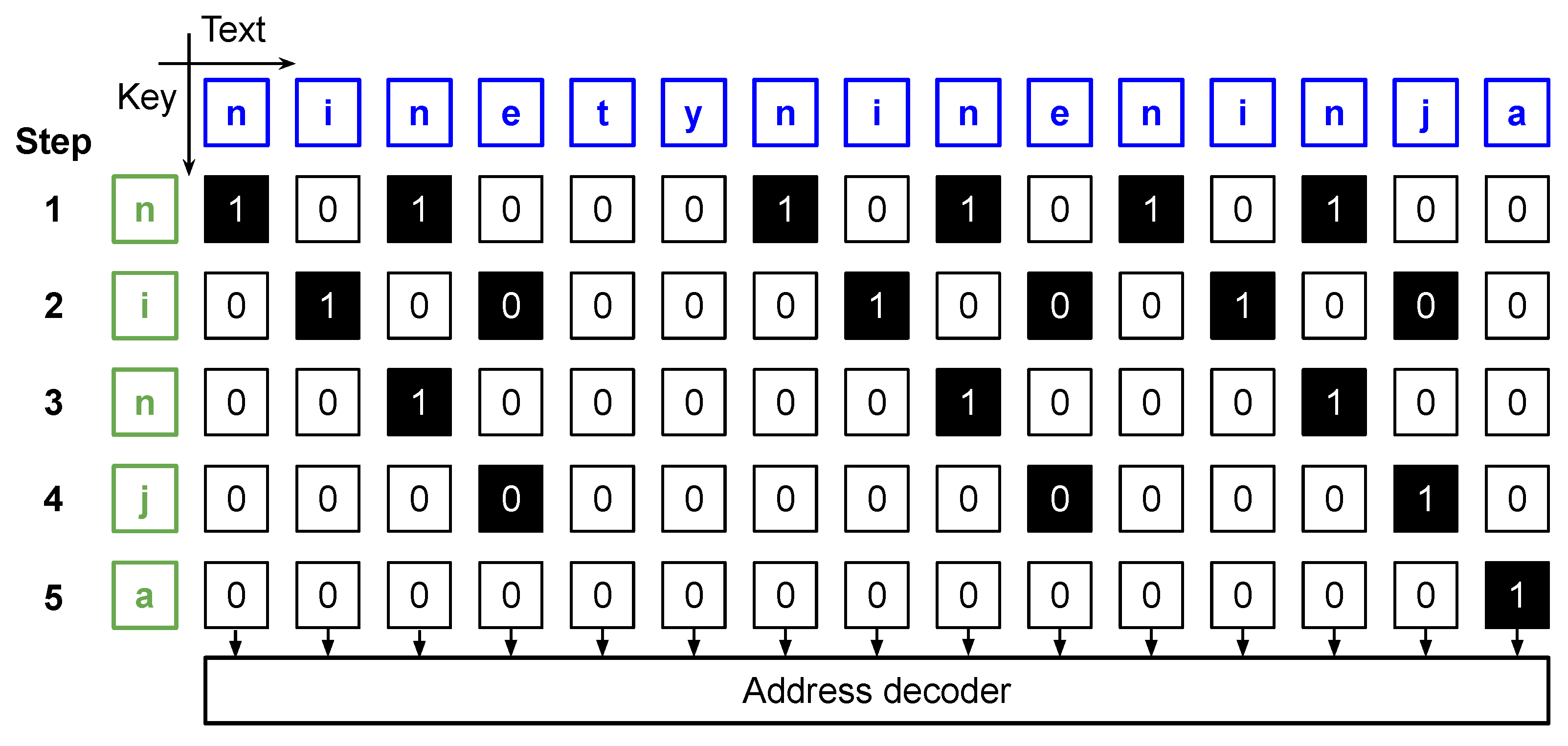
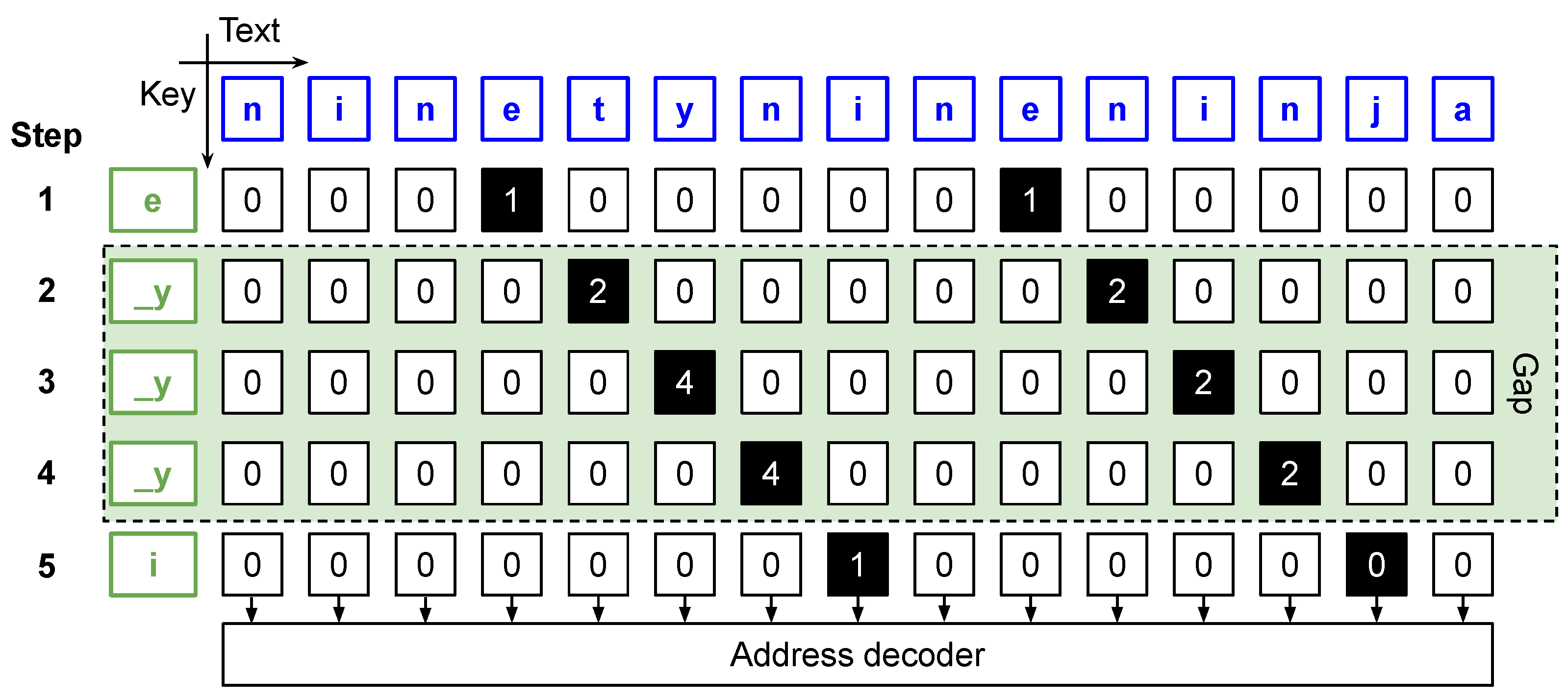
4. Parallel Matching Algorithm
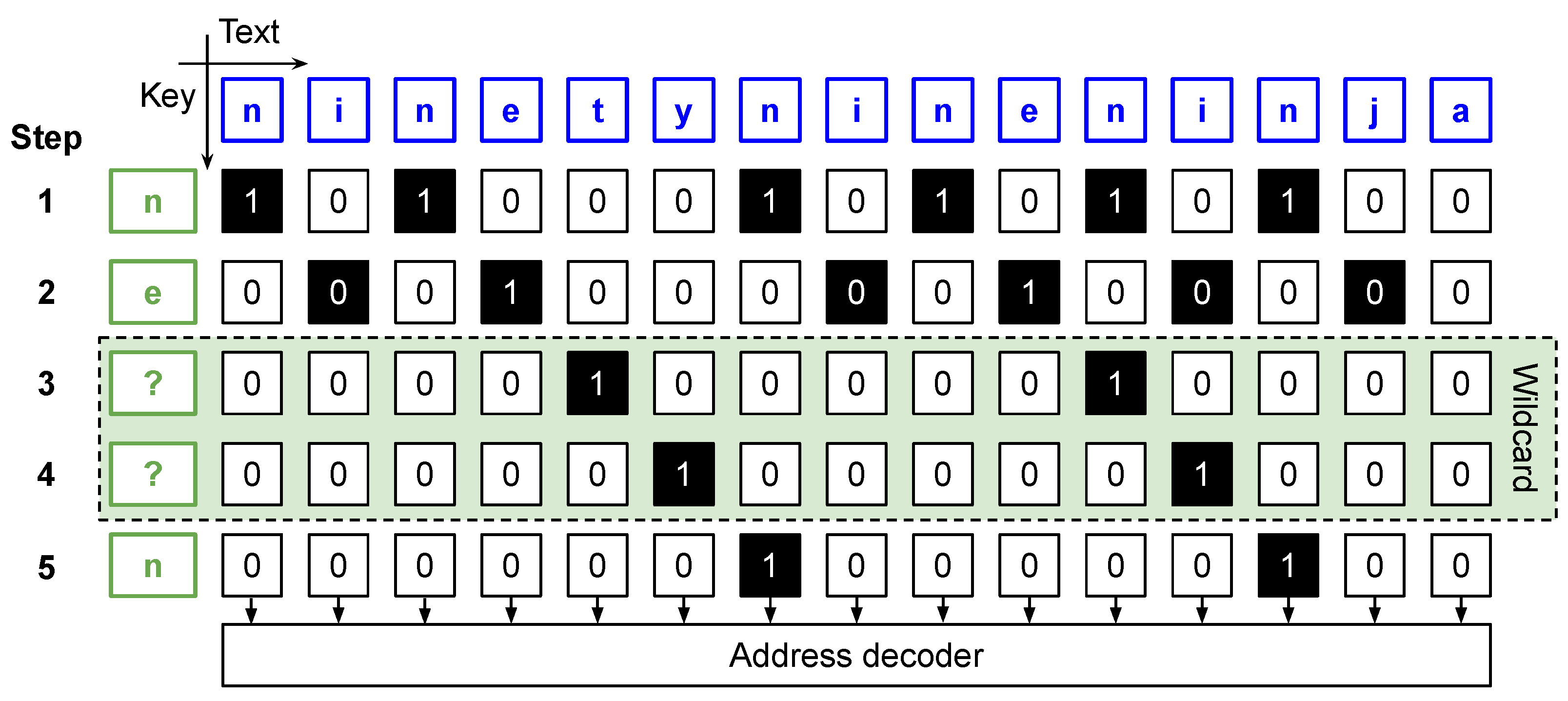
4.1. Parallel Matching Algorithm
| Algorithm 1 Parallel text search algorithm. |
String of keywords of length M, is the number of Processing Elements in the chain
|
4.2. Matching Status Evaluation
| Algorithm 2 Maching status evaluation (). |
|
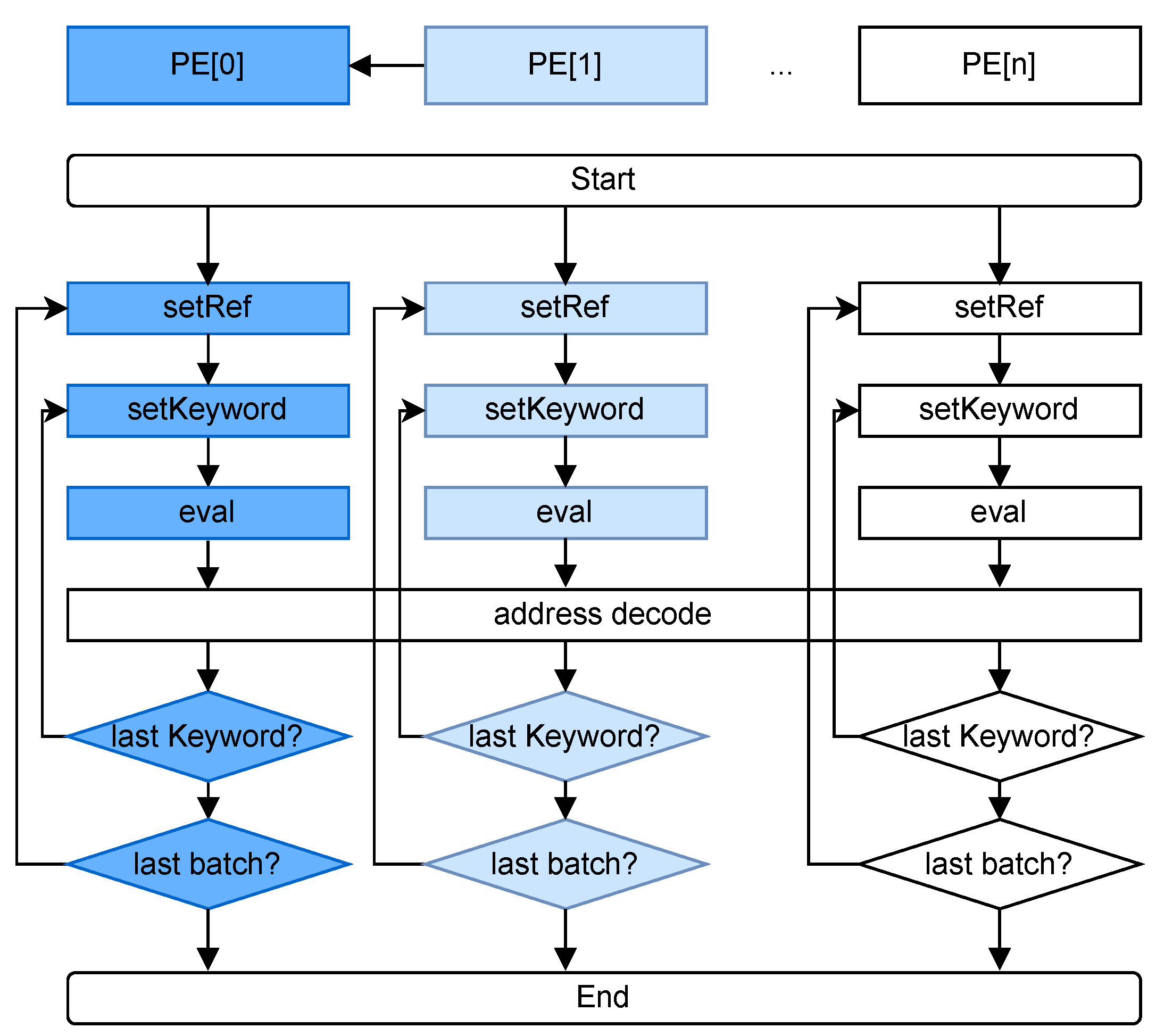
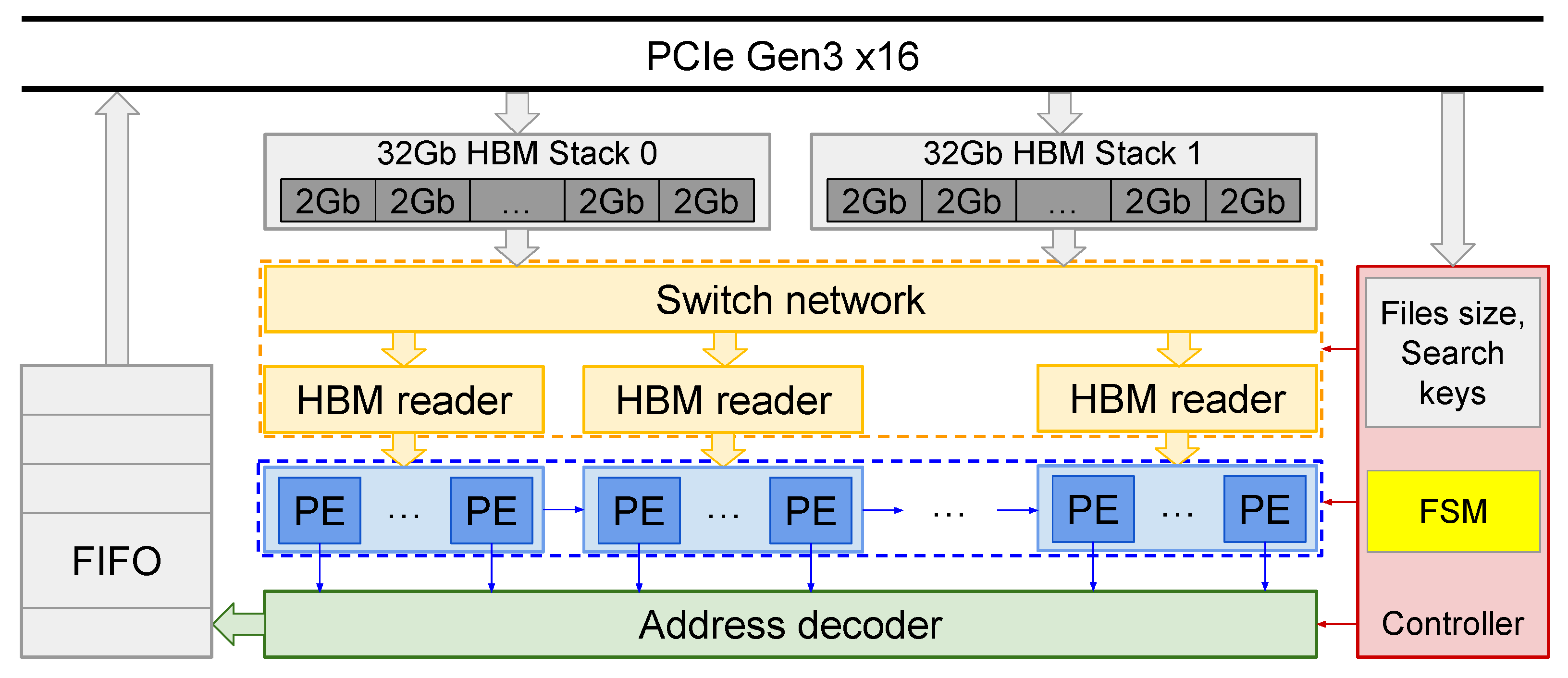
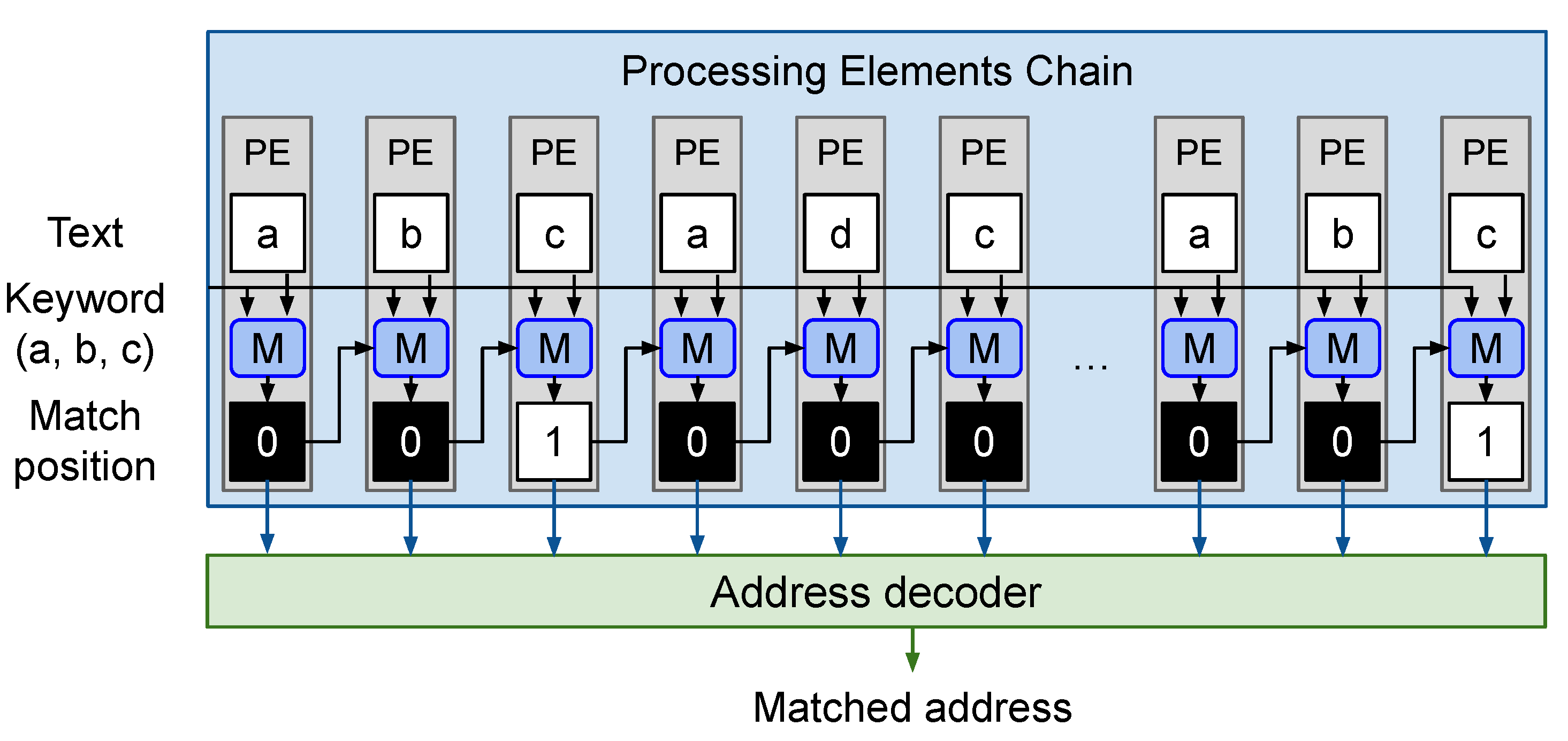
5. Hardware Architecture
5.1. Overall Architecture
5.2. Processing Element
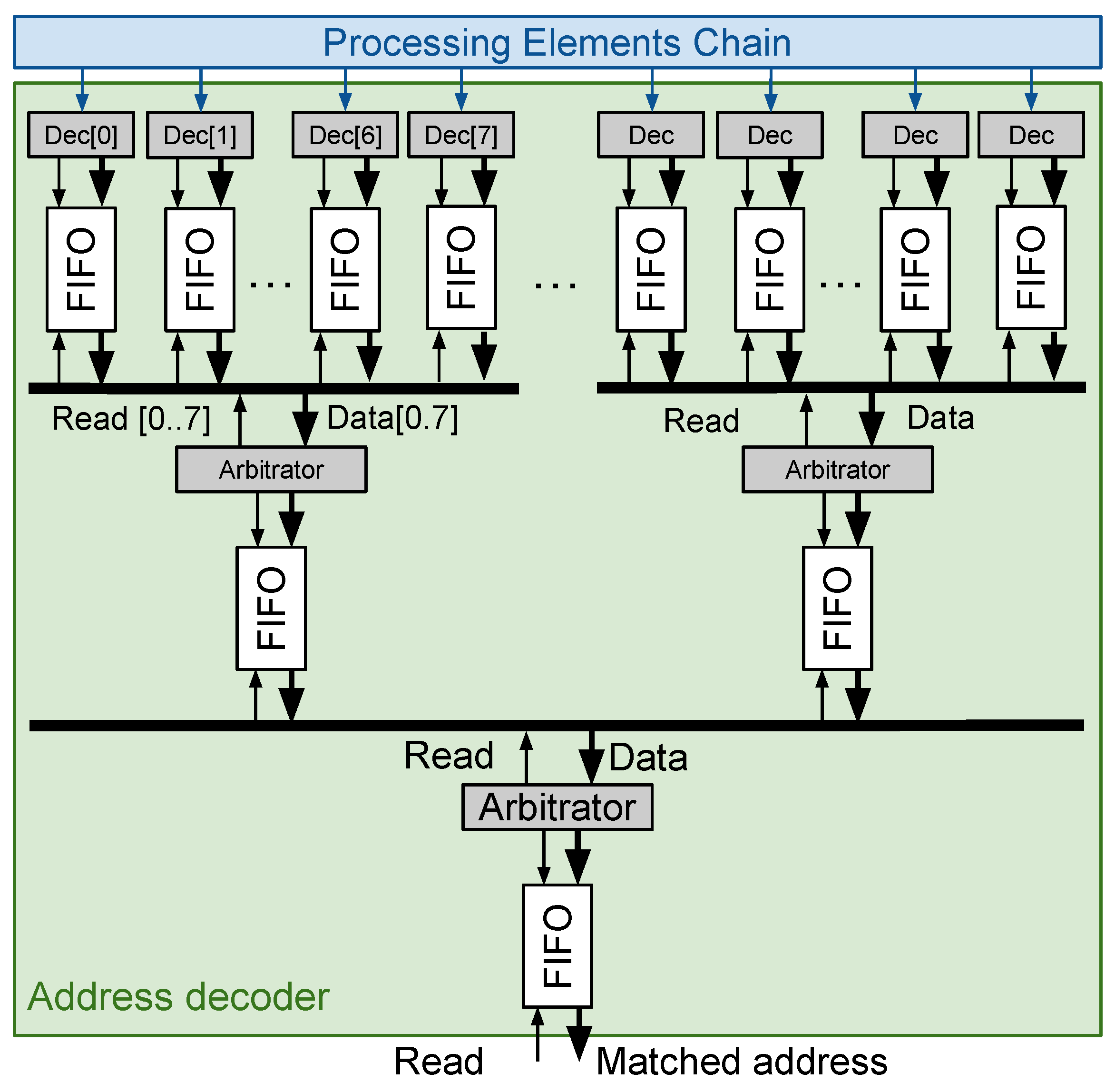
5.3. Address Decoder
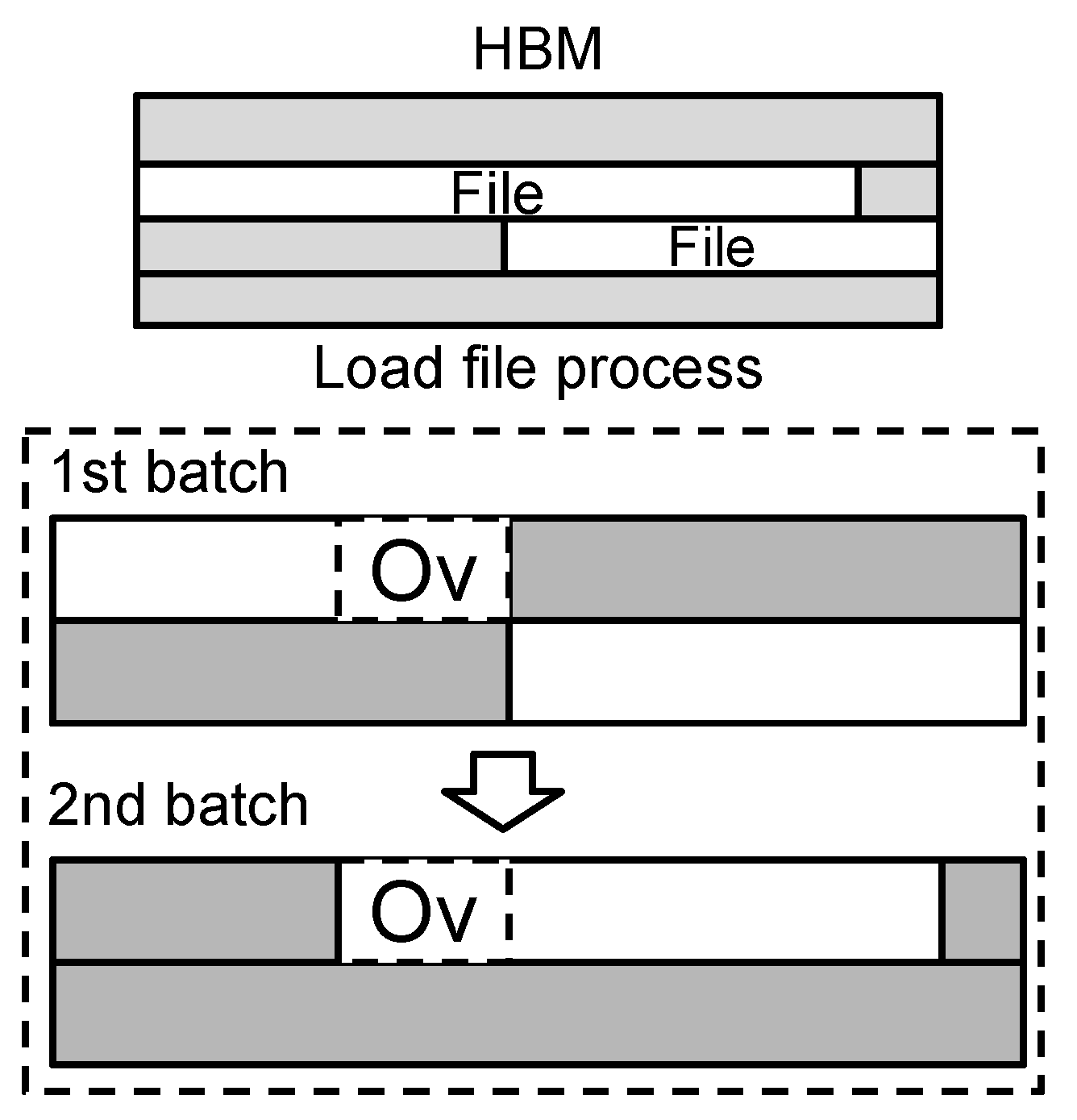
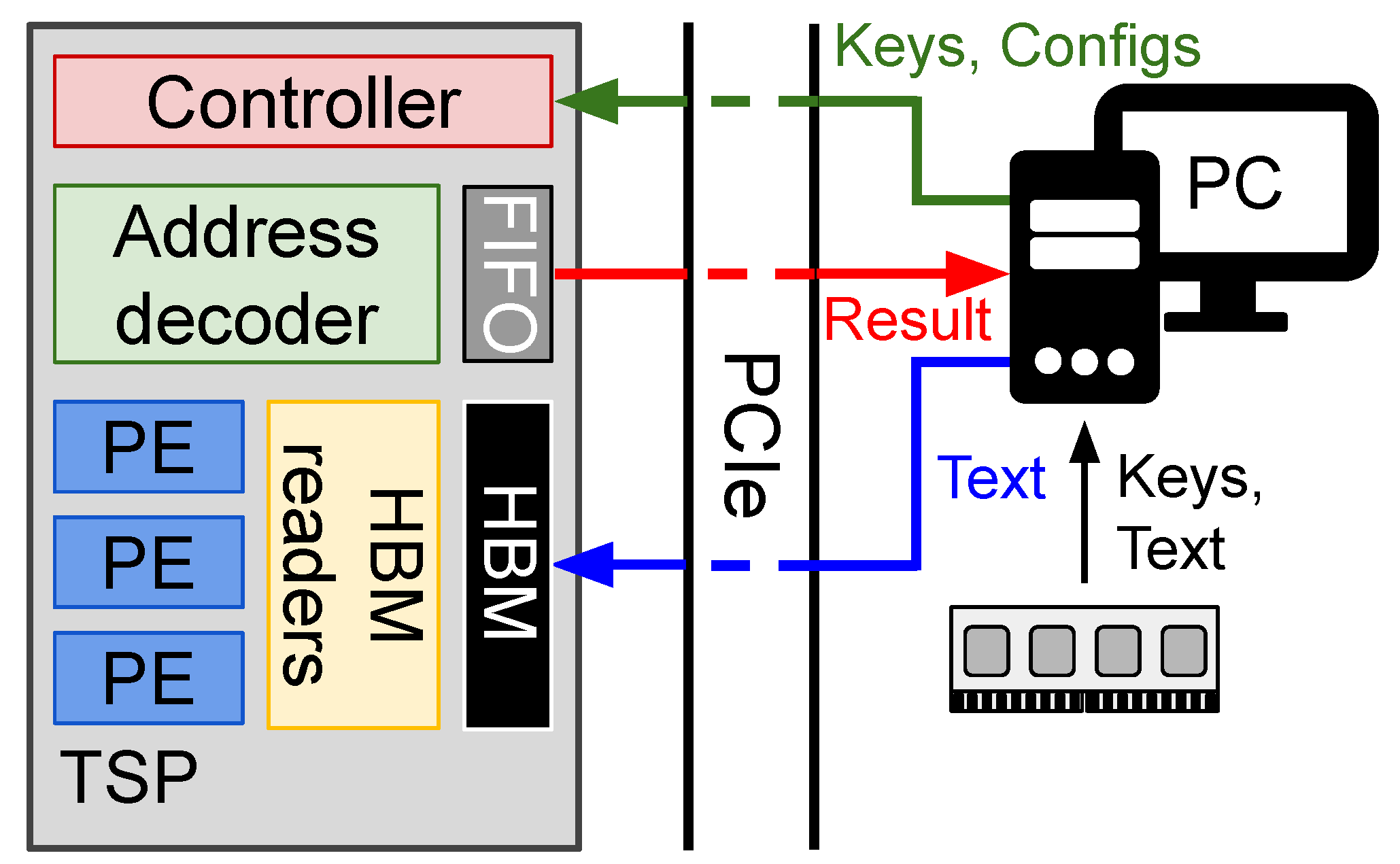
5.4. Data Management System
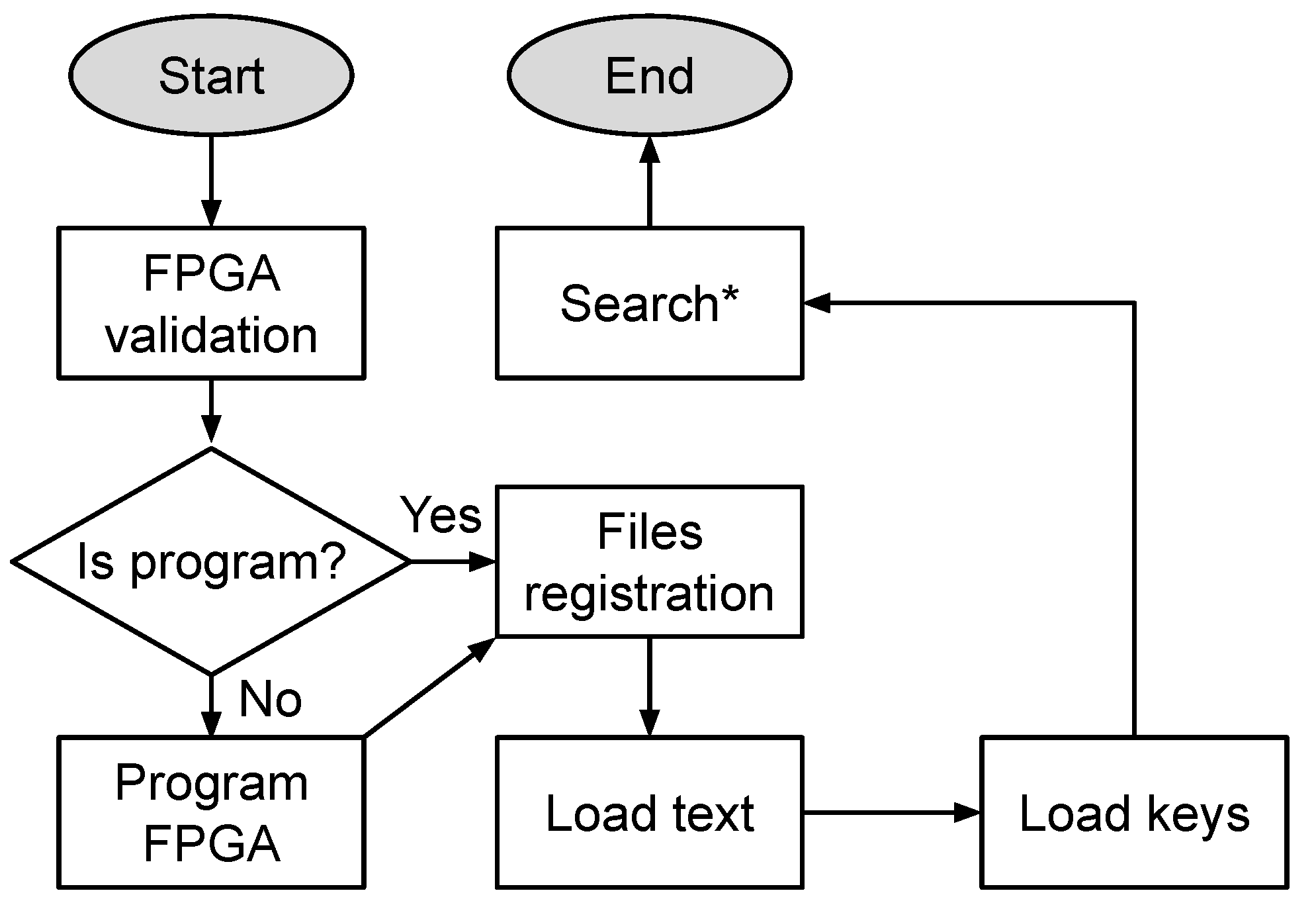
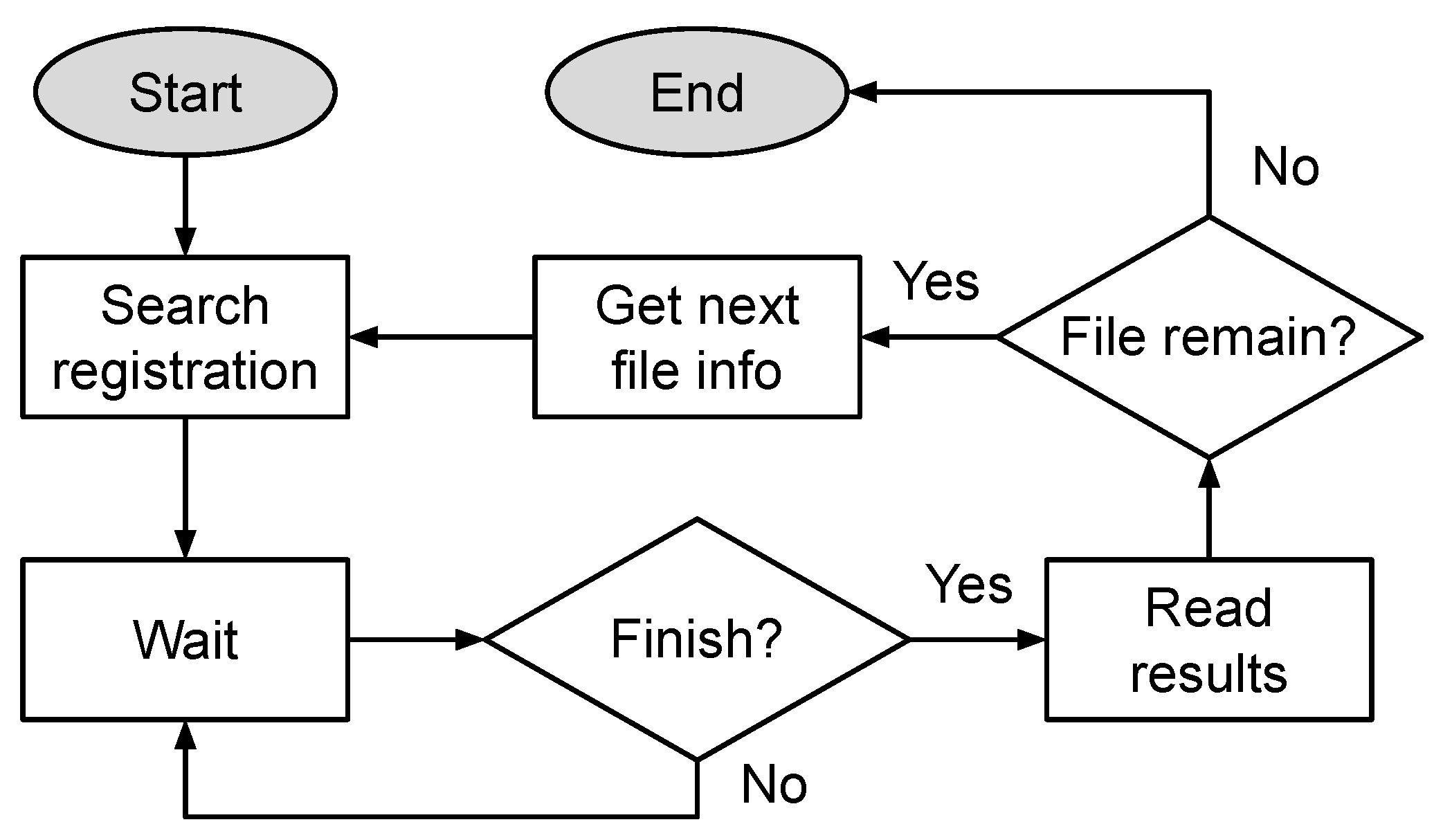
5.5. Hardware and Software Communication
6. Experimental Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Algorithm | Platform | Data Size (MiB) | Processing Time (ms) | Throughput (MiBps) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Index | Text | Index | Retrieval | Total | Retrieval | Total | ||||
| This work | Hardware | Parallel Search | Alveo U50 | 0 | 2252 | 0 | 250.69 | 250.69 | 8773 | 8773 |
| [30] | Succint index | Virtex-5 | 0.06 † | 0.08 | 33.1 † | 0.002 | 33.102 | 40,000 | 2.59 | |
| [44] | Inverted index | TSMC 40-nm | 23,206 ‡ | 398,336 | 41,070,000 ‡ | 7.25 | 41,070,007 | 54,942,896 | 9.69 | |
| [28] | Inverted index | TSMC 40-nm | 23,206 ‡ | 398,336 | 41,070,000 ‡ | 1.62 | 41,070,001 | 245,886,419 | 9.69 | |
| [19] | Software | Hyper Estraier | Intel T6600 | 45.4 | 42.7 | 31,518 | 987 | 32,505 | 43 | 1.31 |
| [47] | Lucene-based | NG * | NG * | 1.03 | 1214 | 1250 | 2464 | 0.82 | 0.42 | |
| [48] | Generalized Suffix tree | Intel i7 6700HQ | 73,440 | 60 | 3,465,000 | 0.005 | 3,465,000 | 12,000,000 | 0.02 | |
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Imura, J.; Tanaka, Y. A Full-Text Search System for Images of Hand-Written Cursive Documents. In Proceedings of the International Conference on Frontiers in Handwriting Recognition (ICFHR), Kolkata, India, 16–18 November 2010; pp. 640–645. [Google Scholar]
- Mu, C.M.; Zhao, J.R.; Yang, G.; Yang, B.; Yan, Z.J. Fast and Exact Nearest Neighbor Search in Hamming Space on Full-Text Search Engines. In Proceedings of the Similarity Search and Applications (SISAP), Newark, NJ, USA, 2–4 October 2019; pp. 49–56. [Google Scholar]
- Dinh, L.T.N.; Karmakar, G.; Kamruzzaman, J. A survey on context awareness in big data analytics for business applications. Knowl. Inf. Syst. 2020, 62, 3387–3415. [Google Scholar] [CrossRef]
- Abbasi, A.; Sarker, S.; Chiang, R. Big Data Research in Information Systems: Toward an Inclusive Research Agenda. J. Assoc. Inf. Syst. 2016, 17, 1–32. [Google Scholar] [CrossRef]
- Virginia, N. On the Impact of High Performance Computing in Big Data Analytics for Medicine. Appl. Med. Inform. 2020, 42, 9–18. [Google Scholar]
- Xie, J.; Qian, C.; Guo, D.; Wang, M.; Shi, S.; Chen, H. Efficient Indexing Mechanism for Unstructured Data Sharing Systems in Edge Computing. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 820–828. [Google Scholar]
- Wang, C.; Xie, M.; Bhowmick, S.S.; Choi, B.; Xiao, X.; Zhou, S. An Indexing Framework for Efficient Visual Exploratory Subgraph Search in Graph Databases. In Proceedings of the International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1666–1669. [Google Scholar]
- Kemouguette, I.; Kouahla, Z.; Benrazek, A.E.; Farou, B.; Seridi, H. Cost-Effective Space Partitioning Approach for IoT Data Indexing and Retrieval. In Proceedings of the International Conference on Networking and Advanced Systems (ICNAS), Annaba, Algeria, 27–28 October 2021; pp. 1–6. [Google Scholar]
- Qin, L.; Josephson, W.; Wang, Z.; Charikar, M.; Li, K. Multi-Probe LSH: Efficient Indexing for High-Dimensional Similarity Search. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 950–961. [Google Scholar]
- Dong, W.; Wang, Z.; Josephson, W.; Charikar, M.; Li, K. Modeling LSH for Performance Tuning. In Proceedings of the ACM Conference on Information and Knowledge Management (CIKM), Napa Valley, CA, USA, 26–30 October 2008; pp. 669–678. [Google Scholar]
- Maleknaz, N.; Guenther, R. Chapter 19—Analytical Product Release Planning. In The Art and Science of Analyzing Software Data; Bird, B.C., Tim, M., Thomas, Z., Eds.; Morga Kaufmann: Boston, MA, USA, 2015; pp. 555–589. [Google Scholar]
- Will, M.A.; Ko, R.K.L.; Witten, I.H. Bin Encoding: A User-Centric Secure Full-Text Searching Scheme for the Cloud. In Proceedings of the IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; pp. 563–570. [Google Scholar]
- Nazemi, K.; Klepsch, M.J.; Burkhardt, D.; Kaupp, L. Comparison of Full-text Articles and Abstracts for Visual Trend Analytics through Natural Language Processing. In Proceedings of the International Conference Information Visualisation (IV), Melbourne, Australia, 7–11 September 2020; pp. 360–367. [Google Scholar]
- Ismail, B.I.; Kandan, R.; Goortani, E.M.; Mydin, M.N.M.; Khalid, M.F.; Hoe, O.H. Reference Architecture for Search Infrastructure. In Proceedings of the International Conference on Control System, Computing and Engineering (ICCSCE), Penang, Malaysia, 24–26 November 2017; pp. 115–120. [Google Scholar]
- Apache Software Foundation. Apache Lucene—Scoring. 2011. Available online: http://lucene.apache.org/java/3_4_0/scoring.html (accessed on 27 May 2024).
- Hirabayashi, M. Hyper Estraier: A Full-Text Search System for Communities. 2007. Available online: https://dbmx.net/hyperestraier (accessed on 27 May 2024).
- Shi, X.; Wang, Z. An Optimized Full-Text Retrieval System Based on Lucene in Oracle Database. In Proceedings of the Enterprise Systems Conference (ES), Shanghai, China, 2–3 August 2014; pp. 61–65. [Google Scholar]
- Lakhara, S.; Mishra, N. Desktop Full-Text Searching Based on Lucene: A Review. In Proceedings of the International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), Chennai, India, 21–22 September 2017; pp. 2434–2438. [Google Scholar]
- Tian, T.W.; Zhou, Y.; Huang, G. Research and Implementation of a Desktop Full-Text Search System Based on Hyper Estraier. In Proceedings of the International Conference on Intelligent Computing and Integrated Systems (ICISS), Guilin, China, 22–24 October 2010; pp. 820–822. [Google Scholar]
- Veretennikov, A.B. Proximity Full-Text Search by Means of Additional Indexes with Multi-component Keys: In Pursuit of Optimal Performance. In Proceedings of the Data Analytics and Management in Data Intensive Domains (DAMDID/RCDL), Kazan, Russia, 15–18 October 2019; pp. 111–130. [Google Scholar]
- Veretennikov, A.B. Proximity Full-Text Search with a Response Time Guarantee by Means of Additional Indexes. In Proceedings of the Intelligent Systems and Applications (IntelliSys), London, UK, 6–7 September 2018; pp. 936–954. [Google Scholar]
- Chaitanya, B.S.S.K.; Reddy, D.A.K.; Chandra, B.P.S.E.; Krishna, A.B.; Menon, R.R.K. Full-Text Search Using Database Index. In Proceedings of the International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 19–21 September 2019; pp. 1–5. [Google Scholar]
- Xu, W.; Zhao, X.; Lao, B.; Nong, G. Enhancing HDFS with a Full-Text Search System for Massive Small Files. J. Supercomput. 2021, 77, 7149–7170. [Google Scholar] [CrossRef]
- Lakshman, A.; Malik, P. Cassandra: A Decentralized Structured Storage System. ACM SIGOPS Oper. Sys. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Yang, Y.; Ning, H. Block Linked List Index Structure for Large Data Full Text Retrieval. In Proceedings of the International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Guilin, China, 29–31 July 2017; pp. 2123–2128. [Google Scholar]
- Vishnoi, S.; Goel, V. Novel Table Based Air Indexing Technique for Full Text Search. In Proceedings of the International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 13–14 February 2015; pp. 410–415. [Google Scholar]
- Yu, J.X.; Su, A.Y.; Liu, W.Y.; Cheng, X.; Yang, J. Thematic Learning-based Full-text Retrieval Research on British and American Journalistic Reading. In Proceedings of the International Conference on Computer Science & Education (ICCSE), Toronto, ON, Canada, 19–21 August 2019; pp. 611–615. [Google Scholar]
- Heo, J.; Lee, S.Y.; Min, S.; Park, Y.; Jung, S.J.; Ham, T.J.; Lee, J.W. BOSS: Bandwidth-Optimized Search Accelerator for Storage-Class Memory. In Proceedings of the International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 279–291. [Google Scholar]
- Patel, S.; Hwu, W.M.W. Accelerator Architectures. IEEE Micro 2008, 28, 4–12. [Google Scholar] [CrossRef]
- Tanida, N.; Inaba, M.; Hiraki, K.; Yoshino, T. Hardware Accelerator for Full-Text Search (HAFTS) with Succinct Data Structure. In Proceedings of the International Conference on Reconfigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 9–11 December 2009; pp. 155–160. [Google Scholar]
- Liu, F.; He, X. Application of Full-Text Indexed Knowledge Graph in Chinese Address Matching for Hazardous Materials Transportation. In Proceedings of the International Conference on Electronic Information Engineering and Computer Science (EIECS), Changchun, China, 23–26 September 2021; pp. 510–515. [Google Scholar]
- Akram, S. Exploiting Intel Optane Persistent Memory for Full Text Search. In Proceedings of the ACM SIGPLAN International Symposium on Memory Management (ISMM), Virtual, 22 June 2021; pp. 80–93. [Google Scholar]
- Advanced Micro Devices (AMD), Inc. Alveo U50 Data Center Accelerator Card Data Sheet (DS965); Advanced Micro Devices (AMD), Inc.: Santa Clara, CA, USA, 2020. [Google Scholar]
- Shi, R.; Kara, K.; Hagleitner, C.; Diamantopoulos, D.; Syrivelis, D.; Alonso, G. Exploiting HBM on FPGAs for Data Processing. ACM Trans. Reconfigurable Technol. Syst. 2022, 15, 1–27. [Google Scholar] [CrossRef]
- Lee, D.U.; Lee, K.S.; Lee, Y.; Kim, K.W.; Kang, J.H.; Lee, J.; Chun, J.H. Design Considerations of HBM Stacked DRAM and the Memory Architecture Extension. In Proceedings of the Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 28–30 September 2015; pp. 1–8. [Google Scholar]
- Jayaraman, S.; Zhang, B.; Prasannar, V. Hypersort: High-performance Parallel Sorting on HBM-enabled FPGA. In Proceedings of the International Conference on Field-Programmable Technology (ICFPT), Hong Kong, China, 5–9 December 2022; pp. 1–11. [Google Scholar]
- Fang, J.; Mulder, Y.T.B.; Hidders, J.; Lee, J.; Hofstee, H.P. In-memory Database Acceleration on FPGAs: A Survey. VLDB J. 2020, 29, 33–59. [Google Scholar] [CrossRef]
- Cheng, X.; He, B.; Lo, E.; Wang, W.; Lu, S.; Chen, X. Deploying Hash Tables on Die-Stacked High Bandwidth Memory. In Proceedings of the International Conference on Information and Knowledge Management (CIKM), Beijing, China, 3–7 November 2019; pp. 239–248. [Google Scholar]
- Chen, X.; Chen, Y.; Cheng, F.; Tan, H.; He, B.; Wong, W.F. ReGraph: Scaling Graph Processing on HBM-enabled FPGAs with Heterogeneous Pipelines. In Proceedings of the International Symposium on Microarchitecture (MICRO), Chicago, IL, USA, 1–5 October 2022; pp. 1342–1358. [Google Scholar]
- Miao, H.; Jeon, M.; Pekhimenko, G.; McKinley, K.S.; Lin, F.X. StreamBox-HBM: Stream Analytics on High Bandwidth Hybrid Memory. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems Providence (ASPLOS), Providence, RI, USA, 13–17 April 2019; pp. 167–181. [Google Scholar]
- Aozora Bunko. Available online: https://www.aozora.gr.jp (accessed on 27 May 2024).
- Web scapping. Available online: https://github.com/trungngv/web_scraping (accessed on 27 May 2024).
- Project Gutenberg. Available online: https://www.gutenberg.org (accessed on 27 May 2024).
- Heo, J.; Won, J.; Lee, Y.; Bharuka, S.; Jang, J.; Ham, T.J.; Lee, J.W. IIU: Specialized Architecture for Inverted Index Search. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Lausanne, Switzerland, 16–20 March 2020; pp. 1233–1245. [Google Scholar]
- Gog, S.; Beller, T.; Moffat, A.; Petri, M. From Theory to Practice: Plug and Play with Succinct Data Structures. In Proceedings of the International Symposium on Experimental Algorithms (SEA 2014), Copenhagen, Denmark, 29 June–1 July 2014; pp. 326–337. [Google Scholar]
- Mallia, M.A.; Michal, S.; Joel, M.; Torsten, S. PISA: Performant Indexes and Search for Academia. In Proceedings of the Open-Source IR Replicability Challenge (OSIRRC), Paris, France, 25 July 2019; pp. 50–56. [Google Scholar]
- Lakhara, S.; Mishra, N. Design and Implementation of Desktop Full-Text Searching System. In Proceedings of the International Conference on. Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 480–485. [Google Scholar]
- Zaky, A.; Munir, R. Full-Text Search on Data with Access Control Using Generalized Suffix Tree. In Proceedings of the International Conference on Data and Software Engineering (ICoDSE), Denpasar, Indonesia, 26–27 October 2016; pp. 1–6. [Google Scholar]

| Match Status | Definition |
|---|---|
| 0 | Not matched |
| 1 | Matched |
| 2 | Not matched with gap |
| 3 | Temporary matched with gap |
| 4 | Matched with gap |
| TSP Configuration | |
| Platform | Xilinx Alveo U50 |
| Language support | Any |
| Search mode | Regular, mask, gap |
| #Processing Elements | 32,768 |
| Resource Usage | |
| #Slices | 100,401 (92.16%) |
| #LUTs | 483,080 (54.69%) |
| #Registers | 692,922 (39.73%) |
| Frequency | 180-MHz |
| Language | File Count | Size (MiB) | Dataset Source |
|---|---|---|---|
| Japanese | 34,508 | 1434 | Aozora Bunko [41] |
| Vietnamese | 28,334 | 113 | VNExpress [42] |
| English | 1205 | 611 | Project Gutenberg [43] |
| Chinese | 231 | 96 | Project Gutenberg [43] |
| Test No | Input Keyword | Keyword Size (Byte) | Match Count | Init Time (ms) | Match Time (ms) | Decode Time (ms) | Writeback Time (ms) | Total Time (ms) |
|---|---|---|---|---|---|---|---|---|
| Scenario 1: English | ||||||||
| 1 | gold | 4 | 23,346 | 186.5 | 7.61 | 55.98 | 0.00013 | 250.09 |
| 2 | Unfeeling | 9 | 12 | 186.5 | 9.61 | 54.89 | 0.00001 | 251.00 |
| 3 | statement | 9 | 8906 | 186.5 | 9.61 | 54.91 | 0.00005 | 251.02 |
| 4 * | Combine | 22 | 32,264 | 308.76 | 26.82 | 165.79 | 0.00019 | 501.37 |
| Scenario 2: Vietnamese | ||||||||
| 6 | ngô | 4 | 9301 | 186.5 | 7.61 | 56.51 | 0.00005 | 250.62 |
| 7 | lân | 4 | 526 | 186.5 | 7.61 | 56.21 | 0.00001 | 250.32 |
| 8 | duyên | 5 | 828 | 186.5 | 8.00 | 55.80 | 0.00001 | 250.51 |
| 9 * | Combine | 14 | 10,655 | 308.56 | 23.22 | 168.53 | 0.00007 | 500.31 |
| Scenario 3: Japanese | ||||||||
| 10 | 野口 | 6 | 854 | 186.5 | 8.41 | 55.41 | 0.00001 | 250.32 |
| 11 | 英司 | 6 | 109 | 186.5 | 8.41 | 55.80 | 0.00001 | 250.71 |
| 12 | 八巻美恵 | 12 | 66 | 186.5 | 10.81 | 53.88 | 0.00001 | 251.19 |
| 13 * | Combine | 24 | 1029 | 307.89 | 27.62 | 165.09 | 0.00003 | 500.61 |
| Scenario 4: Chinese | ||||||||
| 14 | 翩翩舉 | 6 | 3 | 186.5 | 8.41 | 56.17 | 0.00001 | 251.08 |
| 15 | 復行 | 6 | 135 | 186.5 | 8.41 | 55.46 | 0.00001 | 250.37 |
| 16 | 數十 | 12 | 1590 | 186.5 | 10.41 | 53.68 | 0.00001 | 250.99 |
| 17 * | Combine | 24 | 1728 | 307.42 | 27.62 | 165.32 | 0.00003 | 500.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kieu-Do-Nguyen, B.; Dang, T.-K.; The Binh, N.; Pham-Quoc, C.; Phuc Nghi, H.; Tran, N.-T.; Inoue, K.; Pham, C.-K.; Hoang, T.-T. A High-Performance Non-Indexed Text Search System. Electronics 2024, 13, 2125. https://doi.org/10.3390/electronics13112125
Kieu-Do-Nguyen B, Dang T-K, The Binh N, Pham-Quoc C, Phuc Nghi H, Tran N-T, Inoue K, Pham C-K, Hoang T-T. A High-Performance Non-Indexed Text Search System. Electronics. 2024; 13(11):2125. https://doi.org/10.3390/electronics13112125
Chicago/Turabian StyleKieu-Do-Nguyen, Binh, Tuan-Kiet Dang, Nguyen The Binh, Cuong Pham-Quoc, Huynh Phuc Nghi, Ngoc-Thinh Tran, Katsumi Inoue, Cong-Kha Pham, and Trong-Thuc Hoang. 2024. "A High-Performance Non-Indexed Text Search System" Electronics 13, no. 11: 2125. https://doi.org/10.3390/electronics13112125