
Built-In Self-Test Architecture Enabling Diagnosis for Massive Embedded Memory Banks in Large SoCs

 ,
,  ,
,
Abstract
:1. Introduction
2. Background
2.1. Embedded Memory Organization
2.2. MBIST Architectures for Diagnosis
- Read/Write Controller is an input to the memory as it decides when its time to write a new test pattern or read it back.
- Address Generator is also an input to the memory as it decides the address for which the test pattern has to be written to or read from.
- Pattern Generator decides the pattern to write at a specific address in the memory. It also provides the reference pattern to the Output Evaluator, which can then compare it with the output of the flash memory.
- Output Evaluator simply compares the output of the memory at a given address with the expected pattern provided by the Pattern Generator. In case of a mismatch, a fault is detected.
- Count mode: At the end of the memory test, the MBIST makes the total fail count available to the master.
- Stop-on-fail mode: During the memory test, the MBIST module stops each time a fault is detected and provides the fault’s position and type. After a stop event, the master must resume the verification.
2.3. Linear Search Method
| Algorithm 1 Linear Search for N MBISTs |
| procedure linearSearch(N) Start all MBISTs while Test not finished do for each integer i in N do if MBIST[i] found a fault then Retrieve fault coordinate Restart MBIST[i] break else Continue end if end for end while end procedure |
- Banks 0 and 2 represent randomly distributed faults with various shapes.
- Bank 1 has a faulty bit cell at the junction of the “cross” of failing bit cells. That faulty bit cell appears to work correctly but negatively affects nearby cells.
- Failures in Bank 3 represent a failing sense amplifier.
- T0. At the start, each MBIST is in the running phase and is testing the memory in search of faults.
- T1. The MBIST of Bank 0 is the first to find a fault; it stops the bank test and is waiting for the CPU read. The other MBISTs are still running and are searching for faults.
- T2. The CPU accesses MBIST 0; MBIST 3 stops and waits while the other MBISTs are still running.
- T3. The CPU resumes MBIST 0. All the other MBISTs are stopped and are waiting for CPU intervention.
- T4. The CPU starts analyzing MBIST 1. MBISTs 2 and 3 are stopped and are waiting for the CPU read, while MBIST 0 is again running and is searching for faults.
- T5. MBIST 0 stops and is waiting for the CPU, MBIST 1 is running. MBISTs 2 and 3 are still waiting for CPU intervention.
- T6. The CPU starts analyzing MBIST 0. All other MBISTs are stopped and are waiting for CPU attention (MBIST 3 has been waiting since T3).
3. Proposed Approach
- A linear search method, which is considered as a baseline for comparison.
- Two versions of a binary search method: without and with priority shifting.
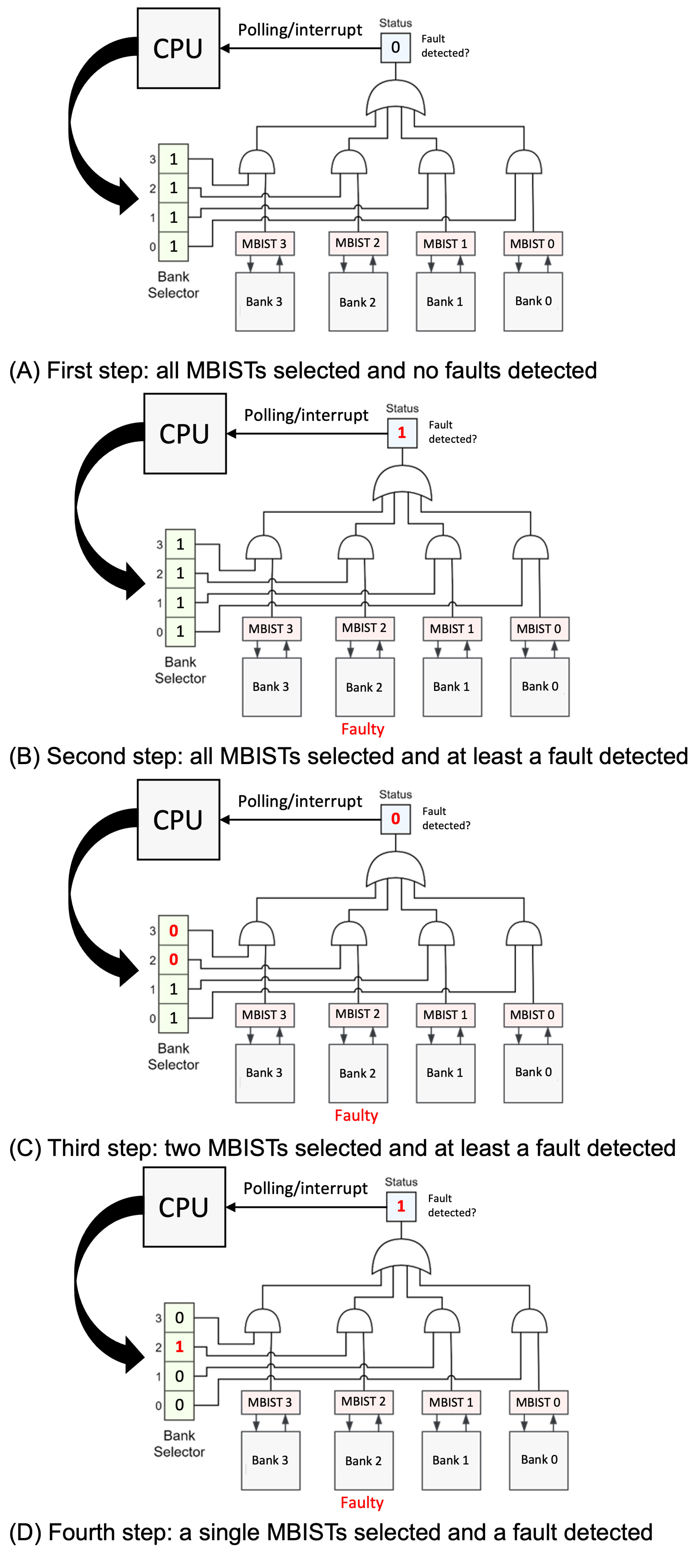
3.1. Hardware Architecture for Diagnosis
3.2. Binary Search Approaches
| Algorithm 2 Binary search for N MBISTs |
| procedure BinarySearch(N) Start all MBISTs Start = 0 End = N − 1 Enable all MBIST outputs while Test not finished do if common status bit is 1 then while end − start != 0 do middle = (start + end)/2 Enable output for MBIST[start] to MBIST[middle] if common status bit is 1 then end = middle Continue else start = middle end if end while end if end while end procedure |
- A
- Figure 8a shows all the failures in the memory. Without an on-chip memorization limit, the total test time is the only difference between the three access methods presented in this paper.
- B
- In Figure 8b, there is a limit to the on-chip memory available to store diagnostic information. Using the linear and binary search approaches, the BIST of Bank 0 is always served first. Bank 1’s BIST is served next and fills the remaining reserved memory space. As can be seen, no information about Banks 2 and 3 reaches the external world as the reserved memory is already saturated when their MBISTs are served.
- C
- Figure 8c shows the effect of the binary search with priority shifting in case the memory limitation is still in place. The result is a fairer memory representation with partial information from all the memory banks.
4. Experimental Results
4.1. Sparse Faults Randomly Distributed
- Single-bit error (SBE) only: at most, a single bit per page can be faulty;
- Pseudo-randomly generated addresses: the indexes of faulty pages are calculated in a pseudo-random manner;
- Number of injected errors is between 0 and 90 k, which roughly corresponds to 0.03% of the bits in the memory.
4.2. Test Time Comparison
4.3. Progress of Bank Verification
- Faults in Banks 0 and 4 start to be analyzed, with Bank 0 receiving the most attention;
- All faults in the other banks are not analyzed.
- Faults in Banks 0 and 4 are completely analyzed at 30% test time;
- Faults in Bank 8 are starting to be analyzed;
- Banks 12 and 14 are not even reached at this point.
- For the linear and binary search algorithms, the intrinsic priority of the lowest-indexed banks is clear. Banks 0 to 4 are completely represented in both cases. The other banks are analyzed just partially or not analyzed at all, e.g., Banks 13 and 14.
- The saturation scenario is entirely different for the binary search with priority shifting algorithm. All the banks are at least partially analyzed, and a couple are already wholly analyzed. This scenario is much fairer in terms of representation. Once analyzed, the 24 KB of collected diagnostic information will reveal the partial situation of all the memory banks, making diagnosis of the device easier.
4.4. Data from Production Tests
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Van De Goor, A.; Gaydadjiev, G.; Hamdioui, S. Memory testing with a RISC microcontroller. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE 2010), Dresden, Germany, 8–12 March 2010. [Google Scholar]
- Bai, X.; Fang, Y.; Lin, W.; Wang, L.; Ju, B.-F. Saliency-Based Defect Detection in Industrial Images by Using Phase Spectrum. IEEE Trans. Ind. Inform. 2014, 10, 2135–2145. [Google Scholar] [CrossRef]
- Yeh, J.C.; Kuo, S.F.; Wu, C.W.; Huang, C.T.; Chen, C.H. A systematic approach to reducing semiconductor memory test time in mass production. In Proceedings of the 2005 IEEE International Workshop on Memory Technology, Design, and Testing (MTDT’05), Taipei, Taiwan, 3–5 August 2005; pp. 97–102. [Google Scholar] [CrossRef]
- Singh, A.; Kumar, G.M.; Aasti, A. Controller Architecture for Memory BIST Algorithms. In Proceedings of the IEEE International Students’ Conference on Electrical, ELectronics and Computer Science (SCEECS), Bhopal, India, 22–23 February 2020. [Google Scholar]
- Chen, J.T.; Khare, J.; Walker, K.; Shaikh, S.; Rajski, J.; Maly, W. Test response compression and bitmap encoding for embedded memories in manufacturing process monitoring. In Proceedings of the International Test Conference, Baltimore, MD, USA, 1 November 2001. [Google Scholar]
- Schanstra, I.; Lukita, D.; van de Goor, A.J.; Veelenturf, K.; van Wijnen, P.J. Semiconductor Manufacturing Process Monitoring using Built-In Self-Test for Embedded Memories. In Proceedings of the International Test Conference, Washington, DC, USA, 18–23 October 1998. [Google Scholar]
- Benso, A.; Carlo, S.D.; Natale, G.D.; Prinetto, P.; Bodoni, M.L. A programmable BIST architecture for clusters of multiple-port SRAMs. In Proceedings of the International Test Conference 2000 (IEEE Cat. No.00CH37159), Atlantic City, NJ, USA, 3–5 October 2000; pp. 557–566. [Google Scholar] [CrossRef]
- Kahng, A.B.; Kang, I. Co-optimization of memory BIST grouping, test scheduling, and logic placement. In Proceedings of the 2014 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 24–28 March 2014; pp. 1–6. [Google Scholar] [CrossRef]
- McLaurin, T.; Frederick, F.; Slobodnik, R. The DFT challenges and solutions for the ARM® Cortex™-A15 Microprocessor. In Proceedings of the 2012 IEEE International Test Conference, Anaheim, CA, USA, 5–8 November 2012; pp. 1–9. [Google Scholar] [CrossRef]
- Das, K.S.; Prakash, P. Automatic MBIST Scheduling Engine. In Proceedings of the 2019 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 26–27 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Bernardi, P.; Ciganda, L. An Adaptive Low-Cost Tester Architecture Supporting Embedded Memory Volume Diagnosis. IEEE Trans. Instrum. Meas. 2012, 61, 1002–1018. [Google Scholar] [CrossRef]
- Silveira, R.; Qureshi, Q.; Zeli, R. Flexible architecture of memory BISTs. In Proceedings of the 2018 IEEE 19th Latin-American Test Symposium (LATS), Sao Paulo, Brazil, 12–14 March 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ghale, S.B.; Namita, P. Design and Implementation of Memory BIST for Hybrid Cache Architecture. In Proceedings of the 2021 6th International Conference on Communication and Electronics Systems (ICCES), Coimbatre, India, 8–10 July 2021; pp. 26–31. [Google Scholar] [CrossRef]
- Zeli, R.; Silveira, R.; Qureshi, Q. SoC Memory Test Optimization using NXP MTR Solutions. In Proceedings of the 2019 IEEE Latin American Test Symposium (LATS), Santiago, Chile, 11–13 March 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Hong, W.; Choi, J.; Chang, H. A programmable memory BIST for embedded memory. In Proceedings of the International SoC Design Conference, Busan, Korea, 24–25 November 2008. [Google Scholar]
- Tsai, C.H.; Wu, C.W. Processor-programmable memory BIST for bus-connected embedded memories. In Proceedings of the Design Automation Conference, Yokohama, Japan, 30 January–2 February 2001. [Google Scholar]
- Manzone, A.; Bernardi, P.; Grosso, M.; Rebaudengo, M.; Sanchez, E.; Reorda, M.S. Integrating BIST techniques for on-line SoC testing. In Proceedings of the 11th IEEE International On-Line Testing Symposium, French Riviera, France, 6–8 July 2005; pp. 235–240. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sparse Random Fault Timing Comparison | ||||
|---|---|---|---|---|
| Fault Count (#) | 27,451 | 41,416 | 54,959 | 68,817 |
| Linear Search (ms) | 92 | 138 | 182 | 228 |
| Binary Search (ms) | 68 | 102 | 134 | 168 |
| Binary Search priority shifting (ms) | 69 | 104 | 138 | 173 |
| Percentage of Stored Faults at 10% Test Time for the Different Approaches | |||||
|---|---|---|---|---|---|
| Bank Number | 0 | 4 | 8 | 12 | 14 |
| Linear Search | 66.89% | 35.81% | 0% | 0% | 0% |
| Binary Search | 100% | 28.68% | 0% | 0% | 0% |
| Binary Search, Priority Shifting | 67.97% | 14.18% | 30.32% | 11.98% | 10.51% |
| Percentage of Stored Faults at 30% Test Time | |||||
|---|---|---|---|---|---|
| Bank Number | 0 | 4 | 8 | 12 | 14 |
| Linear Search | 100% | 100% | 14.4% | 0% | 0% |
| Binary Search | 100% | 100% | 34.5% | 0% | 0% |
| Binary Search, Priority Shifting | 100% | 41.71% | 87.5% | 37% | 29.9% |
| Percentage of Stored Faults at 24 KB Diagnostic Memory Saturation | |||||
|---|---|---|---|---|---|
| Bank Number | 0 | 4 | 8 | 12 | 14 |
| Linear Search | 100% | 100% | 38.03% | 0.67% | 0% |
| Binary Search | 100% | 100% | 22.32% | 0% | 0% |
| Binary Search, Priority Shifting | 100% | 36.31% | 75% | 31.75% | 25.28% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bernardi, P.; Guerriero, A.M.; Insinga, G.; Paganini, G.; Carnevale, G.; Coppetta, M.; Mischo, W.; Ullmann, R. Built-In Self-Test Architecture Enabling Diagnosis for Massive Embedded Memory Banks in Large SoCs. Electronics 2024, 13, 303. https://doi.org/10.3390/electronics13020303
Bernardi P, Guerriero AM, Insinga G, Paganini G, Carnevale G, Coppetta M, Mischo W, Ullmann R. Built-In Self-Test Architecture Enabling Diagnosis for Massive Embedded Memory Banks in Large SoCs. Electronics. 2024; 13(2):303. https://doi.org/10.3390/electronics13020303
Chicago/Turabian StyleBernardi, Paolo, Augusto Maria Guerriero, Giorgio Insinga, Giovanni Paganini, Giambattista Carnevale, Matteo Coppetta, Walter Mischo, and Rudolf Ullmann. 2024. "Built-In Self-Test Architecture Enabling Diagnosis for Massive Embedded Memory Banks in Large SoCs" Electronics 13, no. 2: 303. https://doi.org/10.3390/electronics13020303
APA StyleBernardi, P., Guerriero, A. M., Insinga, G., Paganini, G., Carnevale, G., Coppetta, M., Mischo, W., & Ullmann, R. (2024). Built-In Self-Test Architecture Enabling Diagnosis for Massive Embedded Memory Banks in Large SoCs. Electronics, 13(2), 303. https://doi.org/10.3390/electronics13020303