



Working toward Solving Safety Issues in Human–Robot Collaboration: A Case Study for Recognising Collisions Using Machine Learning Algorithms


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection Process
- Width of 1 frame: 3840 px;
- Height of 1 frame: 2150 px;
- Recording speed: 100 frames/s;
- Data recording format: MPEG-4 HEVC.
2.2. Learning Patterns
- 215 images for the view corresponding to camera position 1;
- 149 images for the view corresponding to camera position 2;
- 120 images for the view corresponding to camera position 3.
2.3. Data Preprocessing
2.4. Neural Network Prediction
3. Results
- Stage 1: detection the position of individual parts of the operator’s body and cobot elements in real time;
- Stage 2: filtering objects, separating and tracking human operators and cobots;
- Stage 3: prediction of the risk of collision between them, taking into account their current direction and speed of movement.
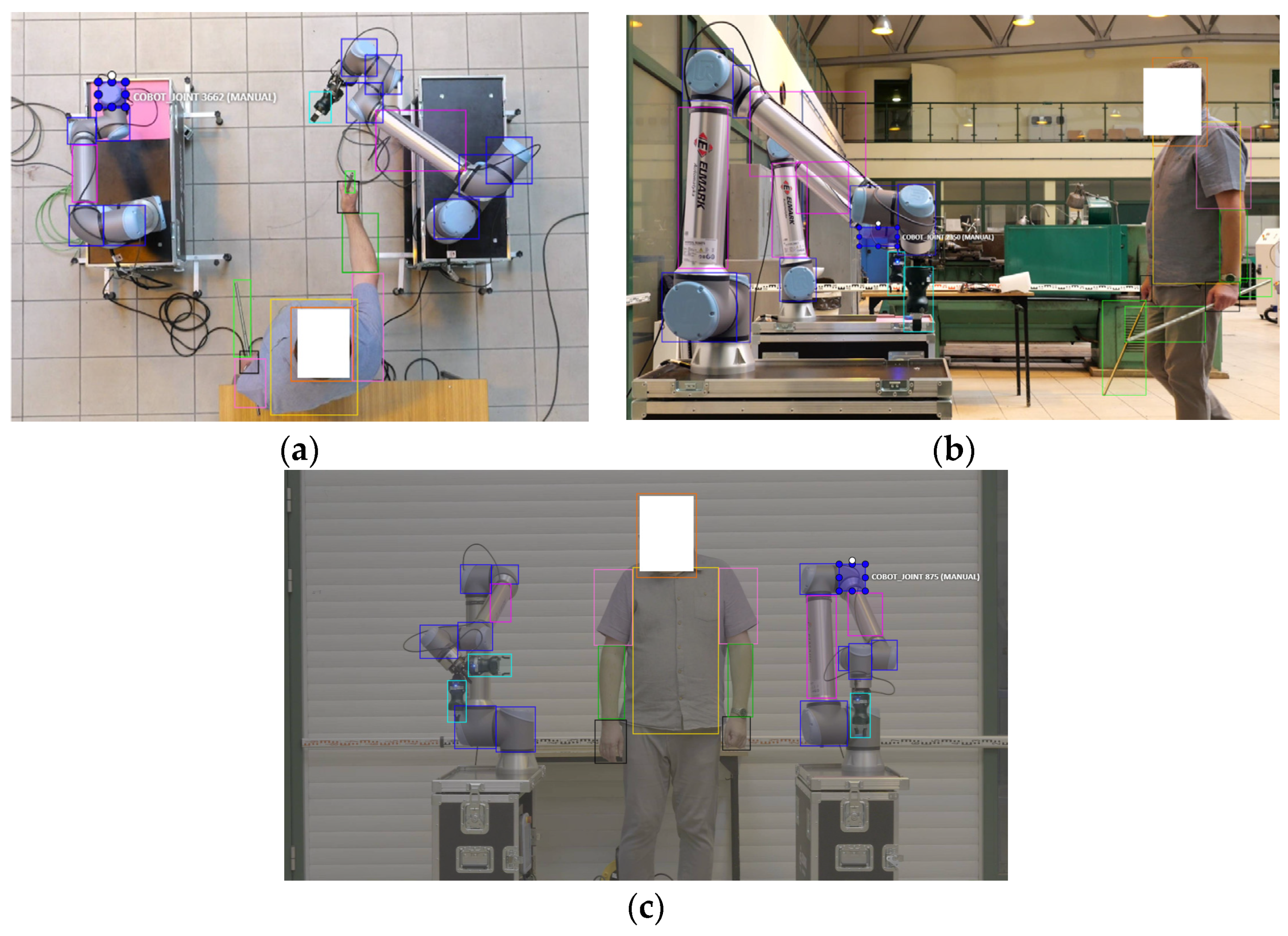
3.1. Object Detection Results
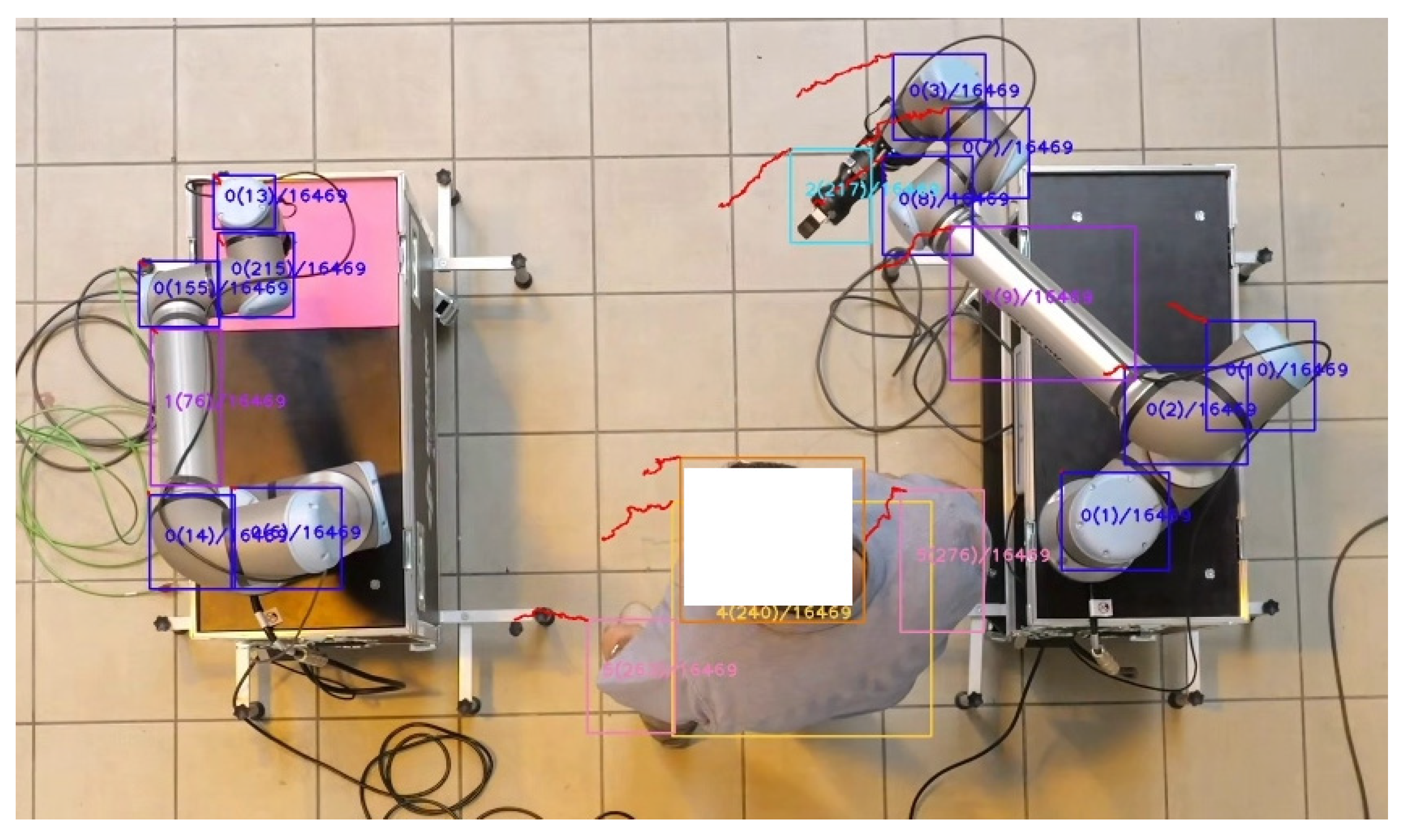
3.2. Filtering the Objects, Separating and Tracking Cobots and Human Operators
3.3. Predicting Possible Collisions in HRC
4. Discussion
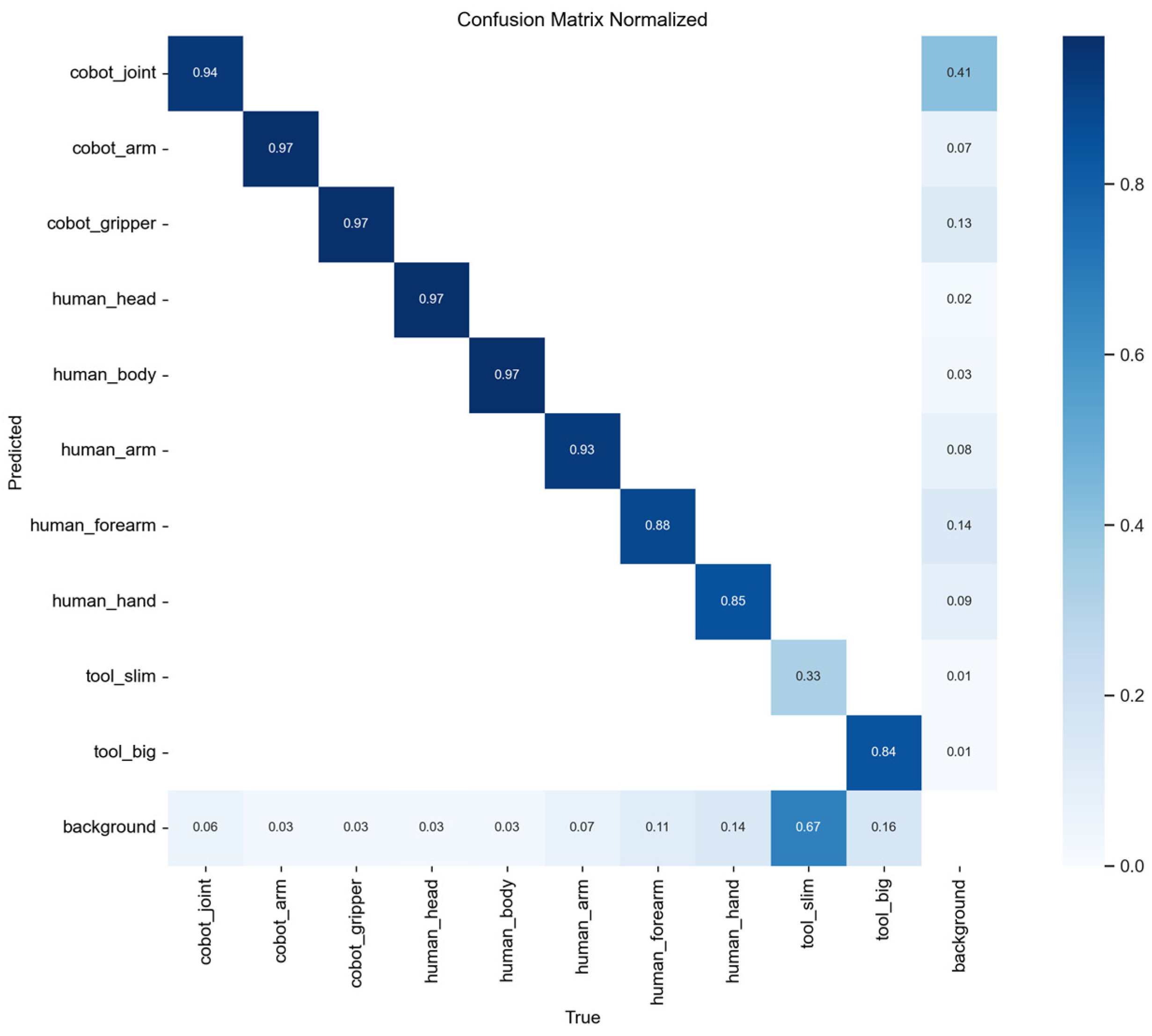
- The YOLO v8 network showed a good level of recognising and indicating individual elements of cobots and operators in common HRC workplaces with an accuracy of 90%.
- The integration of YOLOv8 deep learning approach and CNN classifier enables early warning of potential collisions in common HRC workplace with an accuracy of 96.4%.
- The proposed new method significantly increases the effectiveness of HRC due to the possibility of predicting the occurrence of a collision, instead of detecting the presence of the operator in a certain safety zone, on the one hand by preventing the operator from colliding with the robot’s arm and, on the other hand, eliminating the need to perform a safety stop, which disturbs the continuity of the ongoing process.
- Increasing safety levels within HRC is an important factor in the development of HRC, which allows the unique abilities and skills of people and robots to be combined in order to optimise production processes [19]. Therefore, this research was undertaken in a specific defined HRC area, in order to present how early warning can be given against a potential collision in such an HRC co-operation environment when a human accidentally enters such a space. The work shows three cases of the potential danger, i.e., unexpected entry of a human into the HRC zone: (1) entering the cobot’s workspace facing forward, (2) crouching in the cobot’s workspace, (3) turning around in the cobot’s workspace. In works [20,21,22], comparisons of visual systems used for recognising human and robotic poses can be found, e.g., Azure Kinect Body Tracking, Intel RealSense D435i and also the YOLO network, Azure Kinect and Intel RealSense. The authors of this work used data from video recordings from three cameras due to the possibility of obtaining recordings of HRC from three points: from the front, from the side and from above.
- Currently it is difficult to compare the effectiveness of the results obtained, due to the specific and strictly defined common workplace of humans and cobots with specific behavioural scenarios. According to the notes in the introduction, the results in works [9,10] achieved an accuracy of 90% in recognising an object and 96.4% in predicting collisions, which can be said to be satisfactory. In [23] the scenario covers the HRC space, where an operator exchanges components with one cobot. The results yielded 91% accuracy with R-CNN when trained with synthetic data but only 78% accuracy with real data accuracy, respectively. In our research only real data were used for both training and testing deep learning models. This is particularly important because many works use synthetic or synthetic and real data, because there is no public dataset available [19].
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Siciliano, B.; Khatib, O. Springer Handbook of Robotics, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- La Fata, C.M.; Adelfio, L.; Micale, R.; La Scalia, G. Human error contribution to accidents in the manufacturing sector: A structured approach to evaluate the interdependence among performance shaping factors. Saf. Sci. 2023, 161, 106067. [Google Scholar] [CrossRef]
- Giallanza, A.; La Scalia, G.; Micale, R.; La Fata, C.M. Occupational health and safety issues in human-robot collaboration: State of the art and open challenges. Saf. Sci. 2024, 169, 106313. [Google Scholar] [CrossRef]
- Ko, D.; Lee, S.; Park, J. A study on manufacturing facility safety system using multimedia tools for cyber physical systems. Tools Appl. 2021, 80, 34553–34570. [Google Scholar] [CrossRef]
- Zhang, S.; Li, S.; Li, X.; Xiong, Y.; Xie, Z. A Human-Robot Dynamic Fusion Safety Algorithm for Collaborative Operations of Cobots. J. Intell. Robot. Syst. Theory Appl. 2022, 104, 18. [Google Scholar] [CrossRef]
- Liu, H. Deep Learning-based Multimodal Control Interface for Human-Robot Collaboration. Procedia CIRP 2018, 72, 3–8. [Google Scholar] [CrossRef]
- Liu, Z.; Liu, Q.; Xu, W.; Liu, Z.; Zhou, Z.; Chen, J. Deep Learning-based Human Motion Prediction considering Context Awareness for Human-Robot Collaboration in Manufacturing. Procedia CIRP 2019, 83, 272–278. [Google Scholar] [CrossRef]
- Wang, P.; Liu, H.; Wang, L.; Gao, R.X. Deep learning-based human motion recognition for predictive context-aware human-robot collaboration. CIRP Ann. 2018, 67, 17–20. [Google Scholar] [CrossRef]
- Rodrigues, L.R.; Barbosa, G.; Filho, A.O.; Cani, C.; Dantas, M.; Sadok, D.; Kener, J.; Souza, R.S.; Marquezini, M.V.; Lins, S. Modeling and assessing an intelligent system for safety in human-robot collaboration using deep and machine learning techniques. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2022; p. 81. [Google Scholar]
- Liau, Y.Y.; Ryu, K. Status Recognition Using Pre-Trained YOLOv5 for Sustainable Human-Robot Collaboration (HRC) System in Mold Assembly. Sustainability 2021, 13, 12044. [Google Scholar] [CrossRef]
- Pajak, G.; Krutz, P.; Patalas-Maliszewska, J.; Rehm, M.; Pajak, I.; Dix, M. An approach to sport activities recognition based on an inertial sensor and deep learning. Sens. Actuators A Phys. 2022, 345, 113773. [Google Scholar] [CrossRef]
- Pajak, I.; Krutz, P.; Patalas-Maliszewska, J.; Rehm, M.; Pajak, G.; Schlegel, H.; Dix, M. Sports activity recognition with UWB and inertial sensors using deep learning approach. In Proceedings of the IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Ultralytics, Introducing Ultralytics YOLOv8. Available online: https://docs.ultralytics.com (accessed on 10 October 2023).
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Bewley, A.; Ge, Z.Y.; Ott, L.; Ramov, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 23rd IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Sirisha, U.; Praveen, S.P.; Srinivasu, P.N.; Barsocchi, P.; Bhoi, A.K. Statistical Analysis of Design Aspects of Various YOLO-Based Deep Learning Models for Object Detection. Int. J. Comput. Intell. Syst. 2023, 126, 18. [Google Scholar] [CrossRef]
- Ultralytics. Performance Metrics Deep Dive. Available online: https://docs.ultralytics.com/guides/yolo-performance-metrics/ (accessed on 10 October 2023).
- Mukherjee, D.; Gupta, K.; Chang, L.H.; Najjaran, H. A Survey of Robot Learning Strategies for Human-Robot Collaboration. Ind. Settings Robot. Comput. Integr. Manuf. 2022, 73, 102231. [Google Scholar] [CrossRef]
- Gross, S.; Krenn, B. A Communicative Perspective on Human–Robot Collaboration in Industry: Mapping Communicative Modes on Collaborative Scenarios. Int. J. Soc. Robot. 2023. [Google Scholar] [CrossRef]
- Ramasubramanian, A.K.; Kazasidis, M.; Fay, B.; Papakostas, N. On the Evaluation of Diverse Vision Systems towards Detecting Human Pose in Collaborative Robot Applications. Sensors 2024, 24, 578. [Google Scholar] [CrossRef] [PubMed]
- De Feudis, I.; Buongiorno, D.; Grossi, S.; Losito, G.; Brunetti, A.; Longo, N.; Di Stefano, G.; Bevilacqua, V. Evaluation of Vision-Based Hand Tool Tracking Methods for Quality Assessment and Training in Human-Centered Industry 4.0. Appl. Sci. 2022, 12, 1796. [Google Scholar] [CrossRef]
- Rijal, S.; Pokhrel, S.; Om, M.; Ojha, V.P. Comparing Depth Estimation of Azure Kinect and Realsense D435i Cameras. Ann. Ig. 2023. [Google Scholar]
- Wang, S.; Zhang, J.; Wang, P.; Law, J.; Calinescu, R.; Mihaylova, L. A deep learning-enhanced Digital Twin framework for improving safety and reliability in human–robot collaborative manufacturing. Robot. Comput. Integr. Manuf. 2024, 85, 102608. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Payload | 12.5 kg |
| Reach | 1300 mm |
| Degrees of freedom | 6 rotating joints |
| Force/Torque Sensing | 100.0 N 10.0 Nm |
| Pose Repeatability | ±0.05 m |
| Axis Working Range | ±360° |
| Axis Maximum Speed | ±120°/s (arm) ± 180°/s (wrist) |
| TCP speed | 1 m/s |
| Digital Camera | |
|---|---|
| Model | Panasonic GH6 |
| Type | Digital Single Lens Mirrorless camera |
| Image sensor | Live MOS sensor 25.2 megapixels |
| Image stabilization | 5 axis |
| Control | Remote control |
| Lens | |
| Model | Venus Optics LAOWA 7.5 mm f/2 MFT |
| Focal length | 7.5 mm |
| Maximum aperture | f/2 |
| Lens Construction | 13 elements/9 groups |
| Recording Parameters | |
| Resolution | 3840 × 2150 |
| Recording speed | 100 fps |
| Color coding | 10 bit |
| Compression format | MPEG-4 HEVC |
| Bitrate | min. 50 Mb/s |
| Object Class | Set 1 | Set 3 | Set 3 |
|---|---|---|---|
| cobot joint | 2431 | 1214 | 1382 |
| cobot arm | 640 | 488 | 458 |
| cobot gripper | 245 | 311 | 318 |
| human head | 170 | 153 | 101 |
| human torso | 213 | 170 | 108 |
| human arm | 320 | 261 | 154 |
| human forearm | 271 | 256 | 160 |
| human hand | 280 | 226 | 165 |
| total | 4570 | 3079 | 2846 |
| Distance to Collision (Measured in Time Instants) | Number of Samples | Percentages |
|---|---|---|
| far from collision | 2958 | 72.4% |
| close to collision | 1126 | 27.6% |
| Total | 4084 | 100.0% |
| Phase | Accuracy |
|---|---|
| Training | 97.2% |
| Testing | 95.6% |
| Average | 96.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Patalas-Maliszewska, J.; Dudek, A.; Pajak, G.; Pajak, I. Working toward Solving Safety Issues in Human–Robot Collaboration: A Case Study for Recognising Collisions Using Machine Learning Algorithms. Electronics 2024, 13, 731. https://doi.org/10.3390/electronics13040731
Patalas-Maliszewska J, Dudek A, Pajak G, Pajak I. Working toward Solving Safety Issues in Human–Robot Collaboration: A Case Study for Recognising Collisions Using Machine Learning Algorithms. Electronics. 2024; 13(4):731. https://doi.org/10.3390/electronics13040731
Chicago/Turabian StylePatalas-Maliszewska, Justyna, Adam Dudek, Grzegorz Pajak, and Iwona Pajak. 2024. "Working toward Solving Safety Issues in Human–Robot Collaboration: A Case Study for Recognising Collisions Using Machine Learning Algorithms" Electronics 13, no. 4: 731. https://doi.org/10.3390/electronics13040731
APA StylePatalas-Maliszewska, J., Dudek, A., Pajak, G., & Pajak, I. (2024). Working toward Solving Safety Issues in Human–Robot Collaboration: A Case Study for Recognising Collisions Using Machine Learning Algorithms. Electronics, 13(4), 731. https://doi.org/10.3390/electronics13040731