
Security-Aware Task Offloading Using Deep Reinforcement Learning in Mobile Edge Computing Systems


Abstract
1. Introduction
- Task Offloading for MEC Systems: We undertake a thorough investigation of task offloading within MEC systems, focusing on the security aspects of data transmission between servers and mobile devices.
- DRL-based Task-Offloading Algorithm: We model system utility as a Markov Decision Process (MDP) and introduce a novel task-offloading algorithm using a DRL approach. This algorithm dynamically learns and adapts to the MEC environment to optimize task-offloading decisions.
- Performance Evaluation: Our results indicate that our proposal significantly outperforms traditional methods in minimizing task execution latency and energy consumption while maintaining high levels of data security.
2. Related Work
2.1. Task Offloading in MEC
2.2. Security-Aware Task Offloading in MEC
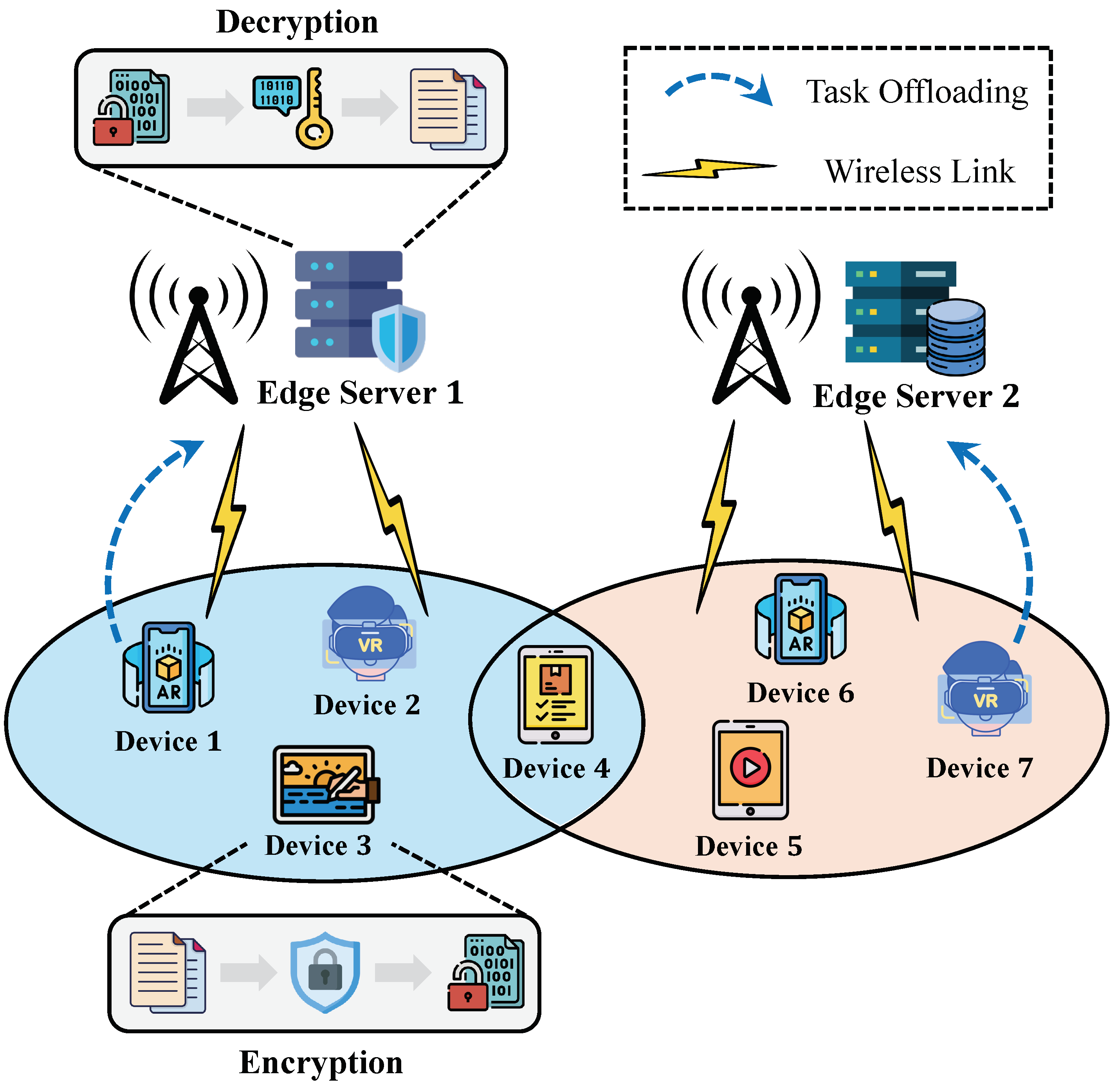
3. System Model and Problem Formulation
3.1. Communication Model
3.2. Security Model
3.3. Computing Model
3.3.1. Mobile Device Computing
3.3.2. Edge Server Computing
3.4. Problem Formulation
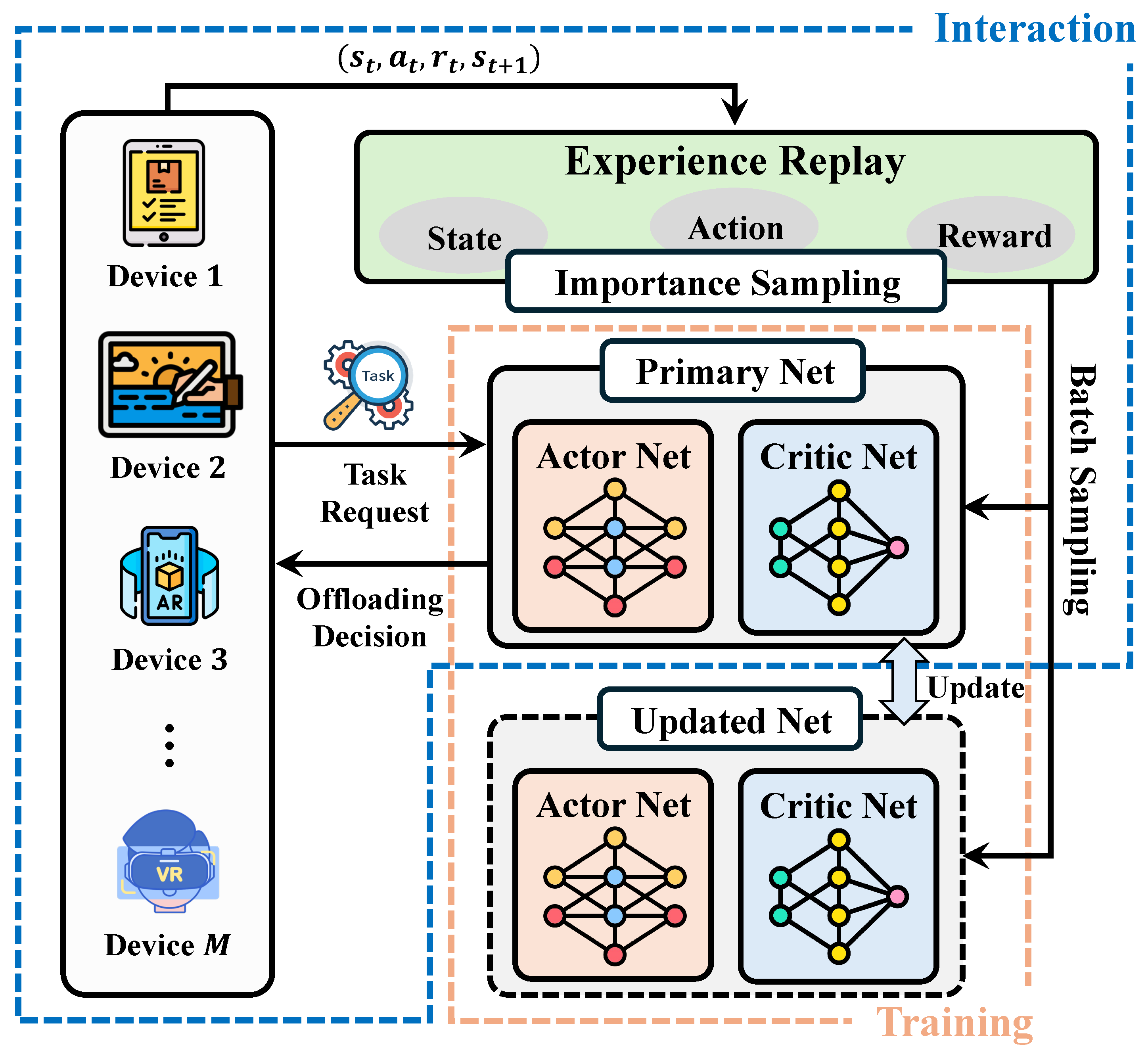
4. DRL-Based Offloading Algorithm
4.1. MDP Formulation
4.2. Preliminaries of DRL
4.3. Complexity Analysis
4.4. Task Offloading Using PPO
| Algorithm 1 DRL-based task offloading. |
|
| Algorithm 2 Data collection for DRL-based task offloading. |
|
5. Performance Evaluation
5.1. Experiment Settings
- Local Execution: All tasks are executed locally on the device without offloading or data transmission, i.e., .
- Full Offloading: All tasks are offloaded to edge servers for execution, i.e., .
- Offloading based on DQN without security (DQN-WS): This approach utilizes the DQN algorithm for task offloading but does not incorporate security measures for data transmission.
- Offloading based on DQN with security (DQN-S): Similar to DQN-WS, this method employs the DQN algorithm but includes task encryption to secure data transmission.
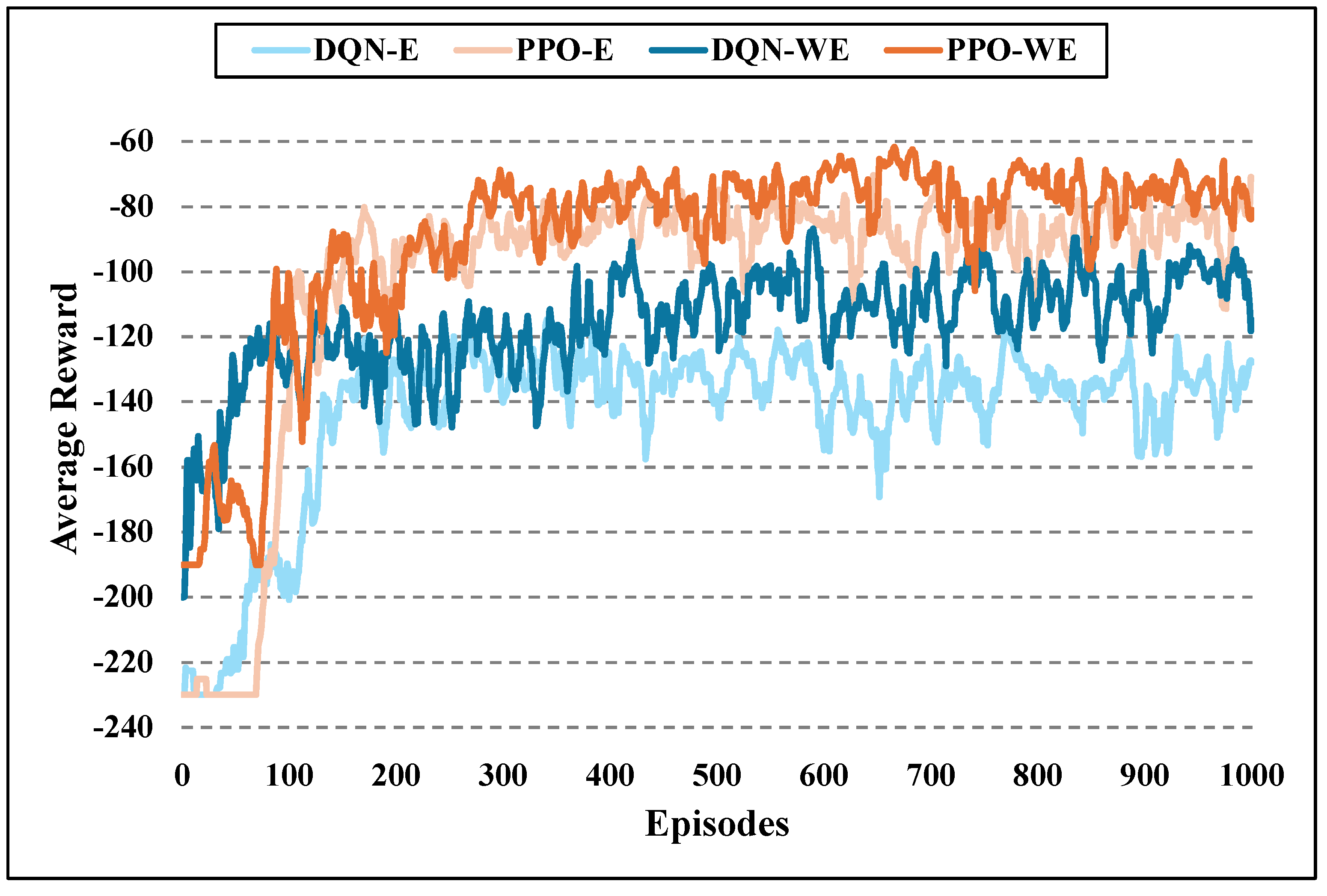
5.2. Algorithm Convergence Comparison
5.3. Average System Performance Analysis
5.4. Impact of Number of Edge Servers
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Number of mobile devices. | |
| Number of edge servers. | |
| Time slots in each episode. | |
| Length of each time slot. | |
| Connectivity status between mobile device m and edge server n at time t. | |
| Channel bandwidth between mobile device m and edge server n. | |
| Channel gain between mobile device and edge server. | |
| Uplink transmission power of mobile device m. | |
| Signal-to-Interference-plus-Noise Ratio (SINR) in wireless link. | |
| Computational task request at time t for mobile device m. | |
| Data size of offloading task at time t for mobile device m. | |
| CPU cycles required for the task requested by mobile device m at time t. | |
| Execution deadline for task requested by mobile device m at time t. | |
| CPU frequency of mobile device m. | |
| CPU frequency of edge server n. | |
| Energy consumption per CPU cycle for mobile device m. | |
| CPU cycles required to encrypt the data. | |
| CPU cycles required to decrypt the data. | |
| Binary indicator of execution. |
References
- Wu, Q.; Chen, X.; Zhou, Z.; Chen, L. Mobile Social Data Learning for User-Centric Location Prediction with Application in Mobile Edge Service Migration. IEEE Internet Things J. 2019, 6, 7737–7747. [Google Scholar] [CrossRef]
- Yin, X.; Liu, X. Multi-Task Convolutional Neural Network for Pose-Invariant Face Recognition. IEEE Trans. Image Process. 2018, 27, 964–975. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y.; Hou, J.; Huang, X.; Shao, Z.; Yang, Y. Green Edge Intelligence Scheme for Mobile Keyboard Emoji Prediction. IEEE Trans. Mob. Comput. 2024, 23, 1888–1901. [Google Scholar] [CrossRef]
- Wang, J.; Du, H.; Niyato, D.; Kang, J.; Xiong, Z.; Rajan, D.; Mao, S.; Shen, X. A Unified Framework for Guiding Generative AI with Wireless Perception in Resource Constrained Mobile Edge Networks. IEEE Trans. Mob. Comput. 2024. [Google Scholar] [CrossRef]
- Wang, J.; Du, H.; Niyato, D.; Xiong, Z.; Kang, J.; Mao, S.; Shen, X.S. Guiding AI-Generated Digital Content with Wireless Perception. IEEE Wirel. Commun. 2024. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Commun. Surv. Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Xu, D.; Su, X.; Wang, H.; Tarkoma, S.; Hui, P. Towards Risk-Averse Edge Computing with Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2024, 23, 7030–7047. [Google Scholar] [CrossRef]
- Ding, Z.; Xu, J.; Dobre, O.A.; Poor, H.V. Joint Power and Time Allocation for NOMA–MEC Offloading. IEEE Trans. Veh. Technol. 2019, 68, 6207–6211. [Google Scholar] [CrossRef]
- Bi, S.; Zhang, Y.J. Computation Rate Maximization for Wireless Powered Mobile-Edge Computing with Binary Computation Offloading. IEEE Trans. Wirel. Commun. 2018, 17, 4177–4190. [Google Scholar] [CrossRef]
- Shirazi, S.N.; Gouglidis, A.; Farshad, A.; Hutchison, D. The Extended Cloud: Review and Analysis of Mobile Edge Computing and Fog from a Security and Resilience Perspective. IEEE J. Sel. Areas Commun. 2017, 35, 2586–2595. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, C.; Lian, Y.; Tian, H.; Kang, J.; Kuang, X.; Niyato, D. When Moving Target Defense Meets Attack Prediction in Digital Twins: A Convolutional and Hierarchical Reinforcement Learning Approach. IEEE J. Sel. Areas Commun. 2023, 41, 3293–3305. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, C.; Shen, J.; Kuang, X.; Grieco, L.A. How to Disturb Network Reconnaissance: A Moving Target Defense Approach Based on Deep Reinforcement Learning. IEEE Trans. Inf. Forensics Secur. 2023, 18, 5735–5748. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, C.; Zou, P.; Tian, H.; Kuang, X.; Yang, S.; Zhong, L.; Niyato, D. How to Mitigate DDoS Intelligently in SD-IoV: A Moving Target Defense Approach. IEEE Trans. Ind. Inform. 2023, 19, 1097–1106. [Google Scholar] [CrossRef]
- Ranaweera, P.; Yadav, A.K.; Liyanage, M.; Jurcut, A.D. Service Migration Authentication Protocol for MEC. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Rio de Janeiro, Brazil, 4–8 December 2022; pp. 5493–5498. [Google Scholar]
- Singh, J.; Bello, Y.; Hussein, A.R.; Erbad, A.; Mohamed, A. Hierarchical Security Paradigm for IoT Multiaccess Edge Computing. IEEE Internet Things J. 2021, 8, 5794–5805. [Google Scholar] [CrossRef]
- Feng, S.; Xiong, Z.; Niyato, D.; Wang, P. Dynamic Resource Management to Defend Against Advanced Persistent Threats in Fog Computing: A Game Theoretic Approach. IEEE Trans. Cloud Comput. 2021, 9, 995–1007. [Google Scholar] [CrossRef]
- Liu, Y.; Du, H.; Niyato, D.; Kang, J.; Xiong, Z.; Jamalipour, A.; Shen, X. ProSecutor: Protecting Mobile AIGC Services on Two-Layer Blockchain via Reputation and Contract Theoretic Approaches. IEEE Trans. Mob. Comput. 2024. [Google Scholar] [CrossRef]
- Eshraghi, N.; Liang, B. Joint Offloading Decision and Resource Allocation with Uncertain Task Computing Requirement. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 1414–1422. [Google Scholar]
- Lyu, X.; Tian, H.; Ni, W.; Zhang, Y.; Zhang, P.; Liu, R.P. Energy-Efficient Admission of Delay-Sensitive Tasks for Mobile Edge Computing. IEEE Trans. Commun. 2018, 66, 2603–2616. [Google Scholar] [CrossRef]
- Tang, M.; Wong, V.W. Deep Reinforcement Learning for Task Offloading in Mobile Edge Computing Systems. IEEE Trans. Mob. Comput. 2022, 21, 1985–1997. [Google Scholar] [CrossRef]
- Wang, X.; Ye, J.; Lui, J.C. Online Learning Aided Decentralized Multi-User Task Offloading for Mobile Edge Computing. IEEE Trans. Mob. Comput. 2024, 23, 3328–3342. [Google Scholar] [CrossRef]
- Liu, J.; Ren, J.; Zhang, Y.; Peng, X.; Zhang, Y.; Yang, Y. Efficient Dependent Task Offloading for Multiple Applications in MEC-Cloud System. IEEE Trans. Mob. Comput. 2023, 22, 2147–2162. [Google Scholar] [CrossRef]
- Wang, P.; Li, K.; Xiao, B.; Li, K. Multiobjective Optimization for Joint Task Offloading, Power Assignment, and Resource Allocation in Mobile Edge Computing. IEEE Internet Things J. 2022, 9, 11737–11748. [Google Scholar] [CrossRef]
- Fang, J.; Qu, D.; Chen, H.; Liu, Y. Dependency-Aware Dynamic Task Offloading Based on Deep Reinforcement Learning in Mobile-Edge Computing. IEEE Trans. Netw. Serv. Manag. 2024, 21, 1403–1415. [Google Scholar] [CrossRef]
- Tan, L.; Kuang, Z.; Zhao, L.; Liu, A. Energy-Efficient Joint Task Offloading and Resource Allocation in OFDMA-Based Collaborative Edge Computing. IEEE Trans. Wirel. Commun. 2022, 21, 1960–1972. [Google Scholar] [CrossRef]
- Wang, J.; Du, H.; Tian, Z.; Niyato, D.; Kang, J.; Shen, X. Semantic-Aware Sensing Information Transmission for Metaverse: A Contest Theoretic Approach. IEEE Trans. Wirel. Commun. 2023, 22, 5214–5228. [Google Scholar] [CrossRef]
- Samy, A.; Elgendy, I.A.; Yu, H.; Zhang, W.; Zhang, H. Secure Task Offloading in Blockchain-Enabled Mobile Edge Computing with Deep Reinforcement Learning. IEEE Trans. Netw. Serv. Manag. 2022, 19, 4872–4887. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.; Tian, Y.C.; Li, K. Resource allocation and computation offloading with data security for mobile edge computing. Future Gener. Comput. Syst. 2019, 100, 531–541. [Google Scholar] [CrossRef]
- Wu, M.; Song, Q.; Guo, L.; Lee, I. Energy-Efficient Secure Computation Offloading in Wireless Powered Mobile Edge Computing Systems. IEEE Trans. Veh. Technol. 2023, 72, 6907–6912. [Google Scholar] [CrossRef]
- Asheralieva, A.; Niyato, D. Fast and Secure Computational Offloading with Lagrange Coded Mobile Edge Computing. IEEE Trans. Veh. Technol. 2021, 70, 4924–4942. [Google Scholar] [CrossRef]
- Li, Y.; Aghvami, A.H.; Dong, D. Intelligent Trajectory Planning in UAV-Mounted Wireless Networks: A Quantum-Inspired Reinforcement Learning Perspective. IEEE Wirel. Commun. Lett. 2021, 10, 1994–1998. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, K.; Lin, Y.; Xu, W. LightChain: A Lightweight Blockchain System for Industrial Internet of Things. IEEE Trans. Ind. Inform. 2019, 15, 3571–3581. [Google Scholar] [CrossRef]
- Gao, Z.; Yang, L.; Dai, Y. Fast Adaptive Task Offloading and Resource Allocation in Large-Scale MEC Systems via Multiagent Graph Reinforcement Learning. IEEE Internet Things J. 2024, 11, 758–776. [Google Scholar] [CrossRef]
- Peng, K.; Xiao, P.; Wang, S.; Leung, V.C. SCOF: Security-Aware Computation Offloading Using Federated Reinforcement Learning in Industrial Internet of Things with Edge Computing. IEEE Trans. Serv. Comput. 2024. [Google Scholar] [CrossRef]
- Zhang, W.Z.; Elgendy, I.A.; Hammad, M.; Iliyasu, A.M.; Du, X.; Guizani, M.; El-Latif, A.A.A. Secure and Optimized Load Balancing for Multitier IoT and Edge-Cloud Computing Systems. IEEE Internet Things J. 2021, 8, 8119–8132. [Google Scholar] [CrossRef]
- Zhan, Y.; Li, P.; Wu, L.; Guo, S. L4L: Experience-Driven Computational Resource Control in Federated Learning. IEEE Trans. Comput. 2022, 71, 971–983. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In Advances in Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Samir, M.; Assi, C.; Sharafeddine, S.; Ghrayeb, A. Online Altitude Control and Scheduling Policy for Minimizing AoI in UAV-Assisted IoT Wireless Networks. IEEE Trans. Mob. Comput. 2022, 21, 2493–2505. [Google Scholar] [CrossRef]
- Lu, H.; He, X.; Du, M.; Ruan, X.; Sun, Y.; Wang, K. Edge QoE: Computation Offloading with Deep Reinforcement Learning for Internet of Things. IEEE Internet Things J. 2020, 7, 9255–9265. [Google Scholar] [CrossRef]
- Li, Y.; Aghvami, A.H.; Dong, D. Path Planning for Cellular-Connected UAV: A DRL Solution with Quantum-Inspired Experience Replay. IEEE Trans. Wirel. Commun. 2022, 21, 7897–7912. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Optimization | DRL-Based | Security | No. of Servers |
|---|---|---|---|---|
| [18] | Latency and energy | No | No | Single Server |
| [19] | Energy | No | No | Single Server |
| [20] | Latency | Yes | No | Multiple Servers |
| [21] | Latency | Yes | No | Multiple Servers |
| [22] | Latency | No | No | Multiple Servers |
| [23] | Latency and energy | No | No | Multiple Servers |
| [24] | Latency and energy | Yes | No | Single Server |
| [25] | Energy | Yes | No | Single Server |
| [27] | Latency and energy | Yes | Yes | Single Server |
| [28] | Latency and energy | No | Yes | Single Server |
| [29] | Energy | No | Yes | Single Server |
| [30] | Latency | Yes | Yes | Single Server |
| Our Work | Latency and energy | Yes | Yes | Multiple Servers |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| Number of mobile devices | 30 | Number of edge servers | 4 |
| Task data size | {5, 10, 15, …, 30} MB | System bandwidth | 15 MHz |
| Background noise | −100 dBm | Computation capacity of device | {0.2, 0.4, 0.6, …, 1.4} GHz |
| MEC server capacity | 10 GHz | Transmission power of device | 250 mW |
| Communication bandwidth | 2 MHz | Carrier frequency | 915 MHz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; He, X.; Zhang, D. Security-Aware Task Offloading Using Deep Reinforcement Learning in Mobile Edge Computing Systems. Electronics 2024, 13, 2933. https://doi.org/10.3390/electronics13152933
Lu H, He X, Zhang D. Security-Aware Task Offloading Using Deep Reinforcement Learning in Mobile Edge Computing Systems. Electronics. 2024; 13(15):2933. https://doi.org/10.3390/electronics13152933
Chicago/Turabian StyleLu, Haodong, Xiaoming He, and Dengyin Zhang. 2024. "Security-Aware Task Offloading Using Deep Reinforcement Learning in Mobile Edge Computing Systems" Electronics 13, no. 15: 2933. https://doi.org/10.3390/electronics13152933
APA StyleLu, H., He, X., & Zhang, D. (2024). Security-Aware Task Offloading Using Deep Reinforcement Learning in Mobile Edge Computing Systems. Electronics, 13(15), 2933. https://doi.org/10.3390/electronics13152933