
A Stealthy Communication Model for Protecting Aggregated Results Integrity in Federated Learning

Abstract
:1. Introduction
- We designed a covert communication scheme based on FL, applying covert communication to FL for the first time, which enhance the integrity of aggregated results in privacy-preserving FL frameworks based on HE.
- We introduce chaotic sequence technology to enhance the anti-detection ability of covert communication. This technology improves the concealment of the communication channel, making it more difficult for attackers to detect embedded information.
- The embedding approach suggested in this study provides strong concealment and large channel capacity, as demonstrated by our experimental results.
2. Preliminaries
2.1. Federated Learning
2.2. Paillier Encryption Algorithm
- Key Generation: To generate keys for the Paillier encryption algorithm, select two large prime numbers, and , and compute . Calculate , where l cm denotes the least common multiple. Choose an integer such that ensuring that has an order multiple of Compute where . The public key is , and the private key is .
- Encryption: Given a plaintext , where ), choose a random integer where ). Compute the ciphertext using the formula .
- Decryption: Given a ciphertext , compute the plaintextusing the formula .
- Homomorphic Addition: For two ciphertexts, and , the decryption of their product corresponds to the sum of their respective plaintexts. The formula is given by Formula (1):
- Homomorphic Addition (encrypted message and plaintext integer): Encrypt a message and then multiply this encrypted result with . Decrypting this product will yield the sum of and . The formula is given by Formula (2):
- Homomorphic Scalar Multiplication: For a ciphertext and a plaintext number , the decryption of the ciphertext raised to the power of corresponds to the plaintext multiplied by . The formula is given by Formula (3):
2.3. Chaotic Sequences
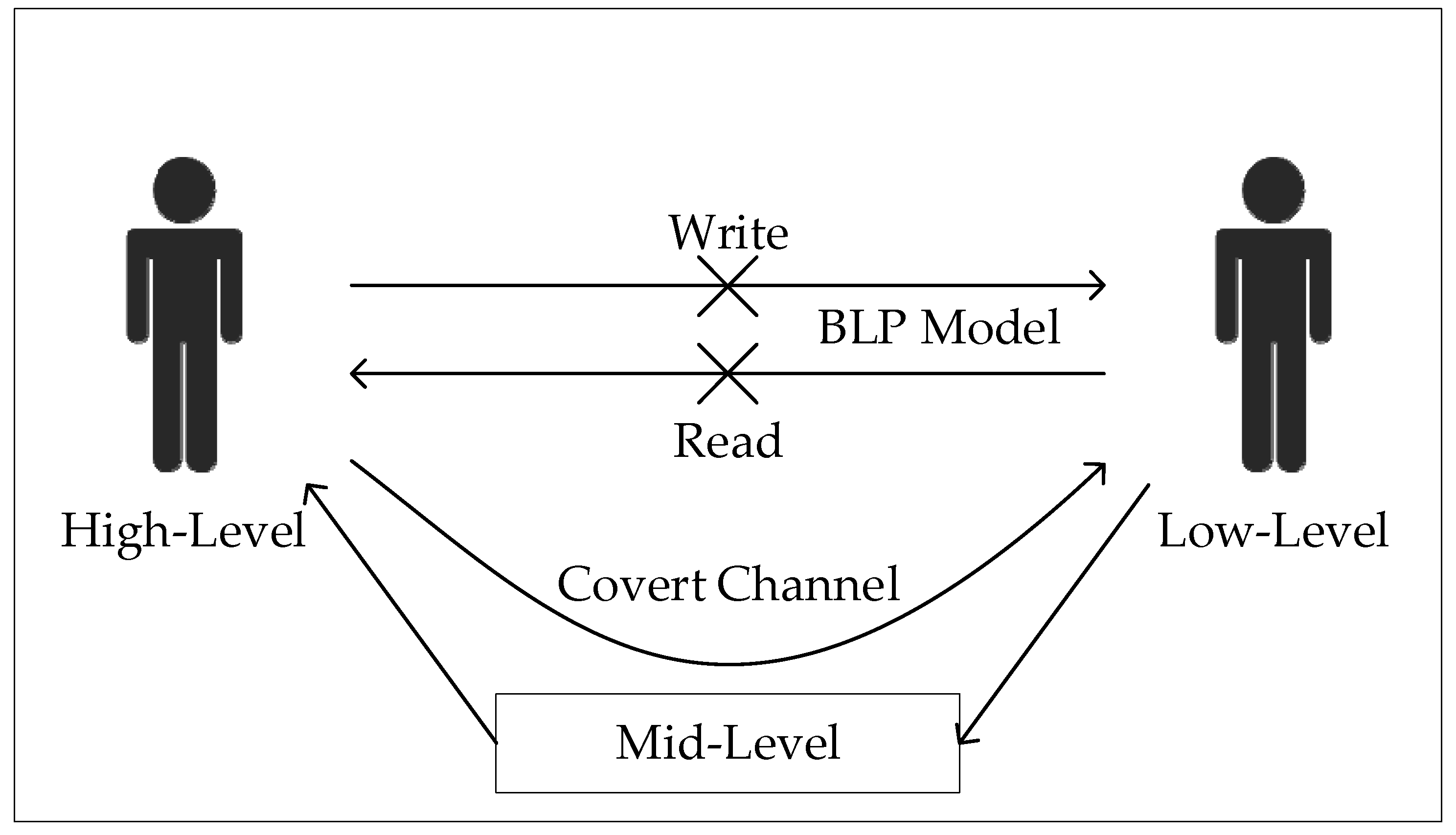
2.4. Covert Channel
3. System Design
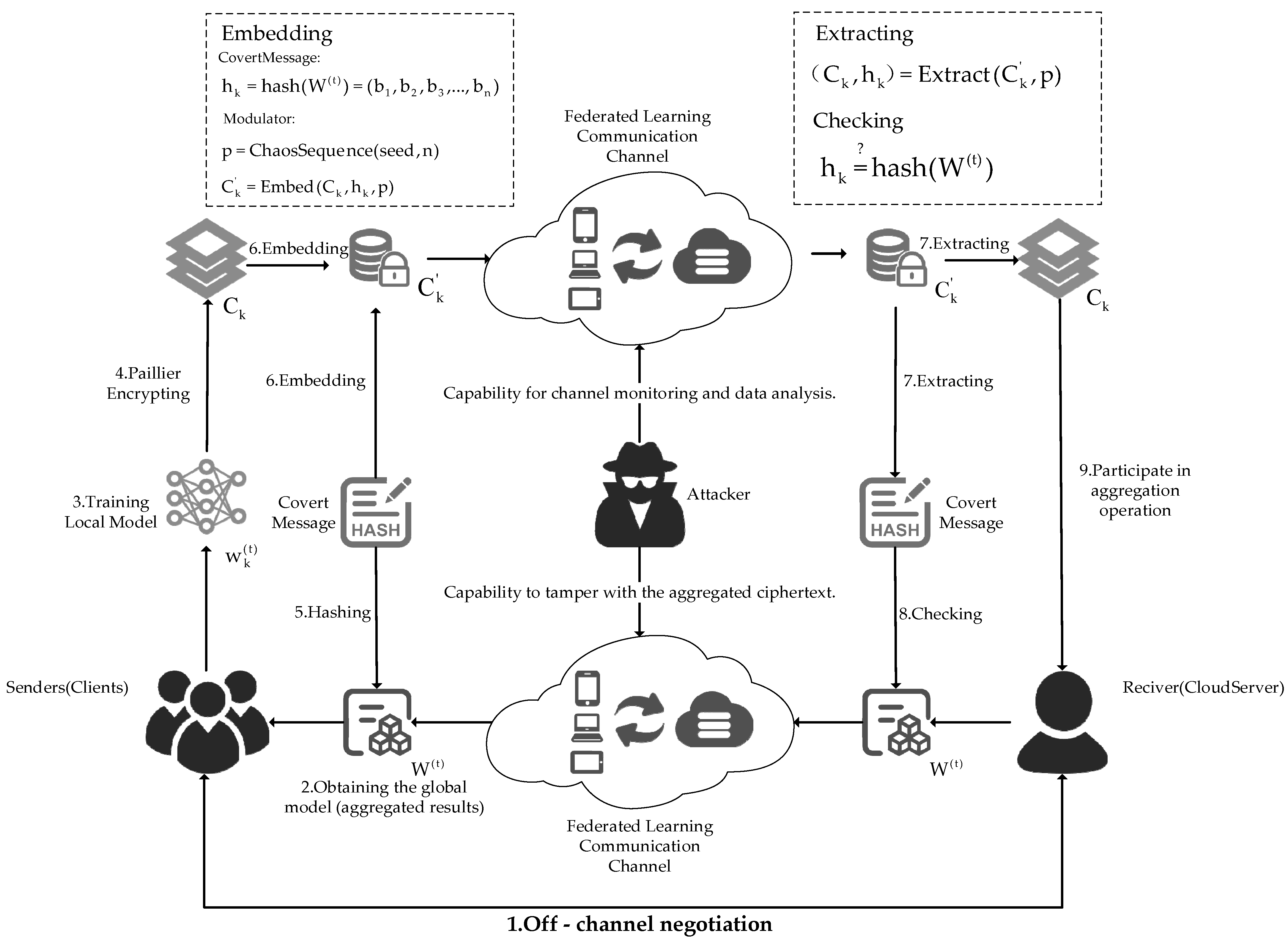
3.1. System Model
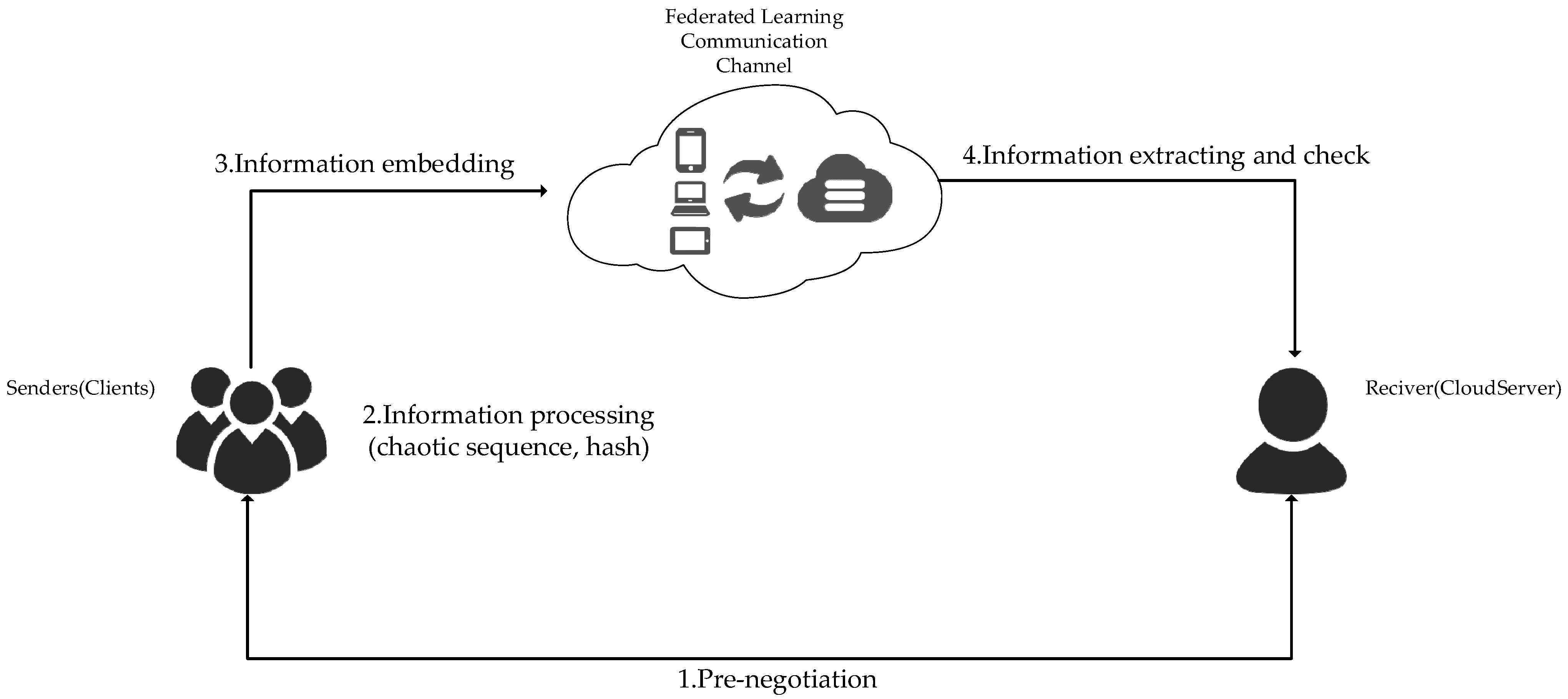
- Off-channel negotiation: In this approach, pre-chain negotiations are carried out off-channel by the sender and the recipient using email, in-person meetings, or other means of contact. The pre-negotiation content includes coding rules for hidden information, embedding location (chaotic sequence ) and mode selection.
- Obtaining the global model (aggregated results): Obtain the ciphertext of the global model from the FL communication channel in the-th round. The obtained ciphertext may have been tampered with by an attacker but can still be decrypted normally.
- Training local model: The sender (client) will use the local dataset and global model for local model training.
- Paillier encrypting: The sender (client) will use the Paillier HE algorithm to encrypt the local model parameters to be uploaded, resulting in encrypted ciphertext .
- Hashing: The sender (client) will perform a hash signature operation on the ciphertext to obtain a hash value of the global model , which is also the covert information to be transmitted.
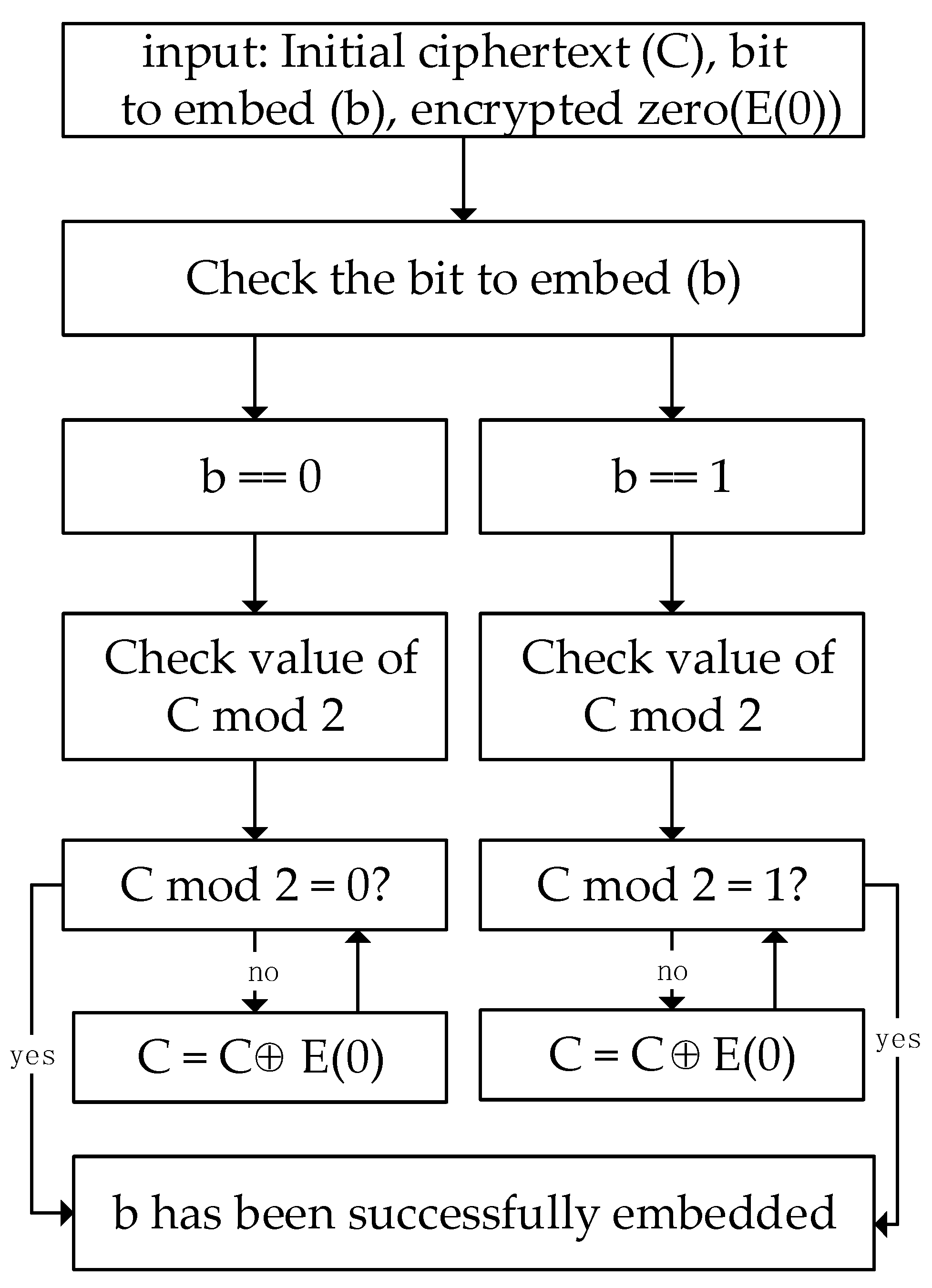
- Embedding: The sender (client) will select the insertion position using chaos sequence and embed the binary sequence corresponding to the hash value into the ciphertext through the homomorphic additive property of the HE ciphertext . This results in a ciphertext that contains the embedded secret information, which is then transmitted through the FL communication channel. Figure 4 illustrates how each covert information bit is embedded into the parameter ciphertext.
- Extracting: When the receiver (cloud server) obtains the ciphertext with the embedded secret information from the FL communication channel, it extracts the covert information based on the embedding location generated by the chaotic sequence and retrieves the original ciphertext .
- Checking: The receiver (cloud server) uses the obtained covert information to verify the global model and check whether its integrity has been compromised.
- Participate in aggregation operation: If the global model received by the sender passes verification and proves it has not been tampered with, the cloud server will include it in the normal aggregation operations; if the global model fails verification, it will not be included in the normal aggregation operations.
3.2. Threat Model
- The adversary has sophisticated capabilities for data processing and surveillance. The adversary can examine every bit of data sent in order to identify the hidden channel. The adversary possesses the public key used for HE and can perform homomorphic addition operations on the ciphertext of the transmitted aggregated results, thereby tampering with the data and compromising its integrity.
- The adversary knows all the implementation details of our proposed scheme.
- When the adversary detects the presence of hidden information in the upload channel through monitoring and analysis (only detection is required, without needing to know the specific content of the secret information), they will forcibly shut down the upload channel, thereby disrupting the covert channel.
- The adversary is able to observe and examine the upload channel of the local model, but it is unable to impede it. The adversary cannot know the pre-agreed content in the scheme.
3.3. Design Goals
- High concealment: Concealment makes the covert channel untraceable by ensuring an attacker cannot tell hidden information from regular data. High concealment in the proposed framework refers to the inability of the threat model to distinguish between plain text and ciphertext carrying hidden information. This ensures that covert communications remain undetected by adversaries.
- High channel capacity: The amount of covert information sent via a covert channel in a given amount of time is referred to as its channel capacity. Massive volumes of clandestine data transmission require a high channel capacity. In the proposed model, it means the ability to transmit more robust hash values generated by hash operations. Generally, the larger the capacity of the hash value, the better its collision resistance, thereby enhancing the effectiveness of ensuring the integrity of the ciphertext during the FL process [31].
- Strong robustness: The robustness of the proposed scheme is defined as the ability to effectively detect tampering of the global model by an adversary. In this scheme, the hash value of the global model is transmitted to the server as secret information. Upon receiving the model parameters returned by the clients, the server extracts the embedded hash value and compares it with the recalculated hash value. If the hash values match, it indicates that the global model has not been tampered with; otherwise, it is considered tampered.
4. Proposed Scheme
4.1. Symbol
4.2. Pre-Negotiate
4.3. Information Processing
| Algorithm 1: Chaotic Sequence Position Selection |
| input: output: 1: Initialize as an empty list 2: Initialize a set to keep track of used positions 3: 4: 5: while do 6: 7: 8: if then 9: Append to 10: Add to U 11: end if 12: 13: end while 14: return |
4.4. Information Embedding
| Algorithm 2: The Covert Channel Information Embedding |
| input: output: 1: Initialization = 1 2: for to do 3: 4: if then 5: if then 6: 7: 8: break 9: else 10: 11: if then 12: 13: 14: break 15: else 16: continue 17: end if 18: end if 19: else 20: if then 21: 22: 23: break 24: else 25: 26: if then 27: 28: 29: break 30: else 31: continue 32: end if 33: end if 34: end if 35: end for |
4.5. Information Extracting and Check
5. System Implementation and Evaluation
5.1. Implementation
5.2. Concealment
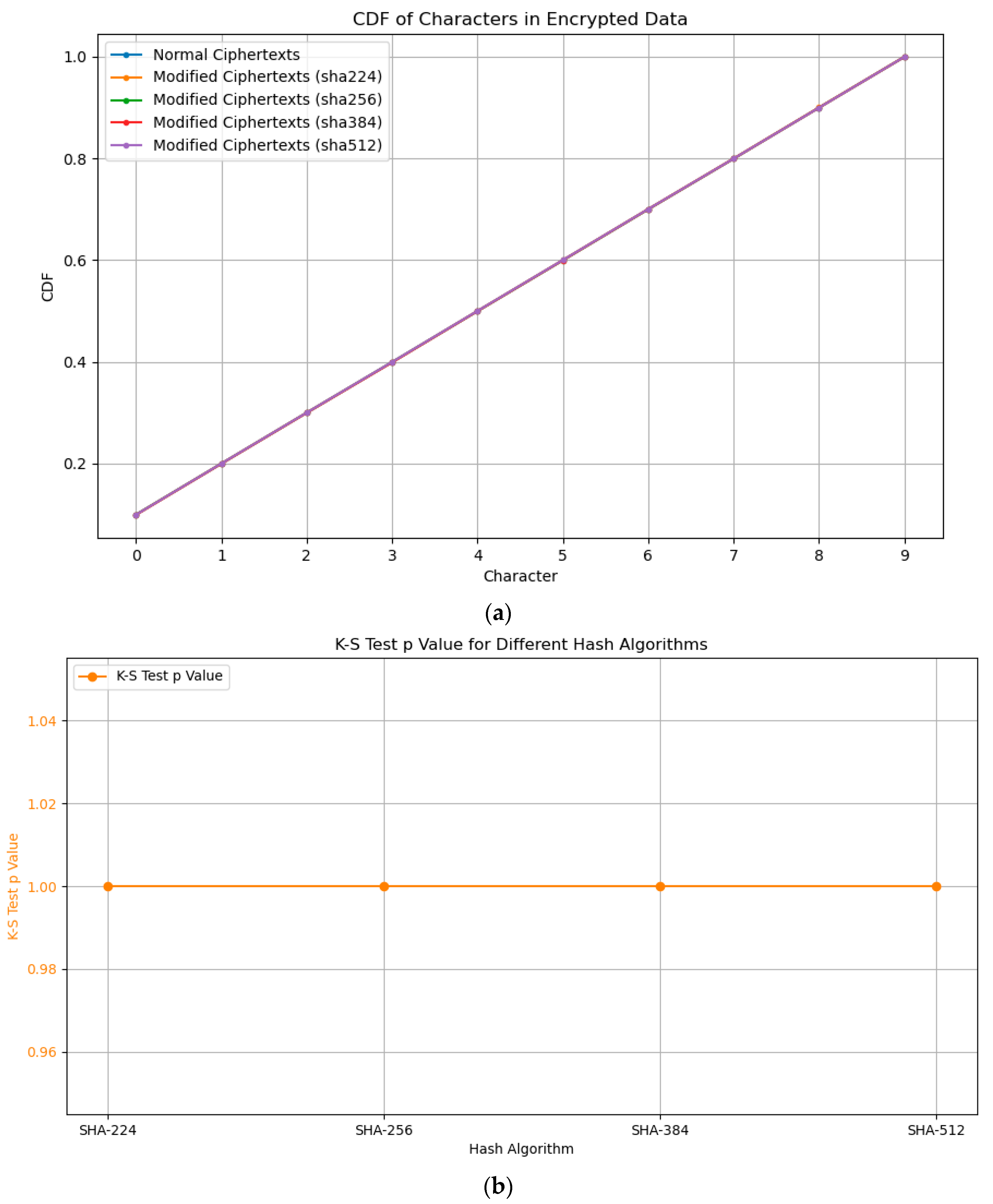
5.2.1. K–S Test and K–L Divergence
5.2.2. Welch’s T-Test
5.3. Channel Capacity
5.4. Performance Comparison before and after Scheme Implementation
6. Related Works
7. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Kang, Y.; Zou, T.; Pu, Y.; He, Y.; Ye, X.; Ouyang, Y.; Zhang, Y.-Q.; Yang, Q. Vertical federated learning: Concepts, advances, and challenges. IEEE Trans. Knowl. Data Eng. 2024, 36, 3615–3634. [Google Scholar] [CrossRef]
- Zhang, X.; Chang, Z.; Hu, T.; Chen, W.; Zhang, X.; Min, G. Vehicle selection and resource allocation for federated learning-assisted vehicular network. IEEE Trans. Mob. Comput. 2023, 23, 3817–3829. [Google Scholar] [CrossRef]
- Rauniyar, A.; Hagos, D.H.; Jha, D.; Håkegård, J.E.; Bagci, U.; Rawat, D.B.; Vlassov, V. Federated learning for medical applications: A taxonomy, current trends, challenges, and future research directions. IEEE Internet Things J. 2023, 11, 7374–7398. [Google Scholar] [CrossRef]
- Jithish, J.; Alangot, B.; Mahalingam, N.; Yeo, K.S. Distributed anomaly detection in smart grids: A federated learning-based approach. IEEE Access 2023, 11, 7157–7179. [Google Scholar] [CrossRef]
- Pandya, S.; Srivastava, G.; Jhaveri, R.; Babu, M.R.; Bhattacharya, S.; Maddikunta, P.K.R.; Mastorakis, S.; Piran, M.J.; Gadekallu, T.R. Federated learning for smart cities: A comprehensive survey. Sustain. Energy Technol. Assess. 2023, 55, 102987. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Cui, H.; Tang, Z.; Li, Y. A review of homomorphic encryption for privacy-preserving biometrics. Sensors 2023, 23, 3566. [Google Scholar] [CrossRef]
- Hu, H.; Zhang, X.; Salcic, Z.; Sun, L.; Choo, K.-K.R.; Dobbie, G. Source inference attacks: Beyond membership inference attacks in federated learning. IEEE Trans. Dependable Secur. Comput. 2023, 21, 3012–3029. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Yin, H.; Molchanov, P.; Myronenko, A.; Li, W.; Dogra, P.; Feng, A.; Flores, M.G.; Kautz, J.; Xu, D. Do gradient inversion attacks make federated learning unsafe? IEEE Trans. Med. Imaging 2023, 42, 2044–2056. [Google Scholar] [CrossRef]
- Wu, R.; Chen, X.; Guo, C.; Weinberger, K.Q. Learning to invert: Simple adaptive attacks for gradient inversion in federated learning. In Proceedings of the Uncertainty in Artificial Intelligence, Pittsburgh, PA, USA, 31 July–4 August 2023; pp. 2293–2303. [Google Scholar]
- Zhang, J.; Liu, Y.; Wu, D.; Lou, S.; Chen, B.; Yu, S. VPFL: A verifiable privacy-preserving federated learning scheme for edge computing systems. Digit. Commun. Netw. 2023, 9, 981–989. [Google Scholar] [CrossRef]
- Wang, Z.; Song, M.; Zhang, Z.; Song, Y.; Wang, Q.; Qi, H. Beyond inferring class representatives: User-level privacy leakage from federated learning. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 9 April–2 May 2019; pp. 2512–2520. [Google Scholar]
- Yin, X.; Zhu, Y.; Hu, J. A comprehensive survey of privacy-preserving federated learning: A taxonomy, review, and future directions. ACM Comput. Surv. (CSUR) 2021, 54, 1–36. [Google Scholar] [CrossRef]
- Gong, X.; Sharma, A.; Karanam, S.; Wu, Z.; Chen, T.; Doermann, D.; Innanje, A. Ensemble attention distillation for privacy-preserving federated learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15076–15086. [Google Scholar]
- Zhang, Z.; Guan, C.; Chen, H.; Yang, X.; Gong, W.; Yang, A. Adaptive privacy-preserving federated learning for fault diagnosis in internet of ships. IEEE Internet Things J. 2021, 9, 6844–6854. [Google Scholar] [CrossRef]
- Liu, C.; Chakraborty, S.; Verma, D. Secure model fusion for distributed learning using partial homomorphic encryption. In Policy-Based Autonomic Data Governance; Springer: Cham, Switzerland, 2019; pp. 154–179. [Google Scholar]
- Hijazi, N.M.; Aloqaily, M.; Guizani, M.; Ouni, B.; Karray, F. Secure federated learning with fully homomorphic encryption for iot communications. IEEE Internet Things J. 2023, 11, 4289–4300. [Google Scholar] [CrossRef]
- Du, W.; Li, M.; Han, Y.; Wang, X.A.; Wei, Z. A Homomorphic Signcryption-Based Privacy Preserving Federated Learning Framework for IoTs. Secur. Commun. Netw. 2022, 2022, 8380239. [Google Scholar] [CrossRef]
- He, C.; Liu, G.; Guo, S.; Yang, Y. Privacy-preserving and low-latency federated learning in edge computing. IEEE Internet Things J. 2022, 9, 20149–20159. [Google Scholar] [CrossRef]
- So, J.; Ali, R.E.; Güler, B.; Jiao, J.; Avestimehr, A.S. Securing secure aggregation: Mitigating multi-round privacy leakage in federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 9864–9873. [Google Scholar]
- Liang, C.; Tan, Y.-a.; Zhang, X.; Wang, X.; Zheng, J.; Zhang, Q. Building packet length covert channel over mobile VoIP traffics. J. Netw. Comput. Appl. 2018, 118, 144–153. [Google Scholar] [CrossRef]
- Tan, Y.-a.; Zhang, X.; Sharif, K.; Liang, C.; Zhang, Q.; Li, Y. Covert timing channels for IoT over mobile networks. IEEE Wirel. Commun. 2018, 25, 38–44. [Google Scholar] [CrossRef]
- Liang, Q.; Shi, N.; Tan, Y.-a.; Li, C.; Liang, C. A Stealthy Communication Model with Blockchain Smart Contract for Bidding Systems. Electronics 2024, 13, 2523. [Google Scholar] [CrossRef]
- Liang, Q.; Zhu, C. A new one-dimensional chaotic map for image encryption scheme based on random DNA coding. Opt. Laser Technol. 2023, 160, 109033. [Google Scholar] [CrossRef]
- Wen, H.; Huang, Y.; Lin, Y. High-quality color image compression-encryption using chaos and block permutation. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 101660. [Google Scholar] [CrossRef]
- Ramos, A.M.; Artiles, J.A.; Chaves, D.P.; Pimentel, C. A fragile image watermarking scheme in dwt domain using chaotic sequences and error-correcting codes. Entropy 2023, 25, 508. [Google Scholar] [CrossRef] [PubMed]
- Bonawitz, K.; Ivanov, V.; Kreuter, B.; Marcedone, A.; McMahan, H.B.; Patel, S.; Ramage, D.; Segal, A.; Seth, K. Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1175–1191. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Caponetto, R.; Fortuna, L.; Fazzino, S.; Xibilia, M.G. Chaotic sequences to improve the performance of evolutionary algorithms. IEEE Trans. Evol. Comput. 2003, 7, 289–304. [Google Scholar] [CrossRef]
- Bell, D.E.; LaPadula, L.J. Secure Computer Systems: Mathematical Foundations; Citeseer; Mitre Corporation: Bedford, MA, USA, 1975. [Google Scholar]
- Preneel, B. Cryptographic hash functions. Eur. Trans. Telecommun. 1994, 5, 431–448. [Google Scholar] [CrossRef]
- Barradas, D.; Santos, N.; Rodrigues, L.; Nunes, V. Poking a hole in the wall: Efficient censorship-resistant Internet communications by parasitizing on WebRTC. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual, 9–13 November 2020; pp. 35–48. [Google Scholar]
- Malik, A.; Ashraf, A.; Wu, H.; Kuribayashi, M. Reversible Data Hiding in Encrypted Text Using Paillier Cryptosystem. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 1495–1499. [Google Scholar]
- Zhang, X.; Liang, C.; Zhang, Q.; Li, Y.; Zheng, J.; Tan, Y.-A. Building covert timing channels by packet rearrangement over mobile networks. Inf. Sci. 2018, 445, 66–78. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, L.; Wang, X.; Zhang, C.; Zhu, H.; Tan, Y.-A. A packet-reordering covert channel over VoLTE voice and video traffics. J. Netw. Comput. Appl. 2019, 126, 29–38. [Google Scholar] [CrossRef]
- Shen, T.; Zhu, L.; Gao, F.; Chen, Z.; Zhang, Z.; Li, M. A Blockchain-Enabled Group Covert Channel against Transaction Forgery. Mathematics 2024, 12, 251. [Google Scholar] [CrossRef]
- Liang, C.; Baker, T.; Li, Y.; Nawaz, R.; Tan, Y.-A. Building covert timing channel of the IoT-enabled MTS based on multi-stage verification. IEEE Trans. Intell. Transp. Syst. 2021, 24, 2578–2595. [Google Scholar] [CrossRef]
- Hitaj, D.; Pagnotta, G.; Hitaj, B.; Perez-Cruz, F.; Mancini, L.V. Fedcomm: Federated learning as a medium for covert communication. IEEE Trans. Dependable Secur. Comput. 2024, 21, 1695–1707. [Google Scholar] [CrossRef]
- Kim, S.W. Covert communication over federated learning channel. In Proceedings of the 2023 17th International Conference on Ubiquitous Information Management and Communication (IMCOM), Seoul, Republic of Korea, 3–5 January 2023; pp. 1–3. [Google Scholar]
- Hou, X.; Wang, J.; Jiang, C.; Zhang, X.; Ren, Y.; Debbah, M. UAV-enabled covert federated learning. IEEE Trans. Wirel. Commun. 2023, 22, 6793–6809. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| global model in the -th communication round | |
| local model of client in the -th communication round | |
| chaotic sequence seed | |
| parameter for logistic map | |
| the length of the position generated by the chaotic sequence | |
| the length of the list of model parameters | |
| selected position sequence | |
| The -th position in the position sequence | |
| covert information | |
| covert information of digital type | |
| the -th covert information | |
| Paillier cryptosystem’s public key parameters |
| Hash Algorithm | Number of Embedded Bits | K–S Test -Value |
|---|---|---|
| SHA-224 | 224 | 1.0 |
| SHA-256 | 256 | 1.0 |
| SHA-384 | 384 | 1.0 |
| SHA-512 | 512 | 1.0 |
| Hash Algorithm | Number of Embedded Bits | K–L Divergence |
|---|---|---|
| SHA-224 | 224 | |
| SHA-256 | 256 | |
| SHA-384 | 384 | |
| SHA-512 | 512 |
| Hash Algorithm | Number of Embedded Bits | Welch’s t-Test -Value |
|---|---|---|
| SHA-224 | 224 | 0.9951 |
| SHA-256 | 256 | 0.9972 |
| SHA-384 | 384 | 0.9973 |
| SHA-512 | 512 | 0.9974 |
| Scheme | Channel Capacity (Bits/Round) |
|---|---|
| Proposed | 512.00 |
| Hitaj et al. (1 sender) | 19.76 |
| Hitaj et al. (2 sender) | 65.87 |
| Hitaj et al. (4 sender) | 263.47 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Sun, X.; Shi, N.; Ci, X.; Liang, C. A Stealthy Communication Model for Protecting Aggregated Results Integrity in Federated Learning. Electronics 2024, 13, 3870. https://doi.org/10.3390/electronics13193870
Li L, Sun X, Shi N, Ci X, Liang C. A Stealthy Communication Model for Protecting Aggregated Results Integrity in Federated Learning. Electronics. 2024; 13(19):3870. https://doi.org/10.3390/electronics13193870
Chicago/Turabian StyleLi, Lu, Xuan Sun, Ning Shi, Xiaotian Ci, and Chen Liang. 2024. "A Stealthy Communication Model for Protecting Aggregated Results Integrity in Federated Learning" Electronics 13, no. 19: 3870. https://doi.org/10.3390/electronics13193870