

A Review of Generative Models in Generating Synthetic Attack Data for Cybersecurity

Abstract
:1. Introduction
- We explored the critical features of generative learning and the capabilities of generative models, highlighting their effectiveness in creating new data compared to discriminative models [7]. This comparison is further enriched by a detailed examination of how generative models operate.
- We provide a concise overview of GANs, focusing on their data generation capabilities and architecture. This includes examining various models and techniques that generate diverse image and text data across domains using GANs.
- Next, we comprehensively review various methods for generating synthetic cyberattack data using GANs.
- Finally, we assess the value of synthetically generated attack data by conducting experiments with the NSL-KDD dataset. Specifically, we examine the characteristics of DoS attacks and gauge how well GAN-generated data can improve the training of intrusion detection systems for real-world cyberattack mitigation.
2. Modeling Techniques
2.1. Generative and Discriminative Models
- a. Generative models: The Generative modeling has been widely used in statistics. When applied to machine learning, it has been useful in various fields like natural language processing, visual recognition, speech recognition, and data generation tasks [10]. Naive Bayes [11], Bayesian networks [12], Markov random fields [13], hidden Markov models [14], and linear discriminant analysis (LDA) [15] are some of those generative modeling techniques. The advent of deep learning [16] has sparked the development of the deep generative models like Boltzmann machines [17], restricted Boltzmann machines [18], deep belief networks [19], and deep Boltzmann machines [20] including graphical models like sigmoid belief networks [21], differentiable generator networks [22], variational autoencoders [23] etc. Generative adversarial network [1], which is as popular as GAN, is a type of generative model that received massive attention in recent years due to its remarkable success in generating synthetic data [24].
- b. Discriminative Models: Discriminative models, as their name indicates, are capable of understanding the boundaries amongst the given data points using probability estimates, and are thus widely used in classification approaches. The supervised learning [25] approaches such as logistic regression [26], support vector machine [27], neural networks [28], and nearest neighbor [29] are based on discriminative modeling. When provided with sufficient labeled data, these methods have succeeded in classification tasks [30]. They can learn to discriminate between different types of data and output the instance that belongs to a particular class.
- c. Difference between Generative and Discriminative Models: The generative and discriminative modeling differs in their approach to solving the learning tasks [31]. The discriminator plays more of a classifier role by creating the decision boundary between the different classes. It does not attempt to learn the actual distribution of the data but tries to learn the mapping between the data vector and the label vector, given enough labeled mapping samples. It is more challenging when the generative family handles the modeling of the data distribution and suggests how likely it is that an example belongs to a distribution.Since the model knows the data and its distribution, it is generative and can produce new examples. It is also possible for them to model a distribution by producing convincingly “fake” data that look like they were drawn from that distribution.
2.2. Why Generative Models?
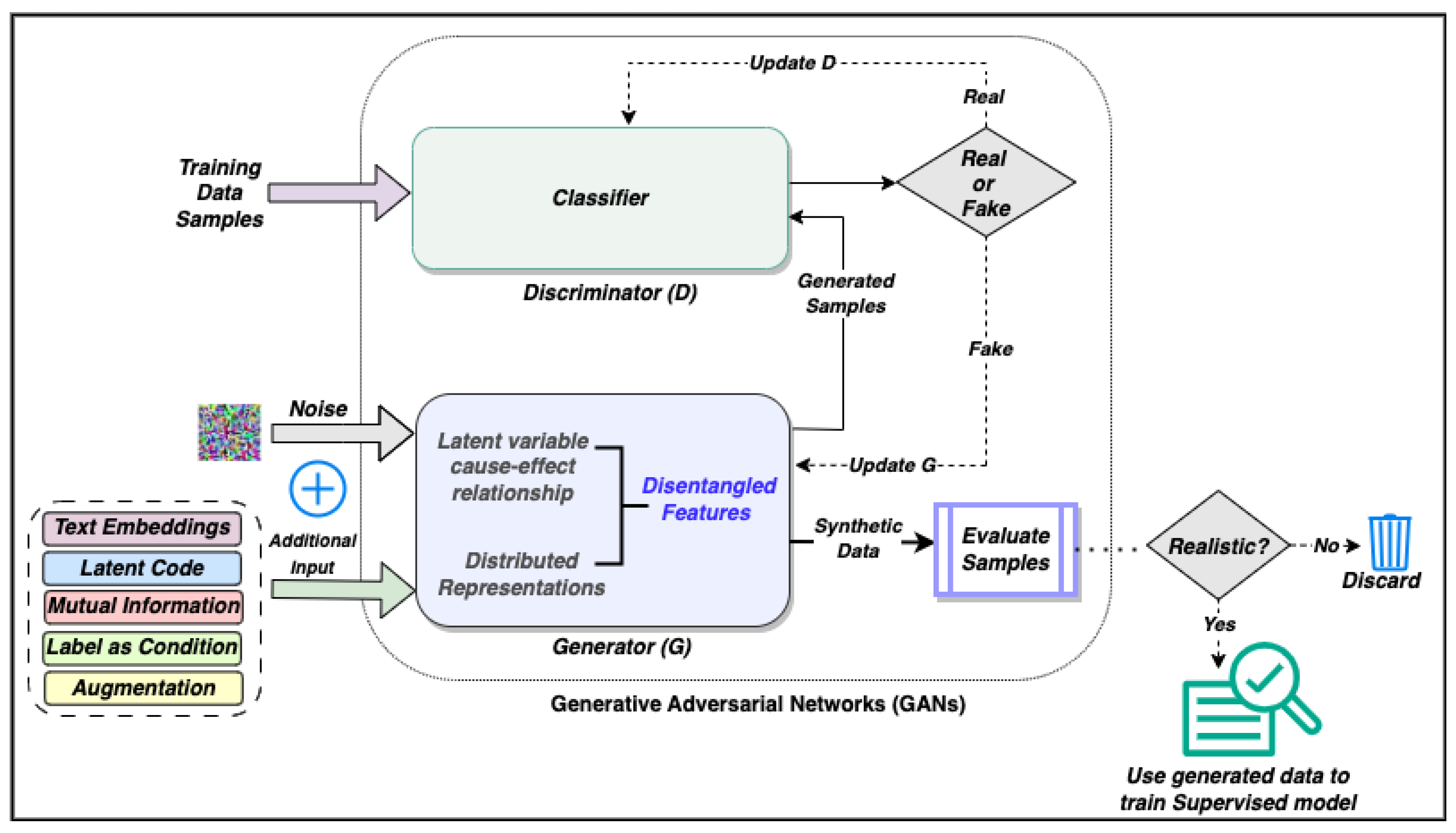
3. Generative Adversarial Networks (GANs)
3.1. Construction of Networks
3.2. Cost Function
3.3. Training of Networks
- False negative—The input is real but the discriminator gives the output as fake: The real data are given to the discriminator. The generator is not involved in this step. The discriminator makes a mistake and classifies the input as fake. This is a training error and the weights of the discriminator are updated using backpropagation.
- True negative—The input is fake and the discriminator gives the output as fake: The generator generates some fake data from random noise in latent space. If the discriminator recognizes this as fake, there is no need to update the discriminator. The weights of the generator should be updated using backpropagation using the loss function value.
- False positive—The input is fake but the discriminator gives the output as real. The discriminator should be updated. The loss function is used to update the weights of the discriminator.
4. Generating Data Using GANs
4.1. Different Techniques in GAN for Generating Data
4.2. Generating Images
4.3. Generating Tabular Synthetic Data
4.3.1. Airline Passenger Name Record (PNR) Generation
4.3.2. Synthesizing Fake Tables
5. Generating Cyberattack Data Using Generative Models
5.1. Flow-Based Network Traffic Generation
5.2. Cyber Intrusion Alert Data Synthesis
5.3. Generating Attack Data Using Adversarial Examples
5.3.1. MalGAN: Generating Malware Adversarial Examples Using GAN
5.3.2. IDSGAN: Generating Adversarial Examples against Intrusion Detection System
5.4. Attack Data Generation Using LLMs
6. Analysis of GAN Generated Synthetic Attack Data
7. Discussion
8. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Shahriar, S. GAN computers generate arts? A survey on visual arts, music, and literary text generation using generative adversarial network. Displays 2022, 73, 102237. [Google Scholar] [CrossRef]
- Yinka-Banjo, C.; Ugot, O.A. A review of generative adversarial networks and its application in cybersecurity. Artif. Intell. Rev. 2020, 53, 1721–1736. [Google Scholar] [CrossRef]
- Cai, Z.; Xiong, Z.; Xu, H.; Wang, P.; Li, W.; Pan, Y. Generative adversarial networks: A survey toward private and secure applications. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. In Proceedings of the Data Mining and Big Data: 7th International Conference, DMBD 2022, Beijing, China, 21–24 November 2022; Springer: Berlin/Heidelberg, Germany, 2023; pp. 409–423. [Google Scholar]
- Ng, A.; Jordan, M. On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. Adv. Neural Inf. Process. Syst. 2002, 14, 841. [Google Scholar]
- Lee, H.W.; Lim, K.Y.; Grabowski, B.L. Generative learning: Principles and implications for making meaning. In Handbook of Research on Educational Communications and Technology; Routledge: Abingdon, UK, 2008; pp. 111–124. [Google Scholar]
- Nallapati, R. Discriminative models for information retrieval. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Sheffield, UK, 25–29 July 2004; pp. 64–71. [Google Scholar]
- Oussidi, A.; Elhassouny, A. Deep generative models: Survey. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision (ISCV), Fez, Morocco, 2–4 April 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Webb, G.I. Naïve Bayes. Encycl. Mach. Learn. 2010, 15, 713–714. [Google Scholar]
- Pearl, J. Bayesian Networks; Department of Statistics, UCLA: Calgary, AB, Canada, 2011. [Google Scholar]
- Clifford, P. Markov random fields in statistics. Disorder in Physical Systems: A Volume in Honour of John M. Hammersley; Clarendon Press: Oxford, UK, 1990; pp. 19–32. [Google Scholar]
- Eddy, S.R. Hidden markov models. Curr. Opin. Struct. Biol. 1996, 6, 361–365. [Google Scholar] [CrossRef]
- Izenman, A.J. Linear discriminant analysis. In Modern Multivariate Statistical Techniques; Springer: Berlin/Heidelberg, Germany, 2013; pp. 237–280. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Fahlman, S.E.; Hinton, G.E.; Sejnowski, T.J. Massively parallel architectures for Al: NETL, Thistle, and Boltzmann machines. In Proceedings of the National Conference on Artificial Intelligence, AAAI, Washington, DC, USA, 22–26 August 1983. [Google Scholar]
- Fischer, A.; Igel, C. An introduction to restricted Boltzmann machines. In Proceedings of the Iberoamerican Congress on Pattern Recognition, Buenos Aires, Argentina, 3–6 September 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 14–36. [Google Scholar]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G. Deep boltzmann machines. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Clearwater, FL, USA, 16–18 April 2009; pp. 448–455. [Google Scholar]
- Sutskever, I.; Hinton, G.E. Deep, narrow sigmoid belief networks are universal approximators. Neural Comput. 2008, 20, 2629–2636. [Google Scholar] [CrossRef] [PubMed]
- Bontrager, P.; Togelius, J. Fully differentiable procedural content generation through generative playing networks. arXiv 2020, arXiv:2002.05259. [Google Scholar]
- Kingma, D.P.; Welling, M. An introduction to variational autoencoders. Found. Trends® Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Nikolenko, S.I. Synthetic Data for Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021; Volume 174. [Google Scholar]
- Caruana, R.; Niculescu-Mizil, A. An empirical comparison of supervised learning algorithms. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 161–168. [Google Scholar]
- Wright, R.E. Logistic regression. In Reading and Understanding Multivariate Statistics; American Psychological Association: Washington, DC, USA, 1995; pp. 217–244. [Google Scholar]
- Joachims, T. ISVM-Light Support Vector Machine, University of Dortmund. 1999. Available online: http://svmlight.joachims.org/ (accessed on 1 January 2020).
- Kröse, B.; Krose, B.; van der Smagt, P.; Smagt, P. An Introduction to Neural Networks; The University of Amsterdam: Amsterdam, The Netherlands, 1993. [Google Scholar]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Phyu, T.N. Survey of classification techniques in data mining. In Proceedings of the International Multiconference of Engineers and Computer Scientists, Hong Kong, 18–20 March 2009; Volume 1. [Google Scholar]
- Bernardo, J.; Bayarri, M.; Berger, J.; Dawid, A.; Heckerman, D.; Smith, A.; West, M. Generative or discriminative? Getting the best of both worlds. Bayesian Stat. 2007, 8, 3–24. [Google Scholar]
- Minka, T. Discriminative Models, Not Discriminative Training; Technical Report, Technical Report MSR-TR-2005-144; Microsoft Research: Redmond, WA, USA, 2005. [Google Scholar]
- Theis, L.; Oord, A.v.d.; Bethge, M. A note on the evaluation of generative models. arXiv 2015, arXiv:1511.01844. [Google Scholar]
- Amit, I.; Matherly, J.; Hewlett, W.; Xu, Z.; Meshi, Y.; Weinberger, Y. Machine learning in cyber-security-problems, challenges and data sets. arXiv 2018, arXiv:1812.07858. [Google Scholar]
- Barlow, H.B. Unsupervised learning. Neural Comput. 1989, 1, 295–311. [Google Scholar] [CrossRef]
- Zhu, X.; Goldberg, A.B. Introduction to Semi-Supervised Learning; Synthesis Lectures on Artificial Intelligence and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2009; Volume 3, pp. 1–130. [Google Scholar]
- Khosravi, P.; Choi, Y.; Liang, Y.; Vergari, A.; Broeck, G.V.d. On tractable computation of expected predictions. arXiv 2019, arXiv:1910.02182. [Google Scholar]
- Huang, C.W.; Touati, A.; Dinh, L.; Drozdzal, M.; Havaei, M.; Charlin, L.; Courville, A. Learnable explicit density for continuous latent space and variational inference. arXiv 2017, arXiv:1710.02248. [Google Scholar]
- Frey, B.J.; Hinton, G.E.; Dayan, P. Does the wake-sleep algorithm produce good density estimators? In Proceedings of the Advances in Neural Information Processing Systems. Citeseer, Denver, CO, USA, 2–5 December 1996; pp. 661–670. [Google Scholar]
- Karhunen, J. Nonlinear independent component analysis. In ICA: Principles and Practice; Cambridge University Press: Cambridge, UK, 2001; pp. 113–134. [Google Scholar]
- Hammersley, J. Monte Carlo Methods; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Tran, D.; Ranganath, R.; Blei, D. Hierarchical implicit models and likelihood-free variational inference. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Ching, W.K.; Huang, X.; Ng, M.K.; Siu, T.-K. Markov Chains; Models, Algorithms and Applications; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. Machine learning basics. Deep. Learn. 2016, 98–164. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Arora, S.; Khandeparkar, H.; Khodak, M.; Plevrakis, O.; Saunshi, N. A theoretical analysis of contrastive unsupervised representation learning. arXiv 2019, arXiv:1902.09229. [Google Scholar]
- Hodson, T.O.; Over, T.M.; Foks, S.S. Mean squared error, deconstructed. J. Adv. Model. Earth Syst. 2021, 13, e2021MS002681. [Google Scholar] [CrossRef]
- Jiang, B.; Zhou, Z.; Wang, X.; Tang, J.; Luo, B. CmSalGAN: RGB-D salient object detection with cross-view generative adversarial networks. IEEE Trans. Multimed. 2020, 23, 1343–1353. [Google Scholar] [CrossRef]
- Goudet, O.; Kalainathan, D.; Caillou, P.; Guyon, I.; Lopez-Paz, D.; Sebag, M. Causal generative neural networks. arXiv 2017, arXiv:1711.08936. [Google Scholar]
- Zhou, G.; Yao, L.; Xu, X.; Wang, C.; Zhu, L.; Zhang, K. On the opportunity of causal deep generative models: A survey and future directions. arXiv 2023, arXiv:2301.12351. [Google Scholar]
- Kügelgen, J.; Mey, A.; Loog, M.; Schölkopf, B. Semi-supervised learning, causality, and the conditional cluster assumption. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, PMLR, Tel Aviv, Israel, 22–25 July 2019; pp. 1–10. [Google Scholar]
- Han, T.; Tu, W.W.; Li, Y.F. Explanation consistency training: Facilitating consistency-based semi-supervised learning with interpretability. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 7639–7646. [Google Scholar]
- Kanungo, T.; Mount, D.M.; Netanyahu, N.S.; Piatko, C.; Silverman, R.; Wu, A.Y. The analysis of a simple k-means clustering algorithm. In Proceedings of the Sixteenth Annual Symposium on Computational Geometry, Hong Kong, 12–14 June 2000; pp. 100–109. [Google Scholar]
- Kramer, O.; Kramer, O. K-nearest neighbors. In Dimensionality Reduction with Unsupervised Nearest Neighbors; Springer: Berlin/Heidelberg, Germany, 2013; pp. 13–23. [Google Scholar]
- De Ville, B. Decision trees. Wiley Interdiscip. Rev. Comput. Stat. 2013, 5, 448–455. [Google Scholar] [CrossRef]
- Cho, Y.; Saul, L. Kernel methods for deep learning. Adv. Neural Inf. Process. Syst. 2009, 22. [Google Scholar]
- Sennrich, R. Modelling and optimizing on syntactic n-grams for statistical machine translation. Trans. Assoc. Comput. Linguist. 2015, 3, 169–182. [Google Scholar] [CrossRef]
- Hinton, G.E. Distributed Representations; Carnegie Mellon University: Pittsburgh, PA, USA, 1984. [Google Scholar]
- Hinton, G.E.; Ghahramani, Z. Generative models for discovering sparse distributed representations. Philos. Trans. R. Soc. Lond. Ser. Biol. Sci. 1997, 352, 1177–1190. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Li, T.; Ortiz, J.M. Generative Adversarial Network 1011; Queen’s University: Belfast, UK, 2022. [Google Scholar]
- Ratliff, L.J.; Burden, S.A.; Sastry, S.S. Characterization and computation of local Nash equilibria in continuous games. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 917–924. [Google Scholar]
- Sun, F.; Xie, X. Deep non-parallel hyperplane support vector machine for classification. IEEE Access 2023, 11, 7759–7767. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Xie, G.S.; Li, X.; Mei, T.; Liu, C.L. A Survey on Learning to Reject. Proc. IEEE 2023, 111, 185–215. [Google Scholar] [CrossRef]
- Chen, L.; Deng, Y.; Cheong, K.H. Permutation Jensen–Shannon divergence for Random Permutation Set. Eng. Appl. Artif. Intell. 2023, 119, 105701. [Google Scholar] [CrossRef]
- Wildberger, J.; Guo, S.; Bhattacharyya, A.; Schölkopf, B. On the Interventional Kullback–Leibler Divergence. arXiv 2023, arXiv:2302.05380. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models using a laplacian pyramid of adversarial networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1486–1494. [Google Scholar]
- Burt, P.; Adelson, E. The Laplacian pyramid as a compact image code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Nair, V.; Hinton, G. Cifar-10 (Canadian Institute for Advanced Research). 2010. Available online: http://www.cs.toronto.edu/kriz/cifar.html (accessed on 10 December 2023).
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. LSUN: Construction of a Large-scale Image Dataset using Deep Learning with Humans in the Loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: Piscataway, NJ, USA, 2003; Volumr 2, pp. 1398–1402. [Google Scholar]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.V.; Wardlaw, J.; Rueckert, D. Gan augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- Sixt, L.; Wild, B.; Landgraf, T. Rendergan: Generating realistic labeled data. Front. Robot. 2018, 5, 66. [Google Scholar] [CrossRef]
- Wario, F.; Wild, B.; Couvillon, M.J.; Rojas, R.; Landgraf, T. Automatic methods for long-term tracking and the detection and decoding of communication dances in honeybees. Front. Ecol. Evol. 2015, 3, 103. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5907–5915. [Google Scholar]
- Reed, S.E.; Akata, Z.; Mohan, S.; Tenka, S.; Schiele, B.; Lee, H. Learning what and where to draw. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 217–225. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-ucsd Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 722–729. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Vinod, B. The continuing evolution: Customer-centric revenue management. J. Revenue Pricing Manag. 2008, 7, 27–39. [Google Scholar] [CrossRef]
- Mottini, A.; Lheritier, A.; Acuna-Agost, R. Airline passenger name record generation using generative adversarial networks. arXiv 2018, arXiv:1807.06657. [Google Scholar]
- Voigt, P.; Von dem Bussche, A. The eu general data protection regulation (gdpr). In A Practical Guide, 1st ed.; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Bellemare, M.G.; Danihelka, I.; Dabney, W.; Mohamed, S.; Lakshminarayanan, B.; Hoyer, S.; Munos, R. The cramer distance as a solution to biased wasserstein gradients. arXiv 2017, arXiv:1705.10743. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, 14 August 2017; pp. 1–7. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein gan. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Ajalloeian, A.; Stich, S.U. Analysis of SGD with Biased Gradient Estimators. arXiv 2020, arXiv:2008.00051. [Google Scholar]
- Székely, G.J. E-Statistics: The Energy of Statistical Samples; Technical Report; Bowling Green State University, Department of Mathematics and Statistics: Bowling Green, OH, USA, 2003; Volume 3, pp. 1–18. [Google Scholar]
- Guo, C.; Berkhahn, F. Entity embeddings of categorical variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Lilliefors, H.W. On the Kolmogorov–Smirnov test for normality with mean and variance unknown. J. Am. Stat. Assoc. 1967, 62, 399–402. [Google Scholar] [CrossRef]
- Park, N.; Mohammadi, M.; Gorde, K.; Jajodia, S.; Park, H.; Kim, Y. Data synthesis based on generative adversarial networks. arXiv 2018, arXiv:1806.03384. [Google Scholar] [CrossRef]
- LA. Available online: https://controllerdata.lacity.org/Payroll/City-Employee-Payroll/pazn-qyym (accessed on 1 December 2023).
- Becker, B.; Kohavi, R. Adult; UCI Machine Learning Repository: Irvine, CA, USA, 1996. [Google Scholar] [CrossRef]
- Health. Health Dataset. Available online: https://wwwn.cdc.gov/Nchs/Nhanes/Default.aspx (accessed on 1 December 2023).
- Airline. US Bureau of Transportation Statistics (BTS). Available online: https://www.transtats.bts.gov/DataIndex.asp (accessed on 1 December 2023).
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership inference attacks against machine learning models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3–18. [Google Scholar]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. Network anomaly detection: Methods, systems and tools. IEEE Commun. Surv. Tutor. 2013, 16, 303–336. [Google Scholar] [CrossRef]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Ahmad, Z.; Shahid Khan, A.; Wai Shiang, C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, X.; Li, T.; Wu, D.; Wang, J.; Zhao, Y.; Han, H. A systematic literature review of methods and datasets for anomaly-based network intrusion detection. Comput. Secur. 2022, 116, 102675. [Google Scholar] [CrossRef]
- Myneni, S.; Chowdhary, A.; Sabur, A.; Sengupta, S.; Agrawal, G.; Huang, D.; Kang, M. DAPT 2020-constructing a benchmark dataset for advanced persistent threats. In Proceedings of the Deployable Machine Learning for Security Defense: First International Workshop, MLHat 2020, San Diego, CA, USA, 24 August 2020; Proceedings 1. Springer: Berlin/Heidelberg, Germany, 2020; pp. 138–163. [Google Scholar]
- Myneni, S.; Jha, K.; Sabur, A.; Agrawal, G.; Deng, Y.; Chowdhary, A.; Huang, D. Unraveled—A semi-synthetic dataset for Advanced Persistent Threats. Comput. Netw. 2023, 227, 109688. [Google Scholar] [CrossRef]
- Bulusu, S.; Kailkhura, B.; Li, B.; Varshney, P.K.; Song, D. Anomalous Instance Detection in Deep Learning: A Survey. arXiv 2020, arXiv:2003.06979. [Google Scholar]
- Kumarage, T.; Ranathunga, S.; Kuruppu, C.; Silva, N.D.; Ranawaka, M. Generative Adversarial Networks (GAN) based Anomaly Detection in Industrial Software Systems. In Proceedings of the 2019 Moratuwa Engineering Research Conference (MERCon), Moratuwa, Sri Lanka, 3–5 July 2019; pp. 43–48. [Google Scholar] [CrossRef]
- Zhang, J.; Tang, J.; Zhang, X.; Ouyang, W.; Wang, D. A survey of network traffic generation. In Proceedings of the Third International Conference on Cyberspace Technology (CCT 2015), Beijing, China, 17–18 October 2015. [Google Scholar]
- Lin, Z.; Jain, A.; Wang, C.; Fanti, G.; Sekar, V. Using GANs for sharing networked time series data: Challenges, initial promise, and open questions. In Proceedings of the ACM Internet Measurement Conference, Virtual, 27–29 October 2020; pp. 464–483. [Google Scholar]
- Xu, S.; Marwah, M.; Arlitt, M.; Ramakrishnan, N. Stan: Synthetic network traffic generation with generative neural models. In Proceedings of the Deployable Machine Learning for Security Defense: Second International Workshop, MLHat 2021, Virtual, 15 August 2021; Proceedings 2. Springer: Berlin/Heidelberg, Germany, 2021; pp. 3–29. [Google Scholar]
- Ring, M.; Schlör, D.; Landes, D.; Hotho, A. Flow-based network traffic generation using generative adversarial networks. Comput. Secur. 2019, 82, 156–172. [Google Scholar] [CrossRef]
- Ring, M.; Wunderlich, S.; Grüdl, D.; Landes, D.; Hotho, A. Flow-based benchmark data sets for intrusion detection. In Proceedings of the 16th European Conference on Cyber Warfare and Security, Dublin, Ireland, 29–30 June 2017; pp. 361–369. [Google Scholar]
- Ring, M.; Dallmann, A.; Landes, D.; Hotho, A. Ip2vec: Learning similarities between ip addresses. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 657–666. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Cheng, A. PAC-GAN: Packet Generation of Network Traffic using Generative Adversarial Networks. In Proceedings of the 2019 IEEE 10th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 728–734. [Google Scholar]
- Shahid, M.R.; Blanc, G.; Jmila, H.; Zhang, Z.; Debar, H. Generative deep learning for Internet of Things network traffic generation. In Proceedings of the 2020 IEEE 25th Pacific Rim International Symposium on Dependable Computing (PRDC), Perth, WA, Australia, 1–4 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 70–79. [Google Scholar]
- Yin, Y.; Lin, Z.; Jin, M.; Fanti, G.; Sekar, V. Practical gan-based synthetic ip header trace generation using netshare. In Proceedings of the ACM SIGCOMM 2022 Conference, Amsterdam, The Netherlands, 22–26 August 2022; pp. 458–472. [Google Scholar]
- Mozo, A.; González-Prieto, Á.; Pastor, A.; Gómez-Canaval, S.; Talavera, E. Synthetic flow-based cryptomining attack generation through Generative Adversarial Networks. Sci. Rep. 2022, 12, 2091. [Google Scholar] [CrossRef]
- Huang, D.; Chowdhary, A.; Pisharody, S. Software-Defined Networking and Security: From Theory to Practice; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Duy, P.T.; Khoa, N.H.; Hien, D.T.T.; Do Hoang, H.; Pham, V.H. Investigating on the robustness of flow-based intrusion detection system against adversarial samples using Generative Adversarial Networks. J. Inf. Secur. Appl. 2023, 74, 103472. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.Y.; He, W.; Liu, M.; Song, D. Generating adversarial examples with adversarial networks. arXiv 2018, arXiv:1801.02610. [Google Scholar]
- Sweet, C.; Moskal, S.; Yang, S.J. On the Variety and Veracity of Cyber Intrusion Alerts Synthesized by Generative Adversarial Networks. ACM Trans. Manag. Inf. Syst. (TMIS) 2020, 11, 1–21. [Google Scholar] [CrossRef]
- Sweet, C.; Moskal, S.; Yang, S.J. Synthetic intrusion alert generation through generative adversarial networks. In Proceedings of the MILCOM 2019-2019 IEEE Military Communications Conference (MILCOM), Norfolk, VA, USA, 12–14 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Belghazi, M.I.; Baratin, A.; Rajeswar, S.; Ozair, S.; Bengio, Y.; Courville, A.; Hjelm, R.D. Mine: Mutual information neural estimation. arXiv 2018, arXiv:1801.04062. [Google Scholar]
- Munaiah, N.; Pelletier, J.; Su, S.H.; Yang, S.J.; Meneely, A. A Cybersecurity Dataset Derived from the National Collegiate Penetration Testing Competition. In Proceedings of the HICSS Symposium on Cybersecurity Big Data Analytics, Maui, HI, USA, 8–11 January 2019. [Google Scholar]
- Kumar, V.; Sinha, D. Synthetic attack data generation model applying generative adversarial network for intrusion detection. Comput. Secur. 2023, 125, 103054. [Google Scholar] [CrossRef]
- Mouyart, M.; Medeiros Machado, G.; Jun, J.Y. A Multi-Agent Intrusion Detection System Optimized by a Deep Reinforcement Learning Approach with a Dataset Enlarged Using a Generative Model to Reduce the Bias Effect. J. Sens. Actuator Netw. 2023, 12, 68. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling tabular data using conditional gan. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 24. [Google Scholar]
- Trzeciak, R.; CERT Insider Threat Center, T. The CERT Insider Threat Database; Carnegie Mellon University, Software Engineering Institute’s Insights (Blog): Washington, DC, USA, 2011. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European symposium on security and privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 372–387. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, United Arab Emirates, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Moraffah, R.; Liu, H. Query-Efficient Target-Agnostic Black-Box Attack. In Proceedings of the 2022 IEEE International Conference on Data Mining (ICDM), Orlando, FL, USA, 28 November–1 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 368–377. [Google Scholar]
- Lin, Z.; Shi, Y.; Xue, Z. Idsgan: Generative adversarial networks for attack generation against intrusion detection. arXiv 2018, arXiv:1809.02077. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Yang, Y.; Zheng, K.; Wu, B.; Yang, Y.; Wang, X. Network intrusion detection based on supervised adversarial variational auto-encoder with regularization. IEEE Access 2020, 8, 42169–42184. [Google Scholar] [CrossRef]
- Lee, J.; Park, K. GAN-based imbalanced data intrusion detection system. Pers. Ubiquitous Comput. 2021, 25, 121–128. [Google Scholar] [CrossRef]
- Huang, S.; Lei, K. IGAN-IDS: An imbalanced generative adversarial network towards intrusion detection system in ad hoc networks. Ad Hoc Netw. 2020, 105, 102177. [Google Scholar] [CrossRef]
- Shahriar, M.H.; Haque, N.I.; Rahman, M.A.; Alonso, M. G-ids: Generative adversarial networks assisted intrusion detection system. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 376–385. [Google Scholar]
- Chauhan, R.; Sabeel, U.; Izaddoost, A.; Shah Heydari, S. Polymorphic Adversarial Cyberattacks Using WGAN. J. Cybersecur. Priv. 2021, 1, 767–792. [Google Scholar] [CrossRef]
- Renaud, K.; Warkentin, M.; Westerman, G. From ChatGPT to HackGPT: Meeting the Cybersecurity Threat of Generative AI; MIT Press: Cambridge, MA, USA, 2023. [Google Scholar]
- Kaheh, M.; Kholgh, D.K.; Kostakos, P. Cyber Sentinel: Exploring Conversational Agents in Streamlining Security Tasks with GPT-4. arXiv 2023, arXiv:2309.16422. [Google Scholar]
- Gupta, M.; Akiri, C.; Aryal, K.; Parker, E.; Praharaj, L. From chatgpt to threatgpt: Impact of generative ai in cybersecurity and privacy. IEEE Access 2023, 11, 80218–80245. [Google Scholar] [CrossRef]
- Al-Hawawreh, M.; Aljuhani, A.; Jararweh, Y. Chatgpt for cybersecurity: Practical applications, challenges, and future directions. Clust. Comput. 2023, 26, 3421–3436. [Google Scholar] [CrossRef]
- Asfour, M.; Murillo, J.C. Harnessing large language models to simulate realistic human responses to social engineering attacks: A case study. Int. J. Cybersecur. Intell. Cybercrime 2023, 6, 21–49. [Google Scholar] [CrossRef]
- Karanjai, R. Targeted phishing campaigns using large scale language models. arXiv 2022, arXiv:2301.00665. [Google Scholar]
- McKee, F.; Noever, D. Chatbots in a botnet world. arXiv 2022, arXiv:2212.11126. [Google Scholar] [CrossRef]
- Beckerich, M.; Plein, L.; Coronado, S. Ratgpt: Turning online llms into proxies for malware attacks. arXiv 2023, arXiv:2308.09183. [Google Scholar]
- McKee, F.; Noever, D. Chatbots in a honeypot world. arXiv 2023, arXiv:2301.03771. [Google Scholar]
- NSL-KDD. A Collaborative Project between the Communications Security Establishment (CSE) and the Canadian Institute for Cybersecurity (CIC). 2009. Available online: https://www.unb.ca/cic/datasets/nsl.html (accessed on 10 December 2023).
- Zhou, J.; Wu, Z.; Xue, Y.; Li, M.; Zhou, D. Network unknown-threat detection based on a generative adversarial network and evolutionary algorithm. Int. J. Intell. Syst. 2022, 37, 4307–4328. [Google Scholar] [CrossRef]
- CIC-IDS2017. A Collaborative Project between the Communications Security Establishment (CSE) and the Canadian Institute for Cybersecurity (CIC). 2017. Available online: https://www.unb.ca/cic/datasets/ids-2017.html (accessed on 4 January 2023).
- CIC-DDoS2019. A Collaborative Project between the Communications Security Establishment (CSE) and the Canadian Institute for Cybersecurity (CIC). 2019. Available online: https://www.unb.ca/cic/datasets/ddos-2019.html (accessed on 4 January 2023).
- CICEV2023. A Collaborative Project between the Communications Security Establishment (CSE) and the Canadian Institute for Cybersecurity (CIC). 2023. Available online: https://www.unb.ca/cic/datasets/cicev2023.html (accessed on 4 January 2023).
- Schneier, B. Attack trees. Dr. Dobb’S J. 1999, 24, 21–29. [Google Scholar]
- Gadyatskaya, O.; Trujillo-Rasua, R. New directions in attack tree research: Catching up with industrial needs. In Proceedings of the Graphical Models for Security: 4th International Workshop, GraMSec 2017, Santa Barbara, CA, USA, 21 August 2017; Revised Selected Papers 4. Springer: Berlin/Heidelberg, Germany, 2018; pp. 115–126. [Google Scholar]
- Wideł, W.; Audinot, M.; Fila, B.; Pinchinat, S. Beyond 2014: Formal Methods for Attack Tree–based Security Modeling. ACM Comput. Surv. (CSUR) 2019, 52, 1–36. [Google Scholar] [CrossRef]
- Kholgh, D.K.; Kostakos, P. PAC-GPT: A novel approach to generating synthetic network traffic with GPT-3. IEEE Access 2023, 11, 114936–114951. [Google Scholar] [CrossRef]
- Gadyatskaya, O.; Papuc, D. ChatGPT Knows Your Attacks: Synthesizing Attack Trees Using LLMs. In Proceedings of the International Conference on Data Science and Artificial Intelligence, Bangkok, Thailand, 27–29 November 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 245–260. [Google Scholar]



{kind=link}
{kind=link}
| Generative Models | Discriminative Models |
|---|---|
| Learn the underlying data distribution | Learn the decision boundary between different classes of the data |
| Model the joint probability distribution between the input and output data | Model the conditional probability distribution of the output given the input |
| Can generate new data from the learned distribution | Cannot generate new data from the learned decision boundary |
| Used for tasks such as image and audio synthesis, text generation, and anomaly detection | Used for tasks such as classification, regression, and object recognition |
| Make no assumptions about the data | Use prior assumptions about the data |
| Examples include VAE, GAN, and RBM | Examples include logistic regression, SVM, and neural networks |
| Data Type | Model | Method | Generated Data Quality |
|---|---|---|---|
| Images | DCGAN [60] | Vector arithmetic manipulation | Low, suffers from mode collapse |
| CGAN [68] | Label as condition | Improved quality | |
| LAPGAN [69] | Conditional GAN with Laplacian pyramid | High-resolution realistic images | |
| PGGAN [67] | Focus on finer-scale details | High-quality synthetic images | |
| RenderGAN [76] | Image augmentation | Realistic labeled images | |
| StackGANs [78] | Generate images from a text description using text embedding | Good quality images, evaluated using inception score | |
| InfoGAN [85] | Use mutual information as condition | Model can disentangle variations, improved generated images | |
| Tabular | PNR generation [89] | Use Cramer GAN [91] | Evaluated using Jensen–Shannon divergence (JSD), realistic data generated |
| Table-GANs [98] | Use 3 CNNs, additional classifier to increase synthetic records integrity | Models trained using synthetic data performed well |
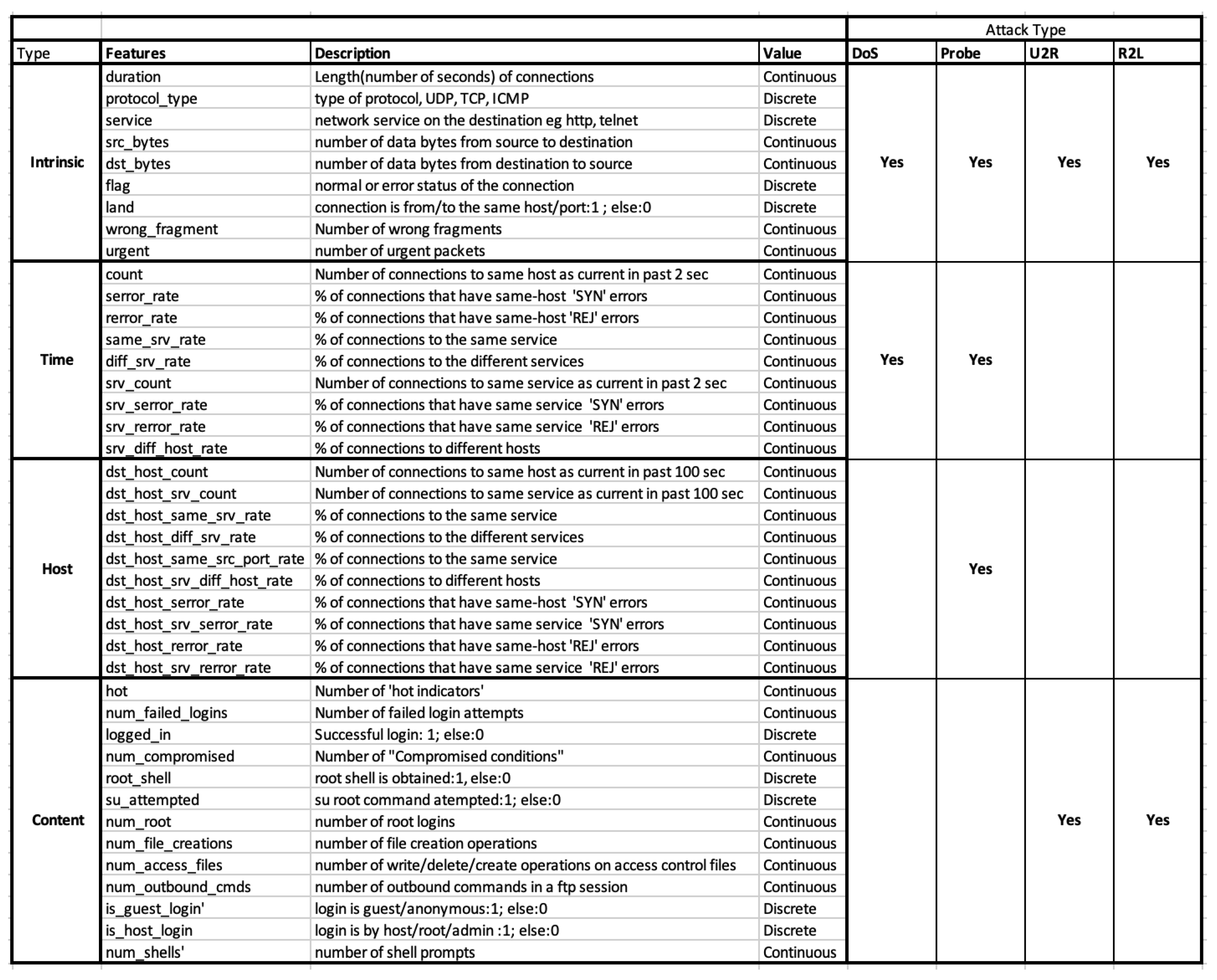
| DoS | R2L | U2R | Probe |
|---|---|---|---|
| back | ftp_write | buffer_overflow | ipsweep |
| land | guess_passwd | loadmodule | nmap |
| pod | imap | perl | portsweep |
| smurf | multihop | rootkit | satan |
| teardrop | phf | ||
| spy | |||
| warezclient | |||
| warezmaster |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agrawal, G.; Kaur, A.; Myneni, S. A Review of Generative Models in Generating Synthetic Attack Data for Cybersecurity. Electronics 2024, 13, 322. https://doi.org/10.3390/electronics13020322
Agrawal G, Kaur A, Myneni S. A Review of Generative Models in Generating Synthetic Attack Data for Cybersecurity. Electronics. 2024; 13(2):322. https://doi.org/10.3390/electronics13020322
Chicago/Turabian StyleAgrawal, Garima, Amardeep Kaur, and Sowmya Myneni. 2024. "A Review of Generative Models in Generating Synthetic Attack Data for Cybersecurity" Electronics 13, no. 2: 322. https://doi.org/10.3390/electronics13020322
APA StyleAgrawal, G., Kaur, A., & Myneni, S. (2024). A Review of Generative Models in Generating Synthetic Attack Data for Cybersecurity. Electronics, 13(2), 322. https://doi.org/10.3390/electronics13020322