Abstract
In the evolving field of taxonomic classification, and especially in Zero-shot Learning (ZSL), the challenge of accurately classifying entities unseen in training datasets remains a significant hurdle. Although the existing literature is rich in developments, it often falls short in two critical areas: semantic consistency (ensuring classifications align with true meanings) and the effective handling of dataset diversity biases. These gaps have created a need for a more robust approach that can navigate both with greater efficacy. This paper introduces an innovative integration of transformer models with ariational autoencoders (VAEs) and generative adversarial networks (GANs), with the aim of addressing them within the ZSL framework. The choice of VAE-GAN is driven by their complementary strengths: VAEs are proficient in providing a richer representation of data patterns, and GANs are able to generate data that is diverse yet representative, thus mitigating biases from dataset diversity. Transformers are employed to further enhance semantic consistency, which is key because many existing models underperform. Through experiments have been conducted on benchmark ZSL datasets such as CUB, SUN, and Animals with Attributes 2 (AWA2), our approach is novel because it demonstrates significant improvements, not only in enhancing semantic and structural coherence, but also in effectively addressing dataset biases. This leads to a notable enhancement of the model’s ability to generalize visual categorization tasks beyond the training data, thus filling a critical gap in the current ZSL research landscape.
1. Introduction
Imagine the challenge of teaching a computer to recognize animals it has never seen before, which is the essence of zero-shot learning (ZSL), a fascinating area of computer science that empowers computers to identify new categories they have not encountered in training. This contrasts with traditional learning methods for computers, which typically require many examples. In ZSL, computers can learn with fewer examples, relying on related information such as descriptions or attributes. This is particularly beneficial in scenarios where it is difficult or expensive to acquire numerous examples, like identifying rare diseases in medical imaging or uncommon animals in natural habitats [1].
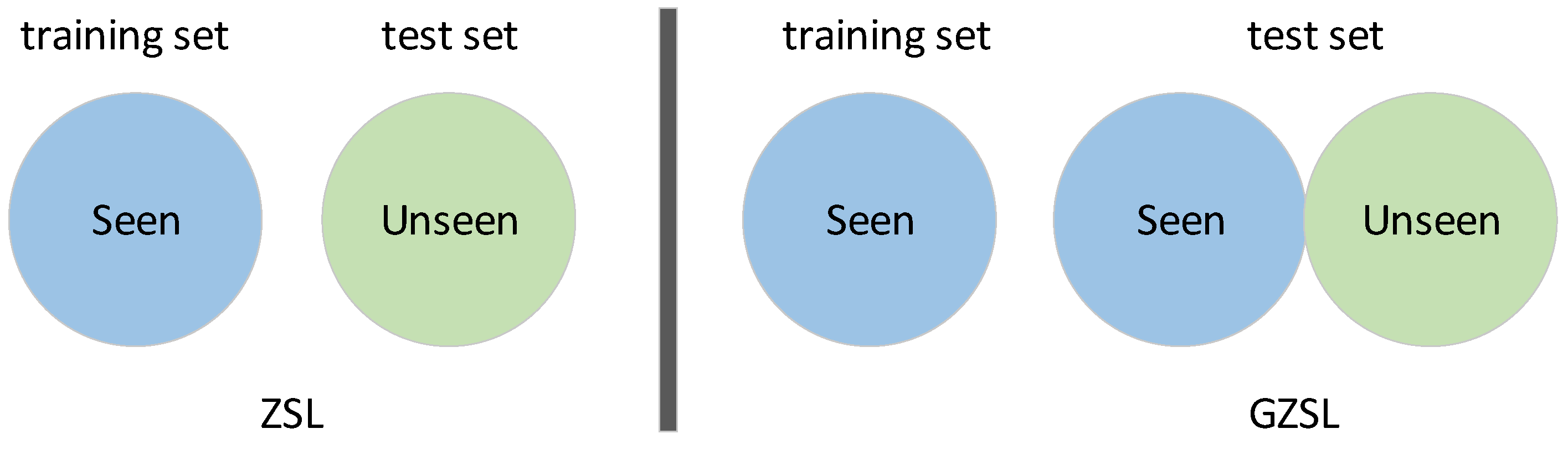
In typical ZSL methods, computers initially receive training on known categories, and then use the similarities between these known categories and new ones to draw inferences about the latter. This process is akin to teaching a computer to recognize a zebra by understanding horses and then noting the similarities and differences between them. ZSL is invaluable in situations with limited data, aiding the application of machine learning in practical scenarios where examples are rare [2]. Traditional zero-shot learning and generalized zero-shot learning can be separated by referring to distinctions between their training and testing sets, as illustrated in Figure 1.
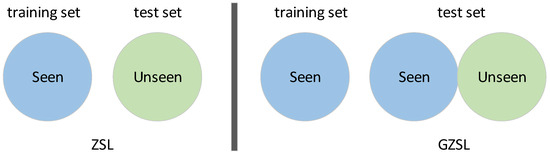
Figure 1.
Zero-shot learning and generalized zero-shot learning.
The DVBE [3] framework has semantic labels that typically exhibit minimal class variance between seen and unseen categories, resulting in diminished visual representational differences after post-semantic visual alignment, which complicates the distinction of semantic consistency. As a consequence, visual representations of unseen and seen categories often align. Moreover, while the DVBE network aims to mitigate seen-class bias by constructing complementary visual representations, it relies on existing semantic information, potentially perpetuating inherent biases present in the dataset. For instance, if category attribute labels are manually annotated based on a biased dataset, biases could adversely influence the model’s learning and application of semantic information.
Our research introduces a novel approach that employs a type of artificial intelligence model known as a Generative Adversarial Network (GAN), which has been effective in various image-related tasks. We integrate GANs with our unique architecture to enhance computer processing and synthesize different types of information, which is known as multimodal fusion [4,5], which is crucial for ensuring that learned characteristics are applicable when the computer faces a task like identifying previously unseen animals. By building on prior studies [6], we have refined the use of GANs to more effectively match observed features to their related information, potentially improving our method’s ability to recognize new categories without explicit training.
Moreover, the superiority of ZSL, when compared to traditional unsupervised learning methods, becomes evident when dealing with the challenge of unseen classes. Unlike unsupervised approaches, ZSL can predict instances where classes are not present in the training data by understanding textual descriptions and semantics. This capability is particularly beneficial in domains where it is impractical to acquire extensive labeled data. Recent studies of ZSL have demonstrated its efficacy in accurately classifying unseen categories, thus confirming its advantage over conventional unsupervised learning methods [7,8].
The transformer architecture, which was originally a breakthrough in natural language processing [6,9], is at the heart of our research, and we have innovatively adapted it for use in our ZSL framework. The Transformer has been intricately integrated into various stages of our process, and encompasses training, feature synthesis, and final classification. Our method is based on a unique combination of a variational auto-encoder-GAN (VAE-GAN), which includes:
Enhancing semantic consistency with transformers: We have adapted the Transformer model, which is commonly used in understanding and processing language, and integrated it into our variational auto-encoder (VAE), which ensures that our model consistently interprets the meaning (or semantics) of data across different forms, such as images and text [6,10].
Maintaining Structural Coherence: By combining a transformer-VAE designed for processing image features with another VAE that specializes in extracting textual features, we ensure our model maintains a uniform structure when processing different types of data, which is crucial for its ability to make accurate predictions across various data formats [6].
Addressing Data Discrepancies with Multi-modal Fusion and GANs: In recognizing the differences that often exist between training and target datasets in real-world applications, we have integrated a combination of multi-modal fusion (which combines different types of data) and GAN networks [11], which enables our model to draw insights from varied data sources and utilize the generative power of GANs; as a result, it adapts well to different data distributions, effectively reducing potential biases [9,12].
Our empirical evaluations of well-known ZSL datasets like CUB, SUN, and AWA2, clearly demonstrated the advantages of incorporating the transformer architecture. Our approach demonstrated superior performance in benchmark comparisons, showing significant improvements in generalized zero-shot object recognition across these datasets. In addition, our method’s compatibility with existing GAN-oriented frameworks enhances its versatility and efficacy in zero-shot recognition tasks [13].
This paper primarily investigates zero-shot learning (ZSL). Section 1 introduces the research significance of ZSL, discusses existing problems in current studies, and then presents the contributions of our paper; Section 2 mainly explores the development of generalized zero-shot learning (GZSL) and current methodologies, with particular emphasis on the embedding approach and the generative approach, two categorizations of ZSL; Section 3 provides a detailed introduction to our algorithm and network structure; in Section 4, experiments are conducted, and results are analyzed; and finally, Section 5 comprehensively summarizes the entire paper.
2. Related Works
2.1. Recent Developments in GZSL
In the dynamic field of computer science, and especially in image recognition and the understanding of human language, the concept of zero-shot learning (ZSL) has emerged as a pivotal area of research. This innovative approach enables computers to recognize new entities—such as animals, objects, or diseases—that they did not encounter in their training phase: a good analogy is teaching someone to identify an unfamiliar fruit by comparing it to similar fruits they already know. Researchers are actively exploring this domain, seeking efficient and precise methods that will impart this ability to computers.
The use of semantic information is a key element of zero-shot learning, and it serves as a bridge that connects the computer’s known and unknown [14,15]. In seeking to optimize the utilization of this information, researchers have developed sophisticated algorithms that establish relationships between different categories [16], and have also leveraged extensive knowledge bases, like databases containing world information, to provide a broader context for the computer’s learning process.
Another critical technique involves teaching computers to autonomously identify and learn vital features [17]. However, an over-reliance on semantic information alone is not sufficient, and this is where techniques like Generative Adversarial Networks (GANs) come into play, by creating new and varied data for the computer to learn from, which enhances its robustness and improves its ability to categorize unfamiliar items [18,19]. Zero-shot learning is an exciting field, with a vast potential that researchers are only beginning to explore.
Nevertheless, zero-shot learning faces several challenges. One significant issue is the imbalance between known and unknown categories that the computer must manage, which often leads to a bias towards the familiar; the use of imperfect semantic information can also result in errors when identifying new entities; and domain shift also presents a hurdle—if the data used for training is vastly different from the data used for testing, it can lead to biases in the computer’s predictions.
2.2. Zero-Shot Learning Strategies: Balancing Embedding and Generative Techniques
In the field of zero-shot learning, experts primarily focus on embedding techniques and generative techniques, which are two strategies that each have unique strengths suited to different contexts. Embedding techniques involve transforming complex data into simpler formats, ensuring easier interpretation by computers and retaining essential information, akin to creating a detailed map that is clear, even when it is zoomed out. This method, which has been significantly enhanced by the advent of deep learning, enhances classification abilities [20,21] by comparing known entities (like common animals) with what is be inferred (such as rare animals). Ref. [22] provides a comprehensive overview of generative adversarial networks and their diverse applications, which contributes to an in-depth understanding. A fuller comprehension of the role and development of attention models in neural networks is also promoted by ref. [23], which offers a detailed survey, highlighting their impact across various domains, along with their contribution to improved model interpretability. On the other hand, generative techniques also revolve around creating new examples for the computer to learn from, and do this by utilizing technologies, like generative adversarial networks (GANs) and variational auto-encoders (VAEs), to generate realistic new data [24,25,26,27].
However, each strategy has limitations. For example, embedding can be complex and may still struggle with changing or intricate data. It sometimes engenders model biases, particularly in skewed datasets or textual descriptors. Advanced embedding techniques, like the attention mechanism [28] and the assimilation external knowledge [29], are being explored with the intention of mitigating these challenges. Conversely, the generative approach focuses on generating synthetic data for unseen categories [30]. This approach, bolstered by the use of GANs and similar models, ensures the generation of high fidelity and life-like synthetic data, opening the way to a more comprehensive training dataset and the improved performance of unseen categories [31].
Our research delves into these strategies, with the aim of addressing the inherent challenges associated with each one and, ultimately, maximizing the effectiveness of zero-shot learning. It is crucial to carefully consider the specific problem and available tools when selecting a strategy. While embedding is more straightforward, generative techniques offer greater flexibility in scenarios with limited data.
3. Materials and Methods
3.1. Overall Framework
Our paper begins by defining key concepts in machine learning, with particular emphasis on generalized zero-shot learning (GZSL) and conventional zero-shot learning (CZSL) in image classification. The training set, denoted as S, comprises triples (x, y, a(y)), while x denotes image features extracted via the convolutional neural networks (CNN) [32]; y is the label for classes encountered in the training phase (represented as ); and a(y) is the semantic attribute representation of each class, which is typically derived from manually annotated attributes or Word2Vec features. In the context of CZSL, the objective is focused on learning a classifier : →. GZSL include an auxiliary training set U, consisting of tuples (u, a(u)), where u symbolizes classes not observed during training (referred to as , and a(u) is the semantic attribute representation for these unseen classes. The set A(U) encompasses all semantic attribute representations of these unseen classes. The fundamental difference between CZSL and GZSL is the objectives of their classifiers. The more difficult and realistic GZSL configuration used in this work aims to learn a classifier : → ∪.
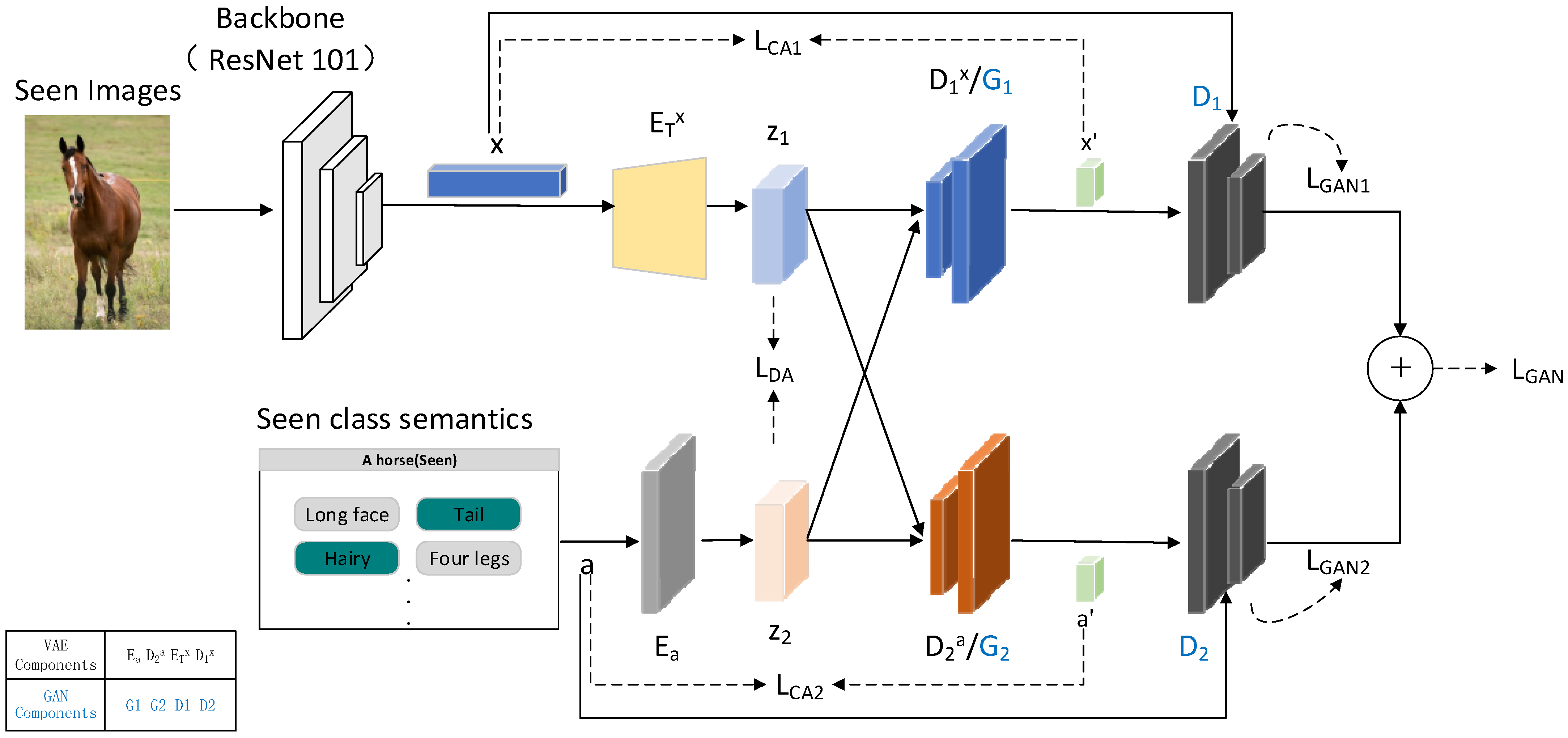
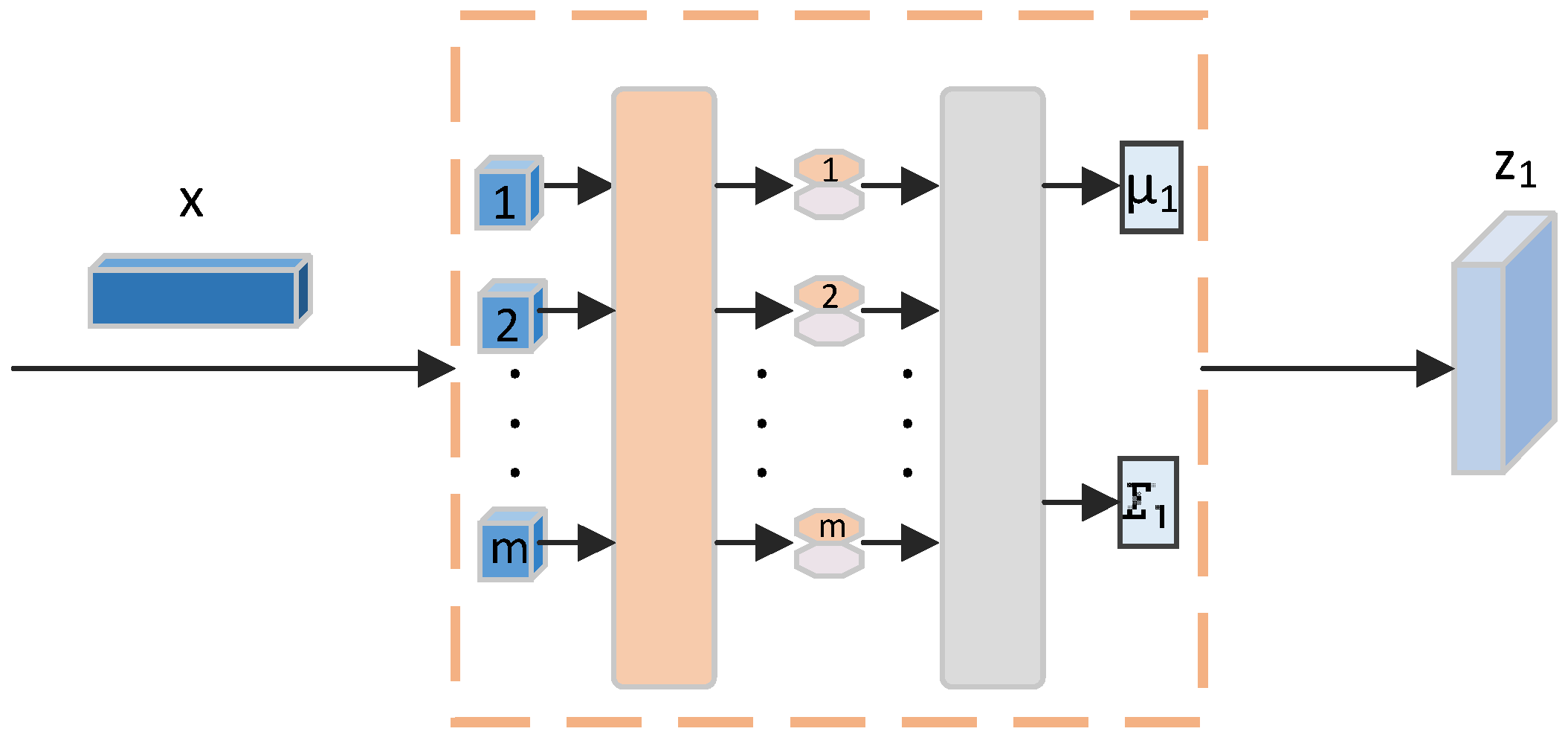
In this paper, we provide an architecture that blends a dual-branch VAE structure with a GAN. As seen in Figure 2, this special construction links the generator of the GAN with the decoder of the VAE via a shared module. Within the VAE-GAN (which consists of an encoder, a decoder, a generator, and a discriminator), the decoder and generator G are common components [33]. The encoder processes visual features , encoding them into latent variable ; similarly, the encoder takes semantic attributes a as an input and encodes them into latent variable . The reconstructed features and are obtained through the modules and , respectively. A cross-alignment loss is employed to compare the synthesized features and with their original counterparts and , respectively. Distribution alignment (DA) loss is used to minimize the Wasserstein distance between prospective distributions, in order to achieve potential distribution alignment (). The is instrumental in quantifying and minimizing discrepancies in latent representations between visual features and semantic attributes, ensuring that representations across different modalities are aligned within a unified space, thereby enhancing the model’s performance and consistency in processing multimodal data. The discriminator in our architecture accepts synthesized features and as inputs, computing a scalar value that is indicative of the authenticity of the input. We employ the GAN loss function at the output of , which facilitates the discrimination of authentic and artificial features.
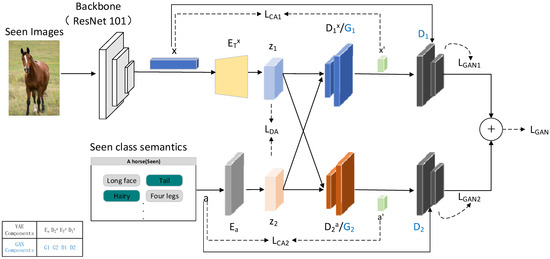
Figure 2.
Variational autoencoder and generative adversarial network dual-architecture system for integrating visual and semantic features.
3.2. Cross and Distribution Aligned VAE
In order for our model to learn representations across N data modalities, it must translate N encoders, which each correspond to a particular modality, into a common space. Decoder networks are used to reconstruct original data so information fidelity is maintained. refers to the encoder with parameter that maps x into the latent space z. refers to parameter θ, which maps the latent space back to the sample space. Consequently, the cumulative total of N distinct VAE losses is as the fundamental loss function of our model:
where the first term represents the reconstruction error, and the second term indicates the unpacked Kullback–Leibler (KL) divergence. Our method involves the modulation of the KL-Divergence by a factor β. We set N = 2 to match visual feature ‘x’ with semantic attribute ‘a’. However, additional regularization terms must be added, to guarantee that modality-specific autoencoders generate similar representations in other modalities. As a result, our model applies a cross-reconstruction criterion and explicitly aligns latent distributions. These two latent distribution alignment procedures, Distribution-Alignment (DA) and Cross-Alignment (CA), are illustrated in Figure 2, which provides a schematic overview of our model.
Loss of Cross-Alignment (CA). In this part, samples from the same class that corresponds to two separate modalities—visual features and semantic attributes—have their latent representations decoded in order to provide cross-modal reconstructions. As a result, latent vectors from the other modality are used to train the decoders that are unique to each modality. The following shows how the cross-reconstruction loss is formalized:
where denotes the cross-reconstruction loss for the visual feature branch, comparing synthesized features with the original features ; represents the cross-reconstruction loss for the semantic attribute branch, and compares synthesized features with original attributes .
Distribution-Alignment (DA) Loss. is utilized to quantify and minimize discrepancies between latent representations generated by the visual features branch and the semantic attributes branch. In this paper, we achieve this by computing and minimizing the Wasserstein distance metric between these two types of latent representations, as expressed by the formula:
where represents the Wasserstein distance between two multivariate Gaussian distributions and , which is defined as:
In this context, and denote the mean vectors of distributions and , respectively, while and denote their covariance matrices. The objective is to minimize by adjusting model parameters, thereby aligning distributions across different modalities in an effective way.
3.3. ViT Encoder Module
This module uses the vision transformer (ViT) architecture, a system based on the transformer model [32]. It divides input features into blocks and processes that each use self-attention [34] and multi-head mechanisms. This design enables the ViT to detect long-range dependencies in the input, which is key for understanding feature relationships. Positional encoding in ViT adds information about the position of features, helping the model to recognize feature sequence and spatial relations, which are both crucial for learning spatial and structural data [32]. When applied in our variational autoencoder (VAE) variant, this method improves the capture of visual characteristics in images, leading to better classification accuracy.
Our encoder is, just like the classic ViT, built by using a feed-forward network and a multi-head self-attention layer. As shown in Figure 3, A k-dimensional feature vector is the first input used in the process. This vector is divided into m sequences, where the product of m and n equals, and each sequence contains n-dimensional feature vectors. These m–n dimensional vectors are now regarded as embeddings of eight patches, with each representing a distinct input feature segment.
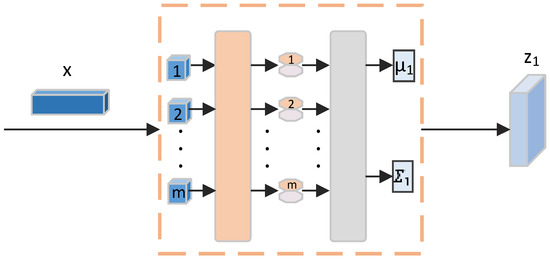
Figure 3.
Transformer encoder structure: working principle diagram.
We introduce positional encoding to retain the sequential order of patches. Each n-dimensional patch is combined with a positional encoding of identical dimensionality. This encoding is not static, and is learnable and refined in training, ensuring the dimensionality of each patch stays at n.
Subsequent steps involve layer normalization (LN) and processing through multi-head attention. In this mechanism, the input is transformed into three forms: query (q), key (k), and value (v). After self-attention processing, the output undergoes another round of layer normalization, retaining its dimensionality. The final step involves the application of a multi-layer perceptron (MLP), which initially expands feature dimensionality, before contracting it back to its original size. This step is crucial to the enhancement of the model’s expressive capability.
3.4. Advancing Zero-Shot Learning with GANs
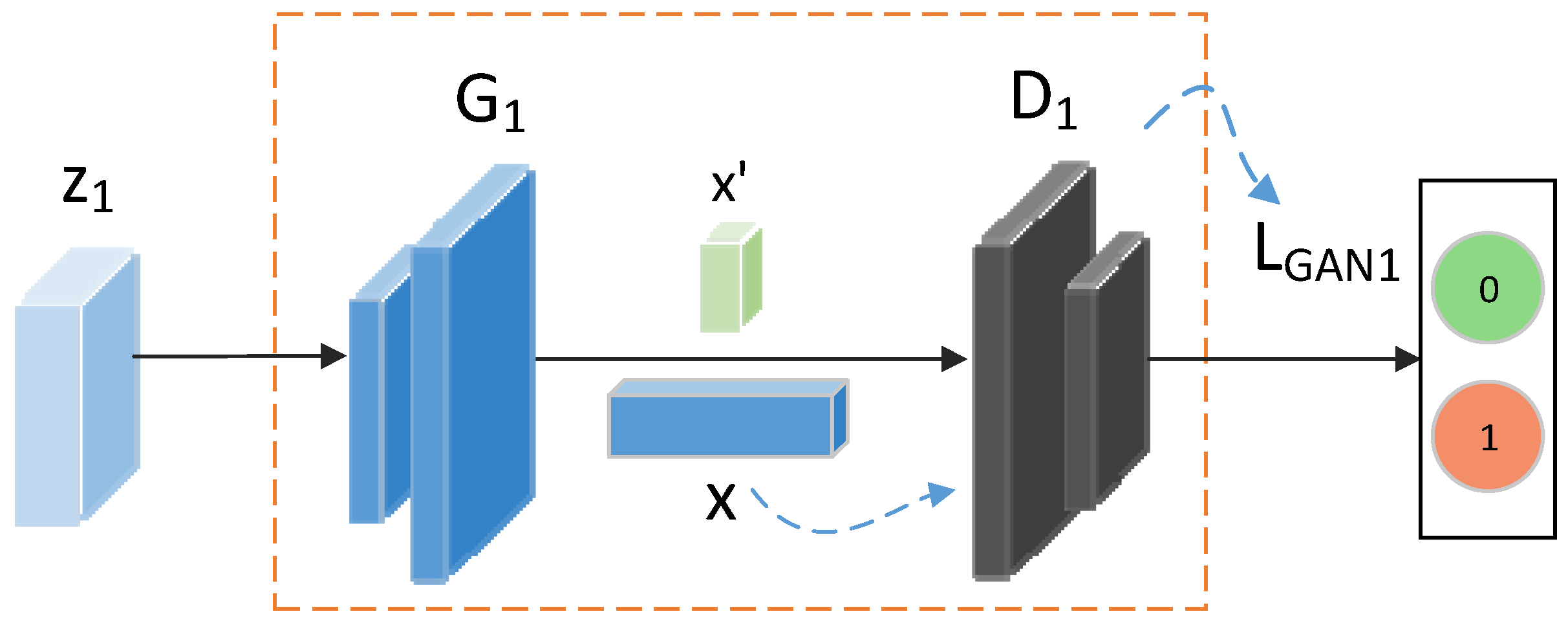
As shown in Figure 2, the decoder in the VAE serves as the generator G, forming the GAN network together with the discriminator D. The z vectors, which represent the vector representation of the feature vectors in the hidden space, are created during the training phase by randomly reconstructing the mean vector (μ) and variance vector (Σ), which are encoded by the encoder. The discriminator loss, generator loss, and total GAN loss in the GAN network are represented by the notations and the corresponding calculation methods given below:
In Figure 4, taking the visual feature branch as an example, x denotes the original visual features; represents the visual features ‘x’ established by the generator through latent variable z; and is a probability value between 0 and 1, indicating the discriminator’s assessment of the likelihood that the data generated by the generator is authentic. If is close to 1, it implies that the discriminator has been deceived into believing that the generated data is indistinguishable from genuine data; conversely, if it is close to 0, it indicates that the discriminator is able to accurately identify the data as a counterfeit generation. The GAN loss for the semantic attribute branch is the same as described above. Thus, the total loss of the GAN network is illustrated by the following formula.
where is calculated based on Equations (7)–(9). The calculation method for is identical to that of . As illustrated in Figure 2, GAN1 is the GAN for the visual feature branch, and GAN2 is the GAN for the semantic attribute branch.
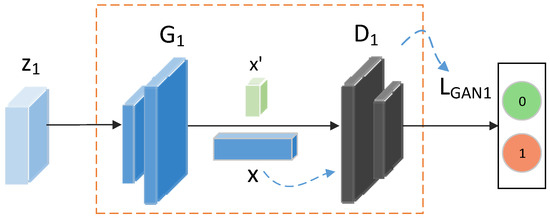
Figure 4.
Discriminator identification diagram of the visual feature branch.
During training, whenever the generator is trained, so is discriminator ; in the process of confrontation, discriminator continuously improves its discriminative ability and generator continuously improves its generative ability, up until the final point where the two reach a dynamic equilibrium; eventually is expected to generate generative data with a quality very close to x and a that is conveyed through the hidden vector z.
In summary, the network’s total loss formula is as follows:
4. Experiments
4.1. Experimental Setting
4.1.1. Datasets
We conduct extensive testing on three well-known ZSL benchmark datasets, which include both coarse-grained (e.g., CUB [35] and SUN [36]) and fine-grained (like AWA2 [37]) categories. 11,788 photos of different bird species that are identified by 312 characteristics are divided into 200 classes (150 seen and 50 unseen), and make up the CUB dataset. A total of 14,340 photos (each image is defined by 102 characteristics) that cover 717 distinct scene classes (645 visible versus 72 unseen classes) are included in the SUN collection. And each of the 50 animal groups (40 seen and 10 unseen) in the AWA2 datasets has 37,322 photos that are classified by 85 criteria.
4.1.2. Assessment Methodology
Our empirical analysis adheres to the standardized evaluation criteria delineated in [38]. In working within the context of the conventional zero-shot learning (CZSL) framework, we gauge the model’s efficacy via the top-1 accuracy metric for classes not observed during training (denoted as Acc). We determine the top-1 accuracy for the recognized (S) and unrecognized (U) classes in the generalized zero-shot learning (GZSL) paradigm, along with the harmonic mean of these accuracies, which is mathematically expressed as H = (2 × S × U)/(S + U).
4.1.3. Implementation Details
All of the visual features after [39] are taken fromResNet101′s 2048-D top-layer pooling units [40]. In order to retrieve the feature map without fine-tuning, we pretrain the ResNet101 on the ImageNet [41] by using 1000 classes of input. Each encoder and decoder in our model is a single-hidden-layer multilayer perceptron. CNN features and characteristics are advanced, and so adding more layers results in a decreased performance. We employ 1660 hidden units for the decoder and 1560 hidden units for picture feature encoding, and there are 1450 hidden units in the attribute encoder and 660 hidden units in the decoder. The latent embedding size for ImageNet is 128 (with two hidden layers in the encoder of the aforementioned size), compared to 64 for other networks. There are 1160 and 1660 units in the picture feature decoder layers, and 460 and 660 units in the attribute decoder. The Adam optimizer and stochastic gradient descent are used, and training takes place across 100 epochs [42]. For ImageNet, the batch size is 128, compared to 50 for other datasets. CNN feature-attribute pairs from the same class are included in each batch, and data pairs are consistently found belong to the same class. We include cross and distribution alignment losses beyond the initial epochs, in which variational autoencoders (VAEs) learn to encode particular types of input. The parameter δ is incrementally increased from 0.54 per epoch between the 6th and 22nd epochs, while γ increases by 0.044 per epoch from the 21st to the 75th epoch. We use an annealing approach for Kullback-Leibler (KL) divergence, and the weight β of the KL divergence is increased by 0.0026 per epoch up to the 90th epoch.
4.2. Comparison with State-of-the-Art Methods
This section compares our dual variational autoencoders and generative adversarial networks (DVAGAN) across three benchmark datasets (CUB, SUN, and AWA2) in the CZSL and GZSL settings. Table 1 displays the experiment results.

Table 1.
Results (%) of state-of-the-art GZSL and CZSL modes for CUB, SUN, and AWA2, including those obtained through both non-generative and generative methods. The initials U, S, and H stand for seen, unseen, and harmonic mean, respectively, and their accuracies are describedfor GZSL. ZSL performance results are displayed with average top-1 classification accuracy (Acc). * signifies that the vertebrae are modified. The best results are indicated by red font, and the second-best results are shown in blue font.
Conventional zero-shot learning compared to generative models: In the CUB dataset, ‘Ours’ achieves an accuracy rate of 64.6%, surpassing all generative models, including the best-performing generative model HSVA, which registers 62.8%. In the AWA2 dataset, ‘Ours’ also shows exceptional performance with an accuracy rate of 71.8%, significantly outperforming all other models. Furthermore, the experimental results indicate that the model performs well when applied to fine-tuned datasets. For instance, in the fine-tuned SUN dataset, accuracy increases from 60.0% to 63.3%, while in the fine-tuned AWA2 dataset, accuracy improves from 71.8% to 77.1%. In the CZSL experiments, the model shows optimal performance when applied to AWA2, a coarse-grained dataset; when applied to the fine-grained CUB dataset, it shows diminished effectiveness; and moderate performance when applied to the SUN dataset, which requires intricate scene understanding, These outcomes suggest that the model possesses robust capabilities for differentiating between categories with significant variances, and that it may need to be further refined before being applied to categories characterized by subtle visual distinctions. In addition, these results imply the model’s attribute learning mechanisms can be adapted across datasets with varying complexity, and also attest to the efficacy of its attention mechanism in capturing details critical for classification. These findings may therefore point to potential avenues that can be pursued when seeking to enhance model performance in fine-grained visual tasks.
Generalized zero-shot learning. We evaluate our model against ten cutting-edge models, and then divide them into generative and non-generative categories. Of these, f-CLSWGAN [43], LisGAN [44], GCM-CF [45], FREE [46], HSVA [47], Proposed KNN [48] and Dual VAEGAN [49] focus on generating synthetic visual data to augment datasets for zero-shot learning, and aim to enhance generalization to unseen classes.
DeVise [50], Cada-vae [51], DVBE [3], GEM-ZSL [52] and DGCNet [53] emphasize embedding and aligning features by using linear or non-linear functions, graph embeddings, or convolutional approaches, without synthetic data generation. Generative models create artificial data to aid improved learning, and non-generative models rely on sophisticated feature alignment and embedding techniques.
Referring to the experimental results above, the DVAGAN model and its variant DVAGAN* demonstrate a notably strong performance, when compared to ten benchmark models from the CUB, SUN, and AWA2 datasets. In the CUB dataset, DVAGAN* excels in recognizing unseen categories (U metric), achieving 54.1%, surpassing the majority of control models, while falling short of the GEM-ZSL model (64.8%). In the SUN dataset, DVAGAN* shows significant generalization capabilities, leading all other models with a 51.2% score on the U metric. While not optimal on the S metric, its robust performance on the H metric is particularly salient, underlining its relative advantage in balancing performance across seen and unseen categories. In the AWA2 dataset results, DVAGAN* is at the forefront with a U metric score of 70.5% and an S metric high of 83.5%, accentuating its comprehensiveness. Crucially, its score of 76.4% on the H metric surpasses all other models, affirming its optimal balancing of generalization and specific category recognition. The relative underperformance of the CUB dataset can be attributed to the challenges DVAGAN* encountered when processing subtle differences, indicating a need for the enhanced specialization of fine-grained recognition tasks. However, the performance of the AWA2 dataset confirms DVAGAN* has a superior ability in coarse-grained generalization tasks, which aptly extend to new, broad categories. The SUN dataset, which straddles coarse and fine granularities, encapsulates a spectrum of categorization demands. The performance of DVAGAN* in the SUN dataset, especially in the U metric, shows its capacity to be generalized across varying granularities.
In contrast, the proposed KNN [48] method, which also uses a combination of variational autoencoders and generative adversarial networks, our approach achieves a more explicit separation and reconstruction of features and semantic information. Similarly, while the Dual VAEGAN [49] method resonates with our concept by introducing a dual variational autoencoder generative network, our network more strongly emphasises the reconstruction of features in different spaces (image and semantic) and incorporates novel loss functions in order to optimize reconstruction errors and adversarial discrepancies. In referring to the f-VAEGAN-D2 [7] method, which does not use a dual encoder structure, our experimental results indicate a substantial gap in performance, sufficiently demonstrating the rationality and superiority of our network architecture.
DVAGAN uses a dual-branch VAE with a GAN network, and its generation of samples from unseen classes differentiates it from the CADA-VAE, and enhances recognition accuracy and generalization. This approach yields superior performance across three datasets. Additionally, an attention mechanism in our model promotes effective multimodal fusion, improving outcomes in datasets with complex classes. While it performs well on fine-grained tasks and excels in coarse-grained datasets (especially in capturing prominent class distinctions), its distinguishing of similar categories has clear room for improvement, as shown by its second place ranking in the intricate SUN dataset.
The results indicate that our algorithm consistently outperforms the baseline algorithm, demonstrating outstanding scalability and computational practicality. Theoretically our approach, which adjusts hyperparameters and integrates additional computational modules, could potentially be adapted to even larger-scale datasets. Future plans could include conducting experiments on even larger datasets, and optimizing strategies to enhance computational efficiency, which could help to ensure the method’s continued practicality in real world applications.
In summary, when compared to the ZSL methods (contrasted with our approach in Table 1)each exhibits distinct strengths, including the use of generative models to enhance data representation; the mapping of learning to simplify feature alignment; and embedding space learning to balance the alignment of visual and semantic information. However, these methods may have limitations, including mode collapse, over-reliance on seen classes, and insufficient generalization capabilities for unseen classes (especially when there are significant differences between datasets). In comparison, our method integrates dual variational autoencoders with generative adversarial networks, and aims to enhance the authenticity and discriminative power of features through separate encoders and decoders for image visual features and category semantic information, which it then couples with adversarial loss to further optimize the model’s ability to be generalized to unseen classes. This architecture effectively leverages complex semantic information and surpasses traditional ZSL methods, in terms of cultivating diversity and creativity.
4.3. Hyperparameter Analysis
- (1)
- Increasing Number of Latent Dimensions.
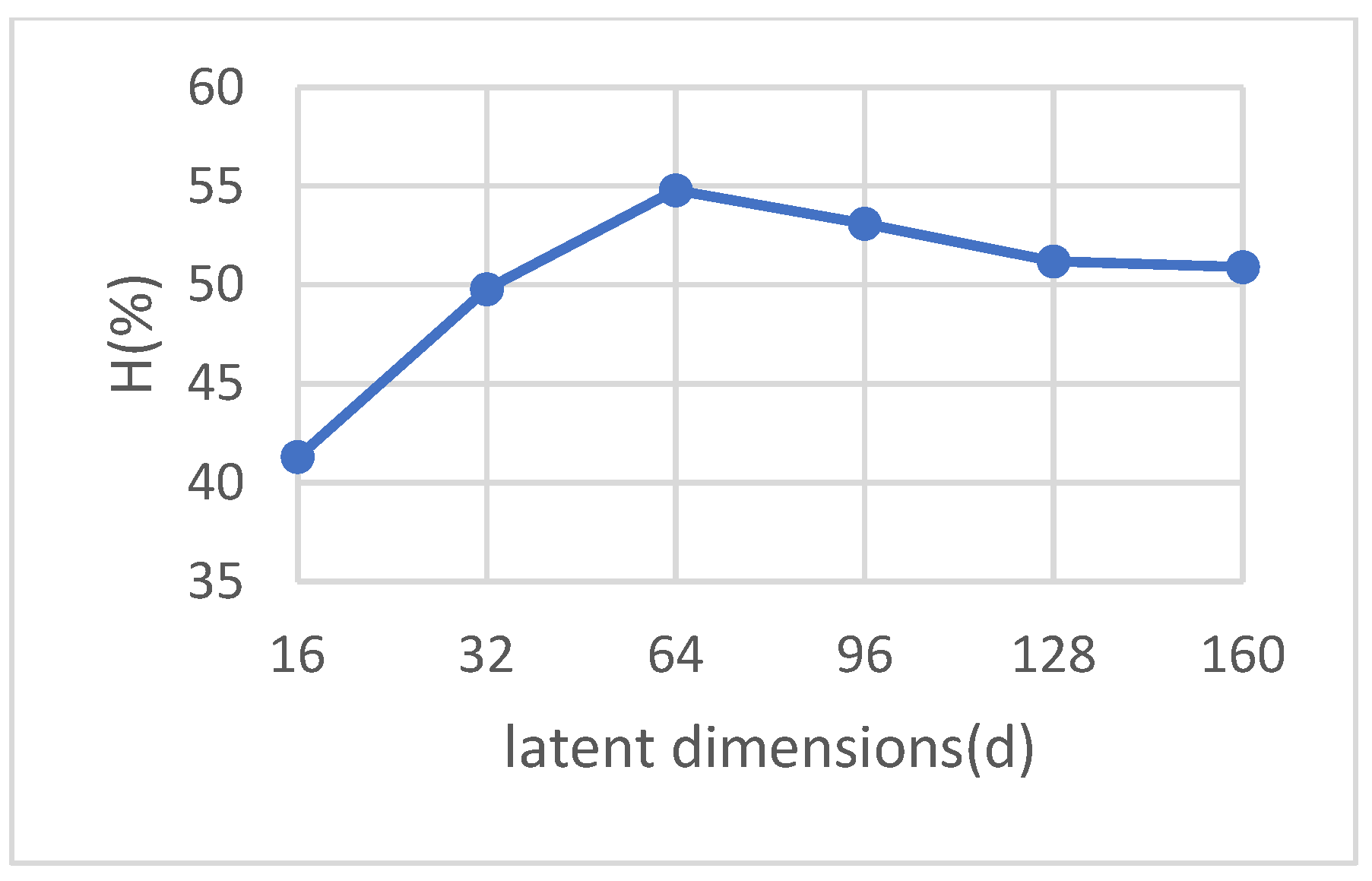
We have thoroughly assessed the robustness of our suggested strategy against changes in the latent space’s dimensionality. Although we recognize that higher-dimensional latent spaces provide more degrees of freedom, we also note that they simultaneously require a larger volume of data. Conversely, lower-dimensional spaces more efficiently encapsulate essential discriminative features. In attempting to generalize our findings, we present the harmonic mean accuracy of the DVAGAN model across different latent dimensions (16, 32, 64, 96, 128, and 160) in the CUB dataset. As illustrated in Figure 5, we observe an initial increment in accuracy with an increase in dimensionality, which peaks at 54.8% accuracy at a latent dimension of 64; beyond this, there is a discernible decline in performance, with further dimensional augmentation. These findings lead us to infer that the optimal balance (for capturing the most discriminative attributes of the two modalities) can be achieved at a latent space dimensionality of approximately 64.
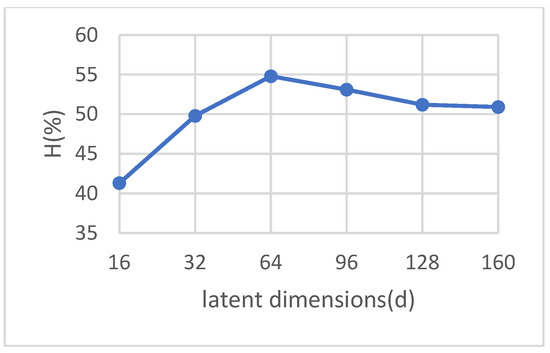
Figure 5.
Evaluating DVAGAN latent feature dimensionality in GZSL classifier performance with harmonic mean accuracy on the CUB dataset.
- (2)
- Sensitivity Analysis of Disentanglement Hyperparameters
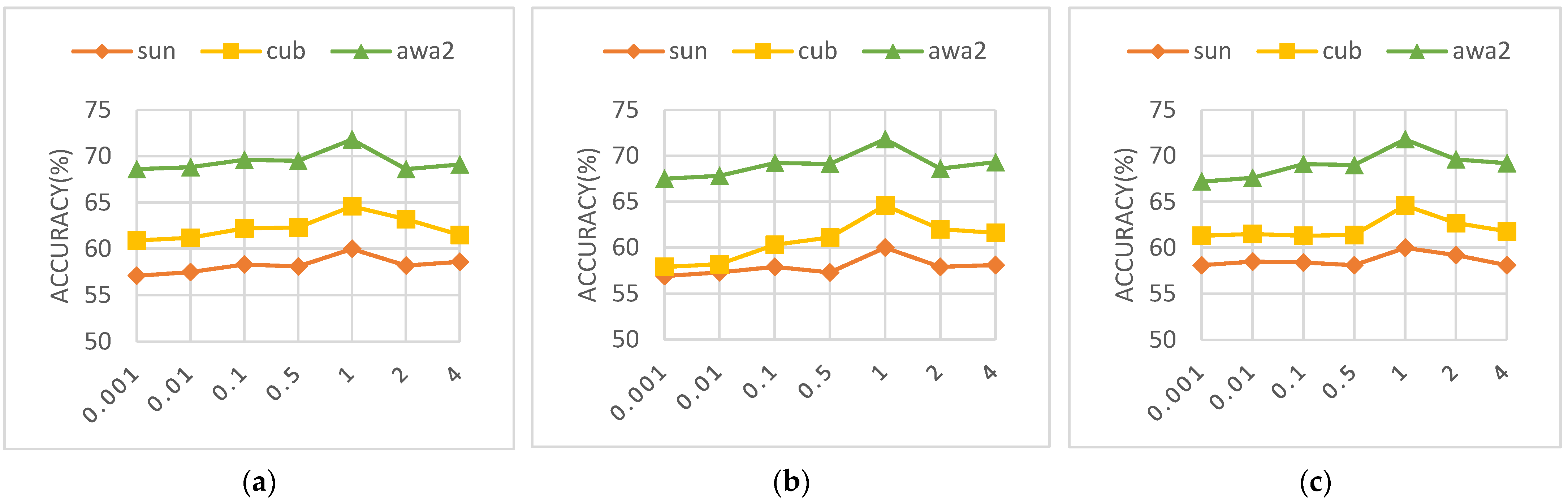
In the context of our study, the optimization objective is governed by three principal hyperparameters: the coefficient for the Cross-Alignment loss (λ1), the coefficient for the Distribution-Alignment loss (λ2), and the coefficient for the discriminator loss (λ3). To elucidate the influence of each disentanglement component on model performance, we have conducted a sensitivity analysis of these hyperparameters. In this context, the values for λ1, λ2, and λ3 are set to {0.001, 0.01, 0.1, 0.5, 1, 2, 4}. It will be noted how different parameters affect the CZSL’s accuracy, whose outcomes are displayed in Figure 6.
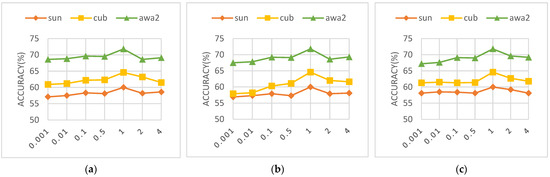
Figure 6.
Hyper-parameter study w.r.t. CA weight , DA weight , and Discriminator weight . (a) CA weight (b) DA weight (c) Discriminator weight .
In Figure 6, the line graphs clearly demonstrate the substantial impact of the values of λ1, λ2, and λ3 on the experimental outcomes. Observing the variations of these hyperparameters from 0.001 to 4, we note that the highest accuracy across the SUN, CUB, and AWA2 datasets is achieved when the parameters are set to 1, which indicates that the hyperparameter weights significantly affect the model’s accuracy. After integrating insights from all three graphs, it becomes apparent that a weight setting of 1 for λ1, λ2, and λ3 has a positive impact on accuracy for all datasets, suggesting that the model is highly sensitive to these hyperparameters. Therefore, a weight of 1 appears to be an optimal hyperparameter setting (for these datasets). In taking these findings into account, subsequent experiments could be designed that further investigate the specific effects of minor fluctuations around this hyperparameter value, with the aim of pinpointing the most advantageous hyperparameter configuration for optimal model performance in diverse datasets.
4.4. Ablation Study
In our ablation study, we aim to isolate the impact of key components in our dual-branch VAE model for zero-shot learning. We remove the distribution alignment loss () to assess the dual VAE’s alignment efficacy; omit the cross-alignment loss () to evaluate the multimodal fusion module; and exclude the GAN loss () to determine the GAN network’s contribution to generalization. These targeted modifications will clarify the role each component plays in the model’s synthesizing and classifying of unseen data. The experimental results are shown in Table 2.
Table 2.
Results of ablation experiments.
In the ablation study, the results indicate that each component—distribution alignment (), cross-alignment (), and GAN loss ()—is integral to DVAGAN’s performance: is essential for unseen class accuracy (U), as its removal reduces U and harmonic mean (H) scores across all datasets. is critical for multimodal integration, as its ablation leads to lower H scores, highlighting its role in synthesizing and aligning multimodal information. contributes to the model’s generalization capabilities, which was especially evident in the noted class accuracy (S) and H scores.
The complete DVAGAN model demonstrates superior performance across all metrics, justifying its architecture for balancing unseen and seen class recognition in zero-shot learning contexts. The integration of VAEs with a GAN framework in DVAGAN is therefore validated as a coherent and effective approach to enhancing model generalization and accuracy in complex multimodal learning scenarios.
5. Conclusions
In comprehensively exploring the zero sample learning (ZSL) paradigm, this paper has not only highlighted the integration of advanced transformer architecture and generative adversarial network (GAN) principles, but has also underscored the pivotal role of multimodal fusion in enhancing ZSL. The practical implications of our findings extend far beyond academic interests, and open up promising avenues for real world applications. For instance, our model’s improved ability to classify unseen entities makes it highly applicable to areas such as medical diagnostics, where it can aid the identification of novel disease patterns; similarly, in being applied to automated wildlife monitoring, it could facilitate the recognition of rare species that were not present in initial training data.
Looking ahead, future research should focus on addressing trade-offs between performance gains and computational practicality. Efforts should be directed towards optimizing the model’s architecture so that its computational demands are reduced, and to maintaining, or perhaps even enhancing, its classification accuracy and generalization capabilities. Continued exploration of the realm of ZSL will undoubtedly lead to more refined and efficient models, further advancing the field and broadening the practical applicability of these techniques. One avenue that should be pursued immediately is to refine our approach to real time applications, where computational efficiency is paramount. Another potential direction is adapting our model to cross-disciplinary use—for example, in linguistics, it could be applied to language processing; and, in finance, to predictive analytics. Finally, in taking the ethical implications of AI into account, future work should also involve ensure that our model’s use in diverse applications is fully aligned with ethical standards, including the on reduction of biases and the promotion of fairness.
Author Contributions
Conceptualization, N.L. and J.C.; Methodology, N.L., J.C. and N.F.; Software, N.L. and W.X.; Validation, N.L. and N.F.; Formal analysis, N.L. and J.C.; Investigation, N.L., N.F. and T.Y.; Resources, N.L. and W.X.; Data curation, N.L. and J.C.; Writing—original draft preparation, T.Y. and J.C.; Writing—review and editing, T.Y. and J.C.; Visualization, W.X.; Supervision, C.G. and P.Z.; Project administration, C.G. and P.Z.; Funding acquisition, C.G. and P.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This paper was partially supported by the National Natural Science Foundation of China (Grant 62075031) and the Intelligent Terminal Key Laboratory of Sichuan Province (Grant SCITLAB-30007). Research on Quality Inspection Robot Technology for Intelligent Terminal Production Line (Project Number: DZKJDX202102001).
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pourpanah, F.; Najafi-Haghi, Z.P.; Wunderlich, H.-J.; Yang, B. A Review of Generalized Zero-Shot Learning Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 4051–4070. [Google Scholar] [CrossRef]
- Fan, W.; Liang, C.; Wang, T. Contrastive Semantic Disentanglement in Latent Space for Generalized Zero-Shot Learning. Knowl.-Based Syst. 2022, 257, 109949. [Google Scholar] [CrossRef]
- Min, S.; Yao, H.; Xie, H.; Wang, C.; Zha, Z.; Zhang, Y. Domain-Aware Visual Bias Eliminating for Generalized Zero-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12661–12670. [Google Scholar]
- Luo, Z.; Li, Q.; Zheng, J. Deep feature fusion for rumor detection on twitter. IEEE Access 2021, 9, 126065–126074. [Google Scholar] [CrossRef]
- Tu, K.; Chen, C.; Hou, C.; Yuan, J.; Li, J.; Yuan, X. Rumor2vec: A rumor detection framework with joint text and propagation structure representation learning. Inf. Sci. 2021, 560, 137–151. [Google Scholar] [CrossRef]
- Li, Q.; Rigall, E.; Sun, X.; Lam, K.M.; Dong, J. Dual Autoencoder Based Zero Shot Learning in Special Domain. Pattern Anal. Appl. 2022, 26, 797–808. [Google Scholar] [CrossRef]
- Schopf, T.; Braun, D.; Matthes, F. Evaluating Unsupervised Text Classification: Zero-shot and Similarity-based Approaches. arXiv 2022, arXiv:2211.16285. [Google Scholar]
- Ye, Z.; Yang, G.; Jin, X.; Liu, Y.; Huang, K. Rebalanced Zero-shot Learning. arXiv 2022, arXiv:2210.07031v2. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Mai Ngoc, K.; Hwang, M. Finding the Best k for the Dimension of the Latent Space in Autoencoders. In Proceedings of the ICCCI 2020, Da Nang, Vietnam, 30 November–3 December 2020; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2020; Volume 12496. [Google Scholar]
- Li, K.; Ye, W. A Generative Adversarial Active Learning Method for Mechanical Layout Generation. Neural Comput. Appl. 2023, 35, 19315–19335. [Google Scholar] [CrossRef]
- Arora, G.; Verma, V.; Mishra, A.; Rai, P. Generalized Zero-Shot Learning via Synthesized Examples. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4281–4289. [Google Scholar]
- Xian, Y.; Sharma, S.; Schiele, B.; Akata, Z. F-VAEGAN-D2: A Feature Generating Framework for Any-Shot Learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10267–10276. [Google Scholar]
- Chen, X.; Lan, X.; Sun, F.-C.; Zheng, N. A Boundary Based Out-of-Distribution Classifier for Generalized Zero-Shot Learning. In Proceedings of the ECCV, Online, 23–28 August 2020. [Google Scholar]
- Ding, Z.; Liu, H. Marginalized Latent Semantic Encoder for Zero-Shot Learning. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 6184–6192. [Google Scholar]
- Ma, S.; Xu, S. A Semantic Relevance Based Neural Network for Text Summarization and Text Simplification. arXiv 2017, arXiv:1710.02318. [Google Scholar]
- Madnick, S.; Zhu, H. Improving Data Quality through Effective Use of Data Semantics. Data Knowl. Eng. 2006, 59, 460–475. [Google Scholar] [CrossRef]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- He, Q.; Yang, Z.; Tian, M. A Full Stage Data Augmentation Method in Deep Convolutional Neural Network for Natural Image Classification. Discrete Dyn. Nat. Soc. 2020, 2020, 4706576. [Google Scholar]
- Wang, D.; Liu, K.; Mohaisen, D.; Wang, P.; Lu, C.; Fu, Y. Automated Feature-Topic Pairing: Aligning Semantic and Embedding Spaces in Spatial Representation Learning. arXiv 2021, arXiv:2109.11053. [Google Scholar]
- Alexander, K.; An, Y. A Survey of Embedding Space Alignment Methods for Language and Knowledge Graphs. arXiv 2010, arXiv:2010.13688. [Google Scholar]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative Adversarial Network: An Overview of Theory and Applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An Attentive Survey of Attention Models. arXiv 2019, arXiv:1904.02874. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM. 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2022, arXiv:1312.6114. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Hughes, D.C.; Ellefsen, S.; Baar, K. Adaptations to Endurance and Strength Training. Cold Spring Harb. Perspect. Med. 2018, 8, a029769. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A General Survey on Attention Mechanisms in Deep Learning. IEEE Trans. Knowl. Data Eng. 2023, 35, 3279–3298. [Google Scholar] [CrossRef]
- Chen, J.; Geng, Y.; Chen, Y. Knowledge-aware Zero-Shot Learning: Survey and Perspective. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–26 August 2021. [Google Scholar]
- Han, Z.; Fu, Z.; Chen, S.; Yang, J. Contrastive Embedding for Generalized Zero-Shot Learning. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2371–2381. [Google Scholar]
- Wendy, M.; Sachiko, K. Congruence Effect in Semantic Categorization with Masked Primes with Narrow and Broad Categories. J. Mem. Lang. 2008, 58, 286–306. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Ji, N.; Dong, H.; Meng, F.; Pang, L. Semantic Segmentation and Depth Estimation Based on Residual Attention Mechanism. Sensors 2023, 23, 7466. [Google Scholar] [CrossRef]
- Silenzi, A.; Castorani, V.; Tomassini, S.; Falcionelli, N.; Contardo, P.; Bonci, A.; Dragoni, A.F.; Sernani, P. Quality Control of Carbon Look Components via Surface Defect Classification with Deep Neural Networks. Sensors 2023, 23, 7607. [Google Scholar] [CrossRef]
- Chowdhary, A.; Jha, K.; Zhao, M. Generative Adversarial Network (GAN)-Based Autonomous Penetration Testing for Web Applications. Sensors 2023, 23, 8014. [Google Scholar] [CrossRef]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.J.; Perona, P. Caltech-Ucsd Birds 200; Tech. Rep. CNS-TR-2010-001, Caltech: Pasadena, CA, USA, 2010. [Google Scholar]
- Patterson, G.; Hays, J. Sun Attribute Database: Discovering, Annotating, and Recognizing Scene Attributes. In Proceedings of the CVPR, Providence, RI, USA, 16–21 June 2012; pp. 2751–2758. [Google Scholar]
- Xian, Y.; Schiele, B.; Akata, Z. Zero-Shot Learning—The Good, the Bad and the Ugly. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 3077–3086. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-shot learning—A comprehensive evaluation of the good, the bad and the ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2251–2265. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xian, Y.; Lorenz, T.; Schiele, B.; Akata, Z. Feature generating networks for zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5542–5551. [Google Scholar]
- Li, J.; Jing, M.; Lu, K.; Ding, Z.; Zhu, L.; Huang, Z. Leveraging the invariant side of generative zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7402–7411. [Google Scholar]
- Yue, Z.; Wang, T.; Zhang, H.; Sun, Q.; Hua, X. Counterfactual Zero-Shot and Open-Set Visual Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, S.; Wang, W.; Xia, B.; Peng, Q.; You, X.; Zheng, F.; Shao, L. FREE: Feature Refinement for Generalized Zero-Shot Learning. In Proceedings of the International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Chen, S.; Xie, G.-S.; Liu, Y.; Peng, Q.; Sun, B.; Li, H.; You, X.; Shao, L. HSVA: Hierarchical Semantic-Visual Adaptation for Zero-Shot Learning. In Proceedings of the Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021. [Google Scholar]
- Gao, R.; Hou, X.; Qin, J.; Chen, J.; Liu, L.; Zhu, F.; Zhang, X.; Shao, L. Zero-VAE-GAN: Generating unseen features for generalized and transductive zero-shot learning. IEEE Trans. Image Process. 2020, 29, 3665–3680. [Google Scholar] [CrossRef]
- Luo, Y.; Wang, X.; Pourpanah, F. Dual VAEGAN: A generative model for generalized zero-shot learning. Appl. Soft Comput. 2021, 107, 107352. [Google Scholar] [CrossRef]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Mikolov, T. Devise: A deep visual-semantic embedding model. In Proceedings of the Neural Information Processing Systems (NIPS), Lake Tahoe, CA, USA, 5–10 December 2013. [Google Scholar]
- Schonfeld, E.; Ebrahimi, S.; Sinha, S.; Darrell, T.; Akata, Z. Generalized zero- and few-shot learning via aligned variational autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8247–8255. [Google Scholar]
- Liu, Y.; Zhou, L.; Bai, X.; Huang, Y.; Gu, L.; Zhou, J.; Harada, T. Goal-Oriented Gaze Estimation for Zero-Shot Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3794–3803. [Google Scholar]
- Zhang, Y.; Tian, Y.; Zhang, S. Dual-uncertainty Guided Cycle-consistent Network for Zero-shot Learning. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6872–6886. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).