HDCCT: Hybrid Densely Connected CNN and Transformer for Infrared and Visible Image Fusion


Abstract
1. Introduction
- A new fusion architecture for multi-modal image fusion including a CNN for local information and a transformer for global information is presented. The hybrid architecture integrates local and global information, sufficiently integrating the information through feature extraction.
- The encoder–decoder architecture is designed for image fusion for both the CNN and the transformer. The encoder–decoder of the CNN use long connections of features from the alignment of different depths to generate local feature information.
- The optimizer enhances the feature representation capacity to extract the global and local features for multi-model fusion. MSE and SSIM losses are used for local and global feature loss, which mainly includes the pixel loss for fusion images.
2. Related Works
2.1. CNN-Based Methods for Image Fusion
2.2. Transformer-Based Methods for Image Fusion
2.3. Multi-Modal Methods for Image Fusion
3. Methodology
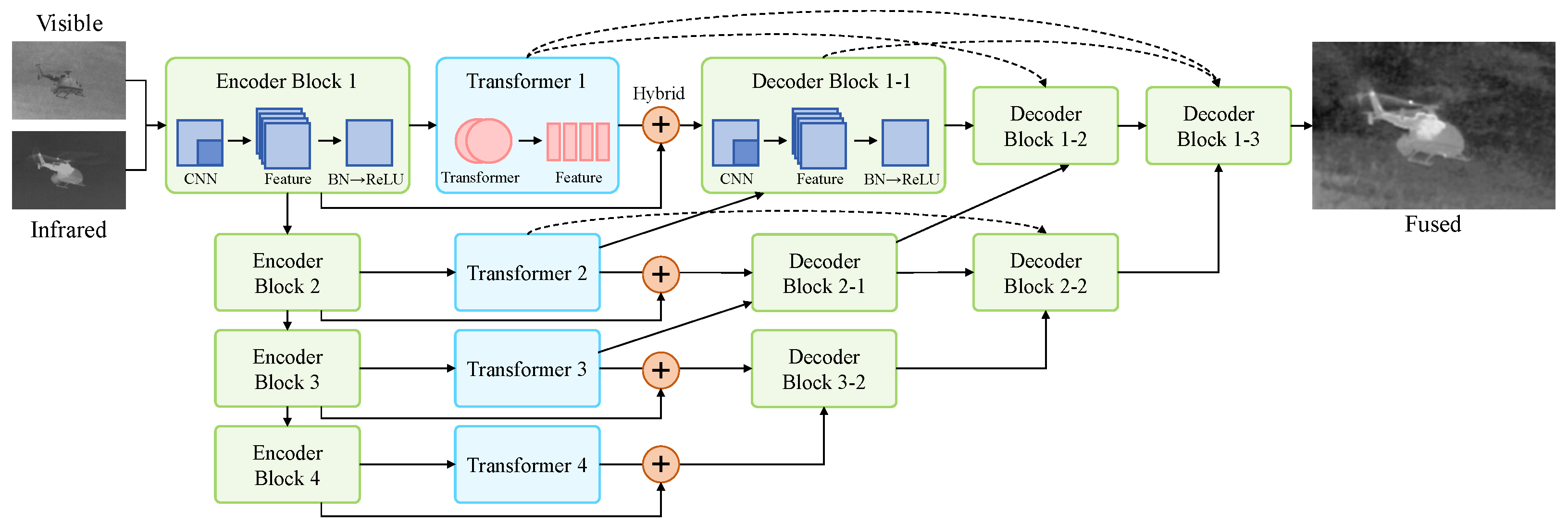
3.1. Overview of Proposed Architecture
3.2. Details of HDCCT
3.2.1. Encoder and Decoder Architecture of HDCCT
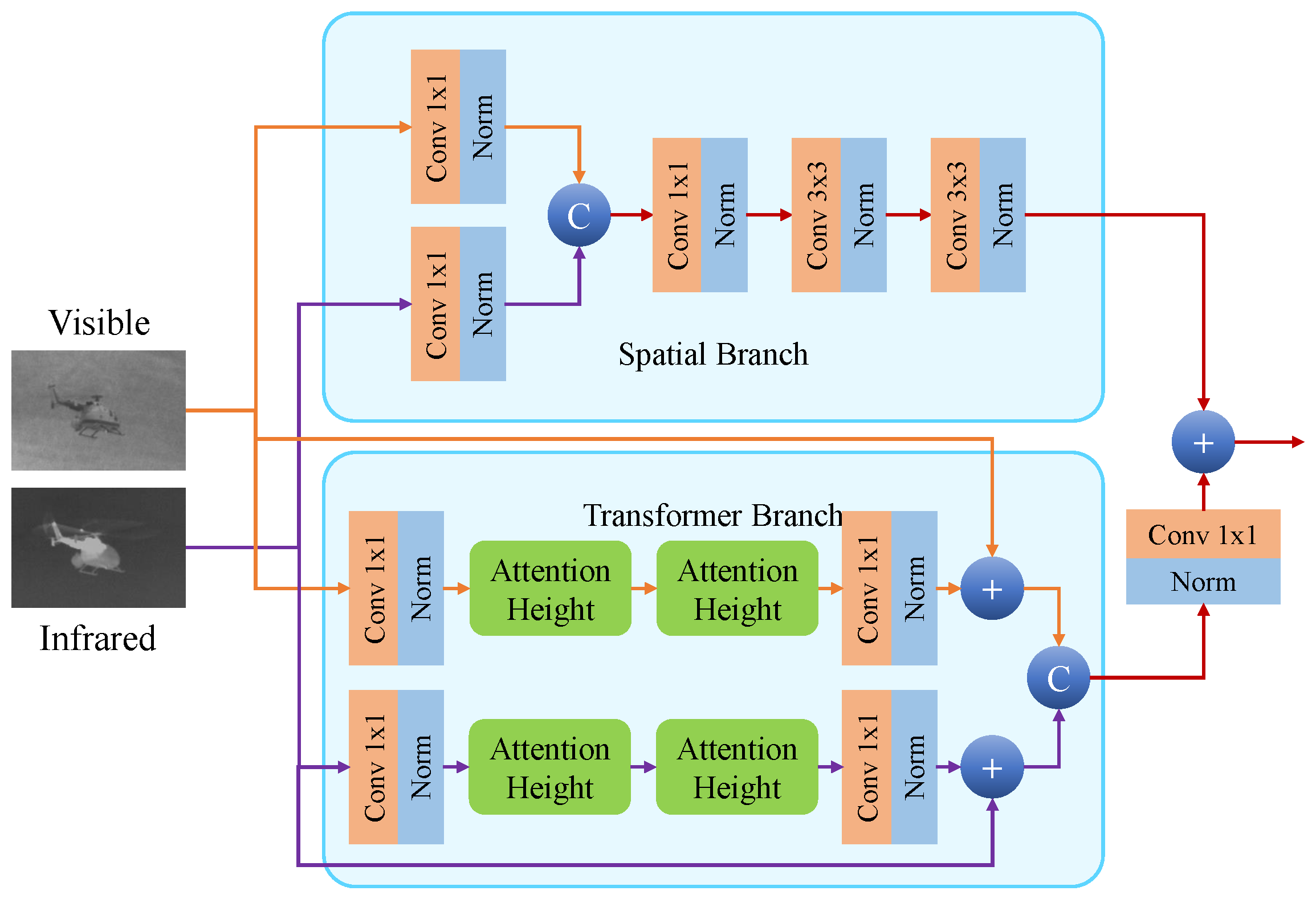
3.2.2. Architecture of Transformer
3.3. Feature Fusion for Multi-Modal Image Fusion
3.4. Loss Function
3.4.1. Local Loss
3.4.2. Global Loss
3.4.3. Overall Loss
4. Experiments and Results
4.1. Experimental Details
4.1.1. Datasets, Compared Methods, and Parameter Settings
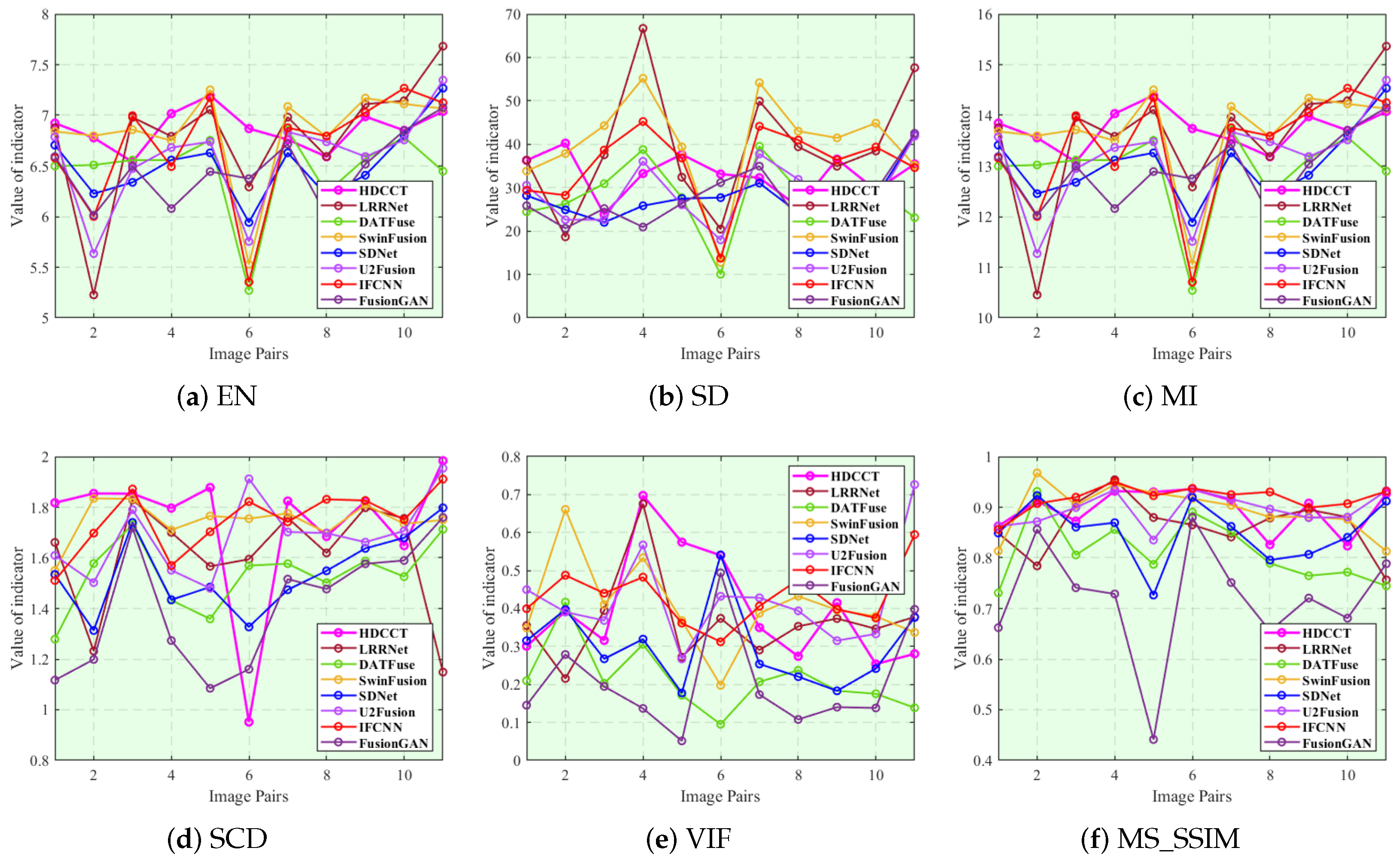
4.1.2. Evaluation Indexes
- Entropy (EN). EN represents the amount of information contained in the image. A higher value of EN represents more information learned from the input images of the fused images. Assuming that n represents the grayscale level and is the grayscale probability distribution, then the expression for EN is
- Standard deviation (SD). SD is used to calculate how spread out the mean of the fused images is. It depicts the dispersion of image information and describes the visual effect on human attention. The larger the SD, the better the visual contrast for the fused images. Let represent the mean of the fused image, represent the grayscale value of each point, and represent the width and height of the fused image, respectively; then, the formula of SD is
- Mutual information (MI). MI represents the information obtained from the input images for image fusion evaluation. The MI evaluation is general, since no assumptions are made on the nature of the relationship between image intensities in the input images. A higher MI value indicates that the fused image has extracted more information from the source image. The expression of MI is , in which and represent the information of transferring two input images to the fused image. Let , , and represent the edge histograms of infrared image, visible image and fused image, and , represents the joint histogram of input image, and fused image; then, and can be expressed as
- Sum of the correlations of differences (SCD). SCD quantifies the information transferred from input images to fused images. It evaluates the merged images by summing the correlation values. The greater the SCD, the better the quality of the fused images. Assuming that and represent the differences between the input infrared/visible image and the fused image, respectively, the expression of SCD can be written as , in which is expressed as
- Visual information fidelity (VIF). VIF describes the quality of a fused image produced by the human visual system at multi-resolutions. Let C represent the random vector in the original image and S represent the forward scalar factor. The VIF between original image X and fused image F can be expressed as
- Multi-scale structural similarity (MS_SSIM). SSIM is a metric that assesses the similarity of two images by taking into consideration brightness, contrast, and structure. MS_SSIM is a multi-scale version of SSIM that captures more detailed information from images. We assume that represents the brightness similarity at the m-th scale, and represent the contrast and structural similarity at the j-th scale, and , , and are parameters used to balance the components. The MS_SSIM between original image X and fused image F can be represented as
4.2. Experiment on TNO Image Fusion
4.3. Experiment on RoadScene Image Fusion
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Kumar, P.; Mittal, A.; Kumar, P. Fusion of thermal infrared and visible spectrum video for robust surveillance. In Proceedings of the Computer Vision, Graphics and Image Processing: 5th Indian Conference, ICVGIP 2006, Madurai, India, 13–16 December 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 528–539. [Google Scholar]
- Eslami, M.; Mohammadzadeh, A. Developing a spectral-based strategy for urban object detection from airborne hyperspectral TIR and visible data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1808–1816. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Zhang, H.; Le, Z.; Shao, Z.; Xu, H.; Ma, J. MFF-GAN: An unsupervised generative adversarial network with adaptive and gradient joint constraints for multi-focus image fusion. Inf. Fusion 2021, 66, 40–53. [Google Scholar] [CrossRef]
- Hu, H.M.; Wu, J.; Li, B.; Guo, Q.; Zheng, J. An adaptive fusion algorithm for visible and infrared videos based on entropy and the cumulative distribution of gray levels. IEEE Trans. Multimed. 2017, 19, 2706–2719. [Google Scholar] [CrossRef]
- Xiang, T.; Yan, L.; Gao, R. A fusion algorithm for infrared and visible images based on adaptive dual-channel unit-linking PCNN in NSCT domain. Infrared Phys. Technol. 2015, 69, 53–61. [Google Scholar] [CrossRef]
- Bin, Y.; Chao, Y.; Guoyu, H. Efficient image fusion with approximate sparse representation. Int. J. Wavelets Multiresolut. Inf. Process. 2016, 14, 1650024. [Google Scholar] [CrossRef]
- Naidu, V. Hybrid DDCT-PCA based multi sensor image fusion. J. Opt. 2014, 43, 48–61. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Liu, Y.; Miao, C.; Ji, J.; Li, X. MMF: A Multi-scale MobileNet based fusion method for infrared and visible image. Infrared Phys. Technol. 2021, 119, 103894. [Google Scholar] [CrossRef]
- Li, Y.; Yang, H.; Wang, J.; Zhang, C.; Liu, Z.; Chen, H. An image fusion method based on special residual network and efficient channel attention. Electronics 2022, 11, 3140. [Google Scholar] [CrossRef]
- Fu, Q.; Fu, H.; Wu, Y. Infrared and Visible Image Fusion Based on Mask and Cross-Dynamic Fusion. Electronics 2023, 12, 4342. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhai, B.; Wang, G.; Lin, J. Pedestrian Detection Method Based on Two-Stage Fusion of Visible Light Image and Thermal Infrared Image. Electronics 2023, 12, 3171. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Gao, Y.; Ma, S.; Liu, J. DCDR-GAN: A densely connected disentangled representation generative adversarial network for infrared and visible image fusion. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 549–561. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Gao, Y.; Ma, S.; Liu, J.; Xiu, X. Fusion-UDCGAN: Multifocus image fusion via a U-type densely connected generation adversarial network. IEEE Trans. Instrum. Meas. 2022, 71, 5008013. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Zhang, X.P. MEF-GAN: Multi-exposure image fusion via generative adversarial networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Wang, H.; Ji, Y.; Song, K.; Sun, M.; Lv, P.; Zhang, T. ViT-P: Classification of genitourinary syndrome of menopause from OCT images based on vision transformer models. IEEE Trans. Instrum. Meas. 2021, 70, 1–14. [Google Scholar] [CrossRef]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Yan, Z.; Tomizuka, M.; Gonzalez, J.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and visible image fusion via dual attention transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Vs, V.; Valanarasu, J.M.J.; Oza, P.; Patel, V.M. Image fusion transformer. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 3566–3570. [Google Scholar]
- Jin, X.; Xi, X.; Zhou, D.; Ren, X.; Yang, J.; Jiang, Q. An unsupervised multi-focus image fusion method based on Transformer and U-Net. IET Image Process. 2023, 17, 733–746. [Google Scholar] [CrossRef]
- Yuan, Y.; Wu, J.; Jing, Z.; Leung, H.; Pan, H. Multimodal image fusion based on hybrid CNN-transformer and non-local cross-modal attention. arXiv 2022, arXiv:2210.09847. [Google Scholar]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 31, 5998–6008. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early convolutions help transformers see better. Adv. Neural Inf. Process. Syst. 2021, 34, 30392–30400. [Google Scholar]
- Peng, Z.; Huang, W.; Gu, S.; Xie, L.; Wang, Y.; Jiao, J.; Ye, Q. Conformer: Local features coupling global representations for visual recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 367–376. [Google Scholar]
- Qu, L.; Liu, S.; Wang, M.; Song, Z. TransMEF: A transformer-based multi-exposure image fusion framework using self-supervised multi-task learning. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2126–2134. [Google Scholar] [CrossRef]
- Dogra, A.; Goyal, B.; Agrawal, S. From multi-scale decomposition to non-multi-scale decomposition methods: A comprehensive survey of image fusion techniques and its applications. IEEE Access 2017, 5, 16040–16067. [Google Scholar] [CrossRef]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Peng, J.; Feng, X.; He, G.; Fan, J. Fusion method for infrared and visible images by using non-negative sparse representation. Infrared Phys. Technol. 2014, 67, 477–489. [Google Scholar] [CrossRef]
- Zhao, J.; Chen, Y.; Feng, H.; Xu, Z.; Li, Q. Infrared image enhancement through saliency feature analysis based on multi-scale decomposition. Infrared Phys. Technol. 2014, 62, 86–93. [Google Scholar] [CrossRef]
- Lu, W.; Lan, C.; Niu, C.; Liu, W.; Lyu, L.; Shi, Q.; Wang, S. A CNN-transformer hybrid model based on CSW in transformer for UAV image object detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 1211–1231. [Google Scholar] [CrossRef]
- Yu, Z.; Lee, F.; Chen, Q. HCT-net: Hybrid CNN-transformer model based on a neural architecture search network for medical image segmentation. Appl. Intell. 2023, 53, 19990–20006. [Google Scholar] [CrossRef]
- Nie, Y.; Sommella, P.; Carratù, M.; O’Nils, M.; Lundgren, J. A deep cnn transformer hybrid model for skin lesion classification of dermoscopic images using focal loss. Diagnostics 2022, 13, 72. [Google Scholar] [CrossRef]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 2, pp. 1398–1402. [Google Scholar]
- Christoffersen, P.; Jacobs, K. The importance of the loss function in option valuation. J. Financ. Econ. 2004, 72, 291–318. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Zhang, H.; Ma, J. SDNet: A versatile squeeze-and-decomposition network for real-time image fusion. Int. J. Comput. Vis. 2021, 129, 2761–2785. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Li, H.; Xu, T.; Wu, X.J.; Lu, J.; Kittler, J. Lrrnet: A novel representation learning guided fusion network for infrared and visible images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11040–11052. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 1. [Google Scholar] [CrossRef]
- Aslantas, V.; Bendes, E. A new image quality metric for image fusion: The sum of the correlations of differences. Aeu-Int. J. Electron. Commun. 2015, 69, 1890–1896. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | EN ↑ | SD ↑ | MI ↑ | SCD ↑ | VIF ↑ | MS_SSIM ↑ |
|---|---|---|---|---|---|---|
| FusionGAN | 6.5508 | 30.6467 | 13.1015 | 1.3722 | 0.2481 | 0.7424 |
| IFCNN | 6.8001 | 36.5316 | 13.6003 | 1.7401 | 0.4685 | 0.9082 |
| U2Fusion | 6.7073 | 30.5278 | 13.4145 | 1.6855 | 0.4501 | 0.9010 |
| SDNet | 6.6932 | 33.6476 | 13.3864 | 1.5491 | 0.3694 | 0.8742 |
| SwinFusion | 6.8990 | 40.0281 | 13.7980 | 1.6775 | 0.3977 | 0.8762 |
| DATFuse | 6.4597 | 27.6206 | 12.9193 | 1.4936 | 0.2036 | 0.8045 |
| LRRNet | 6.7627 | 40.6157 | 13.5255 | 1.4773 | 0.3624 | 0.8319 |
| HDCCT | 6.9004 | 36.7903 | 13.8007 | 1.7654 | 0.4712 | 0.9017 |
| Method | EN ↑ | SD ↑ | MI ↑ | SCD ↑ | VIF ↑ | MS_SSIM ↑ |
|---|---|---|---|---|---|---|
| FusionGAN | 7.1792 | 41.7302 | 14.3584 | 1.4290 | 0.2550 | 0.7277 |
| IFCNN | 7.0799 | 37.2082 | 14.1597 | 1.6853 | 0.4129 | 0.8969 |
| U2Fusion | 6.8991 | 33.7714 | 13.7981 | 1.6181 | 0.3878 | 0.8980 |
| SDNet | 7.3552 | 47.1088 | 14.7104 | 1.6778 | 0.3940 | 0.8937 |
| SwinFusion | 6.6617 | 41.2911 | 13.3235 | 1.6544 | 0.3648 | 0.8033 |
| DATFuse | 6.5200 | 29.0206 | 13.0400 | 1.4062 | 0.1873 | 0.7216 |
| LRRNet | 7.1277 | 43.7184 | 14.2555 | 1.7167 | 0.3731 | 0.7829 |
| HDCCT | 7.3404 | 49.6979 | 14.6808 | 1.8809 | 0.4674 | 0.9054 |
| CNN | Transformer | EN ↑ | SD ↑ | MI ↑ | SCD ↑ | VIF ↑ | MS_SSIM ↑ |
|---|---|---|---|---|---|---|---|
| ✓ | 6.7951 | 36.5268 | 13.4582 | 1.7205 | 0.4486 | 0.8096 | |
| ✓ | 6.8935 | 36.6960 | 13.4796 | 1.7409 | 0.4580 | 0.8734 | |
| ✓ | ✓ | 6.9004 | 36.7903 | 13.8007 | 1.7654 | 0.4712 | 0.9017 |
| CNN | Transformer | EN ↑ | SD ↑ | MI ↑ | SCD ↑ | VIF ↑ | MS_SSIM ↑ |
|---|---|---|---|---|---|---|---|
| ✓ | 7.0485 | 37.1084 | 14.0617 | 1.6559 | 0.4073 | 0.8962 | |
| ✓ | 7.3300 | 49.2201 | 14.6601 | 1.8803 | 0.4627 | 0.9031 | |
| ✓ | ✓ | 7.3404 | 49.6979 | 14.6808 | 1.8809 | 0.4674 | 0.9054 |
| EN ↑ | SD ↑ | MI ↑ | SCD ↑ | VIF ↑ | MS_SSIM ↑ | ||
|---|---|---|---|---|---|---|---|
| ✓ | 7.3032 | 59.4720 | 14.6065 | 0.3843 | 0.3192 | 0.6274 | |
| ✓ | 7.3127 | 52.6281 | 14.6253 | 1.8779 | 0.4800 | 0.9040 | |
| ✓ | ✓ | 7.3404 | 49.6979 | 14.6808 | 1.8809 | 0.4674 | 0.9054 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; He, H.; Shi, J. HDCCT: Hybrid Densely Connected CNN and Transformer for Infrared and Visible Image Fusion. Electronics 2024, 13, 3470. https://doi.org/10.3390/electronics13173470
Li X, He H, Shi J. HDCCT: Hybrid Densely Connected CNN and Transformer for Infrared and Visible Image Fusion. Electronics. 2024; 13(17):3470. https://doi.org/10.3390/electronics13173470
Chicago/Turabian StyleLi, Xue, Hui He, and Jin Shi. 2024. "HDCCT: Hybrid Densely Connected CNN and Transformer for Infrared and Visible Image Fusion" Electronics 13, no. 17: 3470. https://doi.org/10.3390/electronics13173470
APA StyleLi, X., He, H., & Shi, J. (2024). HDCCT: Hybrid Densely Connected CNN and Transformer for Infrared and Visible Image Fusion. Electronics, 13(17), 3470. https://doi.org/10.3390/electronics13173470