

An Efficient and Accurate Ground-Based Synthetic Aperture Radar (GB-SAR) Real-Time Imaging Scheme Based on Parallel Processing Mode and Architecture

Abstract
1. Introduction
2. Signal Model
3. Data Preprocessing before Interpolation
Datasets and System Parameters
4. Fine Parallel Implementation of Stolt Interpolation
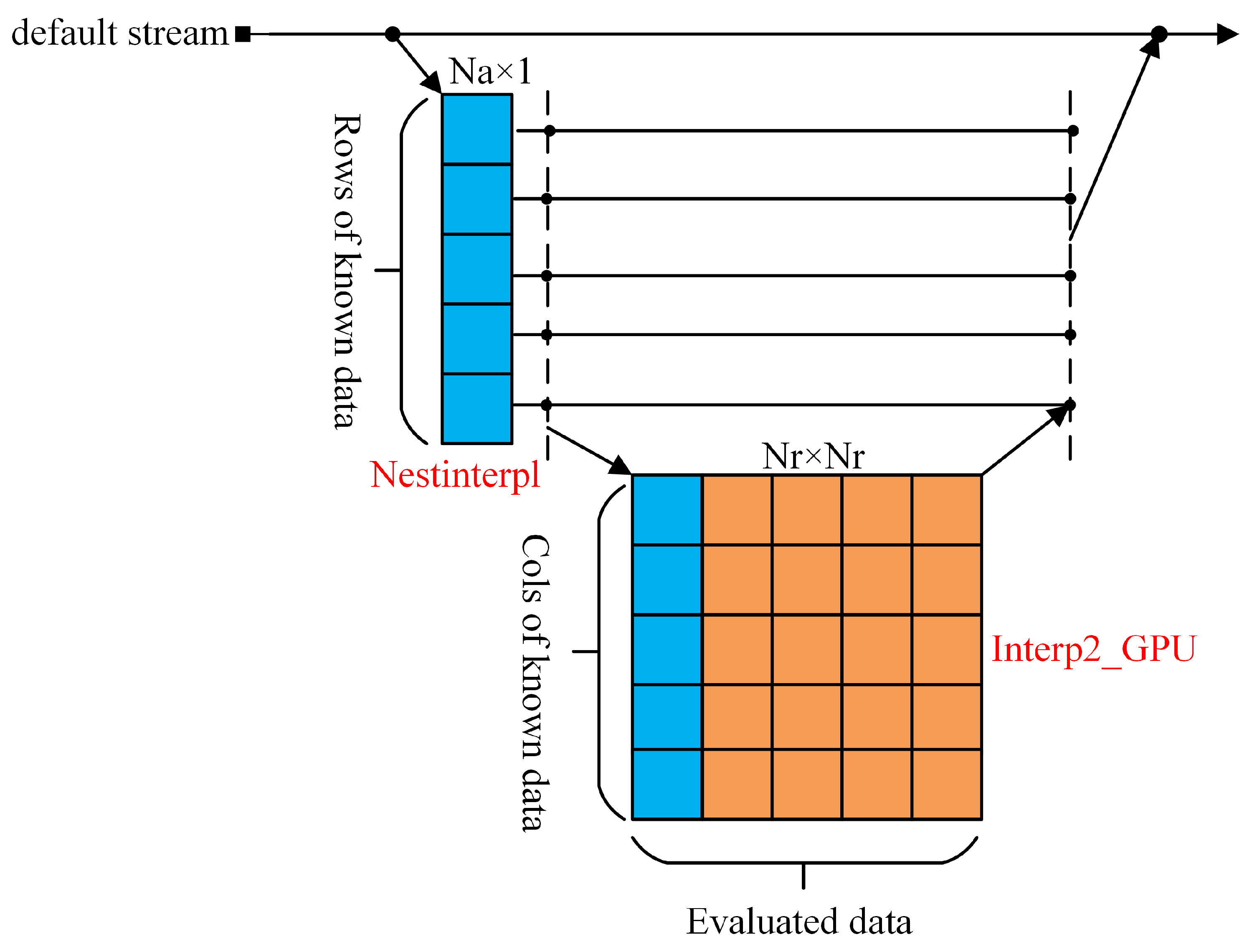
4.1. Three Layers Dynamic Nesting Implementation Scheme
4.1.1. One-Layer Nested Interpolation
4.1.2. Two-Layer Nested Interpolation
4.1.3. Three-Layer Nested Interpolation
4.2. The Processing Mode of --
5. Field Experiment
5.1. Experimental Analysis
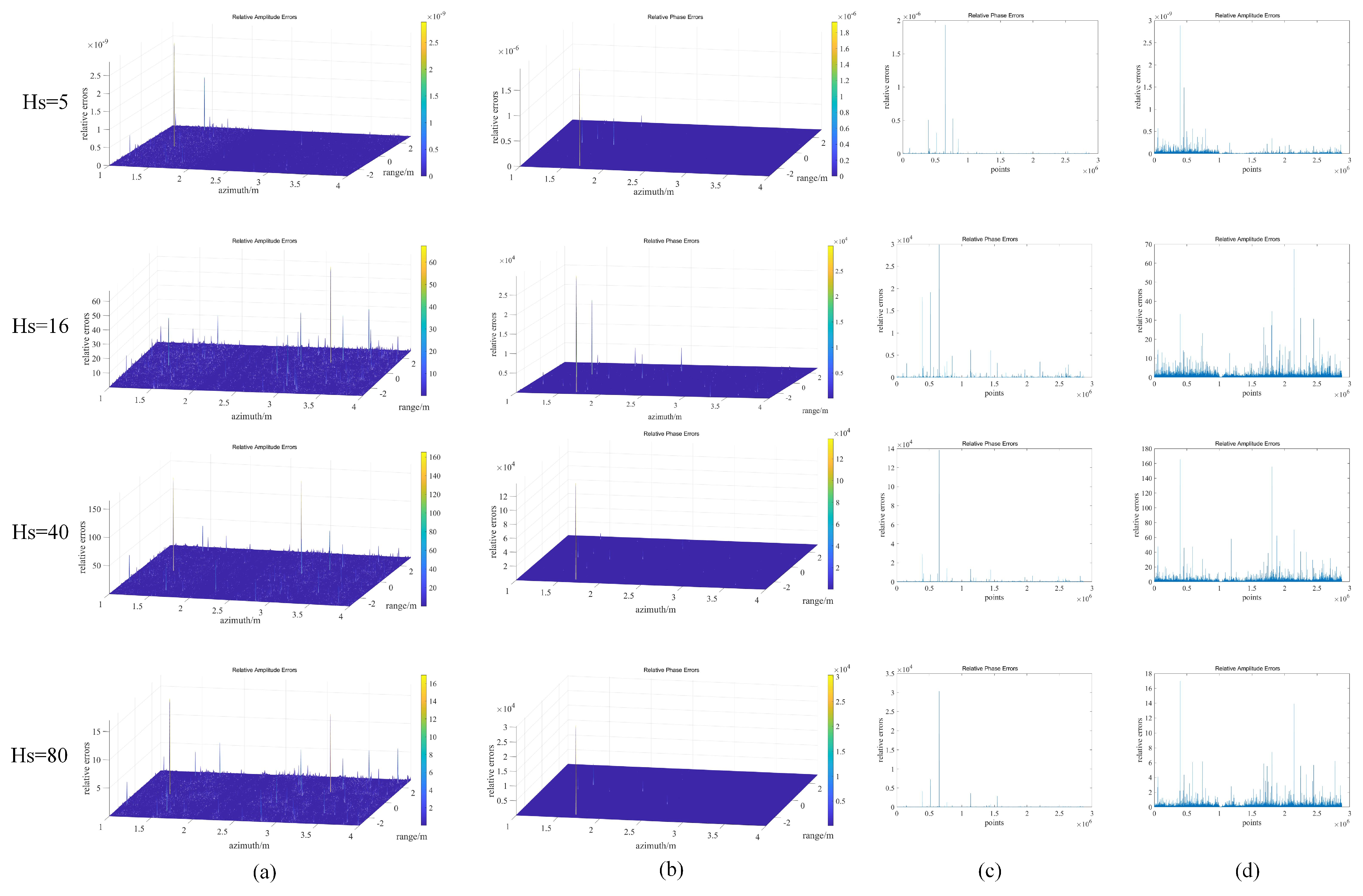
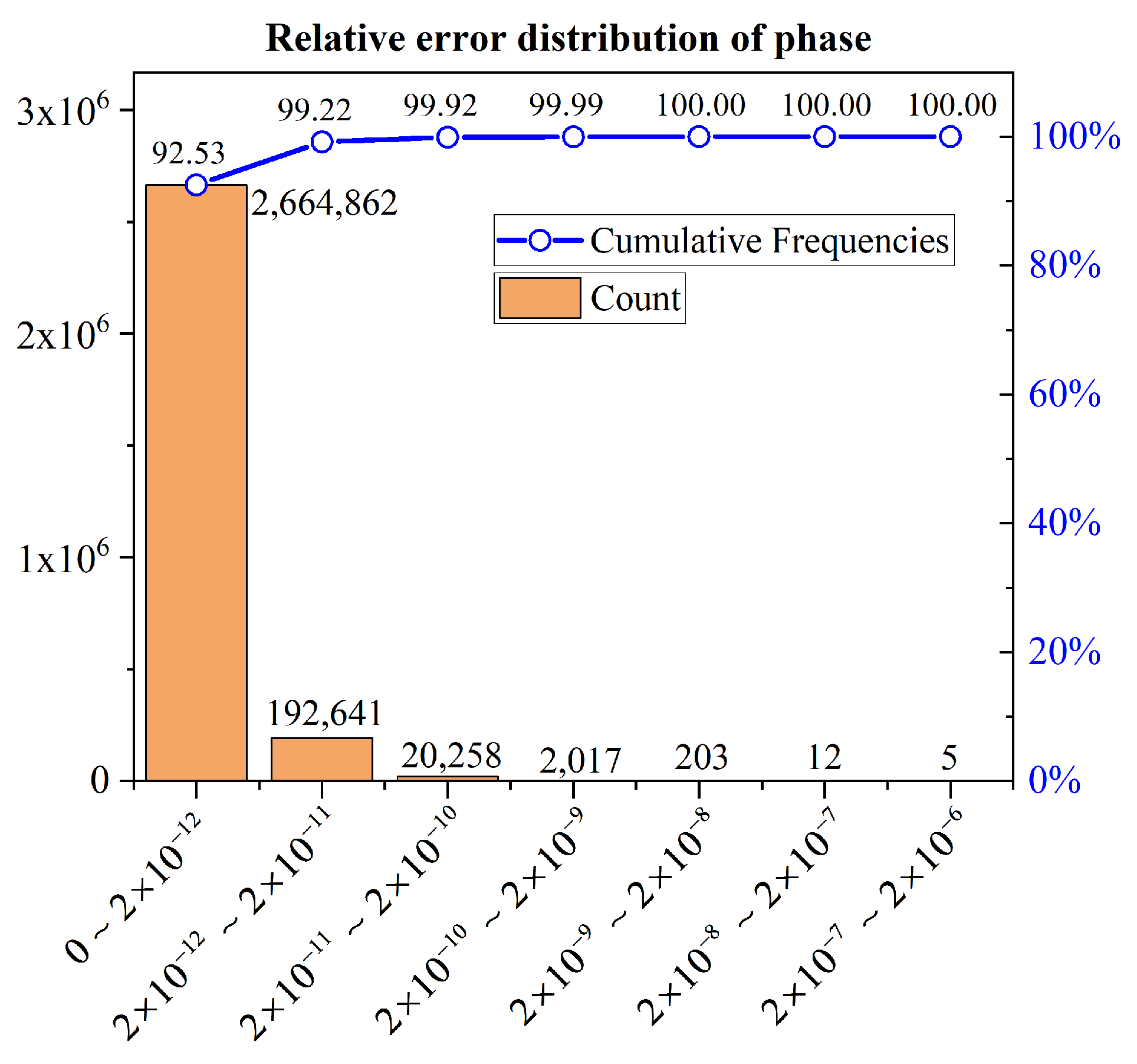
5.2. Experimental Results and Errors
6. Conclusions
- Dynamic parallelism with multilayer kernel concurrency effectively achieves the rapid processing of three-dimensional signals. Three-layer nested interpolation has complex dependency and synchronization relationships, providing no acceleration effect. One-layer nested interpolation lacks sufficient depth, resulting in minimal acceleration. Two-layer nested interpolation demonstrates good parallelism and lower algorithm complexity.
- To further reduce the dependency and synchronization relationships between the upper and lower layers of two-layer nested interpolation, the - model replaces the outermost layer of multiple threads in the two-layer nested interpolation with multiple non-blocking streams, reducing the impact of nested depth on algorithm performance in dynamic parallelism.
- The -- processing model leverages the multi-core parallel capabilities of the CPU for finer-grained parallel computation of the - model, addressing the issue of serial execution within s through hybrid programming with CUDA and OpenMP.
- The effectiveness and accuracy of the proposed method were verified through on-site experiments using a W-band GB-SAR system. The speed-up ratio of the imaging algorithm in this scheme is 37.23, with the interpolation part, which has a high computational load, achieving a speed-up ratio of up to 52.14. The relative amplitude and phase errors are close to 0.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Del Ventisette, C.; Intrieri, E.; Luzi, G.; Casagli, N.; Fanti, R.; Leva, D. Using ground based radar interferometry during emergency: The case of the A3 motorway (Calabria Region, Italy) threatened by a landslide. Nat. Hazards Earth Syst. Sci. 2011, 11, 2483–2495. [Google Scholar] [CrossRef]
- Liu, B.; He, K.; Han, M.; Hu, X.; Ma, G.; Wu, M. Application of UAV and GB-SAR in Mechanism Research and Monitoring of Zhonghaicun Landslide in Southwest China. Remote Sens. 2021, 13, 1653. [Google Scholar] [CrossRef]
- Wang, Y.; Song, Q.; Wang, J.; Yu, H. Airport Runway Foreign Object Debris Detection System Based on Arc-Scanning SAR Technology. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Brown, S.; Quegan, S.; Morrison, K.; Bennett, J.; Cookmartin, G. High-resolution measurements of scattering in wheat canopies-implications for crop parameter retrieval. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1602–1610. [Google Scholar] [CrossRef]
- Xiang, X.; Chen, C.; Wang, H.; Lu, H.; Zhang, H.; Chen, J. A real-time processing method for GB-SAR monitoring data by using the dynamic Kalman filter based on the PS network. Landslides 2023, 20, 1639–1655. [Google Scholar] [CrossRef]
- Jakovljevic, M.; Michaelides, R.; Biondi, E.; Hyun, D.; Zebker, H.A.; Dahl, J.J. Adaptation of Range-Doppler Algorithm for Efficient Beamforming of Monostatic and Multistatic Ultrasound Signals. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2022, 69, 3165–3178. [Google Scholar] [CrossRef]
- Ma, M.; Tang, J.; Wu, H.; Zhang, P.; Ning, M. CZT Algorithm for the Doppler Scale Signal Model of Multireceiver SAS Based on Shear Theorem. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–12. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, X.; Yang, Q.; Xiao, Y.; An, H.; Yang, H.; Wu, J.; Yang, J. Hybrid SAR-ISAR Image Formation via Joint FrFT-WVD Processing for BFSAR Ship Target High-Resolution Imaging. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wang, H.; Chen, X.; Sun, J. FMCW SAR Imaging Algorithm of Sliding Spotlight Mode. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Lin, J.Z.; Chen, P.T.; Chin, H.Y.; Tsai, P.Y.; Lee, S.Y. Design and Implementation of a Real-Time Imaging Processor for Spaceborne Synthetic Aperture Radar with Configurability. IEEE Trans. Very Large Scale Integr. Syst. 2024, 32, 669–681. [Google Scholar] [CrossRef]
- Bi, H.; Wang, J.; Bi, G. Wavenumber Domain Algorithm-Based FMCW SAR Sparse Imaging. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7466–7475. [Google Scholar] [CrossRef]
- Zhou, J.; Zhu, R.; Jiang, G.; Zhao, L.; Cheng, B. A Precise Wavenumber Domain Algorithm for Near Range Microwave Imaging by Cross MIMO Array. IEEE Trans. Microw. Theory Tech. 2019, 67, 1316–1326. [Google Scholar] [CrossRef]
- Xu, G.; Xing, M.; Zhang, L.; Bao, Z. Robust Autofocusing Approach for Highly Squinted SAR Imagery Using the Extended Wavenumber Algorithm. IEEE Trans. Geosci. Remote Sens. 2013, 51, 5031–5046. [Google Scholar] [CrossRef]
- Zhang, L.; Sheng, J.; Xing, M.; Qiao, Z.; Xiong, T.; Bao, Z. Wavenumber-Domain Autofocusing for Highly Squinted UAV SAR Imagery. IEEE Sens. J. 2012, 12, 1574–1588. [Google Scholar] [CrossRef]
- Chen, Y.; Xiong, Z.; Kong, Q.; Ma, X.; Chen, M.; Lu, C. Circular statistics vector for improving coherent plane wave compounding image in Fourier domain. Ultrasonics 2023, 128, 106856. [Google Scholar] [CrossRef]
- Waller, E.H.; Keil, A.; Friederich, F. Quantum range-migration-algorithm for synthetic aperture radar applications. Sci. Rep. 2023, 13, 11436. [Google Scholar] [CrossRef]
- Chen, X.; Wang, H.; Yang, Q.; Zeng, Y.; Deng, B. An Efficient mmW Frequency-Domain Imaging Algorithm for Near-Field Scanning 1-D SIMO/MIMO Array. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Garcia, D.; Tarnec, L.L.; Muth, S.; Montagnon, E.; Porée, J.; Cloutier, G. Stolt’s f-k migration for plane wave ultrasound imaging. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2013, 60, 1853–1867. [Google Scholar] [CrossRef]
- Skjelvareid, M.H.; Olofsson, T.; Birkelund, Y.; Larsen, Y. Synthetic aperture focusing of ultrasonic data from multilayered media using an omega-K algorithm. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2011, 58, 1037–1048. [Google Scholar] [CrossRef]
- Xiong, Y.; Liang, B.; Yu, H.; Chen, J.; Jin, Y.; Xing, M. Processing of Bistatic SAR Data with Nonlinear Trajectory Using a Controlled-SVD Algorithm. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 5750–5759. [Google Scholar] [CrossRef]
- Zaghiyan, M.R.; Eslamian, S.; Gohari, A.; Ebrahimi, M.S. Temporal correction of irregular observed intervals of groundwater level series using interpolation techniques. Theor. Appl. Climatol. 2021, 145, 1027–1037. [Google Scholar] [CrossRef]
- Skouroliakou, V.; Molaei, A.M.; Fusco, V.; Yurduseven, O. Fourier-based Radar Processing for Multistatic Millimetre-wave Imaging with Sparse Apertures. In Proceedings of the 2022 16th European Conference on Antennas and Propagation (EuCAP), Madrid, Spain, 27 March–1 April 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, L.; Ai, Z.; Shi, J.; Wang, J.; Zhang, X.; Yang, J. Low Computational Complexity SAR Imaging Algorithm for Ship Monitoring via 2-D Band-Limited Sparse Fourier Transform. IEEE Sens. J. 2024, 24, 13326–13342. [Google Scholar] [CrossRef]
- Tan, Y.; Lai, T.; Ou, P.; Dan, Q.; Huang, H. Subaperture Real-time Imaging Algorithm Based on GPU. In Proceedings of the EEI 2022; 4th International Conference on Electronic Engineering and Informatics, Guiyang, China, 24–26 June 2022; pp. 1–9. [Google Scholar]
- Cumming, I.G.; Wong, F.H. Digital processing of synthetic aperture radar data. Artech House 2005, 1, 108–110. [Google Scholar]
- Molaei, A.M.; Fromenteze, T.; Skouroliakou, V.; Hoang, T.V.; Kumar, R.; Fusco, V.; Yurduseven, O. Development of Fast Fourier-Compatible Image Reconstruction for 3D Near-Field Bistatic Microwave Imaging with Dynamic Metasurface Antennas. IEEE Trans. Veh. Technol. 2022, 71, 13077–13090. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, C.; Li, W.; Hu, W.; Wang, P.; Li, H.C. A Deep Collaborative Computing Based SAR Raw Data Simulation on Multiple CPU/GPU Platform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 387–399. [Google Scholar] [CrossRef]
- Wang, Y.; Li, W.; Liu, T.; Zhou, L.; Wang, B.; Fan, Z.; Ye, X.; Fan, D.; Ding, C. Characterization and Implementation of Radar System Applications on a Reconfigurable Dataflow Architecture. IEEE Comput. Archit. Lett. 2022, 21, 121–124. [Google Scholar] [CrossRef]
- Guo, Y.; Davy, A.; Facciolo, G.; Morel, J.M.; Jin, Q. Fast, Nonlocal and Neural: A Lightweight High Quality Solution to Image Denoising. IEEE Signal Process. Lett. 2021, 28, 1515–1519. [Google Scholar] [CrossRef]
- Romano, D.; Lapegna, M.; Mele, V.; Laccetti, G. Designing a GPU-parallel algorithm for raw SAR data compression: A focus on parallel performance estimation. Future Gener. Comput. Syst. 2020, 112, 695–708. [Google Scholar] [CrossRef]
- Imperatore, P.; Pepe, A.; Sansosti, E. High Performance Computing in Satellite SAR Interferometry: A Critical Perspective. Remote Sens. 2021, 13, 4756. [Google Scholar] [CrossRef]
- Zhang, F.; Hu, C.; Li, W.; Hu, W.; Li, H.C. Accelerating Time-Domain SAR Raw Data Simulation for Large Areas Using Multi-GPUs. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 3956–3966. [Google Scholar] [CrossRef]
- Chen, Y.; Feng, W.; Ranftl, R.; Qiao, H.; Pock, T. A Higher-Order MRF Based Variational Model for Multiplicative Noise Reduction. IEEE Signal Process. Lett. 2014, 21, 1370–1374. [Google Scholar] [CrossRef]
- Jin, H.; Chen, J. An efficient wavenumber algorithm towards real-time ultrasonic full-matrix imaging of multi-layered medium. Mech. Syst. Signal Process. 2021, 149, 107149. [Google Scholar] [CrossRef]
- Yu, B.; Jin, H.; Mei, Y.; Chen, J.; Wu, E.; Yang, K. 3-D ultrasonic image reconstruction in frequency domain using a virtual transducer model. Ultrasonics 2022, 118, 106573. [Google Scholar] [CrossRef] [PubMed]
- Hernández-Burgos, S.; Gibert, F.; Broquetas, A.; Kleinherenbrink, M.; De la Cruz, A.F.; Gómez-Olivé, A.; García-Mondéjar, A.; i Aparici, M.R. A Fully Focused SAR Omega-K Closed-Form Algorithm for the Sentinel-6 Radar Altimeter: Methodology and Applications. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–16. [Google Scholar] [CrossRef]
- Shi, H.; Zhang, L.; Liu, D.; Yang, T.; Guo, J. SAR Imaging Method for Moving Targets Based on Omega-k and Fourier Ptychographic Microscopy. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Sun, G.C.; Liu, Y.; Xiang, J.; Liu, W.; Xing, M.; Chen, J. Spaceborne Synthetic Aperture Radar Imaging Algorithms: An overview. IEEE Geosci. Remote Sens. Mag. 2022, 10, 161–184. [Google Scholar] [CrossRef]
- Moreira, A. Real-time synthetic aperture radar (SAR) processing with a new subaperture approach. IEEE Trans. Geosci. Remote Sens. 1992, 30, 714–722. [Google Scholar] [CrossRef]
- Li, Z.; Wang, J.; Liu, Q.H. Interpolation-Free Stolt Mapping for SAR Imaging. IEEE Geosci. Remote Sens. Lett. 2014, 11, 926–929. [Google Scholar] [CrossRef]
- Meng, Y.; Lin, C.; Qing, A.; Nikolova, N.K. Accelerated Holographic Imaging With Range Stacking for Linear Frequency Modulation Radar. IEEE Trans. Microw. Theory Tech. 2022, 70, 1630–1638. [Google Scholar] [CrossRef]
- Cheng, J.; Grossman, M.; McKercher, T. Professional CUDA c Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Chandra, R. Parallel Programming in OpenMP; Morgan Kaufmann: Burlington, MA, USA, 2001. [Google Scholar]
- Huber, J.; Cornelius, M.; Georgakoudis, G.; Tian, S.; Diaz, J.M.M.; Dinel, K.; Chapman, B.; Doerfert, J. Efficient Execution of OpenMP on GPUs. In Proceedings of the 2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 2–6 April 2022; pp. 41–52. [Google Scholar] [CrossRef]
- Aldinucci, M.; Cesare, V.; Colonnelli, I.; Martinelli, A.R.; Mittone, G.; Cantalupo, B.; Cavazzoni, C.; Drocco, M. Practical parallelization of scientific applications with OpenMP, OpenACC and MPI. J. Parallel Distrib. Comput. 2021, 157, 13–29. [Google Scholar] [CrossRef]
- Hoffmann, R.B.; Löff, J.; Griebler, D.; Fernandes, L.G. OpenMP as runtime for providing high-level stream parallelism on multi-cores. J. Supercomput. 2022, 78, 7655–7676. [Google Scholar] [CrossRef]
- Daleiden, P.; Stefik, A.; Uesbeck, P.M. GPU programming productivity in different abstraction paradigms: A randomized controlled trial comparing CUDA and thrust. ACM Trans. Comput. Educ. (TOCE) 2020, 20, 1–27. [Google Scholar] [CrossRef]
- Ansorge, R. Programming in Parallel with CUDA: A Practical Guide; Cambridge University Press: Cambridge, UK, 2022. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Carrier frequency () | 95 GHz |
| Bandwidth (B) | 6 GHz |
| Pulse repetition frequency () | 400 MHz |
| Real aperture (L) | 6.05 m |
| Sampling frequency () | 2.5 MHz |
| Echo signal () | 4610 × 8000 |
| Radar speed | 0.3025 m/s |
| Imaging range (R) | 1 m–4 m |
| CPU | Intel i7-9750H |
| GPU | NVIDIA GeForce GTX 1660 Ti |
| Preprocessing | Data Size | GPU | CPU | Speedup | |
|---|---|---|---|---|---|
| Data reading | col FFT | 4608 × 8000 | 120.05 ms | 1250.02 ms | 10.41 |
| col IFFT | 2304 × 8000 | 39.36 ms | 754.12 ms | 19.14 | |
| Azimuth extraction | col FFT | 8000 × 2304 | 42.95 ms | 1115.06 ms | 25.96 |
| col IFFT | 8000 × 2304 | 46.72 ms | 1133.70 ms | 24.27 | |
| extraction | 4000 × 2304 | 1.18 ms | 120.14 ms | 101.81 | |
| Range extraction | col FFT | 4000 × 2304 | 12.32 ms | 228.68 ms | 18.56 |
| col IFFT | 4000 × 2304 | 9.09 ms | 266.86 ms | 29.36 | |
| extraction | 4000 × 1152 | 2.98 ms | 62.10 ms | 20.84 | |
| Windowing and zero-padding | windowing and zero-padding in the range | 4000 × 1152 | 1.03 ms | 106.10 ms | 103.01 |
| windowing in the azimuth | 4000 × 1728 | 1.2309 ms | 397.262 ms | 322.98 | |
| Platform | Number of Host Threads | Interpolation Time | Algorithm Runtime | Phase Relative Error | Amplitude Relative Error |
|---|---|---|---|---|---|
| Traditional KA | 1 | 29,070.4 ms | 42,021.1 ms | 0 | 0 |
| Real-time imaging scheme | 1 | 571.863 ms | 1149.14 ms | ||
| 2 | 557.582 ms | 1128.71 ms | |||
| 4 | 562.984 ms | 1137.75 ms | |||
| 5 | 572.475 ms | 1136.67 ms | |||
| 8 | 589.447 ms | 1180.59 ms | |||
| 10 | 592.201 ms | 1187.64 ms | |||
| 16 | 605.53 ms | 1194.94 ms | |||
| 50 | 440.388 ms | 1006.49 ms |
| Traditional Interpolation Methods | Dynamic Parallel | Group-Nstream Mode | Fthread-Group- Nstream Mode | |||
|---|---|---|---|---|---|---|
| One-Layer Nested Interpolation | Two-Layer Nested Interpolation | Three-Layer Nested Interpolation | ||||
| Running time | 29,070.4 | 7960.81 ms | 1017.64 ms | timeout | 571.863 ms | 557.582 ms |
| Time complexity | ||||||
| Speed-up | / | 3.65 | 28.57 | / | 50.83 | 52.14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, Y.; Li, G.; Zhang, C.; Gan, W. An Efficient and Accurate Ground-Based Synthetic Aperture Radar (GB-SAR) Real-Time Imaging Scheme Based on Parallel Processing Mode and Architecture. Electronics 2024, 13, 3138. https://doi.org/10.3390/electronics13163138
Tan Y, Li G, Zhang C, Gan W. An Efficient and Accurate Ground-Based Synthetic Aperture Radar (GB-SAR) Real-Time Imaging Scheme Based on Parallel Processing Mode and Architecture. Electronics. 2024; 13(16):3138. https://doi.org/10.3390/electronics13163138
Chicago/Turabian StyleTan, Yunxin, Guangju Li, Chun Zhang, and Weiming Gan. 2024. "An Efficient and Accurate Ground-Based Synthetic Aperture Radar (GB-SAR) Real-Time Imaging Scheme Based on Parallel Processing Mode and Architecture" Electronics 13, no. 16: 3138. https://doi.org/10.3390/electronics13163138
APA StyleTan, Y., Li, G., Zhang, C., & Gan, W. (2024). An Efficient and Accurate Ground-Based Synthetic Aperture Radar (GB-SAR) Real-Time Imaging Scheme Based on Parallel Processing Mode and Architecture. Electronics, 13(16), 3138. https://doi.org/10.3390/electronics13163138