

Diffusion Model for Camouflaged Object Segmentation with Frequency Domain


Abstract
:1. Introduction
- We construct a diffusion model for the COS network with the frequency domain, FreDiff. We propose FAM to extract frequency domain information from images and achieve feature alignment through the feature fusion module, thereby obtaining more comprehensive information about camouflaged objects.
- We design GFM and UEM, which allow FreDiff to focus on global features and boundary detail features, respectively, thereby enhancing its understanding of image information and refining edge details.
- We propose a noise schedule for the diffusion model tailored for COS, which improves the model’s segmentation performance and training efficiency by increasing the speed of noise addition during the training stage.
2. Related Work
2.1. Camouflaged Object Segementation
2.2. Diffusion Model
2.3. Frequency-Guided Segmentation
3. Methods
3.1. Mathematical Derivation
3.1.1. Forward Process
3.1.2. Backward Process
3.2. FreDiff Architecture Design
3.2.1. Backbone
3.2.2. FAM
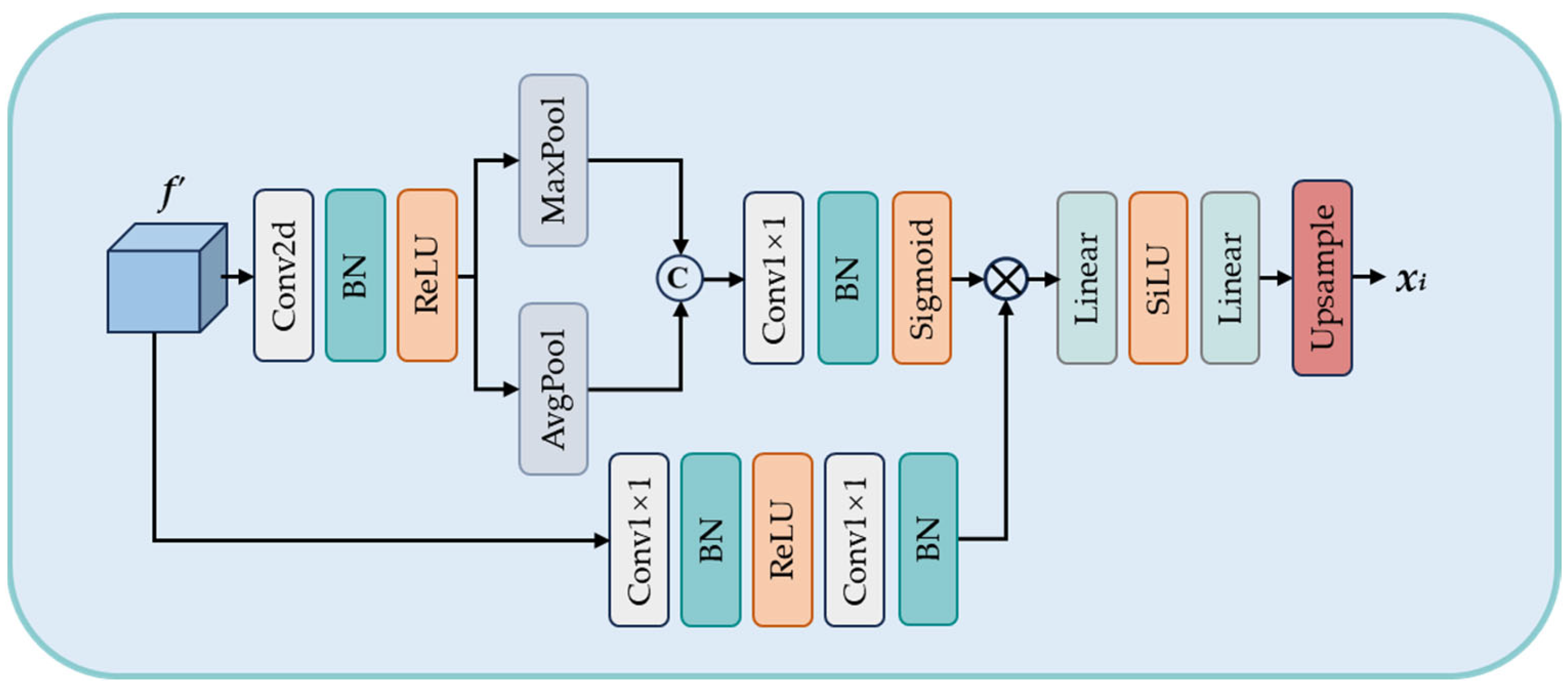
3.2.3. GFM
3.2.4. UEM
3.3. Training and Sampling Strategies
3.3.1. Training Strategy
| Algorithm 1: Training Stage |
| Input: Image, mask ddpm_training_loss (Image, ): Repeat step ~ Uniform ({1, …, T}) Image ~ q (Image) mask ~ q (mask0) # : noise vector Take gradient descent step on: Until converged |
3.3.2. Sampling Strategy
| Algorithm 2: Sampling Stage |
| Input: Image, step, T ddpm_sampling (image, steps, T): = [] # []: array of masks # steps: number of sampling steps # T: time steps for step, t in [T, …, 0]: If t > 0, , else z = 0 |
4. Results
4.1. Experimental Platform Configuration
4.2. Datasets and Evaluation Metrics
4.2.1. Dataset Settings
4.2.2. Evaluation Metrics
4.3. Comparison Algorithms
4.4. Analysis of the Comparative Experimental Results
4.4.1. Quantitative Comparison
4.4.2. Qualitative Comparison
4.5. Ablation Experiments
5. Discussion
5.1. Advantages of FreDiff
5.2. Limitations and Challenge
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fan, D.P.; Ji, G.P.; Sun, G.; Cheng, M.M.; Shen, J.; Shao, L. Camouflaged object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2774–2784. [Google Scholar]
- Liu, M.Z.; Di, X.G. Extraordinary MHNet: Military high-level camouflage object detection network and dataset. Neurocomputing 2023, 549, 126466. [Google Scholar] [CrossRef]
- Li, L.; Liu, J.Y.; Wang, S.; Wang, X.K.; Xiang, T.Z. Trichomonas vaginalis segmentation in microscope images. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2022, Singapore, 18–22 September 2022; Volume 13434, pp. 68–78. [Google Scholar]
- Tabernik, D.; Sela, S.; Skvarc, J.; Skocaj, D. Segmentation-based deep-learning approach for surface-defect detection. J. Intell. Manuf. 2020, 31, 759–776. [Google Scholar] [CrossRef]
- Kumar, K.; Rahman, A. Early detection of locust swarms using deep learning. In Advances in Machine Learning and Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2021; pp. 303–310. [Google Scholar]
- Jiang, X.H.; Cai, W.W.; Ding, Y.; Wang, X.; Yang, Z.Y.; Di, X.Y.; Gao, W.J. Camouflaged Object Detection Based on Ternary Cascade Perception. Remote Sens. 2023, 15, 1188–1210. [Google Scholar] [CrossRef]
- Mei, H.; Ji, G.P.; Wei, Z.; Yang, X.; Wei, X.; Fan, D.P. Camouflaged object segmentation with distraction mining. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Ithaca, NY, USA, 19–25 June 2021; pp. 8768–8777. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Cheng, M.M.; Shao, L. Concealed object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6024–6042. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Xu, S.; Piao, Y.R.; Shi, D.X.; Lin, S.S.; Lu, H.C. Preynet: Preying on camouflaged objects. In Proceedings of the 30th ACM International Conference on Multimedia (MM), New York, NY, USA, 10–14 October 2022; pp. 5323–5332. [Google Scholar]
- Pang, Y.; Zhao, X.; Xiang, T.; Zhang, L.; Lu, H. Zoom In and Out: A Mixed-scale Triplet Network for Camouflaged Object Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 2150–2160. [Google Scholar]
- Wang, W.G.; Lai, Q.X.; Shen, J.B.; Ling, H.B. Salient Object Detection in the Deep Learning Era: An In-depth Survey. IEEE. Trans. Pattern Anal. Mach. Intell. 2019, 44, 3239–3259. [Google Scholar] [CrossRef] [PubMed]
- Li, A.X.; Zhang, J.; Lv, Y.Q.; Liu, B.; Zhang, T.; Dai, Y.C. Uncertainty-aware Joint Salient Object and Camouflaged Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 10066–10076. [Google Scholar]
- Luo, X.J.; Wang, S.; Wu, Z.W.; Sakaridis, C.; Cheng, Y.; Fan, D.P.; Gool, L. CamDiff: Camouflage Image Augmentation via Diffusion. CAAI Artif. Intell. Res. 2023, 2, 915002. [Google Scholar] [CrossRef]
- Wu, Z.W.; Paudel, D.P.; Fan, D.P.; Wang, J.J.; Wang, S.; Demonceaux, C.; Timofte, R.; Van Gool, L. Source-free Depth for Object Pop-out. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 4–6 October 2023; pp. 1032–1042. [Google Scholar]
- He, C.M.; Li, K.; Zhang, Y.C.; Tang, L.X.; Zhang, Y.L.; Guo, Z.H.; Li, X. Camouflaged Object Detection with Feature Decomposition and Edge Reconstruction. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 20–22 June 2023; pp. 22046–22055. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models. ICML 2021, 44, 16784–16804. [Google Scholar]
- Zhang, J.H.; Yan, R.D.; Perell, A.; Chen, X.; Li, C. Phy-Diff: Physics-guided Hourglass Diffusion Model for Diffusion MRI Synthesis. arXiv 2024, arXiv:2406.03002. [Google Scholar]
- Zhou, H.P.; Wang, H.Q.; Ye, T.; Xing, Z.H.; Ma, J.; Li, P.; Wang, Q.; Zhu, L. Timeline and Boundary Guided Diffusion Network for Video Shadow Detection. arXiv 2024, arXiv:2408.11785. [Google Scholar]
- Fan, D.P.; Ji, G.P.; Xu, P.; Cheng, M.M.; Sakaridis, C.; Gool, L.V. Advances in Deep Concealed Scene Understanding. Vis. Intell. 2023, 1, 1–24. [Google Scholar] [CrossRef]
- Le, T.N.; Nguyen, T.V.; Nie, Z.; Tran, M.-T.; Sugimoto, A. Anabranch network for camouflaged object segmentation. Comput. Vis. Image Underst. 2019, 184, 45–56. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, J.; Dai, Y.; Li, A.; Liu, B.; Barnes, N. Simultaneously localize; segment and rank the camouflaged objects. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 11586–11596. [Google Scholar]
- Zhang, J.; Lv, Y.Q.; Xiang, M.C.; Li, A.X.; Dai, Y.C.; Zhong, Y.R. Depth confidence-aware camouflaged object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Ithaca, NY, USA, 19–25 June 2021; pp. 11641–11653. [Google Scholar]
- He, R.Z.; Dong, Q.H.; Lin, J.Y.; Lau, R.W. Weakly-supervised camouflaged object detection with scribble annotations. In Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 7–14 February 2023; pp. 781–789. [Google Scholar]
- Pang, Y.W.; Zhao, X.Q.; Xiang, T.Z.; Zhang, L.H.; Lu, H.C. ZoomNeXt: A Unified Collaborative Pyramid Network for Camouflaged Object Detection. IEEE Trans. Pattern Anal. Mach Intell. 2024, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 6–12 December 2020; pp. 6840–6851. [Google Scholar]
- Wu, J.; Fang, H.; Zhang, Y.; Yang, Y.; Xu, Y. MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model. MIDL 2024, 227, 1623–1639. [Google Scholar]
- Chen, Z.X.; Sun, K.; Liu, X.M.; Ji, R.R. CamoDiffusion: Camouflaged Object Detection via Conditional Diffusion Models. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 07–14 February 2023; pp. 1272–1280. [Google Scholar]
- Chen, S.F.; Sun, P.Z.; Song, Y.B.; Luo, P. DiffusionDet: Diffusion Model for Object Detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 19773–19786. [Google Scholar]
- Xu, K.; Qin, M.H.; Sun, F.; Wang, Y.H.; Chen, Y.K.; Ren, F.B. Learning in the Frequency Domain. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1737–1746. [Google Scholar]
- Zhong, Y.J.; Li, B.; Tang, L.; Kuang, S.Y.; Wu, S.; Ding, S.H. Detecting Camouflaged Object in Frequency Domain. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 4494–4503. [Google Scholar]
- Cong, R.M.; Sun, M.Y.; Zhang, S.Y.; Zhou, X.F.; Zhang, W.; Zhao, Y. Frequency Perception Network for Camouflaged Object Detection. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS’20), Vancouver, BC, Canada, 6–12 December 2020; pp. 1179–1189. [Google Scholar]
- Dong, B.; Wang, P.C.; Wang, F. Head-Free Lightweight Semantic Segmentation with Linear Transformer. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 7–14 February 2023; pp. 516–524. [Google Scholar]
- Wang, W.H.; Xie, E.; Li, X.; Fan, D.P.; Song, K.T.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved baselines with Pyramid Vision Transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Hoogeboom, E.; Heek, J.; Salimans, T. Simple diffusion: End-to-end diffusion for high resolution images. arXiv 2023, arXiv:2301.11093. [Google Scholar]
- Le, T.N.; Cao, Y.B.; Nguyen, T.C.; Do, T.T.; Tran, M.T.; Nguyen, T.V. Camouflaged instance segmentation in-the-wild: Dataset, method, and benchmark suite. IEEE Trans. Image Process. 2022, 31, 287–300. [Google Scholar] [CrossRef]
- Skurowski, P.; Abdulameer, H.; Błaszczyk, J.; Depta, T.; Kornacki, A.; Przemysław, K. Animal camouflage analysis: Chameleon database. Unpubl. Manuscr. 2018, 2, 7. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Ithaca, NY, USA, 22–29 October 2017; pp. 4558–4567. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to evaluate foreground maps. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Ithaca, NY, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Ithaca, NY, USA, 18–22 June 2018; pp. 698–704. [Google Scholar]
- Yang, F.; Zhai, Q.; Li, X.; Huang, R.; Luo, A.; Cheng, H.; Fan, D.P. Uncertainty-Guided Transformer Reasoning for Camouflaged Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 4126–4135. [Google Scholar]
- Zhai, Q.; Li, X.; Yang, F.; Chen, C.Z.; Cheng, H.; Fan, D.P. Mutual Graph Learning for Camouflaged Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 12992–13002. [Google Scholar]
- Zhu, H.W.; Li, P.; Xie, H.R.; Yan, X.F.; Liang, D.; Chen, D.P.; Wei, M.Q.; Qin, J. I Can Find You! Boundary-Guided Separated Attention Network for Camouflaged Object Detection. AAAI 2022, 36, 3608–3616. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Z.L.; Wu, W. Boosting Camouflaged Object Detection with Dual-Task Interactive Transformer. In Proceedings of the 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 140–146. [Google Scholar]
- Lv, Y.Q.; Zhang, J.; Dai, Y.C.; Li, A.X.; Barnes, N.; Fan, D.P. Toward Deeper Understanding of Camouflaged Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 3462–3476. [Google Scholar] [CrossRef]
- Zhang, Q.; Ge, Y.; Zhang, C.; Bi, H.B. TPRNet: Camouflaged object detection via transformer-induced progressive refinement network. Visual Comput. 2022, 39, 4593–4607. [Google Scholar] [CrossRef]
- Ji, G.P.; Fan, D.P.; Chou, Y.C.; Dai, D.; Liniger, A.; Van Gool, L. Deep Gradient Learning for Efficient Camouflaged Object Detection. Mach. Intell. Res. 2023, 20, 92–108. [Google Scholar] [CrossRef]
- Yin, B.; Zhang, X.; Hou, Q.; Sun, B.Y.; Fan, D.P.; Van Gool, L. CamoFormer: Masked Separable Attention for Camouflaged Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 14, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Dai, H.; Xiang, T.-Z.; Wang, S.; Chen, H.-X.; Qin, J.; Xiong, H. Feature Shrinkage Pyramid for Camouflaged Object Detection with Transformers. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 20–22 June 2023; pp. 5557–5566. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regularization | MAE ↓ | ↑ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|
| 2 t | 0.031 | 0.840 | 0.764 | 0.912 | 0.752 |
| t | 0.030 | 0.843 | 0.771 | 0.919 | 0.755 |
| 1/2 t | 0.025 | 0.858 | 0.779 | 0.924 | 0.760 |
| 1/3 t | 0.024 | 0.866 | 0.784 | 0.929 | 0.763 |
| 1/4 t | 0.026 | 0.845 | 0.775 | 0.920 | 0.758 |
| Names | Related Configurations |
|---|---|
| GPU | NVIDIA GeForce RTX 3090 |
| CPU | Xeon Gold 6148/128G |
| Computer platform | CUDA 12.2 |
| Operating system | Windows 10 |
| Deep learning framework | Pytorch |
| GPU memory size | 24 G |
| Methods | Pub.-Year | COD10K | NC4K | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | ↑ | ↑ | ↑ | ↑ | MAE↓ | ↑ | ↑ | ↑ | ↑ | ||
| SINet | CVPR-20 | 0.043 | 0.776 | 0.679 | 0.867 | 0.631 | 0.058 | 0.808 | 0.769 | 0.883 | 0.723 |
| PFNet | CVPR-21 | 0.040 | 0.800 | 0.701 | 0.868 | 0.660 | 0.053 | 0.829 | 0.784 | 0.894 | 0.745 |
| UGTR | ICCV-21 | 0.036 | 0.817 | 0.711 | 0.850 | 0.666 | 0.052 | 0.839 | 0.787 | 0.888 | 0.746 |
| UJSC | CVPR-21 | 0.035 | 0.809 | 0.721 | 0.882 | 0.684 | 0.047 | 0.842 | 0.806 | 0.906 | 0.771 |
| MGL-R | CVPR-21 | 0.035 | 0.814 | 0.710 | 0.864 | 0.666 | 0.053 | 0.833 | 0.782 | 0.889 | 0.739 |
| SINet-V2 | TPAMI-22 | 0.037 | 0.815 | 0.718 | 0.864 | 0.680 | 0.048 | 0.847 | 0.805 | 0.901 | 0.770 |
| PreyNet | MM22 | 0.034 | 0.813 | 0.736 | 0.894 | 0.697 | 0.050 | 0.834 | 0.803 | 0.899 | 0.763 |
| BSANet | AAAI-22 | 0.034 | 0.818 | 0.738 | 0.894 | 0.699 | 0.048 | 0.841 | 0.808 | 0.906 | 0.771 |
| ZoomNet | CVPR-22 | 0.029 | 0.838 | 0.766 | 0.893 | 0.729 | 0.043 | 0.853 | 0.818 | 0.907 | 0.784 |
| DTINet | ICPR-22 | 0.034 | 0.824 | 0.702 | 0.881 | 0.695 | 0.041 | 0.863 | 0.818 | 0.914 | 0.792 |
| SLSR | TCSVT-23 | 0.037 | 0.804 | 0.715 | 0.883 | 0.673 | 0.048 | 0.840 | 0.804 | 0.904 | 0.766 |
| TPRNet | TVCJ-23 | 0.036 | 0.817 | 0.724 | 0.869 | 0.683 | 0.048 | 0.846 | 0.805 | 0.901 | 0.768 |
| PopNet | ICCV-23 | 0.028 | 0.851 | 0.786 | 0.910 | 0.757 | 0.042 | 0.861 | 0.833 | 0.915 | 0.802 |
| FEDER | CVPR-23 | 0.032 | 0.822 | 0.751 | 0.901 | 0.716 | 0.044 | 0.847 | 0.824 | 0.913 | 0.789 |
| DGNet | MIR-23 | 0.033 | 0.822 | 0.728 | 0.879 | 0.693 | 0.042 | 0.857 | 0.814 | 0.910 | 0.784 |
| CamoFormer-R | ArXiv-23 | 0.029 | 0.838 | 0.753 | 0.900 | 0.724 | 0.042 | 0.855 | 0.821 | 0.913 | 0.788 |
| FSPNet | CVPR-23 | 0.026 | 0.851 | 0.769 | 0.900 | 0.735 | 0.035 | 0.879 | 0.843 | 0.923 | 0.816 |
| FreDiff | Ours | 0.024 | 0.866 | 0.784 | 0.929 | 0.763 | 0.030 | 0.886 | 0.844 | 0.936 | 0.827 |
| Methods | Pub.-Year | CAMO | CHAMELEON | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE↓ | ↑ | ↑ | ↑ | ↑ | MAE↓ | ↑ | ↑ | ↑ | ↑ | ||
| SINet | CVPR-20 | 0.092 | 0.745 | 0.702 | 0.825 | 0.644 | 0.034 | 0.872 | 0.827 | 0.938 | 0.806 |
| PFNet | CVPR-21 | 0.085 | 0.782 | 0.746 | 0.855 | 0.695 | 0.033 | 0.882 | 0.828 | 0.942 | 0.810 |
| UGTR | ICCV-21 | 0.086 | 0.784 | 0.735 | 0.858 | 0.684 | 0.031 | 0.888 | 0.819 | 0.921 | 0.794 |
| UJSC | CVPR-21 | 0.073 | 0.800 | 0.772 | 0.872 | 0.728 | 0.030 | 0.891 | 0.847 | 0.943 | 0.833 |
| MGL-R | CVPR-21 | 0.088 | 0.775 | 0.726 | 0.848 | 0.673 | 0.031 | 0.893 | 0.833 | 0.923 | 0.812 |
| SINet-V2 | TPAMI-22 | 0.070 | 0.820 | 0.782 | 0.884 | 0.743 | 0.030 | 0.888 | 0.835 | 0.930 | 0.816 |
| PreyNet | MM22 | 0.077 | 0.790 | 0.757 | 0.856 | 0.708 | 0.028 | 0.895 | 0.859 | 0.951 | 0.844 |
| BSANet | AAAI-22 | 0.079 | 0.794 | 0.763 | 0.866 | 0.717 | 0.027 | 0.895 | 0.858 | 0.946 | 0.841 |
| ZoomNet | CVPR-22 | 0.066 | 0.820 | 0.794 | 0.883 | 0.752 | 0.023 | 0.902 | 0.864 | 0.952 | 0.845 |
| DTINet | ICPR-22 | 0.050 | 0.856 | 0.823 | 0.918 | 0.796 | 0.033 | 0.883 | 0.827 | 0.928 | 0.813 |
| SLSR | TCSVT-23 | 0.080 | 0.787 | 0.744 | 0.859 | 0.696 | 0.030 | 0.890 | 0.841 | 0.936 | 0.822 |
| TPRNet | TVCJ-23 | 0.074 | 0.807 | 0.772 | 0.880 | 0.725 | 0.031 | 0.891 | 0.836 | 0.930 | 0.816 |
| PopNet | ICCV-23 | 0.077 | 0.808 | 0.784 | 0.871 | 0.744 | 0.020 | 0.917 | 0.885 | 0.957 | 0.875 |
| FEDER | CVPR-23 | 0.071 | 0.802 | 0.781 | 0.877 | 0.738 | 0.030 | 0.887 | 0.851 | 0.943 | 0.834 |
| DGNet | MIR-23 | 0.057 | 0.839 | 0.806 | 0.906 | 0.769 | 0.029 | 0.890 | 0.834 | 0.934 | 0.816 |
| CamoFormer-R | ArXiv-23 | 0.076 | 0.816 | 0.745 | 0.863 | 0.712 | 0.026 | 0.898 | 0.863 | 0.951 | 0.844 |
| FSPNet | CVPR-23 | 0.050 | 0.856 | 0.830 | 0.919 | 0.799 | 0.023 | 0.908 | 0.867 | 0.945 | 0.851 |
| FreDiff | Ours | 0.043 | 0.870 | 0.836 | 0.934 | 0.763 | 0.020 | 0.902 | 0.878 | 0.966 | 0.860 |
| Baseline | FAM | GFM | UEM | Strategy | MAE↓ | ↑ | ↑ | ↑ | ↑ |
|---|---|---|---|---|---|---|---|---|---|
| 0.029 | 0.858 | 0.767 | 0.915 | 0.744 | |||||
| 0.027 | 0.861 | 0.773 | 0.912 | 0.749 | |||||
| 0.025 | 0.863 | 0.780 | 0.922 | 0.753 | |||||
| 0.024 | 0.860 | 0.780 | 0.926 | 0.758 | |||||
| 0.024 | 0.866 | 0.784 | 0.929 | 0.763 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, W.; Gao, W.; Ding, Y.; Jiang, X.; Wang, X.; Di, X. Diffusion Model for Camouflaged Object Segmentation with Frequency Domain. Electronics 2024, 13, 3922. https://doi.org/10.3390/electronics13193922
Cai W, Gao W, Ding Y, Jiang X, Wang X, Di X. Diffusion Model for Camouflaged Object Segmentation with Frequency Domain. Electronics. 2024; 13(19):3922. https://doi.org/10.3390/electronics13193922
Chicago/Turabian StyleCai, Wei, Weijie Gao, Yao Ding, Xinhao Jiang, Xin Wang, and Xingyu Di. 2024. "Diffusion Model for Camouflaged Object Segmentation with Frequency Domain" Electronics 13, no. 19: 3922. https://doi.org/10.3390/electronics13193922