
Prompt-Based End-to-End Cross-Domain Dialogue State Tracking

Abstract
:1. Introduction
- We propose a Prompt-based end-to-end Cross-domain joint dialogue state tracking (PCDST) model. To the best of our knowledge, it is the first study on an end-to-end multi-slot joint modeling method for cross-domain dialogue state tracking.
- We propose a dynamic shuffle prompt template construction method, which enriches the diversity of prompt templates, and a dynamic sampling template construction method, which smooths the distribution of slot numbers in the source domain to alleviate the data bias to the slot order and slot number, respectively.
- The experimental results on MultiWOZ 2.0 and MultiWOZ 2.1 based on T5 show that our model consistently outperforms the SOTA baseline model in all target domains, and it improves the efficiency of training and inference by at least 5 times.
- Furthermore, we integrated our approach with instruction fine-tuning methods based on large language models, showing that our method enhances performance in target domains across various models of different performances and sizes.
2. Related Work
2.1. Cross-Domain Dialogue State Tracking
2.2. Joint DST of Multiple Slots
2.3. Prompt-Based Learning in Dialogue
3. Method
3.1. Task Formulation
3.2. PCDST
3.3. Prompt Formation for Training
3.3.1. Prompt Template Construction
3.3.2. Shuffle Prompt Template Construction
3.3.3. Sample Prompt Template Construction
3.3.4. Slot Prompt and Slot Value Prompt Formation
3.4. Prompt Formation for Inference
4. Experiments
4.1. Datasets and Evaluation
4.2. Baselines
4.3. Implementation Details
5. Results and Discussions
5.1. Main Results
5.2. Training and Inference Time
5.3. Results on Large Language Models Instruction Tuning
5.4. Ablation Studies
5.4.1. Effect of Shuffle Construction
5.4.2. Effect of Sampling Construction
5.5. Case Study
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DST | Dialogue state |
| TOD | Task-oriented dialogue |
| NLU | Nature language understanding |
| NLG | Nature language generation |
Appendix A. Instruction Tuning Example

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Slot Names | [Attraction-Area, Attraction-Name, Attraction-Type] | |
|---|---|---|
| Dialogue history | User: Looking for places to go in town that are theatres. System: We have five theatres to choose from, is there a preferred area ? User: No, I have no preference, which one do you recommend ? | |
| Trainging instruction | Input | Please follow the format of “<PAN> slot name <PAV> slot value” to extract the slot value existing in the dialogue. The slot name to be extracted is “<PAN> attraction-area <PAN> attraction-name <PAN> attraction-type”. The dialog history is “‘ <U> Looking for places to go in town that are theatres. <A> We have five theatres to choose from, is there a preferred area ? <U> No, I have no preference, which one do you recommend ? ”’ Among them, “<U>” means User, “<A>” means Agent. If a slot does not exist in the dialog, the slot value is replaced by None. Please follow the format of “<PAN> slot name “<PAV> slot value". The extraction result is as follows: |
| Output | <PAN> attraction-area <PAV> dontcare <PAN> attraction-name <PAV> none <PAN> attraction-type <PAV> theatre | |
| Instruction Text_B | Input | Please follow the format of “<PAN> slot name <PAV> slot value” to extract the slot value existing in the dialogue. The slot name to be extracted is “<PAN> attraction-name <PAN> attraction-type <PAN> attraction-area”. The dialog history is “‘ <U> Looking for places to go in town that are theatres. <A> We have five theatres to choose from, is there a preferred area? <U> No, I have no preference, which one do you recommend? ”’ Among them, “<U>” means User, “<A>” means Agent. If a slot does not exist in the dialog, the slot value is replaced by None. Please follow the format of “<PAN> slot name “<PAV> slot value”. The extraction result is as follows: |
| Output | <PAN> attraction-name <PAV> none <PAN> attraction-type <PAV> theatre <PAN> attraction-area <PAV> dontcare | |
Appendix B. Implementation Details
| Llama1-7b | Llama2-7b | Llama2-13b | Llama3-8b | Gemma-2b | Gemma2-9b | |
|---|---|---|---|---|---|---|
| learning rate | 5e-6 | 5e-6 | 5e-6 | 5e-6 | 5e-6 | 5e-6 |
| batch size | 20 × 8 × 1 | 20 × 8 × 1 | 16 × 8 × 1 | 20 × 8 × 1 | 16 × 8 × 2 | 8 × 8 × 4 |
| epochs | 3 | 3 | 3 | 3 | 2 | 2 |
| smoothing factor | 0.6 | 0.6 | 0.6 | 0.6 | 0.6 | 0.6 |
Appendix C. Detailed Results
| Base_Model | Average | Attraction | Hotel | Restaurant | Taxi | Train | |
|---|---|---|---|---|---|---|---|
| Llama1-7b | IT | 44.54 ± 0.67 | 46.63 ± 7.43 | 28.14 ± 1.81 | 48.65 ± 0.59 | 66.2 ± 2.13 | 33.06 ± 3.31 |
| 40.45 ± 1.39 | 42.14 ± 11.5 | 27.54 ± 0.95 | 39.24 ± 2.43 | 63.59 ± 1.88 | 29.71 ± 1.61 | ||
| PCDST-IT | 47.14 ± 1.73 | 52.36 ± 2.82 | 30.42 ± 1.67 | 48.62 ± 4.22 | 69.36 ± 0.23 | 34.96 ± 3.55 | |
| 46.39 ± 1.2 | 52.8 ± 3.16 | 30.09 ± 1.02 | 45.57 ± 2.81 | 68.53 ± 0.28 | 34.98 ± 2.33 | ||
| Llama2-7b | IT | 48.97 ± 0.16 | 54.46 ± 1.95 | 32.41 ± 0.53 | 59 ± 0.28 | 69.04 ± 1.72 | 29.92 ± 1.2 |
| 47.79 ± 0.32 | 54.28 ± 1.18 | 31.24 ± 0.43 | 57.25 ± 1.36 | 65.73 ± 0.73 | 30.46 ± 0.89 | ||
| PCDST-IT | 50.76 ± 1.15 | 56.9 ± 1.38 | 31.87 ± 4 | 59.52 ± 3.3 | 69.7 ± 1.18 | 35.8 ± 1.28 | |
| 50.87 ± 0.93 | 56.4 ± 1.74 | 32.69 ± 2.13 | 59.34 ± 3.26 | 69.04 ± 1 | 36.87 ± 2.85 | ||
| Llama2-13b | IT | 49.21 ± 1.4 | 59.08 ± 0.85 | 34.46 ± 0.01 | 54.63 ± 1.06 | 69.85 ± 9.9 | 28.02 ± 45.86 |
| 48.61 ± 0.19 | 57.16 ± 2.05 | 32.77 ± 0.24 | 53.36 ± 1.82 | 68.24 ± 2.78 | 31.54 ± 2.78 | ||
| PCDST-IT | 50.26 ± 0.26 | 59.27 ± 0.51 | 32.69 ± 0.56 | 50.82 ± 1.85 | 70.1 ± 0.39 | 38.44 ± 1.7 | |
| 50.06 ± 0.87 | 59.41 ± 1.26 | 31.52 ± 1.89 | 49.52 ± 1.32 | 70.36 ± 0.56 | 39.49 ± 13.11 | ||
| Llama3-8b | IT | 49.74 ± 0.34 | 60.82 ± 1.16 | 32.57 ± 2.59 | 54.5 ± 1.84 | 69.21 ± 0.92 | 31.61 ± 1.24 |
| 47.37 ± 1.14 | 57.01 ± 1.11 | 26.63 ± 9.03 | 55.74 ± 2.25 | 66.37 ± 0.99 | 31.08 ± 1.53 | ||
| PCDST-IT | 50.98 ± 0.68 | 59.14 ± 2.57 | 34.58 ± 1.89 | 53.19 ± 2.31 | 71.31 ± 2.17 | 36.7 ± 1.39 | |
| 50.73 ± 0.51 | 59.07 ± 2.79 | 33.39 ± 1.29 | 53.54 ± 2.26 | 70.4 ± 3.09 | 37.25 ± 1.43 | ||
| Gemma-2b | IT | 41.9 ± 1.99 | 41.82 ± 3.29 | 28.75 ± 1.36 | 47.52 ± 3.45 | 66.47 ± 0.99 | 24.94 ± 8.68 |
| 40.72 ± 0.93 | 37.17 ± 4.46 | 27.94 ± 1.26 | 45.69 ± 2.89 | 63.42 ± 1.35 | 29.41 ± 0.16 | ||
| PCDST-IT | 43.15 ± 2.48 | 40.57 ± 5.31 | 28.66 ± 1.49 | 46.38 ± 1.63 | 67.03 ± 3.51 | 33.1 ± 1.49 | |
| 43.03 ± 2.1 | 40.85 ± 3.95 | 28.43 ± 1.5 | 45.82 ± 1.22 | 67.66 ± 4.07 | 32.39 ± 1.35 | ||
| Gemma2-9b | IT | 52.47 ± 0.59 | 62.69 ± 1.92 | 33.92 ± 2.09 | 65.97 ± 1.3 | 66.67 ± 2.23 | 33.1 ± 0.66 |
| 51.26 ± 1.63 | 61.57 ± 2.45 | 33.44 ± 0.91 | 65.61 ± 1.71 | 65.97 ± 1.89 | 29.73 ± 6.27 | ||
| PCDST-IT | 53.08 ± 2.74 | 65.63 ± 1.66 | 34.62 ± 1.95 | 62.96 ± 3.71 | 66.35 ± 4.23 | 35.84 ± 4.04 | |
| 52.46 ± 2.67 | 65.09 ± 1.17 | 33.92 ± 1.47 | 61.31 ± 3.52 | 65.97 ± 4.17 | 36.01 ± 3.98 | ||
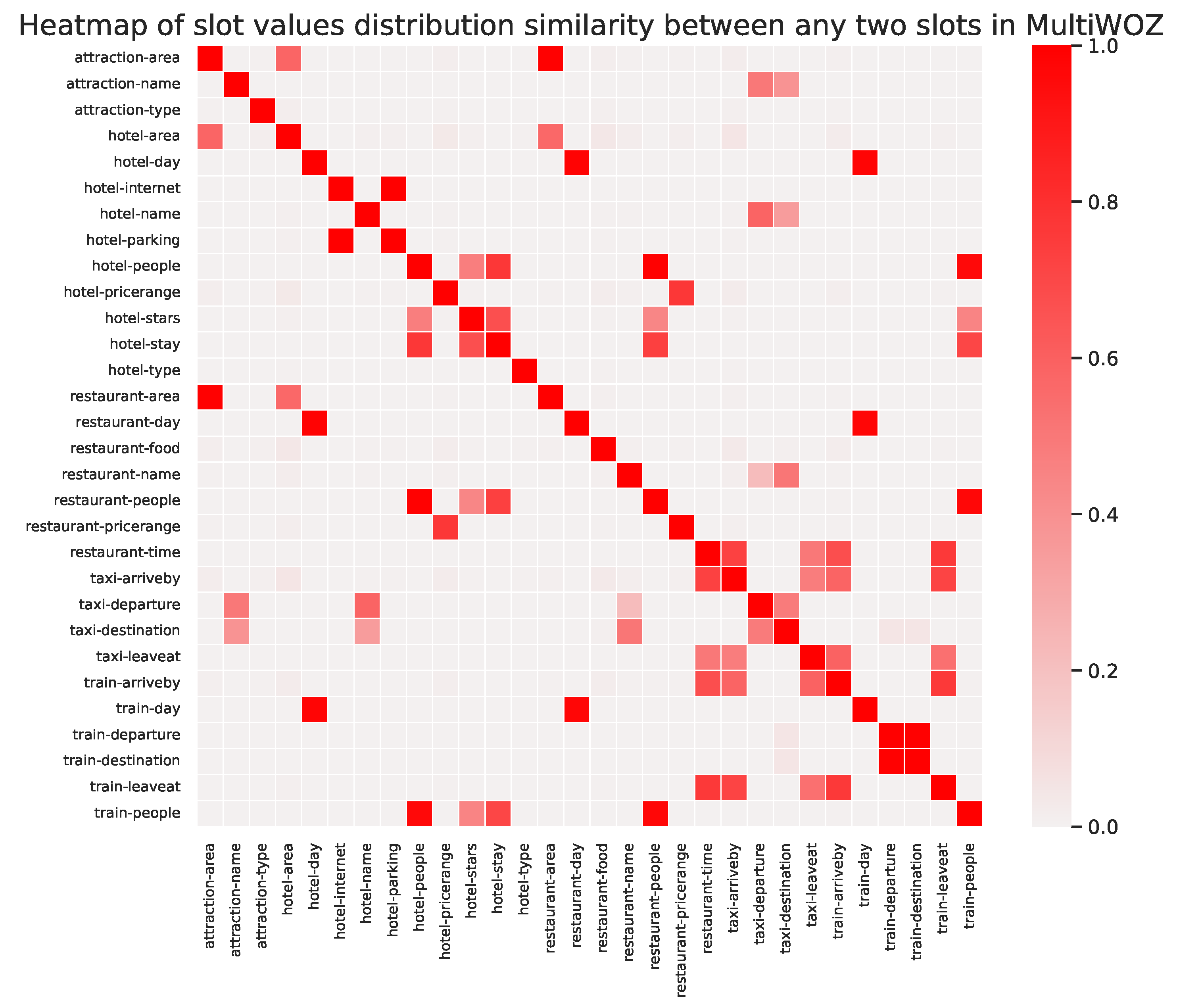
Appendix D. The Similarity between the Slot Value Distributions of Two Slots
References
- Huang, Z.; Li, F.; Yao, J.; Chen, Z. Mgcrl: Multi-view graph convolution and multi-agent reinforcement learning for dialogue state tracking. Neural Comput. Appl. 2024, 36, 4829–4846. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, T.; Yoon, H.; Kang, P.; Bang, J.; Kim, M. Dstea: Improving dialogue state tracking via entity adaptive pre-training. Knowl.-Based Syst. 2024, 290, 111542. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, L.; Yu, K. Label-aware auxiliary learning for dialogue state tracking. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11641–11645. [Google Scholar]
- Jia, X.; Zhang, R.; Peng, M. Multi-domain gate and interactive dual attention for multi-domain dialogue state tracking. Knowl.-Based Syst. 2024, 286, 111383. [Google Scholar] [CrossRef]
- Xu, J.; Song, D.; Liu, C.; Hui, S.C.; Li, F.; Ju, Q.; He, X.; Xie, J. Dialogue state distillation network with inter-slot contrastive learning for dialogue state tracking. Proc. AAAI Conf. Artif. Intell. 2023, 37, 13834–13842. [Google Scholar] [CrossRef]
- Du, M.; Cheng, L.; Xu, B.; Wang, Z.; Wang, S.; Yuan, J.; Pan, C. Ts-dst: A two-stage framework for schema-guided dialogue state tracking with selected dialogue history. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Tian, X.; Huang, L.; Lin, Y.; Bao, S.; He, H.; Yang, Y.; Wu, H.; Wang, F.; Sun, S. Amendable generation for dialogue state tracking. In Proceedings of the 3rd Workshop on Natural Language Processing for Conversational AI, Online, November 2021; pp. 80–92. [Google Scholar]
- Heck, M.; van Niekerk, C.; Lubis, N.; Geishauser, C.; Lin, H.-C.; Moresi, M.; Gasic, M. Trippy: A triple copy strategy for value independent neural dialog state tracking. In Proceedings of the 21th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Online, 1–3 July 2020; pp. 35–44. [Google Scholar]
- Wu, C.-S.; Madotto, A.; Hosseini-Asl, E.; Xiong, C.; Socher, R.; Fung, P. Transferable multi-domain state generator for task-oriented dialogue systems. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 808–819. [Google Scholar]
- Lee, H.; Lee, J.; Kim, T.-Y. Sumbt: Slot-utterance matching for universal and scalable belief tracking. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5478–5483. [Google Scholar]
- Kumar, A.; Ku, P.; Goyal, A.; Metallinou, A.; Hakkani-Tur, D. Ma-dst: Multi-attention-based scalable dialog state tracking. Proc. AAAI Conf. Artif. Intell. 2020, 34, 8107–8114. [Google Scholar] [CrossRef]
- Li, S.; Cao, J.; Sridhar, M.; Zhu, H.; Li, S.-W.; Hamza, W.; McAuley, J. Zero-shot generalization in dialog state tracking through generative question answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 1063–1074. [Google Scholar]
- Wang, Q.; Cao, Y.; Li, P.; Fu, Y.; Lin, Z.; Guo, L. Slot dependency modeling for zero-shot cross-domain dialogue state tracking. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 510–520. [Google Scholar]
- Han, T.; Huang, C.; Peng, W. Coreference augmentation for multi-domain task-oriented dialogue state tracking. arXiv 2021, arXiv:2106.08723. [Google Scholar]
- Lin, Z.; Liu, B.; Moon, S.; Crook, P.A.; Zhou, Z.; Wang, Z.; Yu, Z.; Madotto, A.; Cho, E.; Subba, R. Leveraging slot descriptions for zero-shot cross-domain dialogue statetracking. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5640–5648. [Google Scholar]
- Aksu, I.T.; Kan, M.-Y.; Chen, N. Prompter: Zero-shot adaptive prefixes for dialogue state tracking domain adaptation. arXiv 2023, arXiv:2306.04724. [Google Scholar]
- Xu, H.-D.; Mao, X.-L.; Yang, P.; Sun, F.; Huang, H. Cross-domain coreference modeling in dialogue state tracking with prompt learning. Knowl.-Based Syst. 2024, 283, 111189. [Google Scholar] [CrossRef]
- Chen, L.; Lv, B.; Wang, C.; Zhu, S.; Tan, B.; Yu, K. Schema-guided multi-domain dialogue state tracking with graph attention neural networks. Proc. Aaai Conf. Artif. Intell. 2020, 34, 7521–7528. [Google Scholar] [CrossRef]
- Hosseini-Asl, E.; McCann, B.; Wu, C.-S.; Yavuz, S.; Socher, R. A simple language model for task-oriented dialogue. Adv. Neural Inf. Process. Syst. 2020, 33, 20179–20191. [Google Scholar]
- Victor, S.; Albert, W.; Colin, R.; Stephen, B.; Lintang, S.; Zaid, A.; Antoine, C.; Arnaud, S.; Arun, R.; Manan, D.; et al. Multitask prompted training enables zero-shot task generalization. In Proceedings of the International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Wang, Y.; Mishra, S.; Alipoormolabashi, P.; Kordi, Y.; Mirzaei, A.; Naik, A.; Ashok, A.; Dhanasekaran, A.S.; Arunkumar, A.; Stap, D.; et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5085–5109. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Gao, S.; Agarwal, S.; Jin, D.; Chung, T.; Hakkani-Tur, D. From machine reading comprehension to dialogue state tracking: Bridging the gap. In Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI, Online, 9 July 2020; pp. 79–89. [Google Scholar]
- Heck, M.; Lubis, N.; Ruppik, B.; Vukovic, R.; Feng, S.; Geishauser, C.; Lin, H.-C.; van Niekerk, C.; Gasic, M. Chatgpt for zero-shot dialogue state tracking: A solution or an opportunity? In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 936–950. [Google Scholar]
- Hu, Y.; Lee, C.-H.; Xie, T.; Yu, T.; Smith, N.A.; Ostendorf, M. In-context learning for few-shot dialogue state tracking. arXiv 2022, arXiv:2203.08568. [Google Scholar]
- Yang, Y.; Li, Y.; Quan, X. Ubar: Towards fully end-to-end task-oriented dialog system with gpt-2. Proc. AAAI Conf. Artif. Intell. 2021, 35, 14230–14238. [Google Scholar] [CrossRef]
- Feng, Y.; Wang, Y.; Li, H. A sequence-to-sequence approach to dialogue state tracking. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; pp. 1714–1725. [Google Scholar]
- Lee, C.-H.; Cheng, H.; Ostendorf, M. Dialogue state tracking with a language model using schema-driven prompting. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4937–4949. [Google Scholar]
- Su, Y.; Shu, L.; Mansimov, E.; Gupta, A.; Cai, D.; Lai, Y.-A.; Zhang, Y. Multi-task pre-training for plug-and-play task-oriented dialogue system. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 4661–4676. [Google Scholar]
- Mi, F.; Wang, Y.; Li, Y. Cins: Comprehensive instruction for few-shot learning in task-oriented dialog systems. Proc. AAAI Conf. Artif. Intell. 2022, 36, 11076–11084. [Google Scholar] [CrossRef]
- Budzianowski, P.; Wen, T.-H.; Tseng, B.-H.; Casanueva, I.; Ultes, S.; Ramadan, O.; Gasic, M. Multiwoz-a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. arXiv 2018, arXiv:1810.00278. [Google Scholar]
- Eric, M.; Goel, R.; Paul, S.; Sethi, A.; Agarwal, S.; Gao, S.; Kumar, A.; Goyal, A.; Ku, P.; Hakkani- Tur, D. Multiwoz 2.1: A consolidated multi-domain dialogue dataset with state corrections and state tracking baselines. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 422–428. [Google Scholar]
- Veron, M.; Galibert, O.; Bernard, G.; Rosset, S. Attention modulation for zero-shot cross-domain dialogue state tracking. In Proceedings of the 3rd Workshop on Computational Approaches to Discourse, Gyeongju, Republic of Korea, 16–17 October 2022; pp. 86–91. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI blog 2019, 1, 9. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Lin, Z.; Liu, B.; Madotto, A.; Moon, S.; Zhou, Z.; Crook, P.A.; Wang, Z.; Yu, Z.; Cho, E.; Subba, R.; et al. Zero-shot dialogue state tracking via cross-task transfer. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 7890–7900. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Dubey, A.; Jauhri, A.; Pandey, A.; Kadian, A.; Al-Dahle, A.; Letman, A.; Mathur, A.; Schelten, A.; Yang, A.; Fan, A.; et al. The llama 3 herd of models. arXiv 2024, arXiv:2407.21783. [Google Scholar]
- Gemma Team; Mesnard, T.; Hardin, C.; Dadashi, R.; Bhupatiraju, S.; Pathak, S.; Sifre, L.; Rivière, M.; Kale, M.S.; Love, J.; et al. Gemma: Open models based on gemini research and technology. arXiv 2024, arXiv:2403.08295. [Google Scholar]
- Gemma Team; Riviere, M.; Pathak, S.; Sessa, P.G.; Hardin, C.; Bhupatiraju, S.; Hussenot, L.; Mesnard, T.; Shahriari, B.; Ramé, A.; et al. Gemma 2: Improving Open Language Models at a Practical Size. arXiv 2024, arXiv:2408.00118. [Google Scholar]




| Model | Base Model | Avg | Att | Hot | Res | Tax | Tra |
|---|---|---|---|---|---|---|---|
| TRADE † | N | 25.61 | 19.87 | 13.7 | 11.52 | 60.58 | 22.37 |
| SUMBT ‡ | N | 27.40 | 23.57 | 14.51 | 17.19 | 60.41 | 21.31 |
| SUMBT-variant ‡ | N | 29.24 | 29.83 | 17.09 | 16.8 | 59.72 | 22.74 |
| SimpleTOD++ † | GPT2-b | 29.65 ± 0.58 | 28.01 ± 1.30 | 17.69 ± 1.00 | 15.57 ± 1.54 | 59.22 ± 0.95 | 27.75 ± 1.16 |
| T5DST † | T5-s | 35.2 ± 0.59 | 33.09 ± 1.60 | 21.21 ± 0.61 | 21.65 ± 1.07 | 64.62 ± 0.55 | 35.42 ± 1.42 |
| PCDST | T5-s | 36.88 ± 0.86 | 37.31 ± 0.51 | 24.77 ± 0.5 | 23.79 ± 1.34 | 64.23 ± 0.62 | 34.29 ± 1.84 |
| Model | Base Model | Avg | Att | Hot | Res | Tax | Tra |
|---|---|---|---|---|---|---|---|
| TRADE † | N | 25.69 | 20.06 | 14.2 | 12.59 | 59.21 | 22.39 |
| MA-DST † | N | 26.87 | 22.46 | 16.28 | 13.56 | 59.27 | 22.76 |
| SUMBT † | Bert-b | 28.18 | 22.6 | 19.8 | 16.5 | 59.5 | 22.5 |
| T5DST ‡ | T5-s | 33.56 | 31.92 | 20.72 | 20.09 | 64.12 | 28.83 |
| T5DST ‡ | T5-b | 36.25 | 35.51 | 22.48 | 25.04 | 65.93 | 34.82 |
| TransferQA ‡ | T5-l | 35.77 | 31.25 | 22.72 | 26.28 | 61.87 | 36.72 |
| SDM ‡ | T5-s | 35.55 | 33.92 | 19.85 | 20.75 | 66.25 | 36.96 |
| SDM ‡ | T5-b | 40.18 | 37.83 | 26.50 | 27.05 | 69.23 | 40.27 |
| CLMQ † | GPT2-b | 36.02 | 34.3 | 22.94 | 24.65 | 59.68 | 38.55 |
| CLMQ † | GPT2-m | 39.27 | 42.39 | 24.88 | 27.69 | 60.32 | 41.05 |
| Prompter * | PPTOD-s | 37.27 ± 7.0 | 35.80 ± 0.7 | 19.20 ± 0.8 | 26.00 ± 0.7 | 66.30 ± 0.2 | 39.00 ± 0.5 |
| PCDST | T5-b | 42.62 ± 0.62 | 46.45 ± 0.38 | 25.94 ± 0.26 | 30.85 ± 0.63 | 67.98 ± 0.58 | 41.91 ± 2.12 |
| Model | Training Time (Minutes) | Inference Time (Milliseconds) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Avg | Att | Hot | Res | Tax | Tra | Avg | Att | Hot | Res | Tax | Tra | |
| CLMQ-b | 326 | 335 | 265 | 310 | 380 | 340 | 78 | 43 | 110 | 97 | 45 | 95 |
| T5DST-s | 139 | 165 | 115 | 135 | 150 | 130 | 375 | 179 | 583 | 440 | 244 | 428 |
| T5DST-b | 409 | 450 | 305 | 365 | 510 | 415 | 125 | 67 | 187 | 131 | 88 | 153 |
| PCDST-s | 26 | 25 | 25 | 25 | 30 | 25 | 10 | 6 | 20 | 9 | 8 | 10 |
| PCDST-b | 69 | 70 | 65 | 65 | 75 | 70 | 23 | 17 | 28 | 22 | 22 | 24 |
| Model | Test | Llama1-7b | Llama2-7b | Llama2-13b | Llama3-8b | Gemma-2b | Gemma2-9b |
|---|---|---|---|---|---|---|---|
| IT | Test_A | 44.54 ± 0.67 | 48.97 ± 0.16 | 49.21 ± 1.4 | 49.74 ± 0.34 | 41.9 ± 1.99 | 52.47 ± 0.59 |
| Test_B | 40.45 ± 1.39 | 47.79 ± 0.32 | 48.61 ± 0.19 | 47.37 ± 1.14 | 40.72 ± 0.93 | 51.26 ± 1.63 | |
| PCDST-IT | Test_A | 47.14 ± 1.73 | 50.76 ± 1.15 | 50.26 ± 0.26 | 50.98 ± 0.68 | 43.15 ± 2.48 | 53.08 ± 2.74 |
| Test_B | 46.39 ± 1.2 | 50.87 ± 0.93 | 50.06 ± 0.87 | 50.73 ± 0.51 | 43.03 ± 2.1 | 52.46 ± 2.67 |
| Model | Average | Attraction | Hotel | Restaurant | Taxi | Train |
|---|---|---|---|---|---|---|
| PCDST | 42.62 ± 0.62 | 46.45 ± 0.38 | 25.94 ± 0.26 | 30.85 ± 0.63 | 67.98 ± 0.58 | 41.91 ± 2.12 |
| w/o sample | 34.69 ± 0.88 | 45.1 ± 1.58 | 26.88 ± 0.31 | 30.24 ± 1.78 | 68.66 ± 0.17 | 2.58 ± 4.37 |
| w/o shuffle | 42.14 ± 0.79 | 45.02 ± 1.79 | 25.12 ± 0.51 | 29.73 ± 2.65 | 67.3 ± 0.32 | 43.52 ± 0.48 |
| w/o all | 34.16 ± 0.11 | 46.61 ± 2.21 | 25.22 ± 0.3 | 31.3 ± 0.8 | 67.05 ± 1.36 | 0.6 ± 1.05 |
| Domain | Slot Order |
|---|---|
| Attraction | area, type, name |
| Hotel | type, name, area, pricerange, stars, internet, parking, day, people, stay |
| Restaurant | area, food, pricerange, name, day, people, time |
| Taxi | departure, destination, leaveat, arriveby |
| Train | destination, departure, day, arriveby, leaveat, people |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Zhong, L.; Jiang, H.; Chen, W.; Yuan, C.; Wang, X. Prompt-Based End-to-End Cross-Domain Dialogue State Tracking. Electronics 2024, 13, 3587. https://doi.org/10.3390/electronics13183587
Lu H, Zhong L, Jiang H, Chen W, Yuan C, Wang X. Prompt-Based End-to-End Cross-Domain Dialogue State Tracking. Electronics. 2024; 13(18):3587. https://doi.org/10.3390/electronics13183587
Chicago/Turabian StyleLu, Hengtong, Lucen Zhong, Huixing Jiang, Wei Chen, Caixia Yuan, and Xiaojie Wang. 2024. "Prompt-Based End-to-End Cross-Domain Dialogue State Tracking" Electronics 13, no. 18: 3587. https://doi.org/10.3390/electronics13183587