
TSTL-GNN: Graph-Based Two-Stage Transfer Learning for Timing Engineering Change Order Analysis Acceleration

 , ,
, ,
Abstract
1. Introduction
- We propose the TSTL-GNN model and establish a two-stage prediction task, where the features and the GNN model from the first stage’s transition time prediction are transferred to the second stage for delay prediction through transfer learning. This approach enhances the generalization of delay prediction model, requiring less data and delivering strong performance even in small-scale designs.
- We represent the circuit as a graph by parsing gate-level netlists, and use GNN to aggregate neighboring nodes in order to obtain the circuit’s topology information. We also expand the cells in the critical path to include two-hop neighboring nodes, generating a new subgraph to capture local delay influences.
- In terms of features, we introduce Look-Up Tables (LUTs) from the standard cell library to better align with STA calculation methods. We also represent the complex wire delay using the number of vias and the length on each metal layer, which enhances the accuracy of the model.
2. Related Work
3. Methods
3.1. Graph Neural Networks
3.2. Feature Engineering Originating from Design Files
3.2.1. Hierarchical Netlist-to-Graph Transformation
| Algorithm 1 Netlist parsing |
|
3.2.2. Feature Extraction on Standard Cell Library
3.3. The Framework of TSTL-GNN
4. Experiment
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.2. Path Delay Prediction Performance under Self-Referencing Scenario
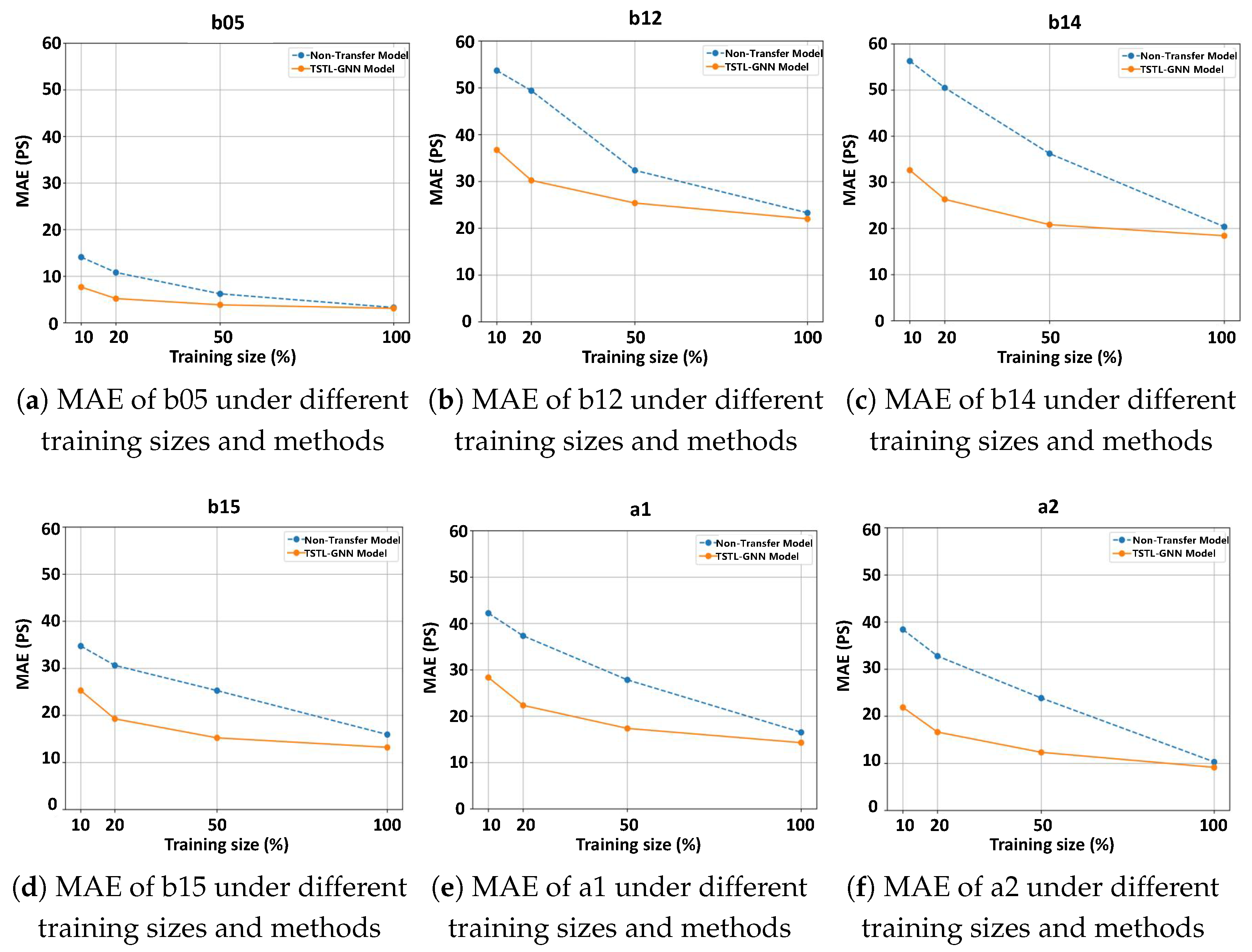
4.3. Path Delay Prediction Performance with Limited Data
4.4. Path Delay Prediction for ECO in Typical Engineering Scenarios
- Compared to the prediction model without introducing transition time, the TSTL-GNN model has a significant improvement in scores for the second-stage prediction based on transfer learning, as it first performs a primary prediction for important features.
- For the netlists after different ECO operations, an average of 24.27% of paths have changed. The average prediction error of the TSTL-GNN model is 11.89 ps, which is better than traditional GNN methods. The stable score confirms our model’s good generalization. Meanwhile, compared to previous work, our model’s average prediction error has decreased by 37.1 ps after various ECO modifications.
4.5. Time Overhead of Path Delay Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ho, K.H.; Jiang, J.H.R.; Chang, Y.W. TRECO: Dynamic technology remapping for timing engineering change orders. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2012, 31, 1723–1733. [Google Scholar]
- Huang, K.; Xiao, C.; Glass, L.M.; Zitnik, M.; Sun, J. SkipGNN: Predicting molecular interactions with skip-graph networks. Sci. Rep. 2020, 10, 21092. [Google Scholar] [CrossRef] [PubMed]
- Yu, Y.; Qian, W.; Zhang, L.; Gao, R. A graph-neural-network-based social network recommendation algorithm using high-order neighbor information. Sensors 2022, 22, 7122. [Google Scholar] [CrossRef] [PubMed]
- Davies, A.; Ajmeri, N. Realistic Synthetic Social Networks with Graph Neural Networks. arXiv 2022, arXiv:2212.07843. [Google Scholar]
- Jiang, W.; Luo, J. Graph neural network for traffic forecasting: A survey. Expert Syst. Appl. 2022, 207, 117921. [Google Scholar] [CrossRef]
- Tong, V.; Nguyen, D.Q.; Phung, D.; Nguyen, D.Q. Two-view graph neural networks for knowledge graph completion. In Proceedings of the European Semantic Web Conference, Crete, Greece, 28 May–1 June 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 262–278. [Google Scholar]
- Guo, Z.; Liu, M.; Gu, J.; Zhang, S.; Pan, D.Z.; Lin, Y. A Timing Engine Inspired Graph Neural Network Model for Pre-Routing Slack Prediction. In Proceedings of the 59th ACM/IEEE Design Automation Conference, DAC ’22, New York, NY, USA, 10–14 July 2022; pp. 1207–1212. [Google Scholar] [CrossRef]
- Zhao, G.; Shamsi, K. Graph neural network based netlist operator detection under circuit rewriting. In Proceedings of the Great Lakes Symposium on VLSI 2022, Irvine, CA, USA, 6–8 June 2022; pp. 53–58. [Google Scholar]
- Manu, D.; Huang, S.; Ding, C.; Yang, L. Co-exploration of graph neural network and network-on-chip design using automl. In Proceedings of the 2021 on Great Lakes Symposium on VLSI, Virtual, 22–25 June 2021; pp. 175–180. [Google Scholar]
- Morsali, M.; Nazzal, M.; Khreishah, A.; Angizi, S. IMA-GNN: In-Memory Acceleration of Centralized and Decentralized Graph Neural Networks at the Edge. In Proceedings of the Great Lakes Symposium on VLSI 2023, Knoxville, TN, USA, 5–7 June 2023; pp. 3–8. [Google Scholar]
- Lopera, D.S.; Servadei, L.; Kiprit, G.N.; Hazra, S.; Wille, R.; Ecker, W. A survey of graph neural networks for electronic design automation. In Proceedings of the 2021 ACM/IEEE 3rd Workshop on Machine Learning for CAD (MLCAD), Raleigh, NC, USA, 30 August–3 September 2021; pp. 1–6. [Google Scholar]
- Ren, H.; Nath, S.; Zhang, Y.; Chen, H.; Liu, M. Why are Graph Neural Networks Effective for EDA Problems? In Proceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design, San Diego, CA, USA, 30 October 2022–3 November 2022; pp. 1–8. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Wu, Z.; Savidis, I. Transfer Learning for Reuse of Analog Circuit Sizing Models Across Technology Nodes. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022. [Google Scholar] [CrossRef]
- Chai, Z.; Zhao, Y.; Liu, W.; Lin, Y.; Wang, R.; Huang, R. CircuitNet: An Open-Source Dataset for Machine Learning in VLSI CAD Applications with Improved Domain-Specific Evaluation Metric and Learning Strategies. IEEE Trans. Comput. -Aided Des. Integr. Circuits Syst. 2023, 42, 5034–5047. [Google Scholar] [CrossRef]
- Murray, K.E.; Betz, V. Tatum: Parallel Timing Analysis for Faster Design Cycles and Improved Optimization. In Proceedings of the 2018 International Conference on Field-Programmable Technology (FPT), Naha, Japan, 10–14 December 2018. [Google Scholar]
- Yuasa, H.; Tsutsui, H.; Ochi, H.; Sato, T. Parallel Acceleration Scheme for Monte Carlo Based SSTA Using Generalized STA Processing Element. IEICE Trans. Electron. 2013, 96, 473–481. [Google Scholar] [CrossRef]
- Huang, T.W.; Guo, G.; Lin, C.X.; Wong, M.D. OpenTimer v2: A New Parallel Incremental Timing Analysis Engine. IEEE Trans. Comput. -Aided Des. Integr. Circuits Syst. 2021, 40, 776–789. [Google Scholar] [CrossRef]
- Guo, G.; Huang, T.W.; Wong, M. Fast STA Graph Partitioning Framework for Multi-GPU Acceleration. In Proceedings of the 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 17–19 April 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Guo, G.; Huang, T.W.; Lin, Y.; Guo, Z. A GPU-accelerated Framework for Path-based Timing Analysis. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 4219–4232. [Google Scholar] [CrossRef]
- Han, A.; Zhao, Z.; Feng, C.; Zhang, S. Stage-Based Path Delay Prediction with Customized Machine Learning Technique. In Proceedings of the 2021 5th International Conference on Electronic Information Technology and Computer Engineering, EITCE ’21, New York, NY, USA, 22–24 October 2022; pp. 926–933. [Google Scholar] [CrossRef]
- Barboza, E.C.; Shukla, N.; Chen, Y.; Hu, J. Machine Learning-Based Pre-Routing Timing Prediction with Reduced Pessimism. In Proceedings of the the 56th Annual Design Automation Conference, Las Vegas, NV, USA, 2–6 June 2019. [Google Scholar]
- Bian, S.; Shintani, M.; Hiromoto, M.; Sato, T. LSTA: Learning-Based Static Timing Analysis for High-Dimensional Correlated On-Chip Variations. In Proceedings of the Design Automation Conference, Austin, TX, USA, 18–22 June 2017. [Google Scholar]
- Lopera, D.S.; Ecker, W. Applying GNNs to Timing Estimation at RTL. In Proceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design, San Diego, CA, USA, 30 October–3 November 2022; pp. 1–8. [Google Scholar]
- Alrahis, L.; Knechtel, J.; Klemme, F.; Amrouch, H.; Sinanoglu, O. GNN4REL: Graph Neural Networks for Predicting Circuit Reliability Degradation. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 41, 3826–3837. [Google Scholar] [CrossRef]
- Yang, T.; He, G.; Cao, P. Pre-Routing Path Delay Estimation Based on Transformer and Residual Framework. In Proceedings of the 27th Asia and South Pacific Design Automation Conference (ASP-DAC), Taipei, Taiwan, 17 January 2022. [Google Scholar]
- Guo, Z.; Lin, Y. Differentiable-Timing-Driven Global Placement. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022. [Google Scholar]
- Corno, F.; Reorda, M.S.; Squillero, G. RT-level ITC’99 benchmarks and first ATPG results. IEEE Des. Test Comput. 2000, 17, 44–53. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Feature | Description | Dimension | Ownership |
|---|---|---|---|---|
| Netlist | PI | Whether it is an Input port | 1 | Inpin_Node |
| PO | Whether it is an Output port | 1 | Outpin_Node | |
| Standard Cell Library | Driving | Driving Strength | 4 | Cell_Edge |
| In_degree | Number of Cell Input Pins | 1 | Inpin_Node | |
| Out_degree | Number of Cell Output Pins | 1 | Outpin_Node | |
| Load_cap | Sum of Cell Load Capacitance | 1 | Outpin_Node | |
| LUT_transition | LUT of Transition | 80 | Cell_Edge | |
| LUT_delay | LUT of Delay | 80 | Cell_Edge | |
| DEF File | Wire_length | Total length of wire on each metal layer | 6 | Net_Edge |
| Via_numbers | Total numbers of vias | 6 | Net_Edge | |
| SDC File | In_transition | Input Transition Time of Path | 1 | Inpin_Node |
| First-stage Prediction | In_cell_transition | Input Transition Time of the Cell | 1 | Inpin_Node |
| Benchmark | Cell | Wire | Cell Type | STA Path | |
|---|---|---|---|---|---|
| Open-Source | b05 | 318 | 302 | 44 | 101,956 |
| b12 | 613 | 616 | 47 | 15,552 | |
| b14 | 2044 | 2049 | 148 | 183,778 | |
| b15 | 3183 | 3290 | 140 | 39,240 | |
| Industrial-Level | a1 | 28,051 | 28,141 | 290 | 1M+ |
| a2 | 63,289 | 61,176 | 307 | 1M+ | |
| b05 | ECO1_b05 | ECO2_b05 | ECO3_b05 | ECO4_b05 | ECO5_b05 | Average | ||
|---|---|---|---|---|---|---|---|---|
| ECO | - | Size cell | Size cell | Insert buffer | Insert buffer | Size cell+Insert buffer | - | |
| POPC | - | 5.32% | 32.64% | 10.79% | 20.17% | 52.43% | 24.27% | |
| GCN | 0.7308 | 0.5242 | 0.3658 | 0.5575 | 0.2675 | 0.0891 | 0.3608 | |
| MAE | 51.37 | 128.45 | 199.82 | 106.81 | 258.63 | 576.81 | 254.10 | |
| GAT | 0.6482 | 0.4765 | 0.4298 | 0.4367 | 0.2367 | 0.1067 | 0.3373 | |
| MAE | 65.13 | 136.79 | 187.62 | 119.20 | 309.58 | 489.28 | 248.49 | |
| GraphSAGE | 0.9066 | 0.6612 | 0.5612 | 0.6941 | 0.4816 | 0.4014 | 0.5599 | |
| MAE | 9.41 | 65.34 | 92.78 | 60.31 | 115.97 | 147.97 | 96.47 | |
| GNN4REL | 0.9618 | 0.8628 | 0.7651 | 0.8475 | 0.6542 | 0.5014 | 0.7262 | |
| MAE | 14.7 | 25.43 | 41.89 | 34.12 | 54.76 | 88.76 | 48.99 | |
| TSTL-GNN | 0.9992 | 0.9362 | 0.9132 | 0.9593 | 0.9342 | 0.8985 | 0.9282 | |
| MAE | 3.11 | 6.38 | 14.12 | 5.62 | 12.64 | 20.69 | 11.89 | |
| Benchmark | Runtime (s) | ||||
|---|---|---|---|---|---|
| Stage1 | Stage2 | Total | STA | Speedup | |
| b05 | 3.6 | 2.2 | 5.8 | 38.6 | 6.66x |
| b12 | 4.2 | 2.6 | 6.8 | 52.8 | 7.76x |
| b14 | 4.4 | 2.8 | 7.2 | 92.9 | 12.9x |
| b15 | 5.5 | 3.1 | 8.6 | 121.7 | 14.15x |
| a1 | 12.9 | 8.5 | 21.4 | 1721.9 | 80.46x |
| a2 | 17.4 | 14.7 | 32.1 | 2460.7 | 76.65x |
| Average | 8.0 | 5.7 | 13.7 | 748.1 | 54.61x |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, W.; Zhao, Z.; Luo, Z.; Zhou, J.; Zhang, S.; Hu, B.; Bian, P. TSTL-GNN: Graph-Based Two-Stage Transfer Learning for Timing Engineering Change Order Analysis Acceleration. Electronics 2024, 13, 2897. https://doi.org/10.3390/electronics13152897
Jiang W, Zhao Z, Luo Z, Zhou J, Zhang S, Hu B, Bian P. TSTL-GNN: Graph-Based Two-Stage Transfer Learning for Timing Engineering Change Order Analysis Acceleration. Electronics. 2024; 13(15):2897. https://doi.org/10.3390/electronics13152897
Chicago/Turabian StyleJiang, Wencheng, Zhenyu Zhao, Zhiyuan Luo, Jie Zhou, Shuzheng Zhang, Bo Hu, and Peiyun Bian. 2024. "TSTL-GNN: Graph-Based Two-Stage Transfer Learning for Timing Engineering Change Order Analysis Acceleration" Electronics 13, no. 15: 2897. https://doi.org/10.3390/electronics13152897
APA StyleJiang, W., Zhao, Z., Luo, Z., Zhou, J., Zhang, S., Hu, B., & Bian, P. (2024). TSTL-GNN: Graph-Based Two-Stage Transfer Learning for Timing Engineering Change Order Analysis Acceleration. Electronics, 13(15), 2897. https://doi.org/10.3390/electronics13152897