
A Multivariate Time Series Prediction Method for Automotive Controller Area Network Bus Data

Abstract
:1. Introduction
2. Backgrounds
2.1. CAN Bus Data
2.2. Transformer for Multi-Dimensional Time Series Data
3. FGA Transformer
3.1. Overall Architecture
- We employ a novel encoding method by calculating absolute ID information and relative timestamps;
- A cross-window block is proposed to process multi-dimensional time series data, characterizing both the spatial and long-term temporal dimensions;
- It replaces the multi-head self-attention mechanism with our proposed single-head FGA mechanism.
3.2. Pre-Processing and Spatiotemporal Encoding
3.3. Cross-Window for Multi-Dimensional Time Series Data
| Algorithm 1. Cross-Window Data |
| Input: Pre-processed data sliced into segments of a given length, ; Stacking attention block num, ; Max pooling size, ; |
| for in range(): if the current stack is not the first one: perform 1D max pooling on along the time axis with |
| Output: Cross-window data, ; |
3.4. Fast Gated Attention Unit
| Algorithm 2. Fast-Gated Attention |
| Input: Cross-window data, ; Group size, ; |
| Perform layer normalization on Random Shift Operation on along ID axis for in range(): Calculate local , (Equations (19) and (20)) Calculate shared weights and (Equations (21) and (25)) Calculate local attention (Equation (17)) Append the current to Append the shared weights and to and if is divisible by Calculate global , based on (Equations (19) and (20)) Calculate global attention (Equation (17)) if contact method: Calculate the total attention (Equation (28)) elif add method: Calculate the total attention (Equation (29)) Append the current to |
| Output: Fast-gated attention output, ; |
4. Experiments
4.1. Datasets
4.2. Evaluation Metrics
4.3. Parameters
4.4. Ablation Experiments
4.5. Comparison with Other Methods
5. Application of the FGA Transformer in Practical Scenarios
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, Y.; Xiao, Y.; Cheng, L.; Peng, G.; Yao, D. Deep learning-based anomaly detection in cyber-physical systems: Progress and opportunities. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Martinez, C.M.; Heucke, M.; Wang, F.Y.; Gao, B.; Cao, D. Driving style recognition for intelligent vehicle control and advanced driver assistance: A survey. IEEE Trans. Intell. Transp. Syst. 2017, 19, 666–676. [Google Scholar] [CrossRef]
- Wang, C.; Xu, X.; Xiao, K.; He, Y.; Yang, H.; Yang, G. Traffic anomaly detection algorithm for CAN bus using similarity analysis. High-Confid. Comput. 2024, 9, 14–21. [Google Scholar] [CrossRef]
- He, T.; Zhang, L.; Kong, F.; Salekin, A. Exploring inherent sensor redundancy for automotive anomaly detection. In Proceedings of the ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Hanselmann, M.; Strauss, T.; Dormann, K.; Ulmer, H. CANet: An unsupervised intrusion detection system for high dimensional CAN bus data. IEEE Access 2020, 8, 58194–58205. [Google Scholar] [CrossRef]
- Qin, H.; Yan, M.; Ji, H. Application of controller area network (CAN) bus anomaly detection based on time series prediction. Veh. Commun. 2021, 27, 100291. [Google Scholar] [CrossRef]
- Sun, H.; Chen, M.; Weng, J.; Liu, Z.; Geng, G. Anomaly detection for in-vehicle network using CNN-LSTM with attention mechanism. IEEE Trans. Veh. Technol. 2021, 70, 10880–10893. [Google Scholar] [CrossRef]
- Kishore, C.R.; Rao, D.C.; Nayak, J.; Behera, H.S. Intelligent intrusion detection framework for anomaly-based can bus network using bidirectional long short-term memory. J. Inst. Eng. India Ser. B 2024, 105, 541–564. [Google Scholar] [CrossRef]
- Song, H.M.; Kim, H.K. Self-supervised anomaly detection for in-vehicle network using noised pseudo normal data. IEEE Trans. Veh. Technol. 2021, 70, 1098–1108. [Google Scholar] [CrossRef]
- Narasimhan, H.; Ravi, V.; Mohammad, N. Unsupervised deep learning approach for in-vehicle intrusion detection system. IEEE Consum. Electr. Mag. 2021, 12, 103–108. [Google Scholar] [CrossRef]
- Agrawal, K.; Alladi, T.; Agrawal, A.; Chamola, V.; Benslimane, A. NovelADS: A novel anomaly detection system for intra-vehicular networks. IEEE Trans. Intell. Transp. Syst. Mag. 2022, 23, 22596–22606. [Google Scholar] [CrossRef]
- Koltai, B.; Gazdag, A.; Acs, G. Supporting CAN bus anomaly detection with correlation data. In Proceedings of the International Conference on Information Systems Security and Privacy, Rome, Italy, 26–28 February 2024; pp. 285–296. [Google Scholar]
- Wei, P.; Wang, B.; Dai, X.; Li, L.; He, F. A novel intrusion detection model for the CAN bus packet of in-vehicle network based on attention mechanism and autoencoder. Digit. Commun. Netw. 2023, 9, 14–21. [Google Scholar] [CrossRef]
- Song, H.M.; Woo, J.; Kim, H.K. In-vehicle network intrusion detection using deep convolutional neural network. Veh. Commun. 2020, 21, 100198. [Google Scholar] [CrossRef]
- Ning, J.; Wang, J.; Liu, J.; Kato, N. Attacker identification and intrusion detection for in-vehicle networks. IEEE Commun. Lett. 2019, 23, 1927–1930. [Google Scholar] [CrossRef]
- Duan, X.; Yan, H.; Tian, D.; Zhou, J.; Su, J.; Hao, W. In-vehicle CAN bus tampering attacks detection for connected and autonomous vehicles using an improved isolation forest method. IEEE Trans. Intell. Transp. Syst. 2023, 24, 2122–2134. [Google Scholar] [CrossRef]
- Zhao, X.; Han, X.; Su, W.; Yan, Z. Time series prediction method based on Convolutional Autoencoder and LSTM. In Proceedings of the Chinese Automation Congress, Hangzhou, China, 22–24 November 2019; pp. 5790–5793. [Google Scholar]
- Zhang, Y.; Thorburn, P.J. A dual-head attention model for time series data imputation. Comput. Electron. Agric. 2021, 189, 106377. [Google Scholar] [CrossRef]
- He, Z.; Zhao, C.; Huang, Y. Multivariate Time Series Deep Spatiotemporal Forecasting with Graph Neural Network. Appl. Sci. 2022, 12, 5731. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, K.; Huang, Y.; Zhu, Y.; Chen, B. Parallel spatio-temporal attention-based TCN for multivariate time series prediction. Neural Comput. Appl. 2023, 35, 13109–13118. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Y.; Liang, J.; Liu, L. DAFA-BiLSTM: Deep autoregression feature augmented bidirectional LSTM network for time series prediction. Neural Netw. 2023, 157, 240–256. [Google Scholar] [CrossRef]
- Gao, Z.; Kuruoğlu, E.E. Attention based hybrid parametric and neural network models for non-stationary time series prediction. Expert Syst. 2024, 41, 13419. [Google Scholar] [CrossRef]
- Bono, F.M.; Radicioni, L.; Cinquemani, S. A novel approach for quality control of automated production lines working under highly inconsistent conditions. Eng. Appl. Artif. Intell. 2023, 122, 106149. [Google Scholar] [CrossRef]
- Chen, Y.; Ding, F.; Zhai, L. Multi-scale temporal features extraction based graph convolutional network with attention for multivariate time series prediction. Expert Syst. Appl. 2022, 200, 117011. [Google Scholar] [CrossRef]
- Buscemi, A.; Turcanu, I.; Castignani, G.; Crunelle, R.; Engel, T. CANMatch: A Fully Automated Tool for CAN Bus Reverse Engineering based on Frame Matching. IEEE Trans. Veh. Technol. 2021, 70, 12358–12373. [Google Scholar] [CrossRef]
- Wen, H.; Zhao, Q.; Chen, Q.A.; Lin, Z. Automated cross-platform reverse engineering of CAN bus commands from mobile apps. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020; pp. 3–17. [Google Scholar]
- Guyon, I.; Luxburg, U.V.; Bengio, S.; Wallach, H.; Fergus, R.; Vishwanathan, S.; Garnett, R. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Ho, J.; Kalchbrenner, N.; Weissenborn, D.; Salimans, T. Axial Attention in Multidimensional transformers. arXiv 2019, arXiv:1912.12180. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 12124–12134. [Google Scholar]
- Hua, W.; Dai, Z.; Liu, H.; Le, Q. Transformer quality in linear time. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 9099–9117. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking attention with performers. arXiv 2020, arXiv:2009.14794. [Google Scholar]
- Song, H.M.; Kim, H.K. Can Network Intrusion Datasets. 2018. Available online: http://ocslab.hksecurity.net/Datasets/car-hacking-dataset (accessed on 28 August 2018).
- Stocker, A.; Kaiser, C.; Festl, A. Automotive Sensor Data. An Example Dataset from the AEGIS Big Data Project. 2017. Available online: https://zenodo.org/records/820576 (accessed on 28 June 2017).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Datasets | Key Findings | Limitations |
|---|---|---|---|
| Anomaly detection using bzip2 compression [3] | Car-Hacking dataset | Extracts crucial info via bzip2; identifies anomalies through similarity assessments | Unable to detect replay attacks |
| Deep auto-encoder neural network [4] | 20 Hz sampled CAN bus data | Reconstructs CAN bus data for anomaly detection | Can only process sampled data |
| CANet with LSTM and auto-encoder [5] | SynCAN | Facilitates interaction and reconstruction of CAN bus data | Model complexity grows with number of CAN devices |
| LSTM [6] | Binary and Hexadecimal CAN Bus Data | Studies CAN bus data with LSTM | Limited by the sequential nature of LSTM |
| CLAM model with convolution and Bi-LSTM [7] | Physical CAN signals | Conv1D to extract the abstract features of the signal values at each time step and Bi-LSTM to extract the time dependence | Processes each ID separately without correlation |
| Bi-LSTM with SMOTE under-sampling [8] | Attack and Defense Challenge-2020 | The SMOTE under-sampling strategy is used to address the issue of imbalanced data | Unable to recover from error |
| Generative Adversarial Network (GAN) [9] | Car-Hacking dataset | Utilizes pseudo data to assist the network in learning normal data features | Cannot detect system errors |
| Auto-encoder with Gaussian mixture model [10] | CAN IDs; KDDCup-99; WSN-DS; ISCX | GMM is employed to cluster the CAN packet data into normal and attacks | Clustering may lead to misclassifications |
| CNN-LSTM stacked networks [11] | Car-Hacking dataset | End-to-end approach with no need to extract manual features | Processes each ID separately without correlation |
| Clustering and TCN for prediction [12] | SynCAN; Crysys dataset of can traffic logs | Combines correlation analysis with time series forecasting | Misgrouping of IDs may lead to severe misinterpretation |
| AMAEID with multi-layer denoising auto-encoder [13] | Binary CAN data | A multi-layer denoising auto-encoder model and the attention mechanism are used | The massive attacks may make the AMAEID model fail |
| Pre-Processing: Extract the CAN IDs and mapping them to the range [0, num(id)] Normalize the timestamps |
| Spatiotemporal Encoding: Convert the CAN data into a sparse matrix according to ID (Equations (8) and (9)) Calculate the encoding offsets based on timestamp and ID (Equations (12) and (13)) The CAN data are added to through a linear layer (Equation (11)) |
| Local Attention and Global Attention Stack × N: Extract data based on a cross-window after one-dimensional max pooling (Equation (14)) Accumulate data from multiple timestamps as global data based on the group size Calculate global Q, K and local Q, K separately (Equations (19) and (20)) Calculate shared weights V and Gate (Equations (21) and (25)) Calculate global attention and local attention separately (Equation (17)) Calculate the total attention (Equations (28) or (29)) Restore cross-window data to normal data |
| Output: Output prediction results after passing through a linear layer |
| ID | Timestamp | Data |
|---|---|---|
| 0350 | 1479121434.850202 | 05 28 84 66 6d 00 00 a2 |
| 02c0 | 1479121434.850423 | 14 00 00 |
| 0430 | 1479121434.850977 | 03 80 00 ff 21 80 00 9d |
| … | … | … |
| Car-Hacking [33] | SynCAN [34] | Automotive Sensors [5] | |
|---|---|---|---|
| Sample Rate | Not Applicable | Not Applicable | 20 Hz |
| Encoding Formats | Hexadecimal | Decimal | Decimal |
| Id Meaning | Unknown | Unknown | Known |
| Dimension | 27 | 21 | 12 |
| Size (Frames) | 988,871 | 9,567,482 | 3,462,015 |
| Parameters | Value |
|---|---|
| Learning rate | 1 × 10−4 |
| Length of input data | 1024 |
| Batch size | 64 |
| Max pooling size | (2,1) |
| FGA depth | 4 |
| Group size | 5 |
| Hidden dim | 512 |
| Attention mechanism | FGA-Concat |
| Pre-Processing Methods | MAE (Norm)/10−4 | RMSE (Norm)/10−3 |
|---|---|---|
| Using Raw CAN Bus Data | 292.91 | 36.28 |
| Sparse Method | 9.10 | 3.03 |
| Attention Mechanisms | Params/MB | MAE (Norm)/10−4 | RMSE (Norm)/10−3 | FPS |
|---|---|---|---|---|
| Scaled Dot Product | 8.2 | 6.01 | 2.98 | 135.22 |
| Local Gate | 8.2 | 11.54 | 25.89 | 745.30 |
| GA-Add | 8.2 | 3.77 | 1.93 | 124.55 |
| GA-Concat | 16.6 | 3.11 | 1.58 | 119.04 |
| FGA-Add | 8.2 | 4.29 | 2.21 | 2197.63 |
| FGA-Concat | 16.6 | 3.64 | 1.86 | 2178.35 |
| Attention Windows | Params/MB | MAE (Norm)/10−4 | RMSE (Norm)/10−3 | FPS |
|---|---|---|---|---|
| Criss-Cross (64) | 16.6 | 16.16 | 7.21 | 309.96 |
| Seq Axial (1024) | 15.9 | 296.61 | 93.32 | 374.22 |
| Cswin (1024) | 30.3 | 289.49 | 95.83 | 1638.09 |
| Our Cross-win (64) | 15.6 | 18.53 | 8.04 | 2237.58 |
| Our Cross win (1024) | 16.6 | 3.64 | 1.86 | 2178.35 |
| Group Size | Params/MB | MAE (Norm)/10−4 | RMSE (Norm)/10−3 | FPS |
|---|---|---|---|---|
| 1 | 16.6 | 16.16 | 7.21 | 309.91 |
| 5 | 16.6 | 3.64 | 1.86 | 2178.35 |
| 10 | 16.6 | 7.16 | 3.31 | 3196.26 |
| Model | Hyperparameters |
|---|---|
| Common Hyperparameters | dropout_prob = 0.2, input_length = 128, batch_size = 64, learning_rate = 1 × 10−4, optimizer = Adam |
| Auto-Encoder [10] | hidden_dim = 256, compression_rate = 0.6, layer_depth = 3 |
| RNN | hidden_dim = 256, layer_depth = 3 |
| LSTM [6] | hidden_dim = 256, layer_depth = 3 |
| Bi-LSTM [7] | hidden_dim = 256, layer_depth = 3 |
| GRU | hidden_dim = 256, layer_depth = 3 |
| Bi-GRU [18] | hidden_dim = 256, layer_depth = 3 |
| GNN [19] | stack_num = 4, graph_depth = 2, nodes_num = IDs_num, neighbors_num = int(IDs_num)/2, node_dim = 40, conv_channels = 16, residual_channels = 16 |
| Model | Params/MB | MAE (Norm)/10−4 | RMSE (Norm)/10−3 | FPS |
|---|---|---|---|---|
| Auto-Encoder [10] | 0.6 | 240.63 | 87.84 | 327.36 |
| RNN | 1.4 | 107.98 | 42.71 | 36.23 |
| LSTM [6] | 5.4 | 159.21 | 55.15 | 35.48 |
| Bi-LSTM [7] | 15.0 | 5.45 | 2.42 | 12.98 |
| GRU | 4.1 | 150.67 | 49.63 | 47.62 |
| Bi-GRU [18] | 11.3 | 5.22 | 2.21 | 17.81 |
| GNN [19] | 10.0 | 6.17 | 2.48 | 16.10 |
| FGA Transformer | 16.6 | 3.64 | 1.86 | 2178.35 |
| Model | Params/MB | MAE (Norm)/10−4 | RMSE (Norm)/10−3 | FPS |
|---|---|---|---|---|
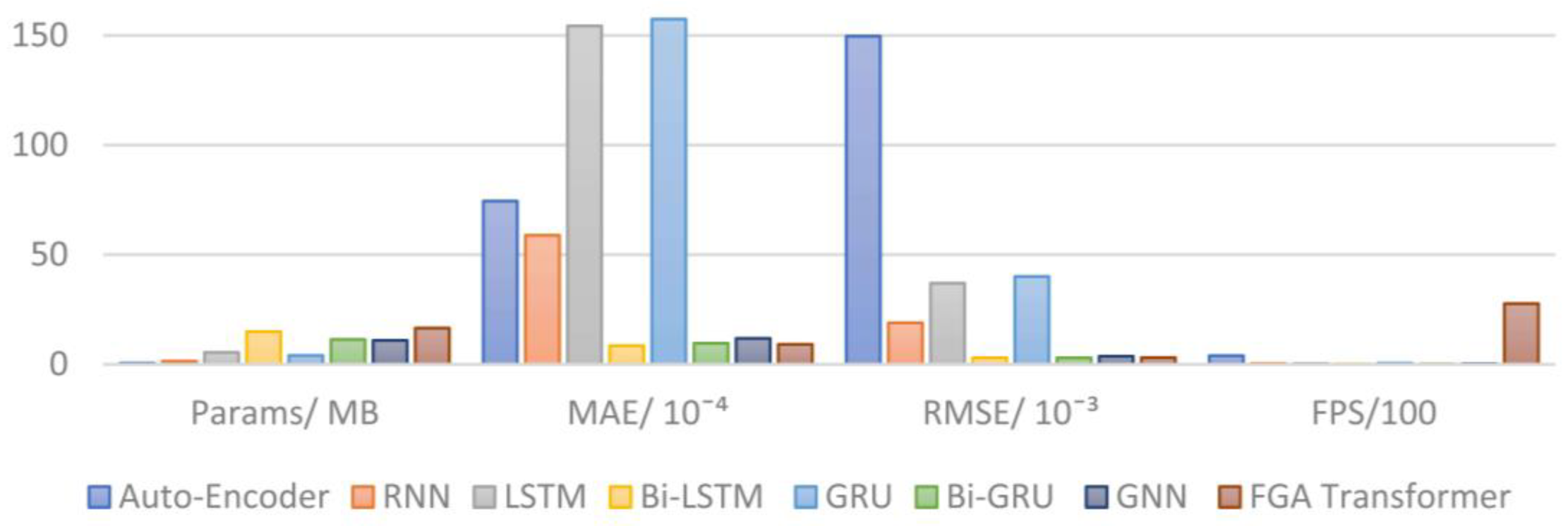
| Auto-Encoder [10] | 0.5 | 74.44 | 149.63 | 393.52 |
| RNN | 1.4 | 58.81 | 18.92 | 38.58 |
| LSTM [6] | 5.4 | 154.30 | 36.97 | 37.12 |
| Bi-LSTM [7] | 14.9 | 8.46 | 2.95 | 16.07 |
| GRU | 4.0 | 157.4 | 40.05 | 49.82 |
| Bi-GRU [18] | 11.3 | 9.59 | 2.93 | 18.49 |
| GNN [19] | 10.9 | 11.81 | 3.67 | 24.75 |
| FGA Transformer | 16.5 | 9.10 | 3.03 | 2768.30 |
| Model | Params/MB | MAE/10−5 | RMSE/10−5 | FPS |
|---|---|---|---|---|
| Auto-Encoder [10] | 0.5 | 18.94 | 65.69 | 335.98 |
| RNN | 1.3 | 51.43 | 178.16 | 37.72 |
| LSTM [6] | 5.3 | 27.87 | 96.55 | 36.22 |
| Bi-LSTM [7] | 14.9 | 27.37 | 94.81 | 15.61 |
| GRU | 4.0 | 5.58 | 18.87 | 48.62 |
| Bi-GRU [18] | 11.2 | 5.02 | 17.38 | 17.87 |
| GNN [19] | 9.0 | 4.61 | 15.98 | 49.75 |
| FGA Transformer | 16.4 | 9.84 | 30.66 | 3062.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Yang, S.; Qu, J.; Wang, K. A Multivariate Time Series Prediction Method for Automotive Controller Area Network Bus Data. Electronics 2024, 13, 2707. https://doi.org/10.3390/electronics13142707
Yang D, Yang S, Qu J, Wang K. A Multivariate Time Series Prediction Method for Automotive Controller Area Network Bus Data. Electronics. 2024; 13(14):2707. https://doi.org/10.3390/electronics13142707
Chicago/Turabian StyleYang, Dan, Shuya Yang, Junsuo Qu, and Ke Wang. 2024. "A Multivariate Time Series Prediction Method for Automotive Controller Area Network Bus Data" Electronics 13, no. 14: 2707. https://doi.org/10.3390/electronics13142707