
Computation Offloading Strategy for Detection Task in Railway IoT with Integrated Sensing, Storage, and Computing


Abstract
1. Introduction
1.1. Background
1.2. Related Work and Contribution
- To better accommodate detection devices deployed in different locations and environments in various types of railways, we proposed two transmission models, namely the direct transmission model and the relay transmission model. Furthermore, in the OFDM system, we introduced NOMA technology to increase channel capacity.
- Taking into account the limitation of computing resources and memory capacity, we allocated computing resources through server selection, combined with the order of arrival, while also ensuring that the task queue pending for each server does not exceed its memory capacity.
- We proposed an improved DDPG algorithm combined with a low-complexity subcarrier allocation algorithm to solve the optimization problem of communication and computing resource allocation.
2. System Model and Problem Formulation
2.1. System Model
2.2. Direct Transmission Model
2.3. Relay Transmission Model
2.4. NOMA-Based Transmission Model
2.5. Transmission Delay
2.6. Computing Delay
2.7. Problem Formulation
3. DDPG-Based Resource Allocation Algorithm
3.1. Subcarrier Allocation Algorithm
| Algorithm 1: Subcarrier Allocation Algorithm |
| Input: |
| Output: |
|
|
|
|
|
3.2. MDP Model
3.3. Improved Deep Deterministic Policy Gradient Algorithm
| Algorithm 2: The Training Process of DDPG Algorithm |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4. Simulation Results and Discussion
4.1. Simulation Setting
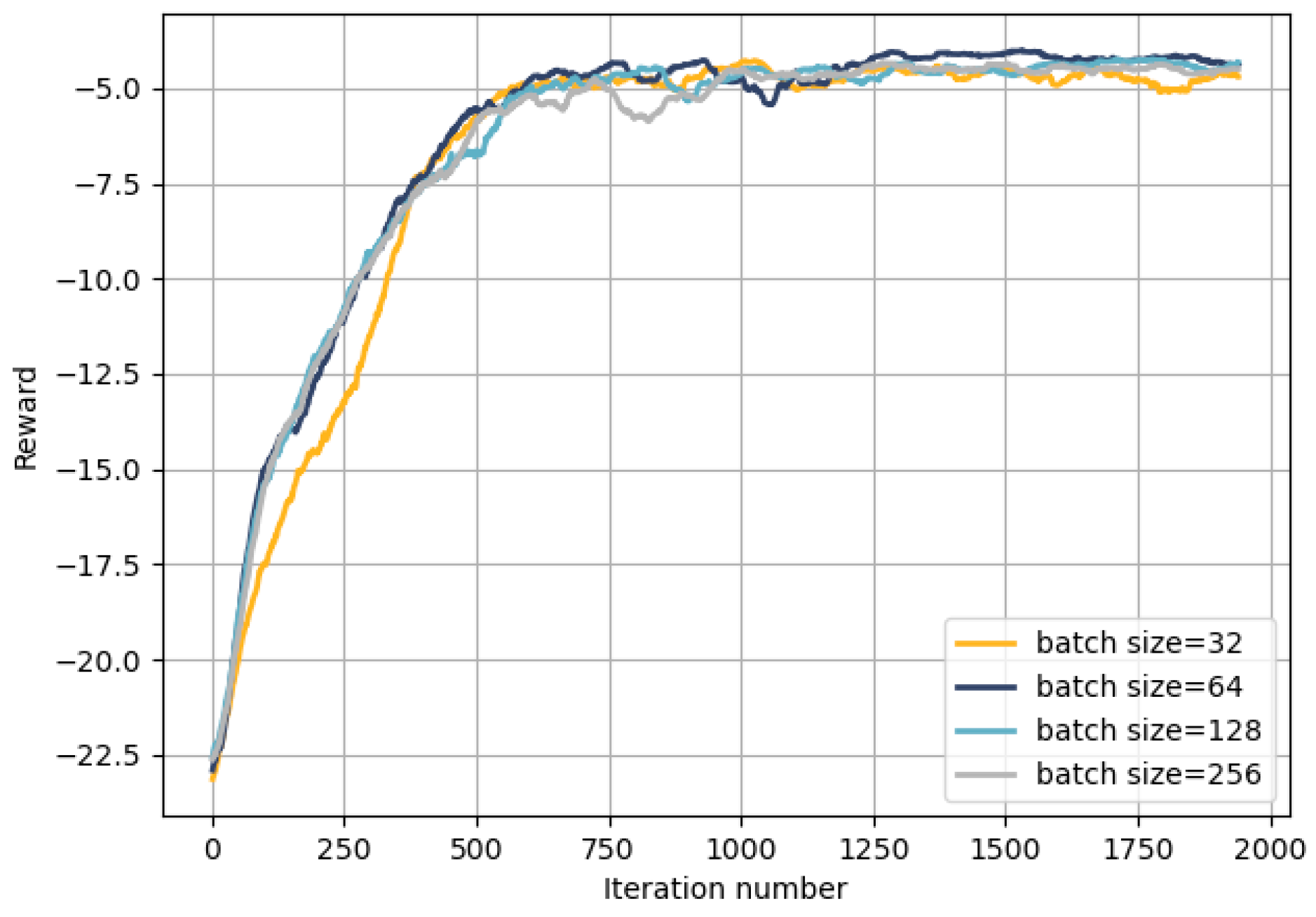
4.2. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, J. Maintenance Scheduling at High-Speed Train Depots: An Optimization Approach. Reliab. Eng. Syst. Saf. 2024, 243, 109809. [Google Scholar] [CrossRef]
- Yang, N.; Chen, M. Design and Application of Big Data Technology Management for the Analysis System of High Speed Railway Operation Safety Rules. In Proceedings of the 2023 IEEE International Conference on Integrated Circuits and Communication Systems (ICICACS), Raichur, India, 24–25 February 2023; pp. 1–6. [Google Scholar]
- Sobhy, H.; Zohny, H.N.; Elhabiby, M. Railway Inspection Using Non-Contact Non-Destructive Techniques. Int. J. Eng. Appl. Sci. (IJEAS) 2020, 7. [Google Scholar] [CrossRef]
- Singh, P.; Elmi, Z.; Krishna Meriga, V.; Pasha, J.; Dulebenets, M.A. Internet of Things for Sustainable Railway Transportation: Past, Present, and Future. Clean. Logist. Supply Chain 2022, 4, 100065. [Google Scholar] [CrossRef]
- Xu, J.; Ai, B.; Chen, L.; Cui, Y.; Wang, N. Deep Reinforcement Learning for Computation and Communication Resource Allocation in Multiaccess MEC Assisted Railway IoT Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23797–23808. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, S.; Ren, X.; Zhao, P.; Zhao, C.; Yang, X. IndustEdge: A Time-Sensitive Networking Enabled Edge-Cloud Collaborative Intelligent Platform for Smart Industry. IEEE Trans. Ind. Inform. 2022, 18, 2386–2398. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, L.; Wu, J.; Wang, H.; Yu, F.R. Computation Resource Optimization for Large-Scale Intelligent Urban Rail Transit: A Mean-Field Game Approach. IEEE Trans. Veh. Technol. 2023, 72, 9868–9879. [Google Scholar] [CrossRef]
- Xu, J.; Wei, Z.; Yuan, X.; Qiao, Y.; Lyu, Z.; Han, J. Throughput Maximization for Result Multicasting by Admitting Delay-Aware Tasks in MEC Networks for High-Speed Railways. IEEE Trans. Veh. Technol. 2024, 73, 8765–8781. [Google Scholar] [CrossRef]
- Khan, K.; Pasricha, S.; Kim, R.G. A Survey of Resource Management for Processing-In-Memory and Near-Memory Processing Architectures. J. Low Power Electron. Appl. 2020, 10, 30. [Google Scholar] [CrossRef]
- Zhao, C.; Cai, Y.; Liu, A.; Zhao, M.; Hanzo, L. Mobile Edge Computing Meets mmWave Communications: Joint Beamforming and Resource Allocation for System Delay Minimization. IEEE Trans. Wirel. Commun. 2020, 19, 2382–2396. [Google Scholar] [CrossRef]
- Jiang, K.; Zhou, H.; Li, D.; Liu, X.; Xu, S. A Q-Learning Based Method for Energy-Efficient Computation Offloading in Mobile Edge Computing. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; pp. 1–7. [Google Scholar]
- Chen, X.; Liu, G. Energy-Efficient Task Offloading and Resource Allocation via Deep Reinforcement Learning for Augmented Reality in Mobile Edge Networks. IEEE Internet Things J. 2021, 8, 10843–10856. [Google Scholar] [CrossRef]
- Ale, L.; King, S.A.; Zhang, N.; Sattar, A.R.; Skandaraniyam, J. D3PG: Dirichlet DDPG for Task Partitioning and Offloading With Constrained Hybrid Action Space in Mobile-Edge Computing. IEEE Internet Things J. 2022, 9, 19260–19272. [Google Scholar] [CrossRef]
- Deng, X.; Yin, J.; Guan, P.; Xiong, N.N.; Zhang, L.; Mumtaz, S. Intelligent Delay-Aware Partial Computing Task Offloading for Multiuser Industrial Internet of Things Through Edge Computing. IEEE Internet Things J. 2023, 10, 2954–2966. [Google Scholar] [CrossRef]
- Li, L.; Niu, Y.; Mao, S.; Ai, B.; Zhong, Z.; Wang, N.; Chen, Y. Resource Allocation and Computation Offloading in a Millimeter-Wave Train-Ground Network. IEEE Trans. Veh. Technol. 2022, 71, 10615–10630. [Google Scholar] [CrossRef]
- Tian, L.; Li, M.; Si, P.; Yang, R.; Sun, Y.; Wang, Z. Design and Optimization in MEC-Based Intelligent Rail System by Integration of Distributed Multi-Hop Communication and Blockchain. Math. Probl. Eng. 2023, 2023, 8858263. [Google Scholar] [CrossRef]
- Xue, Q.; Wei, R.; Li, Z.; Liu, Y.; Xu, Y.; Chen, Q. Beamforming Design for Cooperative Double-RIS Aided mmWave MU-MIMO Communications. IEEE Trans. Green Commun. Netw. 2024; Early Access. [Google Scholar] [CrossRef]
- Xu, C.; Zheng, G.; Zhao, X. Energy-Minimization Task Offloading and Resource Allocation for Mobile Edge Computing in NOMA Heterogeneous Networks. IEEE Trans. Veh. Technol. 2020, 69, 16001–16016. [Google Scholar] [CrossRef]
- Du, J.; Sun, Y.; Zhang, N.; Xiong, Z.; Sun, A.; Ding, Z. Cost-Effective Task Offloading in NOMA-Enabled Vehicular Mobile Edge Computing. IEEE Syst. J. 2023, 17, 928–939. [Google Scholar] [CrossRef]
- Du, R.; Wang, J.; Gao, Y. Computing Offloading and Resource Scheduling Based on DDPG in Ultra-Dense Edge Computing Networks. J Supercomput. 2024, 80, 10275–10300. [Google Scholar] [CrossRef]
- Zhou, X.; Tian, Y.; Wang, X. MEC-DA: Memory-Efficient Collaborative Domain Adaptation for Mobile Edge Devices. IEEE Trans. Mob. Comput. 2024, 23, 3923–3937. [Google Scholar] [CrossRef]
- Wang, J.; Ge, M.; Ding, B.; Xu, Q.; Chen, S.; Kang, Y. NicePIM: Design Space Exploration for Processing-In-Memory DNN Accelerators With 3-D Stacked-DRAM. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 1456–1469. [Google Scholar] [CrossRef]
- Li, Y.; Cimini, L.J. Bounds on the Interchannel Interference of OFDM in Time-Varying Impairments. IEEE Trans. Commun. 2001, 49, 401–404. [Google Scholar] [CrossRef]
- Gao, M.; Ai, B.; Niu, Y.; Wu, W.; Yang, P.; Lyu, F.; Shen, X. Edge Caching and Content Delivery with Minimized Delay for Both High-Speed Train and Local Users. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]
- Jiao, B.; Liu, S.; Lei, Y.; Ma, M. A Networking Solution on Uplink Channel of Co-Frequency and Co-Time System. China Commun. 2016, 13, 183–188. [Google Scholar] [CrossRef]
- Wang, Y.; Niu, Y.; Wu, H.; Ai, B.; Zhong, Z.; Wu, D.O.; Juhana, T. Relay Assisted Concurrent Scheduling to Overcome Blockage in Full-Duplex Millimeter Wave Small Cells. IEEE Access 2019, 7, 105755–105767. [Google Scholar] [CrossRef]
- Xue, J.; An, Y. Joint Task Offloading and Resource Allocation for Multi-Task Multi-Server NOMA-MEC Networks. IEEE Access 2021, 9, 16152–16163. [Google Scholar] [CrossRef]
- Wildemeersch, M.; Quek, T.Q.S.; Kountouris, M.; Rabbachin, A.; Slump, C.H. Successive Interference Cancellation in Heterogeneous Networks. IEEE Trans. Commun. 2014, 62, 4440–4453. [Google Scholar] [CrossRef]
- Zhong, A.; Li, Z.; Wu, D.; Tang, T.; Wang, R. Stochastic Peak Age of Information Guarantee for Cooperative Sensing in Internet of Everything. IEEE Internet Things J. 2023, 10, 15186–15196. [Google Scholar] [CrossRef]
- Maudet, S.; Andrieux, G.; Chevillon, R.; Diouris, J.-F. Practical Evaluation of Wi-Fi HaLow Performance. Internet Things 2023, 24, 100957. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, M.; Li, M. Task Offloading Strategy and Scheduling Optimization for Internet of Vehicles Based on Deep Reinforcement Learning. Ad Hoc Netw. 2023, 147, 103193. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of subcarriers | 256 |
| Subcarrier bandwidth | 15 KHz |
| Carrier frequency | 3 GHz |
| Noise power | −130 dBm |
| Train speed | 300 km/h |
| Power of relay | 20 W |
| signal symbol duration [30]: | 4 µs |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Xu, Z.; Yuan, J.; Wei, Y. Computation Offloading Strategy for Detection Task in Railway IoT with Integrated Sensing, Storage, and Computing. Electronics 2024, 13, 2982. https://doi.org/10.3390/electronics13152982
Guo Q, Xu Z, Yuan J, Wei Y. Computation Offloading Strategy for Detection Task in Railway IoT with Integrated Sensing, Storage, and Computing. Electronics. 2024; 13(15):2982. https://doi.org/10.3390/electronics13152982
Chicago/Turabian StyleGuo, Qichang, Zhanyue Xu, Jiabin Yuan, and Yifei Wei. 2024. "Computation Offloading Strategy for Detection Task in Railway IoT with Integrated Sensing, Storage, and Computing" Electronics 13, no. 15: 2982. https://doi.org/10.3390/electronics13152982
APA StyleGuo, Q., Xu, Z., Yuan, J., & Wei, Y. (2024). Computation Offloading Strategy for Detection Task in Railway IoT with Integrated Sensing, Storage, and Computing. Electronics, 13(15), 2982. https://doi.org/10.3390/electronics13152982