
The Vulnerability Relationship Prediction Research for Network Risk Assessment

Abstract
:1. Introduction
- We propose a two-layer knowledge representation learning model that incorporates entity attribute information during the knowledge representation learning process. The method improves the embedding accuracy of entity nodes, thereby enhancing the accuracy of predicting the impact relationship between vulnerable entities. We constructed a vulnerability knowledge graph containing approximately 100,000 entities and 400,000 relationships, and conducted experiments on this graph to demonstrate that the proposed model outperforms the baseline model.
- A vulnerability risk calculation model based on impact relationships is proposed, which enables risk assessment and ranking of vulnerabilities in network scenarios. This model introduces factors such as the importance of network devices and the impact relationship between vulnerabilities. We initialize the model by constructing a network device connectivity matrix, device vulnerability matrix, vulnerability relationship matrix, and setting relevant weight parameters. And experiments have shown that the vulnerability risk calculation model based on impact relationships proposed in this paper can more reasonably evaluate the actual risk of vulnerabilities in specific network scenarios.
- We propose a network risk model based on Bayesian attack graph to assess the risk of device nodes in the network. This model combines the impact relationship between vulnerabilities and quantifies the probability of vulnerability exploitation and the risk status of network devices. By inferring the likelihood of attackers successfully capturing devices in a given network topology, it provides defense strategy support for network security managers. Compared with other risk assessment methods, this model is more accurate and efficient in evaluating the risk of vulnerabilities being exploited and devices being compromised in the network.
2. Related Work
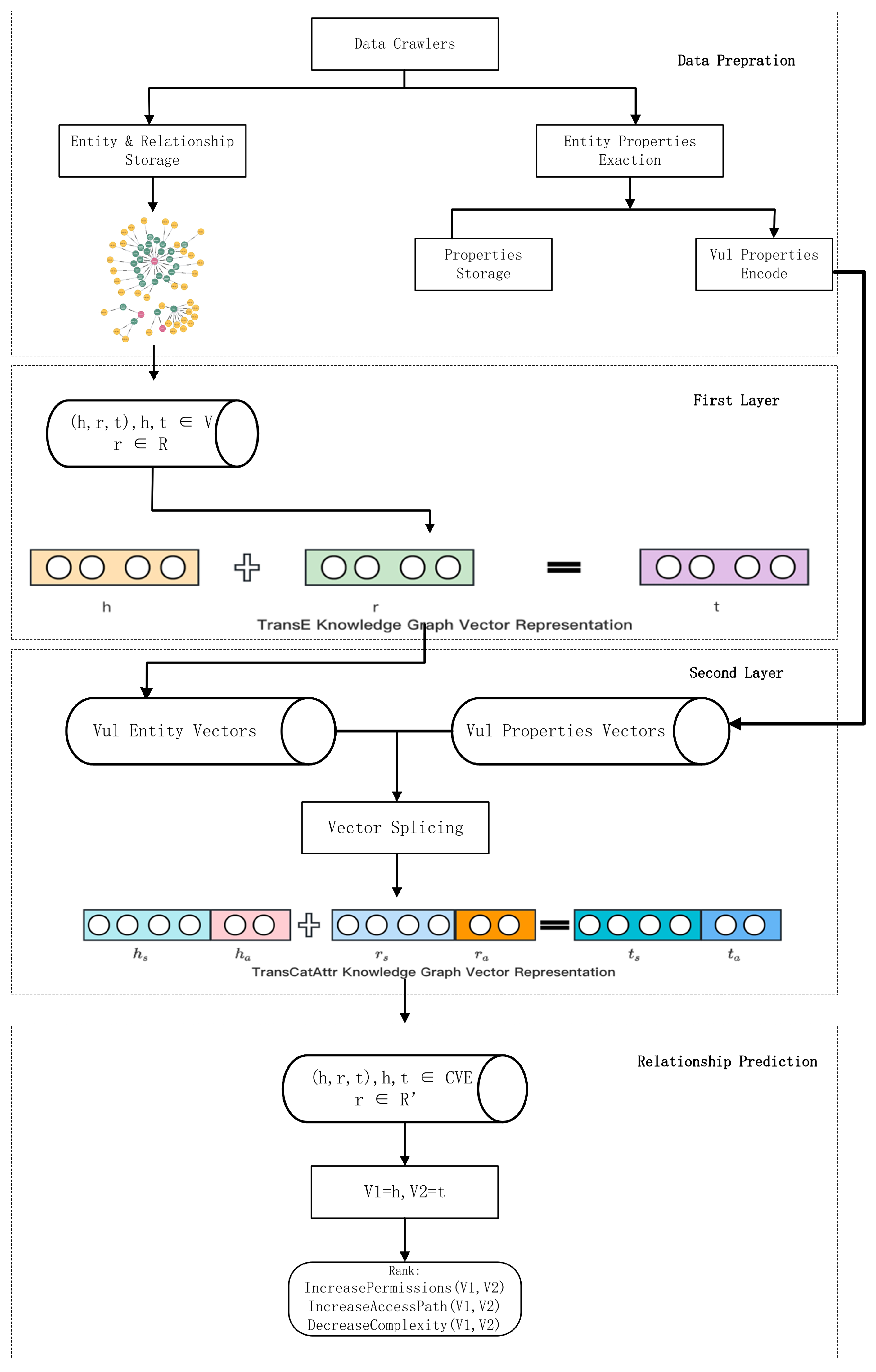
3. Methodology and Implementation
3.1. Vulnerability Knowledge Graph Definition and Construction
3.2. Dual-Layer Knowledge Representation Learning Model
| Algorithm 1 Learning TransCatAttr |
| Input: Training set , entity set V and relation set R, vulnerability entity initial embeddings set l, vulnerability entity attribution embeddings set A, vulnerability relation attribution embeddings set , margin , structure embeddings dimension k, attribution embeddings dimension m. Output: Knowledge graph embedding model
|
3.3. Attack Graph for Relationship Prediction
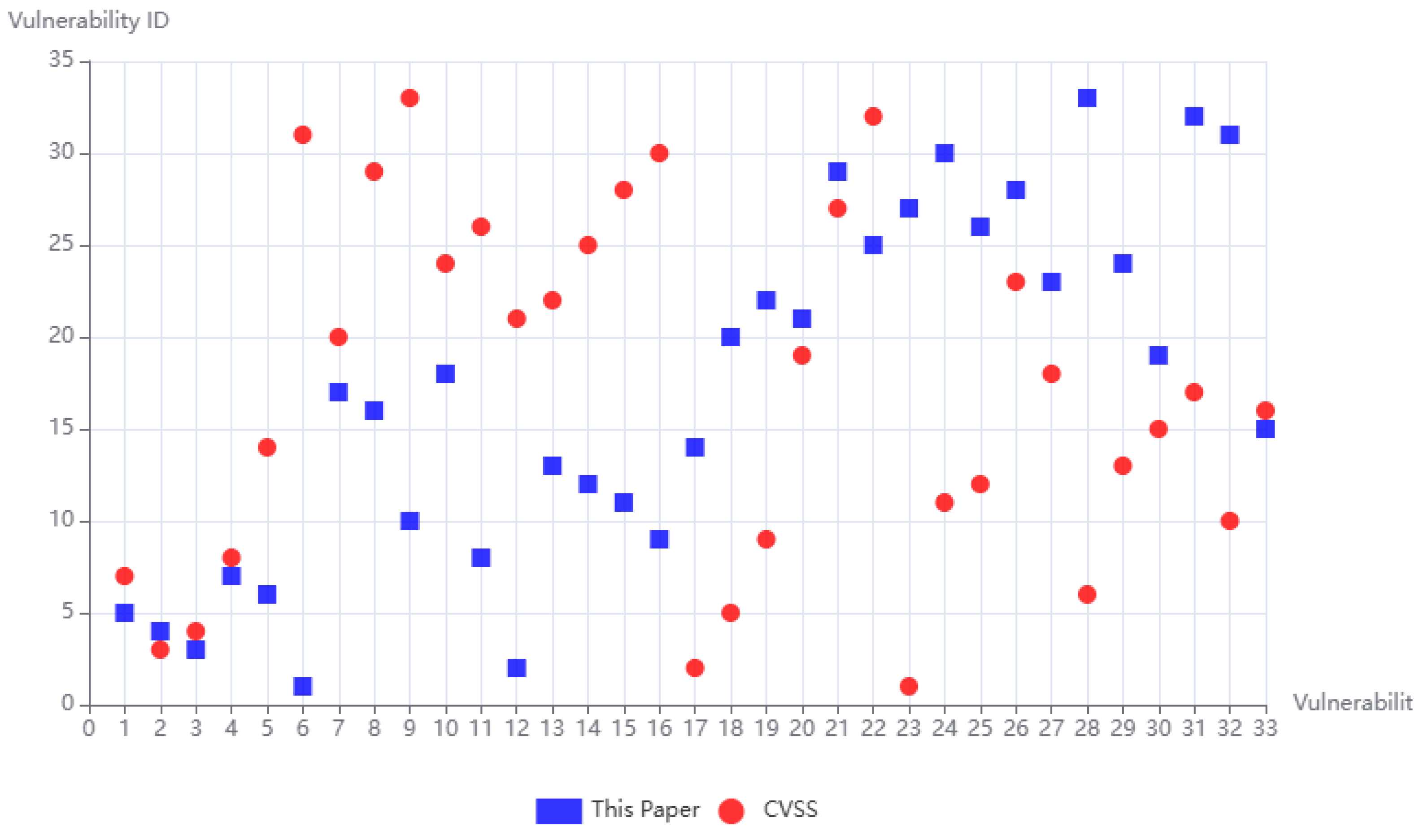
3.4. Experiment Validation
4. Results
5. Discussion
- This paper proposes a two-layer knowledge representation learning model that introduces entity attribute information during the knowledge representation learning process, enabling more accurate embedding of entity nodes and thereby enhancing the prediction accuracy of influence relationships among vulnerability entities. Firstly, a knowledge graph of vulnerabilities in the cybersecurity domain is constructed, and the meanings of entities and relationships within the vulnerability knowledge graph are elaborated in detail. Multiple-attribute information of vulnerabilities is analyzed and summarized. Secondly, the proposed two-layer knowledge representation learning model is utilized to represent entities and relationships in vector form. Each vulnerability entity is divided into two parts for representation: one based on structure and the other on attribute information, to better depict the actual meaning of vulnerability entities. Finally, a vulnerability knowledge graph comprising 96,261 entities and 398,220 relationships is constructed, and experiments are conducted on this graph to predict the influence relationships among vulnerability entities. The results demonstrate that the proposed model outperforms the TransE model.
- A vulnerability risk calculation model oriented towards influence relationships is proposed, which realizes the risk assessment and ranking of vulnerabilities existing in network scenarios. This model incorporates factors such as the importance of network devices, the connectivity between devices, and the influence relationships among vulnerabilities. It initializes the model by constructing network device connectivity matrices, device vulnerability matrices, vulnerability relationship matrices, and setting relevant weight parameters. An iterative method is employed to calculate the risk scores and rankings of devices and vulnerabilities, enabling risk assessments of both. Experimental results demonstrate that the proposed vulnerability risk calculation model oriented towards influence relationships can more reasonably evaluate the actual risks of vulnerabilities in specific network scenarios.
- A network risk model based on Bayesian attack graphs (BAGs) is proposed, which enables risk assessment of device nodes in a network. Firstly, a BAG incorporating the influence relationships among vulnerabilities is defined to model the network environment. Secondly, for vulnerability nodes, the exploitation probability is quantified by considering the influence relationships among vulnerabilities. For network device nodes, the conditional probability is calculated based on the parent vulnerability nodes of the device condition nodes. The reachability probability of the device condition nodes is then derived using the joint conditional probability of the current node and its parent nodes, thereby inferring the likelihood of an attacker successfully compromising the device within a given network topology. This provides cybersecurity managers with insights for defense strategy support. Finally, compared to the original BAG method, the proposed model offers a more accurate assessment of the risks associated with the exploitation of vulnerabilities and the compromise of devices within the network.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribution Type | Attribution Name | Attribution Meaning | Attribution Value |
|---|---|---|---|
| Base attributions of the vulnerability | CVE-ID | CVE number | For example CVE-2019-6551 |
| Product At OS | The operating system where Influenced the product is located | Linux/Windows/Mac/ Android/iOS | |
| Type | Vulnerability type | Sql Injection, XSS, Directory Traversal, DOS, Code Execution, Overflow, Memory Corruption, Bypass, Gain Privileges, CSRF, File Inclusion, Gain Information, Http Response Splitting | |
| CWE-ID | CWE number | For example CWE-79 | |
| Published Date | Vulnerability published date | For example 2021 October 21 | |
| Last Modified | Vulnerability last modified date | For example 2021 November 23 | |
| Condition attributions of vulnerability exploitation | Access Vector | Local/Adjacent Network/Remote Network/Physical | |
| Authentication | Does vulnerability exploitation require authentication? | Multiple/Single/None | |
| Access Complexity | Vulnerability exploitation complexity | High/Low | |
| Privileges Required | Permissions required for vulnerability exploitation | High/Low/None | |
| Read & Write | Read and write permissions required for vulnerability exploitation | Overall/None/Write Access/Read Access | |
| User | Does the exploit | Require/None | |
| User Interaction | Does the exploit require user interaction? | ||
| Impact attributions of vulnerability exploitation | Access Application | Ability to access the system or application | Yes/No |
| Gain Privilege | Gained privilege after vulnerability exploitation | Root/administrator/User/None | |
| Execute System Command | Ability to execute system commands | Yes/(System/Root)/No |
Appendix A.2

Appendix A.3

References
- National Vulnerability Database. Available online: https://nvd.nist.gov (accessed on 20 September 2022).
- Williams, M.A.; Dey, S.; Camacho Barranco, R.; Motahar Naim, S.; Hossain, M.S.; Akbar, M. Analyzing Evolving Trends of Vulnerabilities in National Vulnerability Database. In Proceedings of the 2018 IEEE International Conference on Big Data, Big Data 2018, Seattle, WA, USA, 10–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3011–3020. [Google Scholar]
- Wang, W.; Shi, F.; Zhang, M.; Xu, C.; Zheng, J. A Vulnerability Risk Assessment Method Based on Heterogeneous Information Network. IEEE Access 2020, 8, 148315–148330. [Google Scholar] [CrossRef]
- Cheng, P.; Wang, L.; Jajodia, S.; Singhal, A. Aggregating CVSS base scores for semantics-rich network security metrics. In Proceedings of the IEEE Symposium on Reliable Distributed Systems, Irvine, CA, USA, 8–11 October 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 31–40. [Google Scholar]
- Monostori, L.; Kádár, B.; Bauernhansl, T.; Kondoh, S.; Kumara, S.; Reinhart, G.; Sauer, O.; Schuh, G.; Sihn, W.; Ueda, K. Cyber-physical systems in manufacturing. CIRP Ann. Manuf. Technol. 2016, 65, 621–641. [Google Scholar] [CrossRef]
- Sridhar, S.; Hahn, A.; Govindarasu, M. Cyber–physical system security for the electric power grid. Proc. IEEE 2012, 100, 210–224. [Google Scholar] [CrossRef]
- Liang, X.; Xiao, Y. Game theory for network security. IEEE Commun. Surv. Tutor 2013, 15, 472–486. [Google Scholar] [CrossRef]
- Jiang, W.; Zhan, J. A modified combination rule in generalized evidence theory. Appl. Intell. 2017, 46, 630–640. [Google Scholar] [CrossRef]
- Zheng, Z.; Sun, P. Application of RBF neural network in network security risk assessment. In Proceedings of the 2011 International Conference on Computer Science and Applications, Antwerp, Belgium, 26 March 2011; pp. 43–46. [Google Scholar]
- Liang, L.; Yang, J.; Liu, G.; Zhu, G.; Yang, Y. Novel method of assessing network security risks based on vulnerability correlation graph. In Proceedings of the 2012 IEEE 2nd International Conference on Computer Science and Network Technology (ICCSNT), Changchun, China, 29–31 December 2012; pp. 1085–1090. [Google Scholar]
- Sheyner, O.; Wing, J. Tools for Generating and Analyzing Attack Graphs; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Zhu, Y.; Du, Z. Research on the Key Technologies of Network Security-Oriented Situation Prediction. Sci. Program. 2021, 2021, 5527746. [Google Scholar] [CrossRef]
- Zhou, Y.Y. Risk assessment method for network attack surface based on Bayesian attack graph. Chin. J. Netw. Inf. Secur. 2018, 4, 11–22. [Google Scholar] [CrossRef]
- Huang, K.; Zhou, C.; Tian, Y.C.; Yang, S.; Qin, Y. Assessing the physical impact of cyberattacks on industrial cyber physical systems. IEEE Trans. Ind. Electron. 2018, 65, 8153–8162. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Z.; Feng, X.; Di, X.; Liu, D.; Zhao, J.; Sui, X. Research on Network Security Situation Assessment and Quantification Method Based on Analytic Hierarchy Process. Wirel. Pers. Commun. 2018, 102, 1401–1420. [Google Scholar] [CrossRef]
- Kotenko, I.; Doynikova, E. Security assessment of computer networks based on attack graphs and security events. In Proceedings of the Information & Communication Technology-EurAsia Conference, Bali, Indonesia, 14–17 April 2014; pp. 462–471. [Google Scholar]
- Lallie, H.S.; Debattista, K.; Bal, J. A review of attack graph and attack tree visual syntax in cyber security. Comput. Sci. Rev. 2020, 35, 100219. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Z.; Zhao, J.; Di, X.; Liu, D. A Vulnerability Assessment Method in Industrial Internet of Things Based on Attack Graph and Maximum Flow. IEEE Access 2018, 6, 8599–8609. [Google Scholar] [CrossRef]
- Lee, J.; Moon, D.; Kim, I.; Lee, Y. A semantic approach to improving machine readability of a large-scale attack graph. J. Supercomput. 2019, 75, 3028–3045. [Google Scholar] [CrossRef]
- Poolsappasit, N.; Dewri, R.; Ray, I. Dynamic security risk management using Bayesian attack graphs. IEEE Trans. Dependable Secur. Comput. 2012, 9, 61–74. [Google Scholar] [CrossRef]
- Munoz-Gonzalez, L.; Sgandurra, D.; Barrere, M.; Lupu, E.C. Exact Inference Techniques for the Analysis of Bayesian Attack Graphs. IEEE Trans. Dependable Secur. Comput. 2019, 16, 231–244. [Google Scholar] [CrossRef]
- Lu, J.; Su, P.; Yang, M.; He, L.; Zhang, Y.; Zhu, X.; Lin, H. Software and Cyber Security—A Survey. Ruan Jian Xue Bao/J. Softw. 2016, 29, 42–68. (In Chinese) [Google Scholar]
- Du, Y.; Lu, Y. A weakness relevance evaluation method based on pagerank. In Proceedings of the 2019 IEEE 4th International Conference on Data Science in Cyberspace, Hangzhou, China, 23–25 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 422–427. [Google Scholar]
- Han, Z.; Li, X.; Liu, H.; Xing, Z.; Feng, Z. DeepWeak: Reasoning common software weaknesses via knowledge graph embedding. In Proceedings of the 25th IEEE International Conference on Software Analysis, Evolution and Reengineering, Campobasso, Italy, 20–23 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 456–466. [Google Scholar]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Houston, TX, USA, 10–15 June 2008; pp. 1247–1249. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. DBpedia—A large-scale, multilingual knowledge base extracted from Wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Fabian, M.; Gjergji, K.; Gerhard, W. Yago: A Core of Semantic Knowledge Unifying WordNet and Wikipedia. In Proceedings of the 16th International World Wide Web Conference, Banff, AL, Canada, 8–12 May 2007. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R.; Mitchell, T.M. Toward an architecture for never-ending language learning. In Proceedings of the National Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010; pp. 1306–1313. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef]
- Li, Z.; Liu, H.; Zhang, Z.; Liu, T.; Xiong, N.N. Learning Knowledge Graph Embedding with Heterogeneous Relation Attention Networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 3961–3973. [Google Scholar] [CrossRef]
- Du, H.; Wang, Z.; Nie, H.; Yao, Q.; Li, X. Multi-scale dilated convolutional network for knowledge graph embedding. Sci. China Inf. 2022, 52, 1204–1220. [Google Scholar]
- Chen, Z.; Wang, Y.; Zhao, B.; Cheng, J.; Zhao, X.; Duan, Z. Knowledge graph completion: A review. IEEE Access 2020, 8, 192435–192456. [Google Scholar] [CrossRef]
- Shen, Y.; Ding, N.; Zheng, H.T.; Li, Y.; Yang, M. Modeling Relation Paths for Knowledge Graph Completion. IEEE Trans. Knowl. Data Eng. 2021, 33, 3607–3617. [Google Scholar] [CrossRef]
- Bayrak, B.; Choupani, R.; Dogdu, E. Link Prediction in Knowledge Graphs with Numeric Triples Using Clustering. In Proceedings of the 2020 IEEE International Conference on Big Data, Big Data 2020, Virtual, 10–13 December 2020; pp. 4492–4498. [Google Scholar]
- Zhao, F.; Xu, T.; Jin, L.; Jin, H. Convolutional Network Embedding of Text-Enhanced Representation for Knowledge Graph Completion. IEEE Internet Things J. 2021, 8, 16758–16769. [Google Scholar] [CrossRef]
- Hong, W.; Li, S.; Hu, Z.; Rasool, A.; Jiang, Q.; Weng, Y. Improving Relation Extraction by Knowledge Representation Learning. In Proceedings of the International Conference on Tools with Artificial Intelligence, ICTAI 2021-November, Virtual, 1–3 November 2021; pp. 1211–1215. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Durán, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing (EMNLP 2013), Seattle, WA, USA, 18–21 October 2013; pp. 1533–1544. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge graph embedding via dynamic mapping matrix. In Proceedings of the ACL-IJCNLP 2015—53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Yang, R.; Wei, Z.; Fan, Y.; Zhao, J. A Few-Shot Inductive Link Prediction Model in Knowledge Graphs. IEEE Access 2022, 10, 97370–97380. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- CVSS. Available online: https://www.first.org/cvss/ (accessed on 1 November 2023).

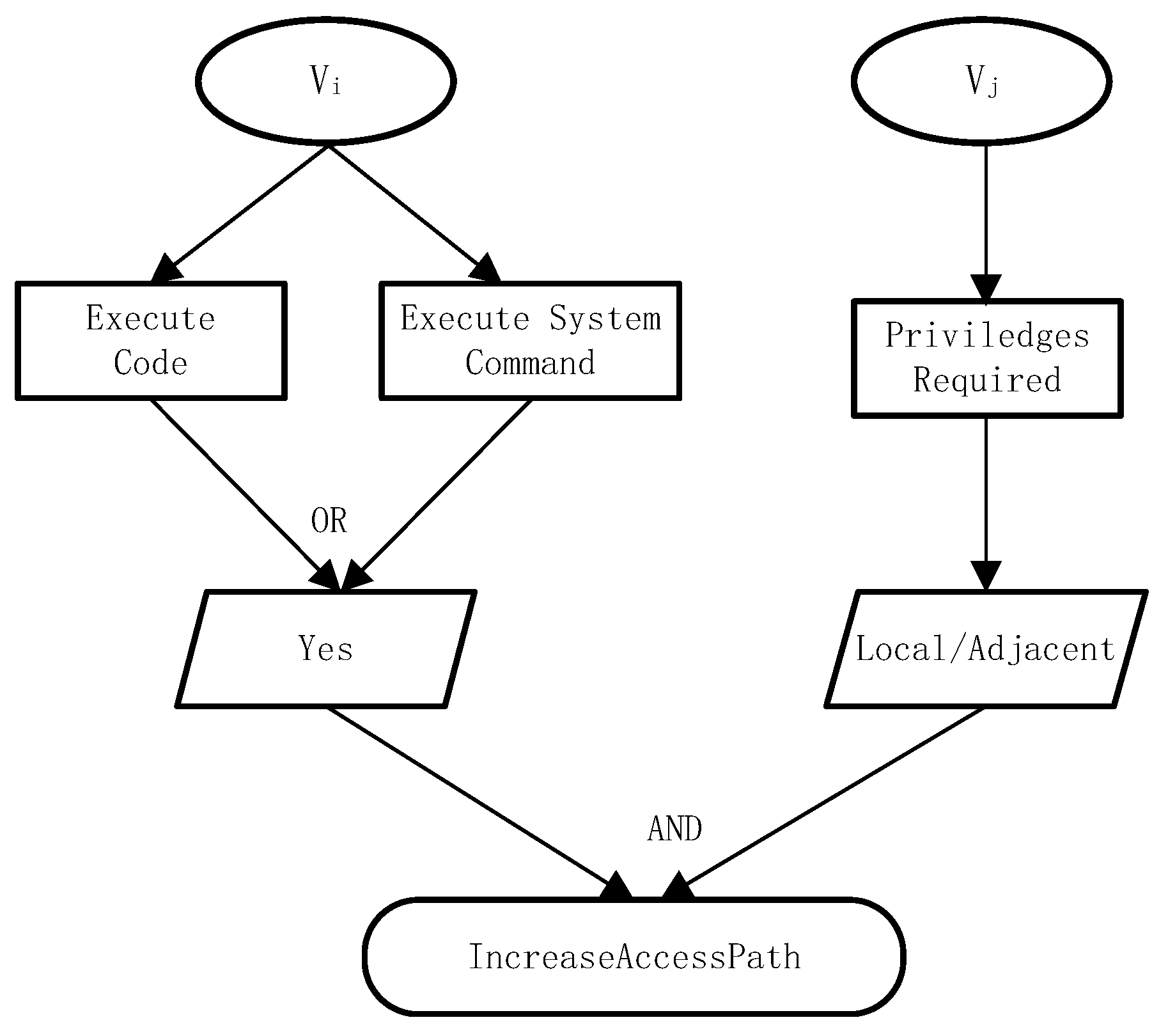





| Indicator Name | Indicator Values |
|---|---|
| PR | None/Low/High |
| AV | Network/Adjacent/Local/Physical |
| AC | Low/High |
| UI | None/Required |
| Symbol | Means |
|---|---|
| S | The device node for attack status from start to end. |
| E | Dependencies between S during the attack occurrence. |
| Vul | Vulnerability assemble for attack. |
| R | The relationship between multiple precursor nodes and the successor nodes is represented as . |
| Inf | Impact relationships between vulnerabilities mentioned in Section 2. |
| Pro | Attack the accessibility probability of the S in the graph. |
| Entity Node Type/Relationship Type | Quantity (Pcs/Strip) |
|---|---|
| Vulnerability | 55,874 |
| Product | 33,249 |
| Vendor | 7138 |
| Influence | 168,406 |
| AffiliatedWith | 33,368 |
| IncreasePermissions | 98,254 |
| IncreaseAccessVector | 20,101 |
| DecreaseComplexity | 78,091 |
| Parameters | Value | Meaning |
|---|---|---|
| embedding_dim | 111 | Embedding dimension |
| 0.01 | Learning rate | |
| margin | 4.0 | Loss function margin |
| norm | 1 | L1-norm or L2-norm |
| c | 0.25 | Threshold value |
| epochs | 500 | Model training iteration times |
| batch_size | 9600 | Batch size |
| Model | Entity MR | Entity Hits@10 | Relationship MR | Relationship Hits@1 |
|---|---|---|---|---|
| TransE | 19.92% | 904.55 | 90.98% | 2 |
| TransCatAttr | 28.89% | 760.6 | 99.19% | 1.4 |
| S2 | S3 | P(S4|S2) | P(S4|S3) | ||
|---|---|---|---|---|---|
| True | False | True | False | ||
| True | True | 0.22 | 0.78 | 0.28 | 0.72 |
| True | False | 0.22 | 0.78 | 0 | 1 |
| False | True | 0 | 0 | 0.28 | 0.72 |
| False | False | 0 | 0 | 0 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, J.; Li, W.; Guo, D. The Vulnerability Relationship Prediction Research for Network Risk Assessment. Electronics 2024, 13, 3350. https://doi.org/10.3390/electronics13173350
Jiao J, Li W, Guo D. The Vulnerability Relationship Prediction Research for Network Risk Assessment. Electronics. 2024; 13(17):3350. https://doi.org/10.3390/electronics13173350
Chicago/Turabian StyleJiao, Jian, Wenhao Li, and Dongchao Guo. 2024. "The Vulnerability Relationship Prediction Research for Network Risk Assessment" Electronics 13, no. 17: 3350. https://doi.org/10.3390/electronics13173350