Abstract
The pantograph–catenary system (PCS) is essential for trains to obtain electrical energy. As the train’s operating speed increases, the vibration between the pantograph and the catenary intensifies, reducing the quality of the current collection. Active control may significantly reduce the vibration of the PCS, effectively lower the cost of line retrofitting, and enhance the quality of the current collection. This article proposes an improved deep deterministic policy gradient (IDDPG) for the pantograph active control problem, which delays updating the Actor and Target–Actor networks and adopts a reconstructed experience replay mechanism. The deep reinforcement learning (DRL) environment module was first established by creating a PCS coupling model. On this basis, the controller’s DRL module is precisely designed using the IDDPG strategy. Ultimately, the control strategy is integrated with the PCS for training, and the controller’s performance is validated on the PCS. Simulation experiments show that the improved strategy significantly reduces the training time, enhances the steady-state performance of the agent during later training stages, and effectively reduces the standard deviation of the pantograph–catenary contact force (PCCF) by an average of over 51.44%, effectively improving the quality of current collection.
1. Introduction
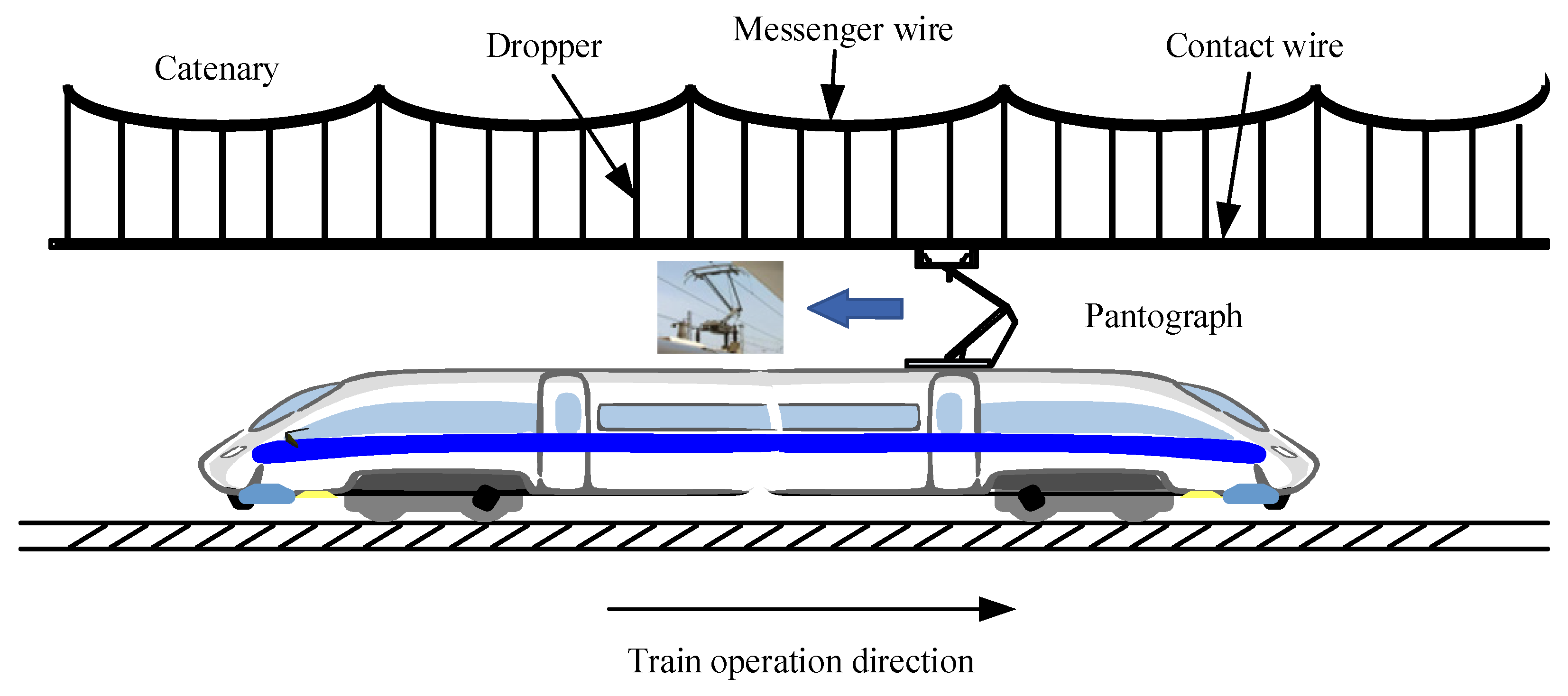
The critical current collection quality component of the electrified railway traction power supply system is the pantograph–catenary system (PCS), which plays an essential role in transferring electrical energy to the train [1]. Figure 1 depicts the schematic diagram of the high-speed railway power control system. The system depicted in Figure 1 is composed of a pantograph and a simple chain-shaped catenary, which primarily includes the messenger wire, dropper, and contact wire. The effectiveness of current collection between the PCS is a critical factor that influences the stability and safety of the train power supply. Good sliding contact between the PCS is a prerequisite to achieving a high-quality current collection. As the operating train speeds up, the oscillation amplitude among the PCS becomes larger. Moreover, maintaining a good contact condition becomes very difficult under external random disturbances and uneven contact. On the one hand, excessive pantograph–catenary contact force (PCCF) may lead to wear on both the pantograph carbon slider and contact wire, resulting in higher operational costs for high-speed railway lines. Insufficient contact forces can result in the pantograph and the contact wire becoming disconnected, causing arc breakdown, which then results in arcing phenomena [2], which affects the effectiveness of the current collection for the train. In serious cases, it may lead to disruptions to the train’s power supply. The train power supply’s quality is directly impacted by the unstable contact between the pantograph and contact wire, shortening the system’s anticipated lifespan, and may even cause the PCS to eventually become paralyzed. Therefore, reducing vibration between the PCS is essential for high-speed railway transportation [3].
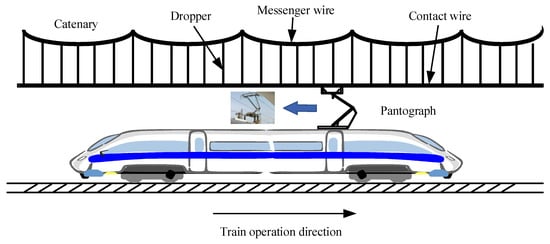
Figure 1.
Schematic diagram of the high-speed railway PCS.
In order to reduce fluctuations in contact force, existing research primarily focuses on two aspects: the improvement of catenary structure and pantograph active control. Because of the catenary’s intricate design, it cannot adaptively adjust to the changes in numerous different catenary parameters and external environmental conditions [4]. Improving the catenary structure requires the reconstruction of the existing railway line, and previous studies have demonstrated that the enhancement potential for the pantograph suspension system is constrained [5].
Therefore, analyzing this problem from the perspective of pantograph active control is a more reasonable and efficient method [6]. Only some control methods need to be added to the existing pantograph. It does not need to optimize the structure of the catenary and can be applied on different railway lines with better applicability.
The active control of pantographs in high-speed railways has been a topic of interest in recent research. In Ref. [7], the accelerated robust adaptive output feedback control method, based on a high-gain observer and utilizing only output information, ensures not only the ultimately uniform bounded tracking error of the contact force but also achieves this with an accelerated preassigned decay rate. Reference [8] employed a proportional–integral–derivative controller for active pantograph torque control to compensate for actual contact force errors. In Ref. [9], the impact of external environmental pulsating wind excitation on the dynamic coupling performance of the pantograph–catenary system is addressed, and a variable universe fuzzy fractional-order PID active control method is proposed for the pantograph. In Refs. [10,11], optimal control of the pantograph for high-speed railways considering actuator time delay is studied. Reference [12] proposes a sliding mode controller with a proportional–derivative (PD) sliding surface for high-speed active pantographs to enhance the quality of current collection under strong random wind fields. In Ref. [13], a novel high-dynamic pantograph test rig with precise virtual catenary simulation is introduced; the proposed test rig controller combines model predictive impedance control to match the desired catenary dynamics. In Ref. [14], a new active control strategy for the pantograph in high-speed electrified railways is suggested based on multi-objective robust control. In Ref. [15], an output feedback scheme is presented to design the active control of the pantograph–catenary system. However, some problems still need to be solved to address practical application cases. (1) Some controllers primarily rely on numerical calculation or the adjustment of parameters, and once set, the controller parameters remain unchanged, unable to adapt in real-time to a different PCS operational environment. (2) Some controllers are only applicable to fixed line parameters, and their performance cannot be verified under different lines.
Recently, deep neural networks have gained prominence across various disciplines and engineering fields, leading to the widespread use of deep reinforcement learning (DRL) techniques in areas such as robotic path planning control [16,17], computer vision [18], autonomous driving [19], and uncrewed aerial vehicle control [20]. DRL-based control strategies do not rely on an accurate system model, and the controllers are able to adaptively adjust the parameters; therefore, these strategies are suitable for PCS under different operating environments.
This paper proposes improved deep deterministic policy gradient (IDDPG) pantograph active control. (1) The state space, action space, and reward function for the PCS coupling model are designed by exploiting the capability of DRL, which does not rely on an accurate model. (2) Achieve controller parameter adaption utilizes the network soft update mechanism in the deep deterministic policy gradient (DDPG) strategy. To address the problem of substantial cumulative errors in the DDPG strategy, a delayed update network is introduced to enhance the agent’s learning efficiency. (3) The DDPG strategy adopts the experience replay mechanism to effectively use previous experience and data. To address the slow training speed of the DDPG strategy, modifications are made to the experience of the replay mechanism. These modifications aim to decrease data sample correlation, improve data sampling efficiency, accelerate the learning process of the agent, and enhance the real-time algorithm.
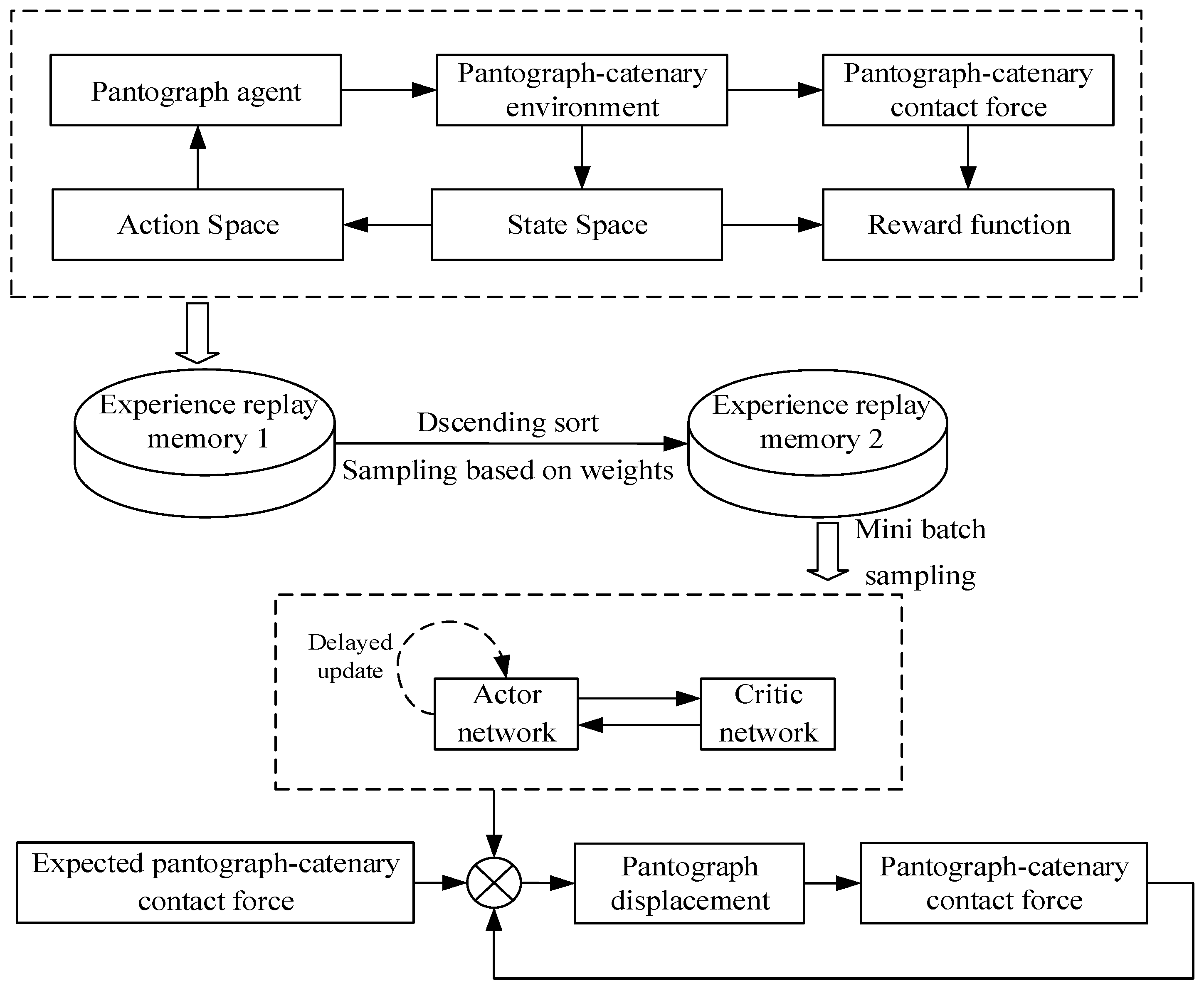
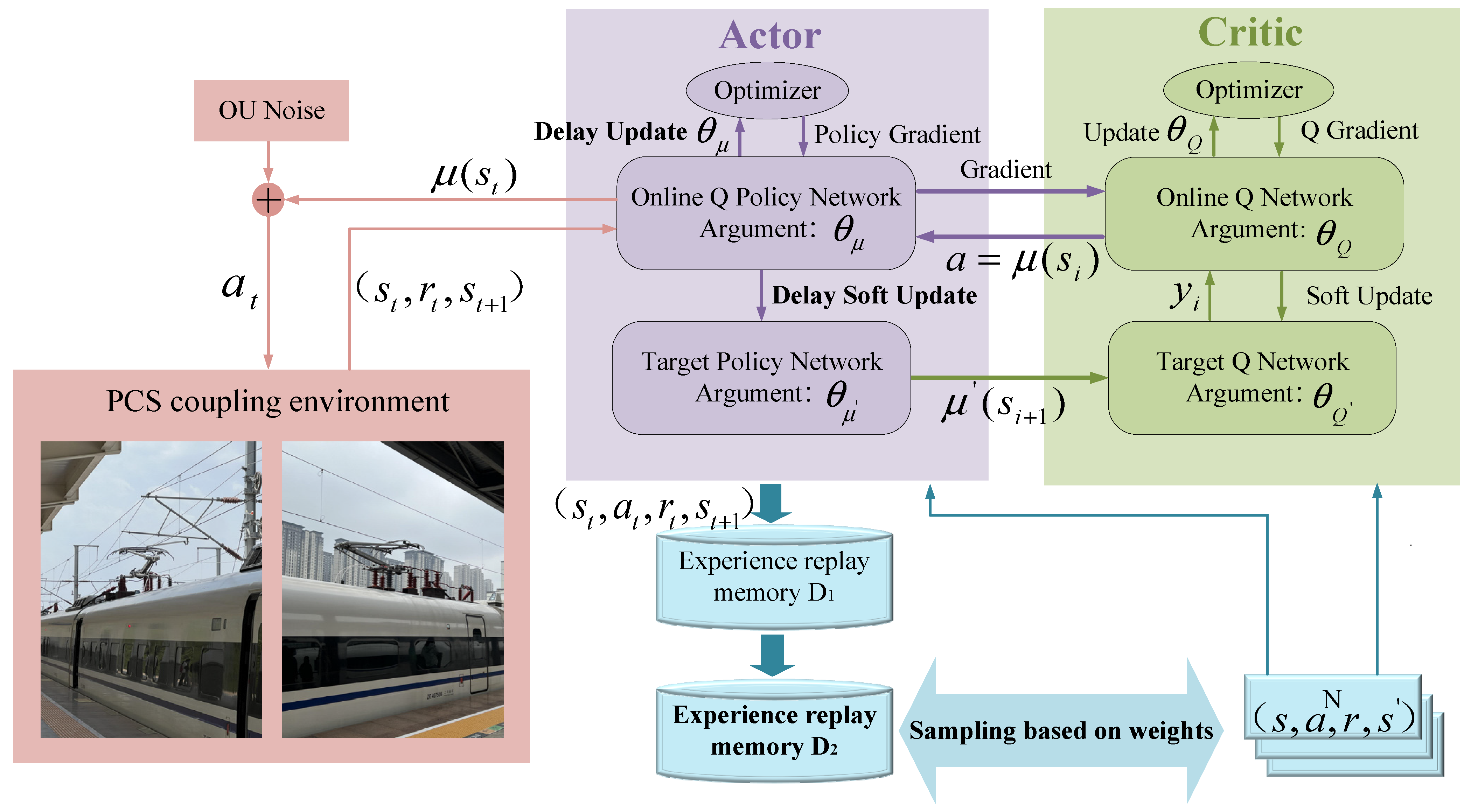
By proposing the IDDPG pantograph active control, the PCS performance optimization under high-speed train operations is achieved, which provides a feasible solution for saving line reconstruction investment and optimizing the performance of current collection. The main control structure of this paper is shown in Figure 2. The remaining content of this article is as follows: Section 2 introduces the theoretical knowledge and selected methods for the modeling of the pantograph–catenary coupling model. Section 3 introduces the basics of deep reinforcement learning and the design of the controller using this strategy. Section 4 verifies the effectiveness and robustness of the improved strategy through simulation. Section 5 contains the Discussion and Conclusions of the full article.

Figure 2.
DRL-based active control diagram for pantographs.
2. Modeling the Pantograph–Catenary Coupling System
The PCS model is the basis for studying pantograph active control. The PCS consists of the pantograph and the catenary. In this paper, the pantograph is modeled using a lumped mass model [21], and the catenary adopts a time-varying stiffness model.
2.1. Pantograph Modeling
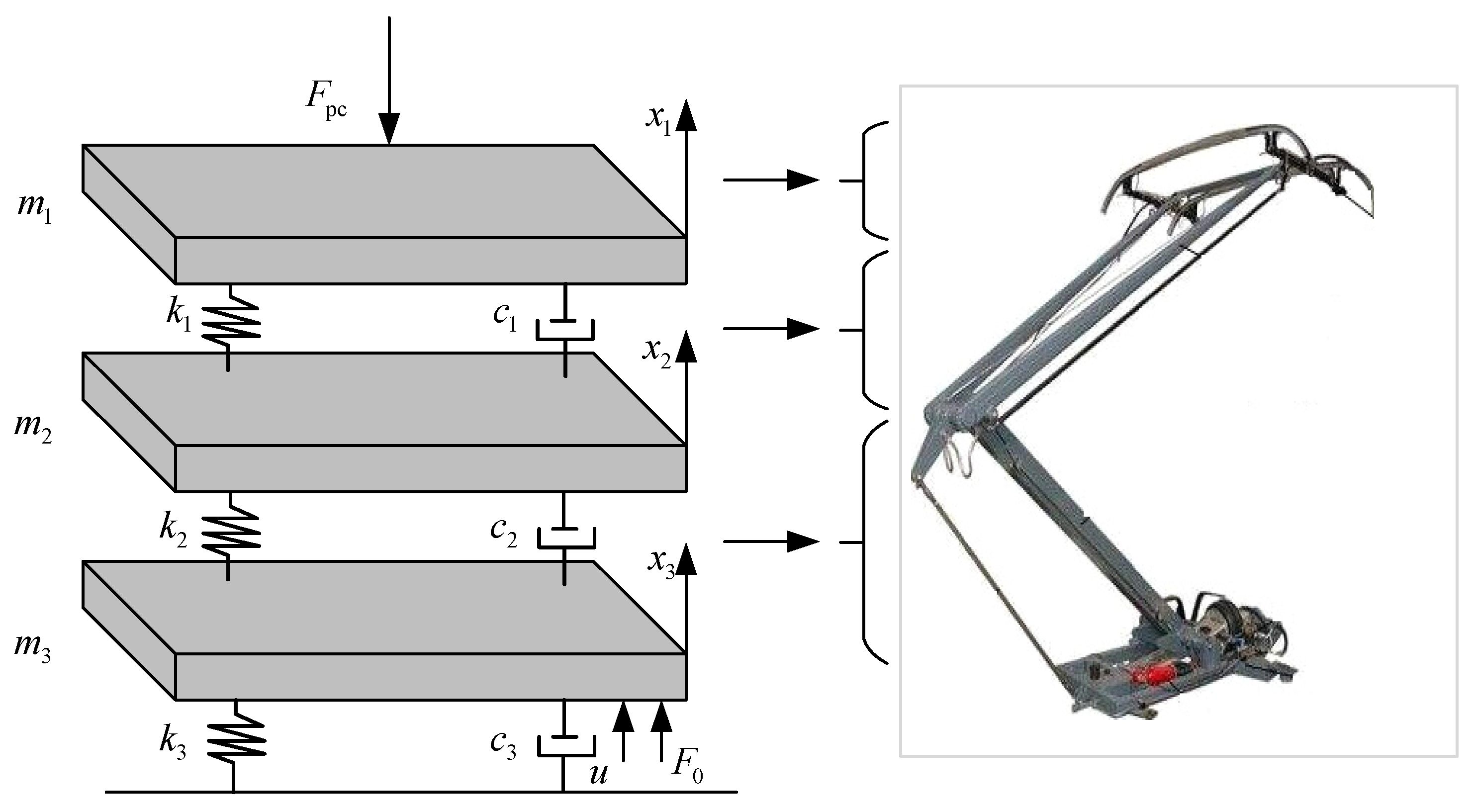
This paper introduces a lumped mass pantograph model, in which the pantograph head, upper frame, and lower frame are represented as a lumped mass model consisting of mass, damping, and stiffness, as shown in Figure 3.

Figure 3.
Pantograph lumped mass model.
In Figure 3, mi, ci, and ki (i = 1, 2, 3) represent the equivalent mass, equivalent damping coefficient, and equivalent stiffness of the pantograph head, upper frame, and lower frame, respectively. Fpc denotes the contact force of the PCS, while u represents the active control force exerted on the pantograph. F0 represents the static lift force. During operation, the pantograph is affected by aerodynamic lift forces, with its value given in [22] F0 = 70 + 0.00097v2.
In this study, we focus on the SSS400+ type roof pantograph used in the Beijing–Tianjin intercity high-speed train. The pantograph’s parameters are shown in Table 1.

Table 1.
Parameters of SSS400+ pantographs.
The vertical motion equation for the lumped mass model pantograph is derived from multi-body dynamics equilibrium equations. It is presented as follows:
In the equation, , and represent the vertical displacements of the pantograph head, upper frame, and lower frame, respectively; , , denote the vertical velocities; and , , are the vertical accelerations.
2.2. Catenary Modeling
Due to the complexity of the catenary structure, models such as the Euler beam, time-varying stiffness equivalent, and finite element model are frequently employed. The catenary model uses a simplified time-varying stiffness equivalent model to make building the active controller easier. The equivalent stiffness of the catenary can be found as follows by fitting the stiffness changes in the catenary with the least squares method [23]:
where k0 is the mean stiffness coefficient, ηi is the fitting factor, τ1 = cos(2πvt/ψ), τ2 = cos(2πvt/ψ1), τ3 = cos(πvt/ψ), τ4 = cos(πvt/ψ1), ψ is the span, ψ1 represents the distance between adjacent droppers in the catenary system, and v denotes the train’s velocity.
2.3. Pantograph–Catenary Coupling System Modeling
Using the lumped mass pantograph model combined with the varying stiffness catenary model, the PCCF Fpc is determined by connecting the pantograph and catenary by a penalty function. The following is the calculating formula:
3. Improved Deep Reinforcement Learning for Controller Design
DRL refers to the process where an agent continuously interacts with its environment, leveraging deep neural networks’ powerful feature extraction and function approximation capabilities, and gradually learns the optimal strategy based on rewards. The DDPG algorithm in DRL is suitable for solving problems in the field of continuous action space control, exhibiting decision-making capabilities compared to other algorithms [24].
To enhance the performance of the DDPG strategy proposed in Section 2 within the context of the PCS coupling model, we propose the following advancements aimed at alleviating significant cumulative errors and enhancing training speed: (1) delays in updating Actor and Target–Actor networks to increase the agent’s learning efficiency; (2) using an improved empirical replay mechanism to lower data sample correlation, which accelerates the DDPG strategy’s convergence. Consequently, an IDDPG deep reinforcement learning strategy for pantograph active control is proposed in this study.
3.1. Basic Deep Reinforcement Learning
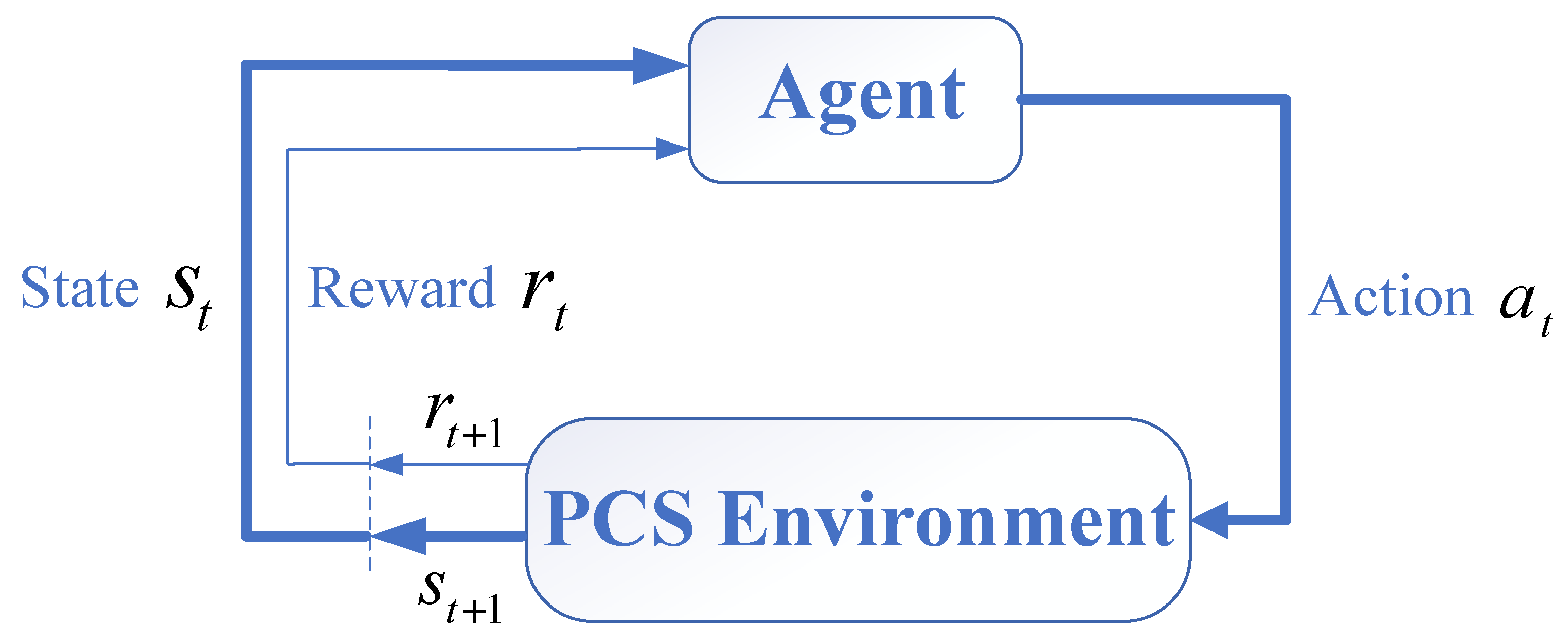
Figure 4 shows how the Markov decision-making process (MDP) might be utilized for the DRL. A tuple (S, A, P, R, γ) that represents the finite state set S, action set A, reward function R, state transition probability P, and discount factor , respectively, can be used to characterize this process. It can be explained as follows: the agent obtains the current state information st at each time step and acts at accordingly. The agent moves to the following state st+1, after completing action at and is rewarded with rt.

Figure 4.
Definition of Markov decision-making process.
The behavior strategy π employed by the agent is used to map the state to the probability distribution of actions, and the agent engages in continual interactions with the surrounding environment. The objective of reinforcement learning is to identify the optimal strategy π* of action that maximizes the state’s reward value, namely the cumulative reward , where γ is the discount factor. In reinforcement learning strategies, the action–value function is used to represent the expected reward after taking an action at under state st, following policy π. And the action–value function is expressed as follows:
3.2. DDPG Strategy
The DDPG strategy, developed by Lillicrap et al. [25], is a DRL strategy established on the Actor–Critic network structure. The Critic network is used by the DDPG strategy to evaluate the relative merits of every action and direct the gradient updates for the Actor network, which is used by the Actor network to explore the environment and make decisions.
The target network and the online network are the two neural networks that make the components of the Actor and Critic networks. Their structure is the same. The parameters of the online Q-network and the online policy network , denoted as and , are initialized randomly, and the corresponding target networks, denoted as and , are initialized using the parameters and . A strategy of action at is selected based on the existing policy, as shown by Equation (5).
where at denotes the action selected by the current policy, st stands for current observation, and Nt indicates the exploration noise.
The DDPG strategy’s decision-making process includes performing an action in the surrounding environment to obtain a reward value rt; the following observation st+1 and the sample information (st, at, rt, st+1) are saved in the experience replay buffer. The target Q-value for the Critic is obtained using Equation (6). The Critic updates by minimizing the TD (temporal difference) error, as illustrated in Equation (7).
In Equation (6), γ represents the discount factor.
Equation (8) shows how the Actor network adjusts its parameters when reacting to the policy gradient.
In the equation, is the gradient of the Actor network, while represents the gradient of the Critic network. makes participants adjust their network parameters toward the maximum reward continuously. The Actors’ online network updates in actual time depending on the Critics’ online network, with the target network serving as a reference. Consequently, the parameters of the online network remain current. Meanwhile, the learning parameters are updated using soft updating based on the online network parameters, delaying the target network parameters using the following equations:
where and are two parameters of the target network and is the update rate of the target network.
The Actor–Critic framework, which continuously engages with the environment to train its networks iteratively, serves as the foundation for the DDPG algorithm. More reliable parameter updates are made possible using the dual-network mechanism, which makes use of online parameter changes for both the target network and the network, which improves the algorithm’s learning efficiency.
The DDPG strategy is executed as follows:
- (1)
- The Actor network generates a set of actions and adds Ornstein–Uhlenbeck (OU) noise;
- (2)
- Based on the current action, the agent inputs the next state st+1 into the reward function and stores (st, at, rt, st+1) in the experience replay buffer;
- (3)
- n samples from the experience replay buffer are extracted, st and st+1 are input to the Actor network, and (st, at, rt, st+1) are input to the Critic network for iterative updating, respectively;
- (4)
- The Target–Actor network receives the states st and st+1, inputs the action at and random noise into the interaction between the agent and the environment, outputs the next action at+1 to the Target–Critic network, then receives the action Q-value and updates the network;
- (5)
- The Target–Critic network receives st+1, at+1, calculates the Q-value, and then combines Q with the reward r for iterative network updating.
3.3. Improved DDPG Solution
In the standard DDPG algorithm, the target network serves as a fixed goal to enhance the stability of the learning process. If the target networks for the Actor and Critic are not distinguished during training, it may lead to instability in the training process or even failure to converge. Through multi-step updates, the Critic network can gradually reduce the discrepancy with the target action value function; however, if the Critic network does not converge, i.e., when the error is significant, the Actor and Target–Actor networks may produce unstable policies, causing oscillations and non-convergence problems during training. To address this problem of significant accumulated errors, this paper proposes a delayed update for the Actor and Target–Actor, which means updating them after the Critic network has been updated N times. This ensures that the Actor and Target–Actor networks are updated when the error of the Critic network is small, thereby improving learning efficiency. The following shows the process of updating N times:
In Equation (11), N1 is the current total number of experiences for the replay buffer, and Nmax is the experience replay buffer’s maximum capacity. At the beginning of training, the capacity of the experience replay buffer is not yet filled, and the minimum is taken to be one. In the early stages of training, since most experiences are of low value, they negatively impact the learning effectiveness of the agent; therefore, it is necessary to accumulate experiences rapidly. Once the replay buffer’s capacity reaches its preset maximum, the agent can fully utilize these experiences for learning.
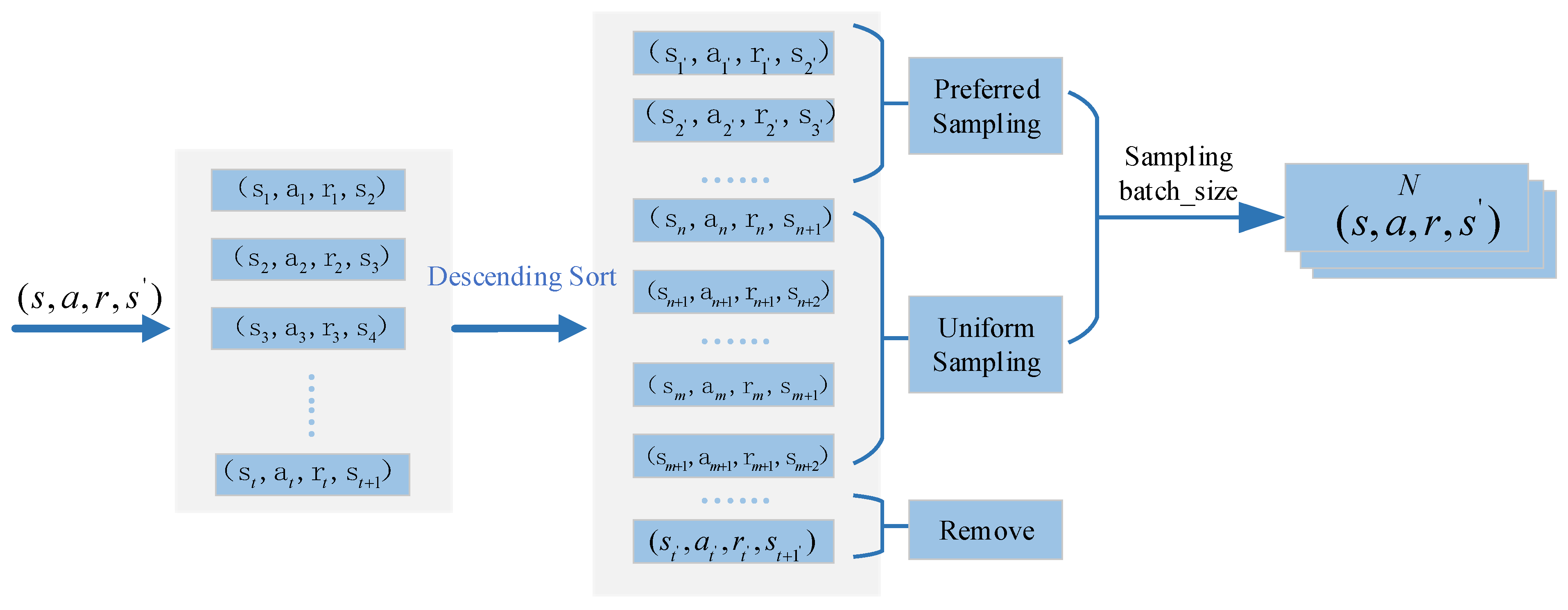
To address the problem of slow training speed, this paper adopts the experience replay mechanism to reduce the correlation between data samples during training and testing. The experience replay buffer stores sample data (st, at, rt, st+1) through the interaction between the pantograph and the PCS environment. Reusing historical samples becomes possible using the experience replay buffer, reducing resource waste. However, the network parameters are learned consistently because the original DDPG strategy considers all data kept in the experience replay buffer identically, without giving any of them priority.
An experience replay buffer D2 is inserted beneath the original experience replay buffer D1 to attempt to fix the problem mentioned above. The reward values of the stored initial samples are sorted in descending order in experience replay buffer D2, as seen in Figure 5. After removing lower-reward data from the bottom of the experience replay buffer, a specific percentage of the remaining data are sampled using both priority sampling and uniform sampling.
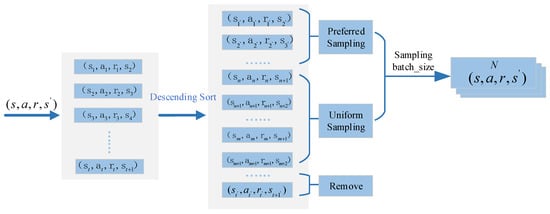
Figure 5.
Improved experience replay buffer D2.
Once weight w is established, the desired and uniform sampling set batch_size*w and batch_size*(1 − w) data are obtained. In the end, batch_size data are gathered for a new round of network training. The enhanced sampling strategy reduces the usage of poorer-quality data by giving them lower weights and prioritizes higher-quality data with higher rewards. It does this by combining the benefits of uniform and priority sampling. This method facilitates quicker strategy convergence and increases the network’s training speed.
Algorithm 1 provides the pseudo-code for the IDDPG interaction process. Two experience replay buffers and four network parameters must be initialized at the beginning of the process. At each step, an action is executed and based on the obtained reward and the next state, and sample data are saved in the experience replay buffer D1 based on the reward received and the subsequent condition. The network is then updated using the mini-batch sample data that were taken from the experience replay buffer D2 in accordance with the revised sampling technique. The Actor network receives updates after the Critic network has been updated N times, with the Actor network parameters being delayed during the period of training.
| Algorithm 1: IDDPG |
| 1: Initialize empty experience replay buffer D1, D2, and the environment E. |
| 2: Initialize the current total number of experiences for the replay buffer N1. |
| 3: Randomly initialize the Critic network and Actor network with weights and . |
| 4: Initialize the target network Q′ and with weights . |
| 5: For episode = 1, M perform the following: |
| 6: Initialize the random process N for exploration. |
| 7: Initialize observation state s1. |
| 8: For step = 1, T perform the following: |
| 9: Select action based on the Actor network. |
| 10: Execute action at, observe reward rt and next state st+1. |
| 11: Store (st, at, rt, st+1) in the experience replay buffer D1. |
| 12: D2 is obtained by sorting D1 in the descending order of reward values and then removing the data with small reward values at the end. |
| 13: Set the weight w according to priority sampling and uniform sampling in the experience divided by proportional batch_size*w and batch_size*(1 − w) in D2, respectively. |
| 14: Update Critic network parameters and the loss. |
| 15: According to the formula , determine whether the Actor network needs to be updated. |
| 16: If it is a multiple of N, conduct the following: |
| 17: Update the Actor policy using the sampling policy gradient: |
| 18: Update the target networks: . |
| 19: End. |
| 20: End. |
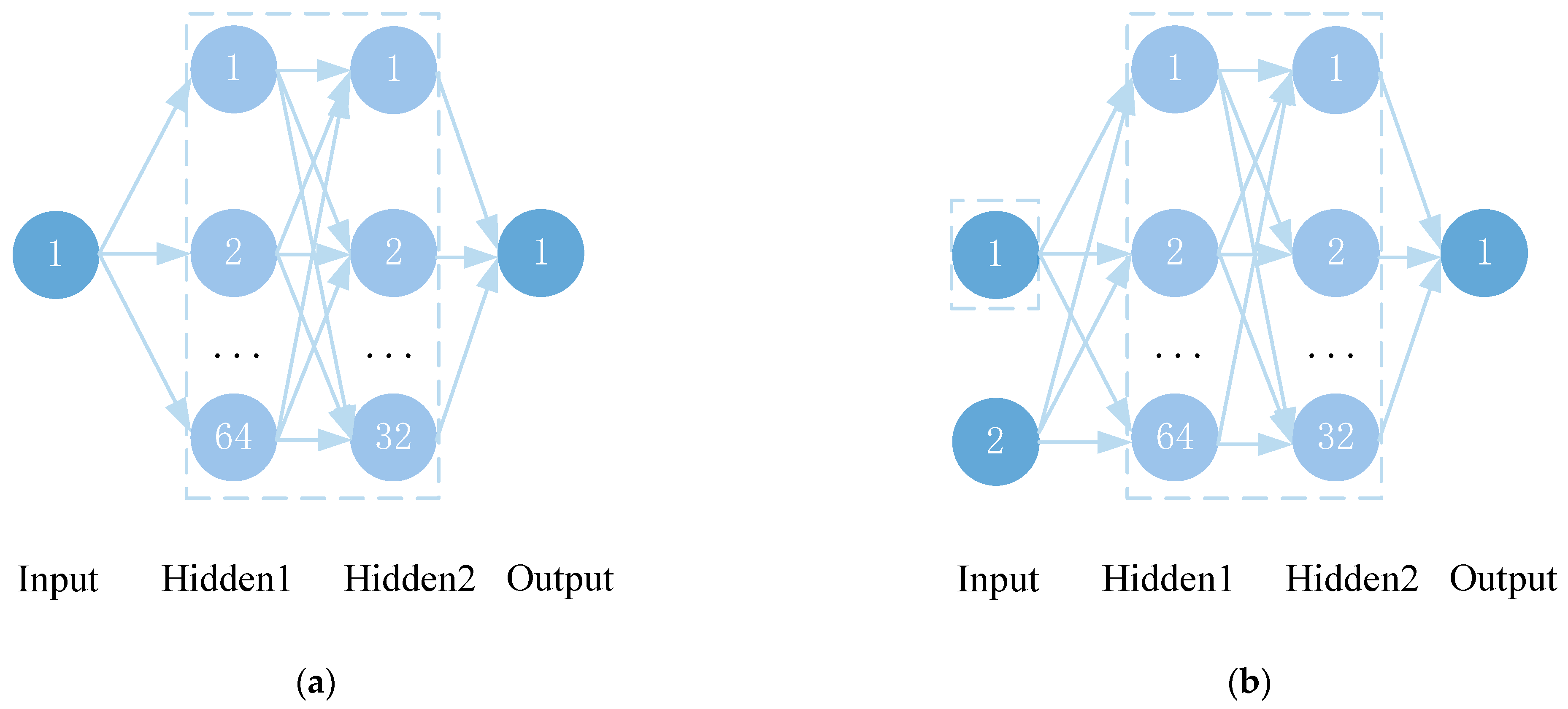
Figure 6a depicts the Actor network structure, which consists of 1 input layer, 2 hidden layers, and 1 output layer. The two hidden layers have 64 and 32 neurons, respectively, while the output layer has one dimension. The input layer has a dimension of 100. The output layer’s activation function uses Tanh, while the middle activation function uses ReLU to better extract relevant characteristics and avoid gradient saturation and disappearance problems. The Critic network structure, which is made up of an input layer, 2 hidden layers, and an output layer, is illustrated in Figure 6b. The state data of the environment and the action value generated from the Actor network make up the two components of the input layer. The two hidden layers have neurons of 64 and 32, respectively, and the output layer has a dimension of one, representing the state–action value.

Figure 6.
Network structure. (a) Actor network structure. (b) Critic network structure.
3.4. Deep Reinforcement Learning Module Design for Controller
The IDDPG algorithm flowchart is shown in Figure 7. In Figure 7, the PCS coupling model serves as the environment, and the collection of pantograph head displacement data set collected during the operation of the PCS coupling model is considered the state. At each time step, the agent implements control action commands at on the PCS environment based on the environmental state st, receiving a reward rt and the next state st+1.

Figure 7.
Flowchart of IDDPG strategy.
The Markov decision process primarily consists of five main components: (1) a pantograph agent, (2) a PCS coupling environment, (3) state space, (4) action space, and (5) reward function. The effective operation of improved DRL is contingent upon the design of these components. The state space, action space, and reward function of the corresponding PCS coupling model are carefully built after the pantograph agent and PCS environment have been selected.
- (1)
- State space design: In an actual environment, measuring the velocity and displacement of a pantograph is challenging. Nonetheless, non-contact measurement techniques make it simple to measure pantograph head displacement.
Furthermore, the amount of historical information can be increased by overlaying the past state with the current state. Consequently, the state vector in this research was constructed using past displacements and the pantograph head displacement. The definition of the state space is as follows:
where n, the distance taking account of the previous states, is taken as n = 100, and st, the agent’s state at time step t, and yt, the pantograph head’s vertical displacement at time step t, are represented.
- (2)
- Action space design: Agents adjust the lift force in order to control the PCCF. The primary concept for pantograph control is to keep the lift force within a safe and appropriate range while guarding against unintentional forces that could harm or wear down mechanical parts. A variation range of −50 N to 50 N was adopted for pantograph control. The action space can be represented as follows.
- (3)
- Design of the reward function: The controller’s main objective is to reduce the PCCF’s fluctuations and make the PCCF smoother. The objective is to achieve optimal control performance and minimize the control force, taking into account the actuator’s energy problem [26]. Negative reward signals are given for excessively high or low PCCF, and positive reward signals are obtained if the PCCF is within the normal range. Training ends when the PCCF stabilizes within a specific range, concluding the current episode. The reward function is set as follows:
The parameters of the reinforcement learning network based on the IDDPG pantograph active control are shown in Table 2.
Table 2.
Simulation parameters.
4. Test Verification of Pantograph IDDPG Network Active Control
The pantograph tested in the experiment, an SSS400+-type pantograph that is typically utilized in high-speed trains, has its parameters listed in Table 1 and was chosen to test the effectiveness of the proposed active control method. The China Beijing–Tianjin Railway line and the China Beijing–Shanghai Railway line provide the real structural standards of the catenary, as Table 3 shows.
Table 3.
The catenary parameters of the high-speed railway line.
4.1. Training Results
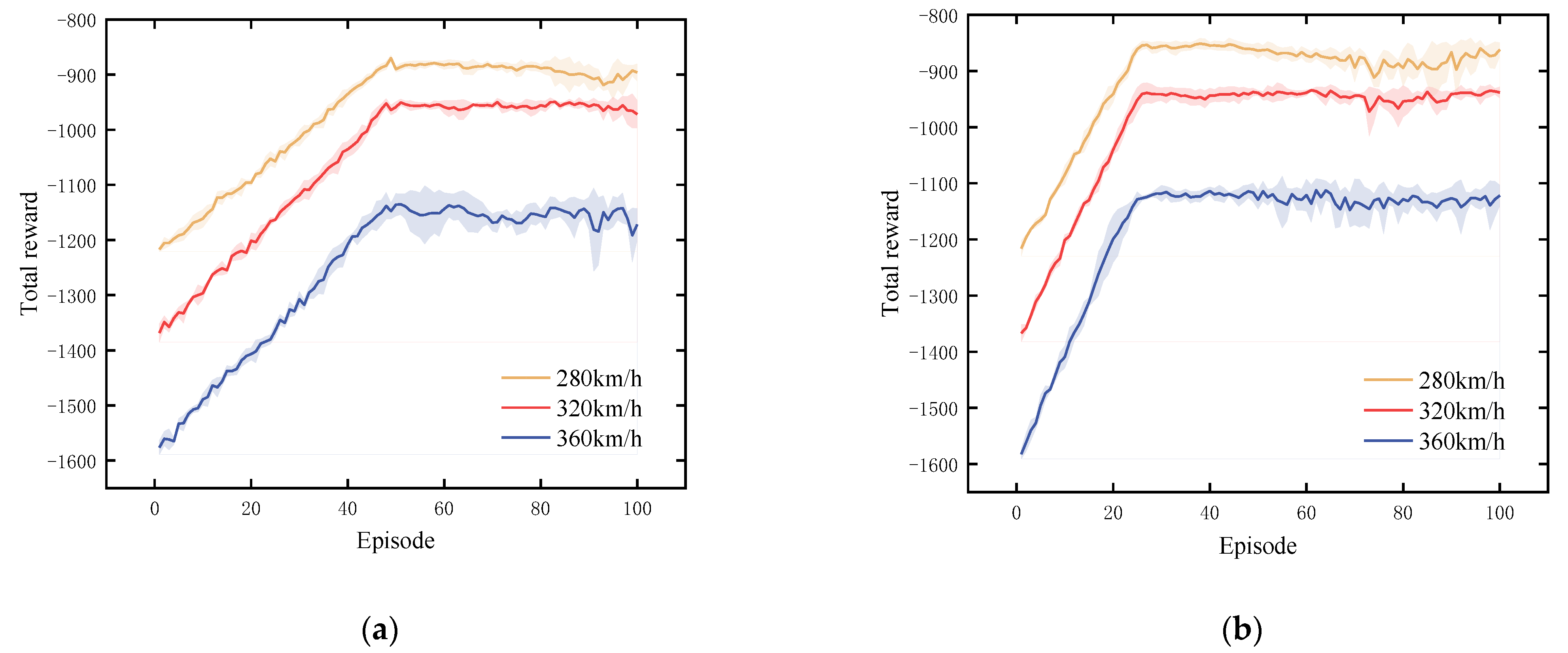
The simulation in this paper is based on the Python programming language, which is executed and validated in the framework of a custom gym environment. In DRL, the reward value for each time is an essential indicator of the training effect. Figure 8 shows the reward function comparison between the DDPG and IDDPG algorithm training for 100 episodes at different operating speeds using the China Beijing–Tianjin railway line’s parameter lines. Five runs of the experiment proceeded, with the solid lines representing the average reward and the shaded areas indicating reward fluctuations. As shown in Figure 8, the IDDPG algorithm significantly reduces the training time and can converge faster, with more stable network performance in the later stage.

Figure 8.
DDPG vs. IDDPG algorithm reward function curves: (a) DDPG; (b) IDDPG.
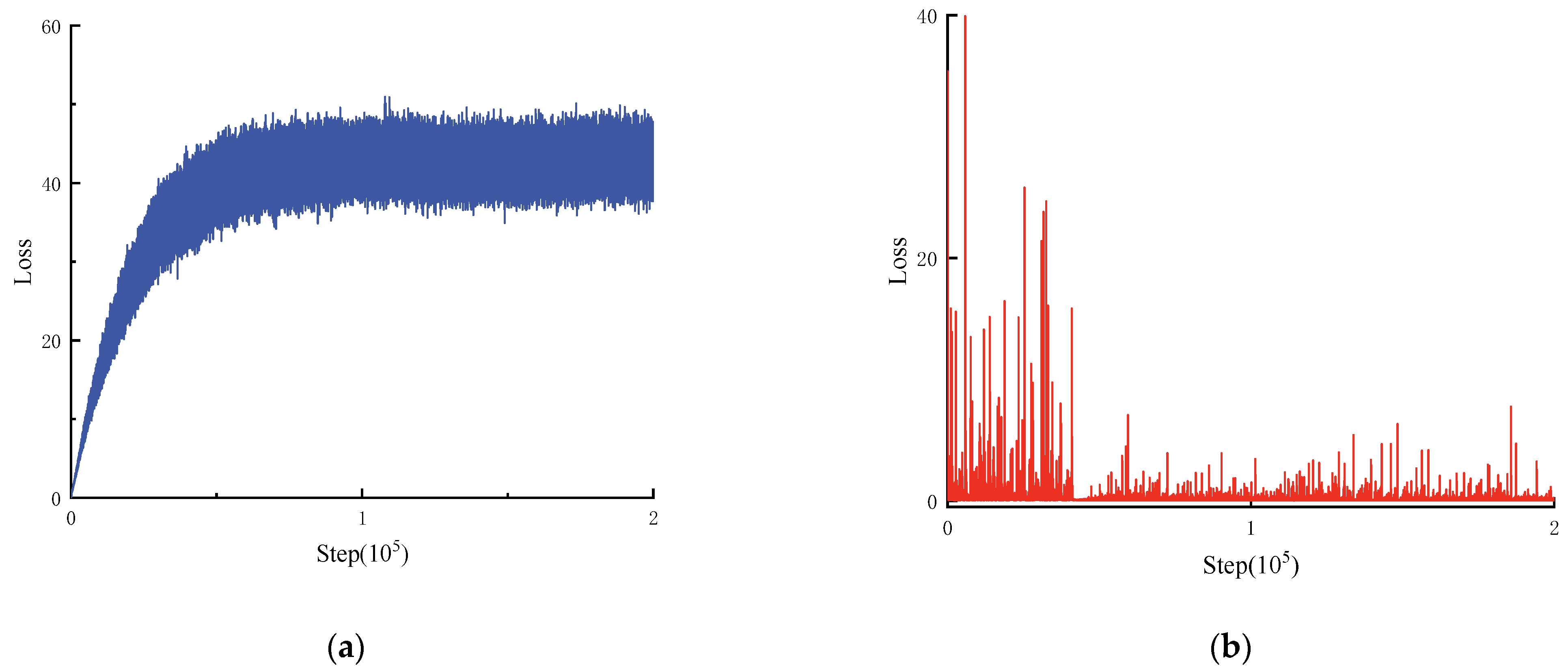
The loss function curve of the IDDPG algorithm network is shown in Figure 9 to further prove the strategy’s stable convergence. Figure 9a shows the increasing and eventually stabilizing curve for the Actor network loss function. The Actor network initially searches for a balance between exploring the action and exploiting the current knowledge, which leads to initial performance reduction and makes the loss function value increase. As training proceeds, the Actor network gradually learns and adjusts its strategy to reduce fluctuations in the contact force, resulting in a stabilized loss function. The Actor network’s stable loss function indicates that it already generated control strategies with more effective results. The Critic network loss function in Figure 9b gradually decreases and stabilizes with the training process, and the Critic network evaluates the rewards received by the Actor network after taking actions.

Figure 9.
IDDPG algorithm network loss function: (a) Actor network; (b) Critic network.
At the beginning of training, the high dynamics of the pantograph control system make it difficult for the Critic network to accurately estimate the long-term impacts on actions, which increases the loss function. Through continual learning updates, the Critic network learns to understand the Actor network’s strategy and the behavior of the pantograph system more accurately as training progresses. As a result, the loss function’s fluctuation eventually stabilizes. The stable loss function of the Critic network indicates that the network was able to effectively estimate the value of the action and provide reliable feedback to the Actor network. In summary, the Actor and Critic networks’ loss functions eventually stabilize while training goes on, indicating that the strategy has been converged stably and optimized. After completing the above training, the Actor network parameters that maximize the reward function in IDDPG are saved and applied to the PCS environment simulation. The convergence comparison between DDPG and IDDPG strategies is shown specifically in Appendix A, Table A1.
4.2. Controller Validity Verification
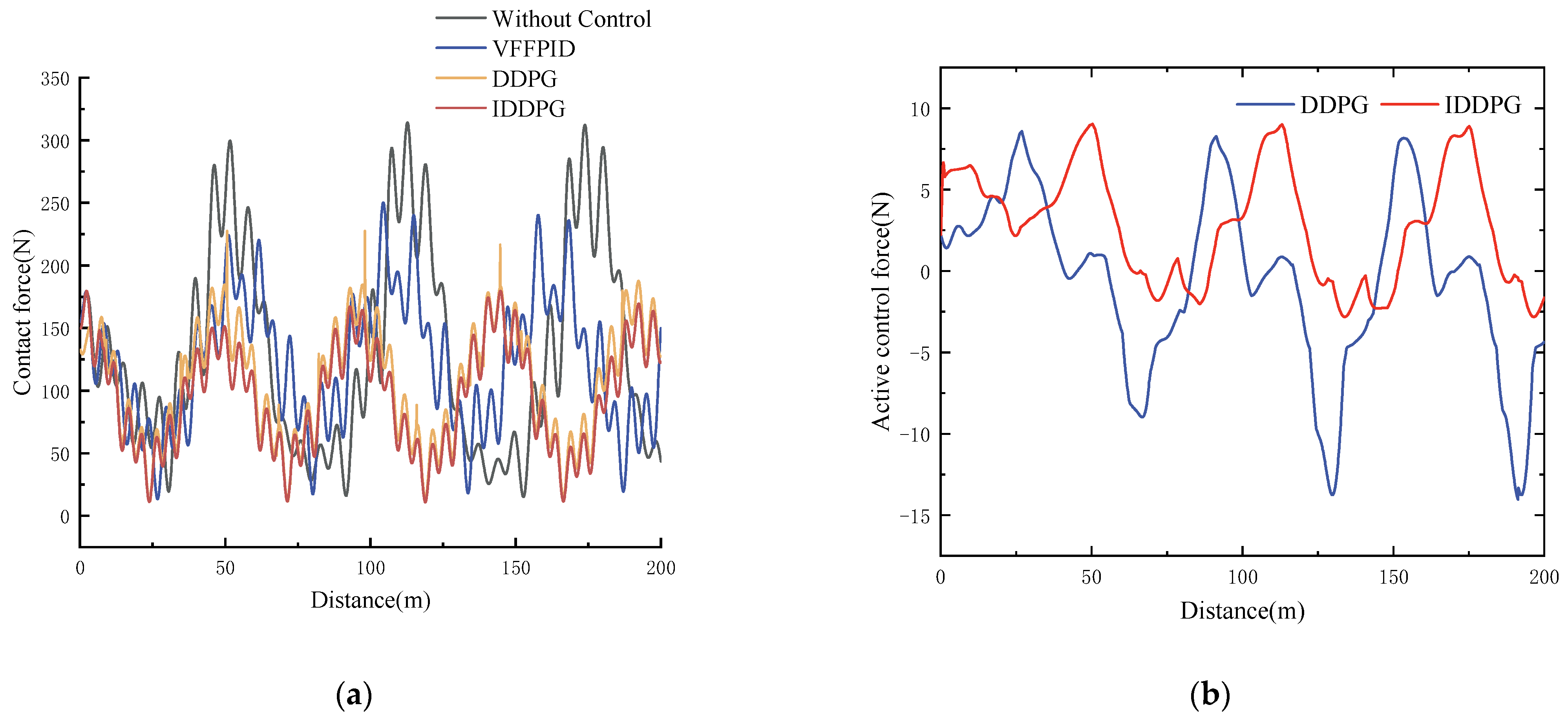
The VFFPID control method is the main benchmark for the performance comparison in this article. The PCCF curves of different controllers operating at 360 km/h are shown in Figure 10a. According to the figure, by raising the minimum value and lowering the maximum value of the PCCF, the strategy may effectively reduce PCCF fluctuations.

Figure 10.
PCCF and active control force comparison at 360 km/h: (a) PCCF; (b) active control force.
Figure 10b shows the control force waveform of the controller at 360 km/h in order to further illustrate the efficiency of the DRL strategy. The IDDPG control strategy requires less control force than the DDPG control strategy, resulting in a more stable control force. The drastic vibration of the control force can cause wear on the PCS components, which may lead to serious power supply interruptions to the train. The proposed method achieves a more optimized control effect with less control force, ensuring the train’s safe operation.
4.3. Controller Robustness Validation at Different Train Speeds
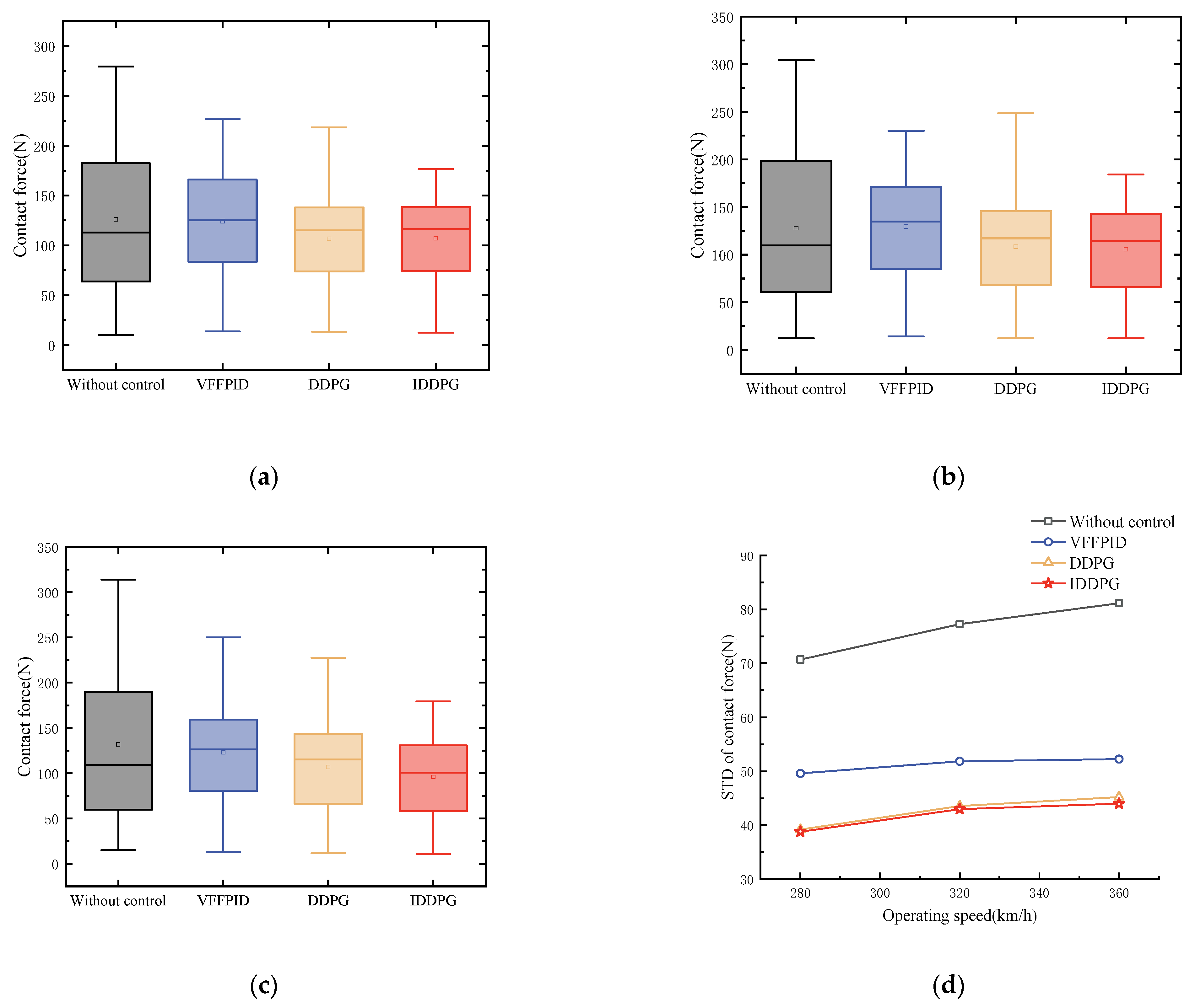
Verification of the strategy’s control performance is conducted at various train operation speeds. Figure 11 shows the distribution of PCCF and its standard deviation under different control methods at different operating speeds. Figure 11a, Figure 11b, and Figure 11c represent the comparison of PCCF at speeds of 280 km/h, 320 km/h, and 360 km/h, respectively. It is clear that the PCCF is reduced with active control at various speeds; the average PCCF value remains essentially constant, effectively reducing the maximum value of PCCF and increasing the minimum value of PCCF.
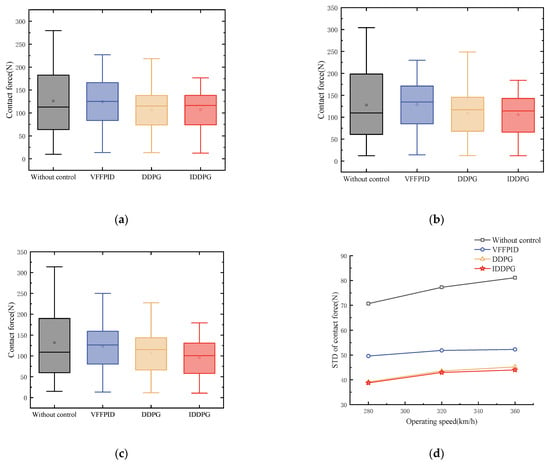
Figure 11.
PCCF and STD comparison for various control strategies at various speeds: (a) comparison of PCCF at 280 km/h; (b) comparison of PCCF at 320 km/h; (c) comparison of PCCF at 360 km/h; and (d) comparison of STD at different speeds.
By measuring the level of dispersion, the standard deviation provides an explanation for the magnitude of PCCF fluctuations. The standard deviation of PCCF under different control strategies and operating speeds is shown in Figure 11d. At 280 km/h, 320 km/h, and 360 km/h, the standard deviation of PCCF is reduced by 53.06%, 55.46%, and 53.11%, respectively. The experimental results show that IDPPG control can effectively suppress the fluctuation of PCCF compared with other control methods. More detailed contact force data for different control methods are shown in Appendix A, Table A2.
4.4. Controller Robustness Validation under Various Railway Lines
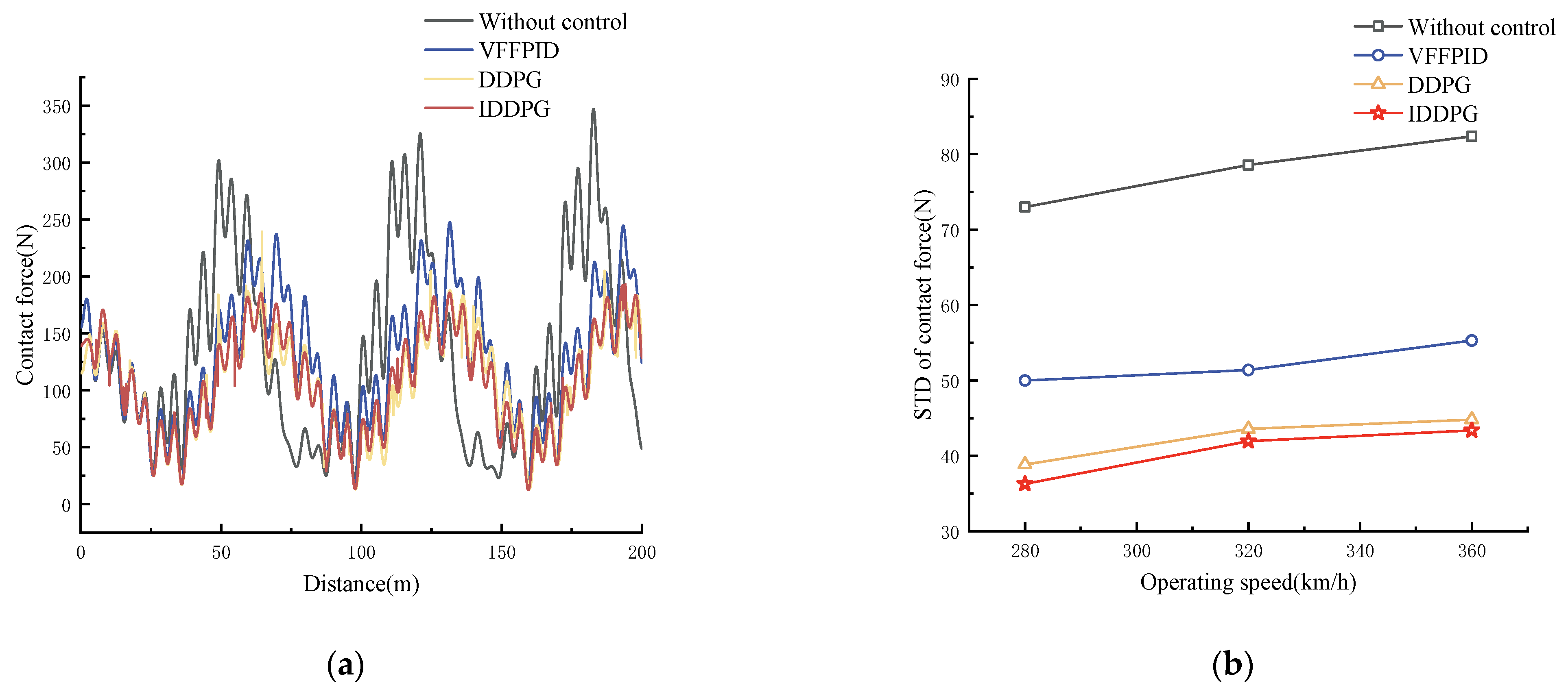
The performance of the controller based on DRL is evaluated using the Beijing–Shanghai Railway line’s standards in order to further prove its efficiency. Figure 12 shows the PCCF values at a speed of 360 km/h (a).

Figure 12.
Comparison of PCCF and STD under China Beijing–Shanghai Railway line: (a) comparison of PCCF at 360 km/h; (b) comparison of STD at different speeds.
As seen in Figure 12b, the PCCF standard deviation is reduced by 51.04%, 54.50%, and 52.99% at 280 km/h, 320 km/h, and 360 km/h, respectively, under different railway line PCSs, and the IDDPG control strategy is more efficient in reducing the fluctuation of the PCCF, which indicates that the proposed control method can be adapted to different railway line conditions and shows the high robustness of the algorithm.
4.5. Controller Robustness Verification under Different Pantograph Parameter Perturbations
Under optimal conditions, the previous simulation is validated without taking parameter perturbations into account. During train operation, the pantograph’s lifting height changes due to aerodynamic forces and external environmental factors, causing parameter variations. Parameter perturbations lead to model mismatches that have significant effects on the performance of the PCS and the controller. As a result, by adjusting the pantograph’s parameters, the effectiveness of the proposed control strategy is evaluated. When considering varying pantograph operating heights, the four following aspects are evaluated:
- (1)
- Modifying the mass of each component;
- (2)
- Modifying the damping of each component;
- (3)
- Modifying the stiffness of each component;
- (4)
- Modifying all parameters concurrently.
Table 1 shows the SSS400+ pantograph perturbation parameters. The controller’s detailed performance is shown in Table 4. According to the related results, PCCF’s standard deviation decreased by 46.11%, 48.19%, 48.81%, and 51.16%, in that order. The performance of the controller decreased slightly as the number of parameter interference terms increased. Additionally, the pantograph is typically performed within the standard range. The results show that the control strategy can handle the perturbations of pantograph parameters to a certain extent.
Table 4.
Controller performance under perturbation of pantograph parameters.
5. Conclusions
In this paper, the IDDPG algorithm in DRL was combined to control the pantograph, effectively reducing the fluctuation of the PCCF of PCS. Firstly, the lumped mass model of the pantograph and the time-varying stiffness equivalent model of the catenary were established. By combining the DRL mechanism, the PCS agent was capable of communicating with the environment. Then, the IDDPG strategy was applied to the active pantograph control, and the robustness and effectiveness of the control strategy were verified under various situations. The results of the experiments show that DRL can effectively reduce the PCCF fluctuation problem arising from high-speed train operations. The three main advantages of the IDDPG control strategy that this article proposes are as follows:
- (1)
- Reinforcement learning selects the optimal action in the current state through its powerful trial-and-error ability, and there is no negative impact, such as reduced control performance, due to the inability of traditional controller parameters to optimize adaptively.
- (2)
- Through multiple experiments, DRL has the ability to estimate the relationship between local conditions and actions and maximize the cumulative reward. By anticipating and promptly modifying the strategy in response to the local state’s consequences, the DRL-based control strategy may effectively adjust to modifications in the external environment.
- (3)
- The IDDPG strategy efficiently decreases the training process error, improves learning efficiency, dramatically increases the training speed, and increases algorithm exploration to enable faster convergence in order to address problems with a large cumulative error and the slow training speed of the DDPG strategy.
In summary, the IDDPG algorithm proposed in this paper has a better performance of optimization. The standard deviation of the PCCF decreased by 53.06%, 55.46%, and 53.11% under different speeds on the same line, by 51.04%, 54.50%, and 52.99% under different speeds on different railway lines, and by 46.11%, 48.19%, 48.81%, and 51.16% under parameter perturbations. The results show that the IDDPG can effectively reduce the fluctuation of the contact force, improve the quality of current collection for trains, reduce wear on PCS components, and effectively extend the service life of railway lines. Future research will further improve and extend the proposed algorithm to enhance the controller’s performance. Meanwhile, more attention needs to be paid to hardware experiments.
Author Contributions
Conceptualization, Y.W. (Yuting Wang) and Y.W. (Ying Wang); methodology, Y.W. (Yuting Wang); formal analysis, Y.W. (Yuting Wang), Y.W. (Ying Wang), and Y.W. (Yixuan Wang); investigation, Y.W. (Yuting Wang) and X.C.; data curation, Y.W. (Yuting Wang), Y.W. (Ying Wang), X.C., and Z.C.; writing—original draft preparation, Y.W. (Yuting Wang); writing—review and editing, Y.W. (Yuting Wang) and Y.W. (Ying Wang); supervision, Y.W. (Yuting Wang); project administration, Y.W. (Ying Wang); funding acquisition, Y.W. (Ying Wang). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (52067013, 52367009); and the Natural Science Key Foundation of Science and Technology Department of Gansu Province (21JR7RA280).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
Author Zhanning Chang was employed by the company China Railway Lanzhou Bureau Group Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Appendix A
Table A1.
The number of episodes to convergence for DDPG and IDDPG strategies.
Table A1.
The number of episodes to convergence for DDPG and IDDPG strategies.
| DDPG | IDDPG | |
|---|---|---|
| 280 km/h | 50 | 27 |
| 320 km/h | 51 | 26 |
| 360 km/h | 49 | 25 |
Table A2.
Comparison of performance indicators of different controllers.
Table A2.
Comparison of performance indicators of different controllers.
| Control Method | Without Control | LQR | VFFPID | DDPG | IDDPG | |
|---|---|---|---|---|---|---|
| Speed | Contact Force | |||||
| 280 km/h | Max | 279.5453 | 237.8598 | 226.8654 | 218.5034 | 176.6796 |
| Min | 9.9796 | 9.1249 | 11.5429 | 12.3172 | 13.4633 | |
| Mean | 126.0376 | 136.4832 | 124.3352 | 107.0818 | 95.7824 | |
| STD | 70.6821 | 52.2767 | 49.6091 | 39.1876 | 38.7872 | |
| 320 km/h | Max | 304.2178 | 234.7181 | 230.0273 | 184.2673 | 178.6796 |
| Min | 12.3821 | 11.6223 | 10.2254 | 11.3626 | 13.2936 | |
| Mean | 127.8825 | 132.7975 | 129.6325 | 106.8854 | 105.7506 | |
| STD | 77.2735 | 52.2991 | 51.8612 | 43.5479 | 42.9887 | |
| 360 km/h | Max | 314.1288 | 232.7940 | 250.2295 | 227.4663 | 179.6263 |
| Min | 13.0708 | 12.4390 | 13.4014 | 10.8986 | 12.7248 | |
| Mean | 132.1117 | 134.2196 | 123.2099 | 106.7462 | 106.8854 | |
| STD | 81.1289 | 51.9724 | 52.2504 | 45.2220 | 43.9998 | |
References
- Chen, J.; Hu, H.; Wang, M.; Ge, Y.; Wang, K.; Huang, Y.; Yang, K.; He, Z.; Xu, Z.; Li, Y.R. Power Flow Control-Based Regenerative Braking Energy Utilization in AC Electrified Railways: Review and Future Trends. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6345–6365. [Google Scholar] [CrossRef]
- Chen, J.; Zhao, Y.; Wang, M.; Wang, K.; Huang, Y.; Xu, Z. Power Sharing and Storage-Based Regenerative Braking Energy Utilization for Sectioning Post in Electrified Railways. IEEE Trans. Transp. Electrif. 2024, 10, 2677–2688. [Google Scholar] [CrossRef]
- Chen, X.; Xi, Z.; Wang, Y.; Wang, X. Improved study on the fluctuation velocity of high-speed railway catenary considering the influence of accessory parts. IEEE Access 2020, 8, 138710–138718. [Google Scholar] [CrossRef]
- Jiang, X.; Gu, X.; Deng, H.; Zhang, Q.; Mo, J. Research on Damage Mechanism and Optimization of Integral Dropper String Based on Fretting Theory. Tiedao Xuebao/J. China Railw. Soc. 2019, 41, 40–45. [Google Scholar]
- Shi, G.; Chen, Z.; Guo, F.; Hui, L.; Dang, W. Research on Characteristic of the Contact Resistance of Pantograph-Catenary under Load Fluctuation Condition. Diangong Jishu Xuebao/Trans. China Electrotech. Soc. 2019, 34, 2287–2295. [Google Scholar]
- Wang, Y.; Liu, Z.-G.; Huang, K.; Gao, S.-B. Pantograph-catenary surface heat flow analysis and calculations based on mechanical and electrical characteristics. Tiedao Xuebao/J. China Railw. Soc. 2014, 36, 36–43. [Google Scholar]
- Song, Y.; Li, L. Robust Adaptive Contact Force Control of Pantograph-Catenary System: An Accelerated Output Feedback Approach. IEEE Trans. Ind. Electron. 2021, 68, 7391–7399. [Google Scholar] [CrossRef]
- Zdziebko, P.; Martowicz, A.; Uhl, T. An investigation on the active control strategy for a high-speed pantograph using co-simulations. Proc. Inst. Mech. Engineers. Part I J. Syst. Control Eng. 2019, 233, 370–383. [Google Scholar] [CrossRef]
- Wang, Y.; Jiao, Y.; Chen, X. Active Control of Pantograph with Fluctuating Wind Excitation of Contact Wire Considered. Mech. Sci. Technol. Aerosp. Eng. 2021, 40, 1149–1157. [Google Scholar]
- Zheng, Y.; Ran, B.; Qu, X.; Zhang, J.; Lin, Y. Cooperative Lane Changing Strategies to Improve Traffic Operation and Safety Nearby Freeway Off-Ramps in a Connected and Automated Vehicles Environment. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4605–4614. [Google Scholar] [CrossRef]
- Xie, S.; Zhang, J.; Song, B.; Liu, Z.; Gao, S. Optimal Control of Pantograph for High-Speed Railway Considering Actuator Time Delay. Diangong Jishu Xuebao/Trans. China Electrotech. Soc. 2022, 37, 505–514. [Google Scholar]
- Song, Y.; Liu, Z.; Ouyang, H.; Wang, H.; Lu, X. Sliding mode control with PD sliding surface for high-speed railway pantograph-catenary contact force under strong stochastic wind field. Shock Vib. 2017, 2017 Pt 1, 4895321. [Google Scholar] [CrossRef]
- Schirrer, A.; Aschauer, G.; Talic, E.; Kozek, M.; Jakubek, S. Catenary emulation for hardware-in-the-loop pantograph testing with a model predictive energy-conserving control algorithm. Mechatronics 2017, 41, 17–28. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, H.; Song, B.; Xie, S.; Liu, Z. A New Active Control Strategy for Pantograph in High-Speed Electrified Railways Based on Multi-Objective Robust Control. IEEE Access 2019, 7, 173719–173730. [Google Scholar] [CrossRef]
- Chater, E.; Ghani, D.; Giri, F.; Haloua, M. Output feedback control of pantograph-catenary system with adaptive estimation of catenary parameters. J. Med. Biol. Eng. 2015, 35, 252–261. [Google Scholar] [CrossRef]
- Duguleana, M.; Mogan, G. Neural networks based reinforcement learning for mobile robots obstacle avoidance. Expert Syst. Appl. 2016, 62, 104–115. [Google Scholar] [CrossRef]
- Cully, A.; Clune, J.; Tarapore, D.; Mouret, J. Robots that can adapt like animals. Nature 2015, 521, 503. [Google Scholar] [CrossRef]
- Wang, Y.; Tan, H.; Wu, Y.; Peng, J. Hybrid Electric Vehicle Energy Management with Computer Vision and Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2021, 17, 3857–3868. [Google Scholar] [CrossRef]
- Zhao, R.; Chen, Z.; Fan, Y.; Li, Y.; Gao, F. Towards Robust Decision-Making for Autonomous Highway Driving Based on Safe Reinforcement Learning. Sensors 2024, 24, 4140. [Google Scholar] [CrossRef]
- Liu, C.H.; Ma, X.; Gao, X.; Tang, J. Distributed Energy-Efficient Multi-UAV Navigation for Long-Term Communication Coverage by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2020, 19, 1274–1285. [Google Scholar] [CrossRef]
- Chen, X.; Shen, Y.; Wang, Y.; Zhang, X.; Cao, L.; Mu, X. Irregularity Detection of Contact Wire Based on Spectral Kurtosis and TimeℋFrequency Analysis. Zhendong Ceshi Yu Zhenduan/J. Vib. Meas. Diagn. 2021, 41, 695–700. [Google Scholar]
- WUY Research on Dynamic Performance and Active Control Strategy of High-Speed Pantograph-Catenary System; Beijing Jiaotong University: Beijing, China, 2011.
- Chen, Z.; Tang, B.; Shi, G. Design of the pantograph optimal tracking controller based on linear quadratic. J. Electron. Meas. Instrum. 2015, 29, 1647–1654. [Google Scholar]
- Mu, R.; Zeng, X. A review of deep learning research. KSII Trans. Internet Inf. Syst. 2019, 13, 1738–1764. [Google Scholar]
- Fan, Q.-Y.; Cai, M.; Xu, B. An Improved Prioritized DDPG Based on Fractional-Order Learning Scheme. IEEE Trans. Neural Netw. Learn. Syst. 2024, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Han, Z.; Wang, H. Active Pantograph Control of Deep Reinforcement Learning Based on Double Delay Depth Deterministic Strategy Gradient. Diangong Jishu Xuebao/Trans. China Electrotech. Soc. 2024, 39, 4547–4556. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).