
Efficient Sparse Bayesian Learning Model for Image Reconstruction Based on Laplacian Hierarchical Priors and GAMP


Abstract
1. Introduction
- (1)
- We propose an efficient sparse Bayesian learning model for image reconstruction based on Laplace hierarchical priors and GAMP. The GAMP structure is used to estimate the mean and variance in the E-step without matrix inversion. It outperforms several mainstream SBL image reconstruction models in terms of running time.
- (2)
- Sufficient damping factors are used to constrain the output to prevent the divergence of the GAMP during iterations.
- (3)
- In order to solve the problem that the prior distribution of the Gaussian mixture function in GAMP cannot fit a fat-tailed distribution well, we use the Laplace hierarchical prior (LHP) instead of the Gaussian prior to update the hyperparameters in the M-step, which improves the robustness of the model and speeds up the convergence of GAMP.
- (4)
- The combination of GAMP and LHP further deepens the hierarchical structure of the model and improves the sparsity of the model. The higher the sparsity of the model, the fewer non-zero elements it has, and the stronger the representation ability of the model (using as few non-zero elements as possible to represent the main characteristic information of the original signal). The reconstruction accuracy is improved without affecting the computational efficiency. A large number of experiments have shown that our LHP-GAMP-SBL model outperforms other mainstream SBL image reconstruction models in overall reconstruction performance.
2. Methods
2.1. Laplace Hierarchical SBL Model
2.2. Laplace Hierarchical Bayesian Inference
2.3. LHP-GAMP-SBL Model
| Algorithm 1: LHP-GAMP-SBL Algorithm |
 |
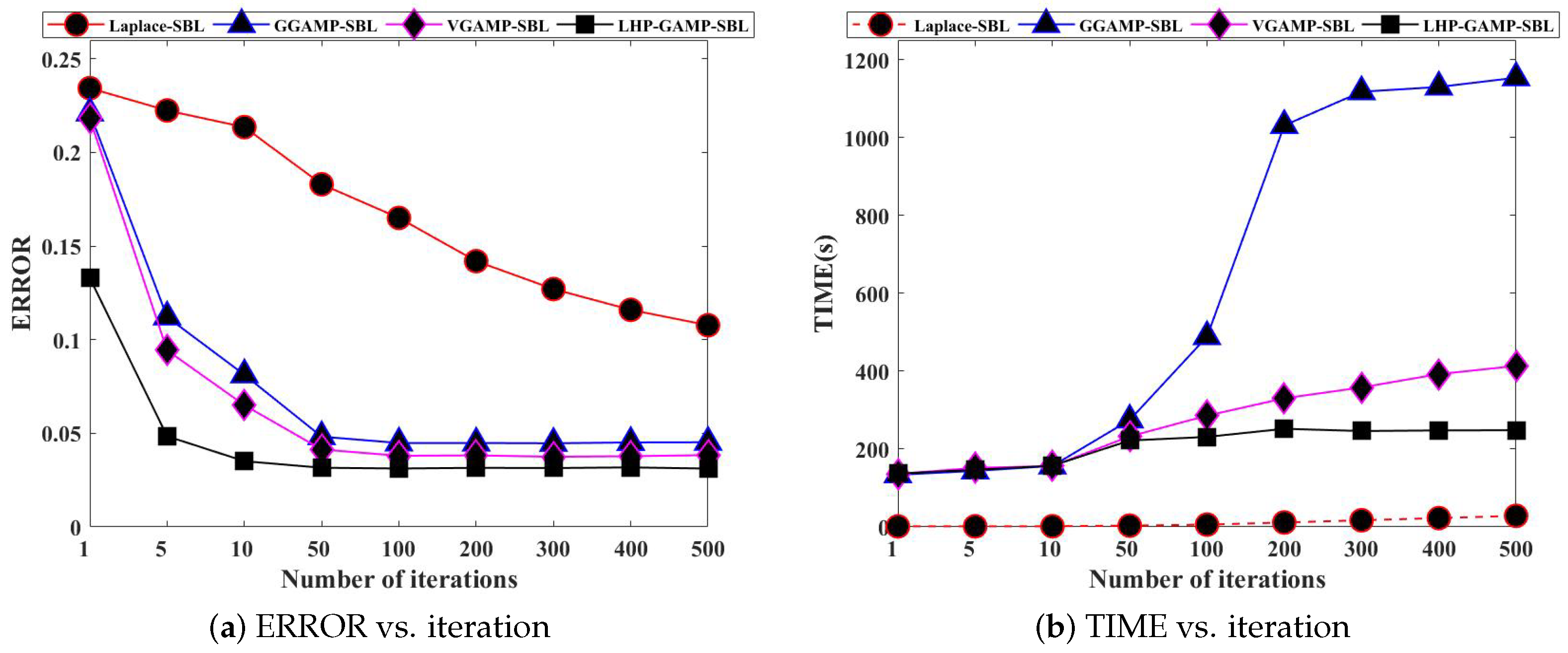
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| SBL | sparse Bayesian learning |
| GAMP | generalized approximate message passing |
| SSR | sparse signal recovery |
| EM | expectation maximization |
| VB | variational Bayesian |
| LHP | Laplace hierarchical priori |
| ELBO | evidence lower bound |
| PSNR | peak signal-to-noise ratio |
| SSIM | structural similarity |
References
- Zhou, W.; Zhang, H.T.; Wang, J. An efficient sparse Bayesian learning algorithm based on Gaussian-scale mixtures. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3065–3078. [Google Scholar] [CrossRef] [PubMed]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Wipf, D.; Rao, B. Sparse Bayesian learning for basis selection. IEEE Trans. Signal Process. 2004, 52, 2153–2164. [Google Scholar] [CrossRef]
- Zhang, Y.; Qi, X.; Jiang, Y.C.; Li, H.B.; Liu, Z.T. Image reconstruction for low-oversampled staggered SAR based on sparsity Bayesian learning in the presence of a nonlinear PRI variation strategy. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–24. [Google Scholar] [CrossRef]
- Chen, P.; Zhao, J.; Bai, X. Block Inverse-free Sparse Bayesian Learning for Block Sparse Signal Recovery. In Proceedings of the 2019 IEEE International Conference on Signal, Information and Data Processing (ICSIDP), Chongqing, China, 11–13 December 2019; pp. 1–4. [Google Scholar]
- Sant, A.; Leinonen, M.; Rao, B.D. Block-sparse signal recovery via general total variation regularized sparse Bayesian learning. IEEE Trans. Signal Process. 2022, 70, 1056–1071. [Google Scholar] [CrossRef]
- Yuan, S.Y.; Ji, Y.Z.; Shi, P.D.; Zeng, J.; Gao, J.H.; Wang, S.X. Sparse Bayesian learning-based seismic high-resolution time-frequency analysis. IEEE Geosci. Remote Sens. Lett. 2018, 16, 623–627. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–22. [Google Scholar] [CrossRef]
- Shutin, D.; Buchgraber, T.; Kulkarni, S.R.; Poor, H.V. Fast variational sparse Bayesian learning with automatic relevance determination for superimposed signals. IEEE Trans. Signal Process. 2011, 59, 6257–6261. [Google Scholar] [CrossRef]
- Duan, H.P.; Yang, L.X.; Fang, J.; Li, H.B. Fast inverse-free sparse Bayesian learning via relaxed evidence lower bound maximization. IEEE Signal Process. Lett. 2017, 24, 774–778. [Google Scholar] [CrossRef]
- Rangan, S. Generalized approximate message passing for estimation with random linear mixing. In Proceedings of the 2011 IEEE International Symposium on Information Theory Proceedings, St. Petersburg, Russia, 31 July–5 August 2011; pp. 2168–2172. [Google Scholar]
- Zou, X.B.; Li, F.W.; Fang, J.; Li, H.B. Computationally efficient sparse Bayesian learning via generalized approximate message passing. In Proceedings of the 2016 IEEE International Conference on Ubiquitous Wireless Broadband (ICUWB), Nanjing, China, 16–19 October 2016; pp. 2168–2172. [Google Scholar]
- Al-Shoukairi, M.; Schniter, P.; Rao, B.D. A GAMP-based low complexity sparse Bayesian learning algorithm. IEEE Trans. Signal Process. 2017, 66, 294–308. [Google Scholar] [CrossRef]
- Dong, J.Y.; Lyu, W.T.; Zhou, D.; Xu, W.Q. Variational Bayesian and Generalized Approximate Message Passing-Based Sparse Bayesian Learning Model for Image Reconstruction. IEEE Signal Process. Lett. 2022, 29, 2328–2332. [Google Scholar] [CrossRef]
- Seeger, M.W.; Nickisch, H. Compressed sensing and Bayesian experimental design. In Proceedings of the 25th International Conference on Machine Learning(ICML), Helsinki, Finland, 5–9 July 2008; pp. 912–919. [Google Scholar]
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Bayesian compressive sensing using Laplace priors. IEEE Trans. Image Process. 2009, 19, 53–63. [Google Scholar] [CrossRef] [PubMed]
- Cheng, G.; Wang, J.B.; Li, K.; Xie, X.X.; Lang, C.B.; Yao, Y.Q.; Han, J.W. Anchor-free oriented proposal generator for object detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Peng, T.; Yi, J.J.; Fang, Y. A Local-global Interactive Vision Transformer for Aerial Scene Classification. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | E-STEP | M-STEP |
|---|---|---|
| IF-SBL [10] | ||
| SBL-EM [3] | ||
| Laplace-SBL [16] | ||
| GGAMP-SBL [13] | ||
| VGAMP-SBL [14] | ||
| LHP-GAMP-SBL |
| Methods | Error (×10−2) | TIME (s) | ||||
|---|---|---|---|---|---|---|
| A | B | C | A | B | C | |
| IF-SBL [10] | 16.54 | 17.51 | 20.55 | 458.2 | 449.2 | 431.2 |
| SBL-EM [3] | 10.66 | 12.28 | 12.89 | 978.2 | 962.4 | 1083.4 |
| Laplace-SBL [16] | 11.03 | 13.48 | 13.01 | 281.9 | 290.2 | 335.0 |
| GGAMP-SBL [13] | 9.49 | 11.87 | 11.53 | 1322.0 | 1414.6 | 1517.5 |
| VGAMP-SBL [14] | 9.04 | 11.56 | 10.78 | 578.1 | 764.5 | 600.1 |
| LHP-GAMP-SBL | 8.73 | 11.10 | 10.36 | 259.0 | 276.3 | 273.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, W.; Lyu, W.; Chen, Y.; Guo, Q.; Deng, Z.; Xu, W. Efficient Sparse Bayesian Learning Model for Image Reconstruction Based on Laplacian Hierarchical Priors and GAMP. Electronics 2024, 13, 3038. https://doi.org/10.3390/electronics13153038
Jin W, Lyu W, Chen Y, Guo Q, Deng Z, Xu W. Efficient Sparse Bayesian Learning Model for Image Reconstruction Based on Laplacian Hierarchical Priors and GAMP. Electronics. 2024; 13(15):3038. https://doi.org/10.3390/electronics13153038
Chicago/Turabian StyleJin, Wenzhe, Wentao Lyu, Yingrou Chen, Qing Guo, Zhijiang Deng, and Weiqiang Xu. 2024. "Efficient Sparse Bayesian Learning Model for Image Reconstruction Based on Laplacian Hierarchical Priors and GAMP" Electronics 13, no. 15: 3038. https://doi.org/10.3390/electronics13153038
APA StyleJin, W., Lyu, W., Chen, Y., Guo, Q., Deng, Z., & Xu, W. (2024). Efficient Sparse Bayesian Learning Model for Image Reconstruction Based on Laplacian Hierarchical Priors and GAMP. Electronics, 13(15), 3038. https://doi.org/10.3390/electronics13153038