Abstract
Traditional jamming technologies have become less effective with the development of anti-jamming technologies, especially with the appearance of intelligent transmitters, which can adaptively adjust their transmission strategies. To deal with intelligent transmitters, in this paper, a game-based intelligent jamming scheme is proposed. Considering that the intelligent transmitter has multiple transmission strategy sets whose prior probabilities are unknown to the jammer, we first model the interaction between the transmitter and the jammer as a dynamic game with incomplete information. Then the perfect Bayesian equilibrium is derived based on assumptions of some prior information. For more practical applications when no prior information about the transmitter is available at the jammer, a Q-learning-based method is proposed to find an intelligent jamming strategy by exploiting the sensing results of the wireless communications. The design of the jammer’s reward function is guided by the game utility and the reward is calculated based on the Acknowledgement/Negative Acknowledgement feedback of the receiver. Simulation results show that the proposed scheme has only loss in jamming utility compared to that of the perfect Bayesian equilibrium strategy. Compared to existing jamming schemes, a higher packet error rate can be achieved by the proposed scheme by consuming less jamming power.
1. Introduction
In recent years, a variety of information technology has been widely used in the electronic warfare field. With the development of electronic countermeasures, there are various anti-jamming methods to cope with malicious interference from a jammer. Traditional jamming techniques usually rely on the experience of experts to formulate jamming strategies or directly use high-power jamming to suppress the communication signals, which makes the jamming efficiency relatively low and may result in the exposure of the jammer’s location [1,2]. To address the above problems, the authors in [3] solved the problem of jamming power allocation when the jammer was power-constrained. Optimal jamming signals have been studied in [4] for digital communication systems. However, the transmission strategies of the transmitter in [3,4] were fixed, and the proposed jamming strategies are only optimal for the given transmissions. The existing jamming strategies cannot interfere with an intelligent transmitter effectively since the transmission strategy can be adjusted adaptively [5]. Therefore, how to effectively jam the intelligent transmission is a challenging and urgent problem to be solved.
Game theory is a framework used to study the behavioral interactions between intelligent players when they aim to maximize their own utilities. It has been used to model the interactions between intelligent transmitters and jammers in [6,7,8,9,10]. Specifically, the authors in [7] examined the power selection problem for transmitters and jammers and modeled this problem as a dynamic game. The authors in [9] investigated the jamming issue in frequency hopping communications, discussing the relationship between the Nash equilibrium solution and the corresponding quadratic programming global optimal solution under perfect information. Some other papers have studied Bayesian game models when players can only observe partial information [11,12]. To solve the optimal strategy, it is often required that the jammer can have some prior information about the communicating party, such as channel state information (CSI), the receiver’s signal to interference plus noise power ratio (SINR), etc., which is difficult to realize in the actual confrontation due to their non-cooperative nature.
Although game theory is a suitable and powerful framework to model the behavioral interaction between transmitters and jammers, it faces problems with information acquisition in electronic warfare scenarios. In recent years, some other researchers have applied reinforcement learning (RL) to make jamming decisions without requiring prior information from the transmitter [13,14]. The authors in [13] studied the interference problem of unmanned aerial vehicles (UAV) on ground communication networks. A neural network-based algorithm was used to predict the state of user communication links and then the UAV Q-learning (QL) algorithm was used to select interference strategies. In [14], an interference problem for frequency hopping communication was investigated and an interference channel decision method based on the deep-Q-network (DQN) algorithm was proposed to realize the tracking and prediction of the communication channel selected by the transmitter. However, few of them have considered the intelligence of the transmitters. Without prior information on the transmitter, how to construct the jammer’s utility is an essential issue worth considering.
In the most recent related work [15], a non-zero-sum game was used to model the nonoperative interaction between the intelligent transmitter and jammer, and a learning-based scheme has been proposed. Different from [15], which assumes that the intelligent transmitter has a single transmission set, in this paper, we attempt to solve the jamming strategy problem when the intelligent transmitter has multiple transmission strategy sets, which are unknown to the jammer. Considering that the jammer can adaptively adjust its jamming strategy after observing the transmissions, a dynamic game with incomplete information is used to model the interaction between the jammer and the transmitter. The Perfect Bayesian Equilibrium (PBE) of the game is first derived based on some ideal assumptions. For more practical scenarios when the jammer has no prior information about the transmitter, a QL-based jamming scheme is proposed in this paper by exploiting the Acknowledgement/Negative Acknowledgement (ACK/NACK) messages from the receiver. The contributions of this paper can be summarized as follows:
- To model the confrontational interaction between the transmitter and jammer, considering that the jammer can only have incomplete information about the transmitter, a dynamic game with incomplete information is formulated in this paper. Utilities for both players are designed. To solve the formulated game model, PBE is derived based on the assumption that some prior information about the transmitter is available at the jammer.
- To solve the jamming strategy in more practical scenarios where no prior information is available at the jammer, a QL-based jamming decision method is proposed, and a new method to calculate the jamming reward is designed based on ACK/NACK information from the receiver rather than any prior information of the transmitter.
- Simulation results show that the proposed scheme can achieve similar utility as that of the PBE strategy. Compared to other jamming schemes, the proposed scheme causes a higher packet error rate (PER) to the wireless transmission with a lower power cost.
The rest of the paper is organized as follows. Section 2 introduces the related work. Section 3 presents the system model and the game formulation. The dynamic game is solved under the assumption of some prior information in Section 4. In Section 5, the QL-based jamming decision scheme is proposed. Section 6 shows the simulation parameters, comparison schemes, simulation results and discussions. Finally, Section 7 concludes this paper.
2. Related Work
So far, research on jamming strategies is not as abundant as research on anti-jamming strategies. Table 1 presents the comparison details of existing studies on jamming strategies. It can be found that most of the existing studies based on game theory and optimization methods are based on the assumption that certain prior information is available at the jammer.

Table 1.
Existing related work on jamming strategies.
Specifically, when the transmitter’s transmission strategy is given, the authors in [3] focused on the issue of optimal power allocation to jammers in communication systems, in particular, how to maximize the jamming effect through power randomization in the presence of non-Gaussian noise. To maximize the jamming effect on digital modulation signals, the authors of [16] investigated the style of the optimal jamming signal, including the average jamming power, the optimal statistical distribution and the modulation of the jamming signal. However, the above studies do not consider the transmitter’s ability to adjust its transmission strategy. When both the transmitter and the jammer can adjust their strategies adaptively, game theory is suitable for modeling the interaction between the intelligent transmitter and the jammer. Actually, there are many studies that use game theory to investigate anti-jamming strategies [21,22,23,24]. For the jamming strategy, the authors in [17] studied the jamming decision problem for the source and relay nodes in a wireless relay system. The interactions between the jammer and the legitimate nodes have been modeled as a Stackelberg game in [17], and the optimal channel power allocation has been derived in a multi-channel attack scenario. In [12], to study the jamming power strategy when the jammer is not fully aware of the opponent’s CSI, a Bayesian–Stackelberg game model has been developed to derive the optimal jamming power strategy. In the above-mentioned studies, some prior information about the opponent has to be used to formulate the game utility and derive the game equilibrium. For the jamming strategy decision, due to the non-cooperative nature between the jammer and the communication party, it is almost impossible for the jammer to obtain the CSI or SINR information of the communication link. Therefore, a major challenge to solving jamming decision problems is the acquisition of prior information about the communication party.
When prior information is not available, RL, which can explore optimal strategies in unknown environments through interaction with the environment and continuous trial and error, is an effective method to find solutions. In the field of radar, the jamming decision method combined with RL has been proposed to implement an attack that can adaptively adjust jamming parameters [25,26,27]. Recent research has applied RL methods to make jamming decisions, realizing the search for optimal jamming strategy without prior information of the wireless communications. In [18], a hierarchical RL model has been proposed for the decision-making of jamming bands and jamming bandwidths for frequency-hopping communication systems with limited jamming resources. The authors in [19] proposed a deep-learning-based communication channel prediction classifier for cognitive radio networks. The sensory information of the jammer has been used in [19] to predict the communication channel of the legitimate user. Based on [16], a parameter optimization method based on the multi-armed bandits (MAB) algorithm has been proposed to optimize the jamming power and jamming pulsing duration. When the jammer does not know the transmit power and modulation of the transmitter, ACK/NACK information fed back from the receiver has been exploited to formulate the jammer’s utility in [20]. In the above RL-based jamming decision schemes, the jamming problem is considered from the perspective of the jammer only. In other words, these studies have not yet considered the situation in which the transmitter has intelligence and can adjust its transmission strategy adaptively.
In general, game theory is good at dealing with the interaction between intelligent transmitters and jammers, but it requires the jammers to have prior information about the transmitter; RL theory can learn the optimal jamming strategy in the absence of prior information, but it tends to look at the problem from a single perspective and tends to neglect the intelligence of the transmitter.
In our recent work [15], a non-zero-sum game has been used to model the interaction between the transmitter and the jammer and a DQN-based jamming strategy has been proposed without requiring prior information. However, the transmission strategy set was assumed to be fixed. When the transmitter has multiple sets of transmission strategies, it can switch among different sets of transmission strategies to achieve better anti-jamming performance. How to deal with the situation when the intelligent transmitter has multiple sets of transmission strategies is a problem to be solved.
3. System Model and Game Formulation
3.1. System Model
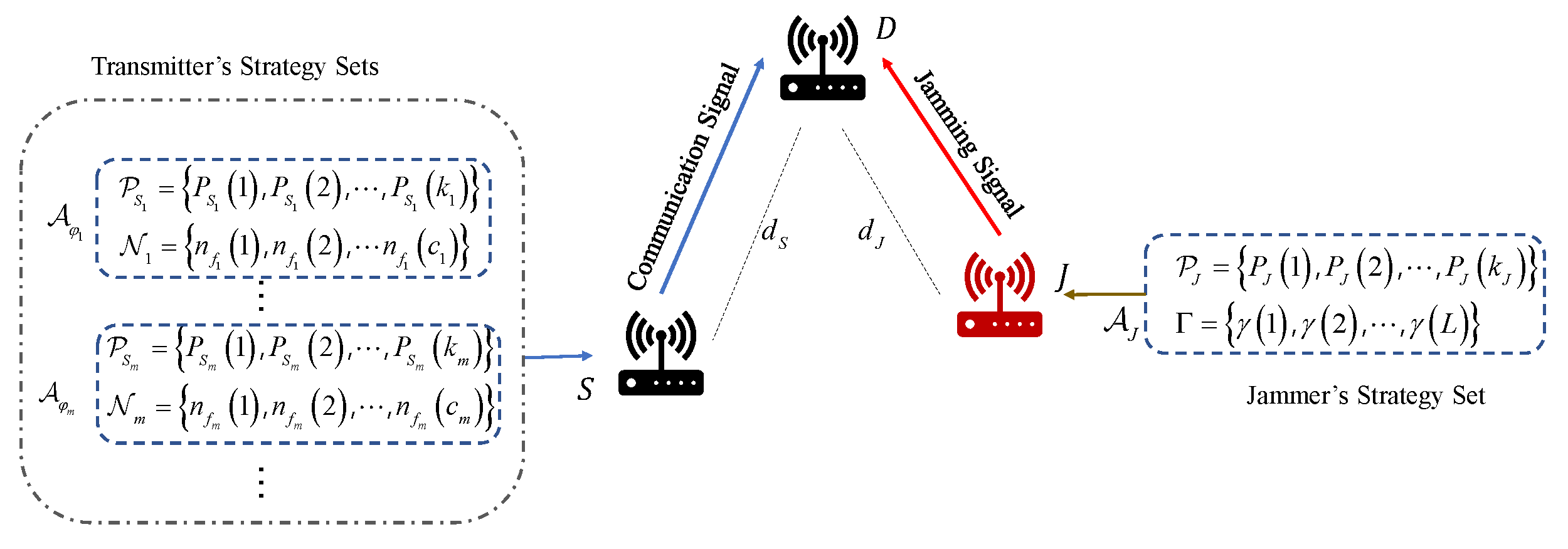
Consider a jamming scenario as shown in Figure 1, where there is a transmitter S communicating with a receiver D, and the distance between S and D is . The jammer J needs to disturb the wireless communication between S and D, and the distance between J and D is .
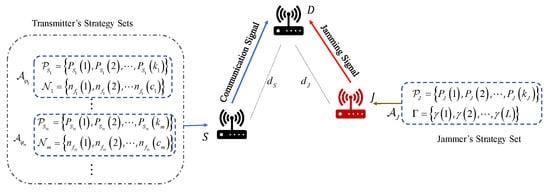
Figure 1.
The system model of wireless communications with a jammer.
To mitigate the effects of the jammer’s interference, S employs frequency hopping and transmit power adapting [28,29]. The available transmit powers and frequency hopping channels construct a transmission strategy set of S. In this paper, S has M available transmission strategy sets, . For different transmission strategy sets, there are different transmit powers and frequency hopping channels involved. The mth transmission strategy set can be denoted as , , where × denotes the Cartesian product, and denote the set of transmit powers and the set of the number of available frequency hopping channels of the mth transmission strategy set of S, respectively, is the number of available power levels in , is the number of available channels of the ith channel set in and is the total number of channel sets in . S switches from one strategy set to another to enhance the anti-jamming ability.
The jammer has two adjustable parameters, the average jamming power and the jamming time ratio, which has been demonstrated in [16] that the jamming effect can be enhanced by modifying these two parameters when the jamming energy is constrained. The jamming strategy set of J can be denoted by , where and denote the set of average jamming powers and the set of jamming time ratios of J, respectively, with and L being the number of available jamming power levels and number of jamming time ratios, respectively. In order to achieve effective jamming, J first detects the communication strategies used by S before transmitting the jamming signal. This allows J to select an appropriate jamming strategy to disrupt the communication. Given that S employs frequency hopping communication, J also needs to detect the communication frequency band in order to capture the communication channel used by S and D. In this paper, we assume that J has detected the communication channel by spectrum sensing.
3.2. Game Formulation
Game theory can be effectively employed to examine the dynamic interactions between the intelligent transmitter and the intelligent jammer. A game is comprised of three fundamental elements: players, strategy set, and utility function set. In this paper, we consider the jamming decision problem for a frequency-hopping communication system with a tracking jammer, which senses the wireless transmissions first and then adjusts its jamming strategy adaptively. After the jammer performs jamming based on the chosen jamming strategy, the transmitter adjusts its transmission strategy accordingly. As the transmission strategy changes, the jammer will detect the wireless transmission and adjust its jamming strategy. The transmitter and the jammer interact with each other until they come to an equilibrium. Dynamic game is a model suitable for studying the behavior of players with sequential order [12], so we model this jamming confrontation process as a dynamic game model, with S designated as the leader and J as the follower.
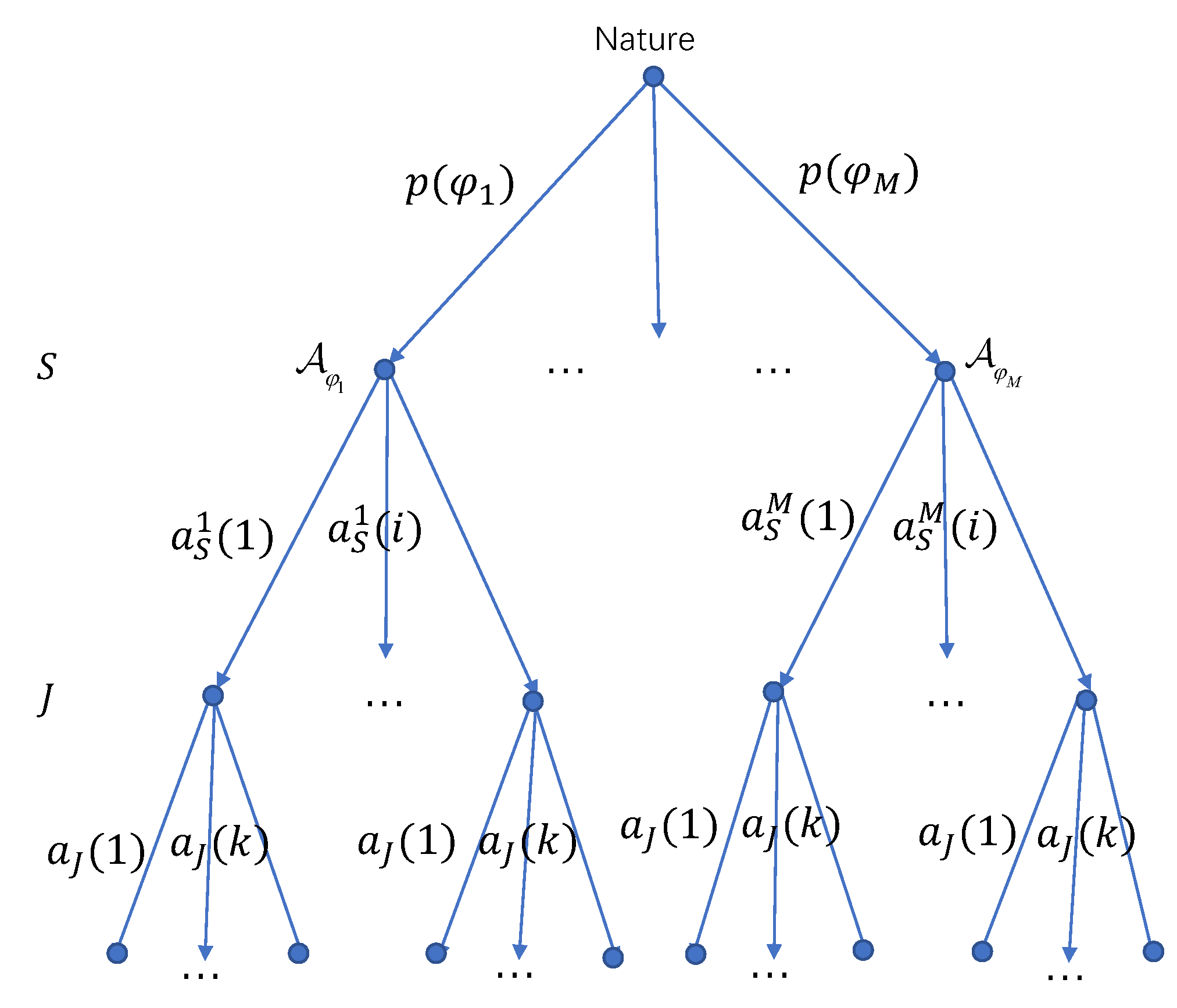
Since S has multiple transmission strategy sets, it will randomly select one out of them for one transmission. Let represent the prior probability distribution, is the probability that the transmission strategy set is chosen by S. As illustrated in Figure 2, for each transmission, S selects a transmission strategy set based on the probability distribution , which is determined by a virtual player `nature’. This probability distribution is not available to J. Then, S chooses a transmission strategy from the selected transmission strategy set , which can be denoted as , where and . For the jammer, its jamming strategy set is , which includes N jamming strategies. The k-th jamming strategy of J is written as with , .
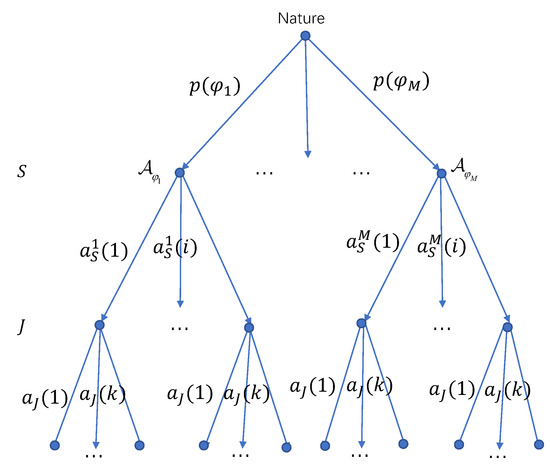
Figure 2.
The schematic diagram of the dynamic game.
Another important factor in game theory is the utility function of the players. The symbol error rate (SER) is a parameter that can directly reflect the communication quality between S and D, and it has been used by existing studies to construct the utility function [6,30]. Consider that wireless communication has certain requirements for the maximum SER (): if the SER is less than or equal to , S and D can communicate normally, defining the communication gain at this time as ; if the SER is over , S and D cannot communicate normally, defining the communication gain at this time as 0. Since the SER of D is related to the specific strategies of S and J, the communication gain is also a function of the strategies of S and J, for a strategy pair of S and J, and , the communication gain can be expressed as follows
where is the SER obtained when S uses the transmission strategy and J uses the jamming strategy . Since S obtains the communication gain by jumping across channels, the normalized gain can be written as . Meanwhile, considering the power cost of S, the utility function of S is defined as
where represents the power cost factor associated with the transmission strategy set .
The jammer J tries to degrade the utility of S by performing jamming. Let denote the utility that S achieves by using the transmission strategy and no jamming attack occurs, J wants to decrease the utility and the degradation of the utility caused by jamming can be regarded as the jamming gain, which can be written as . Considering the jamming power, the utility function of J is defined as follows:
where represents the power cost factor of J.
To calculate the utility functions, the detailed derivation of SER is given in the following.
Assume that S employs quadrature phase-shift keying (QPSK) modulation, the corresponding SER of D without jamming is as follows [31]:
where denotes the channel gain of the link; denotes the noise power. For the channel gain, considering only the path loss, it can be calculated according to [15] by the following equation
where c is the speed of light; is the central frequency of the wireless signal; is the far-field reference distance of the antenna; is the path loss exponent; d is the distance of the communication link.
In the event of jamming, the SER of D is calculated as follows [31]:
where denotes the channel gain of the link, is the jamming power given the selected power and the jamming time ratio .
As a follower, J performs spectrum sensing to detect the communication channel utilized by S. This initial detection period allows J to identify the communication band and avoids interfering with the communication during this crucial stage. It is assumed that the jammer’s detection capability is limited, such that it can perform successful spectrum detection across channels at a time, which has a duration of . This detection time is much smaller than the frequency hopping period T of S. J randomly detects channels continuously to find out which channel is used by S. The maximum number of channel detection used by J is where denotes a downward rounding function, and is the number of channels utilized by S. Since J is able to detect channels at a time, it is easy to know that the probability of , that is, the probability that J can detect the transmission channel at the first attempt, can be calculated as
where is the probability of failing to detect the transmission channel at the first attempt. If J fails to detect the channel at its first attempt, it has to continue detecting in the remaining channels. If J detects times but still fails, the probability that it detects the transmission channel at the th attempt is . In this way, the probability distributions can calculated as follows:
where . Then, the expectation of , i.e., the average number of detections required by J to discover the communication channel, can be calculated based on the probability distribution of as follows:
Therefore, the average detection time required by J is , and the effective time for which J is able to perform jamming is . The actual jamming duration of J is, therefore, , where is the jamming time ratio that J selected. Subsequently, by combining this with Equations (4) and (6), the average SER of D in Equation (1) is derived as follows
In this jamming confrontation game, the objective of S is to maximize its own utility by selecting appropriate transmit power and frequency hopping channels from the strategy set utilized, based on the SER calculated in Equation (10), the utility of S can be formulated as
Similarly, J aims to inflict the greatest possible degree of jamming on wireless communication, which can be formulated as
Given that the final jamming effect is jointly determined by the strategies of both S and J, it is imperative that the latter identifies the optimal jamming strategy by considering the solution to both Equations (11) and (12).
4. Game Equilibrium with Incomplete Information
The Nash equilibrium (NE) represents a pivotal concept in the domain of non-cooperative games. The concept of NE can be extended to dynamic games with incomplete information, wherein it is referred to as PBE [32,33]. Consequently, the equilibrium strategy represents an optimal approach for J, as it guides the game dynamics towards an equilibrium point where the jammer’s utility is maximized and the behavior to disrupt the equilibrium is irrational. To calculate the jamming utility in Equation (3), in this section, it is assumed that J has the prior information of the SER and the maximum utility of S. Although this assumption is challenging to achieve in a practical confrontation, we present an equilibrium solution under this assumption to work as a benchmark for comparison.
In the game, S selects a strategy from a certain transmission strategy set , and this selection procedure can be denoted as , where is the response function of S which will be defined later. After observing the communication behavior, J selects an appropriate jamming strategy from its jamming strategy set according to the current strategy of S. This jamming strategy selection procedure is denoted as , and is the response function of J, which will be defined later.
However, J is unable to ascertain the specific type of strategy set being utilized by S with precision. Instead, J can only make decisions according to its observations. The transmission strategy observed by J is denoted as . In order to derive the optimal strategy, J must first judge the type of the strategy set utilized by S. Additionally, J must speculate on the possible probability distribution of the current strategy set, which is , where is called the jammer’s belief.
Given the beliefs held by J regarding all the strategies of S, J selects the jamming strategy that maximizes its expected utility based on its beliefs. Therefore, the optimal strategy for J selected by its response function can be expressed as:
Meanwhile, S is aware that J will optimize its own utility by adopting the strategy with the highest jamming utility. Consequently, S will select the transmission strategy that is most advantageous to its utility maximization based on the subsequent actions of J. Thus, the optimal strategy of S selected by its response function can be expressed as follows:
Consequently, we obtain a set of optimal strategy combinations under the assumption of the jammer’s belief . The belief of J is based on the prior probability distribution of the strategy sets of S, which is unknown to J. J can estimate this prior probability based on its observation by the Bayesian criterion, i.e.,
where is an indicator function that takes the value 1 when the event is true; otherwise, it takes the value 0.
For each transmission, the entire strategy set is divided into two sets: and , where is a set of the strategies that have been chosen by the response function from all the transmission strategy sets, and is the set of the strategies that would not be used in this transmission. For the strategies in , the belief of J can be calculated by Equation (15). In the case of strategies in , the beliefs cannot be calculated using Equation (15). In this instance, the beliefs are sufficient as long as they are compatible with the equilibrium strategy and satisfy Equation (13). In other words, there exists such that satisfies Equation (13), and this can be transformed into the question of whether there exists a feasible solution to Equation (16),
where can be any linear function. The existence of a feasible solution to this optimization problem implies that the feasible domain constituted by its constraints is not an empty set, i.e., there exists a probability distribution such that the jammer strategy satisfies:
i.e., satisfies Equation (13). The optimization problem described in Equation (16) was finally solved using the ’linprog’ function in Matlab.
After defining the concept of PBE, we present a method for identifying the PBE strategy for this jamming game. The specific steps for solving the PBE strategy are outlined in Algorithm 1. First, the optimal communication strategy is calculated according to Equation (14) given a jammer strategy . Then, it must be determined whether is the optimal strategy under :
- For the strategy , determine whether there exists a feasible solution to Equation (16),
If these two conditions are satisfied, then is a PBE. All PBE of this game can be identified by traversing all available response functions of J.
| Algorithm 1 Specific steps for solving the PBE |
|
5. Intelligent Jamming Decision Model without the Opponent’s Information
In the preceding section, we have formulated a game model for jamming confrontation and proposed a method for solving the PBE. However, it is based on the assumption that the maximum utility of S and SER information are available at J.
In actual communication jamming scenarios, it is almost impossible for a jammer to acquire such information about the opponent. Therefore, the jamming utility defined in Equation (3) cannot be calculated directly. In this section, an intelligent jamming strategy-making scheme is proposed without requiring any prior information about the wireless communications.
5.1. Jamming Decision Model
QL is a model-free decision-making algorithm [34], which aims to maximize long-term cumulative reward and identify optimal strategies through interaction with the environment. The QL algorithm is suitable for dealing with decision problems in discrete space, with strict convergence proof, more stable performance, and faster convergence speed when dealing with small-scale decision problems. Considering that the strategy set of J is not of high dimension, this subsection develops a QL-based jamming decision (QLJD) algorithm.
To use the QL algorithm, it is first necessary to construct a Markov decision process (MDP) model of J. The MDP can be represented by a tuple , where the state transition probability is determined by the transmitter together with the jammer. J can implicitly obtain by interacting with the environment. The discount factor indicates the relative importance that J assigns to the expected future reward. The corresponding values will be provided in the simulation section. The definitions of and are given in the following.
- State: J initially identifies the transmission by observing the communication behaviors, then selects appropriate jamming strategy from . Thus, the state of J is defined as the detected communication strategy utilized by S, i.e.,
- Action: In the game model, the jammer’s strategy is defined as the selected jamming parameters. In this context, it is the same as the game model, i.e.,
- Reward: The objective is to identify the optimal strategy that maximizes the jamming utility. Consequently, the reward for J is defined as the jammer’s utility, i.e.,The jammer’s calculation of rewards requires an estimate of the receiver’s SER and the maximum utility in the absence of jamming . Consequently, the estimation method for reward will be present in Section 5.2.
Next, we will present the steps of jamming decisions based on QL. Initially, the jammer must construct a value table to record the Q-value of each state-action pair, denoted by . This represents a form of assessment of the relative merits and drawbacks of each jamming parameter employed by J. A higher Q-value indicates a greater anticipated benefit for the jamming parameter in question, and thus a more effective jamming outcome. The jammer will update this Q-value table in real-time as a consequence of its interaction with the environment. In the decision-making process, J initially identifies the environmental conditions, i.e., the state . Subsequently, J selects an appropriate action, , to execute in accordance with the observed state. Finally, estimates of the jammer’s reward based on the feedback information is obtained, and then the environment state at the subsequent moment is observed. In the course of the process, J will update the Q-value in accordance with the following equation:
where denotes the learning rate of J. In the initial period of learning, J has not yet had a sufficient opportunity to explore the environment. Consequently, the jamming strategy with the largest Q-value may prevent J from identifying the optimal jamming strategy. Once the Q-value has been updated more moderately (the algorithm has begun to converge), it may no longer be possible to obtain higher benefits by continuing to explore the environment. It is thus essential to strike a balance between exploration and exploitation. The algorithm is employed to achieve a balance between exploration and exploitation in the learning process: The jammer executes the jamming strategy with the highest Q-value with probability , while the remaining probability is allocated to the random selection of a jamming strategy. The specific steps of QLJD are given in Algorithm 2.
| Algorithm 2 QL-based jamming decision algorithm (QLJD) |
|
5.2. ACK/NACK-Based Reward Estimation Method
The SER and the maximum utility of S are private information of the wireless transceiver S and D. In the Transmission Control Protocol/Internet Protocol (TCP/IP), an ACK message is transmitted by the receiver if the receiver successfully receives the data. Some studies have been conducted based on ACK/NACK information for jamming decisions [14,20]. In this paper, we assume that J is located around D and able to intercept the ACK/NACK. An ACK/NACK-based reward estimation method (A/N-RE) is proposed. If the ACK signal is not available at J, depending on the victim’s parameters that J can observe, different utilities or rewards may be used by J, which can be left for our future research.
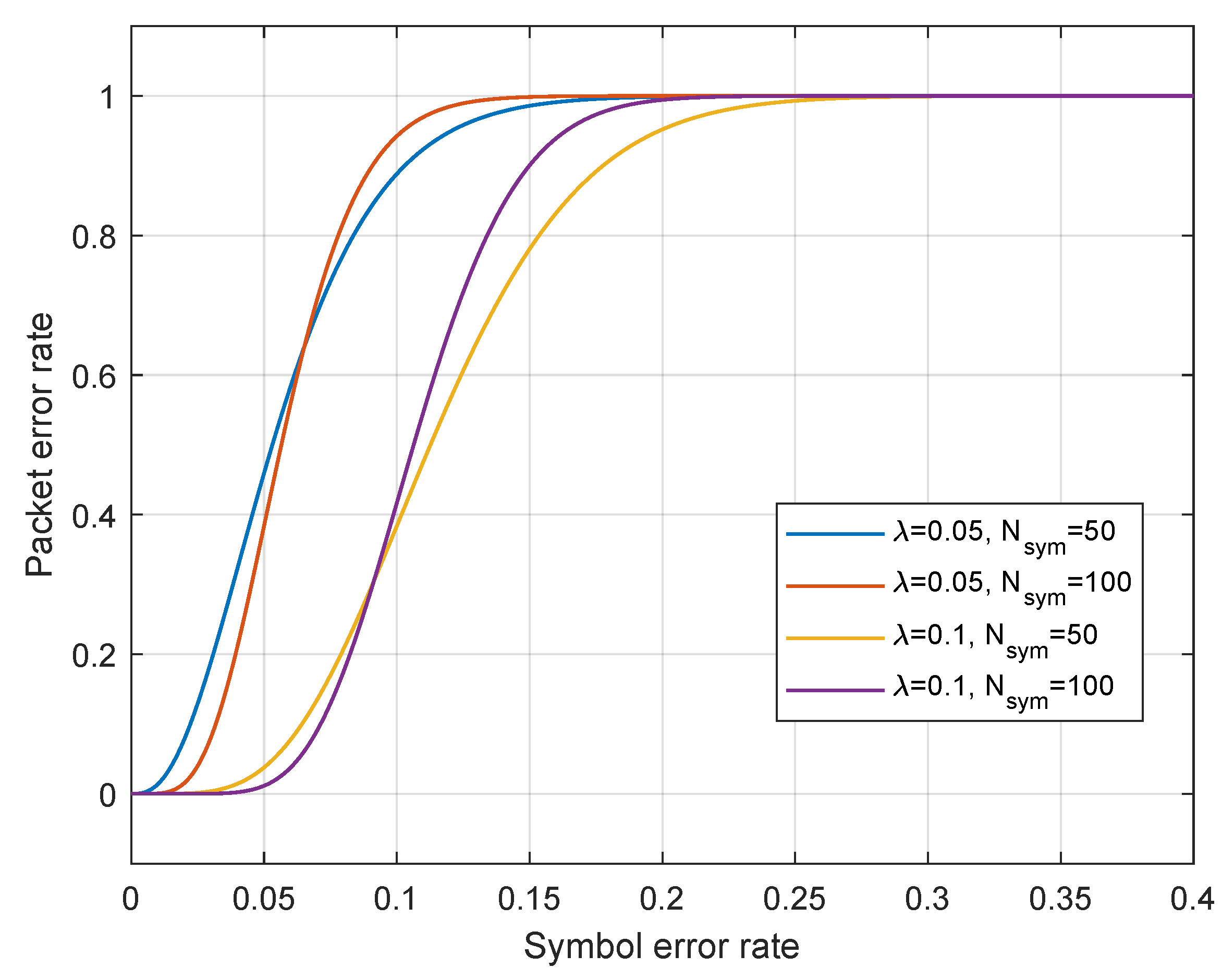
The communication systems possess inherent error correction capabilities and can accommodate a limited number of symbol errors. Assume that the receiver is willing to tolerate a certain level of symbol errors, donated by , and that each packet of data contains symbols, then we can express the relationship between PER and SER as follows:
Figure 3 illustrates the relationship between PER and SER. It can be seen that when is fixed and is changed, the changes in the curve are not significant. However, the change in has a greater influence on the curves. When is fixed and changes from 0.05 to 0.1, the curve shifts to the right overall. The reason is that the parameter represents the error tolerance capability, for the same PER, the PER is mapped to a higher SER due to a higher error tolerance of the system.
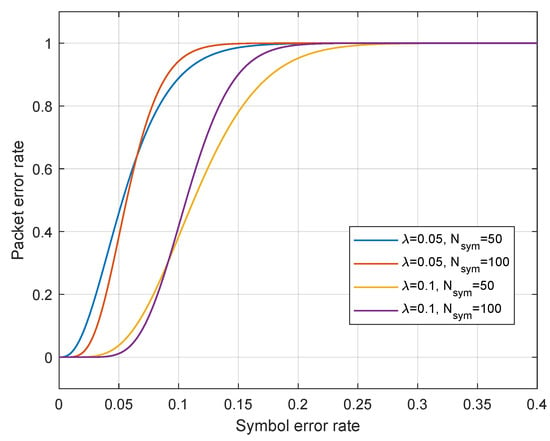
Figure 3.
The relationship between PER and SER.
It is possible to estimate the PER of the receiver as by counting the ACK/NACK messages, and the formula for PER can be expressed as follows:
where and are the number of the ACK and NACK received, respectively. However, it is challenging to calculate the SER directly from the PER according to Equation (22). It is recommended that the value interval of SER be sampled at equal intervals, after which the PER value corresponding to each SER should be calculated in order to obtain the SER-PER table. The PER value that is most proximate to in the SER-PER table should be identified, and its corresponding SER value should be utilized as an approximation of the SER.
In order to calculate the reward for J, it is also necessary to know the maximum utility of the transmitter in the absence of interference. Since the jammer is a tracking jammer, during its detection of wireless communication it can estimate parameters such as the transmission power and communication bands . The maximum transmission gain achieved by the transmitter without being affected by jamming attacks is denoted as . So can be estimated during the detection time as follows:
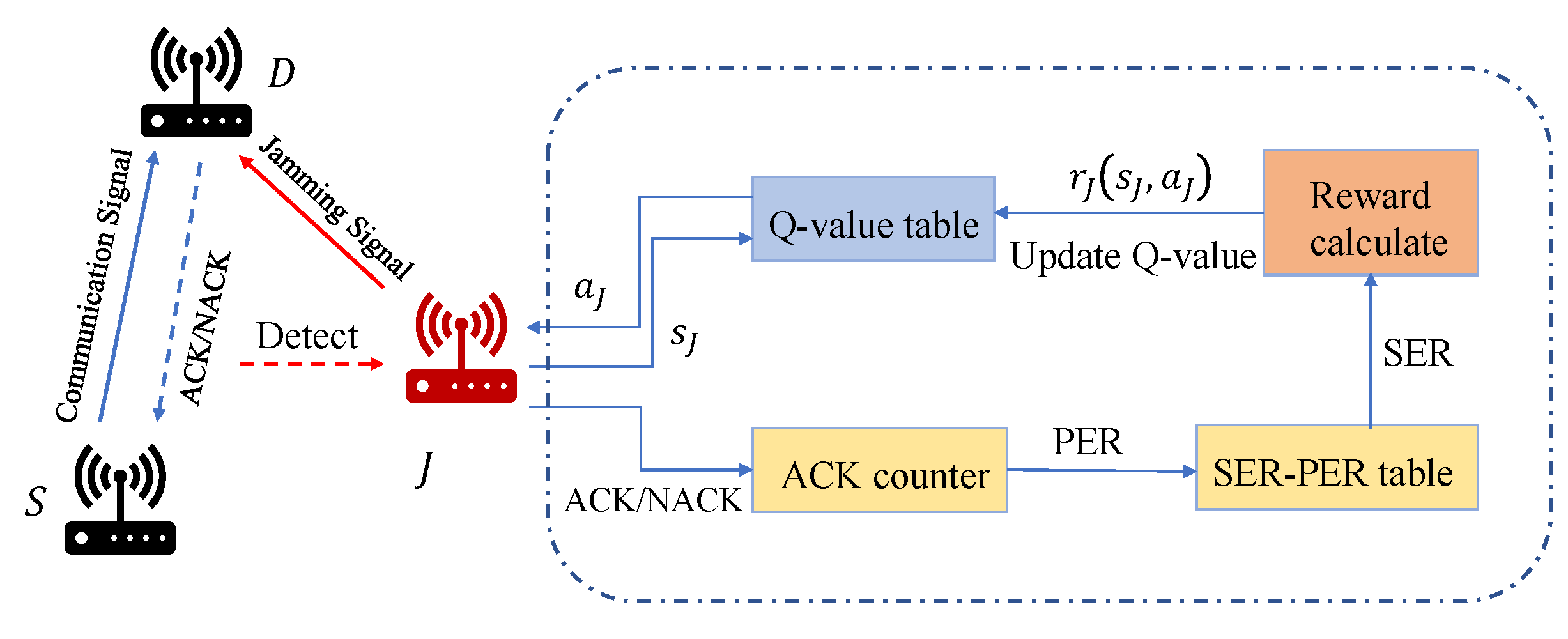
Once J has estimated the SER of D and the maximum utility of S, it is then possible to calculate the current utility of the transmitter according to Equation (20). Figure 4 is a schematic of the jammer’s decision process.
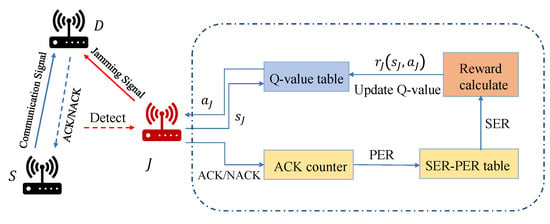
Figure 4.
The schematic of the jammer’s decision process.
5.3. Transmission Decision Model
In this paper, we consider interference against an intelligent transmitter; therefore, the QL algorithm is also used at the transmitter to achieve adaptive tuning of the communication strategy. The MDP of S is denoted as . Similarly, is the state transition probability, which can be obtained by interacting with the environment and the value of will be presented in the simulation section. The definitions of and are given in the following.
- State: S initially identifies the strategy set utilized, then selects an appropriate strategy from . Thus, the state of S is defined as the strategy set utilized by S, i.e.,
- Action: In the game model, the transmitter needs to select a strategy from the strategy set. Thus, the action of S is defined as,
- Reward: The objective is to identify the optimal strategy that maximizes the transmitter’s utility. Consequently, the reward for S is defined as the transmitter’s utility, i.e.,
For the transmitter, the SER can be calculated if the relevant information about the communication link is known, which can be realized easily for Time Division Duplex (TDD) communications due to channel reciprocity.
6. Simulation and Results
6.1. Simulation Setting
Simulations have been conducted in this section to verify the efficacy of the proposed scheme presented in this paper. A total of five transmission strategy sets are utilized at S, as shown in Table 2. The available transmit power and the number of frequency hopping channels for each strategy set are presented in Table 2.
Table 2.
Communication parameters available for each strategy set of S.
The average jamming power available to the jammer is and the optional jamming time ratio is . Additional simulation parameters are provided in Table 3 for reference.
Table 3.
Parameter setting.
6.2. Compared Scheme
To assess the efficacy of the proposed scheme, the following jamming schemes are simulated for comparison.
- PBE: PBE is used as a benchmark for comparison and the solution has been presented in Section 4.
- MAB: A jamming decision method based on the MAB algorithm proposed in [20] is compared as a related work. The jammer continuously interacts with the environment and updates its evaluation of the expected value of each action in real-time.
- Random: Random jamming is a classical jamming scheme where the jammer randomly selects parameters from the set of available parameters with equal probability.
6.3. Simulation Results and Discussions
6.3.1. Scenario of an Intelligent Transmitter
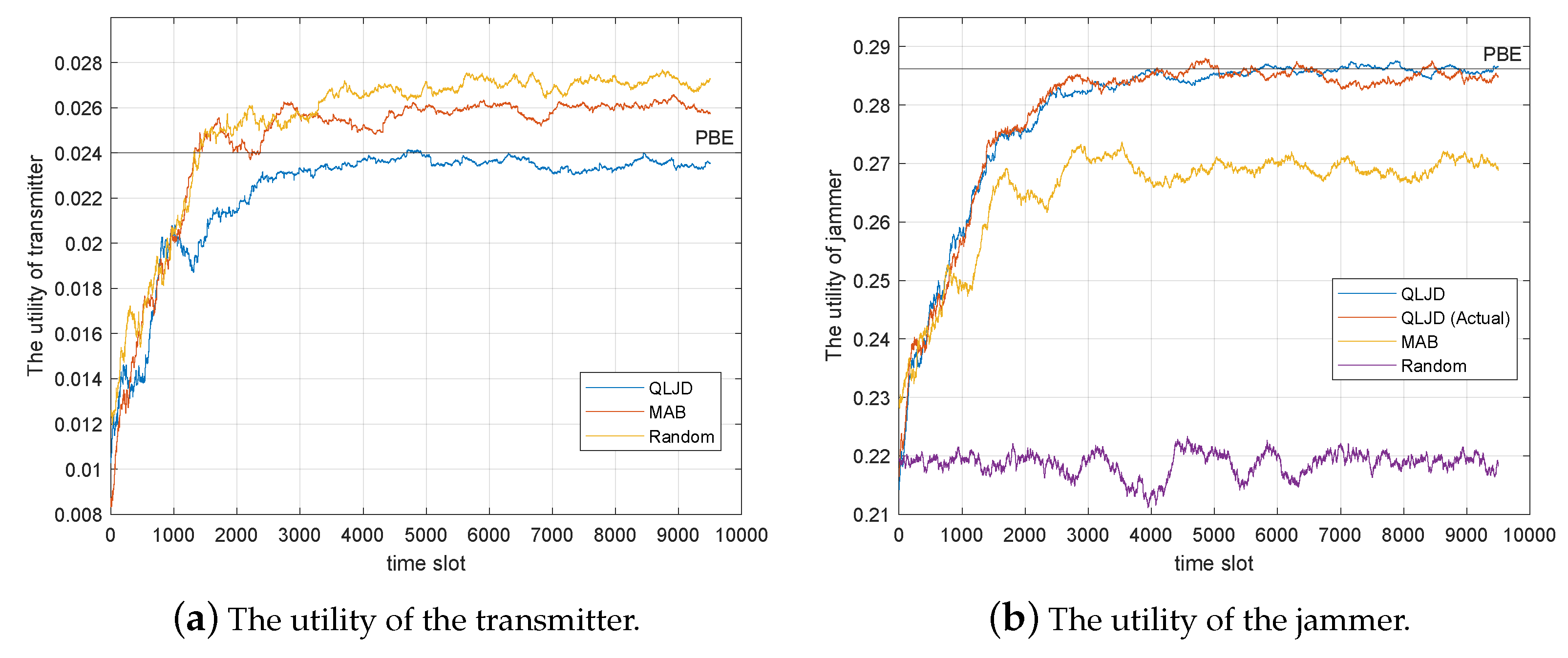
In this subsection, we focus on an intelligent transmitter. The transmitter employs the QL algorithm to identify the optimal strategy for each transmission strategy set, which has been presented in Section 5.3. Figure 5 shows the utilities of S and J, respectively, when S has 2 strategy sets, i.e., 1 and 3 in Table 2. The prior probability of the set 1 and 3 is and , respectively.
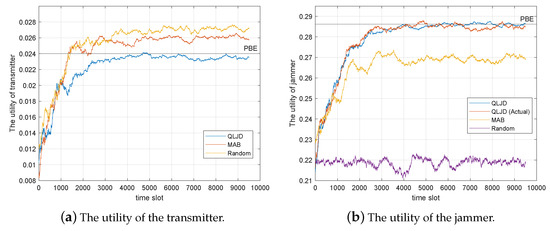
Figure 5.
Performance comparison of jamming schemes when the transmitter has two strategy sets.
In Figure 5, QLJD represents the utility estimated by the A/N-RE algorithm within the context of the QLJD algorithm, while QLJD (Actual) denotes the jamming utility calculated based on the actual SER of D. Apparently, the actual SER of D can not be known by J, thus QLJD (Actual) is a comparison scheme to check the effectiveness of the A/N-RE algorithm. As can be observed, the estimated utility produced by the A/N-RE algorithm and the actual utility exhibit a high degree of similarity, both in terms of value and trend, which implies that the estimation method for the reward is valid. The line represented by PBE is the utility of the PBE strategy. As can be observed, the QLJD ultimately reaches a point of convergence in proximity to the corresponding utility value of PBE. The proposed QLJD scheme exhibits a higher utility than the other compared schemes. The average utility after convergence (calculated over the 5000 to time slots) is , which is only lower than that of the PBE strategy, . In contrast, the MAB and Random schemes demonstrate a decrease of and , respectively, compared to the PBE scheme.
Since the Random scheme does not adjust the jamming strategy based on the wireless transmission, it achieved the worst jamming effect compared to the learning-based schemes, which adaptively adjust the jamming strategies to achieve better jamming utility. As for the learning-based schemes, QLJD and MAB, since MAB only learns the advantages and disadvantages of each jamming strategy during the learning process without considering the changes in the transmission strategy, MAB selects the jamming strategy with a larger utility in the average sense. In QLJD, the current transmission strategy of the transmitter is considered and set as the environmental state in the algorithm, which makes QLJD achieve better utility than MAB when the transmitter adaptively changes its transmission strategy.
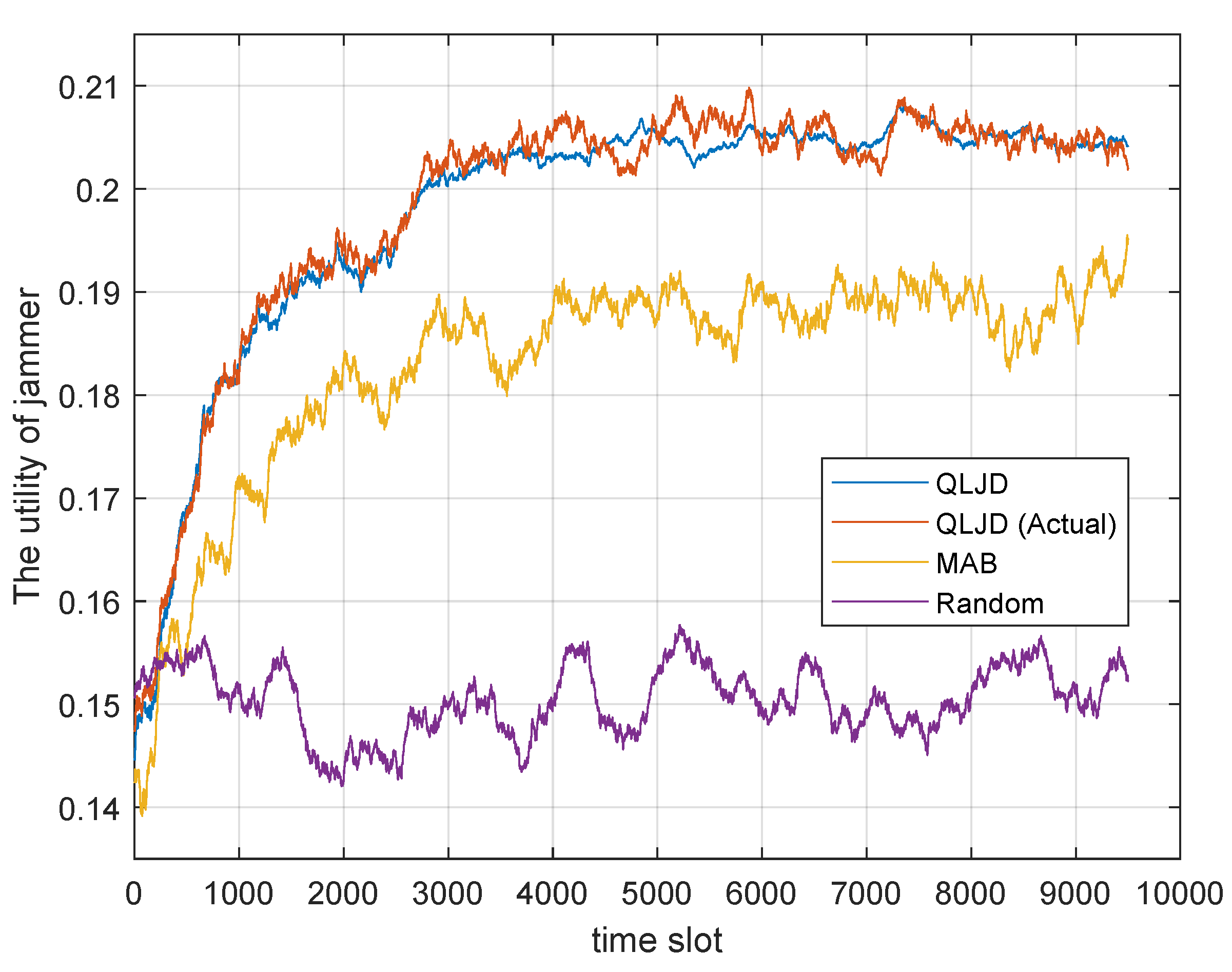
Figure 6 illustrates the performance comparison of various jamming schemes when the transmitter uses all of the strategies sets in Table 2. The corresponding prior probability for each strategy set in Table 2 is , , , , and , respectively.
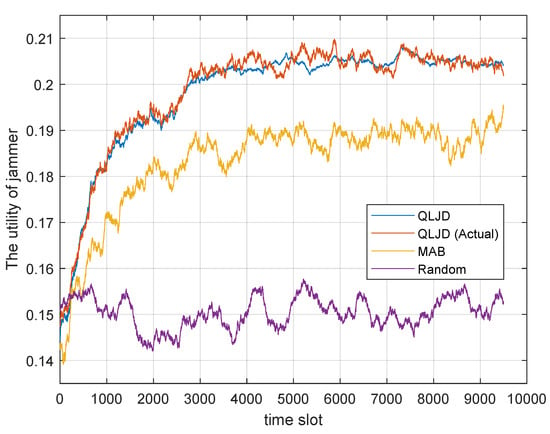
Figure 6.
Performance comparison of jamming schemes when the transmitter has five strategy sets.
Given the five strategy sets, the space of the player strategies is extensive, rendering the solution of the equilibrium strategy challenging. Consequently, only a comparison between QLJD and other jamming schemes is presented in Figure 6. As with Figure 5, the estimated utility QLJD calculated by the A/N-RE algorithm and the actual utility QLJD (Actual) exhibit a high degree of similarity. Furthermore, the utility of the QLJD scheme continues to show a higher utility than other jamming schemes, with an average utility of after convergence. This represents an improvement of over the MAB algorithm and over the Random scheme. The findings indicate that the QLJD scheme exhibits robust universality and maintains effective jamming capabilities when S has more available transmission strategy sets.
The average utility after convergence for each scheme is provided in Table 4. It can be seen that QLJD not only has a higher jamming utility than the other schemes, but the PER caused by the attack is also higher than the other schemes, while it consumes the lowest average power. This indicates that QLJD has better jamming performance and can increase the PER of the receiver while reducing the power cost.
Table 4.
Jamming effect comparisons for an intelligent transmitter.
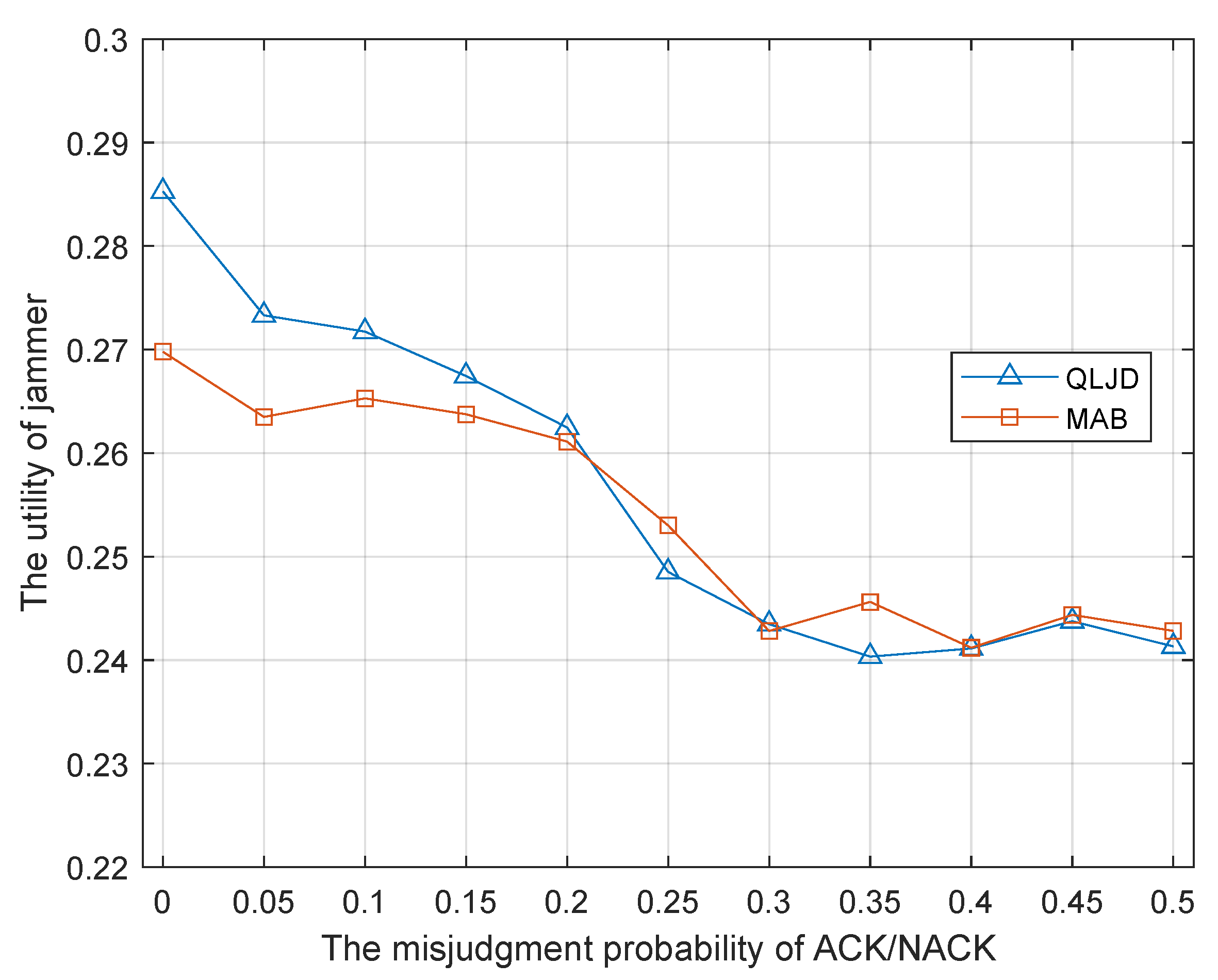
The influence of inaccurate estimation of ACK is considered in the simulations. In the following, we provide the simulation results to discuss the influence of the estimation accuracy of ACK. In the simulation, 1 is sent by the receiver when it decodes the packet correctly, otherwise, it sends 0. It is assumed that the misjudged probability of ACK at the jammer is , which means the jammer detects no ACK as an ACK message has been sent. We conducted simulations when the probability of misjudgment is changing and the results are shown in Figure 7.
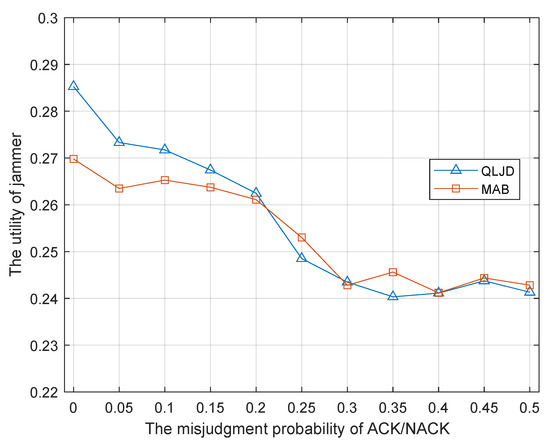
Figure 7.
The performance of QLJD scheme when the jammer’s ACK estimation error.
It can be seen that the best utility of J is achieved when the jammer’s misjudgment probability is 0, which means the jammer is able to acquire the receiver’s ACK information completely and correctly. As the misjudgment probability increases, the jammer’s utility gradually decreases. Inaccurate statistics of ACK result in inaccurate PER and SER, which further result in an inaccurate reward estimation. The jammer’s utility gradually decreases to a floor as the misjudge probability comes to , which means J almost blindly estimates the ACK message as 1 or 0 and it can hardly learn any useful information. We also perform the simulation for the MAB scheme, since the MAB scheme also uses the statistics of the ACK message to estimate the reward. Similar results can be found for the MAB jamming scheme. Therefore, from the simulation results in Figure 7, the estimation of ACK messages can influence the jammer’s utility of the learning-based schemes, which use the statistics of the ACK messages to estimate their rewards.
6.3.2. Scenario of a Strategy-Fixed Transmitter
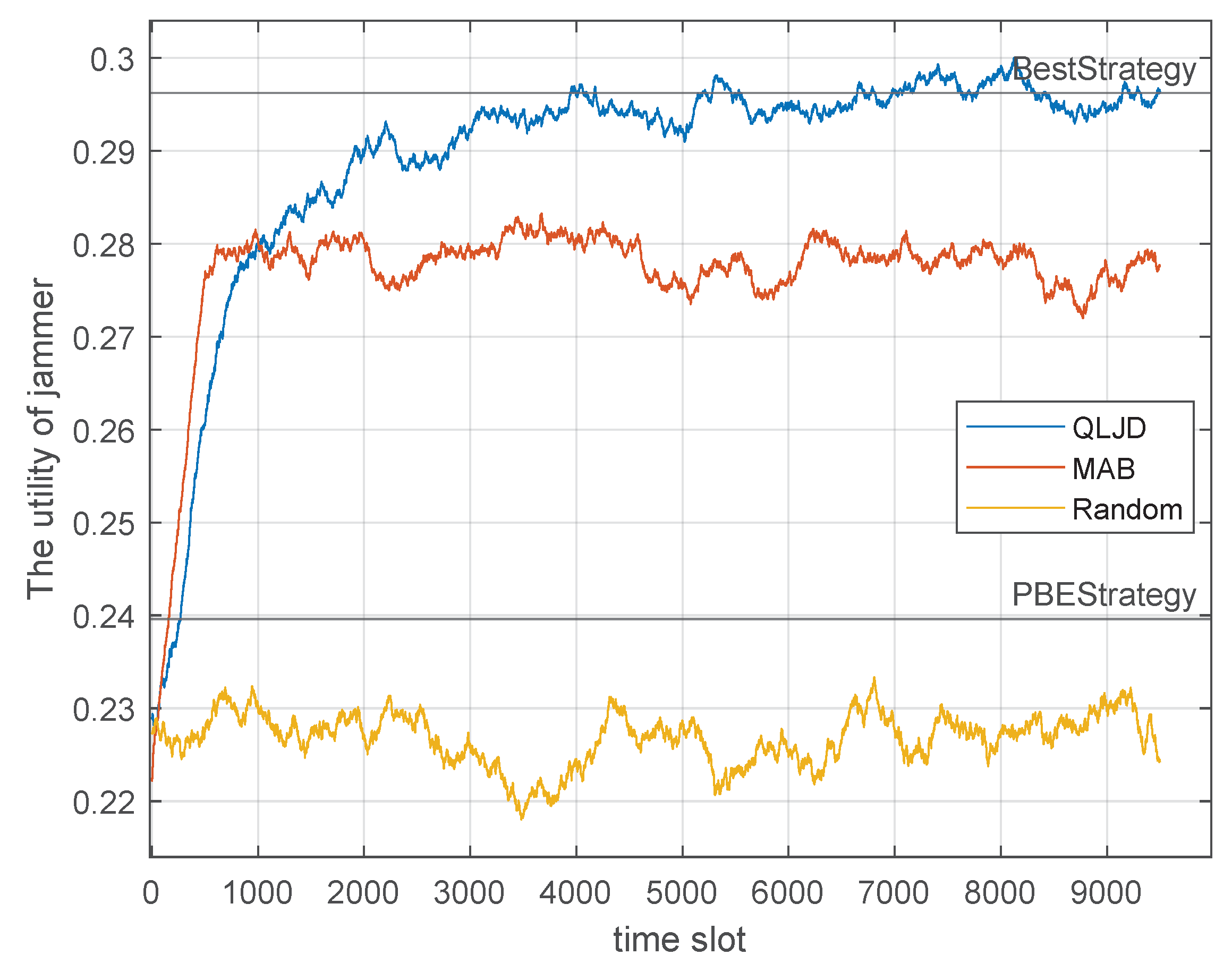
In order to verify the efficacy of the QLJD scheme, we fix the communication strategy to test the performance of QLJD in which the transmit power and the number of hopping channels for each strategy set are predetermined when the transmitter is utilizing strategy sets 1 and 3, with prior probabilities of and , respectively. Figure 8 illustrates the jamming performance of jamming schemes when S uses a fixed transmission strategy.
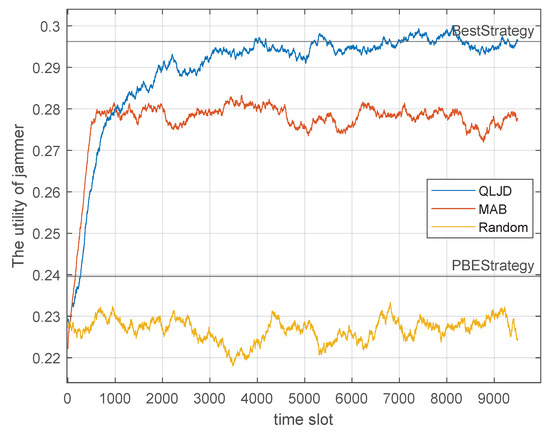
Figure 8.
Performance comparison of jamming schemes for a strategy-fixed transmitter.
The line of BestStrategy is the theoretically optimal jamming strategy, which is calculated according to Equations (13) and (15). The PBEstrategy represents the equilibrium strategy of the jamming confrontation game. As illustrated in Figure 8, the utility of QLJD remains superior to other jamming schemes. After convergence, the jamming utility is , exhibiting a mere discrepancy from that of BestStrategy, . In comparison, MAB and Random exhibit a and decline, respectively. It is evident that PBEStrategy is not performing as optimally as desired. This is due to the fact that game theory assumes that the players are intelligent and rational, the equilibrium strategies of S and J are the strategies they do not want to deviate from; otherwise, their utilities would degrade. However, in the current scenario, for PBEStrategy, which means S uses a fixed strategy while J still sticks to its equilibrium strategy, PBEStrategy cannot achieve the best jamming performance while the transmitter is suboptimal; therefore, the jamming utility becomes worse than the learning-based schemes including QLJD and MAB. QLJD is a model-free algorithm, and it is evident that it continues to demonstrate robust jamming performance. Table 5 illustrates the jamming utility achieved by each jamming scheme after convergence.
Table 5.
Jamming effect comparisons for a strategy-fixed transmitter.
7. Conclusions
In this paper, we consider a jamming scenario where the transmitter has multiple transmission strategy sets and model the behavioral interaction between the the transmitter and the jammer as a dynamic game with incomplete information, while a method for solving PBE is proposed based on the assumption that the maximum utility and SER information of the transmitter are available. However, due to the non-cooperative nature between the transmitter and the jammer, we propose a QL-based jamming decision method to learn intelligent jamming strategies using only the sensing results about the transmitter. An estimation method based on ACK/NACK information is designed to calculate the jammer’s reward. Compared to the benchmark of PBE, the proposed QLJD scheme has only a decrease in utility value after convergence. Compared with other jamming schemes, the proposed QLJD scheme is able to find an intelligent strategy that reduces the average power of the jammer while increasing the PER of the receiver. From the simulation results, we find out that when the transmitter is suboptimal, sticking to PBE cannot achieve the best jamming performance, and the proposed QLJD scheme finds a better jamming strategy than PBE. The inaccurate estimation of ACK will degrade the jamming performance of QLJD. It is our future work to develop more practical jamming schemes for static and dynamic networks.
Author Contributions
Conceptualization, Y.L.; methodology, Z.G. and J.W.; software simulation, J.W.; analysis and validation, J.W. and Z.G.; writing—original draft preparation, J.W. and Z.G.; writing—review and editing, Y.L. and G.L.; visualization, Y.L. and J.W.; supervision, Z.G.; project administration, Y.L.; funding acquisition, Z.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Open Research Found of Complex Electromagnetic Environment Effects on Electronics and Information System (CEMEE) under Grant 2023K0201 and by the National Natural Science Foundation of China under Grant 62071367.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Due to institutional data privacy requirements, our data are unavailable.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| CSI | Channel state information |
| SINR | Signal to interference plus noise power ratio |
| UAV | Unmanned aerial vehicle |
| RL | Reinforcement learning |
| QL | Q-learning |
| DQN | Deep-Q-network |
| PBE | Perfect Bayesian equilibrium |
| ACK/NACK | Acknowledgement/Negative Acknowledgement |
| PER | Packet error rate |
| MAB | Multi-armed bandits |
| QPSK | Quadrature phase-shift keying |
| SER | Symbol error rate |
| NE | Nash equilibrium |
| MDP | Markov decision process |
| QLJD | QL-based jamming decision |
| TCP/IP | Transmission Control Protocol/Internet Protocol |
| A/N-RE | ACK/NACK-based reward estimation method |
| TDD | Time division duplex |
References
- Liu, L.; Wang, B.; Hou, W. Game Decision Modeling of Communication Electronic Jamming Pattern Selection. J. Detect. Control 2021, 43, 71–80. [Google Scholar]
- Pei, L.; Liu, H.; Liu, K. A Jamming Scheme Decision Method Based on Artificial Bee Colony Algorithm. Fire Control Command Control 2024, 1–6. [Google Scholar]
- Bayram, S.; Vanli, N.D.; Dulek, B.; Sezer, I.; Gezici, S. Optimum Power Allocation for Average Power Constrained Jammers in the Presence of Non-Gaussian Noise. IEEE Commun. Lett. 2012, 16, 1153–1156. [Google Scholar] [CrossRef]
- Amuru, S.; Buehrer, R.M. Optimal jamming strategies in digital communications—Impact of modulation. In Proceedings of the 2014 IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014; pp. 1619–1624. [Google Scholar] [CrossRef]
- Xiao, L.; Ding, Y.; Huang, J.; Liu, S.; Tang, Y.; Dai, H. UAV Anti-Jamming Video Transmissions with QoE Guarantee: A Reinforcement Learning-Based Approach. IEEE Trans. Commun. 2021, 69, 5933–5947. [Google Scholar] [CrossRef]
- Sagduyu, Y.E.; Berry, R.A.; Ephremides, A. Jamming games in wireless networks with incomplete information. IEEE Commun. Mag. 2011, 49, 112–118. [Google Scholar] [CrossRef]
- Xiao, L.; Liu, J.; Li, Q.; Mandayam, N.B.; Poor, H.V. User-Centric View of Jamming Games in Cognitive Radio Networks. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2578–2590. [Google Scholar] [CrossRef]
- Dabcevic, K.; Betancourt, A.; Marcenaro, L.; Regazzoni, C.S. A fictitious play-based game-theoretical approach to alleviating jamming attacks for cognitive radios. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 8158–8162. [Google Scholar] [CrossRef]
- Gao, Y.; Xiao, Y.; Wu, M.; Xiao, M.; Shao, J. Game Theory-Based Anti-Jamming Strategies for Frequency Hopping Wireless Communications. IEEE Trans. Wireless Commun. 2018, 17, 5314–5326. [Google Scholar] [CrossRef]
- Firouzbakht, K.; Noubir, G.; Salehi, M. Linearly Constrained Bimatrix Games in Wireless Communications. IEEE Trans. Commun. 2016, 64, 429–440. [Google Scholar] [CrossRef]
- Garnaev, A.; Trappe, W.; Petropulu, A. Combating Jamming in Wireless Networks: A Bayesian Game with Jammer’s Channel Uncertainty. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2447–2451. [Google Scholar] [CrossRef]
- Qi, N.; Wang, W.; Zhou, F.; Jia, L.; Wu, Q.; Jin, S.; Xiao, M. Two Birds with One Stone: Simultaneous Jamming and Eavesdropping with the Bayesian–Stackelberg Game. IEEE Trans. Commun. 2021, 69, 8013–8027. [Google Scholar] [CrossRef]
- Luo, S.; Liu, X. UAV Intelligent Approach Jamming Wireless Communication System. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 24–26 February 2023; pp. 427–432. [Google Scholar] [CrossRef]
- Rao, N.; Xu, H.; Song, B. An Intelligent Jamming Decision Algorithm Based on Action Elimination Dueling Double Deep Q Network. J. Air Force Eng. Univ. Natural Sci. Ed. 2021, 22, 92–98. [Google Scholar]
- Li, Y.; Miao, W.; Gao, Z.; Lv, G. Intelligent Jamming Strategy for Wireless Communications Based on Game Theory. IEEE Access 2024, 12, 110064–110077. [Google Scholar] [CrossRef]
- Amuru, S.; Buehrer, R.M. Optimal Jamming Against Digital Modulation. IEEE Trans. Inf. Forensics Secur. 2015, 10, 2212–2224. [Google Scholar] [CrossRef]
- Wu, N.; Zhou, X.; Sun, M. Multi-Channel Jamming Attacks against Cooperative Defense: A Two-Level Stackelberg Game Approach. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, H.; Song, B.; Jiang, L.; Rao, N.; Shi, Y. An Intelligent Decision-making Algorithm for Communication Countermeasure Jamming Resource Allocation. J. Electron. Inf. Technol. 2021, 43, 3086–3095. [Google Scholar] [CrossRef]
- Shi, Y.; Sagduyu, Y.E.; Erpek, T.; Davaslioglu, K.; Lu, Z.; Li, J.H. Adversarial Deep Learning for Cognitive Radio Security: Jamming Attack and Defense Strategies. In Proceedings of the 2018 IEEE International Conference on Communications Workshops (ICC Workshops), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Amuru, S.; Tekin, C.; van der Schaar, M.; Buehrer, R.M. Jamming Bandits—A Novel Learning Method for Optimal Jamming. IEEE Trans. Wireless Commun. 2016, 15, 2792–2808. [Google Scholar] [CrossRef]
- Im, H.S.; Lee, S.H. Anti-Jamming Games in Multi-Band Wireless Ad Hoc Networks. IEEE Trans. Inf. Forensics Secur. 2023, 18, 872–887. [Google Scholar] [CrossRef]
- Jia, L.; Yao, F.; Sun, Y.; Niu, Y.; Zhu, Y. Bayesian Stackelberg Game for Antijamming Transmission with Incomplete Information. IEEE Commun. Lett. 2016, 20, 1991–1994. [Google Scholar] [CrossRef]
- Xu, Y.; Xu, Y.; Ren, G.; Chen, J.; Yao, C.; Jia, L.; Liu, D.; Wang, X. Play it by Ear: Context-Aware Distributed Coordinated Anti-Jamming Channel Access. IEEE Trans. Inf. Forensics Secur. 2021, 16, 5279–5293. [Google Scholar] [CrossRef]
- Sun, Y.; Zhu, Y.; An, K.; Zheng, G.; Chatzinotas, S.; Wong, K.K.; Liu, P. Robust Design for RIS-Assisted Anti-Jamming Communications with Imperfect Angular Information: A Game-Theoretic Perspective. IEEE Trans. Veh. Technol. 2022, 71, 7967–7972. [Google Scholar] [CrossRef]
- Feng, L.W.; Liu, S.T.; Xu, H.Z. Multifunctional Radar Cognitive Jamming Decision Based on Dueling Double Deep Q-Network. IEEE Access 2022, 10, 112150–112157. [Google Scholar] [CrossRef]
- Xing, Q.; Jia, X.; Zhu, W. Intelligent radar countermeasure based on Q-learning. Syst. Eng. Electron. 2018, 40, 1031–1035. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, D.; Li, N.; Min, L.; Guo, Z. Two-Dimensional Precise Controllable Smart Jamming Against SAR via Phase Errors Modulation of Transmitted Signal. Syst. Eng. Electron. 2024, 21, 1–5. [Google Scholar] [CrossRef]
- Li, Y.; Xiao, L.; Liu, J.; Tang, Y. Power control Stackelberg game in cooperative anti-jamming communications. In Proceedings of the 2014 5th International Conference on Game Theory for Networks, Beijing, China, 25–27 November 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Noori, H.; Vilni, S.S. Defense Against Intelligent Jammer in Cognitive Wireless Networks. In Proceedings of the 2019 27th Iranian Conference on Electrical Engineering (ICEE), Yazd, Iran, 30 April–2 May 2019; pp. 1309–1314. [Google Scholar] [CrossRef]
- Garnaev, A.; Petropulu, A.; Trappe, W.; Poor, H.V. A Multi-Jammer Game with Latency as the User’s Communication Utility. IEEE Commun. Lett. 2020, 24, 1899–1903. [Google Scholar] [CrossRef]
- Madhow, U. Fundamentals of Digital Communication; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Fudenberg, D.; Tirole, J. Game Theory; MIT Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Gibbons, R. A Primer in Game Theory; Harverter Wheatsheaf: Birmingham, UK, 1992. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning, Second Edition: An Introduction; Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).