2.1. Tooth Segmentation
This study proposes methods for upper and lower jaw segmentation. The segmentation methods include image resizing, region cropping, and partial masking. These methods better highlight the upper and lower jaw areas for further easy identification and assessment. The DPR images utilized in this study have inconsistent sizes, so the original images are resized to ensure they have a consistent target size of 1540 × 2816. The resized image helps eliminate variability caused by differences in DPR image sizes. Next, region cropping is applied to extract the upper and lower jaw regions from the entire image. Specific rows and columns are selected to encompass the regions of interest, as shown in
Figure 3a.
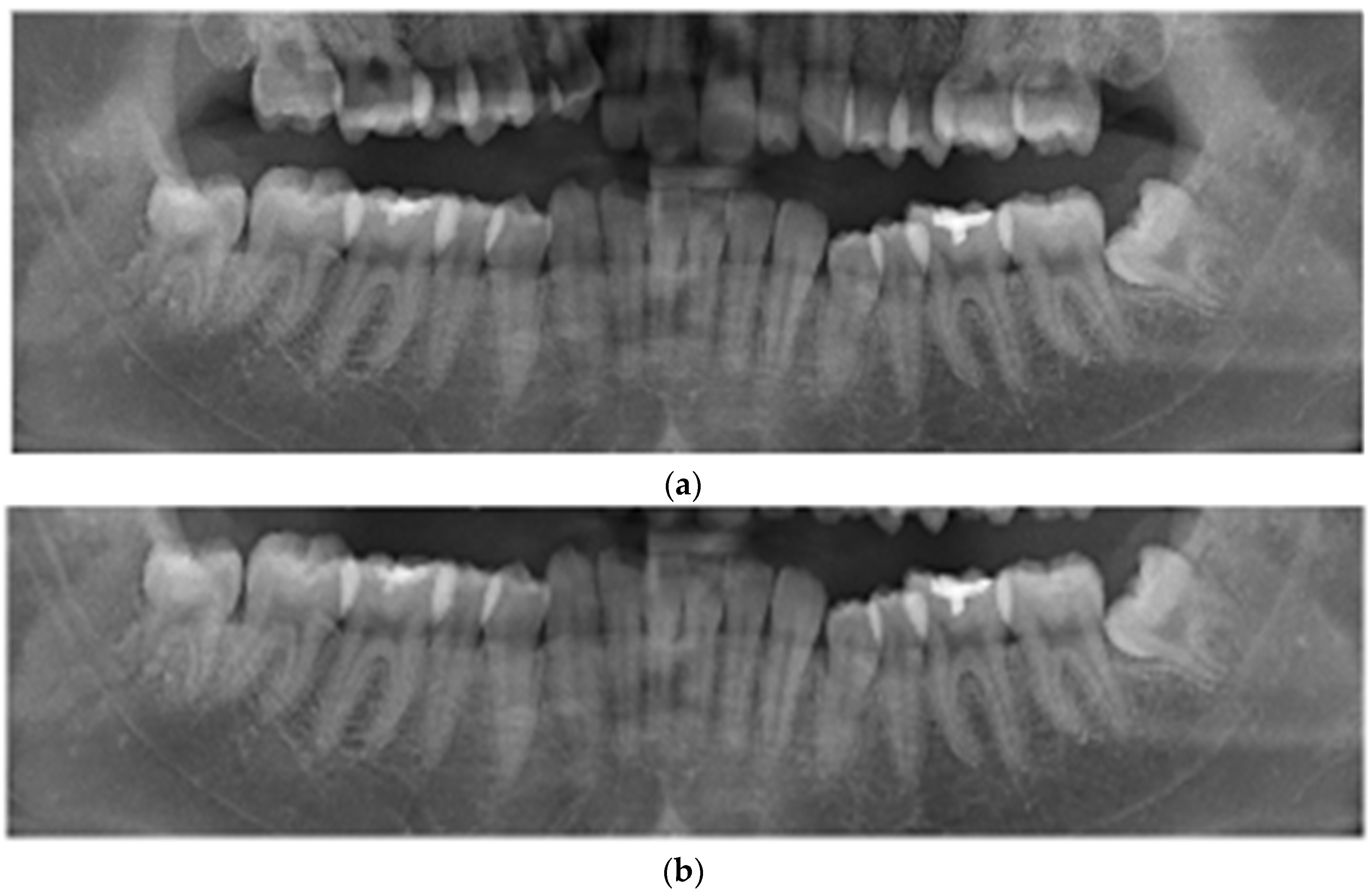
After database analysis and statistics, all of the DPR images used in this study were resized to the same size, and the lower row of teeth was, in all cases, located below 70% of the vertical position of the DPR image. Therefore, this study uses image masking technology to retain the lower row of the DPR image and use this area as the basis for image segmentation, where pixel values outside the mask are set to 255 (white), while pixel values within the mask remain unchanged (original image). This process preserves pixels within the masked area while masking out pixels outside the mask. This effectively improves the visibility of the upper and lower jaw areas. Applying this mask to the original image yields a masked version, which is used for lower teeth segmentation. This method significantly identified the upper and lower jaw regions, as shown in
Figure 3b.
- A.
Grayscale image
The color space of the DPR images is in RGB format. However, the images in RGB format are not conducive for subsequent processing. To streamline the image processing work, in this study, we converted these images into grayscale images. This conversion allows the study to focus solely on the grayscale luminance values of the images, eliminating the need to process each of the three RGB channels separately. This approach simplifies the representation of all pixel points in the images, which can be located using only the x and y-axis coordinates. This not only streamlines the image processing process but also enhances overall work efficiency.
- B.
Gaussian high-pass filter
The major challenge in symptom analysis is the presence of noise points in the images. Therefore, it is crucial to apply filtering techniques to reduce this undesirable noise information. There are various types of filters available in existing technologies, and selecting the most suitable one is a critical decision. A variant of this filter is known as the Gaussian low-pass filter, which is used to reduce specific types of noise. Another variant, the Gaussian high-pass filter, is used to enhance dark areas in the image and accentuate details. The Gaussian high-pass filter is also a common technique employed for image enhancement and feature extraction. In the case of emphasizing the characteristics of the tooth edge, the Gaussian high-pass filter is the most suitable choice [
30]; the formula is shown in (1), where
D0 is the cut-off frequency and
D(
u,
v) is the distance from the center of the frequency rectangle. When
D0 is larger, the smoothness is better. This filter effectively reduces low-frequency components in the image. Consequently, this high-frequency information is preserved in the processed image, as shown in
Figure 4.
- C.
Contrast Stretching
Contrast stretching is a widely used technique in image processing [
31]. It can increase contrast by expanding the brightness distribution of the image. The goal of contrast stretching is to highlight features by increasing image contrast. Contrast enhancement is achieved using histogram equalization, a method that redistributes the brightness levels of an image. It makes the brightness levels in the image more uniformly distributed, thus increasing contrast, as shown in
Figure 5a. The square balancing technique is applied to enhance the differences between brightness levels. The squared image is then subjected to min–max normalization, mapping pixel values to the range of 0 to 255 for display purposes, as shown in
Figure 5b.
Flat field correction is used to mitigate uneven brightness points in an image, ensuring that pixel values tend to be uniform. This correction helps eliminate differences in brightness caused by uneven illumination. Flat field correction is applied to the squared balanced image to improve image quality, as shown in
Figure 5c. The flat field correction formula is as follows (2): where
C represents the corrected image,
R is the original image,
F is the flat field image,
D is the dark field or dark frame, and
m is the average value of (
F −
D). The images of
F and
D are based on adaptive histogram equalization adjustment parameters and are processed if they are lower than the adaptive threshold. If the threshold is lower than the threshold, it will be classified as a dark field, otherwise, it will be classified as a flat field. It can adjust region brightness and contrast in different areas of the image. Parameters are set to ensure that adaptive histogram equalization preserves details and avoids over-enhancement, as shown in
Figure 5d.
- D.
Binarization
Binarization is the conversion of a grayscale image into a binary image [
32], which contains only two pixel values, typically black and white. This transformation highlights the objects of interest in the image, facilitating subsequent analysis and processing. This study adopts a widely used image binarization method known as Otsu’s method. This method relies on an automatically selected threshold that categorizes the pixels in the image into the foreground (the target objects) and the background (everything else). Otsu’s method effectively accomplishes the conversion of an image into a binary image and performs admirably in various scenarios, as shown in
Figure 6.
- E.
Morphological operations
Morphological operations primarily deal with the shape, structure, and geometric features of objects [
33]. These operations enable various enhancements, segmentations, and analyses of images by altering the morphology of objects. Morphological operations are based on a structuring element and a set of operations, including dilation, erosion, opening, and closing, among others. The opening operation formula is as follows (3):
A is the original image,
B is the structural element image, and the set
A is opened by the structural element
B, which means that the result of
A being eroded by
B is then expanded by
B. In this study, the image is first subjected to median filtering to reduce noise, as shown in
Figure 7a. An opening operation is applied to smooth the image and remove unnecessary information, as shown in
Figure 7b.
- F.
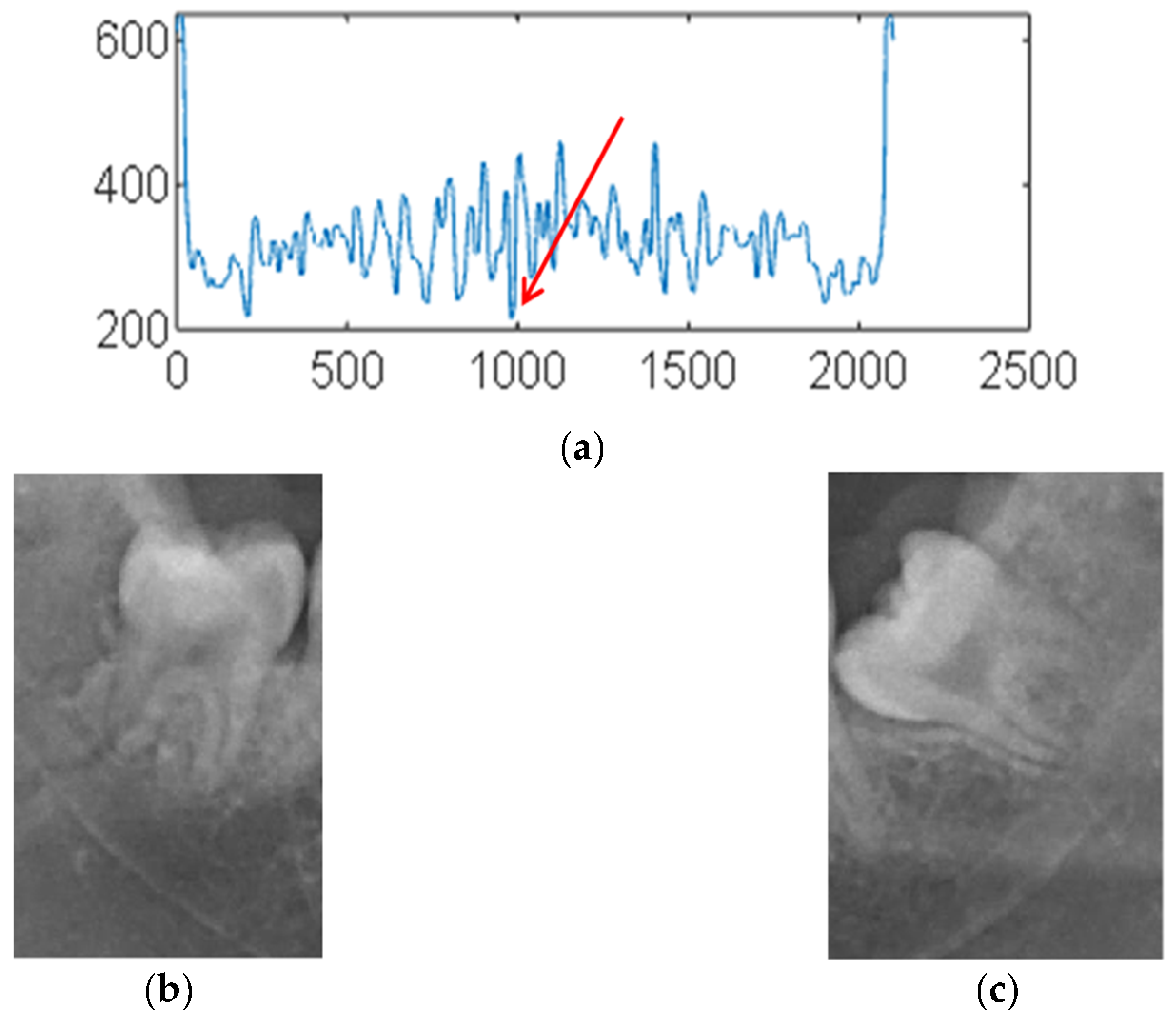
Vertical Grayscale Projection Algorithm
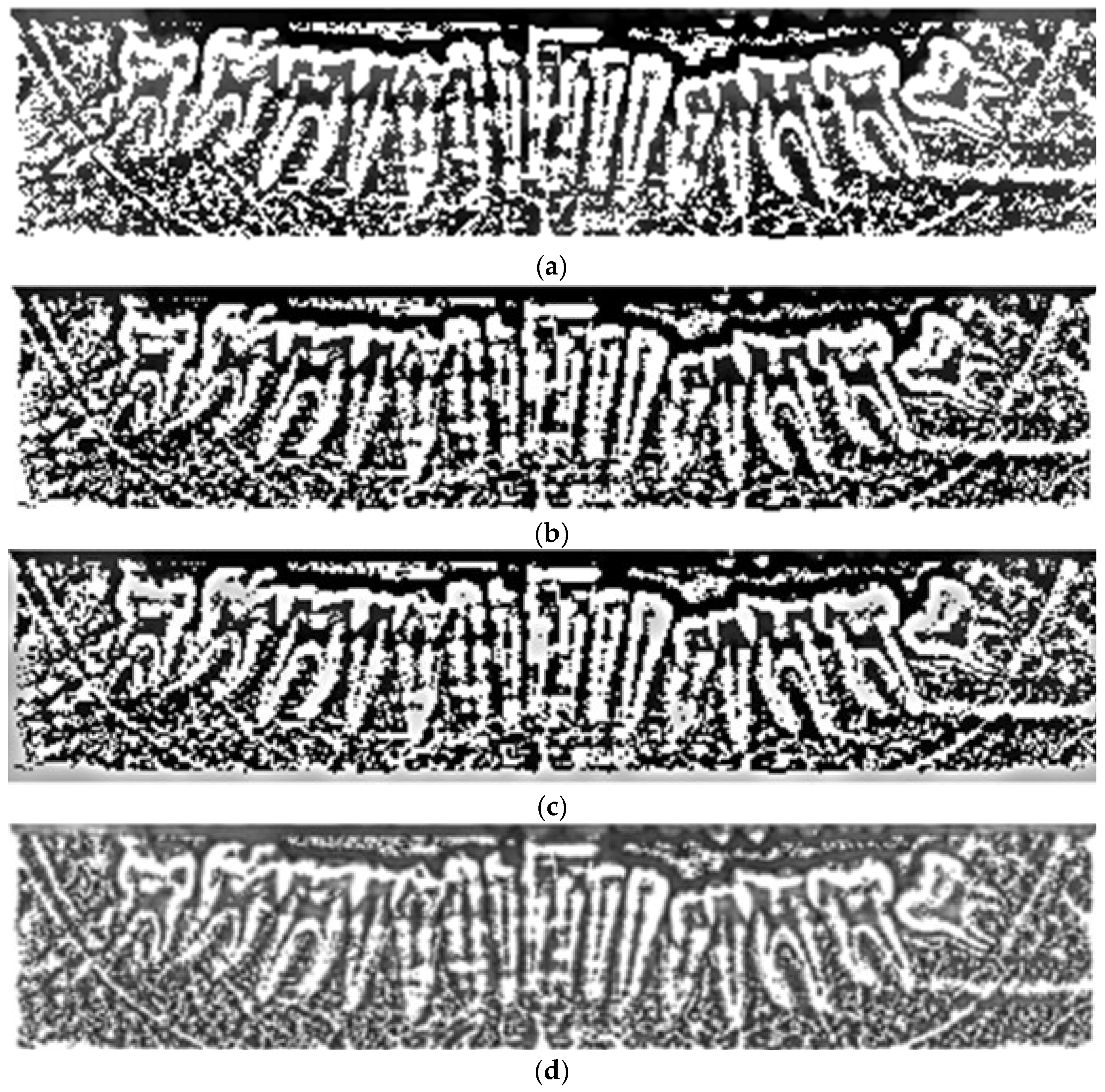
This study proposes a tooth segmentation algorithm based on vertical grayscale projection, which aims to automatically detect and segment teeth in DPR images. Vertical grayscale projection is used to analyze the brightness distribution in different regions. It is employed to identify the positions of tooth clefts, as shown in
Figure 8a. Subsequently, teeth are segmented based on the characteristics of the projection distribution, as shown in
Figure 8b,c. This algorithm exhibits excellent applicability and efficiency in oral image processing.
- G.
YOLO_v4
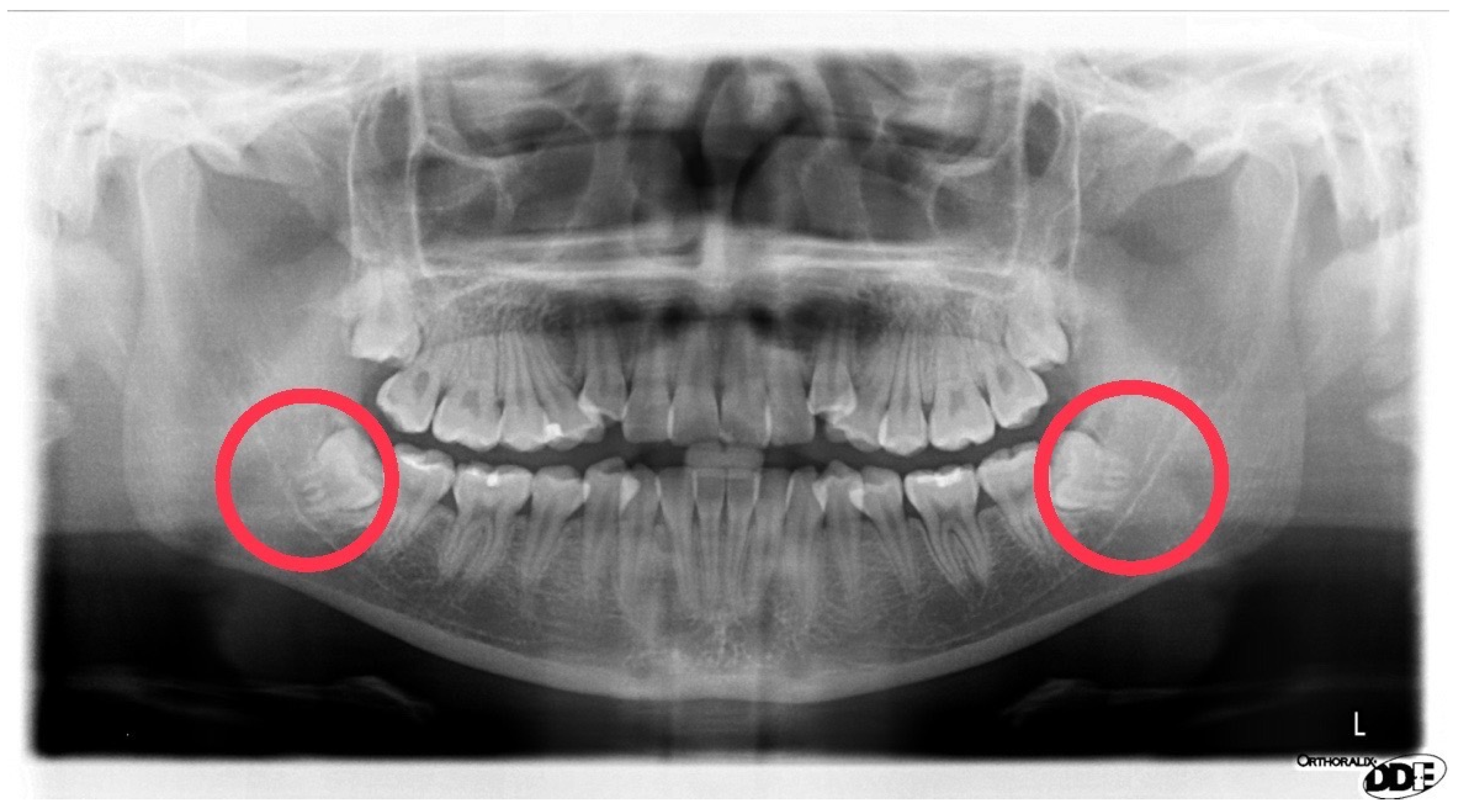
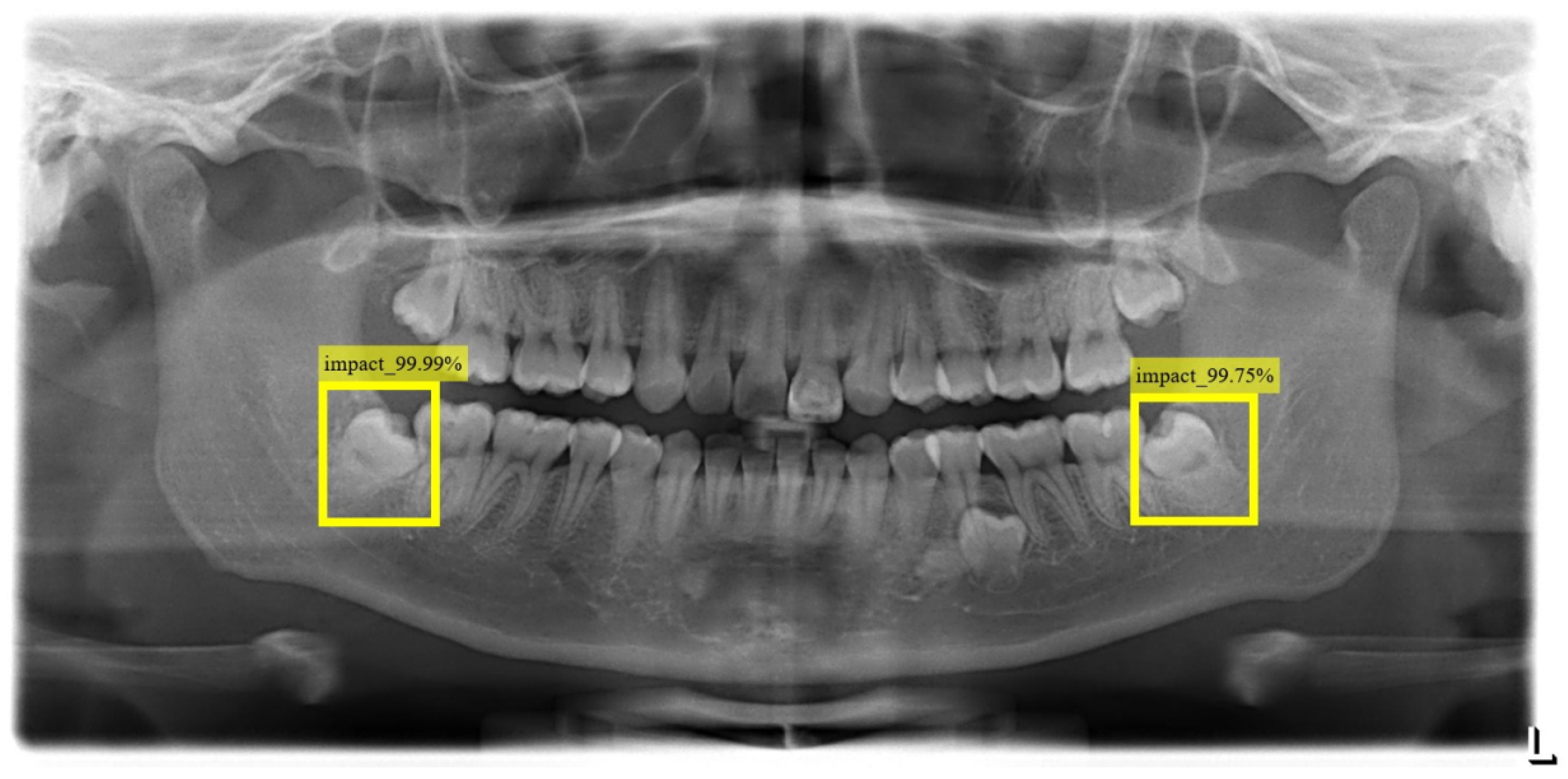
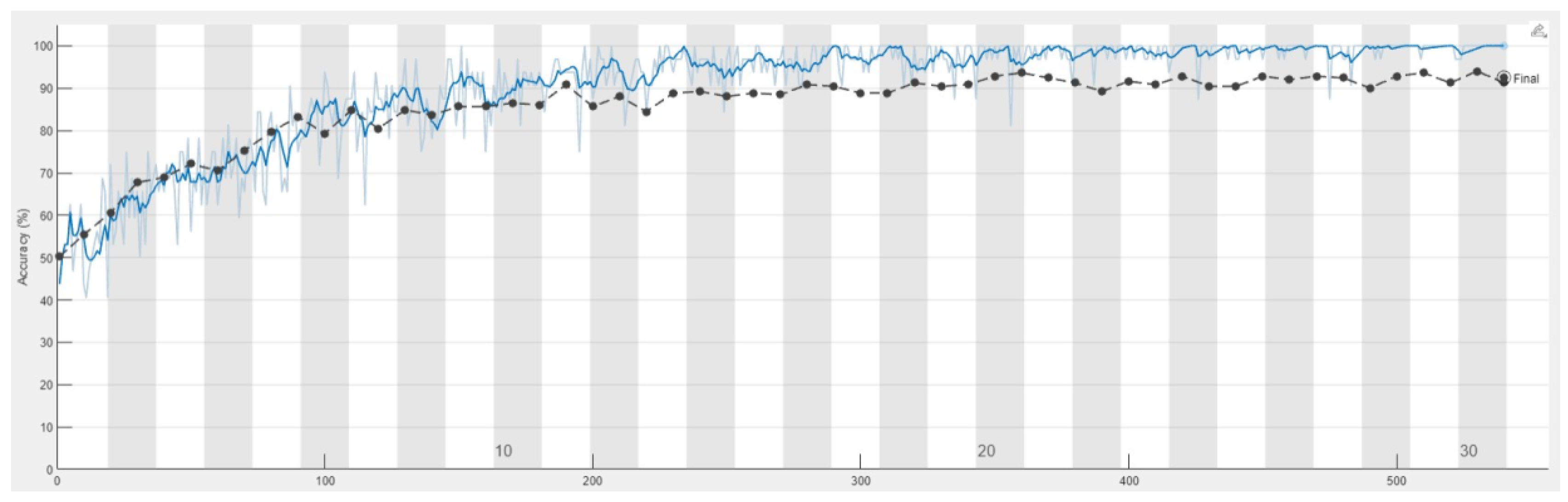
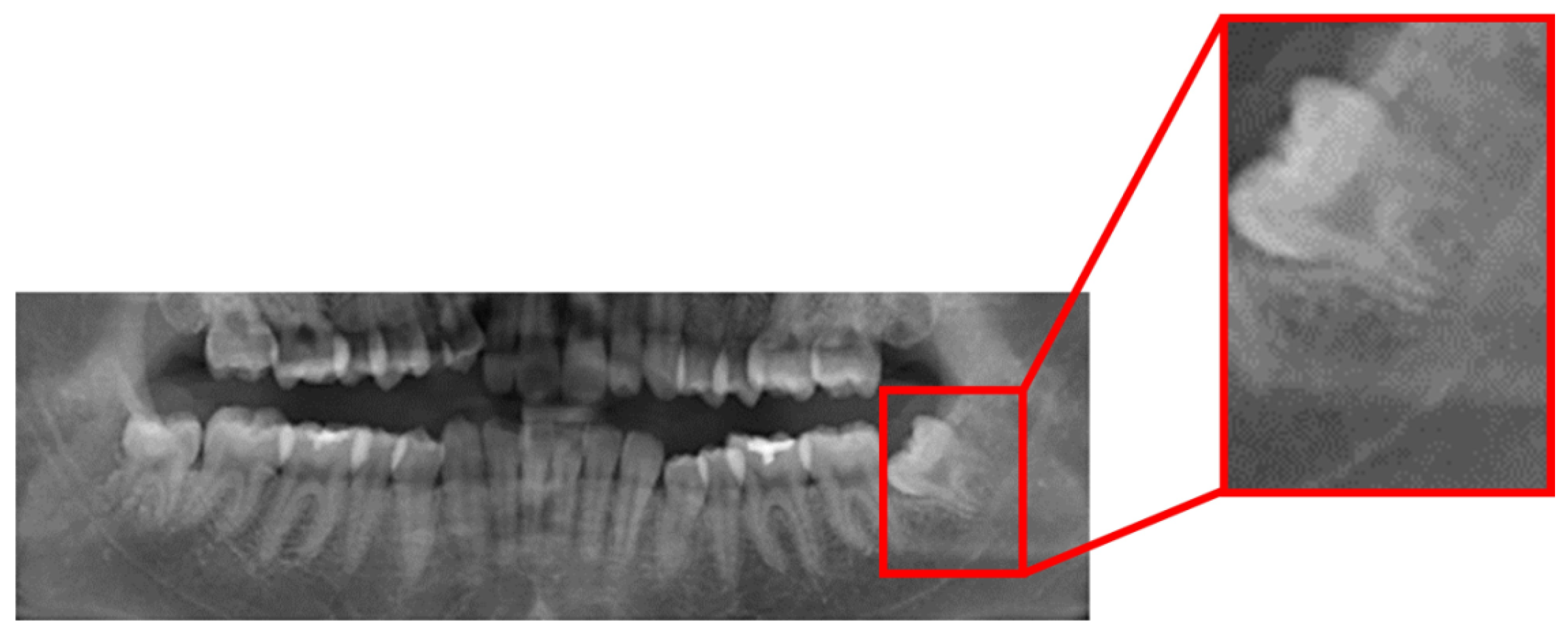
This study uses YOLO_V4 and vertical grayscale projection algorithms to locate the positions of impacted teeth and the inferior alveolar nerve. YOLO_V4 is an object recognition model, often used for detection or license plate recognition. In this research, YOLO_V4 was applied to identify impacted teeth and the inferior alveolar nerve in DPR images. This study annotated 500 DPR images for YOLO_v4 training, with the validation results depicted in
Figure 9, showcasing an impressive accuracy of up to 88%. The YOLO model records both the position and class of bounding boxes, enabling the extraction of impacted teeth based on the recorded positions. The proposed impacted tooth segmentation algorithm, based on vertical grayscale projection, achieves an accuracy rate of 93%. Comparative analysis utilizing 100 untrained images against prior research outcomes, as presented in
Table 1, reveals that the leveraging of the proposed impacted tooth segmentation algorithm in this study demonstrates an enhancement in accuracy by 3–5% compared to previous research and YOLO_v4.
2.2. Single Tooth Image Enhancement
In order to improve the accuracy of CNN training results, it is most critical to highlight the symptoms of impacted teeth. This study uses image preprocessing to eliminate most of the noise of impacted teeth images, additionally creating a black mask over adjacent unaffected tooth areas. The masked images are used as the training image dataset for the CNN model in this study.
- A.
Image preprocessing
To enhance the accuracy of the CNN training model, this study applies image enhancement to the cropped impacted tooth images. Image preprocessing initially involves using guided filtering [
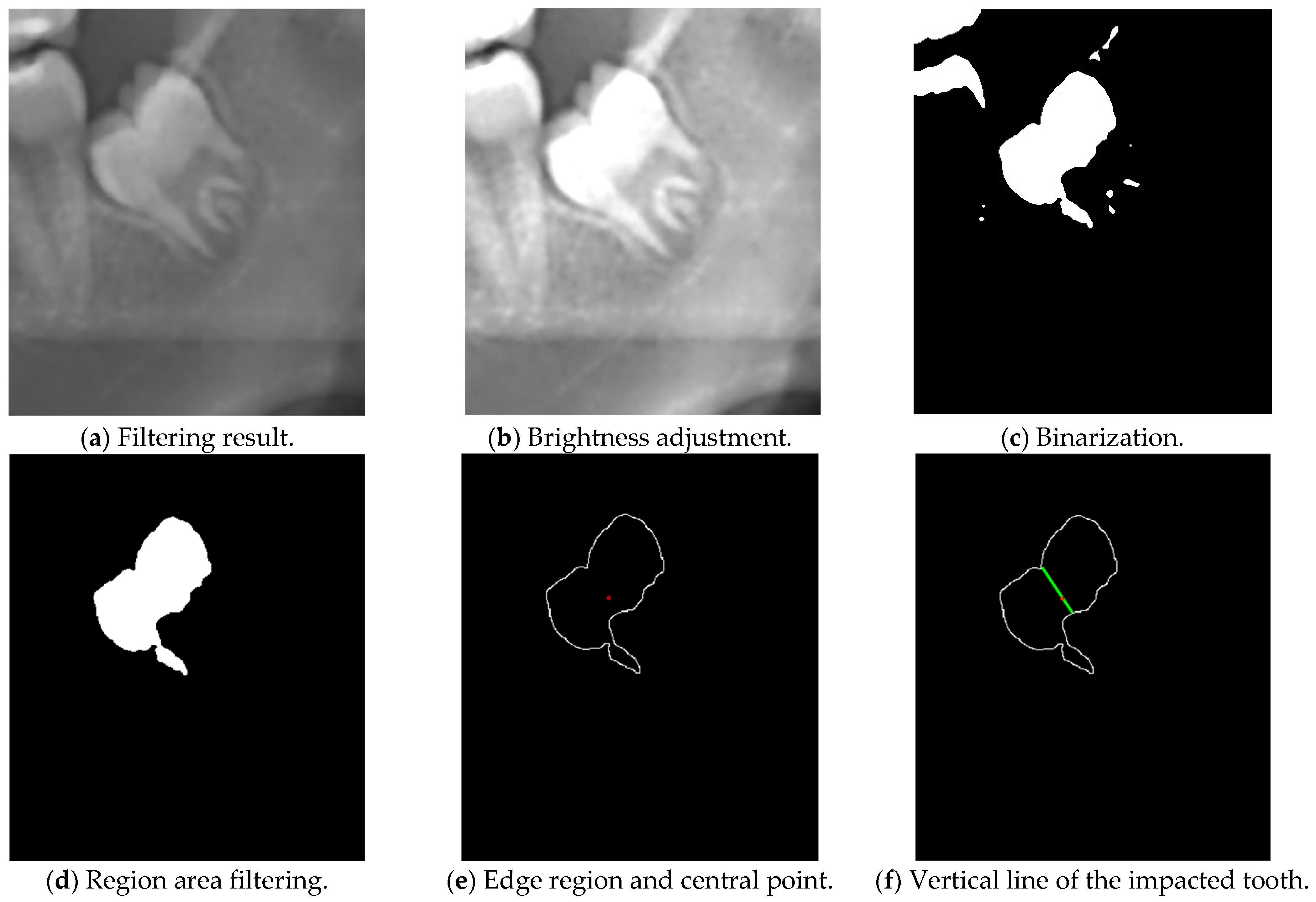
34] to smooth the image while preserving edges and features. Guided filtering is a smoothing image filter that preserves edges. In guided filtering, the original image serves as the guidance map, filtering out edge noise while retaining edge information. This aids in enhancing image quality and emphasizing specific regions of interest. The filtering results are depicted in
Figure 10a, with the formulation given by Algorithm 1.
| Algorithm 1. Guided Filter |
Input filtering input image p, guidance image I, radius γ, regularization ε
Output filtering output image q.
|
- B.
Brightness threshold segmentation
This study calculates the average pixel value of the filtered image, which is the overall brightness level of the image. Based on the calculated average pixel value, brightness adjustment is applied to the image. Different adjustments are made based on different ranges of average pixel values. For example, if the average pixel value is below a certain threshold (e.g., less than 122), the brightness range is adjusted to a brighter region. This helps to highlight low-brightness areas, which makes them easier to be identified; the image after brightness adjustment is shown in
Figure 10b. Subsequently, brightness thresholding is used to convert the processed image into a binary mask. In this mask, pixels with brightness higher than the threshold are considered as the target region, while pixels with brightness lower than the threshold are considered as the background.
- C.
Region Selection
In order to enhance the accuracy of recognition, this research employs a region area filtering technique to select regions of interest while excluding noisy areas. The primary aim is to ensure that the selected regions effectively represent the principal target regions rather than inconsequential noise. Subsequently, a binary mask was generated, with white pixels denoting the regions of interest, while black pixels signified the background as shown in
Figure 10c. This step of constructing the binary mask is important to isolate the target region for more comprehensive analysis and subsequent processing. In this study, brightness threshold segmentation is employed to precisely locate the regions of interest. It can effectively segregate the regions of interest from the background by establishing a binary mask. To eliminate noise from this mask, a region area filtering approach is applied, ensuring that only regions surpassing a predefined area threshold are retained, as shown in
Figure 10d.
- D.
Center Point Calculation and Edge Detection
In the preceding step, a binary image mask is obtained, where white regions represent the objects of interest, and black regions denote the background. To facilitate further analysis and processing of these objects, the next step involves detecting the contours of the target objects. In this study, the Canny edge detection algorithm was employed for this purpose. The Canny algorithm [
35] is adept at detecting edges within regions of interest. Once the edges are detected, the computed center points and contours are overlaid onto the edge regions, as shown in
Figure 10e. This overlaying process aids the positions and shapes of the target objects. It provides a clear representation of the dental structures, which is essential for subsequent analysis and diagnosis.
- E.
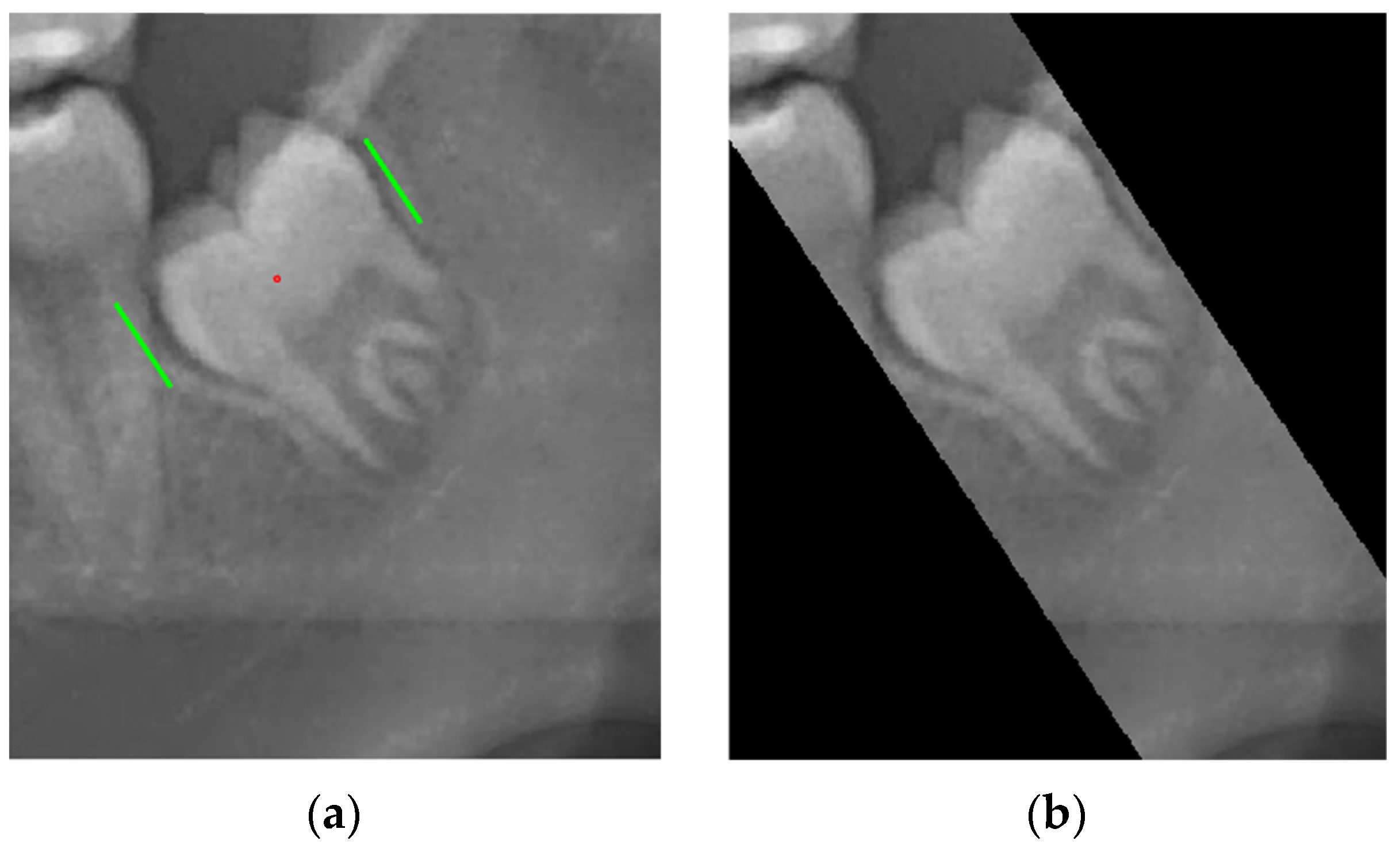
Determining the inclination or tilt direction of the target object
Boundary detection is employed to determine the inclination direction of the impacted tooth. Firstly, the distances between these boundaries within the region of interest is calculated. Subsequently, the shortest line among all possible lines passing through the center point of the region is selected, as shown in
Figure 10f. The shortest line typically represents the connection between the top and bottom of the tooth crown. By determining the slope of this line, the inclination direction of the impacted tooth could be ascertained.
- F.
Image Mask
The threshold related to the width of the tooth is set by the slope of the inclination direction of the impacted tooth. By shifting the line from the central point by this threshold value on both sides, the boundary points of the impacted tooth can be identified. Subsequently, the areas outside the line are covered with a black mask, as shown in
Figure 11.
2.3. CNN Training
In recent years, a suite of influential deep learning models rooted in CNNs has emerged, notably including AlexNet, GoogLeNet, VGGNet, and ResNet, among others. The CNN architecture is often used for classification tasks. This study harnesses four established models—AlexNet, GoogLeNet, MobileNet_V2, and ShuffleNet—for transfer learning purposes. The acceleration of CNN model training within this study is facilitated through the utilization of an Nvidia GeForce GTX 1060 GPU, with comprehensive hardware performance details presented in
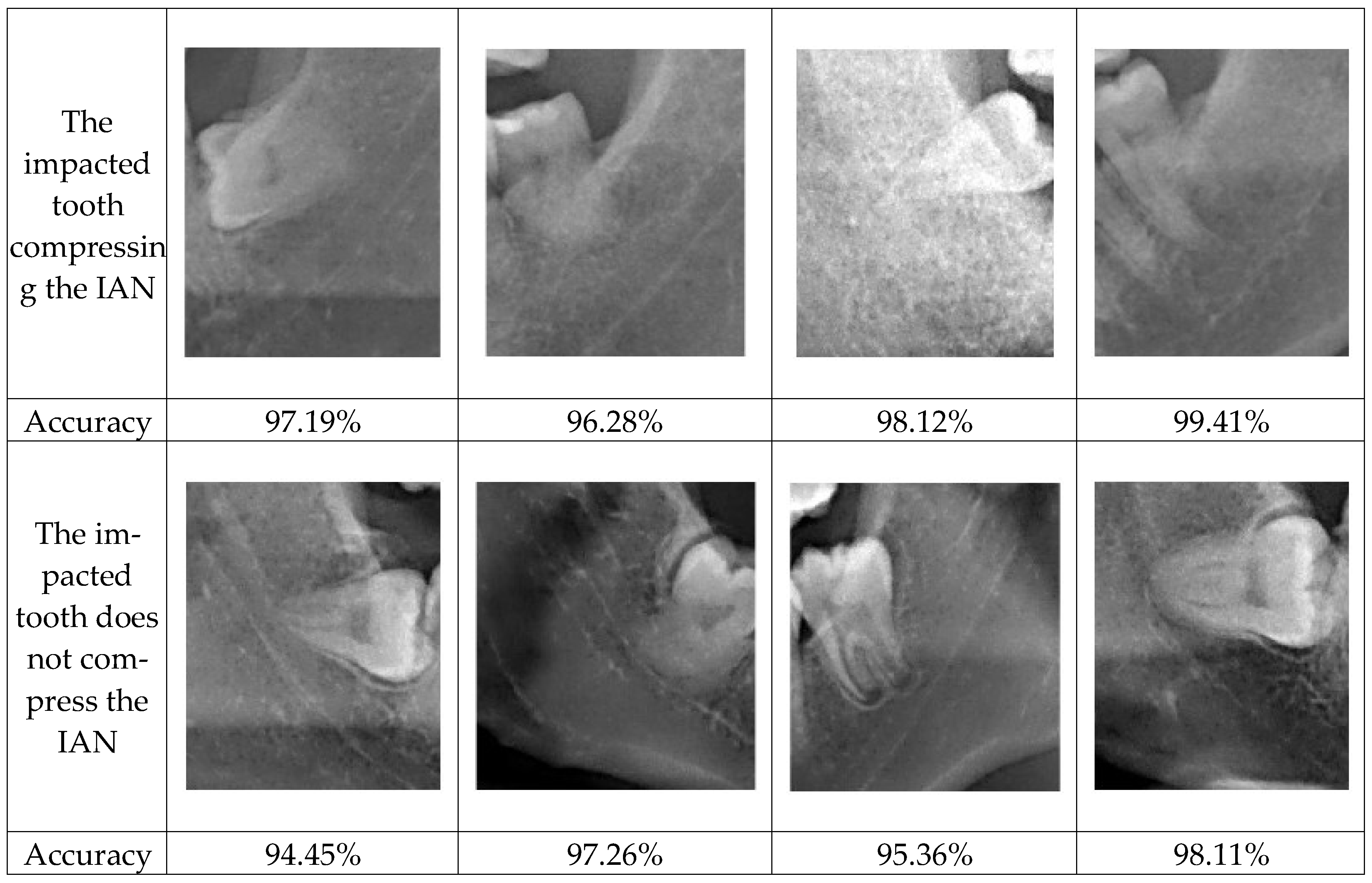
Table 2. MATLAB and Deep Network Designer serve as the foundational software tools for designing convolution network models. The core aim of this research is to discern whether impacted wisdom teeth exert pressure on the inferior alveolar nerve. The image database is segregated into two distinct categories, each containing 1000 images. These images are randomly partitioned, allocating 70% for CNN training and validation purposes. Among the 70%, 60% is dedicated to training and 40% is dedicated to validation. The remaining 30% constitutes test images, utilized to evaluate the accuracy of the CNN.
The architecture of the models, taking ShuffleNet as an example in this study, is outlined in
Table 3. The input image size is 224 × 224. Since this study deals with only two classes, adjustments are made to the fully connected layer to output two classes instead of the original 1000. Training a CNN with existing images alone is insufficient. Therefore, data augmentation is employed to expand the database, such as vertical flipping, brightness adjustment, and image rotation. It results in a total of 1000 images through data augmentation.
During the training phase, the configuration of hyperparameter combinations plays a crucial role in determining the success of the model. Each parameter represents a different aspect, such as the number of neural network layers, the choice of loss function, the size of convolutional kernels, and the learning rate, among others. This study experimented with various hyperparameter combinations. The details of the best performing parameter set are shown in
Table 4.






 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}