Abstract
In recent years, with the rapid development of unmanned aerial vehicle (UAV) technology, multi-view 3D reconstruction has once again become a hot spot in computer vision. Incremental Structure From Motion (SFM) is currently the most prevalent reconstruction pipeline, but it still faces challenges in reconstruction efficiency, accuracy, and feature matching. In this paper, we use deep learning algorithms for feature matching to obtain more accurate matching point pairs. Moreover, we adopted the improved Gauss–Newton (GN) method, which not only avoids numerical divergence but also accelerates the speed of bundle adjustment (BA). Then, the sparse point cloud reconstructed by SFM and the original image are used as the input of the depth estimation network to predict the depth map of each image. Finally, the depth map is fused to complete the reconstruction of dense point clouds. After experimental verification, the reconstructed dense point clouds have rich details and clear textures, and the integrity, overall accuracy, and reconstruction efficiency of the point clouds have been improved.
1. Introduction
As an emerging aerial survey modeling method, UAV remote sensing system has the characteristics of maneuverability, portability, high positioning accuracy, low environmental interference, high imaging resolution, and suitability for surveying high-risk areas. It is widely used in regional monitoring, search and rescue, natural disaster analysis, and other tasks. How to use the images taken by the UAV system to quickly and robustly reconstruct the three-dimensional physical information of these scenes has always been a hot topic in computer vision, photogrammetry, and mapping.
For the 3D reconstruction of outdoor large-scale scenes, the SFM method of geometric vision is mostly used, which can recover the 3D model of the target from several disordered images, and has low requirements on image data, strong applicability, and high versatility. The principle of SFM is multi-view geometry. First, all images need to be feature extracted and matched, then the camera position and posture corresponding to each image are calculated, and finally the three-dimensional coordinates of these feature points are reconstructed according to the matched feature points and camera posture to generate a sparse point cloud model of the scene. The SFM algorithm has been studied for many years. In the case of rich image information and clear texture, the classic SFM algorithm has achieved great success. However, in the case of image features that are difficult to extract, such as in strong reflections, repeated textures, weak textures, and featureless environments, the reconstruction quality is often low or even fails. Therefore, the classic SFM algorithm still needs to be well-optimized. The most classic SFM algorithm is the Photo Tourism system proposed by Snavely, et al. [1] in 2006. Its purpose is to use pictures on the Internet to reconstruct the scene in 3D, then use image rendering and browsing technology to form an advanced image browsing system. The author therefore developed a software called Bundler to achieve this. The core of this software is incremental SFM. First, the Scale Invariant Feature Transform (SIFT) algorithm is used to extract feature points; thereafter, nearest neighbor feature matching, RANdom SAmple Consensus (RANSAC), and Direct Linear Transformation (DLT) are used to restore the motion between cameras, and new images are continuously added for bundle adjustment to reconstruct the target 3D point cloud. Later, Wu, Schonberger, and Griwodz et al. [2,3,4] implemented three-dimensional reconstruction algorithms named VisualSFM, Colmap, and Meshroom based on Bundler, respectively. They optimized the SFM reconstruction efficiency by using SIFTGPU and multi-core bundle adjustment, and reconstructed dense point clouds by using algorithms such as Parallelized Multi-View Stereo (PMVS), Clustered Multi-View Stereo (CMVS), and depth map fusion. These are relatively complete three-dimensional reconstruction algorithms.
2. Related Work
Afterward, many scholars focused their research on improving the details of SFM. For example, Lei et al. [5] proposed a hybrid SFM reconstruction algorithm that combines the detection results of SIFT and Speeded-Up Robust Features (SURF) feature points. While increasing the number of feature points, its block-by-block incremental reconstruction also improves the reconstruction efficiency. Yin et al. [6] used SIFT and Oriented Fast and Rotated Brief (ORB) dual feature detection, filtered out matching points based on local image correlation, reduced the number of BA [7] optimization iterations, and reduced the reprojection error. Xue et al. [8] combined the SFM technique with the DLT algorithm, used the SFM algorithm to obtain dimensionless sparse point clouds, and used the close-range photogrammetry DLT algorithm to provide quantitative features such as scale information and deformation that were missing in the SFM method. Qu et al. [9] compressed the image feature vector, used principal component analysis to analyze the relationship between images, and used weighted BA to estimate 3D coordinates, thereby speeding up the calculation.
The rapid development of deep learning has brought about tremendous innovation in computer vision. Given its great success in scene understanding, including target detection and tracking, semantic segmentation, and stereo matching, some scholars have gradually applied Convolutional Neural Networks (CNNs) to SFM, attempting to use deep learning methods to reconstruct three-dimensional scenes. Lindenberger et al. [10] used a CNN to detect feature points and generate feature descriptors. After feature matching, they used deep feature metrics to optimize the feature point positions. In BA calculation, they used feature metric errors instead of reprojection errors. This improved the mapping accuracy but took up a lot of memory and was not suitable for large-scale scene reconstruction. The MVSNet [11,12] proposed by Professor Quan Long’s team at the Hong Kong University of Science and Technology uses binocular depth estimation to construct a cost volume, uses 3D convolution operations to transform the cost volume with differentiable homography to predict depth information, and then reconstructs the 3D point cloud. The following year, the GRU temporal network was used to replace the 3D convolution operation for improvement, reducing the model size. The MVSNet series of multi-view stereo vision methods rely on supervised training with labeled data, which leads to insufficient generalization ability of the model. It is also difficult to obtain ground truth data during the training process. Dai, Huang et al. [13,14] proposed unsupervised and self-supervised MVSNet models respectively, which can learn to obtain depth maps from input multi-view images. The above learning-based method only obtains the depth information of each image, which is not a complete pipeline 3D reconstruction process. In addition, there will be a lack of effective depth values in weak texture areas, and large scene differences will also lead to poor reconstruction results.
NeRF (Neural Radiance Field) [15], the best paper of ECCV 2020, uses neural networks to reconstruct 3D scenes from multi-view 2D images. It can train a 3D model of complex scenes using only 2D images and camera pose information as supervision. Subsequently, Block-NeRF [16], MVSNeRF [17], and FastNeRF [18] were proposed, which made a series of improvements in large-scale scene reconstruction, the number of training images, and the training and rendering speeds. Although the NeRF reconstruction model is rich in detail and has been studied by many people, its shortcomings are also obvious. Its reconstruction stage requires not only 2D images but also the position of each image. It generally uses the traditional method Colmap for sparse reconstruction to estimate the camera’s internal and external parameters and 3D point information. In addition, NeRF can only represent static scenes. The trained NeRF representation will not generalize to other scenes, and reconstruction is prone to depressions in areas where the image is dark or black.
Since that the classic SFM algorithm is highly adaptable, highly versatile, and easy to collect data, and currently commercial 3D reconstruction software is mostly based on this principle, it still has significant advantages in practical engineering applications. Therefore, this article aims to use multi-view three-dimensional reconstruction and deep learning methods to improve and optimize based on the incremental SFM algorithm. Our main contributions can be summarized as follows:
- We propose a high-resolution image feature extraction and feature matching method based on SuperPoint [19] and SuperGlue [20] algorithm.
- We employ the BFGS-corrected [21] GN solver to minimize the reprojection error.
- In multi-view stereo, we utilize a Sparse-to-Dense depth regression network [22] to predict a full-resolution depth map for reconstructing a dense point cloud.
3. The Proposed Algorithm
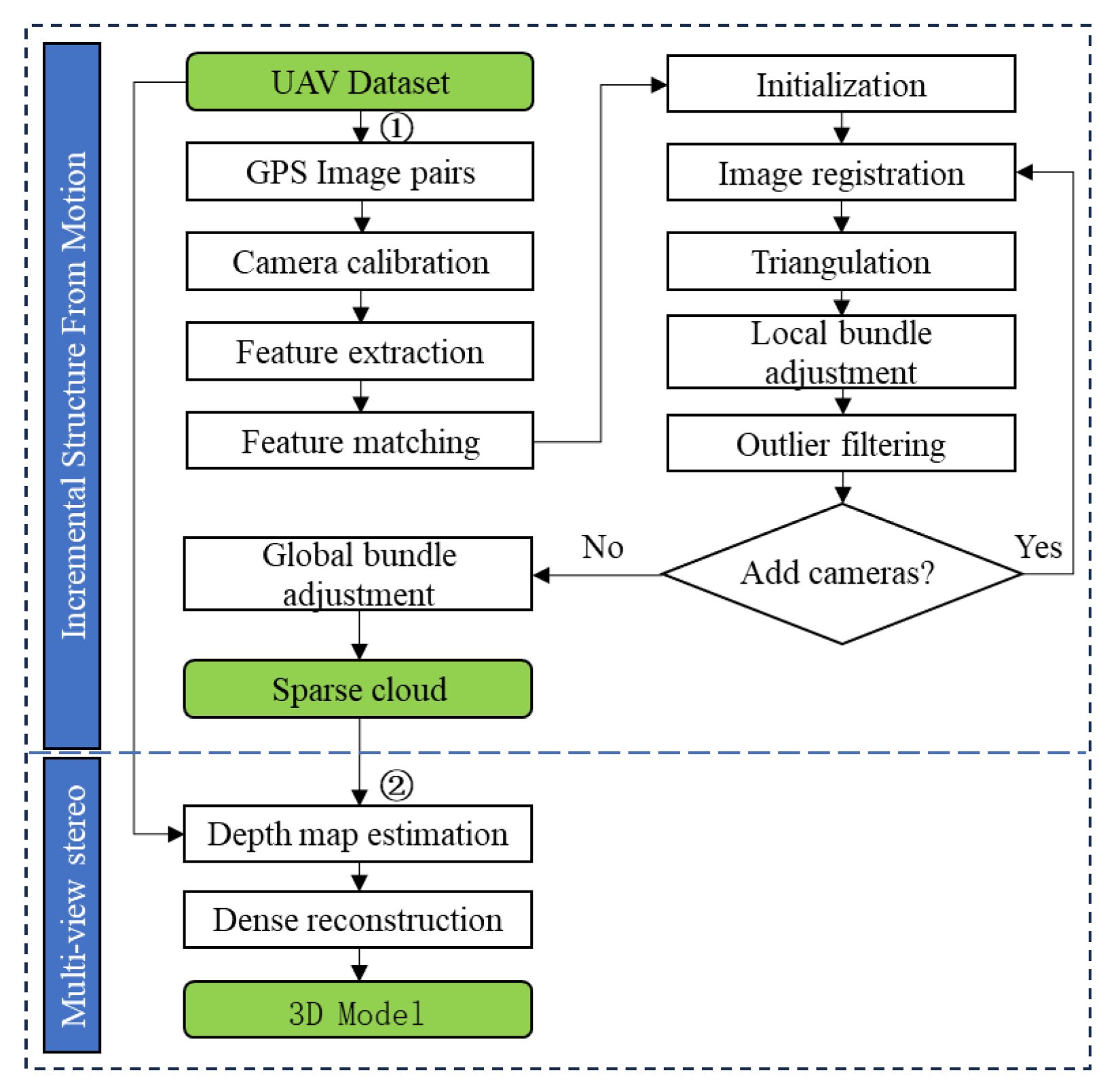
Our work is mainly divided into two parts: sparse point cloud reconstruction using SFM and dense point cloud reconstruction by fusing depth map information. The pipeline of the algorithm is shown in Figure 1.
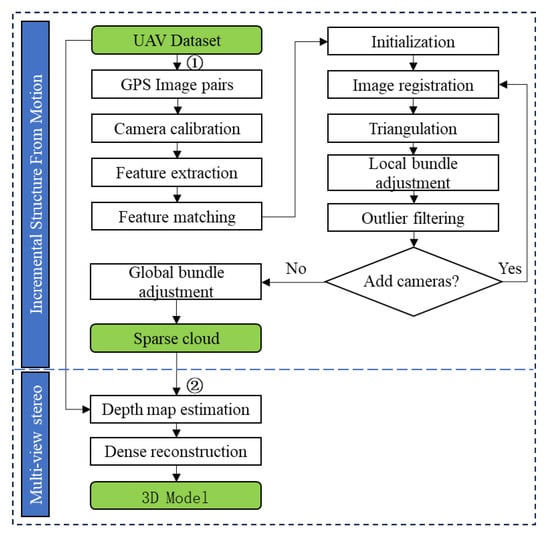
Figure 1.
Algorithm flow chart.
In the SFM algorithm, the camera must first be calibrated to obtain the camera internal parameters. The GPS coordinates are then extracted from the EXIF information of the images taken by the drone as the location prior information. To minimize the time required for matching, only adjacent region images are compiled into image match pairs. Then, SuperPoint [18] is used to extract feature points and generate feature descriptors. The SuperGlue [19] algorithm is used for feature matching. The RANSAC algorithm is then used to eliminate incorrect matching point pairs. The essential matrix is obtained with the eight-point method, using the two images with the most matching feature point pairs. Triangulation is subsequently performed to obtain the 3D point cloud. New images are continuously registered and a local bundle adjustment is executed to reconstruct the point cloud of multiple images. A final global bundle adjustment is carried out to yield the sparse point cloud.
Sparse point clouds are only 3D representations of image feature points. The number of point clouds is small and cannot represent the three-dimensional features of the scene, so the sparse point clouds need to be densely reconstructed. Point cloud dense reconstruction uses the original image and the sparse point cloud reconstructed by SFM as input, and predicts the depth map of each image based on the full convolutional neural network of the codec structure, then fuses the depth map to complete the dense point cloud reconstruction.
3.1. UAV Dataset
The image dataset was collected using the orthophotography method of the DJI Phantom 4 RTK UAV with an accuracy of 1 cm horizontal positioning and a resolution of 5472 × 3648. Based on the urban buildings and park landforms, we set the UAV route in a bow shape with a flight range of approximately 120 × 120 m. At the same time, to ensure image quality and the accuracy of the reconstructed model, we used close-up photography to shoot at a flight altitude of approximately 30 m. A total of 400 images of the two areas were collected.
When reconstructing sparse point clouds, the spatial and geometric relationships of the target were determined by estimating the camera pose, which requires the camera intrinsic parameters. To obtain the intrinsic parameters of the drone camera, the opencv4.5.5 stereo calibration algorithm was used to calibrate and obtain the intrinsic parameter.
3.2. Selecting Image Pairs to Match
Considering that each image contains tens of thousands of feature points, exhaustively matching features between image pairs will result in meaningless matching between a large number of mismatched images and waste a lot of computing resources. To solve this problem, we used the latitude and longitude coordinates of the two images to calculate the Euclidean distance between them. Then we established a threshold for this distance. If the calculated distance was lower than the established threshold, we considered the pair of images as a match and continue with feature matching.
3.3. SuperPoint and SuperGlue Overview
Point features have characteristics such as simplicity in computation and strong robustness. Moreover, local feature matching is currently the most popular feature matching algorithm. The point feature matching algorithm consists of three steps: feature point detection, extraction feature descriptors, and feature point matching. This algorithm is a key processing step in stereo vision and is widely used in fields such as image registration, simultaneous localization and mapping (SLAM), SFM, etc. Classic feature detection algorithms rely on manually designed criteria and gradient statistics such as SIFT, SURF, ORB, etc. Due to mismatched key points and imperfect descriptors, some correspondences may be incorrect. The impact of deep learning in the field of computer vision has led to a shift from manually selecting features to learning features directly from image data. Examples of such methods include Deepdesc [23], LIFT [24], D2-Net [25], SuperPoint, LoFTR [26], etc. SuperPoint can be regarded as a learned version of SIFT, which follows the standard paradigm of extracting local descriptors and has improved accuracy compared to classical vision methods.
3.3.1. Feature Extraction
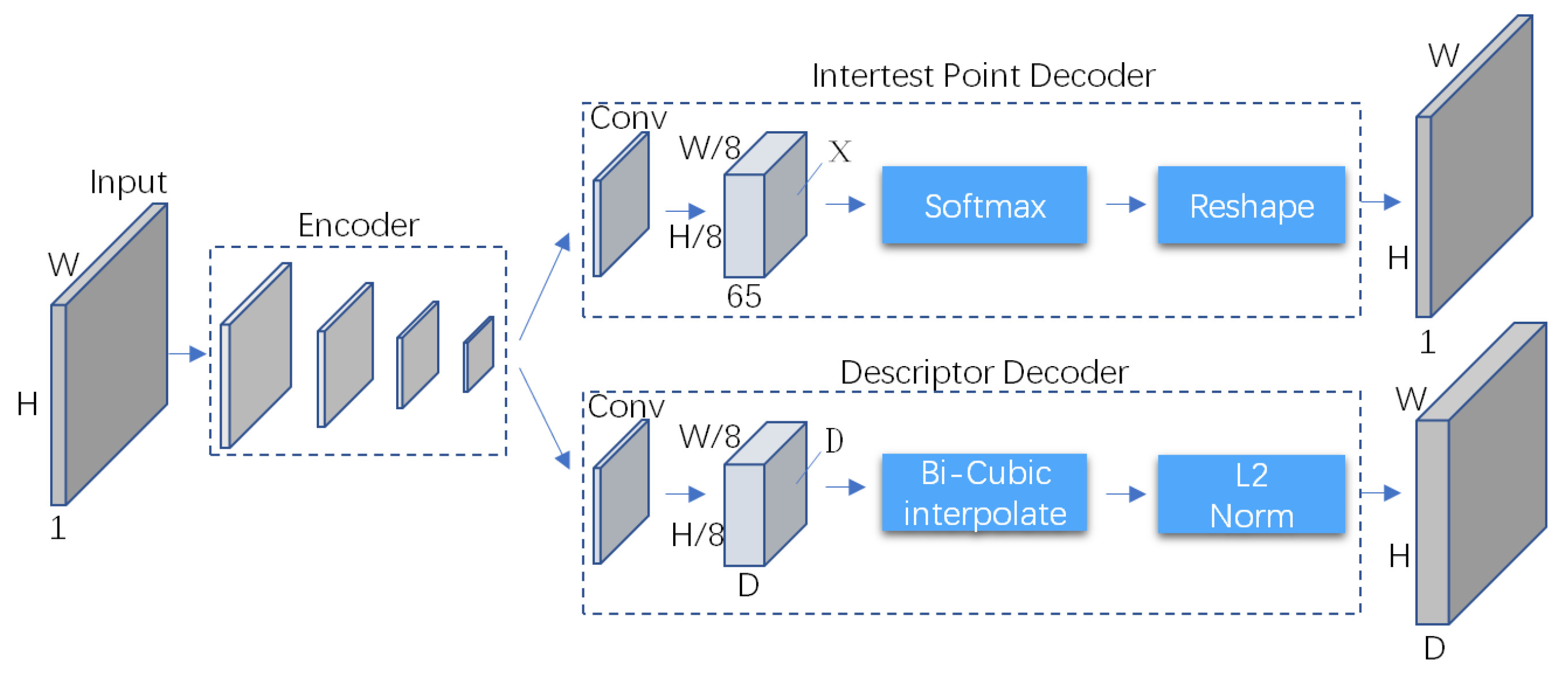
SuperPoint is an end-to-end self-supervised fully convolutional neural network that extracts feature points and generates feature descriptors on full-size images. Its network architecture is shown in Figure 2. The network takes gray images as input. The Encoder part shares a VGGNet encoder. The interest point decoder branch is responsible for keypoint detection, and it outputs the probability of each pixel being an interest point. The descriptor decoder branch outputs a 256-dimensional vector to represent the features of each pixel.
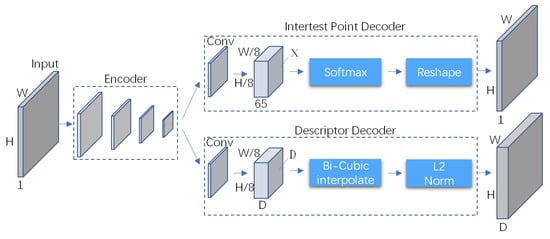
Figure 2.
SuperPoint architecture.
SuperPoint, as a self-supervised network model algorithm for feature detection, has a tremendous innovation in its training process:
- During the pretraining of the feature point detector, synthetic images with pseudo-labels are used. The output is a heatmap with the same size as the input image. Each pixel of the heatmap represents the probability of that point being an interest point. By using non-maximum suppression (NMS), sparse feature points can be obtained, and the resulting model is called MagicPoint [27]. The synthetic images with clear edge and corner features are randomly generated by the computer. These images include triangles, squares, lines, cubes, checkerboards, and stars, among others. Since they are computer-generated, each image comes with the coordinates of feature points on the image. To further increase the robustness of the model, Gaussian noise and circles without any feature points were randomly added to the images during training, which resulted in better generalization and robustness compared to classical detectors.
- Combined with the Homography Adaptation mechanism, the feature point detector is trained using unlabeled real images. First, ( = 100) random homography transformations are applied to generate N Warp Images from the unlabeled images. These Warp Images are then fed into the MagicPoint model, and the detected feature points are projected back onto the original images. This combined set of projected feature points serves as the ground truth for training. By following this process, the detected feature points become more abundant and exhibit certain homography invariance.
- The original images, along with their corresponding images after homographic transformations, are fed into the SuperPoint network. Using the feature point locations and the correspondence relationships between them, the network is trained to generate feature points and descriptors.
3.3.2. Feature Matching
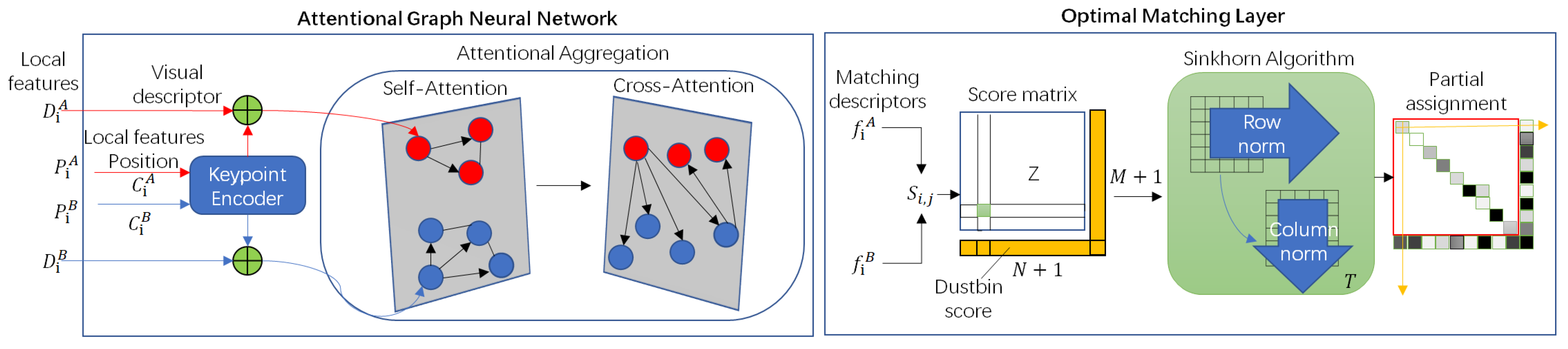
SuperGlue is a feature matching network based on graph neural networks and attention mechanisms. Its input consists of the feature point locations and descriptors of two images, and its output is the feature correspondence. The network architecture is mainly composed of two modules, as shown in Figure 3: Attention Graph Neural Network (GNN) module and Optimal Matching Layer. The keypoint encoder encodes the feature point positions and confidences of images A and B into vectors of the same dimensionality as the feature descriptors. These vectors are then concatenated with the feature descriptors to form feature vectors. Self-attention and cross-attention mechanisms are utilized to enhance the matching performance of this vector. Following that, the process enters the optimal matching layer, where the similarity score matrix is computed by calculating the inner product of the feature matching vectors. Finally, the Sinkhorn algorithm [28] is iteratively applied to solve for the optimal feature assignment matrix.
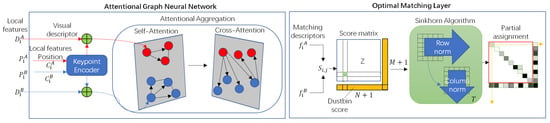
Figure 3.
SuperGlue architecture.
3.3.3. Matching Strategy
SuperPoint is suitable for fast and real-time video feature detection because its encoder adopts shallow VGG network architecture, resulting in a smaller model that allows faster inference. The official training dataset consists of both synthetic and real data, all of which are low-resolution images. Downsampling them to 1/8 allows for extracting high-level semantic information. However, aerial images captured by drones have higher resolutions. If these high-resolution images are directly scaled down and fed into the network for feature extraction, a large amount of key information will be lost. In addition, there is a risk of erroneous feature extraction due to changes in image proportions. On the contrary, using the original resolution as input would consume a lot of memory, which may cause a memory crash.
Inspired by YOLT [29], we adopted a sliding window cropping approach for drone images. Sub-images of size 640 × 480 pixels were generated using a sliding window with a default input size defined by the network. Each sub-image had a 15% overlap region. The feature extraction results of the sub-images were then merged, and non-maximum suppression (NMS) was applied to filter out redundant features. This process yields the feature point detection results for each original image. Subsequently, SuperGlue feature matching was utilized, and the RANSAC algorithm was implemented to further eliminate misaligned feature points. By substituting classical feature matching with a deep learning-based approach and continuing with the subsequent 3D reconstruction process, improvements in both the quantity and accuracy of feature point matching can significantly enhance the SFM reconstruction performance.
3.4. Bundle Adjustment
The bundle adjustment method minimizes the error between the projection of the 3D space point and the corresponding pixel point in the image by adjusting the 3D space point and the calculated camera projection matrix, thereby ensuring the accuracy of the 3D space point coordinates. The core problem of BA is the least squares optimization problem involving camera poses and 3D points, which can be described as follows:
Here, X denotes the set of unknown parameters, n denotes the number of 3D points, m images, and the function h is a projection equation that projects 3D points in space onto a two-dimensional image. is the camera pose, is a 3D point, and the camera pose includes the rotation matrix and the translation vector . The symbol represents whether point i is included in image j. If point i has a projected point in image j, is equal to 1; otherwise, it is 0. By optimizing , we aim to minimize the distance between the projected point and the true point as much as possible.
Similar to Colmap, we did not perform BA after every triangulation step because incremental SFM only affects the model locally. After each triangulation, we applied local BA to the images with the most connections. When the model grew to a certain percentage, we performed global BA. After adding all the images, we conducted another round of global BA to reduce reconstruction errors and improve efficiency.
Currently, for the bundle adjustment method, the main solving methods are the GN method and the Levenberg–Marquardt (LM) algorithm [30]. The GN method is an approximate solution that expands the least squares function with a first-order Taylor series to find the optimal value. It ignores the derivatives of higher-order terms, resulting in fast convergence and greatly reduced computational complexity. However, it also brings new problems. The Jacobian matrix of the first-order derivatives is positive semi-definite. When the initial values of the input model deviate significantly from the true values or when the Jacobian matrix becomes singular, this method is prone to divergence and fails to meet the convergence requirements. The LM algorithm achieves problem solvability by adding a damping term to GN, but since the specific value of the damping term is obtained through continuous trial and error, it is difficult to obtain an accurate descent direction, resulting in a slower descent speed during iteration.
The BFGS method is a local search second-order optimization algorithm and one of the most widely used second-order algorithms in numerical optimization, with a good positive definite property. The sparse BFGS [31] is a new solution method proposed using the positive definite property of BFGS, but each iteration requires computing the high-order information of the Hessian matrix, which increases the number and amount of calculations. BFGS-GN [32] also iteratively solves the high-order derivative information of the objective equation using the BFGS method and accurately represents the Hessian matrix in the objective equation, solving the sensitivity to initial values in the BA method based on the GN method.
The function in (1) can be approximated using Taylor series expansion around the current guess , written as:
Here, and , is the Jacobian matrix. In order to obtain the minimum value, the right side of Equation (2) is differentiated and the first-order derivative is set to zero.
Here, is called a Hessian matrix, . In the GN method, the higher-order derivative matrix is discarded and is used instead of the Hessian matrix to solve the descent direction of the equation.
During the iterative solving process, the Hessian matrix must be positive definite, and the Jacobian matrix in Equation (4) needs to have full rank. The Jacobian matrix represents the relationship between camera parameters and observed 3D coordinate points. It varies with the input transformation. When the initial value is not good, the optimization problem generally cannot be solved. This is the reason why the Gauss–Newton initial value diverges.
BFGS is an extension of the Newton method optimization algorithm, written as:
where is a gain matrix of the kth iteration and is a small positive value, set as 1 × 10−6. In addition, denotes the gradient of the cost function, written as:
According to the singularity-free matrix propagation in the BFGS algorithm, if is a positive definite matrix and , then is also a positive definite matrix. If , remains unchanged and is set to . Therefore, there are two cases for the gain matrix:
Using or modifies Hessian matrix to maintain positive definiteness no matter how the input value changes and iterates, where E is the identity matrix.
is a positive definite dense matrix with high computational complexity, and it cannot be applied to solve large-scale BA problems. Therefore, given a filtered sparse higher-order matrix , we aimed to reduce the density of the gain matrix without compromising accuracy by removing some elements and restoring its sparsity. The low-order derivative matrix is calculated through . When the element at position (i, j) in the matrix is zero, the corresponding element in the filter is also set to zero.
m and n represent the row and column indices of the matrix. The nonzero elements are divided into two categories: diagonal elements and off-diagonal elements. By keeping both of them in the gain matrix , better solution values can be obtained. The gain matrix is transformed into a sparse matrix using the Hadamard product of the filter.
is a sparse matrix with the same structure as the low-order derivative matrix. After utilizing the sparse in solving the descent direction, it becomes feasible to efficiently solve the bundle adjustment problem.
is the newly obtained Hessian matrix.
3.5. Multi-View Stereo
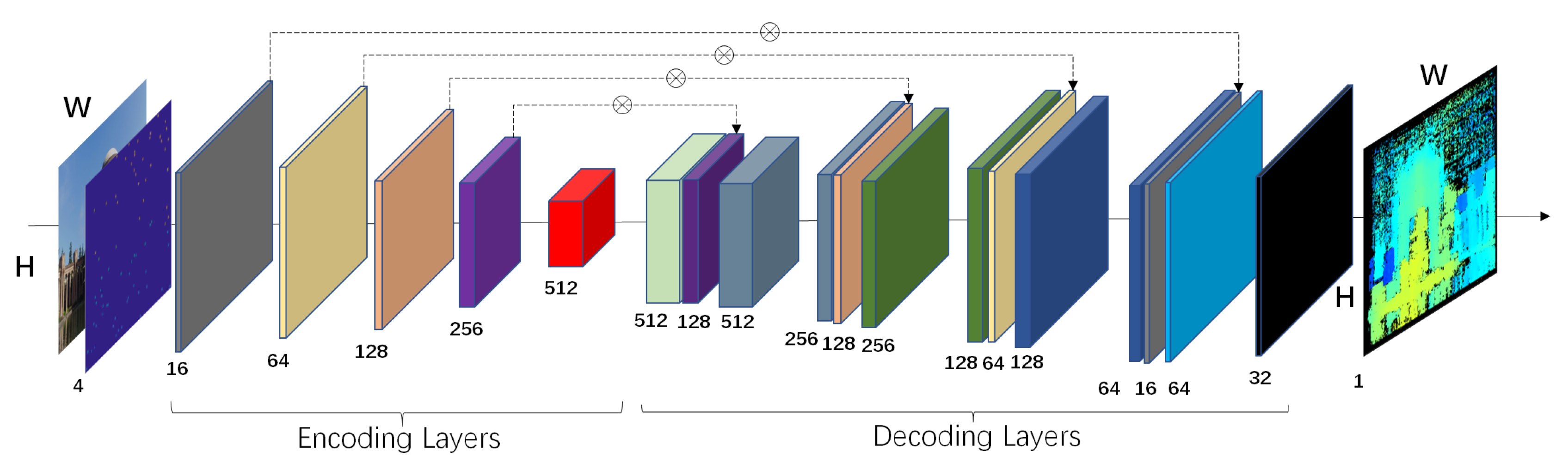
Using the camera poses and sparse point cloud information obtained from SFM as input, it is possible to use multi-view stereo vision techniques for dense reconstruction. The SFM point cloud is derived from feature matching, and the matched point pairs are sparse. Therefore, the reconstructed point cloud model is also sparse, and cannot intuitively display the scene structure and texture features. Dense reconstruction is required to make the sparse point cloud denser. We used RGB images and corresponding sparse depth maps to predict the global depth information of the image. Then, referring to the image sequence and inverse projection matrix, we converted the depth map into a 3D point cloud, achieving a dense reconstruction of the sparse point cloud. Both Sparse-to-Dense and DELTAS [33] proposed an image depth regression model. The sparse point cloud is converted into a sparse depth map with the same resolution as the color image. Then, both the converted sparse depth map and the original RGB image are input into the model to perform image depth estimation. These methods have achieved better results than classical methods on datasets such as NYU-Depth-v2, ScanNet, and KITTI. The network architecture is shown in Figure 4, where the feature extraction layer consists of ResNet and the decoding layer consists of four upsampling layers.
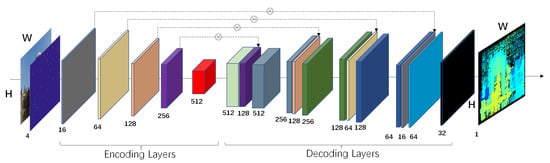
Figure 4.
Sparse-to-Dense architecture.
Geometric Filtering
Projecting the depth values of each pixel in the depth map into three-dimensional space results in a significant amount of redundant points and outliers. It is necessary to use geometric consistency to remove the outliers in the depth map.
The point on image is projected onto image according to its corresponding depth value , resulting in point on . The corresponding depth value of on is . Then, based on , is further projected back onto image to obtain point . The depth value of is denoted as . By calculating the positional offset error between and , as well as the depth error between and , we can evaluate whether point is estimated correctly. When the condition indicated by Equation (12) is satisfied, it means that the depth estimation result of point is geometrically consistent with the view of image .
In the depth map fusion strategy, point needs to satisfy geometric consistency with at least two views other than image in order to be preserved. After performing outlier filtering on all depth maps, the depth pixel points can be projected onto a three-dimensional space using the camera’s inverse projection matrix, resulting in a dense 3D point cloud. In this study, multi-threaded parallel acceleration was enabled during the depth map fusion process, leading to improved efficiency.
4. Experiments
4.1. Feature Matching
To validate the robustness and effectiveness of the outdoor large-scale scene feature matching algorithm, experiments were conducted using a dataset of aerial images captured by unmanned aerial vehicles. A comparison was made in terms of feature point extraction efficiency, matching efficiency, and matching accuracy. The visual results of feature matching are shown in Figure 5. The experimental setup included the following hardware and software environment: CPU: I9 12900KF, GPU: 3080Ti 12GB, 32GB memory, CUDA 11.7, PyTorch 1.3.0.

Figure 5.
Feature matching map.
Figure 5 demonstrates that the SIFT algorithm’s feature extraction capability on aerial image datasets is still remarkable. Compared with SuperPoint, it extracts more feature points and takes more time, as seen in Table 1. However, the number of matched point pairs is lower than SuperPoint, indicating that the SIFT algorithm may not extract point positions or descriptors accurately. To better compare the performance of feature extraction, we cropped 80 images to a size of 640 × 480 and quantitatively compared different feature extraction methods. The time consumption under the average number of feature points per frame is shown in Table 1.

Table 1.
Feature extraction analysis.
From the above, it can be concluded that SuperPoint has better robustness in feature descriptors during feature point matching, with higher matching accuracy compared with SIFT. In cases of weak texture or repetitive patterns, SuperPoint has a certain advantage.
4.2. Depth Map Estimation
Depth map estimation entails the calculation of depth information for each pixel within a reference image, ensuring that the local tangent plane of each pixel mapping closely mirrors the tangent plane of the actual scene. Given the inherent noise present in the generated depth map, it is imperative to filter out any erroneous points. Following this filtration process, depth map fusion is undertaken, with the depth values subsequently back-projected into a three-dimensional space to generate a point cloud model.
To verify the accuracy of depth map estimation in this paper, we trained the model on several open-source datasets including DTU, NYU-Depth-v2, and BlendedMVS [34]. This was to improve the model’s generalization to aerial images and enhance the accuracy of predicted depth maps. The sparse depth maps required for network input were obtained from sparse point clouds obtained by deep learning-based matching and reconstruction. We trained the network model on these three datasets, and the results of the predicted depth maps are shown in Figure 6. It can be observed that the depth estimation achieves good performance across all three datasets. In addition, we also conducted quantitative evaluations on depth maps.

Figure 6.
Depth map estimation results (column 1 is the original image, column 2 is the sparse point cloud map corresponding to the image, column 3 is the depth map estimated by the algorithm in this paper, and column 4 is the ground truth corresponding to the original image).
The evaluation metrics for depth map estimation are the root mean squared error (RMSE) and the mean absolute relative error (REL) between the ground truth depth map and the predicted depth map. It is written as:
The quantitative results are listed in Table 2. Our performance compares favorably to the Colmap fusion techniques. These two methods of MVSNet are even inferior to Colmap.
Table 2.
Quantitative comparison with several other depth map estimation algorithms on three datasets.
4.3. Multi-View Stereo
After depth map estimation, it is necessary to back-project the pixels with depth values into 3D space and use geometric consistency to remove erroneous point clouds and achieve dense point cloud reconstruction. The experimental results are shown in Figure 7, where scene 1 and scene 2 were reconstructed using 125 and 136 images respectively, covering an area of 120 × 120 m. It can be seen from the figure that our method outperforms traditional open-source algorithms such as Colmap and Meshroom, generating more complete and detailed dense point clouds.
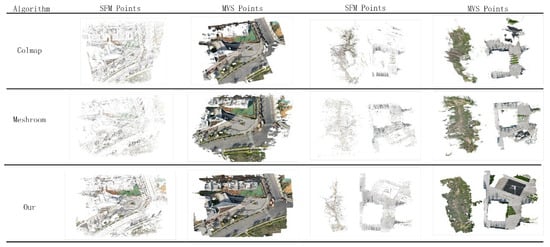
Figure 7.
Sparse and dense point clouds.
We performed block matching on high-resolution images based on a deep learning feature matching method, then used a compensated BFGS-GN bundle adjustment algorithm to optimize the point cloud position. We used a fully convolutional neural network to predict image depth and reconstruct dense point clouds using depth maps to successfully achieve complete 3D reconstruction of drone aerial images.
In order to quantitatively evaluate the speed of the algorithm in this paper, the running time comparison of each stage of the algorithm is shown in Table 3.
Table 3.
Comparison of 3D reconstruction time cost.
To make the experimental comparison fairer, all methods used GPU. From Table 3, we can see that the proposed algorithm reconstructs more 3D points and the whole process takes the shortest time. The reason why the SFM process takes too much time is that more feature points are extracted. The BA method of BFGS-GN has the highest efficiency.
5. Conclusions
The classic incremental motion restoration structure 3D reconstruction has problems such as insufficient efficiency, difficulty in extracting weak texture features, and scene offset when used for drone photography datasets. This paper is based on the feature matching method of SuperPoint + SuperGlue, adopts a sliding window block feature matching strategy, and uses the RANSAC algorithm to eliminate mismatched feature pairs. After selecting the initial image pair for triangulation, the BFGS Gauss–Newton method is used to minimize the reprojection error to optimize the camera pose and 3D point cloud position. This method reduces the time of the BA process. Finally, the sparse to dense fully convolutional neural network estimates the full-resolution depth map with the sparse depth map and the original RGB image, and reconstructs the dense point cloud with geometric consistency constraints. Experimental results show that the point cloud reconstructed in this paper is more complete and has richer details. In general, it improves the efficiency of 3D reconstruction and achieves satisfactory results in the 3D reconstruction task of large scenes. Since incremental SFM is a cumbersome 3D reconstruction method with extremely complex mathematical relationships, and cannot use raw RGB images for end-to-end 3D reconstruction using deep learning, in the future we will further explore improving the SFM algorithm based on deep learning, such as optimizing the estimation of the camera pose in the triangulation step using deep learning to obtain a better 3D reconstruction model.
Author Contributions
Conceptualization, C.W. and C.F. (Chang Feng); methodology, C.W. and L.L. (Lei Liu); software, L.L. (Lei Liu), C.F. (Chuncheng Feng) and W.G.; validation, L.L. (Lei Liu), L.Z. and L.L. (Libin Liao); writing—original draft preparation, L.L. (Lei Liu); writing—review and editing, C.W.; supervision, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Science Foundation of China under Grant No. 62205342, and the Sichuan Science and Technology Program under Grant No. 2022YFG0148.
Data Availability Statement
The data can be shared up on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Noah, S.; Steven, M.S.; Richard, R. Photo tourism: Exploring photo collections in 3D. ACM Trans. Graph. 2006, 25, 835–846. [Google Scholar]
- Zheng, E.L.; Wu, C.C. Structure from Motion using Structure-less Resection. In Proceedings of the International Conference on Computer Vision (ICCV2015), Santiago, Chile, 13–16 December 2015; p. 240. [Google Scholar]
- Schonberger, J.L.; Frahm, J.M. Structure-from-motion revisited. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Carsten, G.; Simone, G.; Fabien, C. AliceVision Meshroom: An open-source 3D reconstruction pipeline. In Proceedings of the 12th ACM Multimedia Systems Conference, Istanbul, Turkey, 28–30 September 2021; pp. 241–247. [Google Scholar]
- Gao, L.; Zhao, Y.B.; Han, J.C.; Liu, H.X. Research on Multi-View 3D Reconstruction Technology Based on SFM. Sensors 2022, 22, 4366. [Google Scholar] [CrossRef] [PubMed]
- Yin, H.Y.; Yu, H.Y. Incremental SFM 3D reconstruction based on monocular. In Proceedings of the 13th International Symposium on Computational Intelligence and Design (ISCID2020), Hangzhou, China, 12–13 December 2020; pp. 17–21. [Google Scholar]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.I. Bundle adjustment—A modern synthesis. In Proceedings of the International Workshop on Vision Algorithms, Corfu, Greece, 21–22 September 1999; pp. 298–372. [Google Scholar]
- Xue, Y.D.; Zhang, S.; Zhou, M.L.; Zhu, H.H. Novel SfM-DLT method for metro tunnel 3D reconstruction and Visualization. Undergr. Space 2021, 6, 134–141. [Google Scholar] [CrossRef]
- Qu, Y.; Huang, J.; Zhang, X. Rapid 3D reconstruction for image sequence acquired from UAV camera. Sensors 2018, 18, 225. [Google Scholar] [CrossRef]
- Lindenberger, P.; Sarlin, P.E.; Larsson, V.; Pollefeys, M. Pixel-perfect structure-from-motion with featuremetric refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–18 October 2021; pp. 5987–5997. [Google Scholar]
- Yao, Y.; Luo, Z.X.; Li, S.W.; Fang, T.; Quan, L. MVSNet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV2018), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Yao, Y.; Luo, Z.X.; Li, S.W.; Shen, T.W.; Fang, T.; Quan, L. Recurrent MVSNet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2019), Long Beach, CA, USA, 16–20 June 2019; pp. 5525–5534. [Google Scholar]
- Dai, Y.C.; Zhu, Z.D.; Rao, Z.B.; Li, B. MVS2: Deep unsupervised multi-view stereo with multi-view symmetry. In Proceedings of the International Conference on 3D Vision, Quebec City, QC, Canada, 16–19 September 2019; pp. 1–8. [Google Scholar]
- Huang, B.C.; Yi, H.W.; Huang, C.; He, Y.J.; Liu, J.B.; Liu, X. M3VSNet: Unsupervised multi-metric multi-view stereo network. In Proceedings of the IEEE International Conference on Image Processing (ICIP2021), Anchorage, AK, USA, 19–22 September 2021; pp. 3163–3167. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Tancik, M.; Casser, V.; Yan, X. Block-nerf: Scalable large scene neural view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 8248–8258. [Google Scholar]
- Chen, A.; Xu, Z.; Zhao, F. MVSNerf: Fast generalizable radiance field reconstruction from multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 14124–14133. [Google Scholar]
- Garbin, S.J.; Kowalski, M.; Johnson, M. FastNerf: High-fidelity neural rendering at 200fps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 14346–14355. [Google Scholar]
- DeTone, D.; Malisiewicz, T.; Rabinovich, A. SuperPoint: Self-supervised interest point detection and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 224–236. [Google Scholar]
- Sarlin, P.E.; DeTone, D.; Malisiewicz, T. Superglue: Learning feature matching with graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4938–4947. [Google Scholar]
- Zhou, W.; Chen, X. Global convergence of a new hybrid Gauss–Newton structured BFGS method for nonlinear least squares problems. SIAM J. Optim. 2010, 20, 2422–2441. [Google Scholar] [CrossRef]
- Ma, F.; Karaman, S. Sparse-to-dense: Depth prediction from sparse depth samples and a single image. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA2018), Brisbane, Australia, 21–25 May 2018; pp. 4796–4803. [Google Scholar]
- Simo-Serra, E.; Trulls, E.; Ferraz, L. Discriminative learning of deep convolutional feature point descriptors. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 118–126. [Google Scholar]
- Yi, K.M.; Trulls, E.; Lepetit, V. Lift: Learned invariant feature transform. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 467–483. [Google Scholar]
- Dusmanu, M.; Rocco, I.; Pajdla, T. D2-Net: A trainable CNN for joint detection and description of local features. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2019), Long Beach, CA, USA, 16–20 June 2019; pp. 8092–8101. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y. LoFTR: Detector-free local feature matching with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2021), Virtual, 19–25 June 2021; pp. 8922–8931. [Google Scholar]
- Daniel, D.; Tomasz, M.; Andrew, R. Toward geometric deep slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2017), Honolulu, HI, USA, 22–25 July 2017; pp. 1–14. [Google Scholar]
- Marco, C. Sinkhorn distances: Lightspeed computation of optimal transportation distances. Adv. Neural Inf. Process. Syst. 2013, 26, 2292–2300. [Google Scholar]
- Adam, V.E. You only look twice: Rapid multi-scale object detection in satellite imagery. In Proceedings of the Computer Vision and Pattern Recognition (CVPR2018), Salt Lake City, UT, USA, 18–23 June 2018; p. 1805.09512. [Google Scholar]
- Ananth, R. The levenberg-marquardt algorithm. Tutor. LM Algorithm 2004, 11, 101–110. [Google Scholar]
- Li, Y.Y.; Fan, S.Y.; Sun, Y.B.; Wang, Q.; Sun, S.L. Bundle adjustment method using sparse BFGS solution. Remote Sens. Lett. 2018, 9, 789–798. [Google Scholar] [CrossRef]
- Zhao, S.H.; Li, Y.Y.; Cao, J.; Cao, X.X. A BFGS-Corrected Gauss-Newton Solver for Bundle Adjustment. Acta Sci. Nat. Univ. Pekin. 2020, 56, 1013–1019. [Google Scholar]
- Ayan, S.; Zak, M.; James, B.; Vijay, B.; Andrew, R. Deltas: Depth estimation by learning triangulation and densification of sparse points. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference (ECCV2020), Glasgow, Scotland, 23–28 August 2020; pp. 104–121. [Google Scholar]
- Yao, Y.; Luo, Z.X.; Li, S.W.; Zhang, J.Y. BlendedMVS: A large-scale dataset for generalized multi-view stereo neworks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR2020), Seattle, WA, USA, 14–19 June 2020; pp. 1790–1799. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).