



An Advanced Approach to Object Detection and Tracking in Robotics and Autonomous Vehicles Using YOLOv8 and LiDAR Data Fusion


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
3. Multiple Object Detection and Tracking
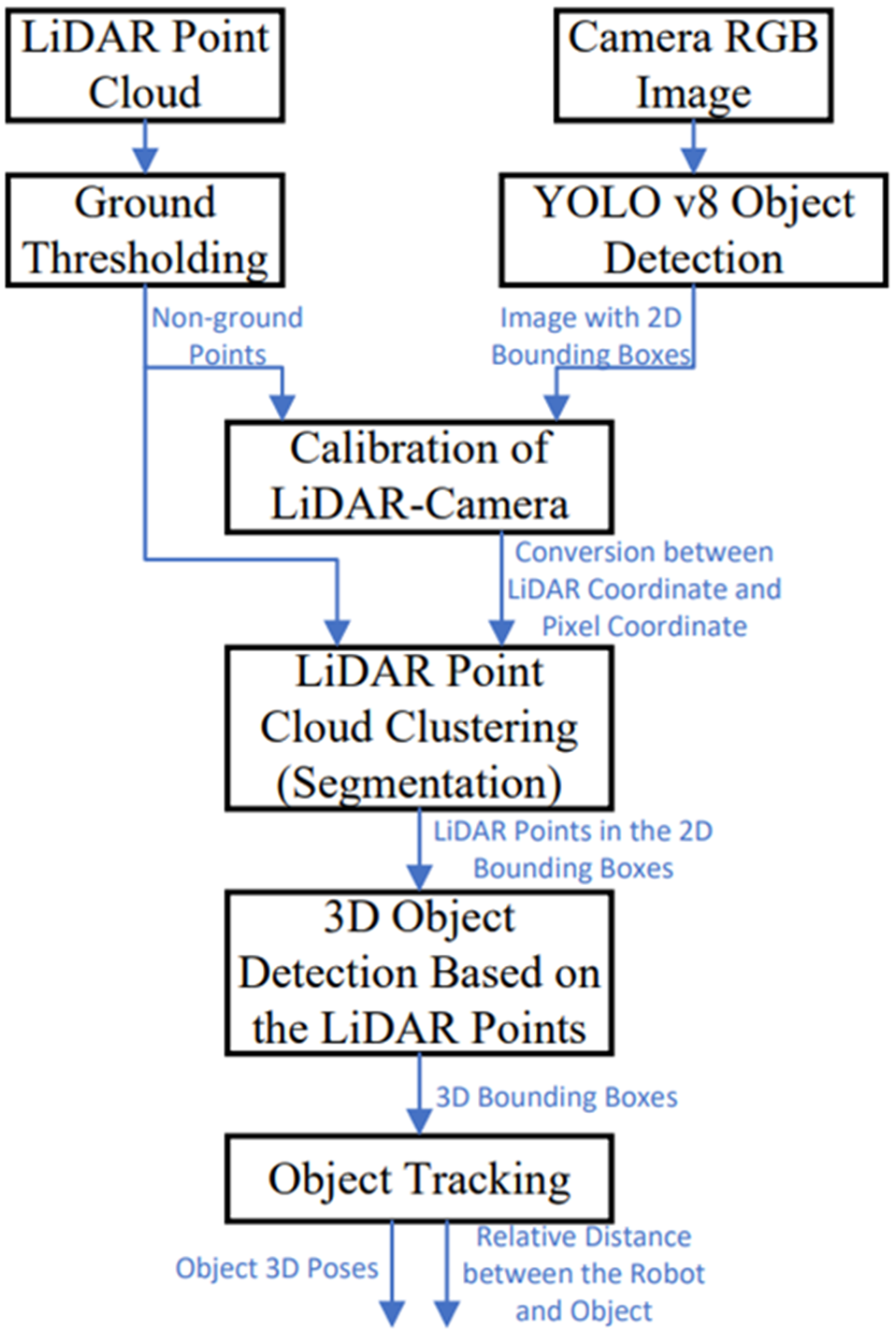
3.1. System Overview
3.2. LiDAR Data Ground Segmentation
3.3. 3D LiDAR and Camera Data Fusion
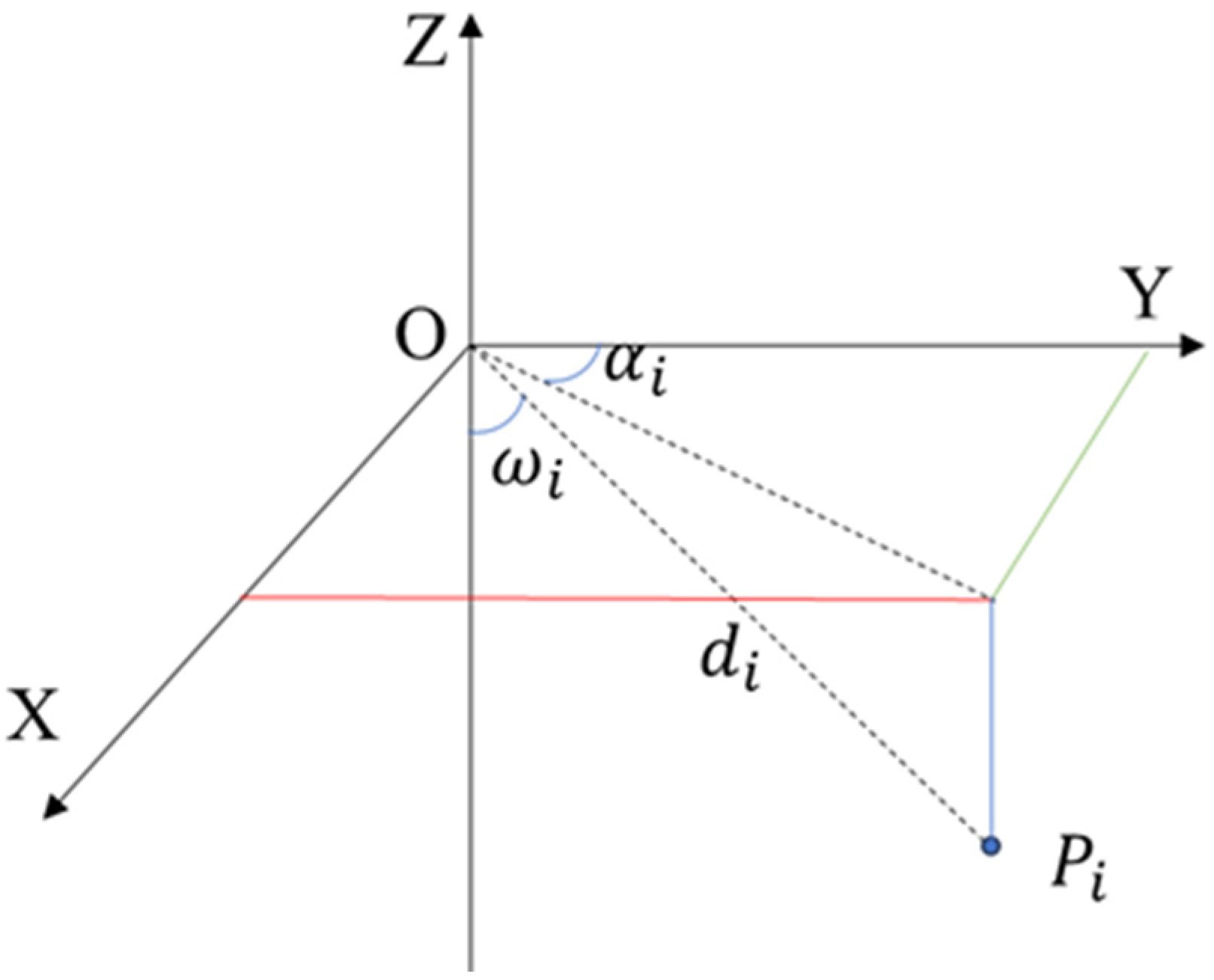
3.4. Object Detection and Tracking
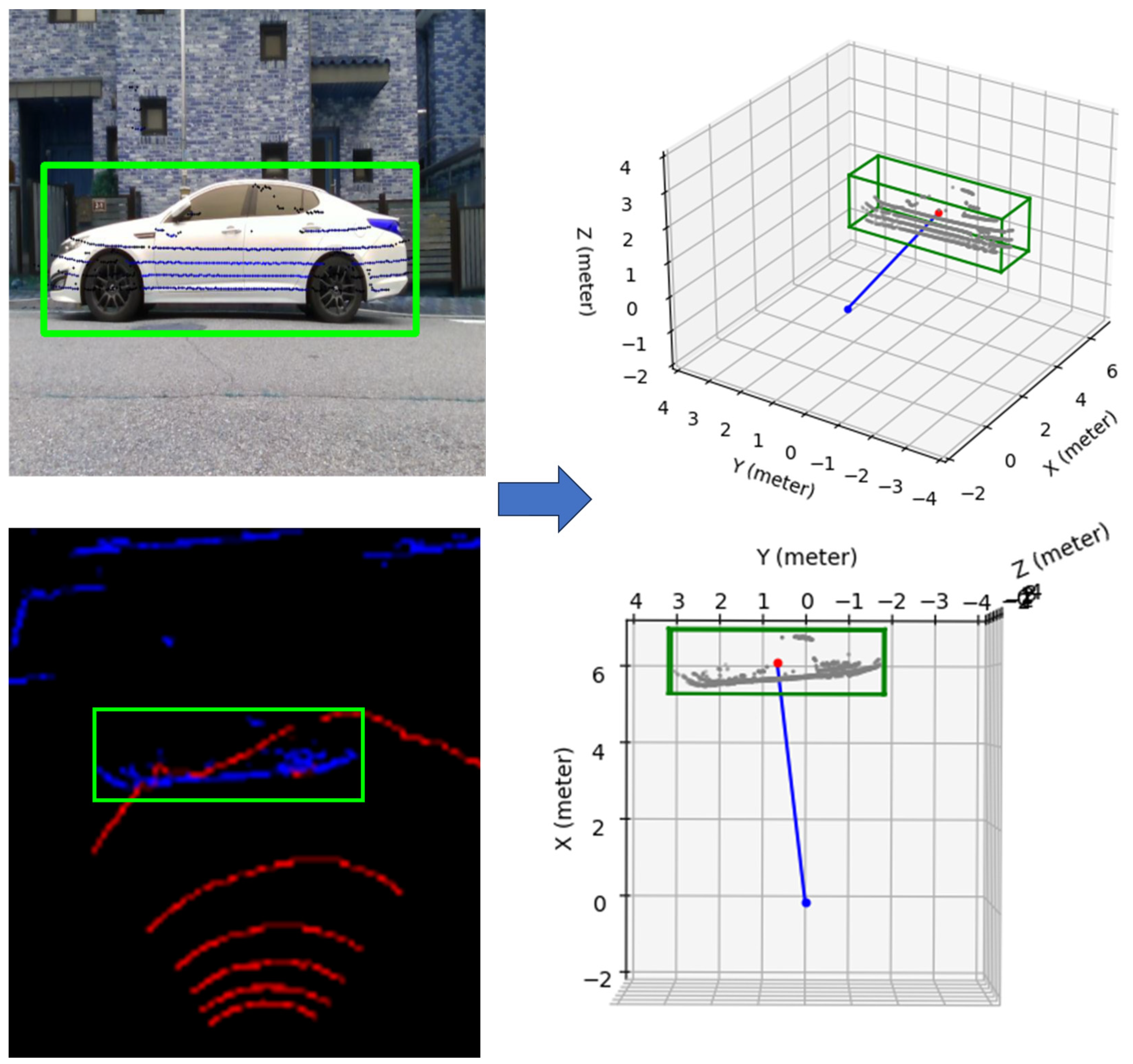
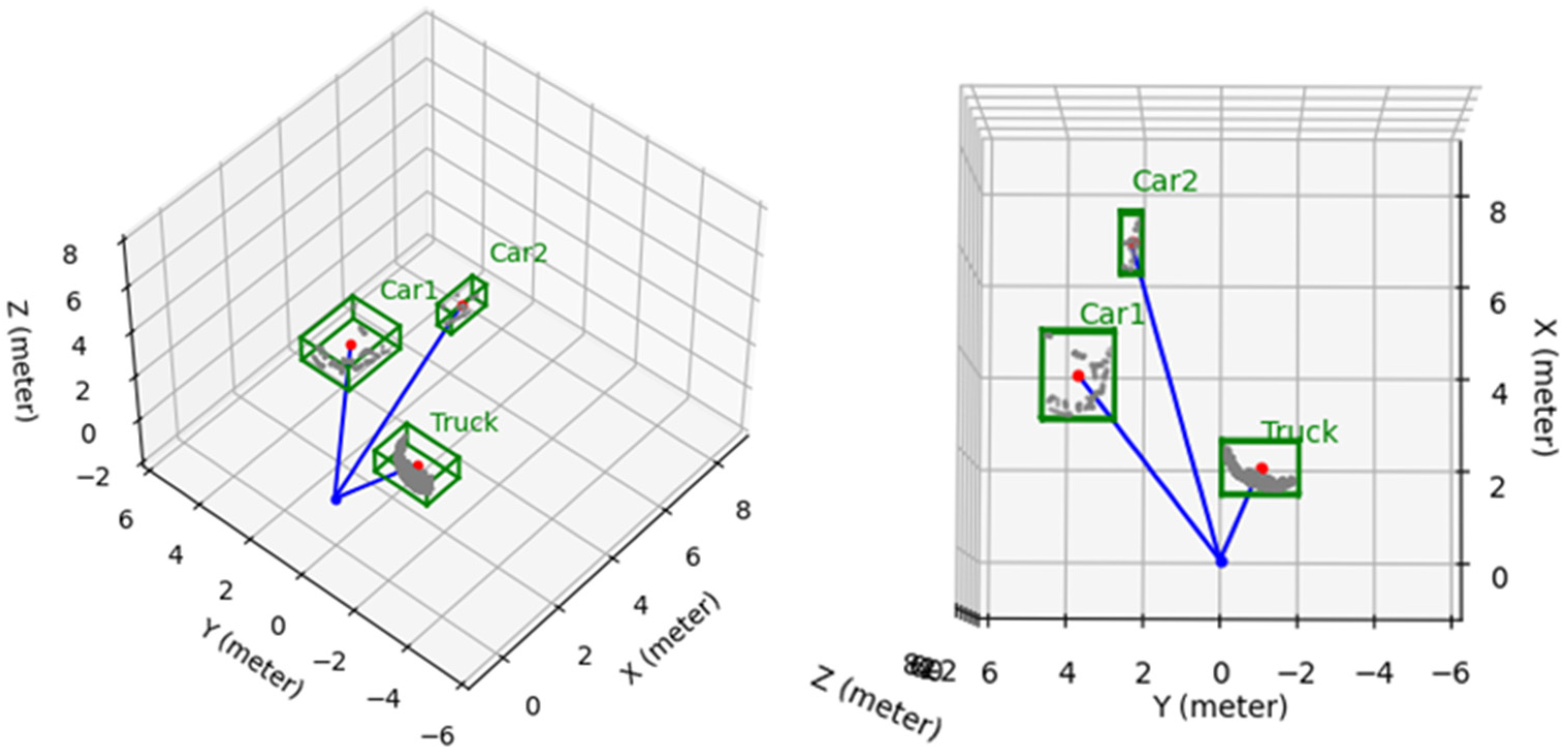
4. Simulations and Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LiDAR | Light Detection and Ranging |
| YOLO | You Only Look Once |
| SSD | Single Shot MultiBox Detector |
| FOV | Field of View |
| 2D | Two dimensional |
| 3D | Three dimensional |
References
- Mehdi, S.M.; Naqvi, R.A.; Mehdi, S.Z. Autonomous object detection and tracking robot using Kinect v2. In Proceedings of the 2021 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 9–10 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, M.-F.R.; Chen, Y.-C. Artificial Intelligence Based Object Detection and Tracking for a Small Underwater Robot. Processes 2023, 11, 312. [Google Scholar] [CrossRef]
- Xu, Z.; Zhan, X.; Xiu, Y.; Suzuki, C.; Sh, K. Onboard Dynamic-object Detection and Tracking for Autonomous Robot Navigation with RGB-D Camera. IEEE Robot. Autom. Lett. 2024, 9, 651–658. [Google Scholar] [CrossRef]
- Gragnaniello, D.; Greco, A.; Saggese, A.; Vento, M.; Vicinanza, A. Benchmarking 2D Multi-Object Detection and Tracking Algorithms in Autonomous Vehicle Driving Scenarios. Sensors 2023, 23, 4024. [Google Scholar] [CrossRef]
- Mendhe, A.; Chaudhari, H.B.; Diwan, A.; Rathod, S.M.; Sharma, A. Object Detection and Tracking for Autonomous Vehicle using AI in CARLA. In Proceedings of the 2022 International Conference on Industry 4.0 Technology (I4Tech), Pune, India, 23–24 September 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Xie, D.; Xu, Y.; Wang, R. Obstacle detection and tracking method for autonomous vehicle based on three-dimensional LiDAR. Int. J. Adv. Robot. Syst. 2019, 16, 172988141983158. [Google Scholar] [CrossRef]
- Nguyen, P.A.; Tran, S.T. Tracking customers in crowded retail scenes with Siamese Tracker. In Proceedings of the 2020 RIVF International Conference on Computing and Communication Technologies (RIVF), Ho Chi Minh City, Vietnam, 14–15 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Lee, J.; Moon, S.; Nam, D.-W.; Lee, J.; Oh, A.R.; Yoo, W. A Study on Sports Player Tracking based on Video using Deep Learning. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Republic of Korea, 21–23 October 2020; pp. 1161–1163. [Google Scholar] [CrossRef]
- Ouardirhi, Z.; Mahmoudi, S.A.; Zbakh, M. Enhancing Object Detection in Smart Video Surveillance: A Survey of Occlusion-Handling Approaches. Electronics 2024, 13, 541. [Google Scholar] [CrossRef]
- Azevedo, P.; Santos, V. YOLO-Based Object Detection and Tracking for Autonomous Vehicles Using Edge Devices. In ROBOT2022: Fifth Iberian Robotics Conference; Springer: Berlin/Heidelberg, Germany, 2022; pp. 297–308. [Google Scholar] [CrossRef]
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep learning for object detection and scene perception in self-driving cars: Survey, challenges and issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Moksyakov, A.; Wu, Y.; Gadsden, S.A.; Yawney, J.; AlShabi, M. Object Detection and Tracking with YOLO and the Sliding Innovation Filter. Sensors 2024, 24, 2107. [Google Scholar] [CrossRef]
- Balamurali, M.; Mihankhah, E. SimMining-3D: Altitude-Aware 3D Object Detection in Complex Mining Environments: A Novel Dataset and ROS-Based Automatic Annotation Pipeline. arXiv 2023, arXiv:2312.06113. [Google Scholar] [CrossRef]
- Dippal, I.; Hiren, M. Identity Retention of Multiple Objects under Extreme Occlusion Scenarios using Feature Descriptors. J. Commun. Softw. Syst. 2018, 14, 290–301. [Google Scholar] [CrossRef]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Kim, T.-K. Multiple object tracking: A literature review. Artif. Intell. 2021, 293, 103448. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Y.; Liao, Y.; Wu, F.; Ye, H.; Li, S. Tracking Transforming Objects: A Benchmark. arXiv 2024, arXiv:2404.18143v1. [Google Scholar]
- Gomes, T.; Matias, D.; Campos, A.; Cunha, L.; Roriz, R. A Survey on Ground Segmentation Methods for Automotive LiDAR Sensors. Sensors 2023, 23, 601. [Google Scholar] [CrossRef]
- Deng, W.; Chen, X.; Jiang, J. A Staged Real-Time Ground Segmentation Algorithm of 3D LiDAR Point Cloud. Electronics 2024, 13, 841. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016. ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9905. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Bharat Mahaur, B.; Mishra, K.K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Li, K.; Wang, Y.; Hu, Z. Improved YOLOv7 for Small Object Detection Algorithm Based on Attention and Dynamic Convolution. Appl. Sci. 2023, 13, 9316. [Google Scholar] [CrossRef]
- Huang, H.; Wang, B.; Xiao, J.; Zhu, T. Improved small-object detection using YOLOv8: A comparative study. Appl. Comput. Eng. 2024, 41, 80–88. [Google Scholar] [CrossRef]
- Lee, J.; Su, Y. Balancing Privacy and Accuracy: Exploring the Impact of Data Anonymization on Deep Learning Models in Computer Vision. IEEE Access 2024, 12, 8346–8358. [Google Scholar] [CrossRef]
- Liu, Y.; Jiang, X.; Cao, W.; Sun, J.; Gao, F. Detection of Thrombin Based on Fluorescence Energy Transfer Between Semiconducting Polymer Dots and BHQ-Labelled Aptamers. Sensors 2018, 18, 589. [Google Scholar] [CrossRef]
- Noguera, J.M.; Jiménez, J.R. Mobile Volume Rendering: Past, Present and Future. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1164–1178. [Google Scholar] [CrossRef]
- Kwak, K.; Huber, D.F.; Badino, H.; Kanade, T. Extrinsic Calibration of a Single Line Scanning Lidar and a Camera. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011; pp. 3283–3289. [Google Scholar]
- Gunjal, P.R.; Gunjal, B.R.; Shinde, H.A.; Vanam, S.M.; Aher, S.S. Moving Object Tracking Using Kalman Filter. In Proceedings of the 2018 International Conference on Advances in Communication and Computing Technology (ICACCT), Sangamner, India, 8–9 February 2018; pp. 544–547. [Google Scholar] [CrossRef]
- Feng, Z. High Speed Moving Target Tracking Algorithm based on Mean Shift for Video Human Motion. J. Phys. Conf. Ser. 2021, 1744, 042180. [Google Scholar] [CrossRef]
- Liu, H.; Wu, C.; Wang, H. Real time object detection using LiDAR and camera fusion for autonomous driving. Sci. Rep. 2023, 13, 8056. [Google Scholar] [CrossRef]
- Kim, T.-L.; Park, T.-H. Camera-LiDAR Fusion Method with Feature Switch Layer for Object Detection Networks. Sensors 2022, 22, 7163. [Google Scholar] [CrossRef]
- Shen, Z.; Liang, H.; Lin, L.; Wang, Z.; Huang, W.; Yu, J. Fast Ground Segmentation for 3D LiDAR Point Cloud Based on Jump-Convolution-Process. Remote Sens. 2021, 13, 3239. [Google Scholar] [CrossRef]
- Paigwar, A.; Erkent, Ö.; González, D.S.; Laugier, C. GndNet: Fast Ground Plane Estimation and Point Cloud Segmentation for Autonomous Vehicles. In Proceedings of the IROS 2020-IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 2150–2156. [Google Scholar] [CrossRef]
- Dai, Y.; Lee, K. 3D map building based on extrinsic sensor calibration method and object contour detector with a fully convolutional neural network. Meas. Control. 2023, 56, 215–227. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y.; Kim, D.; Lee, K. An Advanced Approach to Object Detection and Tracking in Robotics and Autonomous Vehicles Using YOLOv8 and LiDAR Data Fusion. Electronics 2024, 13, 2250. https://doi.org/10.3390/electronics13122250
Dai Y, Kim D, Lee K. An Advanced Approach to Object Detection and Tracking in Robotics and Autonomous Vehicles Using YOLOv8 and LiDAR Data Fusion. Electronics. 2024; 13(12):2250. https://doi.org/10.3390/electronics13122250
Chicago/Turabian StyleDai, Yanyan, Deokgyu Kim, and Kidong Lee. 2024. "An Advanced Approach to Object Detection and Tracking in Robotics and Autonomous Vehicles Using YOLOv8 and LiDAR Data Fusion" Electronics 13, no. 12: 2250. https://doi.org/10.3390/electronics13122250
APA StyleDai, Y., Kim, D., & Lee, K. (2024). An Advanced Approach to Object Detection and Tracking in Robotics and Autonomous Vehicles Using YOLOv8 and LiDAR Data Fusion. Electronics, 13(12), 2250. https://doi.org/10.3390/electronics13122250