Abstract
In edge–cloud collaboration scenarios, data sharing is a critical technological tool, yet smart devices encounter significant challenges in ensuring data-sharing security. Attribute-based keyword search (ABKS) is employed in these contexts to facilitate fine-grained access control over shared data, allowing only users with the necessary privileges to retrieve keywords. The implementation of secure data sharing is threatened since most of the current ABKS protocols cannot resist keyword guessing attacks (KGAs), which can be launched by an untrusted cloud server and result in the exposure of sensitive personal information. Using attribute-based encryption (ABE) as the foundation, we build a secure data exchange paradigm that resists KGAs in this work. In our paper, we provide a secure data-sharing framework that resists KGAs and uses ABE as the foundation to achieve fine-grained access control to resources in the ciphertext. To avoid malicious guessing of keywords by the cloud server, the edge layer computes two encryption session keys based on group key agreement (GKA) technology, which are used to re-encrypt the data user’s secret key of the keyword index and keyword trapdoor. The model is implemented using the JPBC library. According to the security analysis, the model can resist KGAs in the random oracle model. The model’s performance examination demonstrates its feasibility and lightweight nature, its large computing advantages, and lower storage consumption.
1. Introduction
Since the edge–cloud collaboration scenario is developing so quickly, its data-sharing technology has been applied to the Industrial Internet of Things [1], intelligent transportation systems [2], and the Medical Internet of Things [3]. Additionally, resource-constrained intelligent terminals in the edge–cloud collaboration scenario can realize improved computing power elasticity, and the core data-sharing technology satisfies the entity users in the scenario to carry out high-precision, fast-response, low-latency transmission, and safe information exchange. In an edge–cloud scenario, data users can efficiently lower terminal communication costs and realize resource rationalization by outsourcing data to the cloud server. However, sensitive data are contained in the stored data [4,5,6], and data security is readily jeopardized. As a result, maintaining data security becomes an important and difficult responsibility [7].
Sensitive data must first be encrypted before being uploaded to the cloud to enable secure data sharing in edge–cloud scenarios. Users who meet the requirements for keyword information matching can then access the relevant ciphertext information. Unfortunately, fine-grained access control to cloud-stored data cannot be achieved by using public key encryption with keyword search. This is because when more users access cloud-stored data, the cloud generates a significant volume of private data simultaneously. Additionally, there is a greater frequency of information interaction between data users and the cloud. To access the relevant data, users must jointly negotiate a session key, which consumes a lot of computational power and results in inefficient access authorization from the users. The scheme in [8] suggests using ABE in conjunction with keyword search to address this issue. In this method, the data owner encrypts private information using an access policy, creates a secure index for the keyword, and then, outsources the work to the cloud. Only authorized data users who comply with the access policy can verify the keyword trapdoor on the cloud server. Upon successful verification, the cloud server retrieves the corresponding ciphertext and calculation parameters and sends them directly to the authorized data user for decryption. However, a semi-trusted cloud server that uses protocols with keyword-searchable encryption is vulnerable to internal and external KGAs [9,10]. In these attacks, adversaries with probabilistic polynomial-time capabilities can use the captured query message to learn more about a particular keyword and use that information to launch KGAs during a data user’s search.
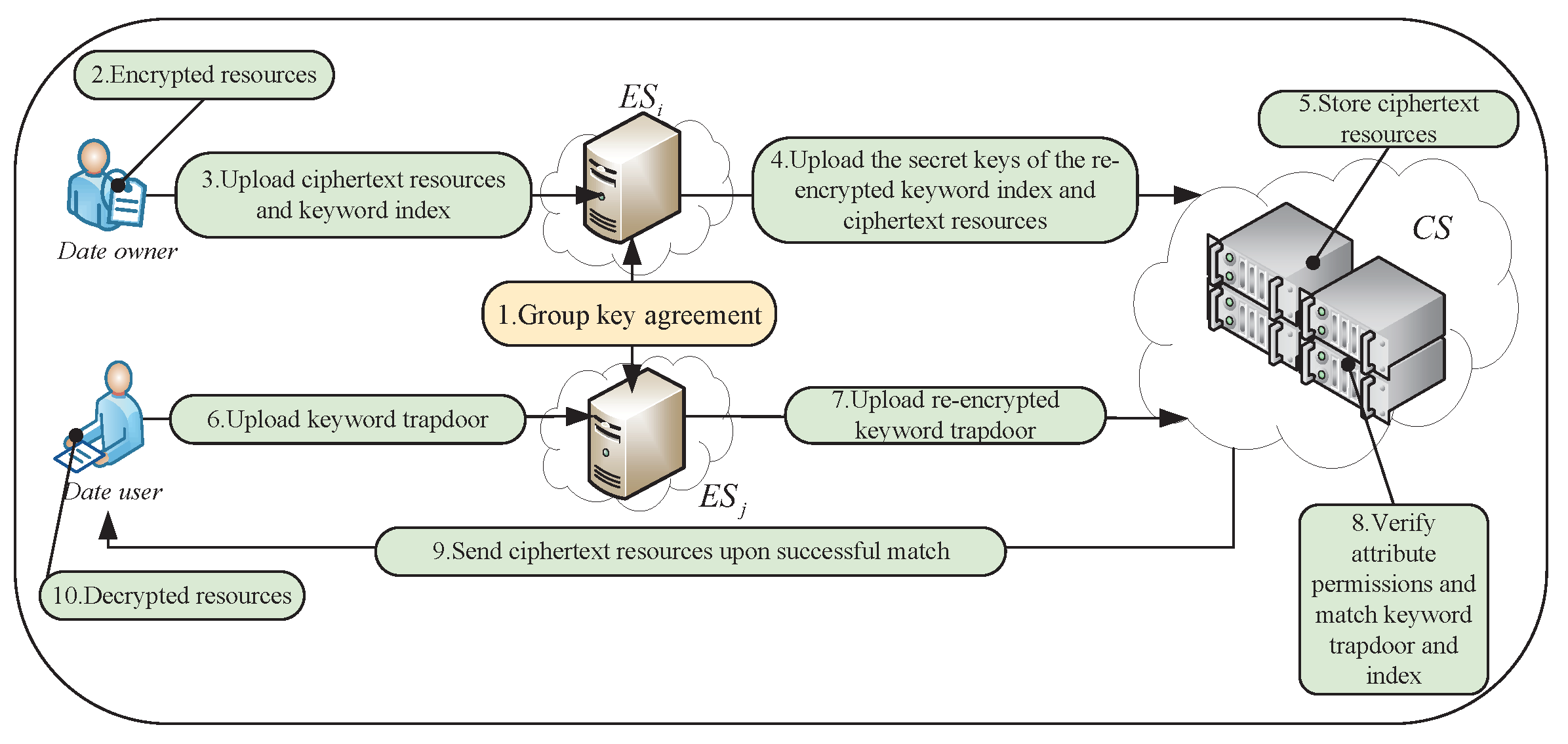
Thus, it is necessary to pay attention to resist KGAs to safeguard the privacy of sensitive data stored in the cloud. This paper aims to tackle the issue of privacy leakage by developing a secure data-sharing model that withstands KGAs in edge–cloud collaboration scenarios. To achieve this goal, the edge layer generates two inversely related session keys based on GKA technology. One is used to re-encrypt the data owner’s secret key of the keyword index to prevent tampering during the upload to the cloud, and the other is used to re-encrypt the keyword trapdoor information to prevent its leakage to the cloud server. The data owner transmits the ciphertext and keyword index parameters to the edge layer, where the edge server managing the domain has the corresponding attribute permissions of the data owner and computes the data user’s decryption key factor based on these permissions. The edge layer uses one of its session keys to re-encrypt the secret key of the keyword index, and then, sends the ciphertext and other parameters to the cloud for secure storage and data sharing. To prevent the cloud server from launching KGAs, the keyword trapdoor is re-encrypted by the edge server managing the domain after the data user computes and sends the keyword trapdoor to it. Only when the keyword trapdoor of the data user, who meets the access policy, successfully matches the keyword index stored in the cloud, does the data user have the authority to access the ciphertext resources. The cloud server searches the ciphertext and sends it along with the decryption key factor to the data user based on their ip address. The data user then uses the decryption key factor and the Lagrange interpolating polynomial to compute the decryption key and decrypt the ciphertext, thereby obtaining the corresponding resources and completing flexible and secure cross-domain data sharing. The re-encrypted keyword trapdoor can resist KGAs initiated by the cloud server in this model and prevent sensitive privacy leakage and tampering. The simplified process of the appeal is shown in Figure 1.
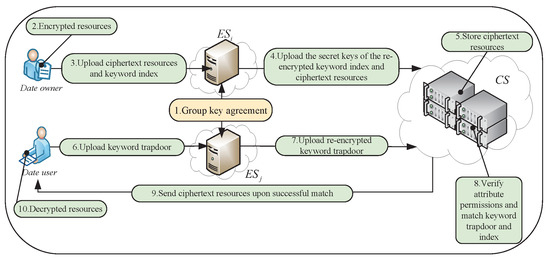
Figure 1.
Simplified process for our model.
2. Related Work
Song et al. [11] were the first to propose the keyword-searchable encryption (SE) technique, which allows data users to securely search ciphertexts stored in the cloud while providing concealed keyword querying. Building on Song’s scheme, Li et al. [12] introduced searchable symmetric encryption (SSE) with forward search privacy. This approach enhances security by enabling the addition of new documents without revealing any information about previous queries, proving to be more effective than previous techniques according to test data. To counteract adversaries with arbitrary background knowledge, Chen et al. [13] developed a framework for SSE systems based on differential privacy approaches, offering verifiable security guarantees. However, experimental investigations have shown that even advanced leakage suppression techniques in SSE schemes are insufficient to defend against new inference attacks. Gui et al. [14] proposed a novel inference attack capable of performing efficient, scalable, and accurate query reconstruction against end-to-end SSE systems, revealing that the existing SSE framework cannot prevent such attacks.
Public-key encryption with keyword search (PEKS) was introduced by Boneh et al. [15] to facilitate data exchange between users. In this scheme, the data provider encrypts the chosen keyword within the ciphertext before outsourcing it to the cloud for storage. The data user generates a list of keywords, searches for them on the cloud server, and utilizes a test function in the cloud to verify the presence of the keywords in each ciphertext. If a match is found, the corresponding ciphertext can be returned to the data user. With this technique, security and privacy could be readily jeopardized if the cloud server is hostile. Most current PEKS systems cannot simultaneously achieve high search efficiency and robust security. To address this challenge, Chen et al. [16] proposed a method for parallel and forward private searchable encryption with cloud data sharing. This approach ensures forward privacy and parallelism, with experimental results demonstrating its effectiveness and applicability. Through comparative analysis and experimental results, Lu et al. [17] proposed an effective PKES scheme featuring flexible keyword-free domain multi-keyword search, and forward ciphertext retrieval. This scheme effectively guards against KGAs and unauthorized ciphertext retrieval, demonstrating security in the random oracle model and outperforming existing schemes. Cheng et al. [18] introduced a server-assisted public-key authentication searchable encryption scheme with constant ciphertext and constant trapdoor sizes, combining sender and receiver servers. In this scheme, the sender only needs to encrypt the keyword once, and the constant sizes of the ciphertext and trapdoor ensure scalability, enabling multi-scenario applications.
Bethencourt, Sahai, and Waters [19] initially introduced ABE with a ciphertext policy to establish access control for cloud data. In this approach, data users determine access based on the specified access policy. Goyal [20] proposed a key-policy attribute-based encryption (KP-ABE) method, featuring a key-associative access control structure. Waters et al. [21] later introduced a ciphertext-policy attribute-based encryption (CP-ABE) approach, enabling one-to-many fine-grained sharing. Subsequently, numerous traditional ABE systems and variations were proposed [22]. To prevent dishonest searches by the data user’s cloud, Zheng and Xu et al. [23] proposed VABKS (verifiable attribute-based keyword search) for outsourced encrypted data. This method can verify whether the cloud has performed honest searches. Combining ABE with SE, ABSE offers advantages over traditional PKES. However, as the cloud is not entirely trustworthy, Liu et al. [24] proposed a key-policy attribute-based searchable encryption (KP-ABSE) method to enhance practicality. This approach can successfully verify the accuracy and integrity of data files stored in the cloud. Since the cloud holds a public key for re-encrypting keyword ciphertexts, it can effectively fend off offline KGAs. Nevertheless, hostile adversaries can fabricate the cloud’s public key, compromising user data privacy.
Liang and Susilo [25] employed attribute-based proxy re-encryption capabilities and ABKS to facilitate data sharing and keyword upgrading. The approach verifies that it is chosen-ciphertext-safe in the random oracle and guarantees that the ciphertexts’ keyword search functionality can be maintained after ciphertext sharing. A verifiable keyword search for encrypted cloud data in smart cities was proposed by Miao [26]. This allows the data user to confirm the search results and also demonstrates the security of the scheme against targeted keyword attacks (CKAs). A verified attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud was proposed by Sun et al. [27] Multiple data owners and users are supported by this method. Large-scale systems may scale more easily thanks to the user owner’s enforced search authorization, and the user revocation process is more effective and resilient to targeted keyword attacks.
Cui et al. [28] proposed an attribute-based keyword search with an effective revocation scheme (AKSER). AKSER achieves fine-grained authorization of search under a distributed multi-attribute authority institution. It also ensures keyword semantic security, keyword confidentiality, trapdoor unlinkability, and collision resistance. In contrast to ciphertext-policy attribute-based encryption schemes, Wang et al. [29] introduced the first hierarchical attribute-based encryption scheme for document collections, which uses fewer ciphertext storage resources. They also developed a depth-first search algorithm for ARF trees, enhancing search efficiency, which can be further improved through parallel computing. The search algorithm only requires one keyword to be the same in two keyword sets to output the corresponding correlation, reflecting the number of identical keywords in these sets. Meng et al. [30] proposed an attribute-based encryption and dynamic keyword search method in fog computing that shifts the majority of computational overhead from resource-constrained users to fog nodes, reducing the computational load on the endpoints. Current CP-ABKS methods are designed for non-shared multi-owner configurations and are not immediately applicable to shared multi-owner configurations.
To improve monitoring of hostile users for selective security and resistance to offline keyword guessing attacks, Miao et al. [31] presented privacy-preserving attribute-based keyword searches in shared owner settings. Most earlier techniques are vulnerable to offline KGAs when the keyword space is polynomial. To address these issues, Zhang et al. [32] proposed an attribute-based encryption scheme with searchable and verifiable multiple keywords based on cloud data. Their experimental results demonstrate the scheme’s effectiveness, achieving selective security against offline keyword guessing attacks and ensuring the unforgeability of signatures.
Li et al. [33] proposed an attribute-based keyword search strategy that prevents keyword guessing attacks by signing the keyword with the data owner’s private key before generating the keyword ciphertext. To combat data tampering, Zhang et al. [34] introduced a blockchain-based anonymous attribute searchable encryption scheme for data sharing. This scheme leverages blockchain technology to conceal the attributes of the access policy while ensuring tamper resistance, integrity verification, and non-repudiation. Experimental results demonstrate the scheme’s practicality and efficiency. Ge et al. [35] proposed an attribute-based proxy re-encryption scheme with a direct revocation mechanism for data sharing in the cloud. This mechanism allows the cloud server to directly revoke users in the original shared set involved in the re-encryption key. Additionally, Ge et al. [36] proposed a secure keyword search and data-sharing mechanism for cloud computing, addressing the need for users to quickly search and return results without compromising data confidentiality. This mechanism supports attribute-based keyword search and attribute-based data sharing simultaneously, and it has been shown to be secure against chosen-ciphertext attacks in random oracle models and CKAs.
Upon perusing the above references, it is evident that researchers have made significant contributions to the attainment of secure data sharing. However, there exist certain limitations. Specifically, the majority of schemes are susceptible to KGAs, and in the event of a probabilistic polynomial-time adversary of a semi-trusted cloud server, they can obtain specific keyword information through the captured query information, thereby compromising privacy. In the edge–cloud collaboration scenario, we propose a secure data-sharing model based on an anti-keyword guessing attack to counter the appeal attack. The model is lightweight and highly appropriate for resource-constrained smart terminals, as it achieves resistance to keyword guessing attacks through key negotiation at the edge layer, and safe in terms of privacy for end users. Comparative investigations indicate that this model performs better than existing schemes.
Methodology
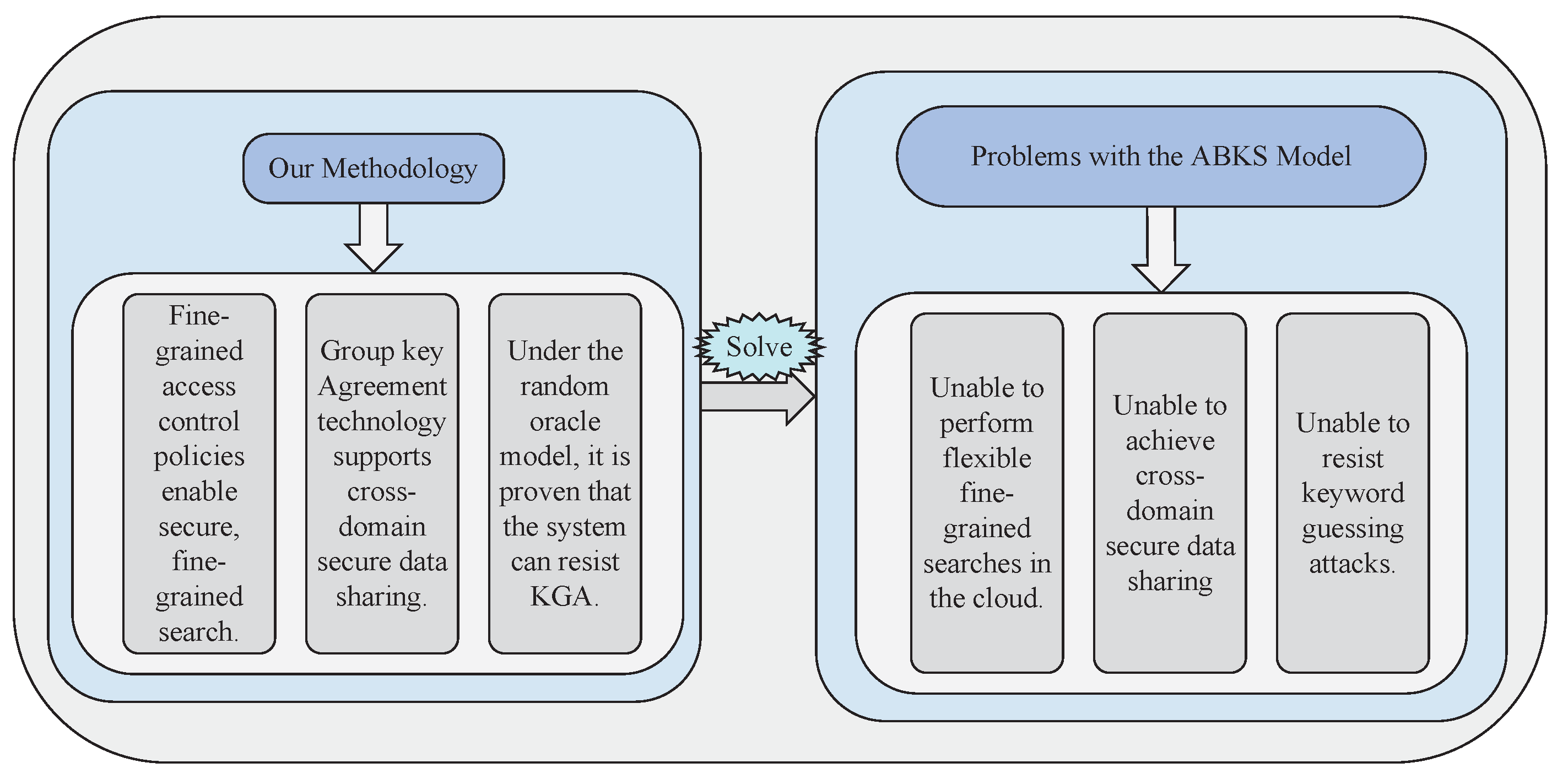
We propose a secure data-sharing model that resists keyword guessing attacks in edge–cloud collaboration scenarios (SDSM-KGA). The methodology of this paper is as follows, and the problems addressed are illustrated in Figure 2.
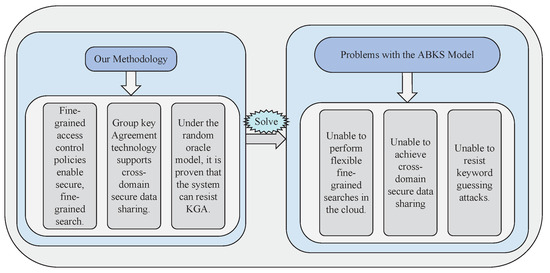
Figure 2.
Problems solved by the methodology.
- (1)
- This paper extends the traditional attribute-based keyword search (ABKS) model by proposing a new flexible, fine-grained access control mechanism. This mechanism allows data users with identical attribute permissions to perform fine-grained searches on ciphertext based on specific access policies, enabling flexible and secure data sharing. If a data user’s attribute permissions do not meet the requirements of the access policy, they are not able to access the shared ciphertext. This access control strategy enhances the efficiency and security of data sharing among users.
- (2)
- The ABKS model we propose supports cross-domain data sharing and can effectively resist KGAs initiated by cloud servers. In traditional models, keyword trapdoor information is public in the cloud, and is therefore vulnerable to attacks by external attackers or malicious cloud servers. To prevent such attacks, we implement a key negotiation method at the edge layer. This allows the edge layer to re-encrypt the keys of the data owner’s keyword index and keyword trapdoor key stored in the cloud to prevent other entities from identifying them.
- (3)
- We define a new security model and prove its ability to resist KGAs under the random oracle model, and implement our scheme using the JPBC library. The experimental evaluation proves the practicality and high performance of the scheme compared with other traditional schemes.
3. Basic Knowledge
3.1. Bilinear Map
Let be an additive group and g be a generator. represents a multiplicative cyclic group. and have the same prime order q. We can say is a bilinear pairing if it meets the following properties:
- (1)
- Bilinearity: For all and , we have .
- (2)
- Non-degenerate: , .
- (3)
- Computability: ; there exist efficient algorithms in polynomial time that can compute the .
3.2. Access Structure
Let denote the set of participants, and let . For , if and , then . If is a non-empty subset of , then is called an access structure. For any set D, if , then D is an authorized set; otherwise, it is an unauthorized set.
3.3. Linear Secret-Sharing Scheme
The set of participants is , where the access structure is . Here, M is a matrix with n rows and m columns. For all , is a mapping function that maps each row of the matrix to different attributes. If satisfies the following conditions, then is a linear secret-sharing scheme (LSSS) defined over P.
- (1)
- Given a secret value , randomly select ; construct the column vector . Then, compute , where represents the secret share held by .
- (2)
- There exists a set of vectors such that . The secret value s can be reconstructed as , where are valid secret shares of the secret value.
This scheme is based on the algorithm idea of scheme [37], using the elements in the access matrix to encrypt the information, and decrypting according to , which can ensure that .
3.4. Decisional Bilinear Diffie–Hellman Assumption
Considering the bilinear mapping elements and random elements , we see that adversary is unable to discriminate between the tuples and , where Z is chosen at random from . Consequently, there is no probabilistic polynomial time (PPT). The advantage of in resolving the DBDH problem is described as follows, assuming the following equations hold.
3.5. Security Model
Init: The simulator ensures that the keyword index secret key remains secret. The value is sent by to the attacker . Attacker challenges the access structure and randomly selects attributes to form a set , which is then sent to the simulator . The simulator computes the corresponding attribute permissions and sends them to . The attacker subsequently computes the attribute permission key for the challenge.
Phase 1: executes a polynomially limited number of queries in an adaptive manner, which means that each query may depend on the response to previous queries.
- (1)
- Attribute permissions secret-key extraction query: chooses an attribute permissions secret key , then sends to simulator to verify whether the private key is legal or not; the verification succeeds in computing the key , then runs the re-encryption attribute permissions private key to obtain , and then, returns to .
- (2)
- Keyword trapdoor extraction query: randomly selects a keyword from the keyword dictionary, then sends to ; simulator calculates the keyword trapdoor of the searchable keyword , then runs to re-encrypt the trapdoor and returns to .
Challenge: decides when the first stage will end. generates two keywords and of the same length that it wants to be challenged. The simulator randomly selects bits , computes the trapdoor for keyword as , and then, runs the re-encryption trapdoor to obtain . re-encrypts the attribute permissions private key to obtain , and sends as the challenged parameters to . If the encryption of the trapdoor for the target keyword fails, then aborts the game.
Phase 2: can make a polynomially bounded number of adaptive queries as in phase 1, except that it cannot make private-key extraction queries and trapdoor extraction queries for and .
outputs the result , if will win the game. We define the advantage of in attacking the scheme as .
4. System Model and Initialization
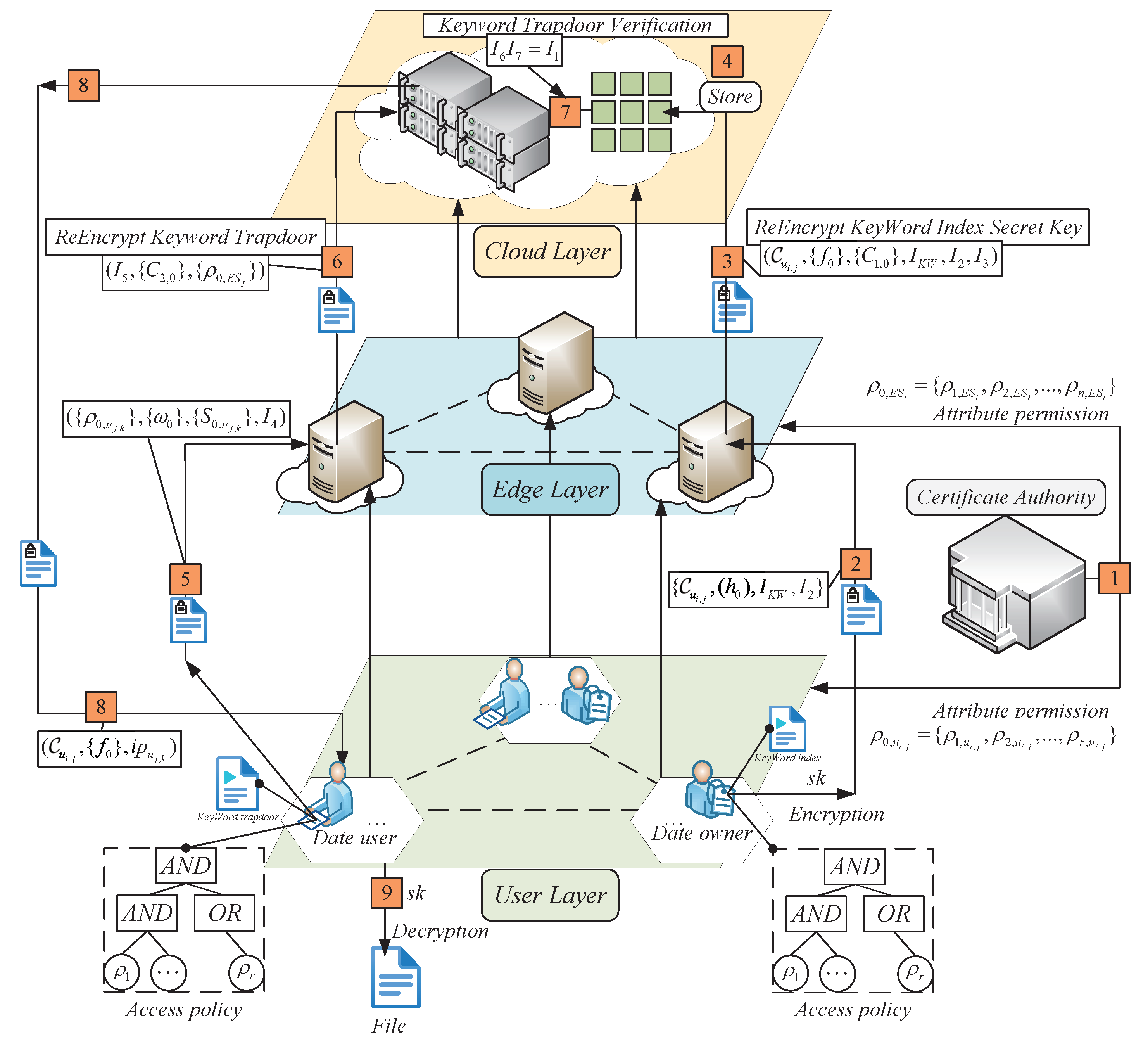
In this paper, we propose a secure data-sharing model to resist keyword guessing attacks in the edge–cloud collaboration scenario. The system model is shown in Figure 3, which mainly has certification authority, cloud layer, edge layer, and data user layer.
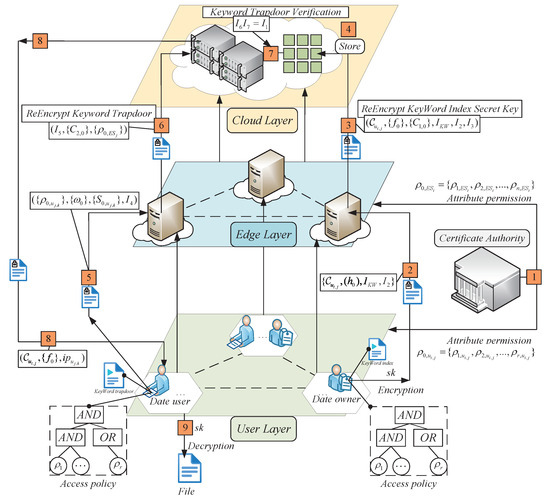
Figure 3.
System model.
4.1. System Model
CA Authentication Center: The center is responsible for implementing system parameter settings, generating the system’s master and public keys, registering user attributes, determining attribute permissions, and distributing attributes to data users and edge servers.
Cloud service layer: Comprised of a cloud server, the primary purpose of this layer is to store and validate the private key and re-encrypted keyword trapdoor data sent by the edge layer. Upon successful verification, ciphertext resources are sent to data users who comply with the access policy. This layer also offers higher storage capacity, high scalability, and flexibility, while handling complex calculations and tasks from the edge layer and providing a secure channel for data sharing.
Edge layer: The edge layer primarily handles the negotiation of session keys, one is used to re-encrypt the data owner’s secret key of the keyword index to prevent tampering during the upload to the cloud, and the other is used to re-encrypt the keyword trapdoor information to prevent its leakage to the cloud server. This layer facilitates collaborative computation, enhances data resource-sharing security, and reduces processing times. By decreasing latency and improving security, it ensures efficient collaborative computation.
User layer: This layer consists of mobile data users and data owners. The data owner is the one who uploads the shared resources. For a data user to access the decrypted key factor and ciphertext resources, their attribute permission set must match the access policy. Additionally, only when the keyword index and trapdoor are successfully verified by the cloud server will ciphertext resources be accessible.
4.2. System Initialization
The CA authentication center generates a bilinear mapping , where is an addition group, is a multiplicative cyclic group, the prime order is q, and g is a generating element of . Then, it selects a random number , and computes , where is the CA’s public/private key pair, and the CA selects a hash function , and the CA sets the system’s public parameters .
4.3. System Entity Key Generation
Assume there are N edge servers , each edge server manages the corresponding domain and the number of data users in each domain is at most n. For example, data user is the j-th user in the i-th domain, and the identity set of data users in the i-th domain is . Using data user who is controlled by edge server as an example, the CA broadcasts system parameters in the following ways:
- 1.
- The data user , whose identity is , receives the system parameters that the CA broadcasts, chooses a positive number at random, computes public key and . After that, the CA receives argument .
- 2.
- After receiving the parameter , the CA checks whether the public key and the user’s identity correspond using equation to verify its legitimacy. If valid, the CA publishes the valid public key of . The procedure mentioned above provides the identified public-key information to the data user , enabling them to create their own public/private key pair .
The process of creating the public/private key pair for the cloud server (CS) and the edge server is the same. The entity’s CS generated the public/private key pair through the above process. The of the i management domain generated the public/private key pair .
4.4. Acquisition of Data User Attribute Permissions
For network resource access, the CA authentication center defines the system attribute set . The attribute serial number corresponding to each attribute is . It also generates the corresponding attribute parameter for each attribute to form the attribute parameter set , and the terminal members receive the attribute set that is available for authentication. Assuming that the attribute set of is expressed as , where , attribute registration for arbitrary terminals and acquisition of attribute privileges are as follows:
- 1.
- When carrying out the process of attribute authentication, the terminal obtains the set of authentication attributes announced by the CA, randomly chooses , computes , , ,…,, as the signature message, , where , and then, sends the parameters to the CA.
- 2.
- After receiving the parameters from , the CA computes ,…, and , ,…, by comparing the sets and to see if they are equal; the CA can determine the set of attributes and the corresponding attribute sequence numbers of the attributes . The CA computes , verifies the signature of by Equation , and determines whether the equation is valid. The CA can determine the set of attributes has, and the CA selects the corresponding attribute parameters according to the corresponding attributes to compute for the set of attribute authority factors for the set , …, . The CA chooses randomly, computes , , and then, sends the parameters to .
- 3.
- receives the public parameters sent by the CA, computes , verifies if the CA’s signature is valid through equation , accepts the parameters if valid, and then, calculates the attribute permissions through the attribute factor , . Thus, the set of attribute permissions is , where . The attribute permissions set corresponds to the attribute set .
The edge server is specialized and is considered to have all the attributes of the system attribute set as well as the attribute sequence numbers corresponding to the attributes, and all the attribute permission sets are obtained according to the above process, where . The CA carries out the division of the management domain according to the address of and the of the edge server .
4.5. Edge Server Session Key Establishment
Each edge server in the system manages different domains. In order to enable secure cross-domain data access, the edge servers use a ring data structure. This structure facilitates the negotiation of the session private key and the calculation of the inverse session private key by the edge server based on GKA technology. Each edge server is connected to its neighboring edge servers, and authentication is performed through signing and calculating the session key factor. The specific steps are as follows:
- 1.
- Using the edge server as an example, computes the session factor about the key to the neighboring edge server . randomly selects , and computes parameters , , , and the signature . The parameter set is sent to the edge server .
- 2.
- Edge server receives the parameters , computes and verifies the signature through equation , if the equation holds computes the session key factor , in which . randomly selects and computes .
- 3.
- Following the steps of the appeal, sends message to . Then, computes , where , verifies the signature by equation , and if the equation holds computes as the session key for the system edge servers layer, then sends the parameters to the corresponding edge servers based on the address. When the edge servers have all accepted the parameter to compute , there exists .
5. The Construction of Our Model
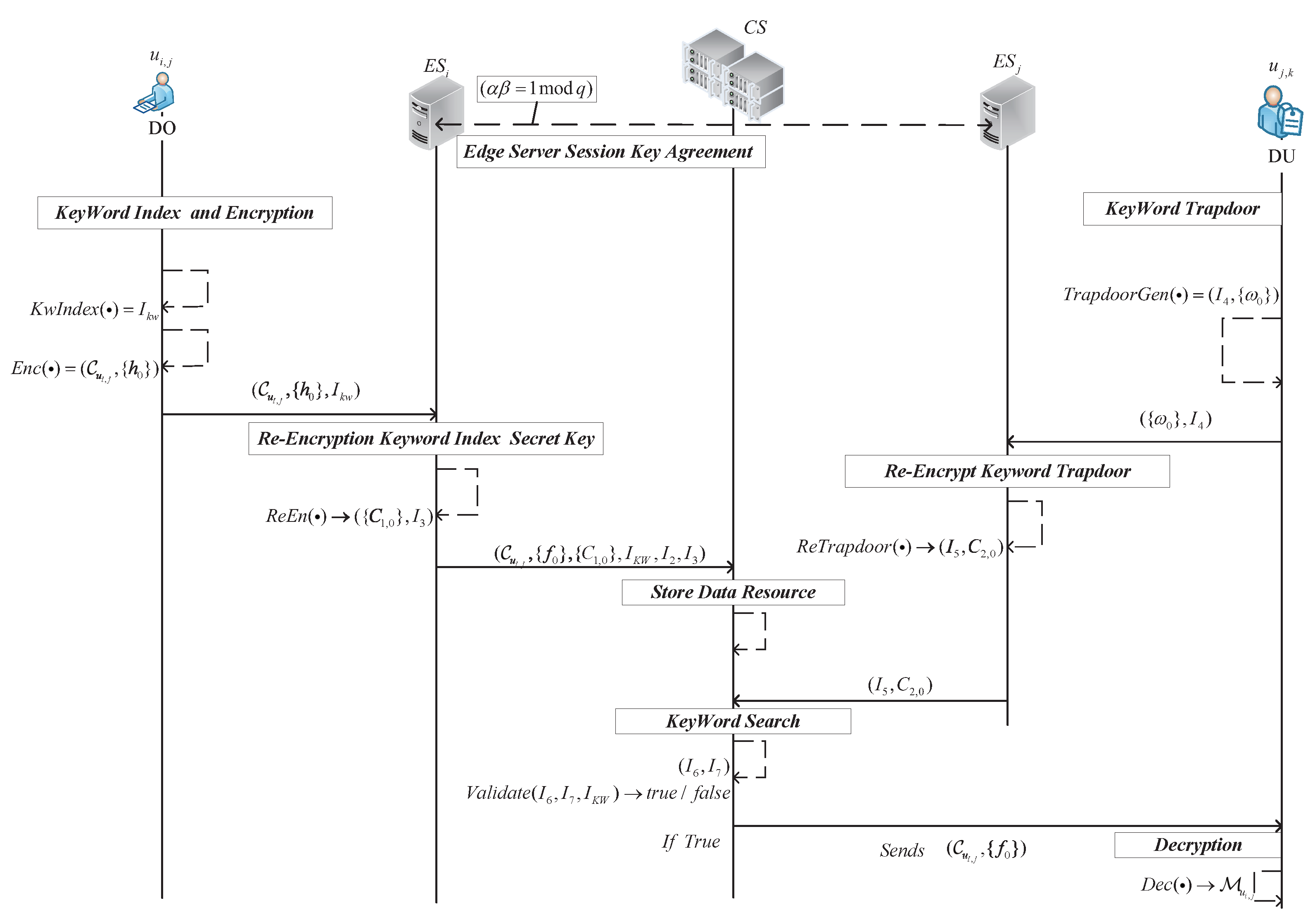
Taking the data owner in the management domain of the edge server as an example, the related algorithm interaction process is depicted in Figure 4.
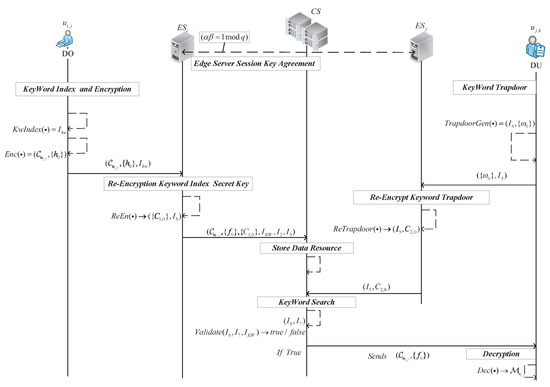
Figure 4.
Interaction process of different SDSM-KGA algorithms.
5.1. Keyword Index Generation
: If the data owner wants to share the data , randomly selects a keyword from the keyword dictionary . The keyword is the extraction information of the shared data . computes , where is the universal element of set that satisfies the access policy, the attribute permissions secret key . randomly selects and computes the signature parameters , . The keyword index of is , with as the secret key of the keyword index.
5.2. Data Owner Encryption
: Data owner computes . According to Section 3.3, randomly selects to combine into secret vectors . to encrypt the plaintext message , to obtain the ciphertext . computes the share of the randomized secret value from this matrix , the secret key of the keyword index share parameter and the signature information and . The attribute sequence number is , whose parameters will be sent over a secure channel to the edge server that manages the domain .
5.3. Edge Server Re-Encrypts Secret Key of Keyword Index
: When the edge server receives the parameters , it computes , determines whether the equation is valid by , and accepts the parameters if it is valid, and computes , . obtains the corresponding attribute permissions based on the set of permission numbers sent by to access the ciphertext, constructs a polynomial of degree , and then, substitutes the attribute values into the polynomial . Respectively, obtains the r function value , the encryption factor of the key reconstruction. re-encrypts the secret key of keyword index and re-encrypts the secret key of keyword index share . Then, randomly selects and computes and . Then, sends the parameters to the cloud server for storage.
5.4. Cloud Server Ciphertext Resource Store
The cloud server receives the parameters , computes and verifies the equation . If the equation holds, stores the ciphertext and keyword index.
5.5. Data User’s Trapdoor Generation
: Taking the data user demander in the management domain of as an example, assume that has the attribute permission of and the corresponding attribute sequence of . According to the corresponding access policy to obtain the matrix M, according to Section 3.3, we can obtain ; obtains . computes and attribute permissions secret , , where is the universal element of set that satisfies the access policy. randomly selects and computes . Then, selects the keyword from the keyword dictionary and computes the parameter of the keyword trapdoor . The signature information is , sends the parameters , , , to the edge server managing the domain .
5.6. Edge Server Re-Encrypts Keyword Trapdoor
: according to the serial number to find the corresponding attribute permissions, and then, computes based on the serial number sent. If the equation holds, re-encrypts the keyword trapdoor and the keyword index secret-key share parameter , . computes parameters and . Then, sends parameters to the .
5.7. Cloud Server Keyword Search
: After the receives parameters , the computes if the equation is true. And, if it is true computes and . matches the keyword trapdoor information by equation . verifies if the equation holds true, if the equation holds it means that the keyword information is matched successfully. Then, the retrieves the corresponding ciphertext resources and computes , the ciphertext parameters are sent directly to through the .
5.8. Data User Decryption
: After receiving the parameters , decrypts and computes . By verifying the equation , if true, the decryption key is then computed. uses the encryption key factors of , along with the attribute permissions it possesses, and parameters , where (for ). For data users who satisfy the access policy, based on the Lagrange interpolation theorem they reconstruct the polynomial using the parameters and the equation , where . The polynomial is reconstructed. serves as the decryption key for the shared resource. The data user decrypts the resource as to obtain the plaintext data.
6. Security Analysis
This scheme proposes a cross-domain secure data-sharing model to resist keyword guessing attacks. To demonstrate the correctness and security of the model, this section discusses the security analysis of the model.
Theorem 1.
If a probabilistic polynomial-time (PPT) adversary can break the KGA security of our scheme with non-negligible advantage, then the simulator can break the assumption of the DBDH problem with advantage ε.
Proof of Theorem 1.
We are assuming the existence of an adversary that can break our protocol in polynomial time t by a non-negligible advantage in the IND-KGA security model; we construct a simulator to solve the DBDH problem. Given an instance of the problem on a bilinear pair of groups , where g is a generator of an additive group , is randomly chosen, and let be a random bit 0 or 1, when , Z in this case can be equal to and when , Z is a random element in ; the interaction between the challenger and the adversary is as follows.
Init: Initialize the secret key of the keyword index as ; the challenger enters the public parameters to send to the attacker ; the attacker selects the challenge access structure and the set of challenged attributes to send to ; randomly selects and computes the attribute permissions , and sends them to .
Phase 1: can query oracles that can be simulated by as follows.
Hash query: The adversary performs a private-key hash query in this phase, the attacker computes the attribute permission secret key , using j to represent the number of queries, where and , where and represent the number of queries to the random oracles and , respectively. The simulator creates two hash lists to record all queries and responses, and the hash lists are initialized to be empty.
- 1.
- Let the j-th query of be ; if the hash list already has corresponding options, the simulator answers the query according to the hash list; otherwise, the simulator randomly chooses , tosses a biased coin where , where , and when , set ; when , . The simulator then marks as the should for that query and adds the corresponding tuple to the hash table.
- 2.
- The adversary randomly selects keyword from the keyword dictionary for each query; if there is already an item corresponding to in the hash list, simulator answers the query based on the hash list; otherwise, simulator randomly selects (the k-th query of is , when , ; when , ), and adds the tuple to the hash list.
Attribute permissions secret-key extraction query: The adversary performs private-key interrogation in this phase. queries the attribute permissions secret key of such that is the corresponding tuple; it randomly tosses a coin and aborts if ; otherwise, according to the simulation process, and computes , so that is a valid intermediate parameter, and randomly choosing , computes the re-encryption attribute permissions secret key and adds to this tuple .
Keyword trapdoor extraction query: The adversary makes a keyword trapdoor query in this phase to respond to the keyword trapdoor extraction query; the simulator maintains a list keyword trapdoor ; selects the keyword to be queried, and if , aborts; if , the simulation process calculates that , and therefore, is a valid trapdoor corresponding to the keyword, and selects , where , and re-encrypts the keyword trapdoor . adds to that tuple .
Challenge phase: Challenge phase: the adversary selects two equal-length keywords and a challenge attribute permission secret key in the hash list, corresponding to the tuple , if , it reports a failure and an abort; otherwise, if , it can obtain . corresponding to the tuple , corresponding to the tuple , and the simulator randomly selects again, and if , the simulator reports a failure and an abort; if , the simulator can compute the challenge keyword information as , where . If we make , we can compute , then we can obtain the challenge keyword trapdoor information , and therefore, this challenge keyword parameter is the correct parameter corresponding to the attribute permission and keyword trapdoor information .
Phase 2: can adaptively interrogate queries for a polynomial a bounded number of times as in phase 1, but it cannot perform an attribute permissions secret-key extraction query for and a keyword trapdoor extraction query for and , where .
Guess: Adversary outputs a guess about the result of , , the simulator outputs ; otherwise, it outputs . We use to denote that the simulator reports failed and aborted events during the game, and from the process above we can see that there are two cases: denotes that reports failed and aborted events during attribute permissions secret-key extraction queries and keyword trapdoor extraction queries, denotes that reports failed and aborted events during the generation of challenge permissions during the challenge phase and during the challenge trapdoor, , because of . It can be computed when , . It can be shown that the probability is non-negligible. □
The time cost of the simulation process is . According to Equation (1), the probability that the simulator can solve the DBDH problem is . If is non-negligible, simulator will be able to solve the DBDH problem with . Since the DBDH problem is difficult, no attacker can break the IND-KGA security of our protocol.
7. Performance Analysis
In this section, we evaluate the performance aspects of the scheme, which we compare with the most advanced schemes [30,31,32,33,38,39,40,41]. We evaluate the performance of our scheme. In terms of theoretical performance, we mainly analyze the aspect of computational complexity. Then, we perform experimental comparisons using real datasets to demonstrate the feasibility and effectiveness of our scheme.
7.1. Functional Comparison
Before analyzing the performance of our scheme, we first compare the functionality of our scheme with several state-of-the-art schemes in Table 1. All the schemes in Table 1 satisfy fine-grained keyword search; Refs. [30,33,38] are based on the structural construction of an access tree, Ref. [39] is based on the structural construction of a hidden AND-tree; Ref. [32] and the present scheme are based on the structural construction of LSSS; all the schemes are efficient in terms of expressiveness. Refs. [30,32,39] cannot resist keyword guessing attacks; Refs. [30,33,38,39] cannot realize cross-domain data sharing; and only the present scheme supports resisting keyword guessing attack and cross-domain data sharing of the above schemes.

Table 1.
Functional comparison of various schemes.
7.2. Theoretical Performance
The existing schemes’ computational times and storage costs are shown in Table 2 and Table 3, respectively, taking into account certain time-consuming operations. The bilinear pairing operation is denoted by , the point addition operation is denoted by in the additive group , and the exponential operation is denoted by in the multiplication cyclic group . In addition, we consider to denote the length of an element in , and denotes the length of an element in group ; denotes the size of an element in group .
Table 2.
Computational costs in various schemes.
Table 3.
Storage costs of various schemes.
Key generation: Data users in our scheme need to obtain public and private key pairs and attribute permissions, and our scheme has a very significant reduction in computational overhead compared to the schemes in [31,32,38,39,40,41]. The data user obtains the corresponding attribute privileges by CA authentication computation for randomly selected attributes from the attribute collection, and our scheme significantly outperforms the compared schemes. Our scheme has slightly higher storage overhead compared to the scheme in [41], but it is superior to the schemes in [31,32,38,39,40]. It offers certain advantages in terms of storage overhead and shows significant advantages for data users with limited resources.
Encryption: Our scheme has a similar computational cost to the schemes in [38,40]. However, compared to the schemes in [31,32,39,41], our scheme has a lower overhead cost, making it more suitable for resource-constrained terminal devices. The storage overhead of our scheme is better than that of the schemes in [38,41], but higher than that of the schemes in [31,32,39]. However, since most of the storage overhead in our scheme is handled by the edge server, it does not impose any additional resource burden on data users.
Trapdoor generation: Our scheme has a lower overhead cost compared to the schemes in [31,32,38,39,40,41], because the trapdoor is generated based on the number of attribute permissions of the attribute endpoints that satisfy the access structure. In contrast, the schemes in [31,32,39,40] require exponential operations, the scheme in [38] requires exponential operations, and the scheme in [41] requires exponential operations. The storage cost of our scheme is slightly higher than that of the schemes in [31,32,39,41], but better than the schemes in [38,40]. Additionally, at this stage our scheme offloads part of the computation to the edge server, thereby reducing the actual storage costs for data users.
Keyword search: Our scheme’s efficiency in the search phase is comparable to the schemes in [38,41], but significantly better than the comparison schemes in [31,32,39,40]. This is because those comparison schemes incur time overhead due to bilinear pair operations, whereas our scheme only requires r bilinear pair operations, resulting in less overhead during the verification process. In terms of storage overhead, our scheme is on par with the comparison schemes in [31,32,39], and all are lower than those of the schemes in [38,40]. Although the scheme in [41] has certain advantages, our scheme performs searches in the cloud, ensuring that no extra storage space is occupied.
Decryption: In our scheme, data users decrypt based on an interpolated polynomial reduction key during the decryption process. The time overhead in this phase is highly efficient compared to the comparison schemes in [31,32]. Although it is higher than the scheme in [40], the computational overhead remains acceptable. Our scheme has the same storage overhead as the comparison scheme in [32], is lower than the schemes in [31,38], and is slightly higher than the scheme in [40]. Additionally, it does not incur any extra storage overhead.
7.3. Actual Performance
In this section, we tested on an Android device with 8.0 GB + 2.0 GB (HONOR RAM Turbo) of RAM and 256 GB of storage space, using the JPBC encryption library (version JPBC-2.0.0) in Java to measure the computational time for the processes used, as shown in Table 2 and Table 3. The process of testing the algorithm time is divided into two steps. First, the APK file is generated in Android Studio, and then, the APK file is run on the Android phone to obtain the corresponding algorithm time. The obtained calculation data are shown in Table 4.
Table 4.
Time of operation execution.
We consider = 128 bit to denote the length of the elements in , 512 bit to denote the length of the elements in , = 512 bit to denote the length of the elements in , and for ease of description, we assume that the range of the attributes is . In this paper, we show the performance characteristics of some of the main algorithms, key generation, encryption, trapdoor generation, keyword search, and decryption.
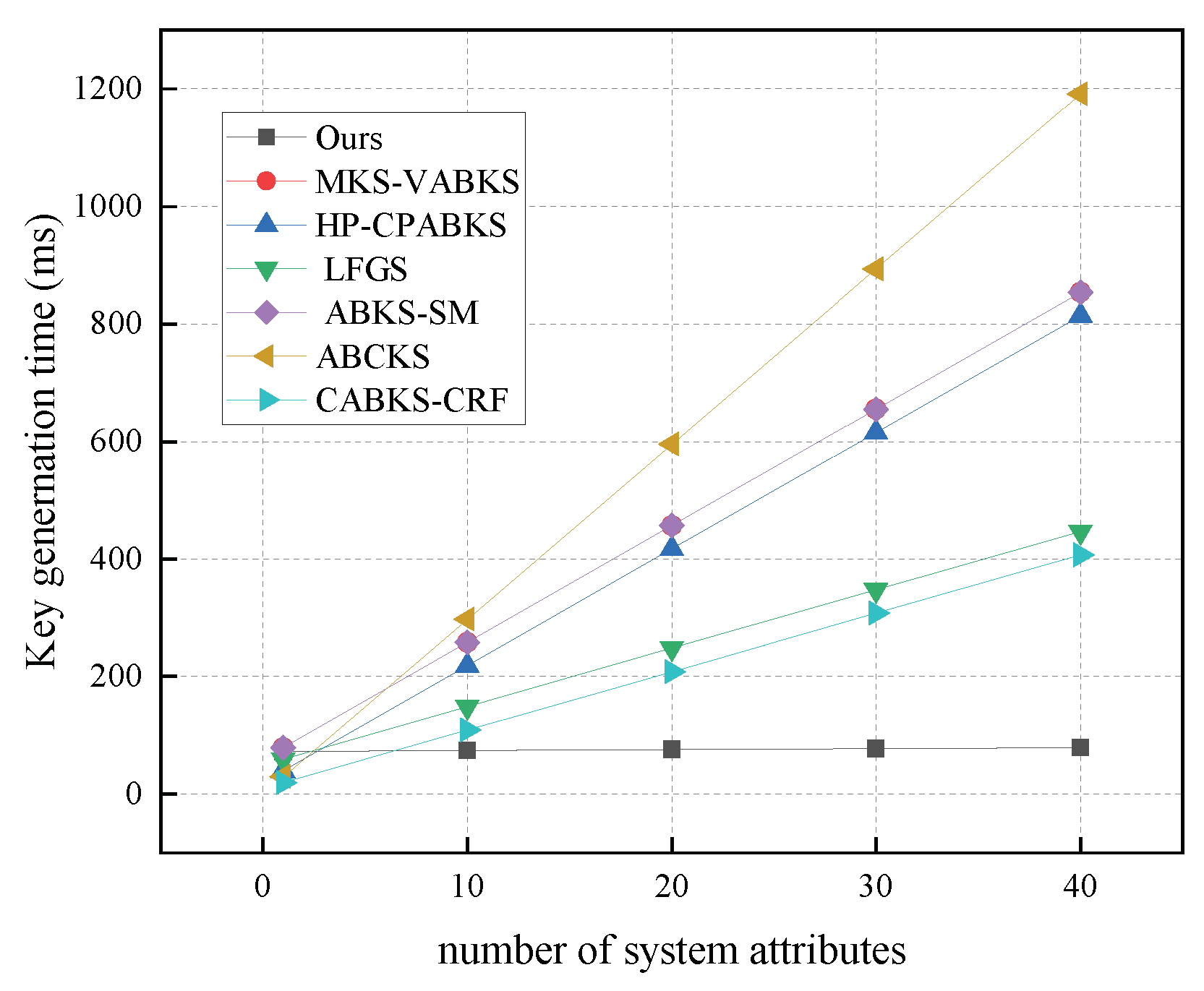
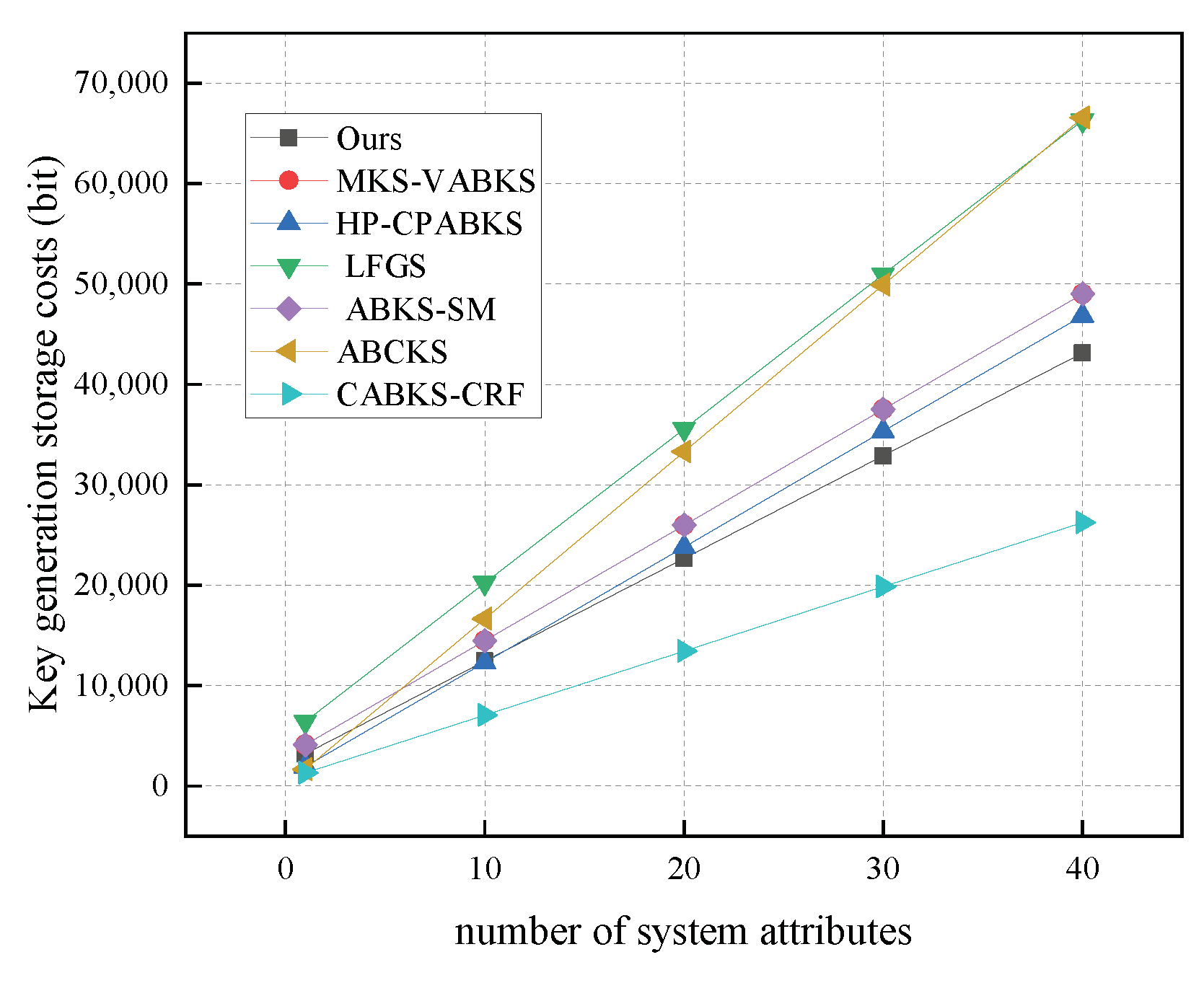
In Figure 5, we present the computational costs of key generation algorithms, illustrating variations in time consumption across the comparison schemes with r set to 10, 20, 30, and 40. When the number of attributes is 40, our scheme consistently exhibits the lowest computational cost, approximately 78.75 ms. In contrast, the time consumption of the comparison schemes in [31,32,39] is around 850 ms, while the scheme in [40] has the highest time consumption at 1191.73 ms, and the scheme in [41] shows a time consumption of 407.18 ms. In Figure 6, we analyze the storage overhead of key generation algorithms. Our scheme demonstrates the lowest storage consumption at 5.27 kb, highlighting a clear advantage over the schemes in [31,32,38,39,40]. Although the scheme in [41] has a lower storage overhead of 3.20 kb in key generation, our scheme still has an advantage over the storage overhead of other algorithms.
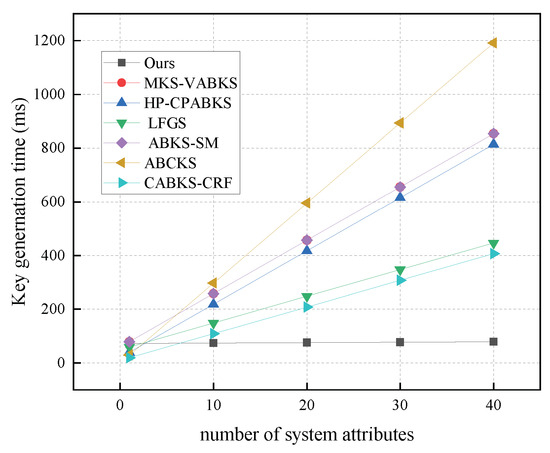
Figure 5.
Computational costs in KeyGen. (The red line of MKS-VABKS overlaps with the purple line of ABKS-SM).
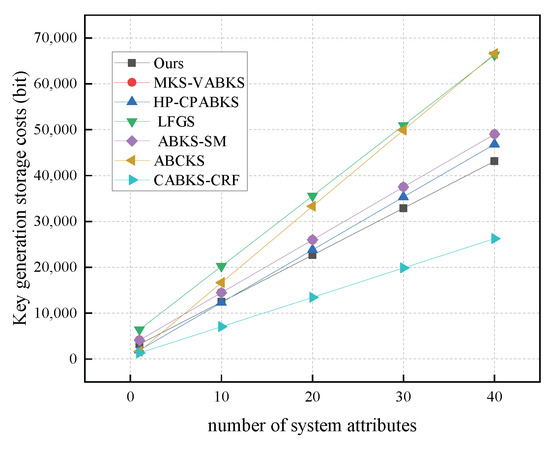
Figure 6.
Storage costs in KeyGen. (The red line of MKS-VABKS overlaps with the purple line of ABKS-SM).
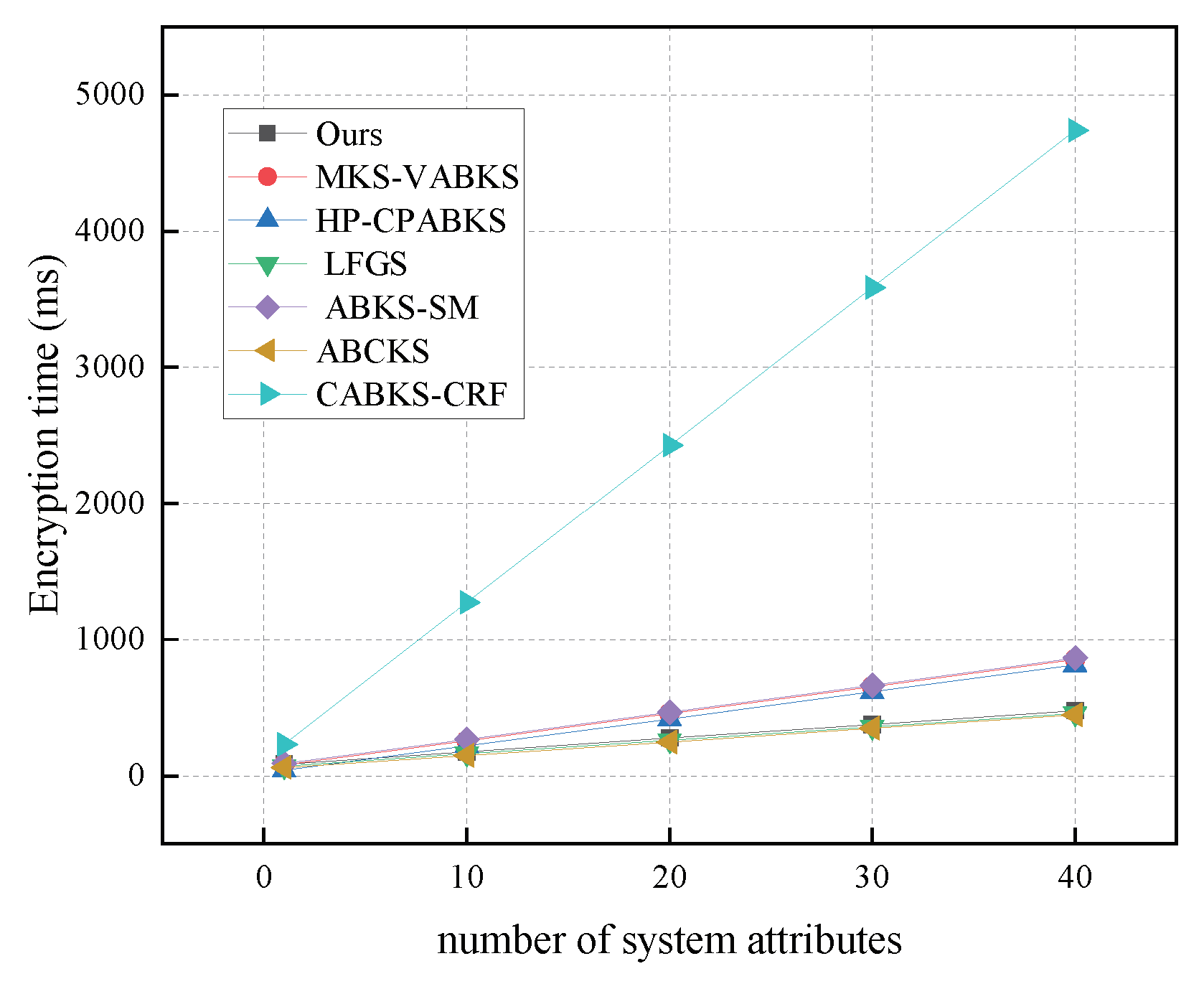
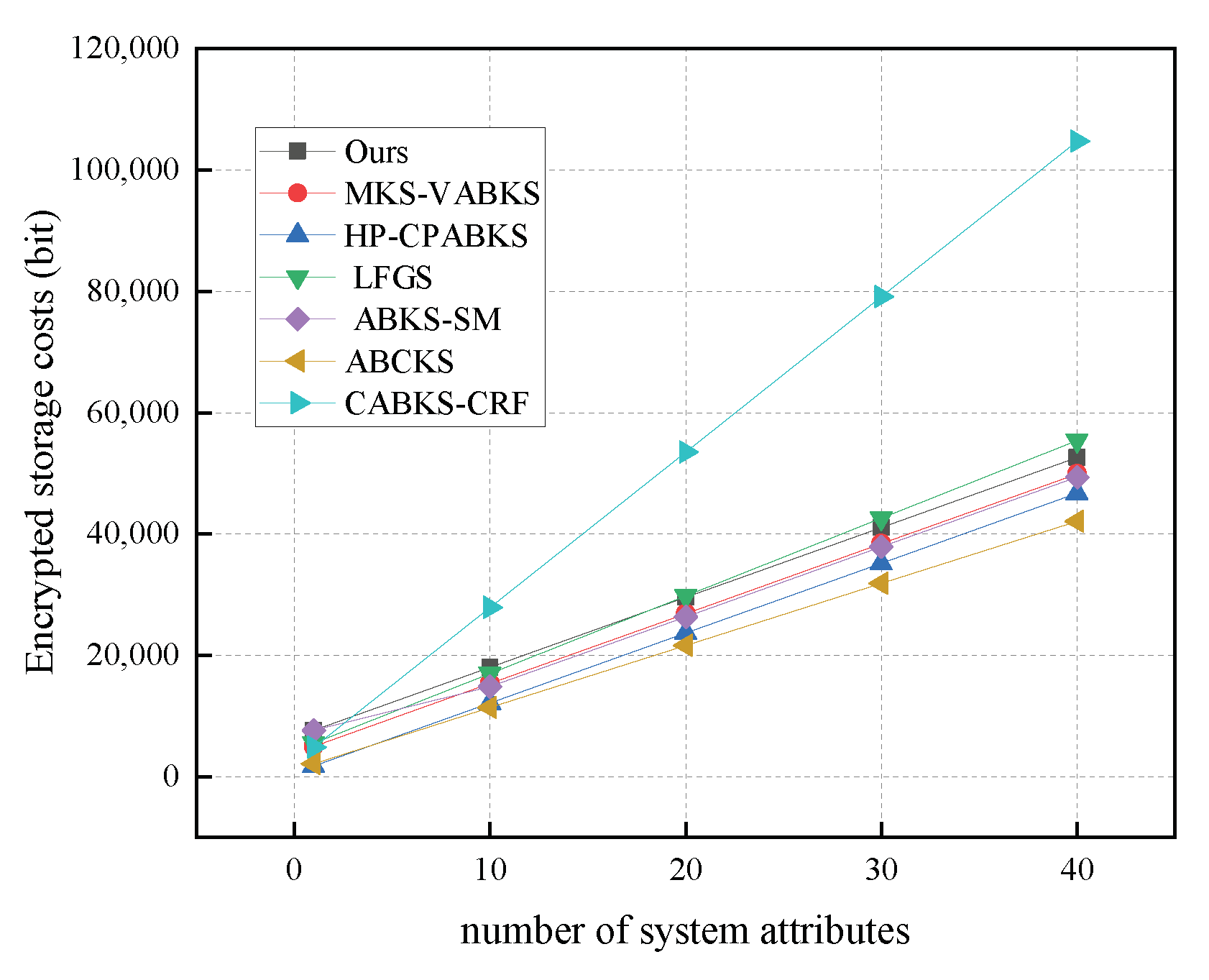
In Figure 7, we maintain r values from 10 to 40 to compare encryption algorithms. Our scheme demonstrates a time consumption of 477.24 ms, while the scheme from Ref. [38] shows 458.96 ms, and the scheme in [40] shows 446.89 ms. All of these schemes significantly outperform the schemes in [31,32,39,41]. In Figure 8, we analyze the storage overhead of the encryption algorithms. Our scheme has a storage consumption of 6.42 kb, which is slightly higher than the schemes in [31,32,39,40], but better than the storage overhead of the schemes in [38,41].
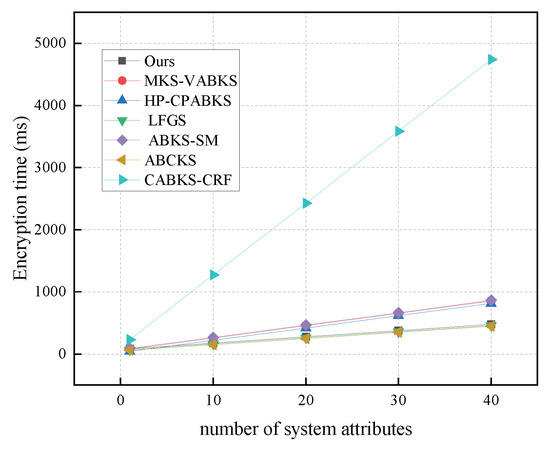
Figure 7.
Computational costs in Enc.
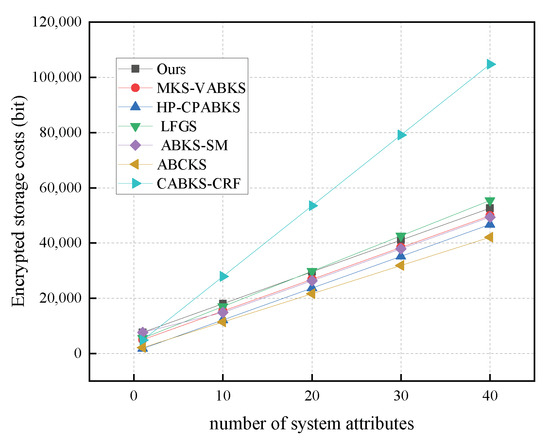
Figure 8.
Storage costs in Enc.
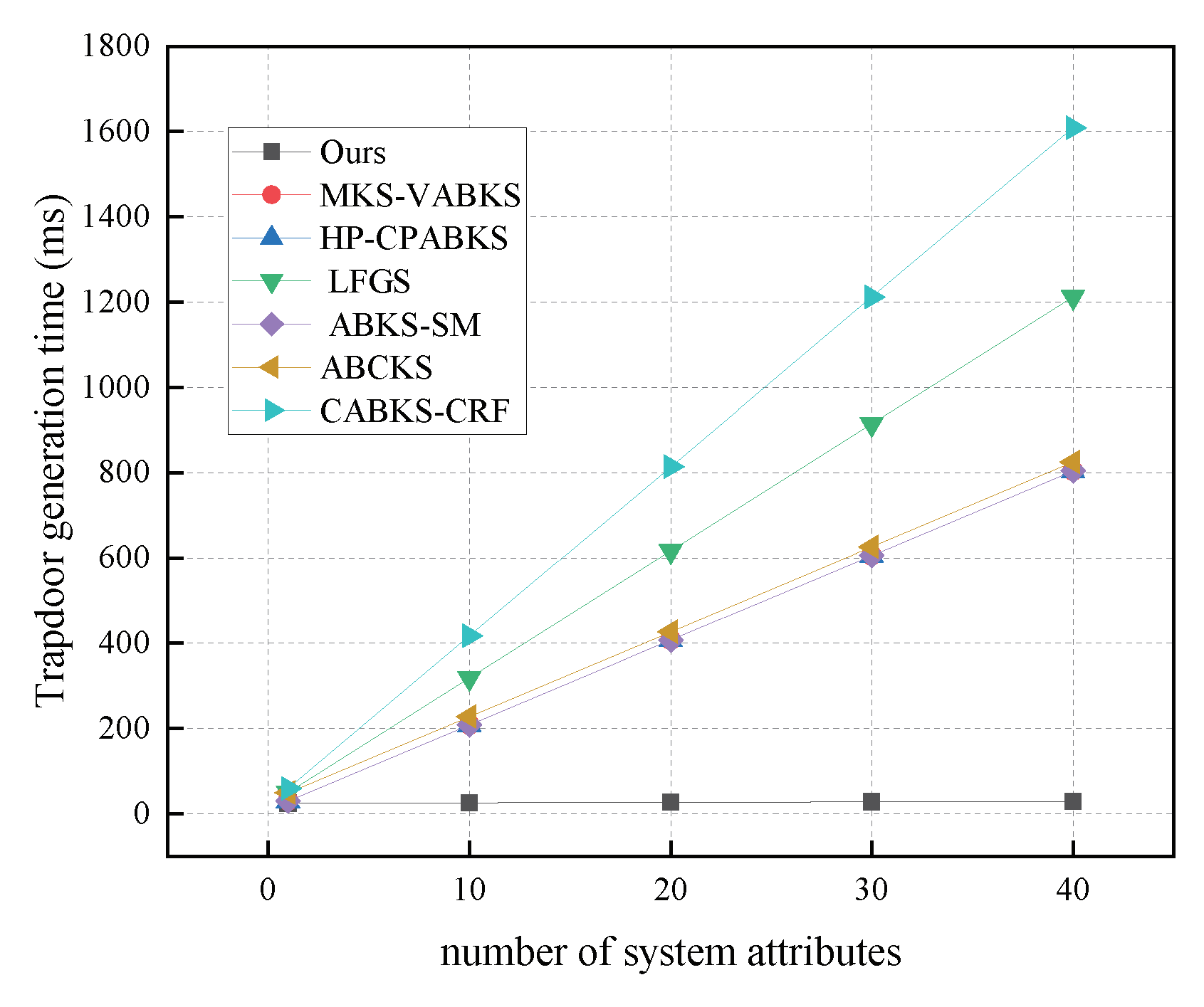
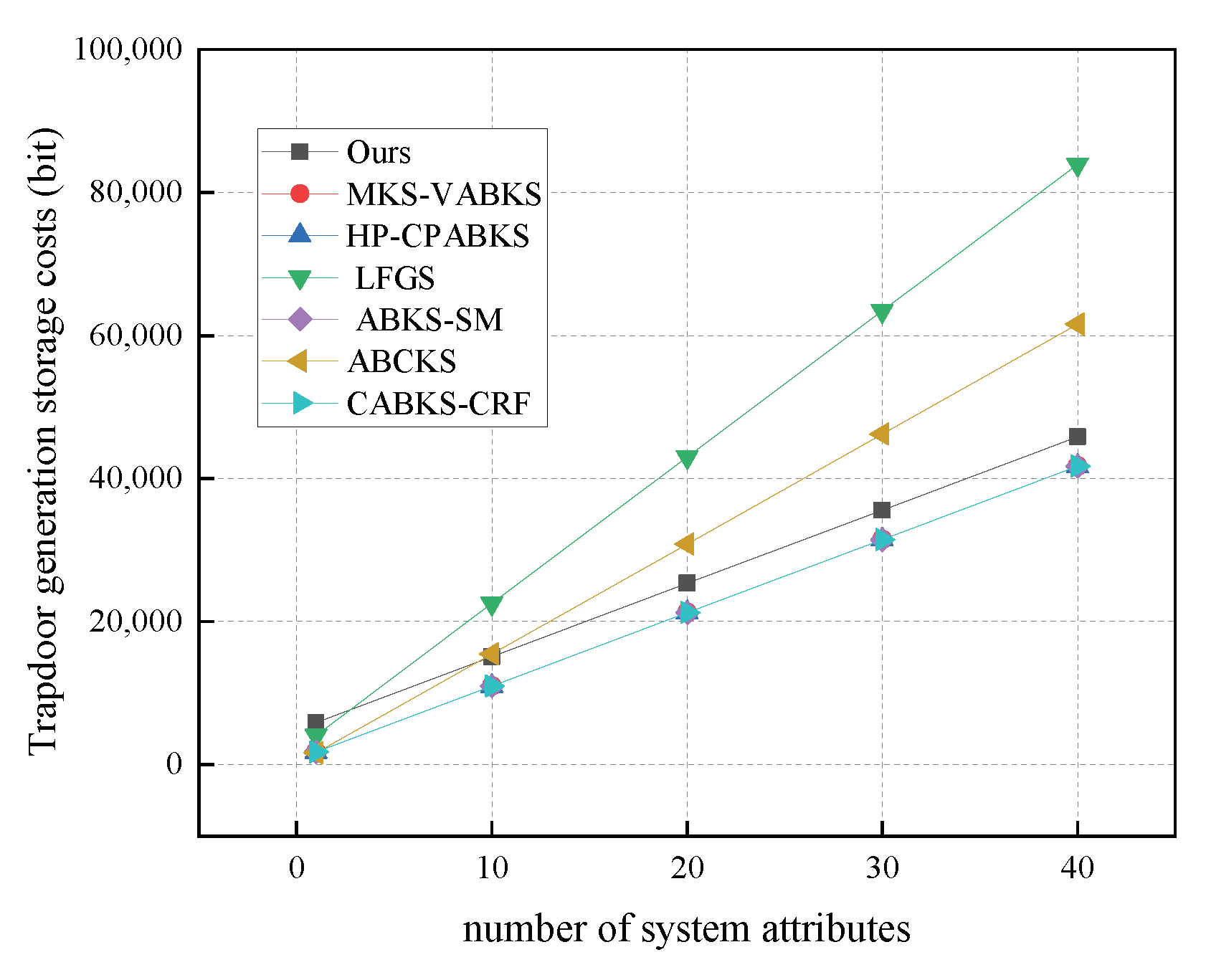
In Figure 9, we compare the computational costs of the trapdoor generation algorithms among the schemes in [31,32,39]. The time consumption for these three schemes is consistently 804.42 ms, while the scheme in [41] exhibits the highest time expenditure at approximately 1608.84 ms. Our scheme, with a time overhead of only 29.38 ms, demonstrates a significant advantage. In Figure 10, we analyze the storage overhead of the trapdoor algorithms. Our scheme has a storage overhead of 5.59 kb, which is slightly higher than the 5.09 kb overhead of the comparison schemes in [31,32,39], and the scheme in [41], but lower than the 10.25 kb overhead of the scheme in [38].
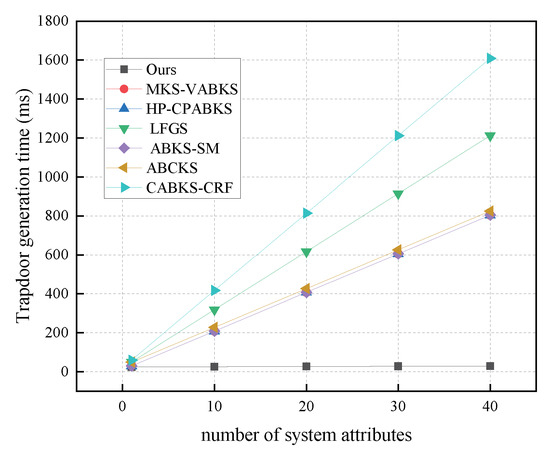
Figure 9.
Computational costs in TrapdoorGen. (The red line of MKS-VABKS and the blue line of HP-CPABKS overlap with the purple line of ABKS-SM.)
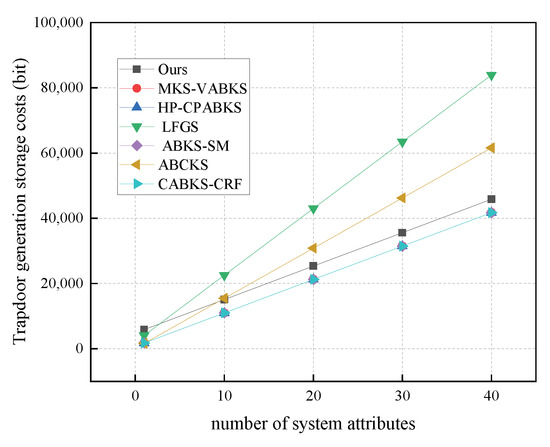
Figure 10.
Storage costs in TrapdoorGen. (The red line of MKS-VABKS, the blue line of HP-CPABKS, and the purple line of ABKS-SM overlap with the cyan line of CABKS-CRF.)
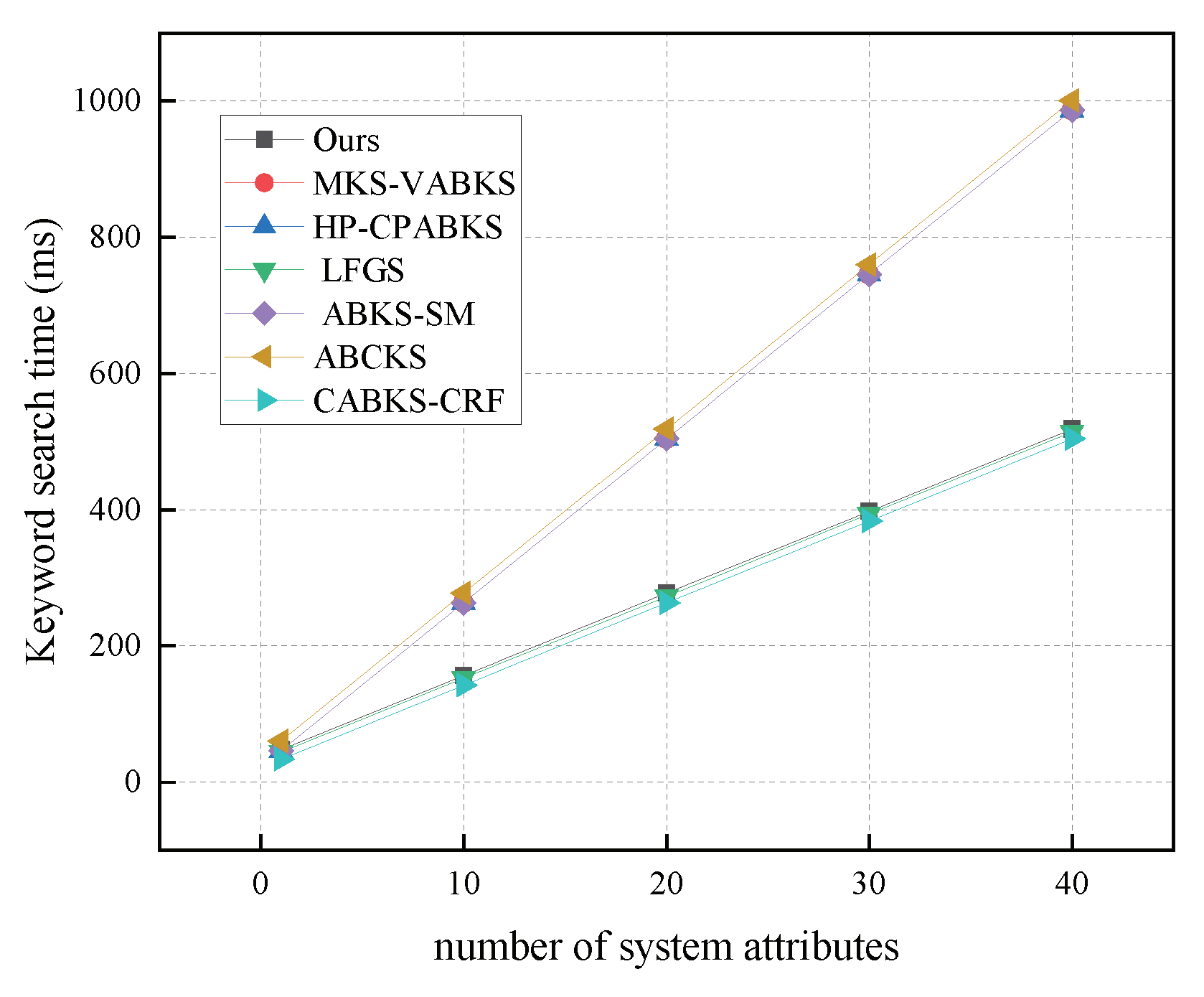
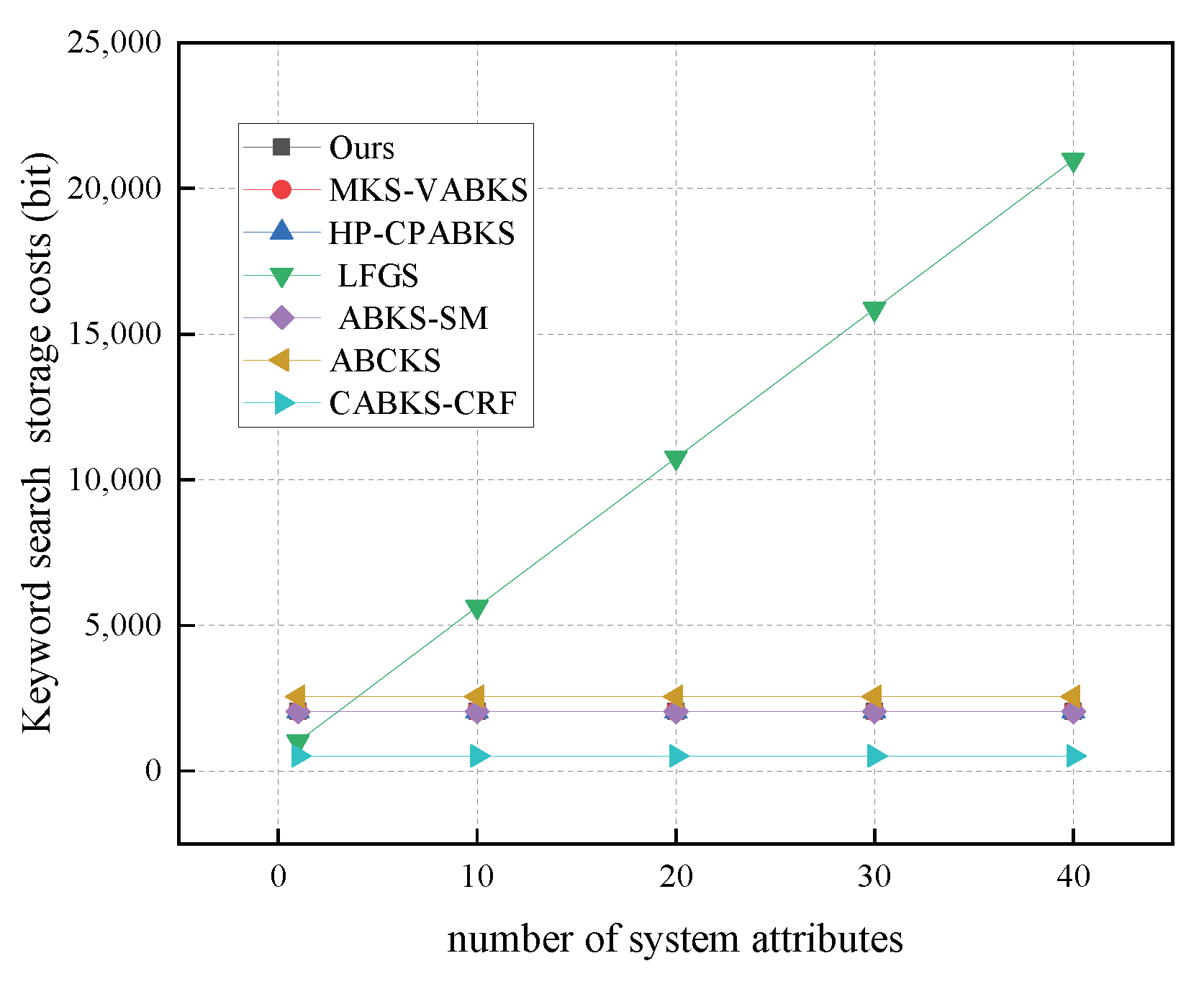
In Figure 11, we analyze the computational overhead of the keyword search algorithms. The schemes in [31,32,39] all have a time overhead of 986.6 ms. Our scheme shows a time overhead of 518.60 ms, which is comparable to the scheme in [38] with 514.23 ms and the scheme in [41] with 504.30 ms. The scheme in [40] has the highest time overhead at 1000.79 ms, ensuring efficient search for ciphertext information by data users. In Figure 12, we analyze the storage overhead of keyword search algorithms. Our scheme and the comparison schemes in [31,32,39] all have a storage overhead of 0.25 kb. Although the scheme in [41] has a lower storage overhead of 0.0625 kb, our scheme overall provides better performance. The scheme in [38] has the highest storage overhead at 2.56 kb.
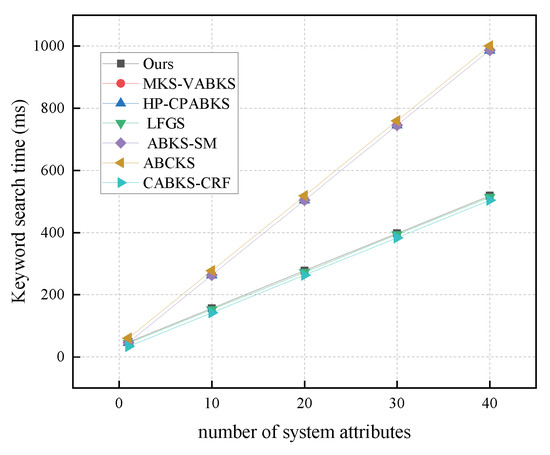
Figure 11.
Computational costs in Keyword Search. (The red line of MKS-VABKS and the blue line of HP-CPABKS overlap with the purple line of ABKS-SM.)
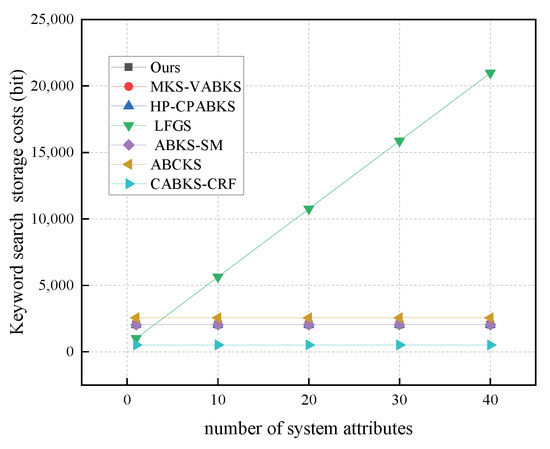
Figure 12.
Storage costs in Keyword Search. (The gray line of our scheme, the red line of MKS-VABKS, and the blue line of HP-CPABKS overlap with the purple line of ABKS-SM.)
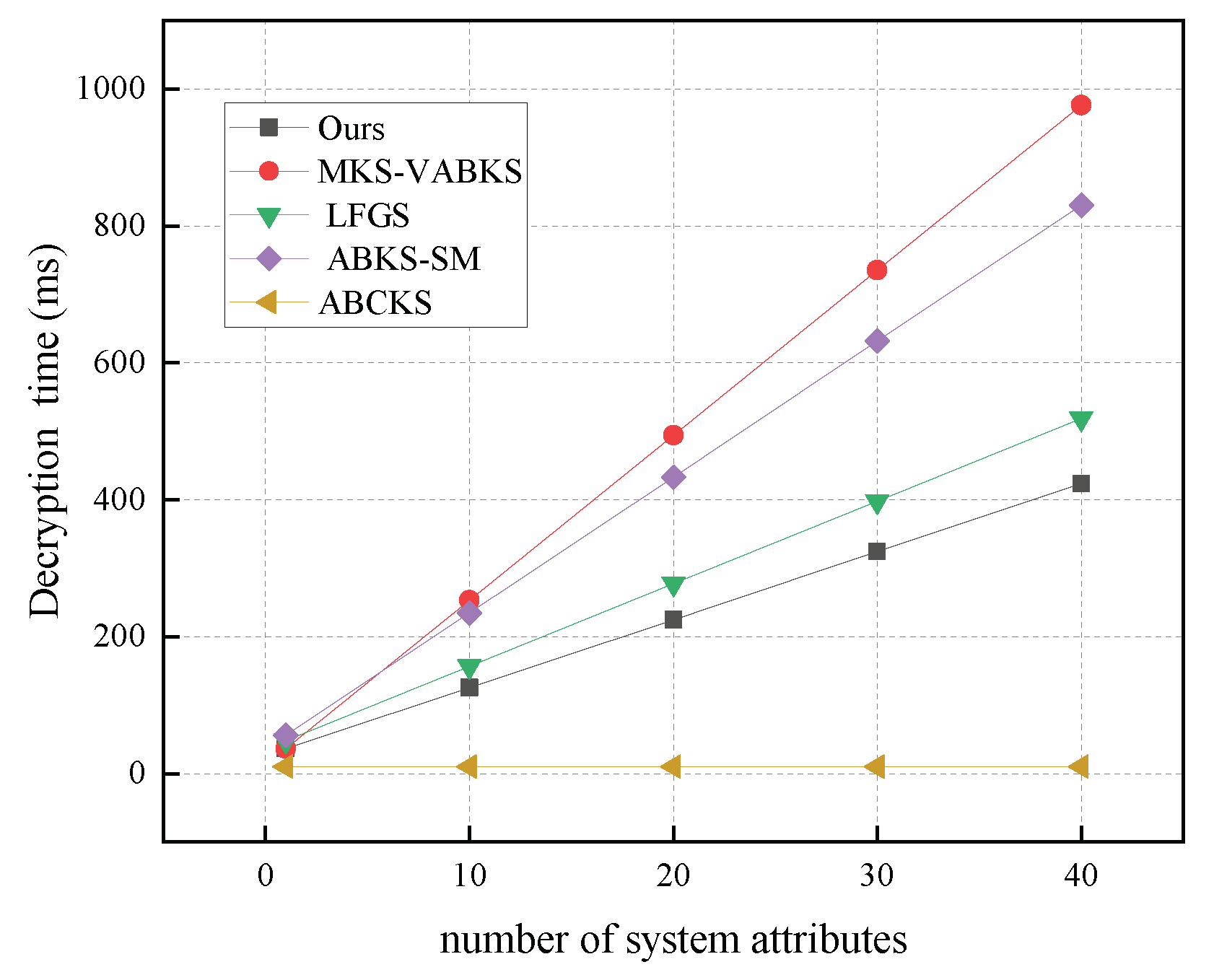
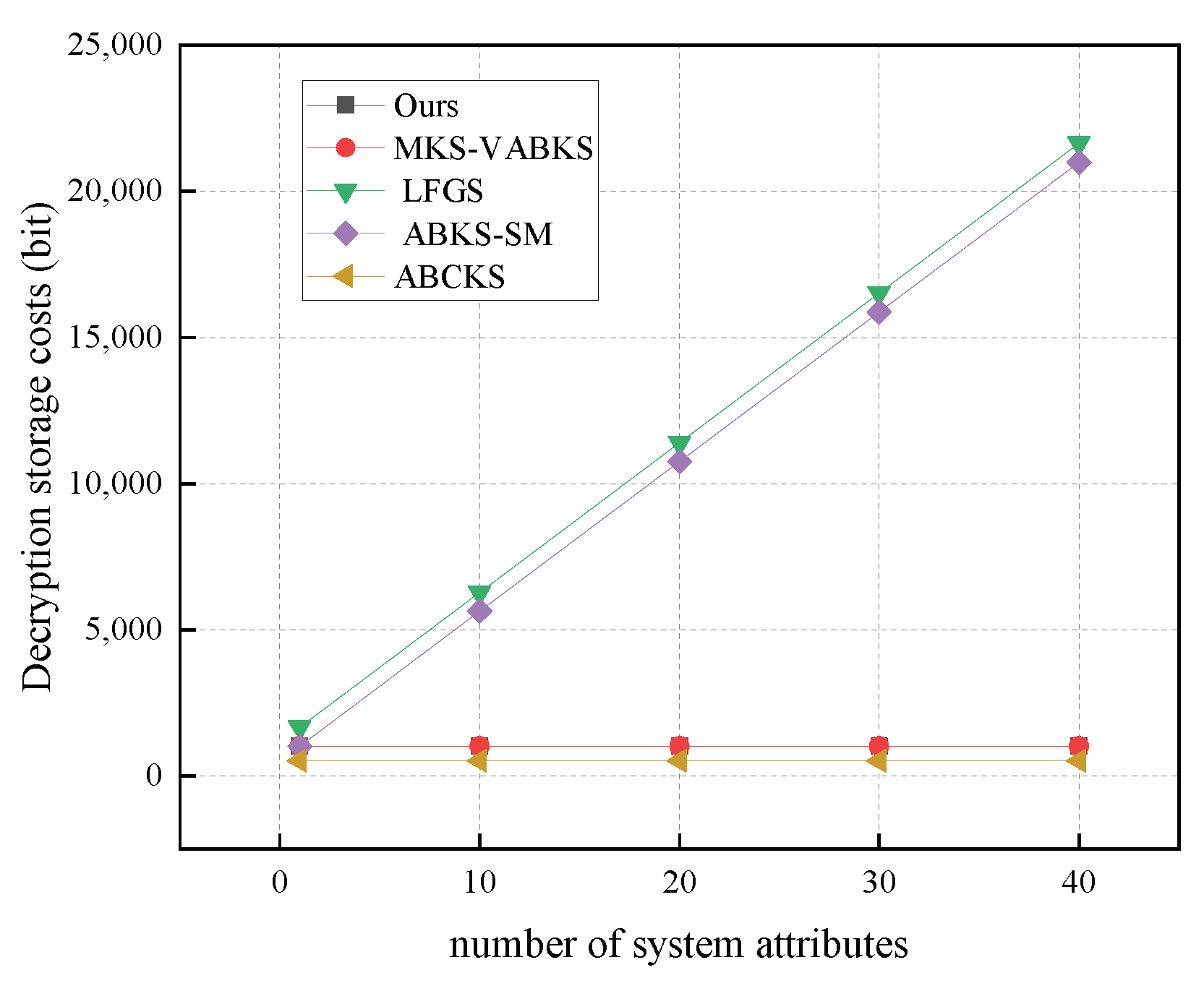
In Figure 13, we analyze the computational overhead of the decryption algorithms. The scheme in [31] exhibits a computational overhead of 830.66 ms, while the schemes in [32,38] show time overheads of 976.67 ms and 518.48 ms, respectively. Our scheme achieves a time overhead of 423.55 ms, and although the scheme in [40] has a time overhead of 9.93 ms, our scheme still significantly outperforms it in overall computational cost. In Figure 14, we analyze the storage overhead of decryption algorithms with the number of system attributes set to 40. Both our scheme and the comparison scheme in [32] have the same storage overhead of 0.125 kb. In contrast, the schemes in [31,38] have storage overheads of 2.64 kb and 2.56 kb, respectively. Our scheme demonstrates a clear storage advantage in this phase, making it suitable for resource-constrained terminal devices.
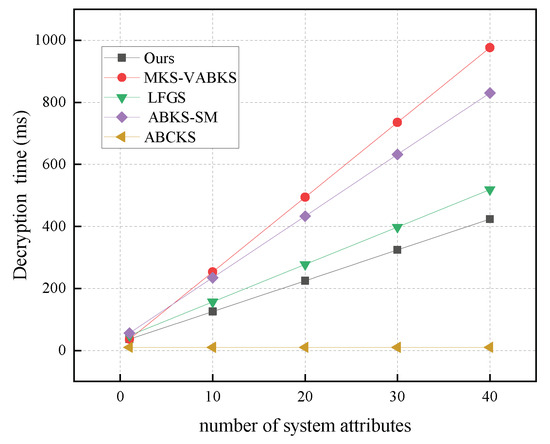
Figure 13.
Computational costs in Dec.
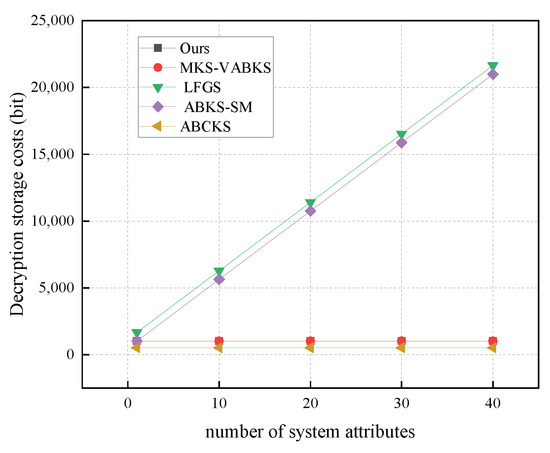
Figure 14.
Storage costs in Dec. (The gray line of our scheme overlaps with the red line of MKS-VABKS.)
8. Discussion
We have designed a new secure data-sharing model that uses an edge–cloud server architecture to enable secret resource sharing between data users across different domains. First, this model consists of algorithms with five stages, and compared to other schemes it shows significant advantages in terms of overall computational performance and storage consumption. The model supports fine-grained search characteristics during keyword searches in the cloud, and its lower computational overhead allows for faster responses in real-world environments. Second, the edge layer of the model uses group key agreement technology to re-encrypt ciphertext and keyword information, preventing keyword trapdoor guessing in the cloud and further enhancing security. Third, the model is based on the computational difficulty of the Decisional Bilinear Diffie–Hellman (DBDH) problem, and its security under the random oracle model is proven, ensuring theoretical completeness.
However, our model also has some drawbacks, such as handling attribute updates and revocations, updating and revoking data users, and whether it can allow data users to authenticate without a CA. A decentralized secure data-sharing model, where users authenticate themselves using their own public and private keys, could be explored. Currently, using a CA for authentication may impose a heavy computational burden on the CA. For future work, we will continue to explore attribute-based keyword search, focusing on flexible attribute updates, revocations, and traceability. In practical applications, both data users and attribute sets are dynamically changing. If user attributes are updated, how can secure data sharing be ensured? Thus, we need to address several challenges, such as revoking user permissions at specific attribute levels to allow secure data sharing and tracking malicious users’ identities. If a user’s identity is found to be malicious, it can be directly revoked to enhance the model’s robustness. Additionally, we aim to develop a decentralized secure data-sharing model that does not rely on CA authentication centers. Therefore, we will further optimize our model to improve its efficiency and adaptability across various environments.
For future work, we will continue to work on attribute-based keyword search, including flexible attribute updates, revocations, and traceability. In practical applications, data users and attribute sets are dynamically changing. If user attributes are updated, how to ensure secure data sharing? Therefore, some challenges need to be addressed, such as revoking the permissions of a user at a specific attribute level so that the user can still share data securely, and tracking the identity of malicious users. If the user identity is malicious, it can be directly revoked to make the model more complete. Therefore, in the future, SDSM-KGA will be further optimized to improve efficiency so that it can be used in various environments.
9. Conclusions
In this work, we propose the secure data-sharing model resisting keyword guessing attacks in edge–cloud collaboration scenarios (SDSM-KGA). On the one hand, SDSM-KGA can greatly reduce the computation and storage burden through the edge layer without leaking sensitive information. On the other hand, the SDSM-KGA supports fine-grained keyword search and resists keyword guessing attacks in the cloud. Furthermore, standard security analyses demonstrate that it is capable of resisting keyword guessing attacks (KGAs) in the random oracle model. This empirical experiment using a cryptographic database illustrates the efficiency and feasibility of SDSM-KGA.
Author Contributions
Conceptualization, Y.L. and M.X.; methodology, M.X.; validation, M.X., Q.Z. and J.Y.; formal analysis, J.Y. and H.Z.; resources, Y.L.; data curation, M.X.; writing—original draft preparation, M.X.; writing—review and editing, Y.L.; visualization, Y.L.; supervision, J.Y. and H.Z; project administration, Y.L and H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work is supported by the National Natural Science Foundation of China under Grant No. 61971380, 61772477, and the key technologies R&D Program of Henan Province (No. 242102211098), and the research funding of Key Laboratory of Big Data Intelligent Computing (No. BDIC-2023-B-006).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pan, J.; McElhannon, J. Future edge cloud and edge computing for internet of things applications. IEEE Internet Things J. 2017, 5, 439–449. [Google Scholar] [CrossRef]
- Arthurs, P.; Gillam, L.; Krause, P.; Wang, N.; Halder, K.; Mouzakitis, A. A taxonomy and survey of edge cloud computing for intelligent transportation systems and connected vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6206–6221. [Google Scholar] [CrossRef]
- Lakhan, A.; Sodhro, A.H.; Majumdar, A.; Khuwuthyakorn, P.; Thinnukool, O. A lightweight secure adaptive approach for internet-of-medical-things healthcare applications in edge-cloud-based networks. Sensors 2022, 22, 2379. [Google Scholar] [CrossRef]
- Alouffi, B.; Hasnain, M.; Alharbi, A.; Alosaimi, W.; Alyami, H.; Ayaz, M. A systematic literature review on cloud computing security: Threats and mitigation strategies. IEEE Access 2021, 9, 57792–57807. [Google Scholar] [CrossRef]
- Saxena, D.; Gupta, I.; Singh, A.K.; Lee, C.N. A fault tolerant elastic resource management framework toward high availability of cloud services. IEEE Trans. Netw. Serv. Manag. 2022, 19, 3048–3061. [Google Scholar] [CrossRef]
- Gupta, I.; Singh, A.K. SELI: Statistical evaluation based leaker identification stochastic scheme for secure data sharing. IET Commun. 2020, 14, 3607–3618. [Google Scholar] [CrossRef]
- Gupta, I.; Singh, A.K. GUIM-SMD: Guilty user identification model using summation matrix-based distribution. IET Inf. Secur. 2020, 14, 773–782. [Google Scholar] [CrossRef]
- Wang, C.; Li, W.; Li, Y.; Xu, X. A ciphertext-policy attribute-based encryption scheme supporting keyword search function. In Proceedings of the Cyberspace Safety and Security: 5th International Symposium, CSS 2013, Zhangjiajie, China, 13–15 November 2013; pp. 377–386. [Google Scholar]
- Byun, J.W.; Rhee, H.S.; Park, H.A.; Lee, D.H. Off-line keyword guessing attacks on recent keyword search schemes over encrypted data. In Proceedings of the Workshop on Secure Data Management, Seoul, Republic of Korea, 10–11 September 2006; pp. 75–83. [Google Scholar]
- Yau, W.C.; Heng, S.H.; Goi, B.M. Off-line keyword guessing attacks on recent public key encryption with keyword search schemes. In Proceedings of the Autonomic and Trusted Computing: 5th International Conference, ATC 2008, Oslo, Norway, 23–25 June 2008; pp. 100–105. [Google Scholar]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the Proceeding 2000 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Li, J.; Huang, Y.; Wei, Y.; Lv, S.; Liu, Z.; Dong, C.; Lou, W. Searchable symmetric encryption with forward search privacy. IEEE Trans. Dependable Secur. Comput. 2019, 18, 460–474. [Google Scholar] [CrossRef]
- Chen, G.; Lai, T.H.; Reiter, M.K.; Zhang, Y. Differentially private access patterns for searchable symmetric encryption. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 810–818. [Google Scholar]
- Gui, Z.; Paterson, K.G.; Patranabis, S. Rethinking searchable symmetric encryption. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–25 May 2023; pp. 1401–1418. [Google Scholar]
- Boneh, D.; Di Crescenzo, G.; Ostrovsky, R.; Persiano, G. Public key encryption with keyword search. In Proceedings of the Advances in Cryptology-EUROCRYPT 2004: International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; pp. 506–522. [Google Scholar]
- Chen, B.; Wu, L.; Li, L.; Choo, K.K.R.; He, D. A parallel and forward private searchable public-key encryption for cloud-based data sharing. IEEE Access 2020, 8, 28009–28020. [Google Scholar] [CrossRef]
- Lu, Y.; Li, J. Privacy-preserving and forward public key encryption with field-free multi-keyword search for cloud encrypted data. IEEE Trans. Cloud Comput. 2023, 11, 3619–3630. [Google Scholar] [CrossRef]
- Cheng, L.; Meng, F. Server-Aided Public Key Authenticated Searchable Encryption With Constant Ciphertext and Constant Trapdoor. IEEE Trans. Inf. Forensics Secur. 2023, 19, 1388–1400. [Google Scholar] [CrossRef]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for fine-grained access control of encrypted data. In Proceedings of the 13th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 30 October–3 November 2006; pp. 89–98. [Google Scholar]
- Waters, B. Ciphertext-policy attribute-based encryption: An expressive, efficient, and provably secure realization. In Proceedings of the International Workshop on Public Key Cryptography, Taormina, Italy, 6–9 March 2011; pp. 53–70. [Google Scholar]
- Lewko, A.; Waters, B. New proof methods for attribute-based encryption: Achieving full security through selective techniques. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 9–23 August 2012; pp. 180–198. [Google Scholar]
- Zheng, Q.; Xu, S.; Ateniese, G. VABKS: Verifiable attribute-based keyword search over outsourced encrypted data. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 23 April–2 May 2014; pp. 522–530. [Google Scholar]
- Liu, P.; Wang, J.; Ma, H.; Nie, H. Efficient verifiable public key encryption with keyword search based on KP-ABE. In Proceedings of the 2014 Ninth International Conference on Broadband and Wireless Computing, Communication and Applications, Guangzhou, China, 8–10 November 2014; pp. 584–589. [Google Scholar]
- Liang, K.; Susilo, W. Searchable attribute-based mechanism with efficient data sharing for secure cloud storage. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1981–1992. [Google Scholar] [CrossRef]
- Miao, Y.; Ma, J.; Jiang, Q.; Li, X.; Sangaiah, A.K. Verifiable keyword search over encrypted cloud data in smart city. Comput. Electr. Eng. 2018, 65, 90–101. [Google Scholar] [CrossRef]
- Sun, W.; Yu, S.; Lou, W.; Hou, Y.T.; Li, H. Protecting your right: Verifiable attribute-based keyword search with fine-grained owner-enforced search authorization in the cloud. IEEE Trans. Parallel Distrib. Syst. 2014, 27, 1187–1198. [Google Scholar] [CrossRef]
- Cui, J.; Zhou, H.; Zhong, H.; Xu, Y. AKSER: Attribute-based keyword search with efficient revocation in cloud computing. Inf. Sci. 2018, 423, 343–352. [Google Scholar] [CrossRef]
- Wang, N.; Fu, J.; Bhargava, B.K.; Zeng, J. Efficient retrieval over documents encrypted by attributes in cloud computing. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2653–2667. [Google Scholar] [CrossRef]
- Meng, F.; Cheng, L.; Wang, M. ABDKS: Attribute-based encryption with dynamic keyword search in fog computing. Front. Comput. Sci. 2021, 15, 155810. [Google Scholar] [CrossRef]
- Miao, Y.; Liu, X.; Choo, K.K.R.; Deng, R.H.; Li, J.; Li, H.; Ma, J. Privacy-preserving attribute-based keyword search in shared multi-owner setting. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1080–1094. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhu, T.; Guo, R.; Xu, S.; Cui, H.; Cao, J. Multi-keyword searchable and verifiable attribute-based encryption over cloud data. IEEE Trans. Cloud Comput. 2021, 11, 971–983. [Google Scholar] [CrossRef]
- Li, J.; Wang, M.; Lu, Y.; Zhang, Y.; Wang, H. ABKS-SKGA: Attribute-based keyword search secure against keyword guessing attack. Comput. Stand. Interfaces 2021, 74, 103471. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Y.; Li, Y.; Liu, X.; Lu, L. A blockchain-based anonymous attribute-based searchable encryption scheme for data sharing. IEEE Internet Things J. 2023, 11, 1685–1697. [Google Scholar] [CrossRef]
- Ge, C.; Susilo, W.; Liu, Z.; Xia, J.; Szalachowski, P.; Fang, L. Secure keyword search and data sharing mechanism for cloud computing. IEEE Trans. Dependable Secur. Comput. 2020, 18, 2787–2800. [Google Scholar] [CrossRef]
- Ge, C.; Susilo, W.; Liu, Z.; Baek, J.; Luo, X.; Fang, L. Attribute-Based Proxy Re-Encryption With Direct Revocation Mechanism for Data Sharing in Clouds. IEEE Trans. Dependable Secur. Comput. 2023, 21, 949–960. [Google Scholar] [CrossRef]
- Agrawal, S.; Chase, M. FAME: Fast attribute-based message encryption. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 665–682. [Google Scholar]
- Miao, Y.; Ma, J.; Liu, X.; Weng, J.; Li, H.; Li, H. Lightweight fine-grained search over encrypted data in fog computing. IEEE Trans. Serv. Comput. 2018, 12, 772–785. [Google Scholar] [CrossRef]
- Qiu, S.; Liu, J.; Shi, Y.; Zhang, R. Hidden policy ciphertext-policy attribute-based encryption with keyword search against keyword guessing attack. Sci. China Inf. Sci. 2017, 60, 1–12. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, S.; Zhang, Q.; Zhang, Y. Attribute Based Conjunctive Keywords Search With Verifiability and Fair Payment Using Blockchain. IEEE Trans. Serv. Comput. 2023, 16, 4168–4182. [Google Scholar] [CrossRef]
- Zhang, K.; Jiang, Z.; Ning, J.; Huang, X. Subversion-Resistant and Consistent Attribute-Based Keyword Search for Secure Cloud Storage. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1771–1784. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).