
Charge-Domain Static Random Access Memory-Based In-Memory Computing with Low-Cost Multiply-and-Accumulate Operation and Energy-Efficient 7-Bit Hybrid Analog-to-Digital Converter


Abstract
:1. Introduction

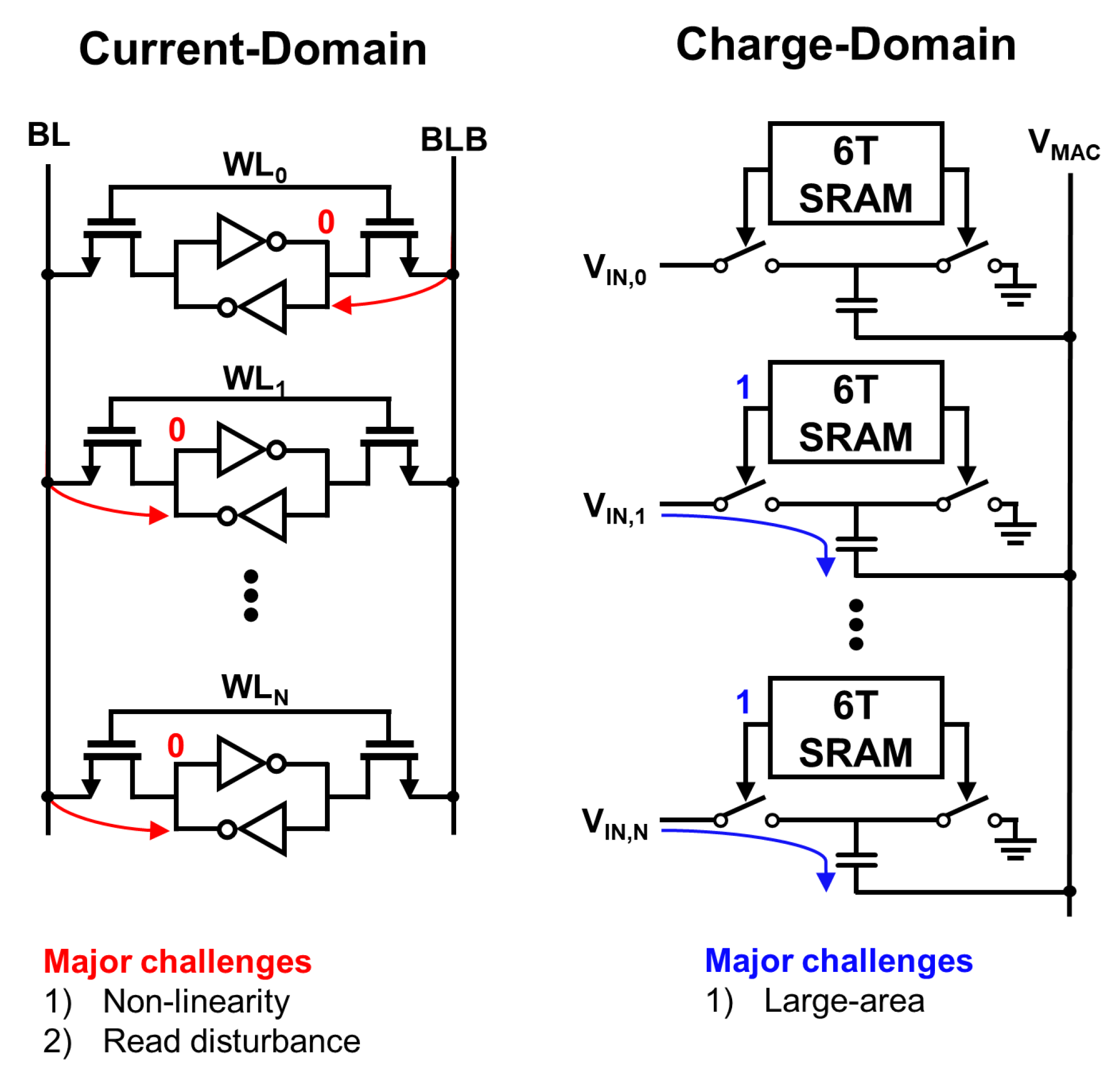
- The proposed capacitive coupling is free from charge injection and additional input signals that occur based on switched-capacitor. Thus, the summation mechanism proposed in this paper can reduce the required capacitance substantially.
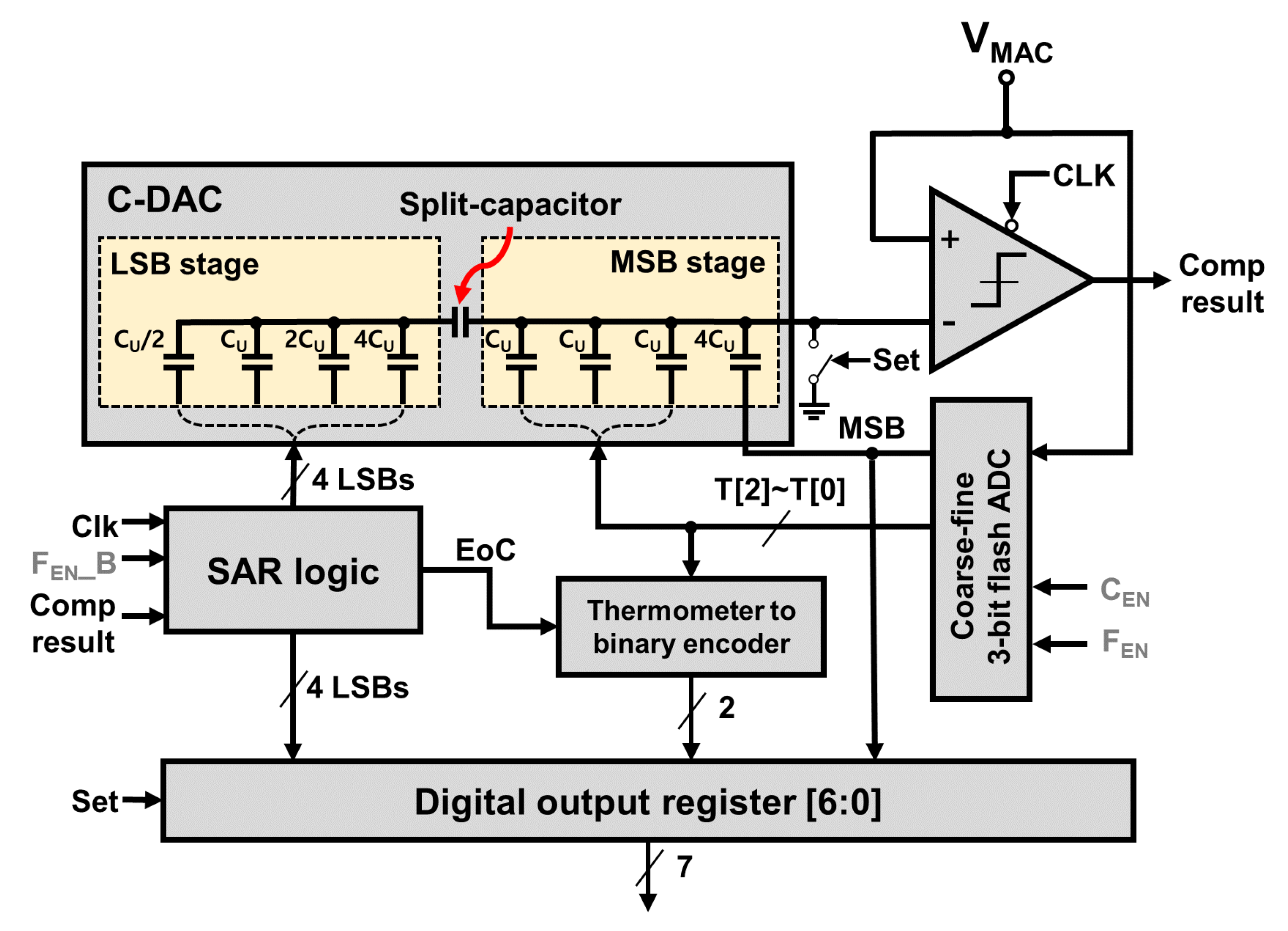
- Proposed an energy-efficient 7-bit flash-SAR Hybrid ADC (FS ADC) that merges the strengths of both flash and SRA ADC architectures to address the limitations associated with each ADC.
- The proposed coarse–fine architecture of the flash ADC reduces the number of comparators from 2N − 1 to 2N − 1, minimizing the impact of the comparator’s input gate capacitance. This not only reduces errors in the MAC generated by capacitive coupling in in-memory arrays, but also enables 4-bit summation with low capacitance.
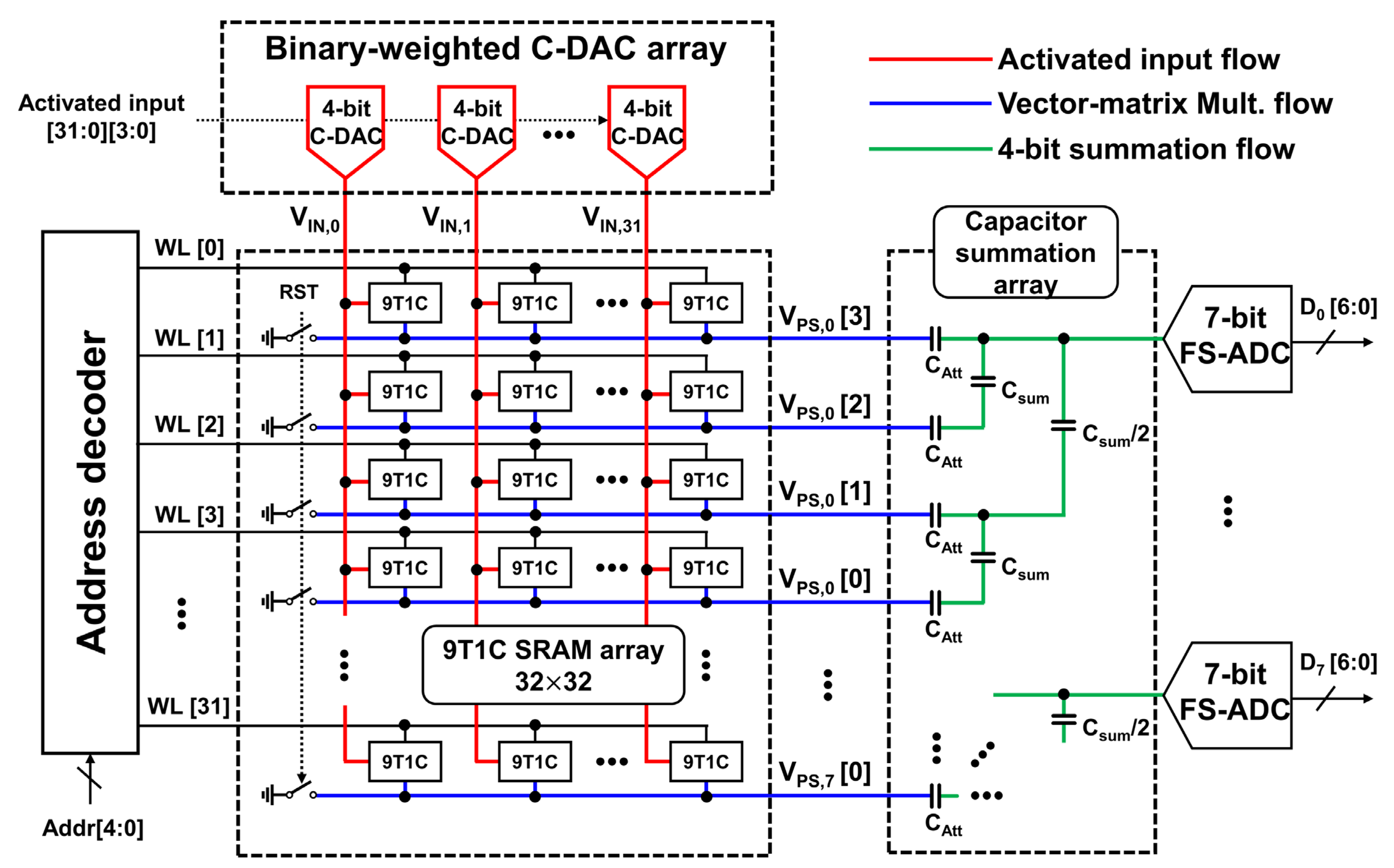
2. Proposed Charge-Domain Computing Architecture
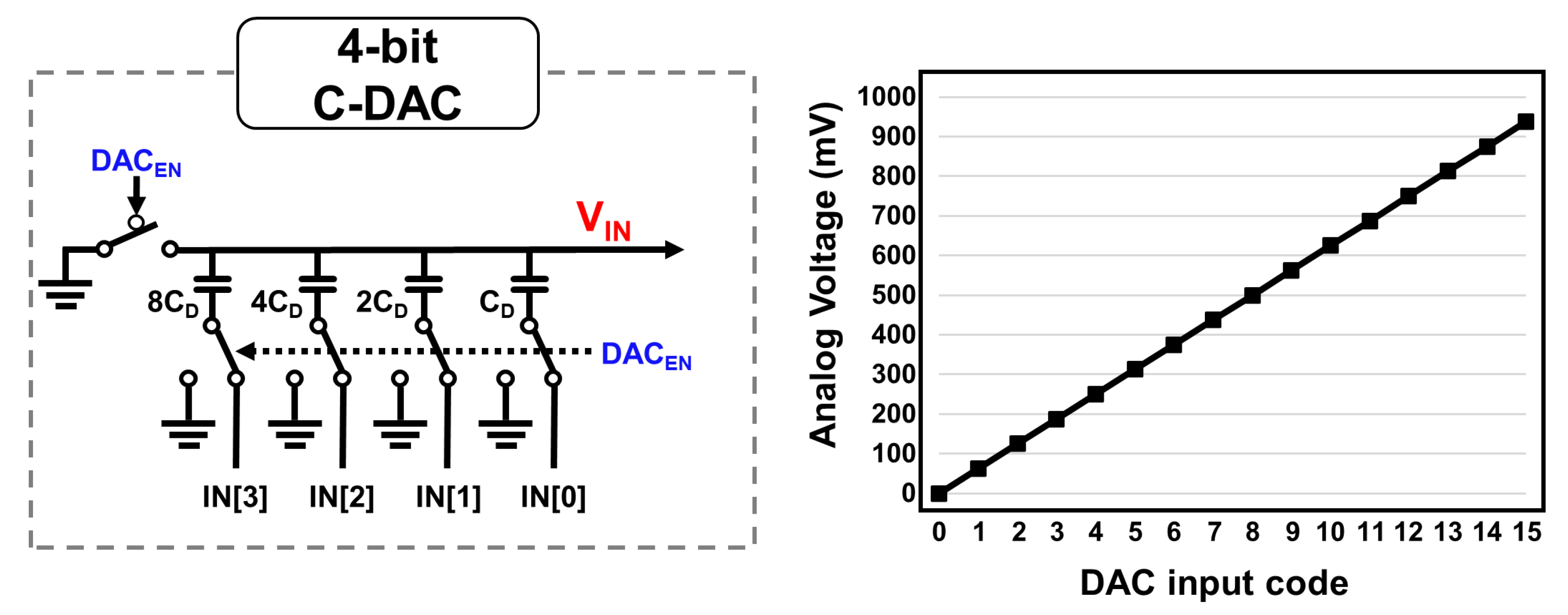
2.1. Binary Weighted Capacitor DAC
2.2. 9T1C Bitcell
2.3. Proposed Capacitor Summation Mechanism
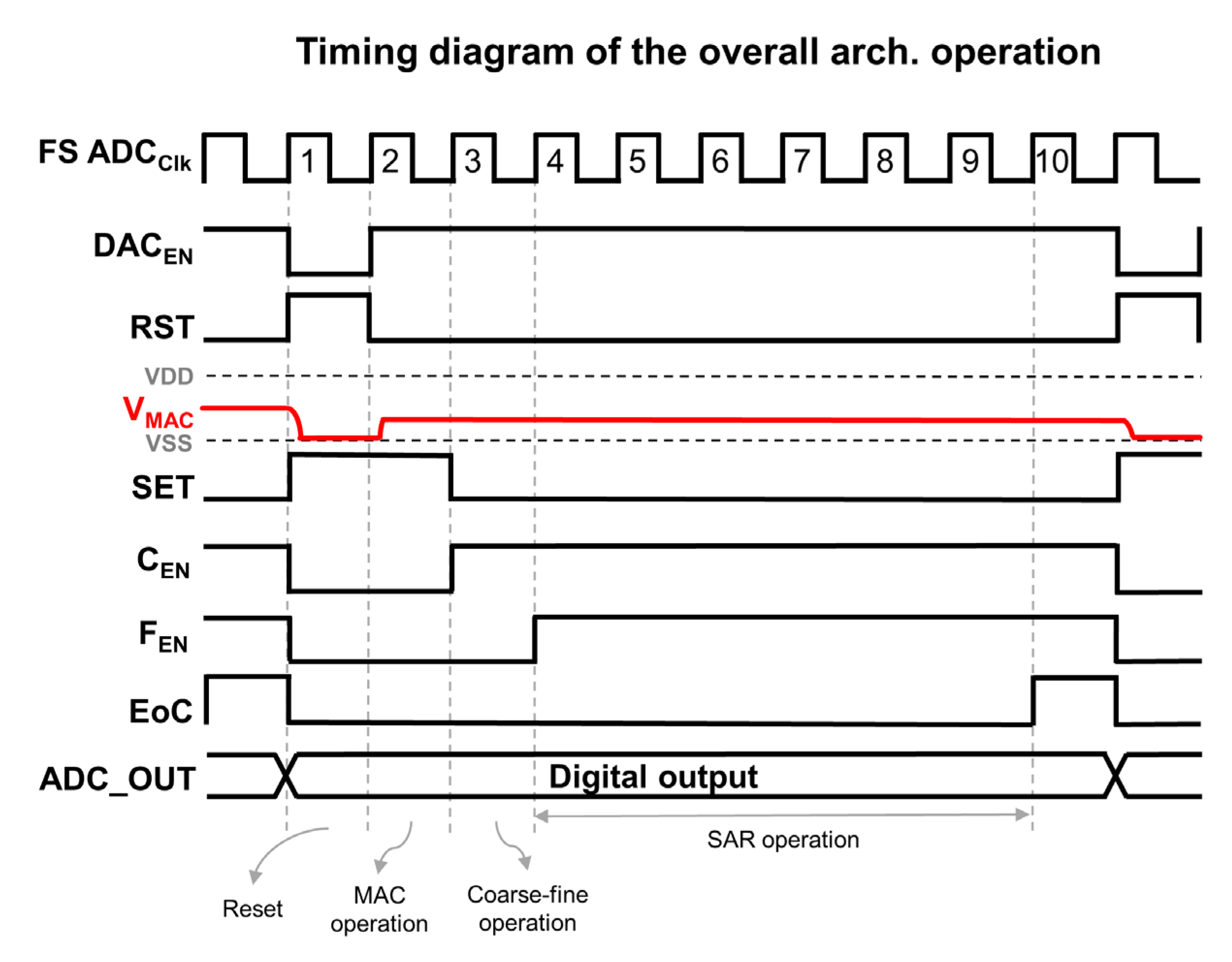
3. Architecture of Flash-SAR Hybrid ADC
3.1. Coarse–Fine Flash ADC
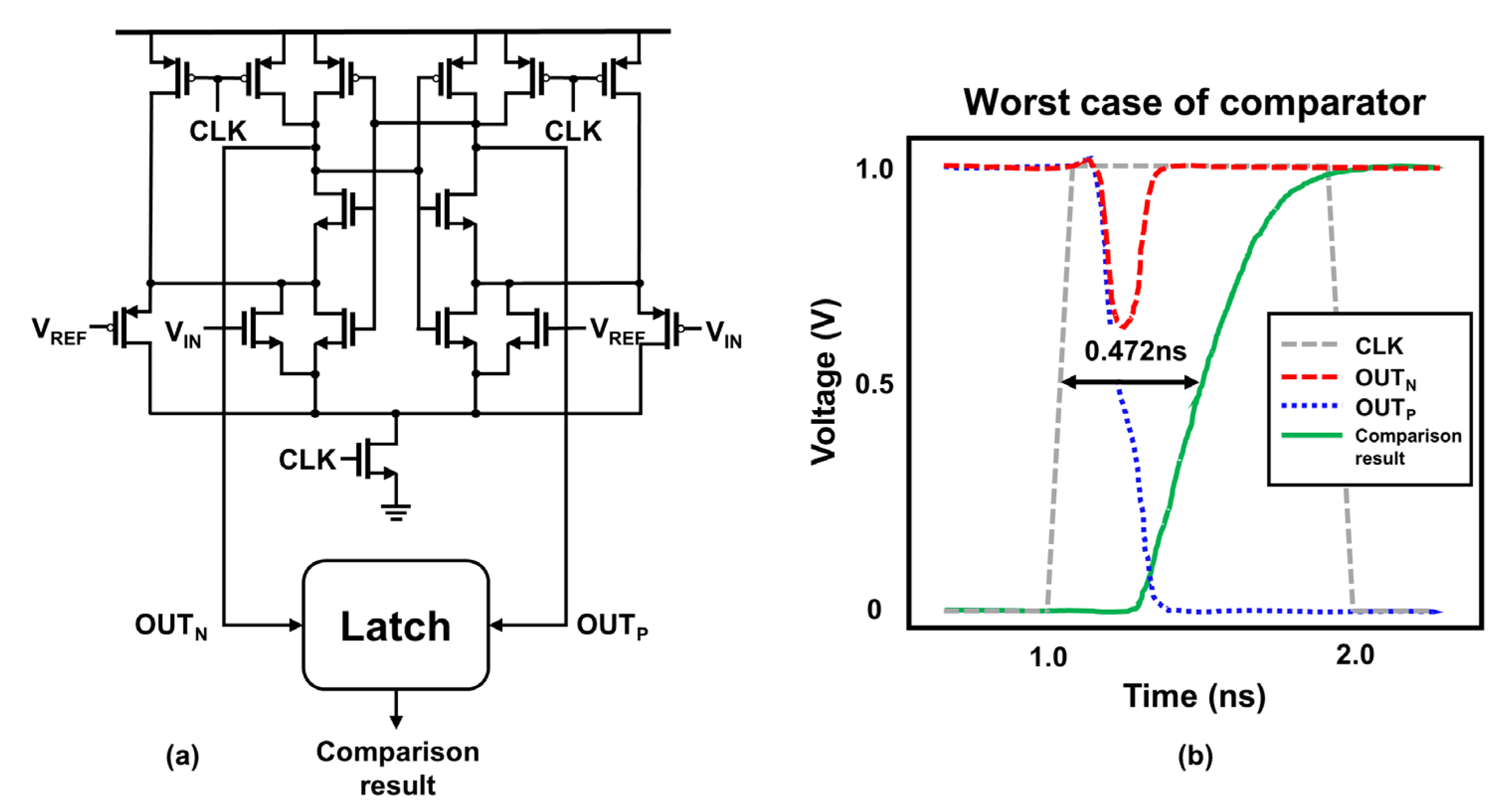
3.2. High-Speed Rail-to-Rail Comparator
4. Simulation Results
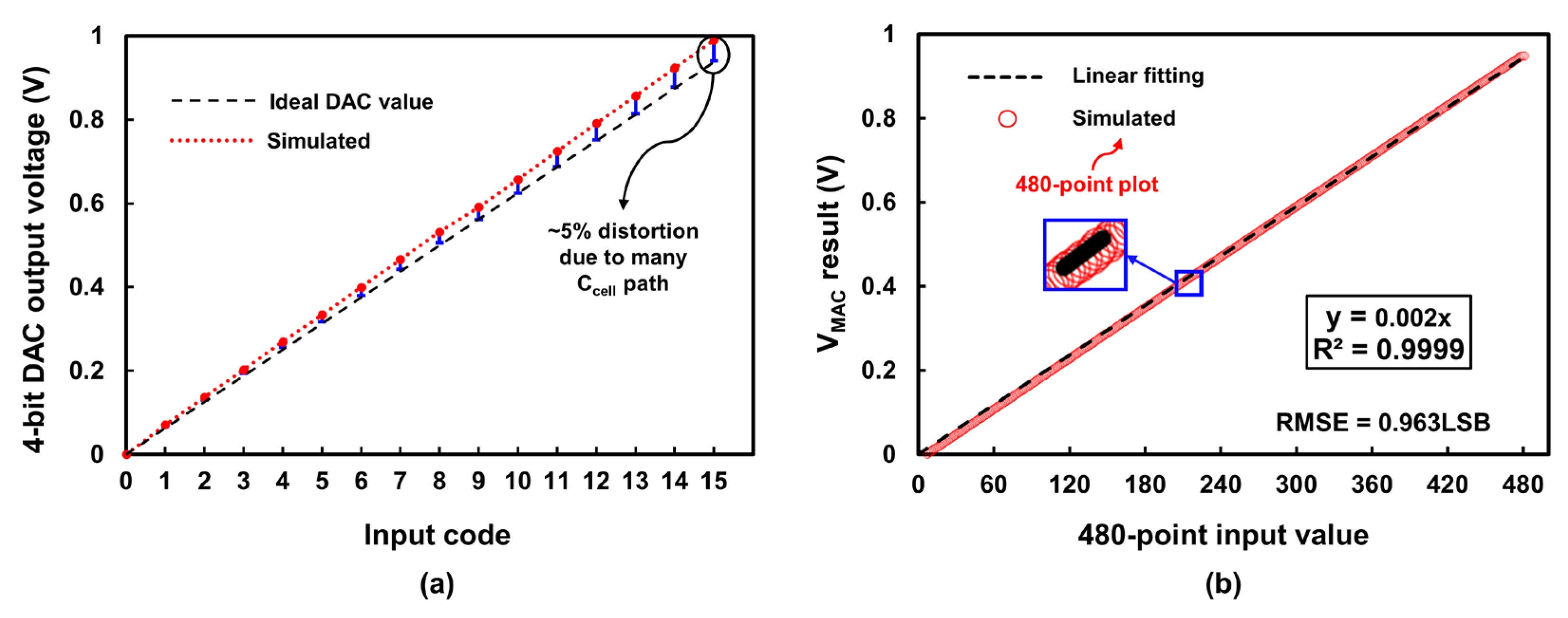
4.1. Linearity of 4-bit DAC
4.2. Linearity of Charge-Domain MAC Operation
4.3. Performance of FS ADC
4.4. Performance Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jaiswal, A.; Chakraborty, I.; Agrawal, A.; Roy, K. 8T SRAM Cell as a Multibit Dot-Product Engine for Beyond Von Neumann Computing. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2556–2567. [Google Scholar] [CrossRef]
- Nguyen, V.T.; Kim, J.-S.; Lee, J.-W. 10T SRAM Computing-in-Memory Macros for Binary and Multibit MAC Operation of DNN Edge Processors. IEEE Access 2021, 9, 71262–71276. [Google Scholar] [CrossRef]
- Si, X.; Tu, Y.-N.; Huang, W.-H.; Su, J.-W.; Lu, P.-J.; Wang, J.-H.; Liu, T.-W.; Wu, S.-Y.; Liu, R.; Chou, Y.-C.; et al. 15.5 A 28nm 64Kb 6T SRAM Computing-in-Memory Macro with 8b MAC Operation for AI Edge Chips. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 16–20 February 2020; pp. 246–248. [Google Scholar]
- Dong, Q.; Jeloka, S.; Saligane, M.; Kim, Y.; Kawaminami, M.; Harada, A.; Miyoshi, S.; Yasuda, M.; Blaauw, D.; Sylvester, D. A 4+ 2T SRAM for Searching and In-Memory Computing with 0.3-V VDDmin. IEEE J. Solid-State Circuits 2017, 53, 1006–1015. [Google Scholar] [CrossRef]
- Munoz-Martin, I.; Bianchi, S.; Melnic, O.; Bonfanti, A.G.; Ielmini, D. A Drift-Resilient Hardware Implementation of Neural Accelerators Based on Phase Change Memory Devices. IEEE Trans. Electron Devices 2021, 68, 6076–6081. [Google Scholar] [CrossRef]
- Yao, P.; Wu, H.; Gao, B.; Tang, J.; Zhang, Q.; Zhang, W.; Yang, J.J.; Qian, H. Fully hardware-implemented memristor convolutional neural network. Nature 2020, 577, 641–646. [Google Scholar] [CrossRef]
- Jhang, C.-J.; Xue, C.-X.; Hung, J.-M.; Chang, F.-C.; Chang, M.-F. Challenges and Trends of SRAM-Based Computing-In-Memory for AI Edge Devices. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1773–1786. [Google Scholar] [CrossRef]
- Sinangil, M.E.; Erbagci, B.; Naous, R.; Akarvardar, K.; Sun, D.; Khwa, W.S.; Liao, H.J.; Wang, Y.; Chang, J. A 7-nm compute-in-memory SRAM macro supporting multi-bit input, weight and output and achieving 351 TOPS/W and 372.4 GOPS. IEEE J. Solid-State Circuits 2020, 56, 188–198. [Google Scholar] [CrossRef]
- Si, X.; Chang, M.-F.; Khwa, W.-S.; Chen, J.-J.; Li, J.-F.; Sun, X.; Liu, R.; Yu, S.; Yamauchi, H.; Li, Q. A Dual-Split 6T SRAM-Based Computing-in-Memory Unit-Macro with Fully Parallel Product-Sum Operation for Binarized DNN Edge Processors. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 4172–4185. [Google Scholar] [CrossRef]
- Si, X.; Liu, R.; Yu, S.; Liu, R.-S.; Hsieh, C.-C.; Tang, K.-T.; Li, Q.; Chang, M.-F.; Chen, J.-J.; Tu, Y.-N.; et al. A twin-8T SRAM computation-in-memory unit-macro for multibit CNN-Based AI edge processors. IEEE J. Solid-State Circuits 2019, 55, 189–202. [Google Scholar] [CrossRef]
- Lee, K.; Jeong, J.; Cheon, S.; Choi, W.; Park, J. Bit parallel 6T SRAM In-memory computing with reconfigurable bit-precision. In Proceedings of the 2020 57th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 20–24 July 2020; pp. 1–6. [Google Scholar]
- Biswas, A.; Chandrakasan, A.P. CONV-SRAM: An energy-efficient sram with in-memory dot-product computation for low-power convolutional neural networks. IEEE J. Solid-State Circuits 2018, 54, 217–230. [Google Scholar] [CrossRef]
- Ali, M.; Jaiswal, A.; Kodge, S.; Agrawal, A.; Chakraborty, I.; Roy, K. IMAC: In-Memory Multi-Bit Multiplication and ACcumulation in 6T SRAM Array. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 2521–2531. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, Z.; Verma, N. In-Memory Computation of a Machine-Learning Classifier in a Standard 6T SRAM Array. IEEE J. Solid-State Circuits 2017, 52, 915–924. [Google Scholar] [CrossRef]
- Mu, J.; Kim, H.; Kim, B. SRAM-Based In-Memory Computing Macro Featuring Voltage-Mode Accumulator and Row-by-Row ADC for Processing Neural Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2022, 69, 2412–2422. [Google Scholar] [CrossRef]
- Yin, S.; Jiang, Z.; Seo, J.S.; Seok, M. XNOR-SRAM: In-Memory Computing SRAM Macro for Binary/Ternary Deep Neural Networks. IEEE J. Solid-State Circuits 2020, 55, 1733–1743. [Google Scholar] [CrossRef]
- Song, J.; Tang, X.; Qiao, X.; Wang, Y.; Wang, R.; Huang, R. A 28 nm 16 Kb Bit-Scalable Charge-Domain Transpose 6T SRAM In-Memory Computing Macro. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 70, 1835–1845. [Google Scholar] [CrossRef]
- Valavi, H.; Ramadge, P.J.; Nestler, E.; Verma, N. A 64-Tile 2.4-Mb In-Memory-Computing CNN Accelerator Employing Charge-Domain Compute. IEEE J. Solid-State Circuits 2019, 54, 1789–1799. [Google Scholar] [CrossRef]
- Zhang, B.; Saikia, J.; Meng, J.; Wang, D.; Kwon, S.; Myung, S.; Kim, H.; Kim, S.J.; Seo, J.-S.; Seok, M. A 177 TOPS/W, capacitor-based in-memory computing SRAM macro with stepwise-charging/discharging DACs and sparsity-optimized bitcells for 4-bit deep convolutional neural networks. In Proceedings of the 2022 IEEE Custom Integrated Circuits Conference (CICC), Newport Beach, CA, USA, 24–27 April 2022; pp. 1–2. [Google Scholar]
- Wang, H.; Liu, R.; Dorrance, R.; Dasalukunte, D.; Lake, D.; Carlton, B. A Charge Domain SRAM Compute-in-Memory Macro with C-2C Ladder-Based 8-Bit MAC Unit in 22-nm FinFET Process for Edge Inference. IEEE J. Solid-State Circuits 2023, 58, 1037–1050. [Google Scholar] [CrossRef]
- Jia, H.; Valavi, H.; Tang, Y.; Zhang, J.; Verma, N. A Programmable Heterogeneous Microprocessor Based on Bit-Scalable In-Memory Computing. IEEE J. Solid-State Circuits 2020, 55, 2609–2621. [Google Scholar] [CrossRef]
- Jiang, Z.; Yin, S.; Seo, J.-S.; Seok, M. C3SRAM: An In-Memory-Computing SRAM Macro Based on Robust Capacitive Coupling Computing Mechanism. IEEE J. Solid-State Circuits 2020, 55, 1888–1897. [Google Scholar] [CrossRef]
- Chen, Z.; Yu, Z.; Jin, Q.; He, Y.; Wang, J.; Lin, S.; Li, D.; Wang, Y.; Yang, K. CAP-RAM: A Charge-Domain In-Memory Computing 6T-SRAM for Accurate and Precision-Programmable CNN Inference. IEEE J. Solid-State Circuits 2021, 56, 1924–1935. [Google Scholar] [CrossRef]
- Oh, H.; Kim, H.; Ahn, D.; Park, J.; Kim, Y.; Lee, I.; Kim, J.-J. Energy-Efficient In-Memory Binary Neural Network Accelerator Design Based on 8T2C SRAM Cell. IEEE Solid-State Circuits Lett. 2022, 5, 70–73. [Google Scholar] [CrossRef]
- Lee, J.; Valavi, H.; Tang, Y.; Verma, N. Fully row/column-parallel in-memory computing SRAM macro employing capacitor-based mixed-signal computation with 5-b inputs. In Proceedings of the 2021 Symposium on VLSI Circuits, Kyoto, Japan, 13–19 June 2021. [Google Scholar]
- Jia, H.; Ozatay, M.; Tang, Y.; Valavi, H.; Pathak, R.; Lee, J.; Verma, N. Scalable and programmable neural network inference accelerator based on in-memory computing. IEEE J. Solid-State Circuits 2021, 57, 198–211. [Google Scholar] [CrossRef]
- Choi, E.J.; Choi, I.; Jeon, C.; Yun, G.; Yi, D.; Ha, S.; Chang, I.-J.; Je, M. SRAM-based computing-in-memory macro with fully parallel one-step multibit computation. IEEE Solid-State Circuits Lett. 2022, 5, 234–237. [Google Scholar] [CrossRef]
- Lin, Y.-Z.; Liu, C.-C.; Huang, G.-Y.; Shyu, Y.-T.; Liu, Y.-T.; Chang, S.-J. A 9-Bit 150-MS/s Subrange ADC Based on SAR Architecture in 90-nm CMOS. IEEE Trans. Circuits Syst. I Regul. Pap. 2013, 60, 570–581. [Google Scholar] [CrossRef]
- Oh, D.-R.; Moon, K.-J.; Lim, W.-M.; Kim, Y.-D.; An, E.-J.; Ryu, S.-T. An 8-bit 1-GS/s asynchronous loop-unrolled SAR-flash ADC with complementary dynamic amplifiers in 28-nm CMOS. IEEE J. Solid-State Circuits 2020, 56, 1216–1226. [Google Scholar] [CrossRef]
- Al-Qadasi, M.A.; Alshehri, A.; Alturki, A.; Almansouri, A.S.; Salama, K.N.; Fariborzi, H.; Al-Attar, T. Rail-to-rail complementary input StrongARM comparator for low-power applications. IET Circuits Devices Syst. 2020, 14, 898–900. [Google Scholar] [CrossRef]
- Tripathi, V.; Murmann, B. Mismatch characterization of small metal fringe capacitors. IEEE Trans. Circuits Syst. I Reg. Pap. 2014, 61, 2236–2242. [Google Scholar] [CrossRef]
- Omran, H.; Alahmadi, H.; Salama, K.N. Matching properties of femtofarad and sub-femtofarad MOM capacitors. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 63, 763–772. [Google Scholar] [CrossRef]
- Xie, S.; Ni, C.; Sayal, A.; Jain, P.; Hamzaoglu, F.; Kulkarni, J.P. eDRAM-CIM: Compute-in-memory design with reconfigurable embedded-dynamic-memory array realizing adaptive data converters embedded-dynamic-memory array realizing adaptive data converters and charge-domain computing. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; pp. 248–250. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | This Work * | JSSC’19 [12] | JSSC’20 [16] | TCAS’23 [17] | JSSC’20 [21] | JSSC’21 [23] |
|---|---|---|---|---|---|---|
| Technology | 65-nm | 65-nm | 65-nm | 28-nm | 65-nm | 65-nm |
| Bitcell Structure | 9T1C | 10T | 12T | 6T | 10T1C | 6T |
| Array Size | 32 × 32 | 256 × 64 | 256 × 64 | 128 × 128 | 2304 × 256 | 512 × 256 |
| Supply Voltage | 1 V | 0.8~1.2 V | 0.6~1.0 V | 0.6~0.9 V | 0.85/1 V | 1.2 V |
| Frequency | 50 MHz | 5 MHz | 100 MHz | 50 MHz | 100 MHz | N/A |
| Computing Type | Charge | Current | Current | Charge | Charge | Charge |
| ADC Type | Flash-SAR | Integrating | Flash | Flash | SAR | ciSAR ADC |
| Bit Precision (Input/Weight/Output) | 4/4/7 | 6/1/7 | 1/1/3.46 | 4/4/4 | 1/1/8 | 4/1/7 |
| Throughput ** (GOPS) | 102.4 | 8 | N/A | 204.8 | 2185 | 573.4 |
| Energy Efficiency(TOPS/W) | 33.6 | 40.3 | 403 | 16.9 (3.13) *** | 192 | 49.4 |
| FoM **** | 537.6 | 241.8 | 403 | 50 | 192 | 197.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Kim, Y. Charge-Domain Static Random Access Memory-Based In-Memory Computing with Low-Cost Multiply-and-Accumulate Operation and Energy-Efficient 7-Bit Hybrid Analog-to-Digital Converter. Electronics 2024, 13, 666. https://doi.org/10.3390/electronics13030666
Lee S, Kim Y. Charge-Domain Static Random Access Memory-Based In-Memory Computing with Low-Cost Multiply-and-Accumulate Operation and Energy-Efficient 7-Bit Hybrid Analog-to-Digital Converter. Electronics. 2024; 13(3):666. https://doi.org/10.3390/electronics13030666
Chicago/Turabian StyleLee, Sanghyun, and Youngmin Kim. 2024. "Charge-Domain Static Random Access Memory-Based In-Memory Computing with Low-Cost Multiply-and-Accumulate Operation and Energy-Efficient 7-Bit Hybrid Analog-to-Digital Converter" Electronics 13, no. 3: 666. https://doi.org/10.3390/electronics13030666
APA StyleLee, S., & Kim, Y. (2024). Charge-Domain Static Random Access Memory-Based In-Memory Computing with Low-Cost Multiply-and-Accumulate Operation and Energy-Efficient 7-Bit Hybrid Analog-to-Digital Converter. Electronics, 13(3), 666. https://doi.org/10.3390/electronics13030666