
DynER: Optimized Test Case Generation for Representational State Transfer (REST)ful Application Programming Interface (API) Fuzzers Guided by Dynamic Error Responses


Abstract
1. Introduction
- We propose a novel test case generation method named DynER. DynER generates new test requests by purposefully revising the errors of invalid tested requests guided by dynamic error responses. DynER designs two new strategies for generating legal parameter values, which explore the potential of LLMs in assisting fuzzers in understanding dynamic error responses and exploit the resource design features of RESTful API to actively access resource information from the SUTs.
- We apply DynER to the state-of-the-art fuzzer RESTler and implement DynER-RESTler. DynER can be generally applied to a broad range of existing RESTful API fuzzers and facilitate future research on RESTful API fuzzing.
- We evaluate DynER-RESTler against RESTler and foREST on real-world RESTful services. The results demonstrate the significant performance of DynER on high-quality test request generation. DynER can significantly optimize the test case generation and improve fuzzing performance for RESTful API fuzzers.
2. Related Works
2.1. Automated Test Generation for RESTful API
2.2. Large Language Model for Fuzzing
3. Background
3.1. RESTful API
3.2. RESTful API Fuzzing
3.3. Large Language Models
4. Motivation
4.1. Limitations of Existing Test Case Generation
4.2. Dynamic Error Responses of Invalid Test Requests
4.3. API-Related Resources of RESTful Service
5. Method
5.1. Overview of DynER
5.2. Error Parameter Revision Strategy Based on LLM Semantic Understanding
| Algorithm 1 Error Parameter Revision Strategy Based on LLM Semantic Understanding |
|
- 1.
- Endpoint path. The LLM should revise only the parameter fields within the endpoint path of the original request. If the fixed fields of the path are revised, i.e., the endpoint is revised, the resulting request no longer corresponds to the original request and becomes unusable. To prevent this, the strategy establishes multiple path-checking rules as follows:
- The number of path separators, i.e., “/”, should remain consistent before and after.
- Any two consecutive parts separated by “/” should not be modified simultaneously.
- 2.
- HTTP method. The LLM should not revise the HTTP method of the original request. If the method type is revised, the output will fail verification and will be discarded.
- 3.
- User authentication information. Modifying the test user authentication information could affect the results of the test request. Therefore, during verification, the authentication information of output requests is restored to the original test user authentication details.
5.3. Error Parameter Revision Strategy Based on Recursively Constructing Parent Requests
| Algorithm 2 Error Parameter Revision Strategy Based on Recursively Constructing Parent Requests |
|
6. Evaluation
- RQ1: How is the improvement of DynER in generating effective test cases for the most representative RESTful API fuzzer RESTler?
- RQ2: How is the fuzzing performance of DynER-RESTler compared to the existing tools, such as RESTler and foREST?
- RQ3: How do the two error parameter revision strategies of DynER contribute to its overall performance?
6.1. Implementation and Experimental Setting
- Code Coverage (LOCs). Code coverage can reflect the exploration capability of the fuzzers. We measure the number of covered code lines triggered by test requests.
- Number of successfully tested request types (STRTs). The more unique request types are successfully tested, the more kinds of behaviors are triggered by fuzzers. We measure the number of successfully requested unique request types that obtain responses in the 20X range, which can reflect the tested depth of code logic of the RESTful service.
- Pass rate of test requests(PRTT). Receiving successful responses means the target service executes the test request, which passes the syntax and semantic checking. We measure the pass rate of each fuzzer to the syntax and semantic checking of a web service, which is calculated by dividing the number of successful responses in the 20X and 50X range by the number of total responses.
- Number of unique errors(Bugs). In the context of RESTful service, an error is considered to trigger the response in 50X range. A bug can be related to many errors. We manually classified the errors into unique bugs according to response bodies, server logs, etc.
6.2. Effectiveness in Test Case Generation (RQ1)
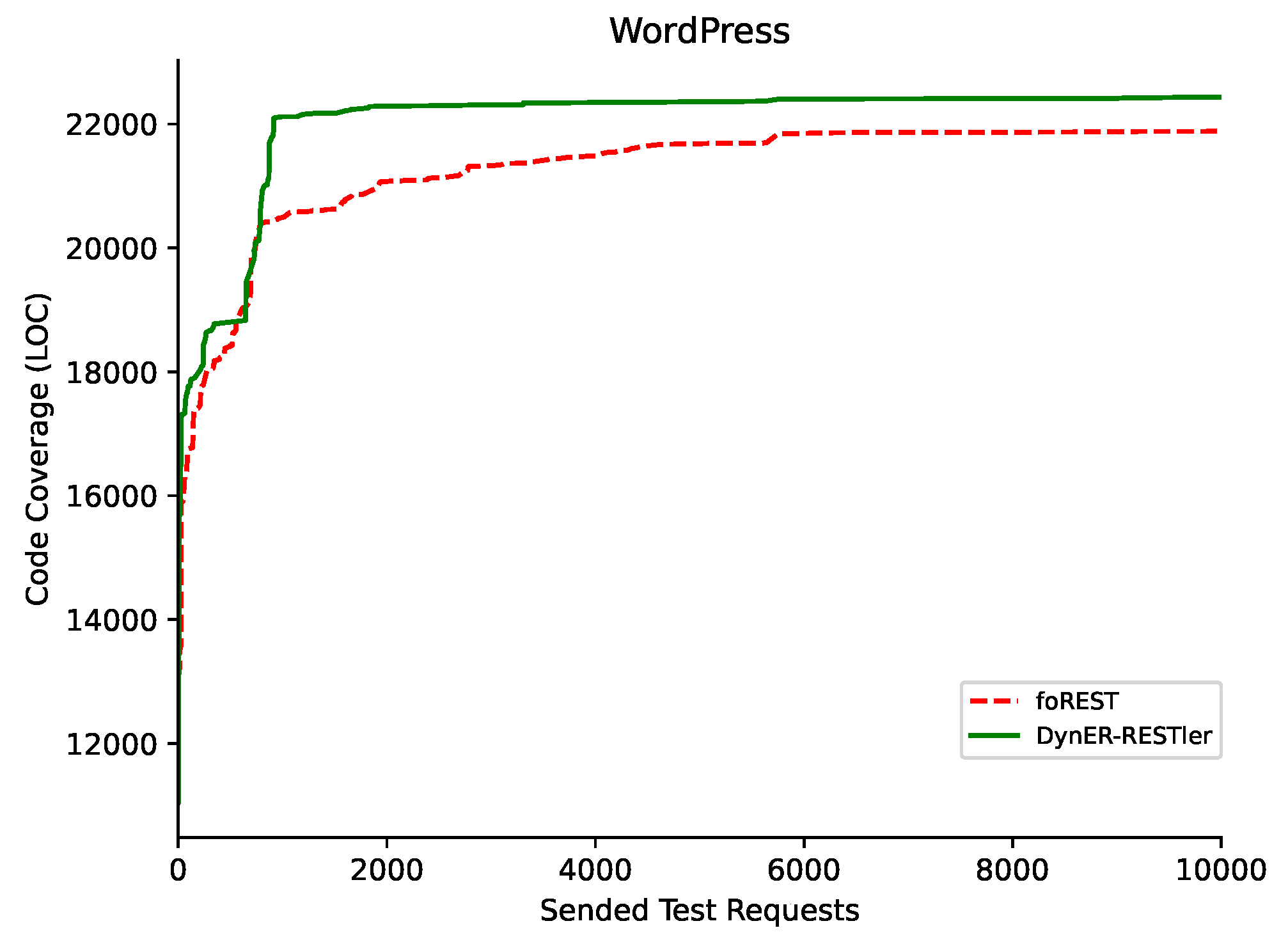
6.3. Fuzzing Performance (RQ2)
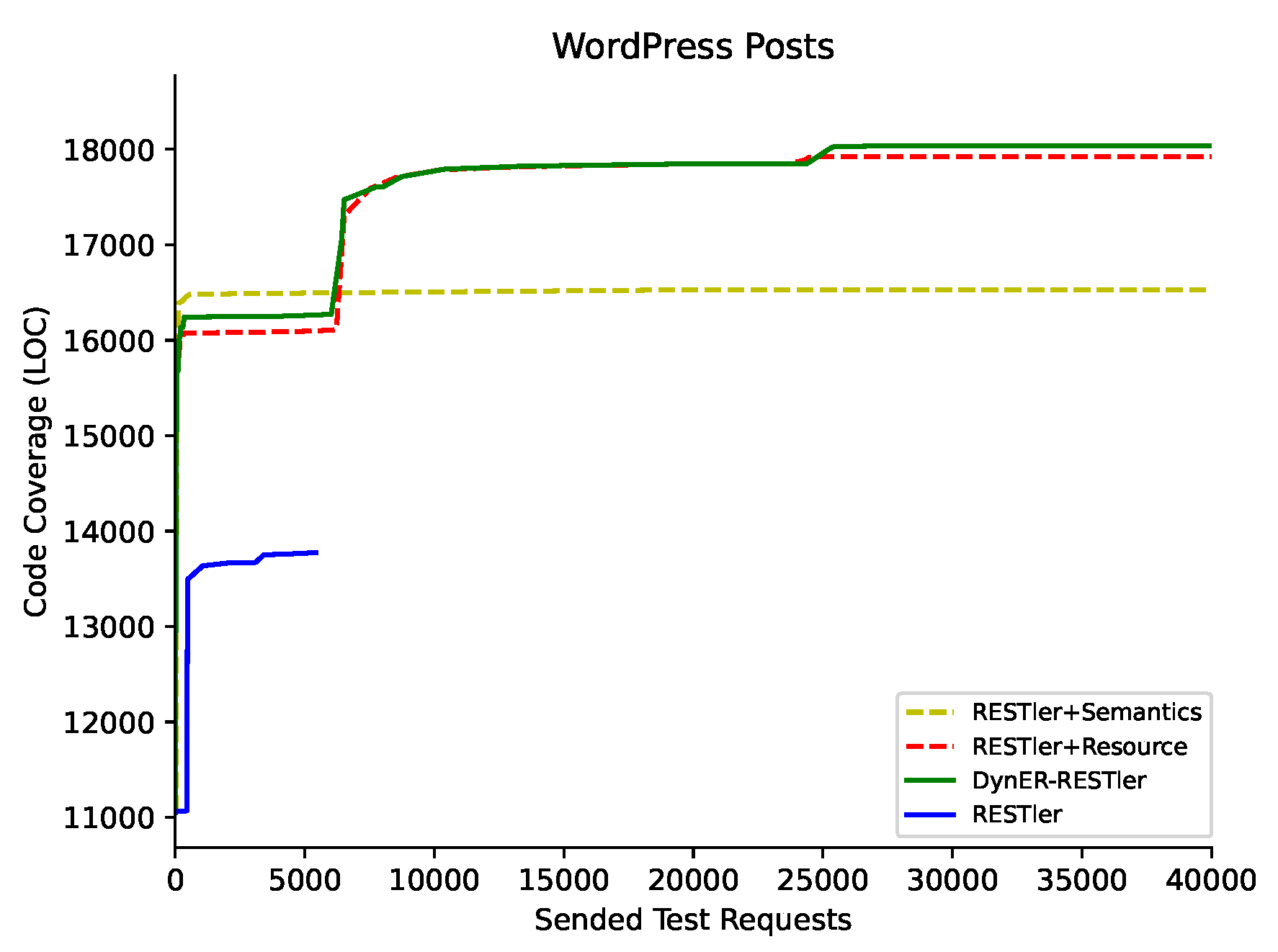
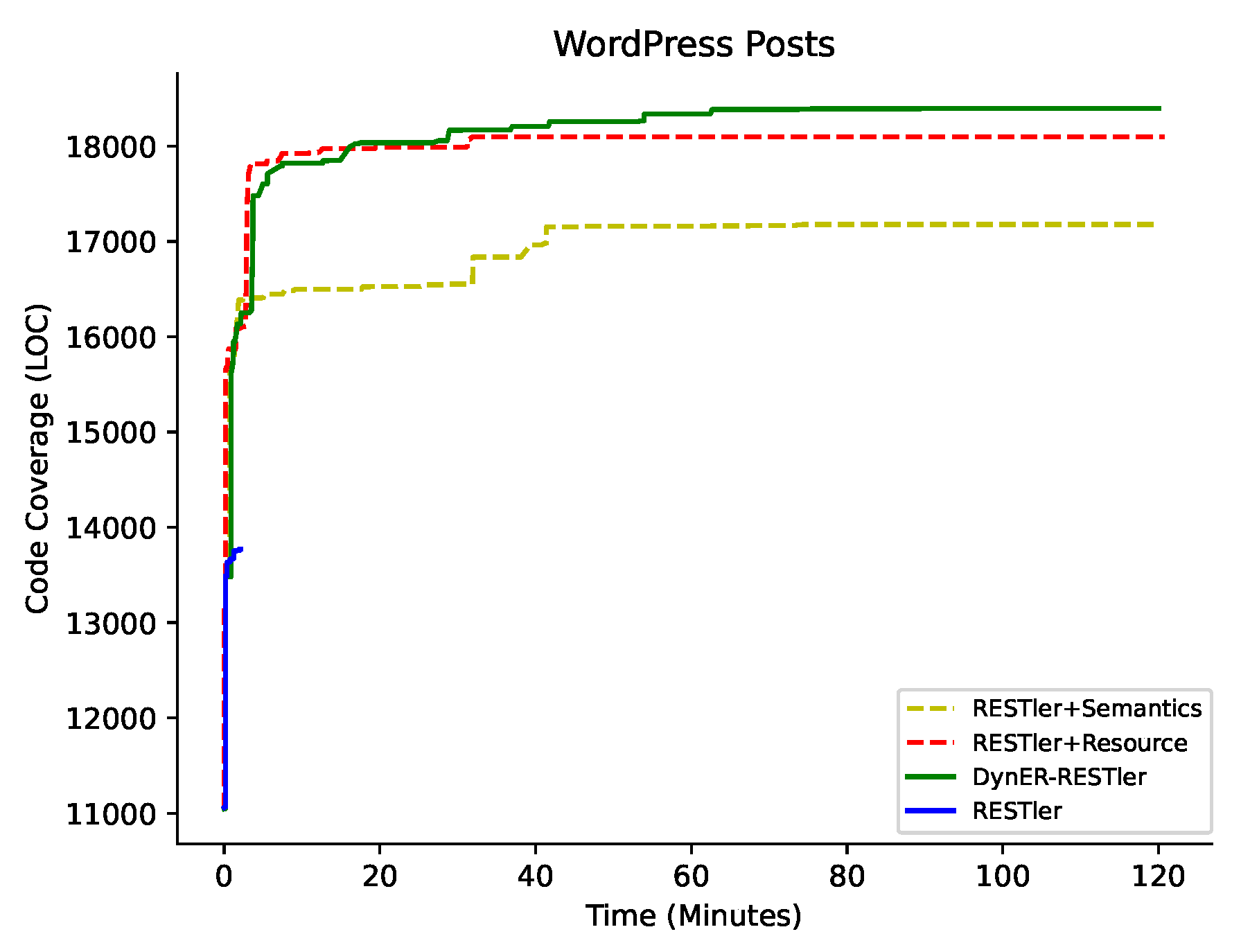
6.4. Ablation Study (RQ3)
6.5. Case Study of New Bugs
7. Discussion and Future Work
7.1. Threats to Validity
7.2. Future Work
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gamez-Diaz, A.; Fernandez, P.; Ruiz-Cortes, A. An analysis of RESTful APIs offerings in the industry. In Proceedings of the International Conference on Service-Oriented Computing, Malaga, Spain, 13–16 November 2017; Springer: Cham, Switzerland, 2017; pp. 589–604. [Google Scholar]
- Google Inc. Available online: https://www.google.com/ (accessed on 1 July 2024).
- Amazon Inc. Available online: https://www.amazon.com/ (accessed on 1 July 2024).
- Golmohammadi, A.; Zhang, M.; Arcuri, A. Testing restful apis: A survey. ACM Trans. Softw. Eng. Methodol. 2023, 33, 1–41. [Google Scholar] [CrossRef]
- Atlidakis, V.; Godefroid, P.; Polishchuk, M. Restler: Stateful rest api fuzzing. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), Montreal, QC, Canada, 25–31 May 2019; pp. 748–758. [Google Scholar]
- Viglianisi, E.; Dallago, M.; Ceccato, M. Resttestgen: Automated black-box testing of restful apis. In Proceedings of the 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), Porto, Portugal, 23–27 March 2020; pp. 142–152. [Google Scholar]
- Liu, Y.; Li, Y.; Deng, G.; Liu, Y.; Wan, R.; Wu, R.; Ji, D.; Xu, S.; Bao, M. Morest: Model-based RESTful API testing with execution feedback. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 1406–1417. [Google Scholar]
- Lin, J.; Li, T.; Chen, Y.; Wei, G.; Lin, J.; Zhang, S.; Xu, H. foREST: A Tree-based Black-box Fuzzing Approach for RESTful APIs. In Proceedings of the 2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE), Florence, Italy, 9–12 October 2023; pp. 695–705. [Google Scholar]
- Lyu, C.; Xu, J.; Ji, S.; Zhang, X.; Wang, Q.; Zhao, B.; Pan, G.; Cao, W.; Chen, P.; Beyah, R. {MINER}: A Hybrid {Data-Driven} Approach for {REST}{API} Fuzzing. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 4517–4534. [Google Scholar]
- Wu, H.; Xu, L.; Niu, X.; Nie, C. Combinatorial testing of restful apis. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 25–27 May 2022; pp. 426–437. [Google Scholar]
- Martin-Lopez, A.; Segura, S.; Ruiz-Cortés, A. RESTest: Black-Box Constraint-Based Testing of RESTful Web APIs. In Proceedings of the Service-Oriented Computing: 18th International Conference, ICSOC 2020, Dubai, United Arab Emirates, 14–17 December 2020; Proceedings. Springer: Berlin/Heidelberg, Germany, 2020; pp. 459–475. [Google Scholar] [CrossRef]
- Kim, M.; Corradini, D.; Sinha, S.; Orso, A.; Pasqua, M.; Tzoref-Brill, R.; Ceccato, M. Enhancing REST API Testing with NLP Techniques. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, WA, USA, 17–21 July 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 1232–1243. [Google Scholar] [CrossRef]
- Alonso, J.C.; Martin-Lopez, A.; Segura, S.; García, J.M.; Ruiz-Cortés, A. ARTE: Automated Generation of Realistic Test Inputs for Web APIs. IEEE Trans. Softw. Eng. 2023, 49, 348–363. [Google Scholar] [CrossRef]
- OpenAPI Specification. Available online: https://swagger.io/specification/ (accessed on 1 July 2024).
- The Most-Comprehensive AI-Powered DevSecOps Platform | GitLab. Available online: https://about.gitlab.com/ (accessed on 1 July 2024).
- Blog Tool, Publishing Platform, and CMS—WordPress.org. Available online: https://wordpress.org/ (accessed on 1 July 2024).
- Atlidakis, V.; Godefroid, P.; Polishchuk, M. Checking security properties of cloud service REST APIs. In Proceedings of the 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), Porto, Portugal, 23–27 March 2020; pp. 387–397. [Google Scholar]
- Godefroid, P.; Lehmann, D.; Polishchuk, M. Differential regression testing for REST APIs. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2020; pp. 312–323. [Google Scholar]
- Godefroid, P.; Huang, B.Y.; Polishchuk, M. Intelligent REST API data fuzzing. In Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, 8–13 November 2020; pp. 725–736. [Google Scholar]
- Karlsson, S.; Čaušević, A.; Sundmark, D. QuickREST: Property-based Test Generation of OpenAPI-Described RESTful APIs. In Proceedings of the 2020 IEEE 13th International Conference on Software Testing, Validation and Verification (ICST), Porto, Portugal, 23–27 March 2020; pp. 131–141. [Google Scholar] [CrossRef]
- Hatfield-Dodds, Z.; Dygalo, D. Deriving Semantics-Aware Fuzzers from Web API Schemas. In Proceedings of the 2022 IEEE/ACM 44th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Pittsburgh, PA, USA, 22–24 May 2022; pp. 345–346. [Google Scholar] [CrossRef]
- Tsai, C.H.; Tsai, S.C.; Huang, S.K. REST API Fuzzing by Coverage Level Guided Blackbox Testing. In Proceedings of the 2021 IEEE 21st International Conference on Software Quality, Reliability and Security (QRS), Hainan, China, 6–10 December 2021; pp. 291–300. [Google Scholar] [CrossRef]
- Martin-Lopez, A.; Segura, S.; Ruiz-Cortés, A. Test coverage criteria for RESTful web APIs. In Proceedings of the 10th ACM SIGSOFT International Workshop on Automating TEST Case Design, Selection, and Evaluation, A-TEST 2019, Tallinn, Estonia, 26–27 August 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 15–21. [Google Scholar] [CrossRef]
- Atlidakis, V.; Geambasu, R.; Godefroid, P.; Polishchuk, M.; Ray, B. Pythia: Grammar-based fuzzing of rest apis with coverage-guided feedback and learning-based mutations. arXiv 2020, arXiv:2005.11498. [Google Scholar]
- Arcuri, A. RESTful API Automated Test Case Generation. In Proceedings of the 2017 IEEE International Conference on Software Quality, Reliability and Security (QRS), Prague, Czech Republic, 25–29 July 2017; pp. 9–20. [Google Scholar] [CrossRef]
- Arcuri, A. RESTful API Automated Test Case Generation with EvoMaster. ACM Trans. Softw. Eng. Methodol. 2019, 28, 3. [Google Scholar] [CrossRef]
- Arcuri, A.; Galeotti, J.P. Handling SQL Databases in Automated System Test Generation. ACM Trans. Softw. Eng. Methodol. 2020, 29, 22. [Google Scholar] [CrossRef]
- Zhang, M.; Arcuri, A. Adaptive Hypermutation for Search-Based System Test Generation: A Study on REST APIs with EvoMaster. ACM Trans. Softw. Eng. Methodol. 2021, 31, 2. [Google Scholar] [CrossRef]
- Zhang, M.; Arcuri, A. Enhancing Resource-Based Test Case Generation for RESTful APIs with SQL Handling. In Proceedings of the Search-Based Software Engineering: 13th International Symposium, SSBSE 2021, Bari, Italy, 11–12 October 2021; Proceedings. Springer: Berlin/Heidelberg, Germany, 2021; pp. 103–117. [Google Scholar] [CrossRef]
- Kim, M.; Xin, Q.; Sinha, S.; Orso, A. Automated test generation for rest apis: No time to rest yet. In Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual, 18–22 July 2022; pp. 289–301. [Google Scholar]
- Martin-Lopez, A.; Segura, S.; Müller, C.; Ruiz-Cortés, A. Specification and Automated Analysis of Inter-Parameter Dependencies in Web APIs. IEEE Trans. Serv. Comput. 2022, 15, 2342–2355. [Google Scholar] [CrossRef]
- Mirabella, A.G.; Martin-Lopez, A.; Segura, S.; Valencia-Cabrera, L.; Ruiz-Cortés, A. Deep Learning-Based Prediction of Test Input Validity for RESTful APIs. In Proceedings of the 2021 IEEE/ACM Third International Workshop on Deep Learning for Testing and Testing for Deep Learning (DeepTest), Madrid, Spain, 1 June 2021; pp. 9–16. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Comput. Surv. 2023, 55, 195. [Google Scholar] [CrossRef]
- Lemieux, C.; Inala, J.P.; Lahiri, S.K.; Sen, S. CodaMosa: Escaping Coverage Plateaus in Test Generation with Pre-Trained Large Language Models. In Proceedings of the 45th International Conference on Software Engineering, ICSE ’23, Melbourne, Australia, 17–19 May 2023; IEEE Press: Piscataway, NJ, USA, 2023; pp. 919–931. [Google Scholar] [CrossRef]
- Deng, Y.; Xia, C.S.; Peng, H.; Yang, C.; Zhang, L. Large Language Models Are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2023, Seattle, WA, USA, 17–21 July 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 423–435. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pondé, H.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Fried, D.; Aghajanyan, A.; Lin, J.; Wang, S.I.; Wallace, E.; Shi, F.; Zhong, R.; Tau Yih, W.; Zettlemoyer, L.; Lewis, M. InCoder: A Generative Model for Code Infilling and Synthesis. arXiv 2022, arXiv:2204.05999. [Google Scholar]
- Deng, Y.; Xia, C.S.; Yang, C.; Zhang, S.D.; Yang, S.; Zhang, L. Large Language Models are Edge-Case Generators: Crafting Unusual Programs for Fuzzing Deep Learning Libraries. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE ’24, Lisbon, Portugal, 14–20 April 2024; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Ackerman, J.; Cybenko, G. Large Language Models for Fuzzing Parsers (Registered Report). In Proceedings of the 2nd International Fuzzing Workshop, FUZZING 2023, Seattle, WA, USA, 17 July 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 31–38. [Google Scholar] [CrossRef]
- Meng, R.; Mirchev, M.; Böhme, M.; Roychoudhury, A. Large language model guided protocol fuzzing. In Proceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 26 February–1 March 2024. [Google Scholar]
- Cheng, M.; Zhu, K.; Chen, Y.; Yang, G.; Lu, Y.; Lu, C. MSFuzz: Augmenting Protocol Fuzzing with Message Syntax Comprehension via Large Language Models. Electronics 2024, 13, 2632. [Google Scholar] [CrossRef]
- Wang, J.; Yu, L.; Luo, X. LLMIF: Augmented Large Language Model for Fuzzing IoT Devices. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP). IEEE Computer Society, San Francisco, CA, USA, 23 May 2024; p. 196. [Google Scholar]
- Xia, C.S.; Paltenghi, M.; Le Tian, J.; Pradel, M.; Zhang, L. Fuzz4All: Universal Fuzzing with Large Language Models. In Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, ICSE’24, Lisbon, Portugal, 14–20 April 2024; Association for Computing Machinery: New York, NY, USA, 2024. [Google Scholar] [CrossRef]
- Decrop, A.; Perrouin, G.; Papadakis, M.; Devroey, X.; Schobbens, P.Y. You Can REST Now: Automated Specification Inference and Black-Box Testing of RESTful APIs with Large Language Models. arXiv 2024, arXiv:2402.05102. [Google Scholar]
- Kim, M.; Stennett, T.; Shah, D.; Sinha, S.; Orso, A. Leveraging Large Language Models to Improve REST API Testing. In Proceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results, ICSE-NIER’24, Lisbon, Portugal, 14–20 April 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 37–41. [Google Scholar] [CrossRef]
- Richards, R.; Richards, R. Representational state transfer (rest). In Pro PHP XML and Web Services; Apress: New York, NY, USA, 2006; pp. 633–672. [Google Scholar]
- Fielding, R.T. Architectural Styles and the Design of Network-Based Software Architectures; University of California: Irvine, CA, USA, 2000. [Google Scholar]
- What is REST? Available online: https://restfulapi.net/ (accessed on 1 July 2024).
- Berners-Lee, T.; Fielding, R.; Frystyk, H. Hypertext transfer protocol–HTTP/1.0; RFC Editor: Marina del Rey, CA, USA, 1996; Volume 1945, pp. 1–60. [Google Scholar]
- Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; et al. Lamda: Language models for dialog applications. arXiv 2022, arXiv:2201.08239. [Google Scholar]
- Ye, Q.; Axmed, M.; Pryzant, R.; Khani, F. Prompt engineering a prompt engineer. arXiv 2023, arXiv:2311.05661. [Google Scholar]
- HTTP Methods. Available online: https://restfulapi.net/http-methods/ (accessed on 1 July 2024).
- Shelby, Z. RFC 6690: Constrained RESTful Environments (CoRE) Link Format; RFC Editor: Marina del Rey, CA, USA, 2012; pp. 1–20. [Google Scholar]
- Nadkarni, P.M.; Ohno-Machado, L.; Chapman, W.W. Natural language processing: An introduction. J. Am. Med Inform. Assoc. 2011, 18, 544–551. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RESTful Service | API Group | # Request Types | Description |
|---|---|---|---|
| WordPress5.8.1 | Posts | 11 | API to maintain posts resource. |
| Pages | 11 | API to maintain page resource. | |
| Users | 8 | API to maintain user resource. | |
| Medias | 5 | API to maintain media resource. | |
| Categories | 5 | API to maintain category resource. | |
| Tags | 5 | API to maintain tag resource. | |
| Comments | 5 | API to maintain comment resource. | |
| Themes | 2 | API to maintain theme resource. | |
| Taxonomies | 2 | API to maintain taxonomy resource. | |
| Types | 2 | API to maintain type resource. | |
| Status | 2 | API to maintain status resource. | |
| Settings | 2 | API to maintain setting of the website. | |
| GitLab14.4.2-ee.0. | Projects | 33 | API to maintain project resource. |
| Issues | 24 | API to maintain issue resource. | |
| Groups | 23 | API to maintain group resource. |
| RESTful Service | API Group | # Request Types | RESTler | DynER-RESTler | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| LOCs | STRTs | PRTT | Bugs | LOCs | STRTs | PRTT | Bugs | |||
| WordPress | Pages | 11 | 13,542 | 0 | <1% | 0 | 16,931 | 10 | 40.90% | 0 |
| Posts | 11 | 13,774 | 0 | <1% | 0 | 18,404 | 10 | 58.29% | 0 | |
| Media | 5 | 13,618 | 0 | <1% | 0 | 16,834 | 4 | 73.98% | 1 | |
| GitLab | Projects | 33 | 2164 | 5 | 7.14% | 0 | 7669 | 29 | 32.91% | 3 |
| Issues | 24 | 1480 | 0 | <1% | 0 | 5799 | 22 | 36.87% | 2 | |
| Groups | 23 | 1233 | 0 | <1% | 0 | 6429 | 21 | 45.36% | 2 | |
| RESTful Service | API Group | # Request Types | RESTler | foREST | DynER-RESTler | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LOCs | STRTs | PRTT | Bugs | LOCs | STRTs | PRTT | Bugs | LOCs | STRTs | PRTT | Bugs | |||
| WordPress | All | 60 | 17,699 | 4 | <1% | 2 | 21,933 | 48 | 6.50% | 9 | 22,351 | 54 | 47.71% | 7 |
| GitLab | All | 80 | 2255 | 0 | <1% | 2 | 15,989 | 57 | 8.57% | 5 | 16,267 | 70 | 34.90% | 4 |
| RESTful Service | API Group | # Request Types | RESTler | RESTler+Semantics | RESTler+Resource | DynER-RESTler | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LOCs | STRTs | PRTT | LOCs | STRTs | PRTT | LOCs | STRTs | PRTT | LOCs | STRTs | PRTT | |||
| WordPress | Posts | 11 | 13,774 | 0 | <1% | 17,179 | 5 | 84.54% | 18,101 | 9 | 67.31% | 18,397 | 10 | 50.26% |
| GitLab | Projects | 33 | 2164 | 5 | 7.14% | 6389 | 20 | 39.75% | 7777 | 27 | 30.62% | 7669 | 29 | 32.91% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Chen, Y.; Pan, Z.; Chen, Y.; Li, Y.; Li, Y.; Zhang, M.; Shen, Y. DynER: Optimized Test Case Generation for Representational State Transfer (REST)ful Application Programming Interface (API) Fuzzers Guided by Dynamic Error Responses. Electronics 2024, 13, 3476. https://doi.org/10.3390/electronics13173476
Chen J, Chen Y, Pan Z, Chen Y, Li Y, Li Y, Zhang M, Shen Y. DynER: Optimized Test Case Generation for Representational State Transfer (REST)ful Application Programming Interface (API) Fuzzers Guided by Dynamic Error Responses. Electronics. 2024; 13(17):3476. https://doi.org/10.3390/electronics13173476
Chicago/Turabian StyleChen, Juxing, Yuanchao Chen, Zulie Pan, Yu Chen, Yuwei Li, Yang Li, Min Zhang, and Yi Shen. 2024. "DynER: Optimized Test Case Generation for Representational State Transfer (REST)ful Application Programming Interface (API) Fuzzers Guided by Dynamic Error Responses" Electronics 13, no. 17: 3476. https://doi.org/10.3390/electronics13173476
APA StyleChen, J., Chen, Y., Pan, Z., Chen, Y., Li, Y., Li, Y., Zhang, M., & Shen, Y. (2024). DynER: Optimized Test Case Generation for Representational State Transfer (REST)ful Application Programming Interface (API) Fuzzers Guided by Dynamic Error Responses. Electronics, 13(17), 3476. https://doi.org/10.3390/electronics13173476