
An Encrypted Traffic Classification Approach Based on Path Signature Features and LSTM
Abstract
:1. Introduction
- We propose an encrypted traffic classifier that combines path signature features with an LSTM model. This classifier extracts the complex dynamics and geometric structures of encrypted traffic using path signature features and utilizes an LSTM model to perform the classification task, significantly reducing the computational resources required for traffic classification.
- We introduce a multi-scale cumulative feature extraction method to generate path signature features that are optimally suited for LSTM models. Using this method, the classification accuracy of the LSTM model can be improved by 5–30%, validating the effectiveness of our new feature extraction approach.
- Our proposed method achieves competitive classification results using only 24 consecutive packet length and time interval features. It demonstrates classification accuracies of 94.74%, 90.53%, 93.86%, and 95.03% on the ISCX-VPN, ISCX-nonVPN, ISCX-Tor, and ISCX-nonTor datasets, respectively, proving the effectiveness of our approach.
2. Related Work
2.1. Encrypted Traffic Classification
- Distinguishing between encrypted and unencrypted traffic [3];
- Identifying the specific applications associated with the traffic [13];
- Classifying traffic based on different service types. Service types refer to the purpose of the traffic, i.e., traffic generated to meet specific user needs. For example, file transfer traffic is generated when users perform upload or download operations on the network, and streaming traffic is generated when users use streaming media services, such as listening to music or watching videos [14].
2.2. Path Signature Features
2.2.1. Definition of Path Signatures
2.2.2. Geometric Interpretation of Path Signatures
2.2.3. Properties of Path Signatures
- Uniqueness: Hambly et al. [27] established that each rough path possesses a distinct path signature, ensuring a one-to-one correspondence between non-tree-like paths and their signatures. This fundamental property asserts that path signatures can precisely encapsulate the geometric traits of paths. Incorporating time as a monotonically increasing dimension in the sequence of encrypted traffic transforms these sequences into non-tree-like paths, thus providing a robust theoretical framework for substituting original paths with their path signature features as input for analytical models.
- Invariance under parameter changes: Different sampling strategies yield varied parameters for the same path, yet the path signature remains consistent across these variations [27]. This invariance implies that classification outcomes for traffic from specific application types remain stable, unaffected by the diversity in parameters. Leveraging this attribute allows for the elimination of discrepancies introduced by various reparameterizations of traffic within the same category, highlighting a crucial advantage of utilizing path signature features.
- Dimension invariance: The dimensionality of path signature features is determined solely by the chosen truncation depth, independent of the actual path length [27]. For instance, considering the previously discussed two-dimensional path t ∈ [0,4], (a = 0,b = 4) with and , truncating to one dimension results in a path signature length of 3, while truncation to two dimensions yields a length of 7. This fixed-length feature extraction from paths of varying lengths significantly simplifies the feature extraction process, especially for models necessitating fixed-length input features.
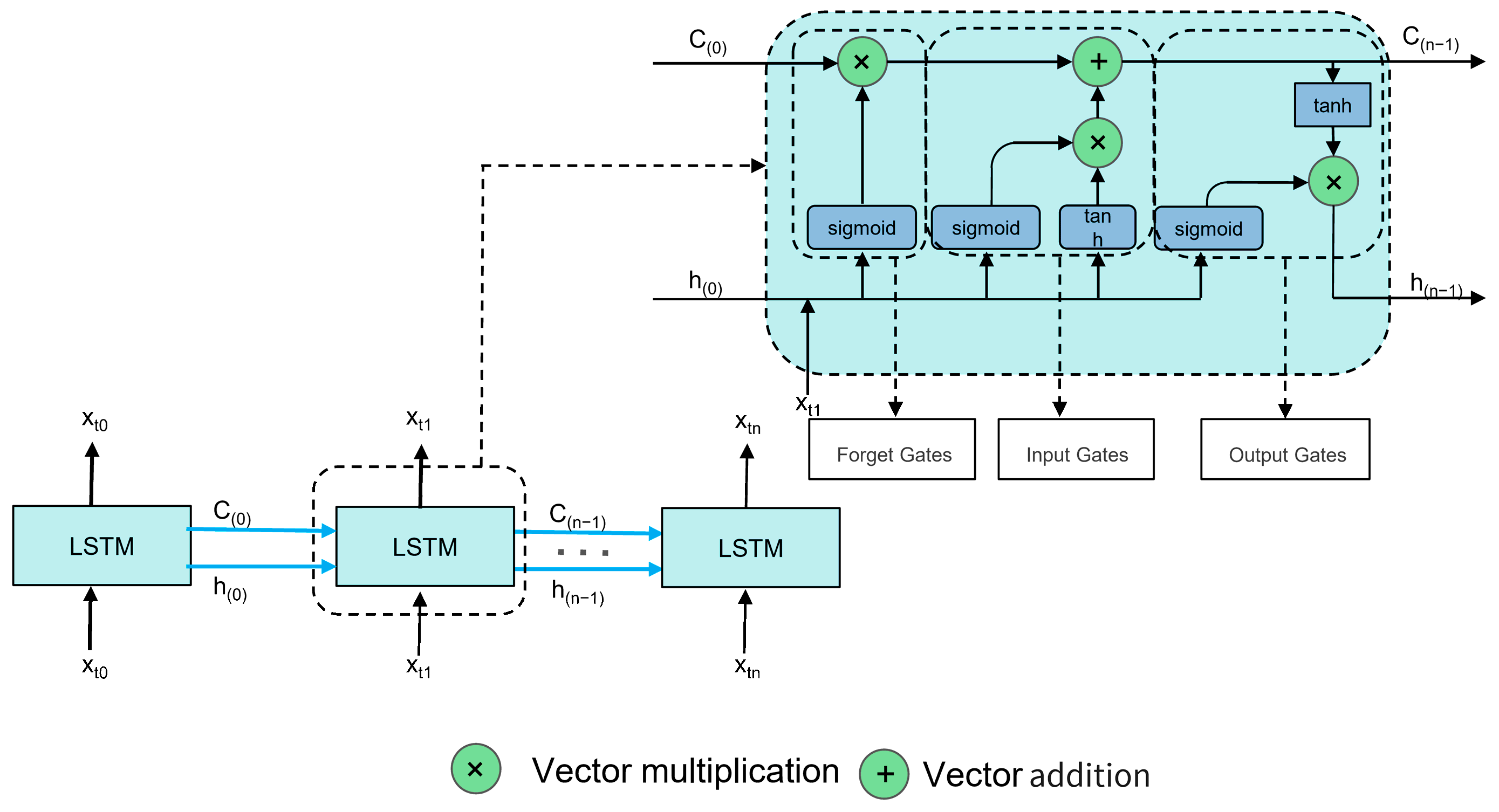
2.3. LSTM Model
- Input Gate: Oversees the flow of incoming data into the cell, deciding how much of the new information should be stored;
- Output Gate: Determines the extent to which the cell’s current state influences other parts of the network, controlling the output flow;
- Forget Gate: Adjusts the cell’s self-recurrent connections using sigmoid functions to scale values between 0 and 1, determining what information is discarded or retained.
- Better handling of temporal dependencies: While CNNs excel at capturing spatial hierarchies and patterns, they are typically more effective in processing data with spatial correlations (such as images) and cannot capture temporal dependencies as effectively as LSTM [33].
- More straightforward and more direct data processing: Applying CNNs to sequence data requires transforming the time series into a format suitable for convolution operations, necessitating more complex data processing. In contrast, LSTM allows direct input of time series features into the model.
- Lower computational resource requirements: Transformer models have recently gained popularity for their success in sequence-to-sequence tasks, especially in natural language processing. Transformers use self-attention mechanisms to capture dependencies between different parts of the input sequence, regardless of their distance [34]. While this is beneficial for capturing global dependencies, Transformers typically require substantial computational resources and large datasets for practical training. LSTM networks, using inherent gating mechanisms to process sequential data, require fewer computational resources for training and deployment.
3. Methodology
3.1. Overview of the Approach
3.2. Data Preprocessing
3.3. Build Traffic Paths
3.4. Transform Traffic Paths
3.4.1. Path Splitting
3.4.2. Path Accumulation
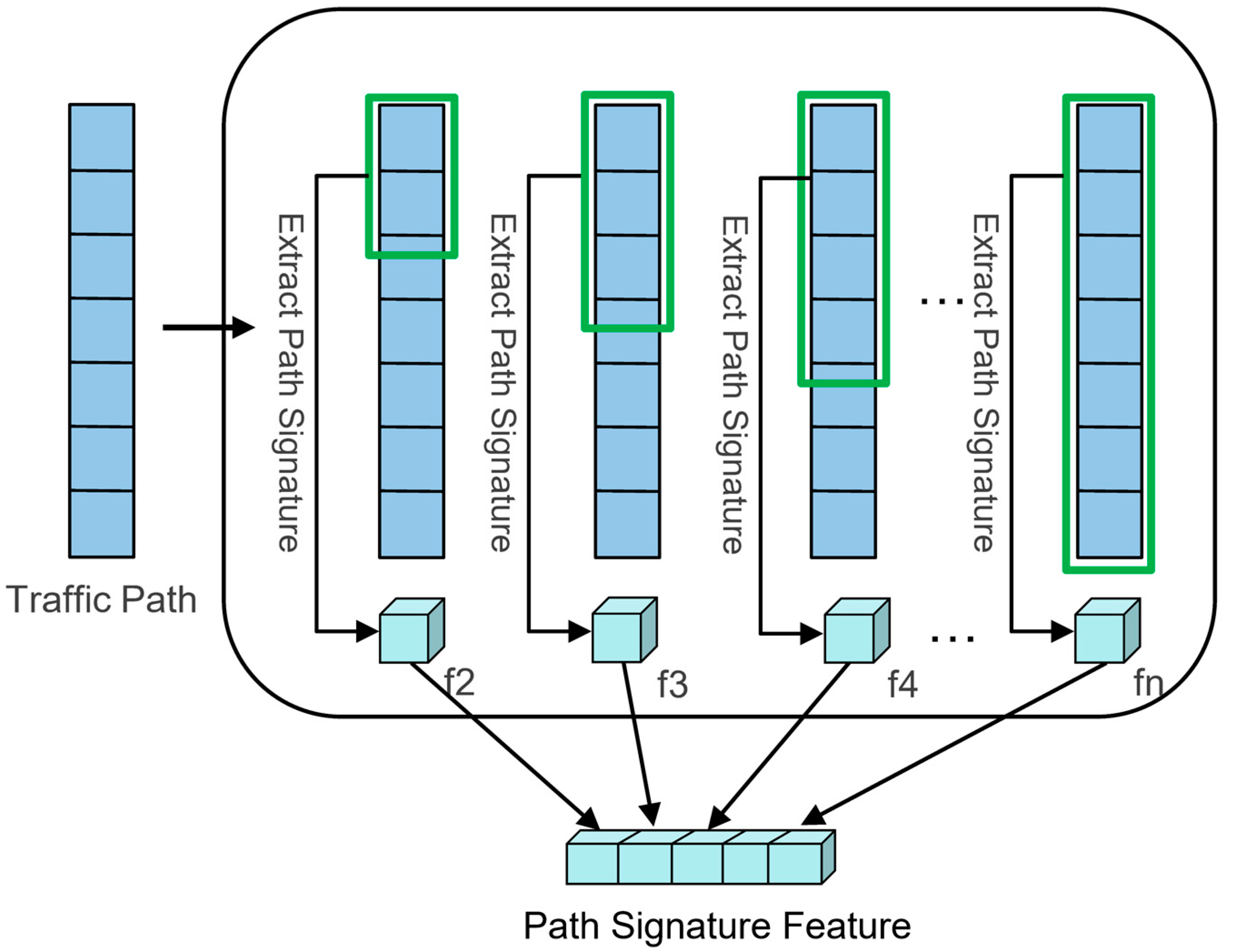
3.5. Extracting Path Signature
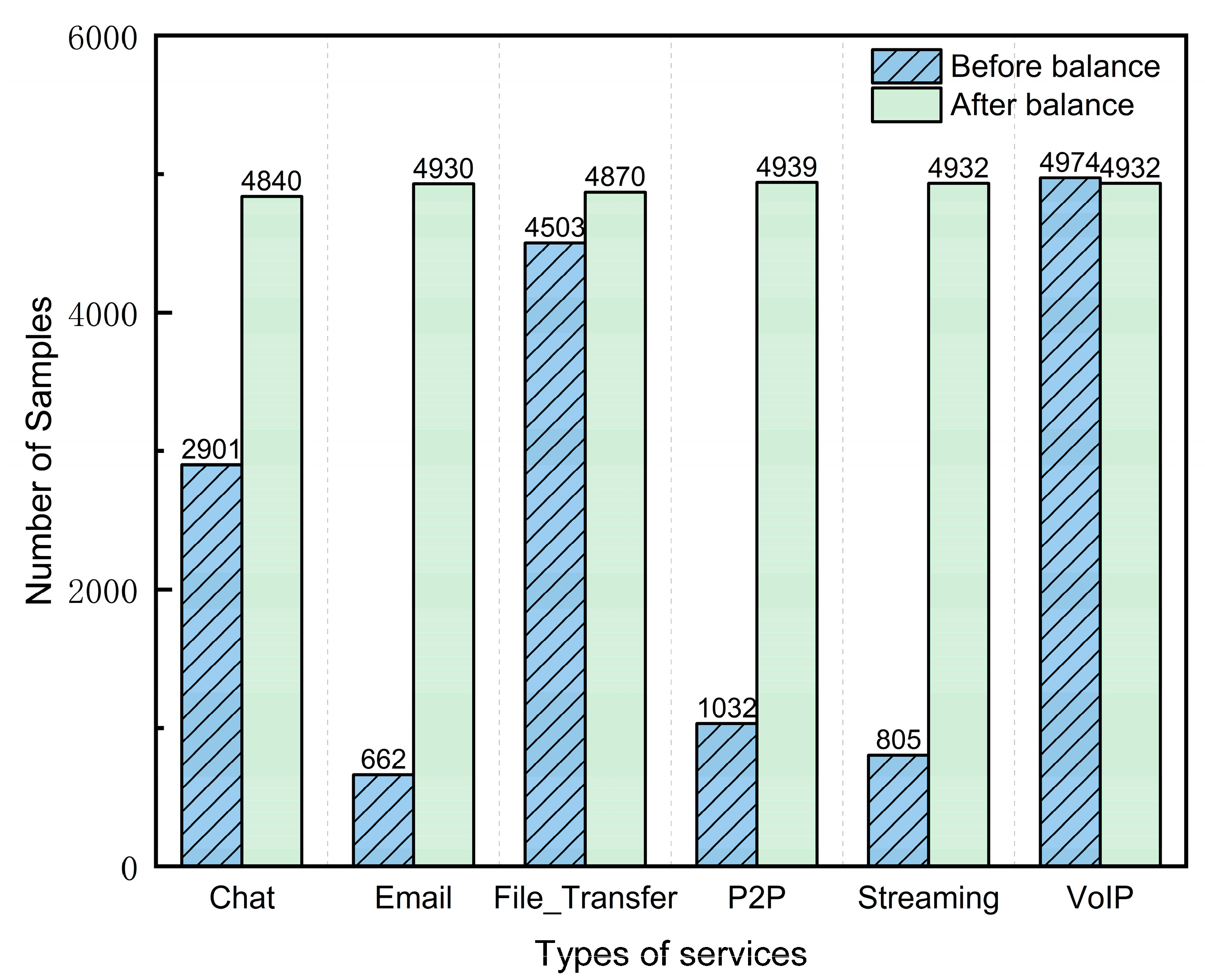
3.6. Data Balancing
3.6.1. SMOTE (Synthetic Minority Over-Sampling Technique)
3.6.2. ENN (Edited Nearest Neighbors)
3.6.3. SMOTE-ENN
3.7. Input to the LSTM Model
3.8. Fully Connected Layer
3.9. Complete Workflow
4. Discussion
4.1. Experimental Environment
4.2. Evaluation Metrics
4.3. Datasets
4.4. Data Balancing
4.5. Parameter Selection
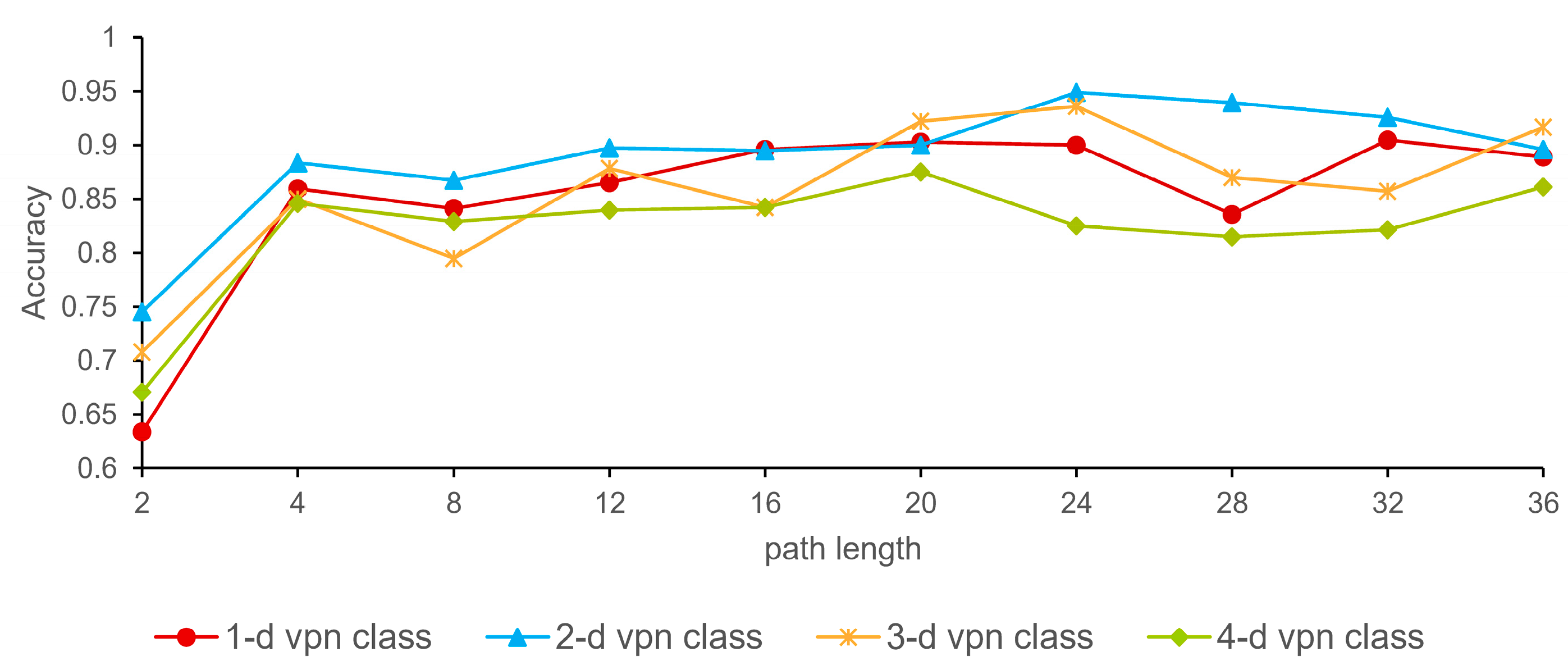
4.6. Sensitivity Analysis
4.7. Ablation Study
4.8. Comparison Experiments
4.8.1. The Benchmark Methods
- Fingerprint construction: FlowPrint [17];
4.8.2. Experimental Results
4.8.3. Performance Analysis
- Our model architecture has a lower complexity and requires fewer computational resources. As a result, the calculations are completed quickly once the samples are input into the model, thereby reducing the inference time.
- Our sample size is relatively small, with an input size of (1,23,56). Additionally, the computational load on the CPU is minimal, allowing for a swift transfer of data from the CPU to the GPU, thereby reducing the latency time.
4.8.4. Statistical Analysis
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bader, O.; Lichy, A.; Hajaj, C.; Dubin, R.; Dvir, A. MalDIST: From Encrypted Traffic Classification to Malware Traffic Detection and Classification. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; pp. 527–533. [Google Scholar]
- Wang, Y.; He, H.; Lai, Y.; Liu, A.X. A Two-Phase Approach to Fast and Accurate Classification of Encrypted Traffic. IEEE/ACM Trans. Netw. 2023, 31, 1071–1086. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the 2017 IEEE International Conference on Intelligence and Security Informatics (ISI), Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar]
- Shen, M.; Liu, Y.; Zhu, L.; Xu, K.; Du, X.; Guizani, N. Optimizing Feature Selection for Efficient Encrypted Traffic Classification: A Systematic Approach. IEEE Netw. 2020, 34, 20–27. [Google Scholar] [CrossRef]
- Karagiannis, T.; Papagiannaki, K.; Faloutsos, M. BLINC: Multilevel traffic classification in the dark. ACM SIGCOMM Comput. Commun. Rev. 2005, 35, 229–240. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Jafari Siavoshani, M.; Shirali Hossein Zade, R.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Al-Naami, K.; Chandra, S.; Mustafa, A.; Khan, L.; Thuraisingham, B.M. Adaptive encrypted traffic fingerprinting with bi-directional dependence. In Proceedings of the Conference on Computer Security Applications, Los Angeles, CA, USA, 5–9 December 2016. [Google Scholar]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. Robust Smartphone App Identification via Encrypted Network Traffic Analysis. IEEE Trans. Inf. Forensics Secur. 2018, 13, 63–78. [Google Scholar] [CrossRef]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. AppScanner: Automatic Fingerprinting of Smartphone Apps from Encrypted Network Traffic. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrucken, Germany, 21–24 March 2016; pp. 439–454. [Google Scholar]
- Xie, G.; Li, Q.; Jiang, Y. Self-attentive deep learning method for online traffic classification and its interpretability. Comput. Netw. 2021, 196, 108267. [Google Scholar] [CrossRef]
- Chen, K.T. Integration of Paths—A Faithful Representation of Paths by Noncommutative Formal Power Series. Trans. Am. Math. Soc. 1958, 89, 395–407. [Google Scholar] [CrossRef]
- Xu, S.-J.; Geng, G.-G.; Jin, X.-B.; Liu, D.-J.; Weng, J. Seeing traffic paths: Encrypted traffic classification with path signature features. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2166–2181. [Google Scholar] [CrossRef]
- Yamansavascilar, B.; Guvensan, M.A.; Yavuz, A.G.; Karsligil, M.E. Application identification via network traffic classification. In Proceedings of the 2017 International Conference on Computing, Networking and Communications (ICNC), Silicon Valley, CA, USA, 26–29 January 2017; pp. 843–848. [Google Scholar]
- Chen, R.T.Q.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural ordinary differential equations. Adv. Neural Inf. Process. Syst. 2018, 31, 07366. [Google Scholar]
- Dainotti, A.; Pescape, A.; Claffy, K.C. Issues and Future Directions in Traffic Classification. IEEE Netw. 2012, 26, 35–40. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 633–642. [Google Scholar]
- Van Ede, T.; Bortolameotti, R.; Continella, A.; Ren, J.; Dubois, D.J.; Lindorfer, M.; Choffnes, D.; van Steen, M.; Peter, A. Flowprint: Semi-supervised mobile-app fingerprinting on encrypted network traffic. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Biju, V.G.; Prashanth, C. Friedman and Wilcoxon evaluations comparing SVM, bagging, boosting, K-NN and decision tree classifiers. J. Appl. Comput. Sci. Methods 2017, 9, 23–47. [Google Scholar] [CrossRef]
- Sirinam, P.; Imani, M.; Juarez, M.; Wright, M. Deep fingerprinting: Undermining website fingerprinting defenses with deep learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1928–1943. [Google Scholar]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. Fs-net: A flow sequence network for encrypted traffic classification. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference On Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- Lin, K.; Xu, X.; Gao, H. TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput. Netw. 2021, 190, 107974. [Google Scholar] [CrossRef]
- Zhang, H.; Yu, L.; Xiao, X.; Li, Q.; Mercaldo, F.; Luo, X.; Liu, Q. TFE-GNN: A Temporal Fusion Encoder Using Graph Neural Networks for Fine-grained Encrypted Traffic Classification. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–1 May 2023; pp. 2066–2075. [Google Scholar]
- Zhao, R.; Deng, X.; Yan, Z.; Ma, J.; Xue, Z.; Wang, Y. Mt-flowformer: A semi-supervised flow transformer for encrypted traffic classification. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2576–2584. [Google Scholar]
- Graham, B. Sparse arrays of signatures for online character recognition. arXiv 2013, arXiv:1308.0371. [Google Scholar]
- Gyurkó, L.G.; Lyons, T.; Kontkowski, M.; Field, J. Extracting information from the signature of a financial data stream. arXiv 2013, arXiv:1307.7244. [Google Scholar]
- Perez Arribas, I.; Goodwin, G.M.; Geddes, J.R.; Lyons, T.; Saunders, K.E. A signature-based machine learning model for distinguishing bipolar disorder and borderline personality disorder. Transl. Psychiatry 2018, 8, 274. [Google Scholar] [CrossRef] [PubMed]
- Hambly, B.; Lyons, T. Uniqueness for the signature of a path of bounded variation and the reduced path group. Ann. Math. 2010, 171, 109–167. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Shen, S.; Han, T.; Pang, J. Car drag coefficient prediction using long–short term memory neural network and LASSO. Measurement 2024, 225, 113982. [Google Scholar] [CrossRef]
- Yeganeh, A.; Ahmadi, F.; Wong, Y.J.; Shadman, A.; Barati, R.; Saeedi, R. Shallow vs. Deep Learning Models for Groundwater Level Prediction: A Multi-Piezometer Data Integration Approach. Water Air Soil. Pollut. 2024, 235, 441. [Google Scholar] [CrossRef]
- Zhao, L.; Farhi, N.; Valero, Y.; Christoforou, Z. Long short-time memory neural networks for human driving behavior modelling. Transp. Res. Procedia 2023, 72, 2589–2596. [Google Scholar] [CrossRef]
- Eswarsai. Exploring Different Types of LSTMs. Available online: https://medium.com/analytics-vidhya/exploring-different-types-of-lstms-6109bcb037c4 (accessed on 28 July 2024).
- Sun, Y.; Wang, X.; Tang, X. Deeply learned face representations are sparse, selective, and robust. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Panchenko, A.; Lanze, F.; Pennekamp, J.; Engel, T.; Zinnen, A.; Henze, M.; Wehrle, K. Website Fingerprinting at Internet Scale. In Proceedings of the NDSS 2016, San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wilson, D.L. Asymptotic properties of nearest neighbor rules using edited data. IEEE Trans. Syst. Man Cybern. 1972, 2, 408–421. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Lashkari, A.H.; Gil, G.D.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the International Conference on Information Systems Security and Privacy, Rome, Italy, 29–31 May 2017; pp. 253–262. [Google Scholar]
- Shapira, T.; Shavitt, Y. FlowPic: A generic representation for encrypted traffic classification and applications identification. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1218–1232. [Google Scholar] [CrossRef]
- Hayes, J.; Danezis, G. k-fingerprinting: A robust scalable website fingerprinting technique. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 1187–1203. [Google Scholar]
- Zaki, F.; Afifi, F.; Abd Razak, S.; Gani, A.; Anuar, N.B. GRAIN: Granular multi-label encrypted traffic classification using classifier chain. Comput. Netw. 2022, 213, 109084. [Google Scholar] [CrossRef]
- Shen, M.; Zhang, J.; Zhu, L.; Xu, K.; Du, X. Accurate decentralized application identification via encrypted traffic analysis using graph neural networks. IEEE Trans. Inf. Forensics Secur. 2021, 16, 2367–2380. [Google Scholar] [CrossRef]
- Sun, P.; Li, S.; Xie, J.; Xu, H.; Cheng, Z.; Yang, R. GPMT: Generating practical malicious traffic based on adversarial attacks with little prior knowledge. Comput. Secur. 2023, 130, 103257. [Google Scholar] [CrossRef]
- Yu, S.; Zhao, G.; Dou, W.; James, S. Predicted packet padding for anonymous web browsing against traffic analysis attacks. IEEE Trans. Inf. Forensics Secur. 2012, 7, 1381–1393. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L | C | S | T | |||
|---|---|---|---|---|---|---|
| 194 | 194 | 0 | 194 | 194 | 0 | 0 |
| −83 | 0 | −83 | 111 | 194 | −83 | 2 |
| −32 | 0 | −32 | 79 | 194 | −115 | 5 |
| 53 | 53 | 0 | 132 | 247 | −115 | 8 |
| 86 | 86 | 0 | 218 | 333 | −115 | 10 |
| Stage | Description | Shape |
|---|---|---|
| Raw Data | Capture encrypted traffic sequence | __ |
| Build Traffic Paths | Extract packet length and arrival time | (24, 2) |
| Path Splitting | Split the length sequence into two paths | (24, 4) |
| Path Accumulation | Accumulate three-length sequences | (24, 7) |
| Extracting Path Signature | Use path signature feature function to extract path signature features | (24, 56) |
| LSTM Input | Use path signature features as input to LSTM | (1, 24, 56) |
| LSTM Hidden Units | 64 hidden units of LSTM layer process input sequence, returning hidden states for all time steps | (1, 24, 64) |
| Final Hidden State | Select the hidden state of the last time step in the LSTM model and input the fully connected layer | (1, 64) |
| Fully Connected Layer Output | The fully connected layer outputs the probability distribution of the classification result | (1, 6) |
| Service | Application | Description |
|---|---|---|
| Chat | AIM, ICQ, Skype, Facebook, Hangouts | Traffic generated during online chat communication |
| Email, Gmail | Traffic generated during email transmission | |
| File transfer | Skype SFTP, FTPS, SCP | Traffic generated during file uploads and downloads |
| Streaming | Vimeo, YouTube, Netflix, Spotify | Traffic generated when using streaming applications |
| P2P | uTorrent, BitTorrent | Traffic generated when sharing torrent resources using P2P programs |
| VoIP | Facebook, Skype, Hangouts, VoipBuster | Traffic generated during online voice calls |
| Learning Rate | 0.1 | 0.01 | 0.001 | 0.0001 | 0.00001 |
| Accuracy | 0.8596 | 0.8918 | 0.9152 | 0.9474 | 0.9298 |
| Regularization Parameters | 0.01 | 0.001 | 0.0001 | 0.00005 | 0.00001 |
| Accuracy | 0.8099 | 0.9006 | 0.9474 | 0.921 | 0.9152 |
| Dataset | ISCX-VPN | ISCX-nonVPN | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
| FlowPrint [17] | 0.8538 | 0.7451 | 0.7917 | 0.7566 | 0.6944 | 0.7073 | 0.7310 | 0.7131 |
| AppScanner [9] | 0.8889 | 0.8679 | 0.8851 | 0.8722 | 0.7576 | 0.7594 | 0.7465 | 0.7486 |
| CUMUL [35] | 0.7661 | 0.7531 | 0.7852 | 0.7644 | 0.6187 | 0.5941 | 0.5971 | 0.5897 |
| K-FP [42] | 0.8713 | 0.8750 | 0.8748 | 0.8747 | 0.7551 | 0.7478 | 0.7354 | 0.7387 |
| GRAIN [44] | 0.8129 | 0.8077 | 0.8109 | 0.8027 | 0.6667 | 0.6532 | 0.6664 | 0.6567 |
| ETC-PS [12] | 0.8889 | 0.8803 | 0.8937 | 0.8851 | 0.7273 | 0.7414 | 0.7133 | 0.7208 |
| FS-net [20] | 0.9298 | 0.9263 | 0.9211 | 0.9234 | 0.7626 | 0.7685 | 0.7534 | 0.7355 |
| DF [19] | 0.8012 | 0.7799 | 0.8152 | 0.7921 | 0.6742 | 0.6857 | 0.6717 | 0.6701 |
| MT-FlowFormer [23] | 0.9327 | 0.9152 | 0.9243 | 0.9193 | 0.8549 | 0.8473 | 0.8268 | 0.8344 |
| GraphDApp [44] | 0.6491 | 0.5668 | 0.6103 | 0.5740 | 0.4495 | 0.4230 | 0.3647 | 0.3614 |
| ET-BERT (flow) [16] | 0.9532 | 0.9436 | 0.9507 | 0.9463 | 0.9167 | 0.9245 | 0.9229 | 0.9235 |
| Proposed | 0.9474 | 0.9480 | 0.9474 | 0.9472 | 0.9053 | 0.9064 | 0.9053 | 0.9050 |
| Dataset | ISCX-Tor | ISCX-nonTor | ||||||
|---|---|---|---|---|---|---|---|---|
| Method | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
| FlowPrint [17] | 0.2400 | 0.0300 | 0.1250 | 0.0484 | 0.5243 | 0.7590 | 0.6074 | 0.6153 |
| AppScanner [9] | 0.7543 | 0.6629 | 0.6042 | 0.6163 | 0.9153 | 0.8435 | 0.814 | 0.8273 |
| CUMUL [35] | 0.6686 | 0.5349 | 0.4899 | 0.4997 | 0.8605 | 0.8143 | 0.7393 | 0.7627 |
| K-FP [42] | 0.7771 | 0.7417 | 0.6209 | 0.6313 | 0.8741 | 0.8653 | 0.7792 | 0.8167 |
| GRAIN [44] | 0.6914 | 0.5253 | 0.5346 | 0.5234 | 0.7895 | 0.6714 | 0.6615 | 0.6613 |
| ETC-PS [12] | 0.7486 | 0.6811 | 0.5929 | 0.6033 | 0.9155 | 0.8710 | 0.8311 | 0.8486 |
| FS-net [20] | 0.8286 | 0.7487 | 0.7197 | 0.7242 | 0.9278 | 0.8368 | 0.8254 | 0.8285 |
| DF [19] | 0.6514 | 0.4803 | 0.4767 | 0.4719 | 0.8568 | 0.8003 | 0.7415 | 0.7590 |
| MT-FlowFormer [23] | 0.8750 | 0.8252 | 0.8217 | 0.8220 | 0.8941 | 0.8742 | 0.8651 | 0.8670 |
| GraphDApp [44] | 0.4286 | 0.2557 | 0.2509 | 0.2281 | 0.6936 | 0.5447 | 0.5398 | 0.5352 |
| ET-BERT(flow) [16] | 0.9543 | 0.9242 | 0.9606 | 0.9397 | 0.9029 | 0.8560 | 0.8217 | 0.8332 |
| Proposed | 0.9386 | 0.9400 | 0.9386 | 0.9385 | 0.9503 | 0.9510 | 0.9503 | 0.9502 |
| Method | Params (M) | FLOPs (G) | Inference Time (ms) | Latency Time (ms) |
|---|---|---|---|---|
| FS-net [20] | 2.17 | 24.86 | 39.94 | 45.72 |
| DF [19] | 1.83 | 3.06 | 29.57 | 33.56 |
| MT-FlowFormer [23] | 0.26 | 1.07 | 57.79 | 63.08 |
| GraphDApp [44] | 0.22 | 0.59 | 78.43 | 84.72 |
| ET-BERT (flow) [16] | 85.70 | 10.87 | 104.04 | 110.94 |
| Proposed | 0.03 | 7.32 × 10−4 | 4.02 | 5.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mei, Y.; Luktarhan, N.; Zhao, G.; Yang, X. An Encrypted Traffic Classification Approach Based on Path Signature Features and LSTM. Electronics 2024, 13, 3060. https://doi.org/10.3390/electronics13153060
Mei Y, Luktarhan N, Zhao G, Yang X. An Encrypted Traffic Classification Approach Based on Path Signature Features and LSTM. Electronics. 2024; 13(15):3060. https://doi.org/10.3390/electronics13153060
Chicago/Turabian StyleMei, Yihe, Nurbol Luktarhan, Guodong Zhao, and Xiaotong Yang. 2024. "An Encrypted Traffic Classification Approach Based on Path Signature Features and LSTM" Electronics 13, no. 15: 3060. https://doi.org/10.3390/electronics13153060