Abstract
Automatic music transcription (AMT) aims to convert raw audio signals into symbolic music. This is a highly challenging task in the fields of signal processing and artificial intelligence, and it holds significant application value in music information retrieval (MIR). Existing methods based on convolutional neural networks (CNNs) often fall short in capturing the time-frequency characteristics of audio signals and tend to overlook the interdependencies between notes when processing polyphonic piano with multiple simultaneous notes. To address these issues, we propose a dual attention feature extraction and multi-scale graph attention network (DAFE-MSGAT). Specifically, we design a dual attention feature extraction module (DAFE) to enhance the frequency and time-domain features of the audio signal, and we utilize a long short-term memory network (LSTM) to capture the temporal features within the audio signal. We introduce a multi-scale graph attention network (MSGAT), which leverages the various implicit relationships between notes to enhance the interaction between different notes. Experimental results demonstrate that our model achieves high accuracy in detecting the onset and offset of notes on public datasets. In both frame-level and note-level metrics, DAFE-MSGAT achieves performance comparable to the state-of-the-art methods, showcasing exceptional transcription capabilities.
1. Introduction
Automatic music transcription (AMT) is a crucial task [1,2,3] that involves converting audio signals into symbolic music representations, and it holds significant importance in music information retrieval (MIR). The goal of AMT is to automatically transform a segment of audio into MIDI or sheet music representations. Its applications span various areas, including automatic music search, automatic accompaniment generation and musicological analysis [4,5,6].
Existing AMT methods can be mainly categorized into frame-level transcription and note-level transcription based on their output forms. Frame-level transcription focuses on estimating the number and pitch of simultaneous notes within each time frame and its computational efficiency is very high. Note-level transcription not only estimates pitches but also connects pitch estimates across time frames to form complete notes, providing richer musical structure information.
In recent years, deep learning-based methods [7,8,9,10,11] have achieved significant progress in AMT. However, accurately identifying the notes faces a substantial challenge [12,13], due to the polyphonic nature of piano music, where multiple notes can appear simultaneously. Duan and Temperley [14] pointed out that there were implicit dependencies between notes, but most methods overlook the implicit relationships between notes. For example, the proportional relationships between the root, third, and fifth notes of a piano chord determine the fundamental nature of the chord. These dependencies are particularly crucial in polyphonic piano transcription, as models need to capture and understand these complex dependency structures to accurately reproduce the true chord effects. Moreover, methods [15,16,17] based on convolutional neural networks (CNNs) can capture the spatial features of audio signals to some extent. However, they have limitations in handling temporal dependencies and capturing fine-grained time-frequency features, making them insufficient when dealing with complex signals. These models struggle to accurately distinguish and parse overlapping notes in complex multi-track music signals. The frequency components of different notes interfere with each other, increasing the difficulty of transcription.
To overcome these challenges, we propose a polyphonic piano transcription model based on dual attention feature extraction and multi-scale graph attention network (DAFE-MSGAT). The model comprises two stages: In the time-frequency attention enhancement stage, we design a dual attention feature extraction module (DAFE) that enhances the frequency and temporal characteristics of the audio signal through attention mechanisms. This enhancement improves the accuracy of note recognition. In the multi-scale graph feature fusion stage, we employ a multi-scale graph attention network (MSGAT) to capture the interdependencies between notes. By utilizing multi-head attention mechanisms and multi-scale feature fusion, we enhance the model’s feature representation capability.
The contributions of this paper are summarized as follows:
- We design a DAFE-MSGAT, which effectively captures time-frequency features and utilizes the interdependencies between notes, achieving outstanding performance in polyphonic piano transcription.
- We propose a DAFE to enhance the frequency and temporal characteristics of audio signals, overcoming the limitations of traditional convolutional neural networks in capturing audio signal details.
- We introduce the graph attention mechanism (GAT) into AMT for the first time, designing an MSGAT to model the implicit interdependencies between notes, thereby enhancing the richness and diversity of feature representations.
- Experimental results demonstrate that our proposed model performs exceptionally well on public datasets, accurately identifying the onset and offset times of notes. It shows competitive performance against existing methods in both frame-level and note-level metrics.
2. Related Work
2.1. Frame-Level and Note-Level Transcription
AMT is a complex task that involves converting audio signals into musical notation. Based on the form of the output representation, existing AMT methods can be broadly categorized into frame-level transcription and note-level transcription.
Frame-level transcription methods, also known as multi-pitch estimation (MPE), aim to estimate the number of simultaneous notes and their pitches within each time frame. These methods typically perform estimation independently within each frame, although sometimes contextual information is utilized during a post-processing stage. Benetos et al. [18] provided a detailed overview of existing traditional signal processing methods [19], probabilistic modeling methods [20], and non-negative matrix factorization (NMF) methods [21,22] in frame-level transcription. They highlighted the limitations of these methods in handling multiple note combinations and suggested potential directions for future research.
Note-level transcription methods not only estimate the pitch for each time frame but also connect these pitch estimates to form complete notes. Duan et al. [14] proposed a maximum likelihood sampling method, which effectively reduced spurious notes and significantly improved the accuracy of note-level transcription by post-processing frame-level multi-pitch estimation outputs. Additionally, Su and Yang [23] introduced a multi-pitch estimation method that combined frequency and periodicity. This method detected pitches through the consistency between harmonic sequences in the frequency domain and subharmonic sequences in the lag domain, effectively integrating the complementary advantages of both feature domains across different frequency ranges. As a result, it enhanced the robustness of pitch detection under multiple harmonic interferences, thereby improving the accuracy of note-level transcription.
In this paper, we evaluate the transcription performance of our proposed model at both the frame level and the note level.
2.2. Deep Learning Methods for AMT
In recent years, the application of deep learning methods in AMT has made significant progress. Sigtia et al. [24] proposed a music language model based on recurrent neural networks (RNNs) combined with a PLCA acoustic model, improving the accuracy of automatic music transcription and enabling efficient transcription of polyphonic music involving multiple instruments. Sturm et al. [25] utilized long short-term memory networks (LSTMs) for music transcription and generation. By training on approximately 23,000 music transcription samples, they achieved automatic generation of new music segments, which can be applied in various music creation contexts. Fernandez et al. [15] introduced a convolutional neural network (CNN)-based method for detecting the onset and velocity of piano notes. This model performed excellently on the MAESTRO dataset [26] and was capable of real-time note onset detection on low-cost hardware. Hawthorne et al. [27] developed a Transformer-based sequence-to-sequence piano transcription model. By using spectrogram frames as input and decoding the output through an autoregressive algorithm, the model excelled in handling fine temporal information of notes. These studies have provided multiple effective deep learning methods and implementation approaches for automatic piano transcription.
Additionally, the attention mechanism has been widely applied in AMT. By assigning different importance weights to input features, it can more effectively capture crucial information. The attention mechanism, first proposed by Bahdanau et al. [28], achieved success in machine translation and was subsequently introduced to music transcription. Hawthorne et al. [26] utilized the attention mechanism to enhance feature extraction from audio signals, generating music with longer temporal consistency and improving the accuracy of note recognition.
In this paper, we design a transcription model based on CNNs and introduce the graph attention mechanism into polyphonic piano transcription for the first time.
3. The Proposed Method
In this section, we provide a detailed description of the proposed DAFE-MSGAT for polyphonic piano transcription. First, we elucidate the overall architecture of the model. Next, we describe the detailed structure of each sub-module within the network. Finally, we introduce the loss function that we employ.
3.1. Architecture Overview
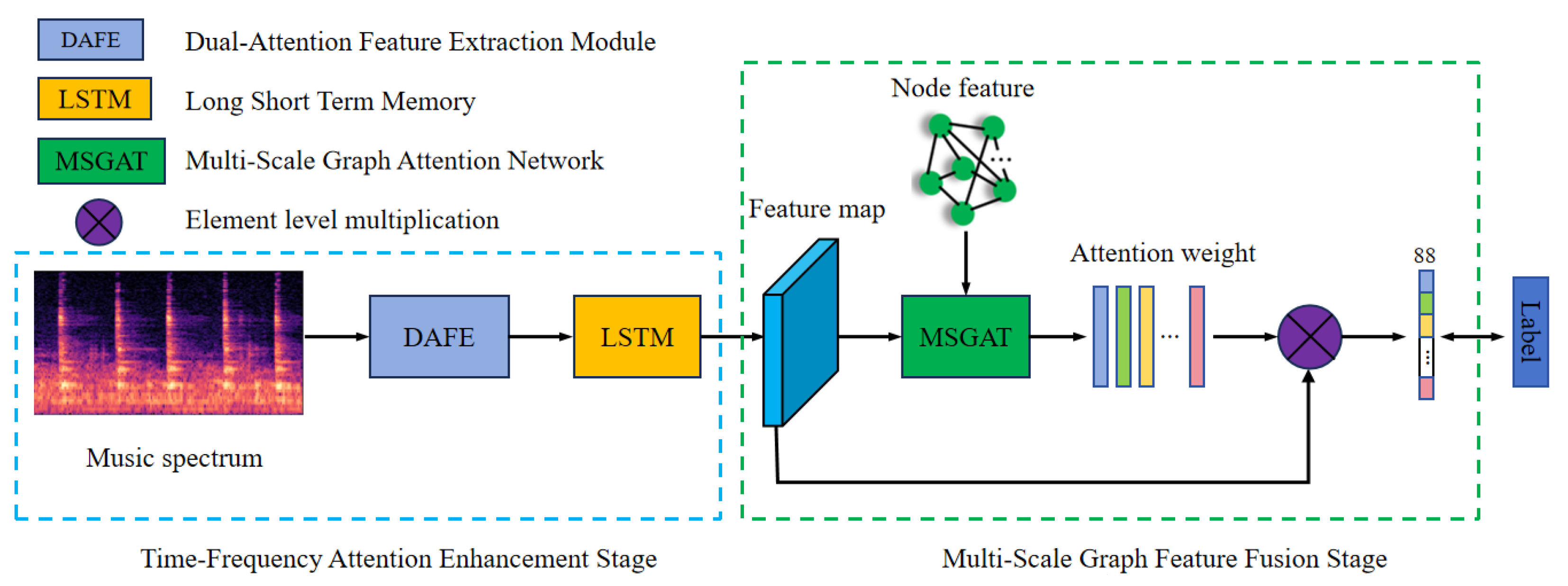
As shown in Figure 1, the proposed DAFE-MSGAT is an end-to-end encoder–decoder network. For a given music segment, a Mel filter is used to convert the audio signal into a Mel spectrogram [29] X, which serves as the input to the network. The workflow of this method primarily consists of two stages: the time-frequency attention feature enhancement stage and the multi-scale graph feature fusion stage.
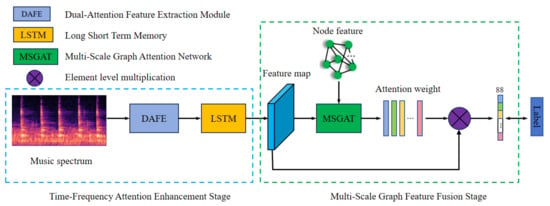
Figure 1.
The overall framework of our proposed dual attention feature extraction and multi-scale graph attention network.
In the time-frequency attention feature enhancement stage, the input Mel spectrogram is first fed into the DAFE, which enhances the frequency and temporal characteristics of the audio signal by combining frequency-domain attention mechanisms and time-domain attention mechanisms. The frequency-domain attention mechanism adaptively weights different frequency components to highlight important frequency information, while the time-domain attention mechanism adaptively weights features at different time points to accurately capture the dynamic changes in notes. The spectrogram, after being processed by the DAFE module, generates a feature map rich in time-frequency information, which is subsequently passed through an LSTM to extract the temporal features of the audio signal. This effectively captures long-term dependencies in the audio signal, identifying the onset, offset, and duration of notes, thereby improving the accuracy of note recognition.
In the multi-scale graph feature fusion stage, the feature map output by the LSTM is fed into the MSGAT, which is designed based on the GAT. The MSGAT leverages the graph-structured data as input to extract and fuse features at different levels through a multi-head attention mechanism, thereby enhancing the expressiveness of the features. Specifically, the dependencies between notes can be naturally represented as graph-structured data, where the notes serve as nodes in the graph, and the edges between the nodes represent the relationships or dependencies between the notes, such as their adjacency in temporal order or repetitive patterns present in the audio signal. Finally, the feature map output by the MSGAT module is used as weights, and it is multiplied element-wise with the previous feature map. This fusion step ensures that information from different feature extraction modules is effectively combined, taking into account frequency-domain, time-domain, and graph-structured features, thereby further improving the overall performance of the model. Through this design, the model can accurately recognize and extract the time-frequency characteristics of notes from complex audio signals, achieving the goal of automatic piano transcription.
3.2. Dual-Attention Feature Extraction Module
Polyphonic piano transcription requires precise identification of note onset times, offset times, and intensities. Methods based on CNNs often struggle to adequately capture the subtle features within audio signals, particularly in the comprehensive extraction of frequency and temporal information.
To address this, we design a DAFE, which integrates frequency-domain attention mechanisms and time-domain attention mechanisms to enhance the frequency and temporal characteristics of audio signals, respectively. The frequency-domain attention mechanism adaptively weights different frequency components to highlight important frequency information, while the time-domain attention mechanism adaptively weights features at different time points to accurately capture the dynamic changes in notes. Through this design, the DAFE improves the feature extraction capability of the network, thereby enhancing the accuracy of note recognition.
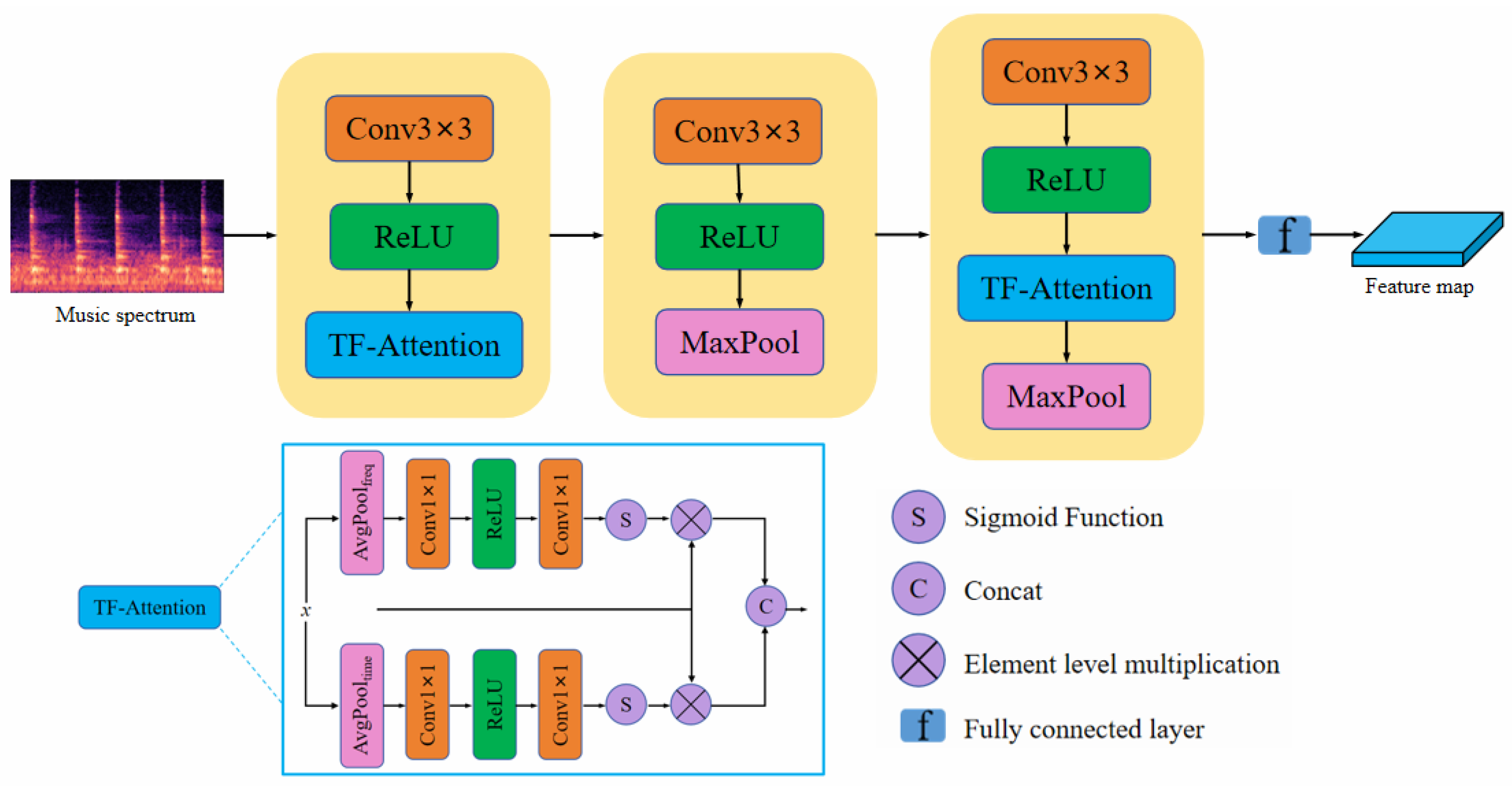
The specific structure of the DAFE is illustrated in Figure 2. By embedding the designed time-frequency attention feature fusion (TF-Attention) module into the traditional convolutional network, we enhance the feature representation capabilities. The process involves a series of convolutional layers, ReLU activation layers, max-pooling layers, and fully connected layers, resulting in the output feature map, where the ReLU activation function is defined as , and its purpose is to introduce non-linearity by setting negative values to zero, thereby enhancing the network’s representational capacity.
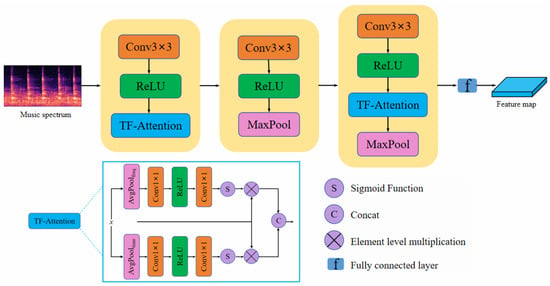
Figure 2.
The architecture of our proposed dual attention feature extraction module.
Specifically, the TF-Attention module consists of three parts: the frequency-domain attention mechanism, the time-domain attention mechanism, and multi-scale fusion. First, the frequency-domain attention mechanism performs adaptive average pooling on the input feature map X along the time dimension to obtain a time-compressed feature map. Then, a convolution is applied to reduce the channel dimensions, followed by a ReLU activation function to introduce non-linearity. Another convolution is then performed to restore the number of channels. Finally, a Sigmoid activation function normalizes the feature map to a range between 0 and 1, generating the frequency-domain attention weights:
The time-domain attention mechanism performs adaptive average pooling on the input feature map X along the frequency dimension. It then undergoes a similar processing sequence to generate the time-domain attention weights:
Finally, the frequency-domain attention weights and the time-domain attention weights are combined with the original feature map X through element-wise multiplication:
Subsequently, the frequency-domain and time-domain features are concatenated along the channel dimension for fusion:
The final output feature map has the same dimensions as the input.
3.3. Multi-Scale Graph Attention Network
In polyphonic piano transcription, there exist complex and intricate dependencies between notes in multi-track music. These dependencies are particularly prominent in polyphonic music, requiring our model to precisely capture the interrelationships between notes during the transcription process. Specifically, the interactions between notes in terms of time and pitch constitute the interwoven harmonies, melodies, and rhythms, forming the overall musical structure. Each note is not merely an independent sound unit but an element that interacts with other notes, with its position, pitch, and dynamics influenced by those of other notes. However, existing CNN-based methods overlook these dependencies, focusing solely on local feature extraction and failing to effectively capture the complex temporal and pitch interactions between notes. This limitation prevents CNNs from accurately reproducing the overall structure of notes in multi-track music, resulting in transcription outcomes that lack coherence and expressiveness.
To effectively address the aforementioned issues, we design an MSGAT. This network leverages the graph attention mechanism to assign adaptive attention weights to each neighboring node in graph-structured data, aggregating relevant neighbor information. Through multi-scale processing, the MSGAT captures dependencies between notes at different levels. This enables us to not only focus on the relationships between local notes during transcription but also to understand their position and role within the global musical structure.
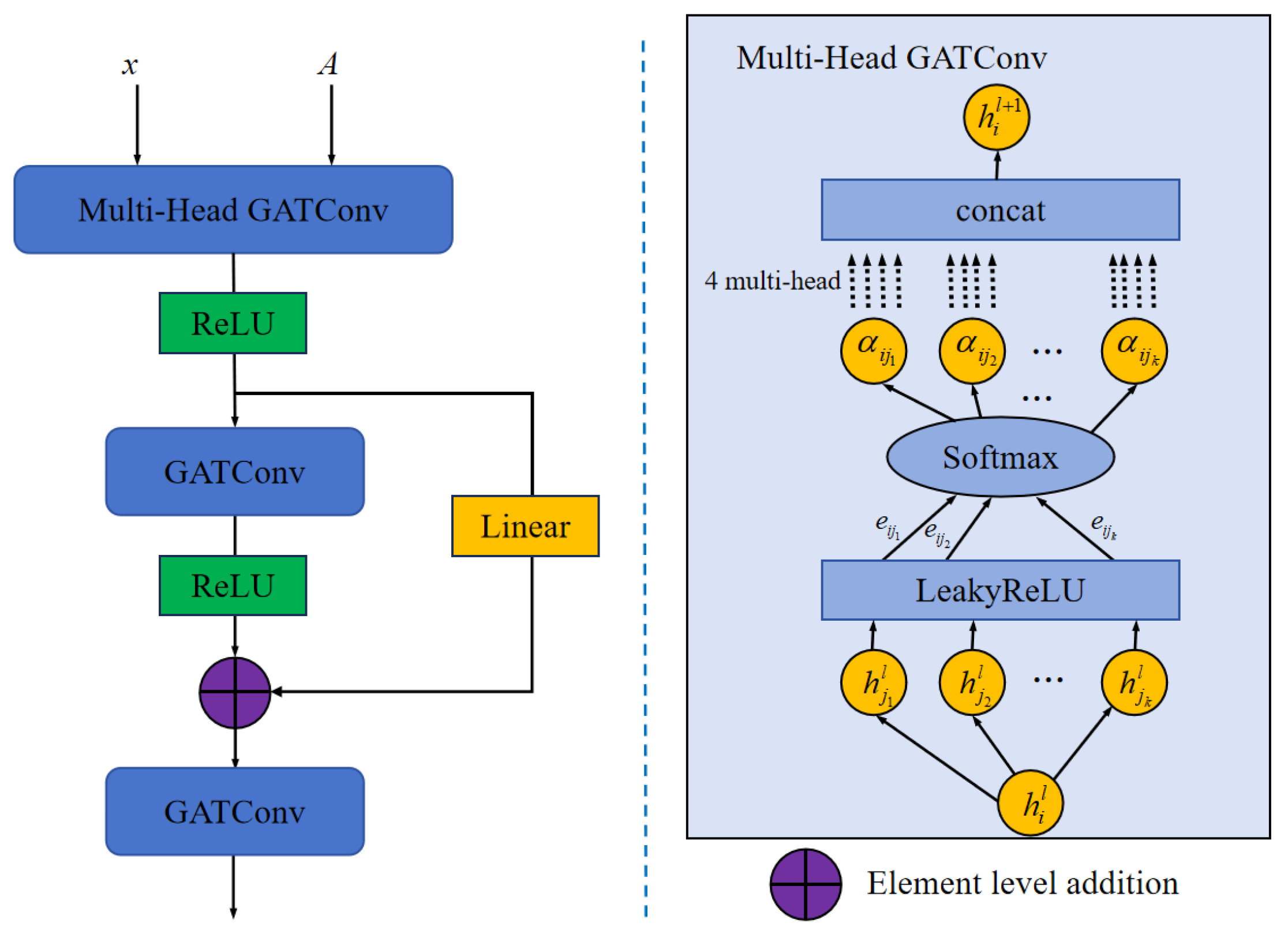
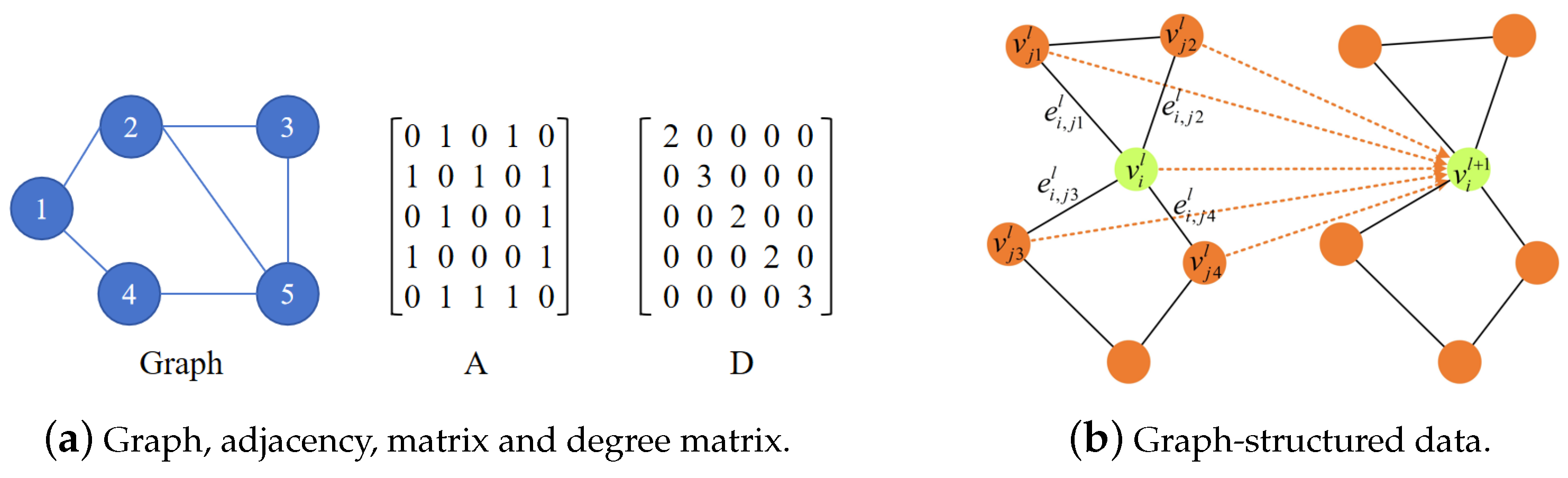
The structure of the MSGAT is illustrated in Figure 3. First, as shown in Figure 4, we construct a graph structure among the notes, treating the notes as nodes and the dependencies between notes as edges. We use ground truth priors to construct the graph’s adjacency matrix A, and then normalize A to make it suitable for the attention mechanism. The normalization formula is as follows:
where D is the diagonal matrix, with each diagonal element representing the sum of the elements in the i-th row of the adjacency matrix A.
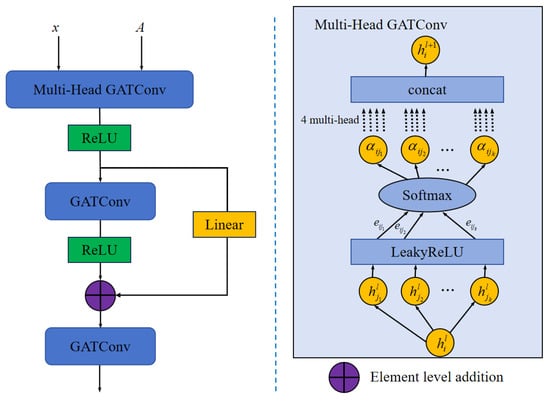
Figure 3.
The architecture of our proposed multi-scale graph attention network.
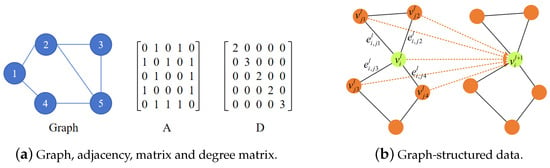
Figure 4.
The construction process of the graph-structured data, as well as the adjacency matrix and degree matrix.
In our designed MSGAT network, we use three graph attention layers (GATConv) for feature extraction. The first layer employs multi-head graph attention to extract features at different scales, enabling a fine-grained processing of information layer by layer. This multi-scale processing approach allows the model to simultaneously capture both local and global features in the audio signal, enhancing the expression of the time-frequency characteristics of the notes:
where K represents the number of attention heads, with K = 4 in this layer. In the second and third graph attention layers, residual connections are introduced to ensure that information from earlier layers can be directly transmitted to subsequent layers, thereby avoiding the issue of information loss in shallow networks. The calculation formula is as follows:
where is the linear transformation matrix in the skip connection, used to adapt the output of the first layer to the dimensionality of the second layer.
3.4. Loss Function
In the research on polyphonic piano transcription, label data sparse and class imbalance are significant challenges. The label matrix tends to have relatively large dimensions, but the elements containing actual information are very limited, with most positions being zero, which results in a low density of useful information in the training data, increasing the difficulty for models to extract valuable features from it. So we choose to use Focal Loss [30] as the loss function. Binary cross-entropy loss, when handling imbalanced datasets, tends to be influenced by a large number of easy samples, resulting in insufficient attention of the model to hard-to-classify samples. Focal Loss introduces a focusing factor into the cross-entropy loss function, making the model focus more on hard-to-classify samples. This modulation factor dynamically adjusts the loss weight based on the difficulty of classifying a sample, reducing the weight for easily classified samples, thus addressing the issue of data imbalance. Additionally, Focal Loss incorporates a class balance factor to further balance the distribution of different classes, improving the model’s performance on imbalanced datasets.
The formula for the Focal Loss that we used is as follows:
where is the predicted probability for a sample, and when the label of a positive sample is 1, . The term is the class balance factor, used to balance the ratio of positive and negative samples. The term is the focusing factor, which reduces the loss contribution from easy samples and ensures the model pays more attention to hard-to-classify samples. In our model, through extensive parameter tuning experiments, we set to 0.9 and to 2.
4. Experiments
4.1. Datasets and Evaluation Metrics
To thoroughly assess the effectiveness of the proposed method, we conduct extensive experiments on two widely recognized benchmark datasets for AMT tasks, i.e., MAPS dataset [19] and MAESTRO dataset [26].
The MAPS dataset is one of the key benchmark datasets in the field of automatic music transcription. It provides high-quality piano audio recordings and their aligned MIDI files, covering various piano timbres, including recordings from grand pianos, upright pianos, and synthetic pianos. The audio quality of the MAPS dataset reaches CD-level (16-bit, 44 kHz sampling rate), with a total size of approximately 40 GB, which is equivalent to about 65 h of recording time. The dataset includes single notes, chords, and complete music pieces, with all audio files precisely aligned with MIDI files that record detailed information for each note. Due to its diversity and high quality, the MAPS dataset is widely used for training and evaluating automatic music transcription models. The dataset consists of 210 synthetic recordings and 60 real recordings. Following the approach in [31,32], we use the synthetic music as the training set and the real piano recordings as the test set to validate the effectiveness of our model.
The MAESTRO dataset is a large-scale dataset specifically designed for automatic music transcription research, particularly for piano music. It contains over 200 h of solo piano recordings and their aligned MIDI files. The recordings in the MAESTRO dataset come from international piano competitions, performed by professional pianists on grand pianos, utilizing a high-precision MIDI capture and playback system. These recordings not only boast exceptional audio quality but also include detailed metadata for each audio file, such as composer, piece title, and performance year. The MAESTRO dataset is divided into training, validation, and test sets, providing researchers with a rich and comprehensive resource for developing and evaluating advanced automatic music transcription systems.
For a quantitative assessment of the effectiveness of the proposed method, we introduce three evaluation metrics, encompassing Precision, Recall and F1 score [33], to evaluate the system performance at both the frame-level and note-level metrics. The formulas are as follows:
where TP is the number of true positives, FP is the number of false positives and FN is the number of false negatives.
4.2. Implementation Details
The proposed method is built upon the PyTorch 1.13.1 deep learning framework and implemented using the PyTorch Geometric (PyG) machine learning library on an NVIDIA TITAN RTX (24 GB) platform.
The initial input audio sampling rate is set to 16 kHz, covering the frequency of the highest piano note, C8 (4186 Hz). Then, a short-time Fourier transform (STFT) is applied to the audio segments using a Hann window function to extract the spectrogram. Finally, the spectrogram is converted to a log Mel spectrogram using Mel filters, which serves as the input to our model. The signal is represented by 229 log-spaced frequency bins, with a hop length of 512 and an FFT window size of 2048.
We employ the Adam optimizer to train the entire network model, with an initial learning rate of 5 , which decays to 0.98 times its original value every 10,000 iterations.
4.3. Comparison with the SOTA
To facilitate a comparison with cutting-edge algorithms, we have selected the most classical algorithms from four distinct solutions. These include SHA [34], SPNRM [20], S3F [35], and CBLSTM [32]. Additionally, we have reproduced four recent works, S2S [27], HRT [36], HPPNet [37] and CR-GCN [38]. These eight reference methods, along with our proposed model, were evaluated on the same dataset for comparative analysis.
The experimental results based on the MAPS dataset are presented in Table 1. Overall, deep learning models still demonstrate significant advantages in handling polyphonic piano transcription compared to the other three methods. In terms of note-level metrics, HRT achieves the highest F1 score at 85.03%, while our method ranks third with an F1 score of 84.36%. For the Recall metric, our method ranks second with a score of 83.94%. While our method slightly trails behind HRT in F1 score, the design of DAFE-MSGAT provides some advantages. Specifically, our dual attention mechanism enables more refined time-frequency feature extraction, which helps capture subtle differences in polyphonic transcription that traditional methods, even HRT, might overlook. This qualitative improvement, though not fully reflected in the numerical F1 score, offers greater flexibility in detecting complex note patterns. For frame-level metrics, the S2S method achieves the highest F1 score at 83.75%, and our method scores 79.63%. Although the frame-level performance of our model is lower than S2S, the multi-scale graph attention in DAFE-MSGAT enables more effective dependency modeling between notes. This qualitative distinction allows our model to better capture note relationships across various time frames, which is particularly useful in longer sequences of music, where contextual dependencies are crucial. All five deep learning-based methods achieve high scores in this regard. However, the overall results considering offset are less satisfactory. Once a note is triggered, its energy decays over time, making it challenging to detect the note duration accurately.

Table 1.
Transcription results evaluated on the MAPS dataset (the top three indicators with the best results are represented in red font, green font, and blue font, respectively).
The experimental results based on the MAESTRO dataset are presented in Table 2. Due to the significant gap between deep learning models and traditional methods on the MAPS dataset, we have only listed the experimental results of five deep learning algorithms on the MAESTRO dataset. It can be observed that HPPnet achieved the best F1 scores on both the frame-level and note-level metrics. Our method demonstrated excellent performance in frame-level metrics, achieving the highest Recall rate of 95.21% and the second-highest F1 score of 92.79%. While HPPNet achieves state-of-the-art results, it faces challenges in offset detection and generalizing to instruments with less stable pitch. Additionally, HPPNet’s harmonic dilated convolution, while effective, is computationally expensive, and future optimizations are necessary to reduce its complexity. In contrast, our model, though performing slightly lower on F1 metrics, offers a flexible and scalable framework that can be adapted to a wider range of polyphonic transcription tasks with potentially fewer computational constraints. Compared to the MAPS dataset, the results from the MAESTRO dataset generally improved by 12%. This is because the MAESTRO dataset is three times larger, and models trained on a larger dataset have a significant advantage.
Table 2.
Transcription results evaluated on the MAESTRO dataset (the top three indicators with the best results are represented in red font, green font, and blue font, respectively).
4.4. Transcription Results
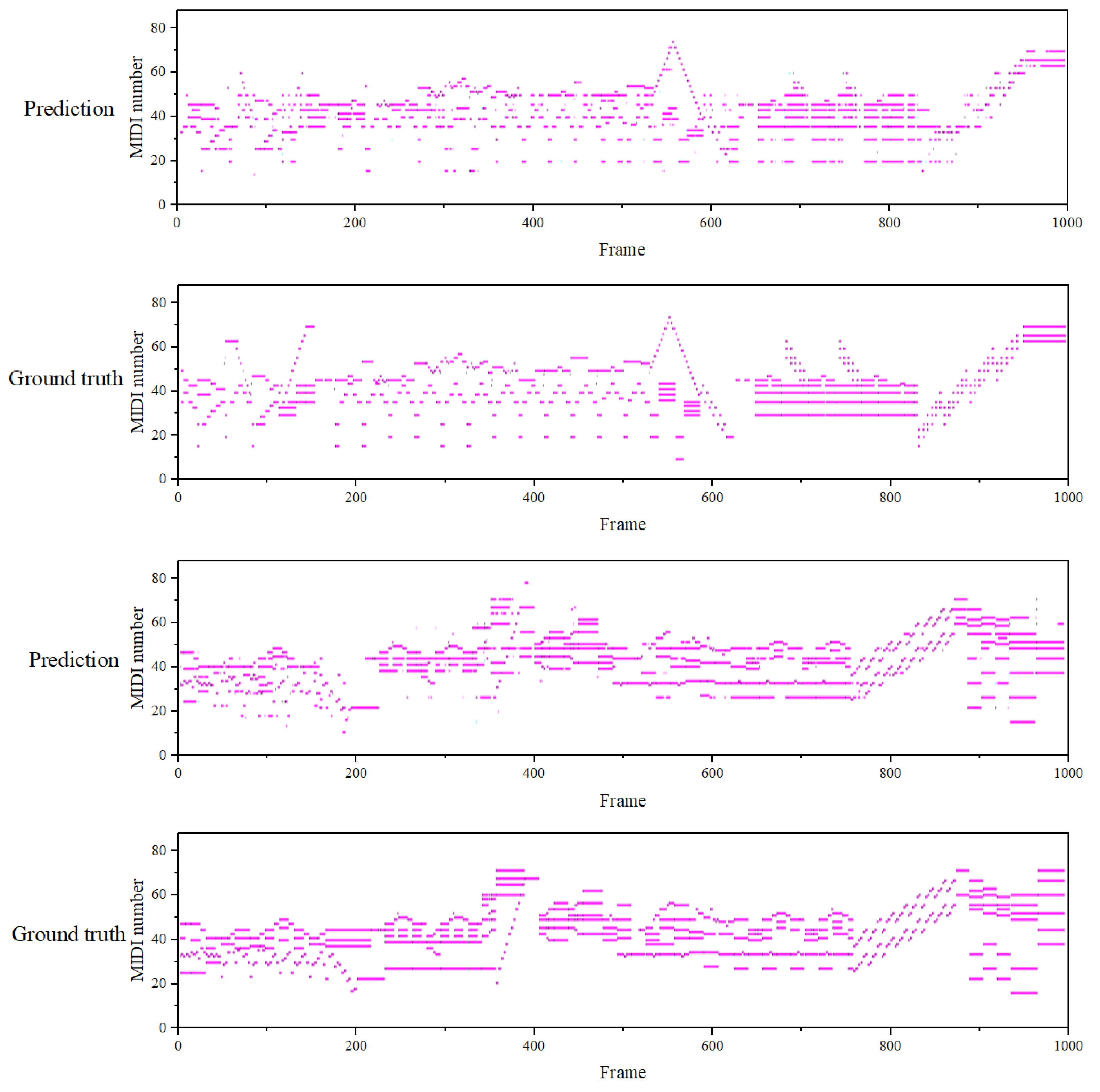
We present the transcription results for two 1000-frame music segments from the MAPS dataset. As shown in Figure 5, the abscissa represents audio frames, and the ordinate represents the notes triggered in the current audio frame, encoded using MIDI numbers, with a total of 88 notes, where frames represent the time information and the MIDI note numbers represent the frequency information. The visualization results indicate that our method has fewer errors at the frame level and the transcription results are close to the ground truth. Specifically, the dual attention mechanism in our model enhances the time-frequency feature extraction by dynamically focusing on relevant time frames and frequencies. Compared to CNN-based models, which often struggle with capturing long-range temporal dependencies and subtle frequency shifts, our model is able to maintain a more precise alignment between time and frequency, as seen in the clear distinction between note onsets and offsets. For example, in scenarios involving chord transitions, the requirements for time-frequency feature extraction are significantly higher. As observed in the first piano roll between time steps 500 and 600, our transcription results align closely with the ground truth. This demonstrates the effectiveness of our model in accurately capturing time-frequency features in complex musical passages.
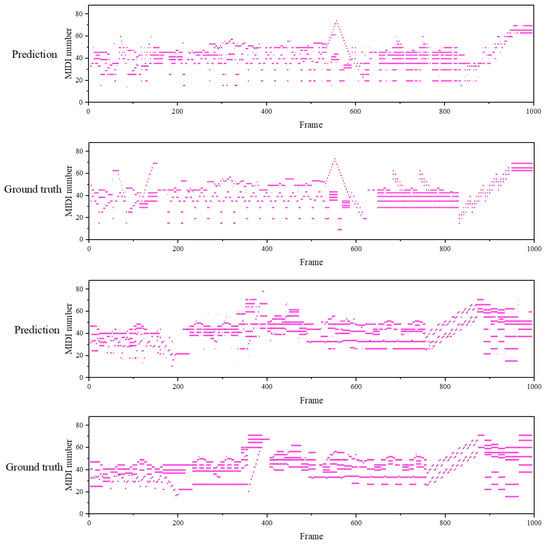
Figure 5.
The visualization results of the piano scores transcribed by our model.
4.5. Ablation Study
We have conducted comprehensive ablation experiments to assess the performance of the proposed methods, including the effectiveness of the DAFE, the availability of the MSGAT, and the validity of the Focal Loss.
4.5.1. Effectiveness of the DAFE
To validate the effectiveness of the DAFE, we replace it with a standard convolutional layer and then retrained the entire network. The performance results are shown in the third row of Table 3. Comparing this with the last row, the network performance decreases by 2.47% and 5.54% in F1 scores at the note level and frame level, respectively, after replacing the DAFE. This highlights the limitations of traditional convolutional neural networks in capturing time-frequency features, particularly in handling complex polyphonic music signals, where they struggle to fully extract the rich information. In contrast, the DAFE effectively emphasizes important frequency information and accurately captures the dynamic changes in notes, thereby enhancing the overall transcription performance.
Table 3.
The impact of different modules (the crude body datas represent the best result).
4.5.2. Availability of the MSGAT
We removed MSGAT from the model and then retrained the entire network. The performance results are shown in the fourth row of Table 3. By comparing this with the last row, we can observe a significant decline of 7.93% and 7.47% in network performance in F1 scores at the note level and frame level, respectively. This fully demonstrates the necessity of the MSGAT network for the overall model. The MSGAT, through the graph attention mechanism and multi-scale processing, effectively captures the complex dependencies between notes in polyphonic piano music. It not only focuses on the relationships between local notes but also understands their positions and roles within the global musical structure, significantly enhancing the transcription performance.
4.5.3. Validity of the Focal Loss
To validate the rationale behind using Focal Loss, we replace it with binary cross-entropy loss and retrain the entire network. The performance results are shown in the fifth row of Table 3. Comparing this with the last row, there is a substantial decrease in model performance, with F1 scores dropping by 34.99% and 43.68% at the note level and frame level, respectively. Focal Loss demonstrates significant advantages in focusing the model’s attention on hard-to-classify samples, ensuring effective handling of sparse and imbalanced label data.
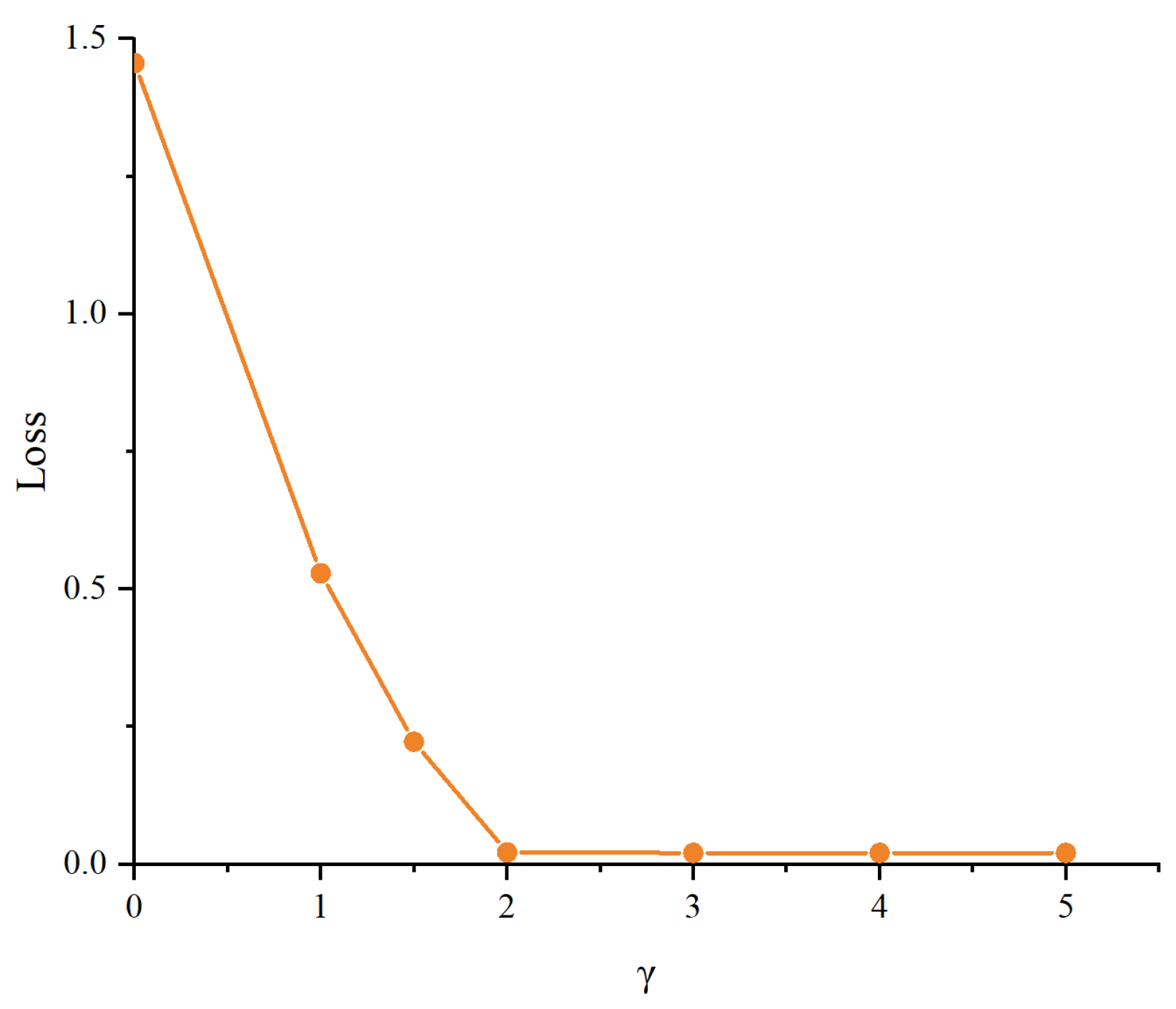
We also conducted experiments on the parameter in Focal Loss to observe the changes in the loss function under different values. Figure 6 shows that as increases, the loss gradually decreases and stabilizes around a value of approximately 2. This indicates that appropriately choosing the value can effectively reduce the loss and improve the model’s performance in polyphonic piano transcription tasks. Ultimately, we selected a value of 2 to ensure that Focal Loss fully leverages its advantages in handling imbalanced data, enhancing the model’s focus on hard-to-classify samples.
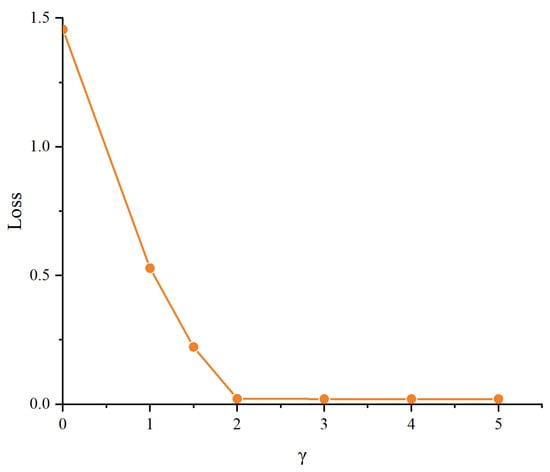
Figure 6.
The impact of different values of on the model’s loss.
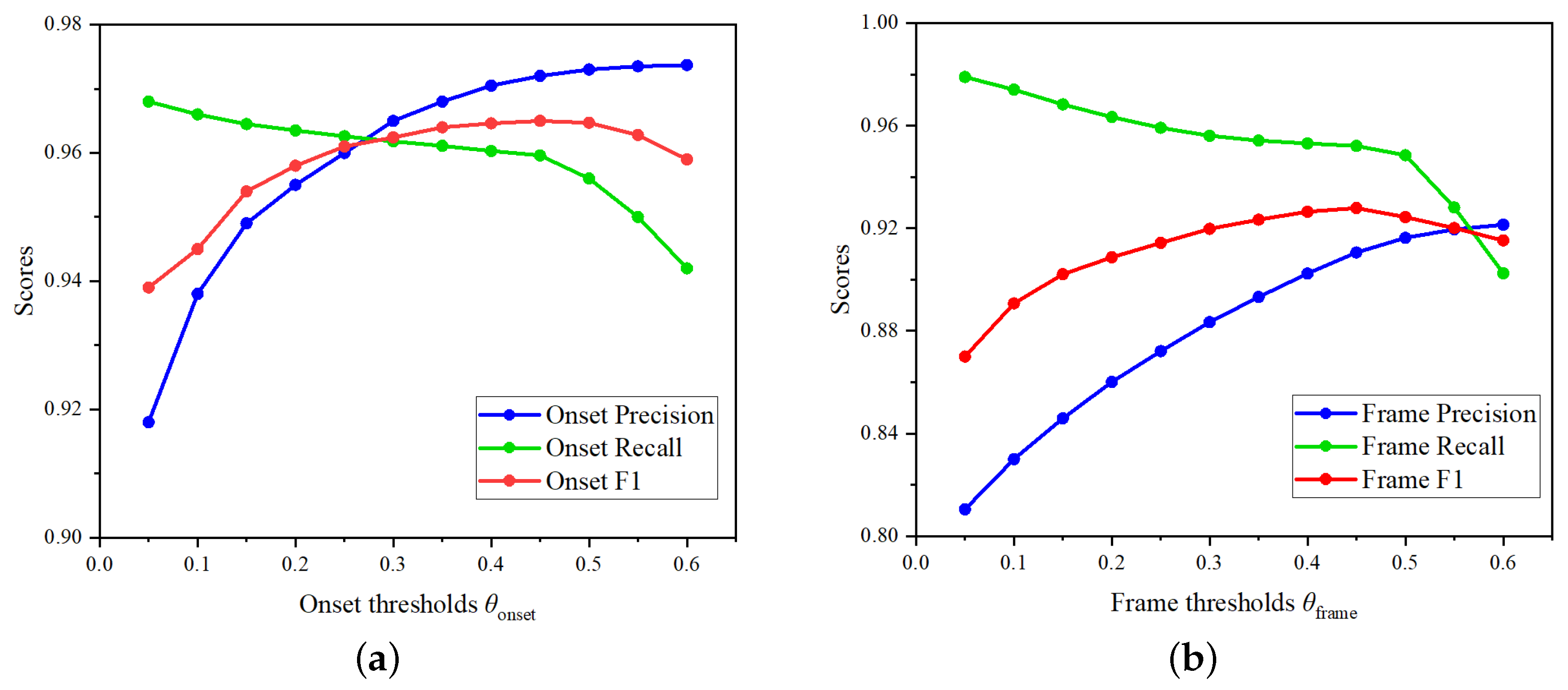
4.6. Effects of Different Threshold Values ,
To systematically evaluate different thresholds for piano transcription, we conducted experiments by adjusting the onset and frame thresholds between 0.05 and 0.60. Figure 7 details the Precision, Recall, and F1 scores for polyphonic piano transcription under various threshold settings. The experimental results show that as the thresholds increase, Precision improves while Recall decreases, indicating that higher thresholds, while enhancing Precision, lead to the omission of some notes. Specifically, we observed that at higher thresholds, the model can more accurately identify correct notes, but it misses more notes, particularly in complex polyphonic passages. This trade-off highlights the challenge of balancing Precision and Recall. By comparing F1 scores across different thresholds, we found that the F1 scores remain stable between 0.35 and 0.5, suggesting that this range achieves a good balance between Precision and Recall. Therefore, we set the threshold to 0.45, which provided an optimal balance based on multiple evaluation metrics.
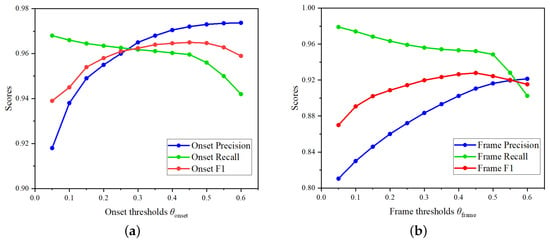
Figure 7.
The impact of different thresholds on Precision, Recall and F1 score. (a) Performance indicators evaluated with different onset thresholds . (b) Performance indicators evaluated with different frame thresholds .
4.7. Error Analysis
Error analysis was carried out on several transcribed pieces, and we identified two common types of errors. The first and most frequent error relate to offset detection. Our model often struggles to determine the exact duration of sustained notes, especially when their energy gradually decays over time. In such cases, the subtle decrease in energy makes it difficult for the model to detect when a note ends. The second common issue is harmonic confusion. In complex polyphonic sections, the model sometimes confuses harmonically related notes. The harmonic structure of piano notes, especially the presence of overtones, can obscure the fundamental frequencies of some notes, leading the model to mistakenly identify or group notes that sound similar. Although the dual attention mechanism in our model improves its ability to capture fine-grained details, harmonic interference in dense polyphonic music still poses a significant challenge.
5. Conclusions
In this paper, we propose a DAFE-MSGAT for polyphonic piano transcription from the perspectives of time-frequency feature enhancement and capturing interdependencies between notes. Specifically, in the time-frequency attention feature enhancement stage, we propose the DAFE to overcome the limitations of CNNs in capturing audio signal details. In the phase of multi-scale graph feature fusion, we design the MSGAT, which utilizes the implicit dependency modeling between notes to fully mine the node information. We conduct comprehensive comparative experiments on two publicly available benchmark datasets against SOTA methods. The experimental results demonstrate that our proposed approach achieves competitive or even superior detection results compared to the contrasted methods. Moreover, comprehensive ablation analysis experiments are undertaken in this paper to validate the efficacy of the proposed individual modules. The findings suggest that our approach provides an effective solution for polyphonic piano transcription tasks. The proposed model’s architecture could be extended to other domains, such as multi-instrument transcription, speech separation, and sound event detection. For future research, we recommend exploring the generalization of the model to more diverse and noisy datasets, as well as optimizing computational efficiency to better support real-time applications. Further development in these areas could enhance the model’s applicability to a wider range of tasks in music information retrieval.
Author Contributions
R.C.: Formal analysis, Supervision, Software and Writing—original draft. Z.L.: Software, Validation, Writing—original draft. Z.Y.: Conceptualization, Methodology, Formal analysis, Writing—reviewing. B.L.: Investigation, Formal analysis, Visualization. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by the Fujian Provincial Education Science “14th Five-Year Plan” Special Research Project for 2023, titled “Innovative Practices in Art Education from the Perspective of the Metaverse” (Project No.: Fjxczx23-007), and by the Xiamen Municipal Special Funds for Cultural and Artistic Development for 2024, for the project “Large-Scale Symphony Choir ‘Chen Jiageng Song Set’ ” (Project No.: WT202408).
Data Availability Statement
The datasets are available within the link http://www.tsi.telecom-paristech.fr/aao/en/category/database/ accessed on 1 October 2024.
Acknowledgments
The authors would like to extend our gratitude to Wei Xiong and Lina Gao for their help during the experimental process and to Yuanzi Li for her guidance during the writing of the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Benetos, E.; Dixon, S.; Duan, Z.; Ewert, S. Automatic music transcription: An overview. IEEE Signal Process. Mag. 2018, 36, 20–30. [Google Scholar] [CrossRef]
- Raphael, C. Automatic Transcription of Piano Music. In Proceedings of the 2002 3rd International Conference on Music Information Retrieval, Paris, France, 13–17 October 2002. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Bello Correa, J.P. Towards the Automated Analysis of Simple Polyphonic Music: A Knowledge-Based Approach. Ph.D. Thesis, Queen Mary University of London, London, UK, 2003. [Google Scholar]
- Goto, M. A real-time music-scene-description system: Predominant-F0 estimation for detecting melody and bass lines in real-world audio signals. Speech Commun. 2004, 43, 311–329. [Google Scholar] [CrossRef]
- Klapuri, A.; Davy, M. Signal Processing Methods for Music Transcription; Springer: New York, NY, USA, 2007. [Google Scholar]
- Nam, J.; Ngiam, J.; Lee, H.; Slaney, M. A Classification-Based Polyphonic Piano Transcription Approach Using Learned Feature Representations. In Proceedings of the 12th International Society for Music Information Retrieval Conference (ISMIR 2011), Miami, FL, USA, 24–28 October 2011; Citeseer: Princeton, NJ, USA, 2011; pp. 175–180. [Google Scholar]
- Böck, S.; Schedl, M. Polyphonic piano note transcription with recurrent neural networks. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: New York, NY, USA, 2012; pp. 121–124. [Google Scholar]
- Sigtia, S.; Benetos, E.; Dixon, S. An end-to-end neural network for polyphonic piano music transcription. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 927–939. [Google Scholar] [CrossRef]
- Kelz, R.; Dorfer, M.; Korzeniowski, F.; Böck, S.; Arzt, A.; Widmer, G. On the potential of simple framewise approaches to piano transcription. arXiv 2016, arXiv:1612.05153. [Google Scholar]
- Kelz, R.; Böck, S.; Widnaer, C. Multitask learning for polyphonic piano transcription, a case study. In Proceedings of the 2019 International Workshop on Multilayer Music Representation and Processing (MMRP), Milan, Italy, 23–24 January 2019; IEEE: New York, NY, USA, 2019; pp. 85–91. [Google Scholar]
- Benetos, E.; Dixon, S.; Giannoulis, D.; Kirchhoff, H.; Klapuri, A. Automatic music transcription: Challenges and future directions. J. Intell. Inf. Syst. 2013, 41, 407–434. [Google Scholar] [CrossRef]
- Gardner, J.; Simon, I.; Manilow, E.; Hawthorne, C.; Engel, J. MT3: Multi-task multitrack music transcription. arXiv 2021, arXiv:2111.03017. [Google Scholar]
- Duan, Z.; Temperley, D. Note-level Music Transcription by Maximum Likelihood Sampling. In Proceedings of the 15th International Society for Music Information Retrieval Conference (ISMIR 2014), Taipei, Taiwan, 27–31 October 2014; Citeseer: Princeton, NJ, USA, 2014; pp. 181–186. [Google Scholar]
- Fernandez, A. Onsets and Velocities: Affordable Real-Time Piano Transcription Using Convolutional Neural Networks. In Proceedings of the 2023 31st European Signal Processing Conference (EUSIPCO), Helsinki, Finland, 4–8 September 2023; IEEE: New York, NY, USA, 2023; pp. 151–155. [Google Scholar]
- Meng, Z.; Chen, W. Automatic music transcription based on convolutional neural network, constant Q transform and MFCC. J. Phys. Conf. Ser. 2020, 1651, 012192. [Google Scholar] [CrossRef]
- Aljamea, H.H.; Mattar, E.A. Automatic music transcription using CNN neural networks on segmented audio. In Proceedings of the 4th Smart Cities Symposium (SCS 2021), Online Conference, 21–23 November 2021; IET: London, UK, 2021; Volume 2021, pp. 333–337. [Google Scholar]
- Benetos, E.; Dixon, S.; Giannoulis, D.; Kirchhoff, H.; Klapuri, A. Automatic music transcription: Breaking the glass ceiling. In Proceedings of the 13th International Society for Music Information Retrieval Conference (ISMIR 2012), Porto, Portugal, 8–12 October 2012. [Google Scholar]
- Emiya, V.; Badeau, R.; David, B. Multipitch estimation of piano sounds using a new probabilistic spectral smoothness principle. IEEE Trans. Audio Speech Lang. Process. 2009, 18, 1643–1654. [Google Scholar] [CrossRef]
- Duan, Z.; Pardo, B.; Zhang, C. Multiple fundamental frequency estimation by modeling spectral peaks and non-peak regions. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 2121–2133. [Google Scholar] [CrossRef]
- Smaragdis, P.; Brown, J.C. Non-negative matrix factorization for polyphonic music transcription. In Proceedings of the 2003 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (IEEE Cat. No. 03TH8684), New Paltz, NY, USA, 19–22 October 2003; IEEE: New York, NY, USA, 2003; pp. 177–180. [Google Scholar]
- Vincent, E.; Bertin, N.; Badeau, R. Adaptive harmonic spectral decomposition for multiple pitch estimation. IEEE Trans. Audio Speech Lang. Process. 2009, 18, 528–537. [Google Scholar] [CrossRef]
- Su, L.; Yang, Y.H. Combining spectral and temporal representations for multipitch estimation of polyphonic music. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1600–1612. [Google Scholar] [CrossRef]
- Sigtia, S.; Benetos, E.; Cherla, S.; Weyde, T.; Garcez, A.; Dixon, S. An RNN-based music language model for improving automatic music transcription. In Proceedings of the 15th International Society for Music Information Retrieval Conference (ISMIR 2014), Taipei, Taiwan, 27–31 October 2014; Society for Music Information Retrieval, 2014; pp. 53–58. [Google Scholar]
- Sturm, B.L.; Santos, J.F.; Ben-Tal, O.; Korshunova, I. Music transcription modelling and composition using deep learning. arXiv 2016, arXiv:1604.08723. [Google Scholar]
- Hawthorne, C.; Stasyuk, A.; Roberts, A.; Simon, I.; Huang, C.Z.A.; Dieleman, S.; Elsen, E.; Engel, J.; Eck, D. Enabling factorized piano music modeling and generation with the MAESTRO dataset. arXiv 2018, arXiv:1810.12247. [Google Scholar]
- Hawthorne, C.; Simon, I.; Swavely, R.; Manilow, E.; Engel, J. Sequence-to-sequence piano transcription with transformers. arXiv 2021, arXiv:2107.09142. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Raguraman, P.; Mohan, R.; Vijayan, M. Librosa based assessment tool for music information retrieval systems. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; IEEE: New York, NY, USA, 2019; pp. 109–114. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhang, W.; Chen, Z.; Yin, F. Multi-Pitch Estimation of Polyphonic Music Based on Pseudo Two-Dimensional Spectrum. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2095–2108. [Google Scholar] [CrossRef]
- Hawthorne, C.; Elsen, E.; Song, J.; Roberts, A.; Simon, I.; Raffel, C.; Engel, J.; Oore, S.; Eck, D. Onsets and frames: Dual-objective piano transcription. arXiv 2017, arXiv:1710.11153. [Google Scholar]
- Yacouby, R.; Axman, D. Probabilistic extension of precision, recall, and f1 score for more thorough evaluation of classification models. In Proceedings of the First Workshop on Evaluation and Comparison of NLP Systems, Online; 2020; pp. 79–91. [Google Scholar]
- Klapuri, A. Multiple fundamental frequency estimation by summing harmonic amplitudes. In Proceedings of the 7th International Conference on Music Information Retrieval, Victoria, BC, Canada, 8–12 October 2006; pp. 216–221. [Google Scholar]
- Benetos, E.; Weyde, T. Multiple-F0 estimation and note tracking for Mirex 2015 using a sound state-based spectrogram factorization model. In Proceedings of the 11th Annual Music Information Retrieval eXchange (MIREX’15), Malaga, Spain, 26–30 October 2015; pp. 1–2. [Google Scholar]
- Kong, Q.; Li, B.; Song, X.; Wan, Y.; Wang, Y. High-Resolution Piano Transcription With Pedals by Regressing Onset and Offset Times. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3707–3717. [Google Scholar] [CrossRef]
- Wei, W.; Li, P.; Yu, Y.; Li, W. Hppnet: Modeling the harmonic structure and pitch invariance in piano transcription. arXiv 2022, arXiv:2208.14339. [Google Scholar]
- Xiao, Z.; Chen, X.; Zhou, L. Polyphonic piano transcription based on graph convolutional network. Signal Process. 2023, 212, 109134. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).