
MTTEGDM: A Moving Target Evolutionary Game Defense Model Based on Three-Way Decisions


Abstract
:1. Introduction
- (1)
- Constructing the MTTEGDM with the signal game as the premise, releasing the error information in priority to induce the attacker to make the wrong judgment, breaking through the assumption of the defender’s complete rationality, and calculating the future discounted return by using the Markov decision process, so as to make the attack and defense game model closer to the real situation.
- (2)
- Constructing an evolutionary dynamic adjustment method based on three-way decisions, introducing the attack intention into the attack and defense quantification from the perspective of network security attributes, customizing the loss function based on the information evolution, and giving full consideration to the degree of harm associated with the attack strategy.
- (3)
- Constructing an MTD-based attack success probability calculation method that limits the maximum number of resources being reconfigured while considering the impact of the reconfiguration rate under resource constraints more accurately describes the success of an attack under the conditions of Moving Target Defense.
- (4)
- The MTD optimal defense policy selection algorithm is designed to provide decision support for network active defense. The effectiveness of the proposed model and method is verified through simulation experiments. Furthermore, the algorithm’s suitability for the actual situation is enhanced due to its consideration of the dynamics of attack and defense games and the quantification of gains from a multi-attribute perspective.
2. Related Work
2.1. Three-Way Decisions
- (1)
- ;
- (2)
- ;
- (3)
- .
2.2. Evolutionary Game
2.3. Moving Target Defense
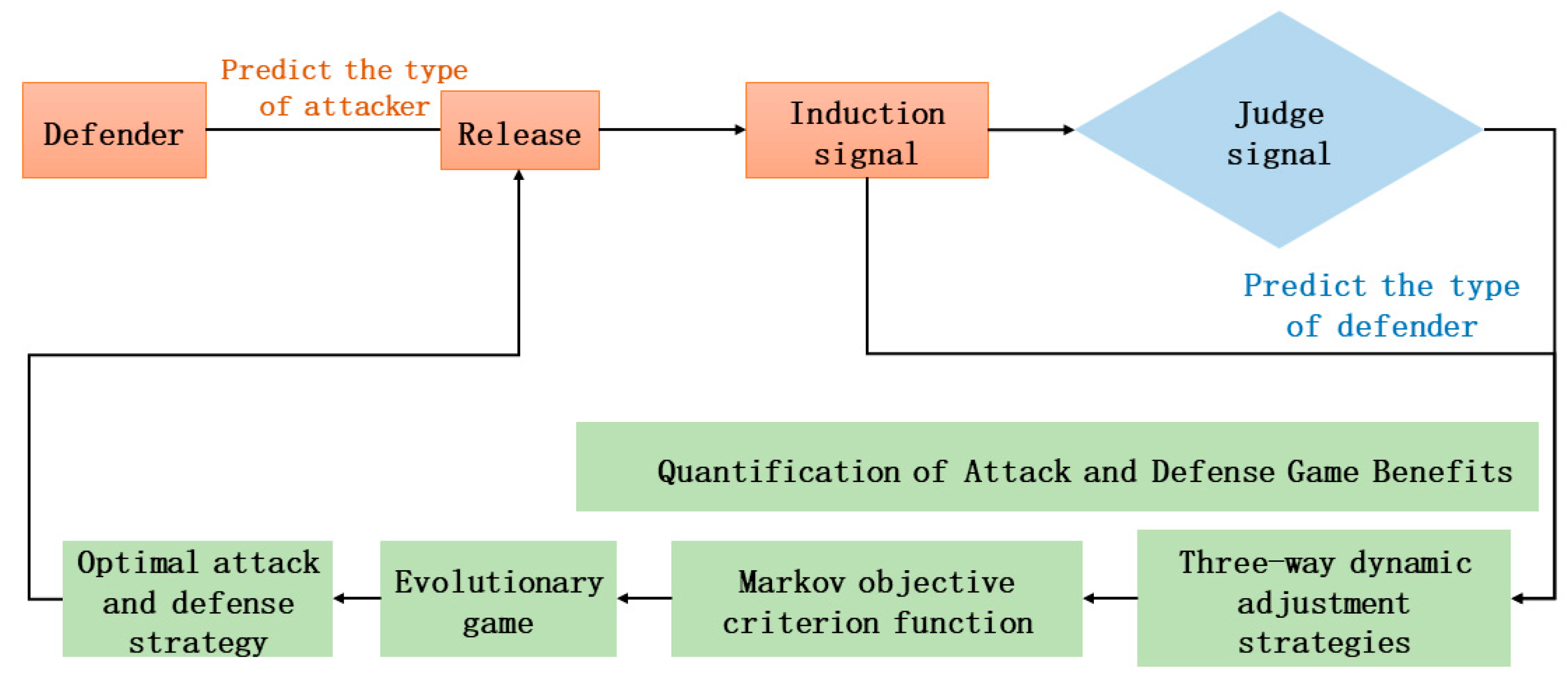
3. Moving Target Three-Way Evolutionary Game Defense Model
3.1. Three-Way Evolutionary Game Defense Model Construction
- (1)
- General Framework
- (1)
- Using the defender as a signal sender and inducing the attacker to get the wrong information makes the defense gain maximized.
- (2)
- Quantifying offensive and defensive gains from a multi-attribute perspective makes offensive and defensive interactions more relevant.
- (3)
- Adopting the idea of evolutionary game theory, we conduct repetitive games between the attacking and defending sides, construct replicated dynamic equations, solve for the evolutionarily stable equilibrium, and challenge the assumption of complete rationality in traditional games.
- (4)
- A Markov decision process is used to transform future returns into real returns, constructing a multi-stage discounted objective criterion function to find the optimal defense strategy.
- (2)
- Model Definition
- (1)
- is the space of gamers, where is the attacker, and is the defender.
- (2)
- is the set of types of game participants. The shorter time attackers can spend to seize control of the resources on the attacked surface means the stronger the attacking capability. Where is the overall set of attackers’ types, and , , and are the total number of defender’s types.
- (3)
- is the total number of stages of the multi-stage game, , .
- (4)
- is the set of attack and defense strategies of the game participants, denoting the complete set of courses of action chosen by the attackers and defenders. For the defender, denotes the set of optional defense strategies at stage , and denotes the set of optional attack strategies at stage .
- (5)
- is the defender’s signal space, i.e., the induction factor, and the signal name corresponds to the defender’s type. The defender can autonomously choose the induction signal to be sent to achieve the effect of camouflage. In order to defend against attacks, the defender releases induction signals when the IDS detects abnormal behavior or abnormal traffic to interfere with the attacker’s choice of attack strategy.
- (6)
- is the set of a priori beliefs of the participants in the game, indicating the likelihood that a participant will guess that the other participants are of a certain type when choosing their side’s type.
- (7)
- is the posterior probability that after t attack confrontations, the attacker observes the defender’s defense strategy information, resulting in a change in the attacker’s beliefs about the defender, forming the attacker’s posterior probability regarding the defender, denoted as .
- (8)
- is the signal attenuation factor, which indicates the degree of attenuation of the false signal in different game stages, , then the posterior probability of the attacker against the defender type: . represents the number of game stages.When , that is, in the first stage of the attack and defense game, the signal did not decay. At this time, the false defense signal deterrence, deception, and inducement play the largest role. With the advancement of the game process, the signal attenuation and the degree of attenuation increase, deterrence, deception, and inducement of the role of decline. When , at this time, the influence of the false defense signal on the attack and defense game disappears.
- (9)
- is the set of initial security states of the network system.
- (10)
- is the set of security states of the network system. The states in and correspond to the game phases, and the evolutionary game culminates in state during game stage with an initial state .
- (11)
- denotes the security state transfer probability, and denotes the probability that the system jumps from state to state .
- (12)
- is the discount factor, which indicates the proportion of returns in game stage that is discounted compared to the initial stage, .
- (13)
- is the set of payoff functions, and and represent the payoff functions of the defender and the attacker in the game stage.
3.2. Quantification of Attack and Defense Game Benefits
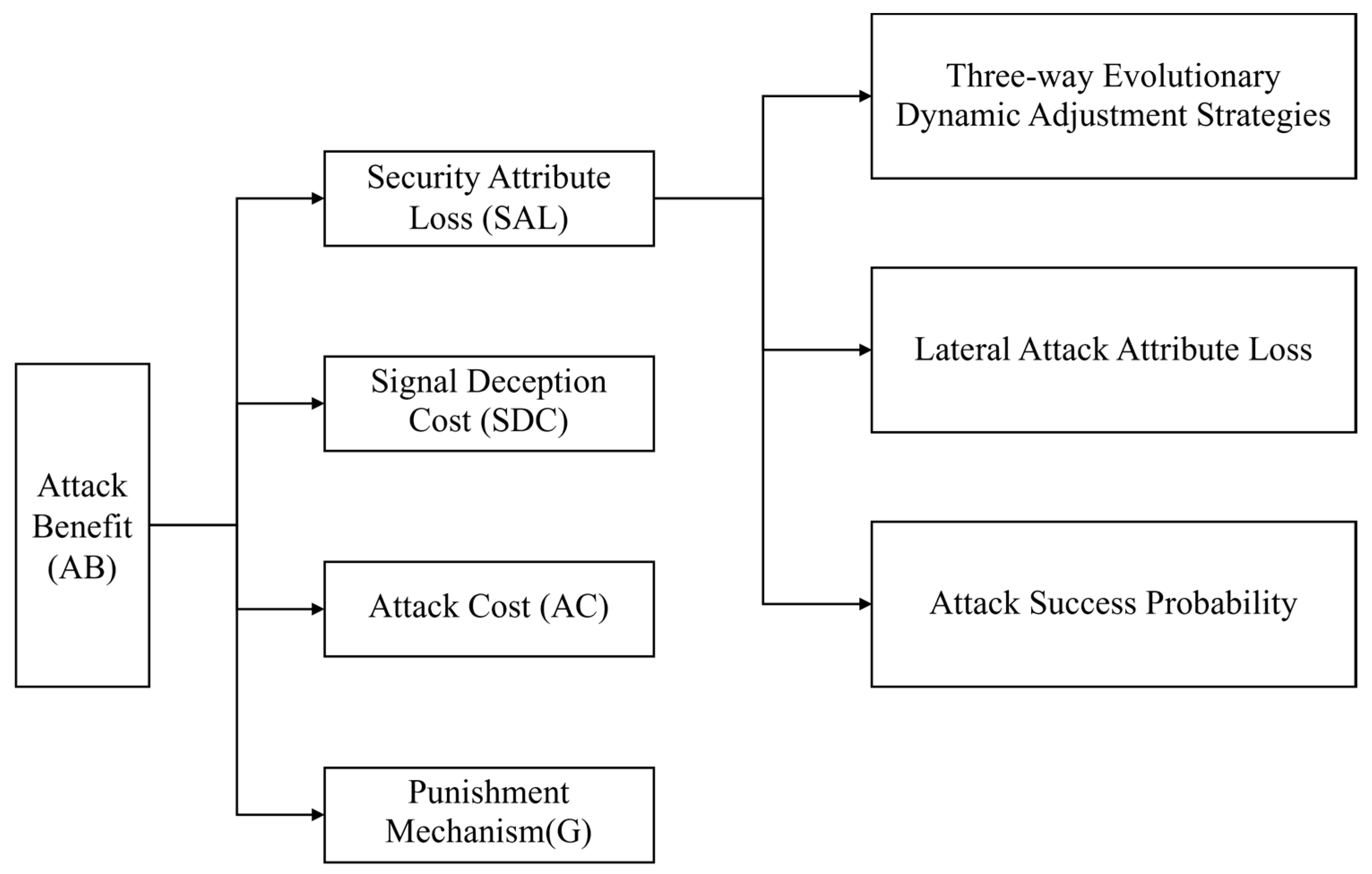
3.2.1. Attack Benefit (AB)
- (1)
- Security Attribute Loss (SAL)
- (1)
- Three-way Evolutionary Dynamic Adjustment Strategies
- (2)
- Lateral Attack Attribute Loss
- (3)
- Attack Success Probability ()
- (2)
- Signal Deception Cost (SDC)
- (3)
- Attack Cost (AC)
- (4)
- Punishment Mechanism (G)
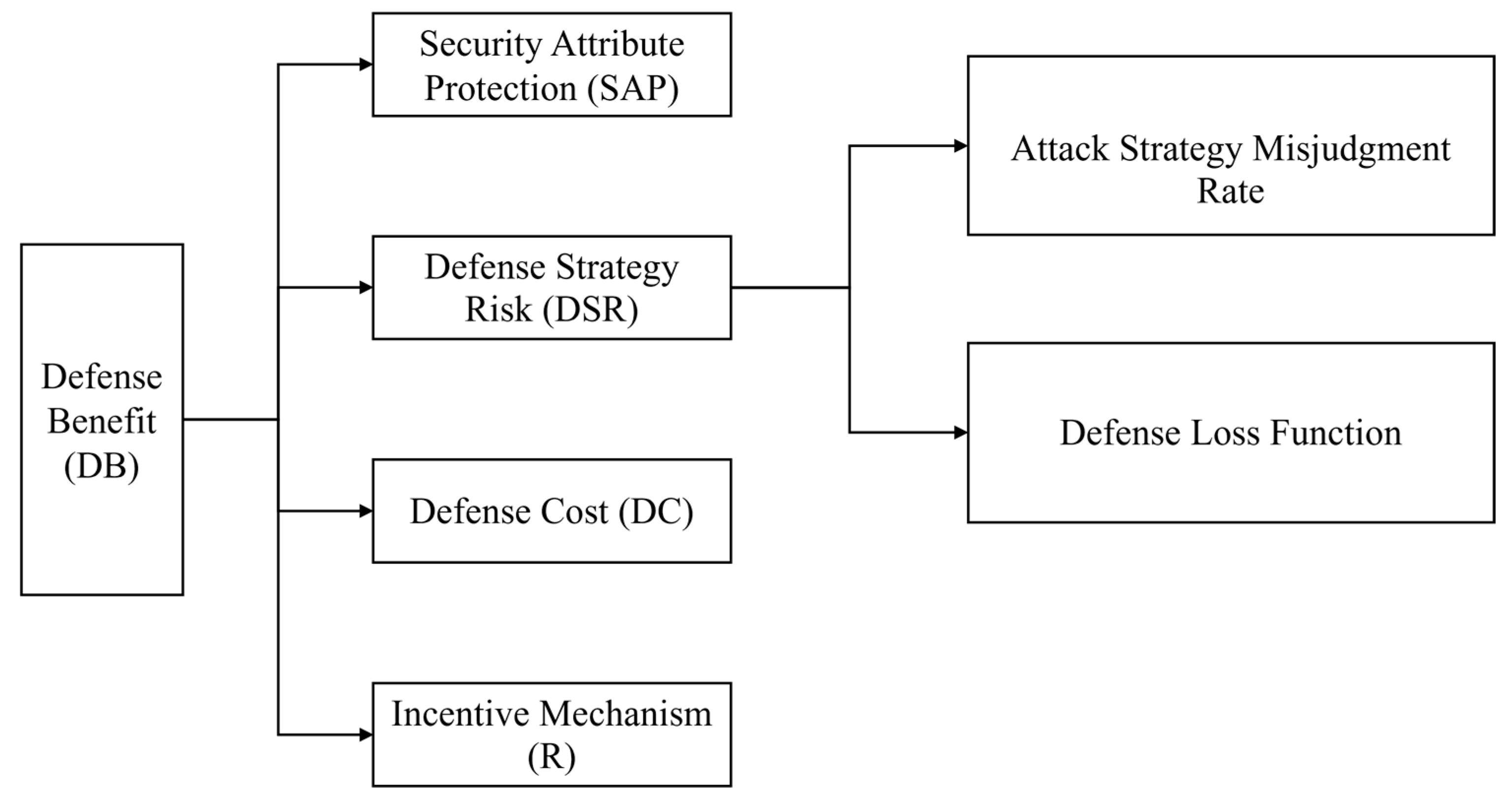
3.2.2. Defense Benefit (DB)
- (1)
- Security Attribute Protection (SAP)
- (2)
- Defense Strategy Risk (DSR)
- (1)
- Attack Strategy Misjudgment Rate
- (2)
- Defense Loss Function
- (3)
- Defense Cost (DC)
- (4)
- Incentive Mechanism (R)
3.3. Evolutionary Equilibrium Solution
- (1)
- The defender releases an induced signal, and the attacker picks the optimal attack strategy.
- (2)
- The attacker chooses the optimal attack strategy by analyzing the incoming signals.
- (3)
- Solve the -stage equilibrium strategy of the evolutionary game :
- (4)
- According to the above sought equilibrium solution and Bayes’ law, the a posteriori probability of the defender’s judgment is solved. The modified posteriori probability is then substituted into the next stage of the attack and defense confrontation to accelerate the convergence speed of the evolutionary game.
3.4. Algorithm Design and Analysis
3.4.1. Algorithm for Selecting Defense Strategies for Three-Way Evolutionary Games
| Algorithm 1: Algorithm for Selecting Defense Strategies for Moving Target Three-way Evolutionary Games |
| Input MTTEGDM Output Optimal Defense Strategy BEGIN
|
3.4.2. Algorithm Analysis and Comparison
4. Simulation Experiment and Analysis
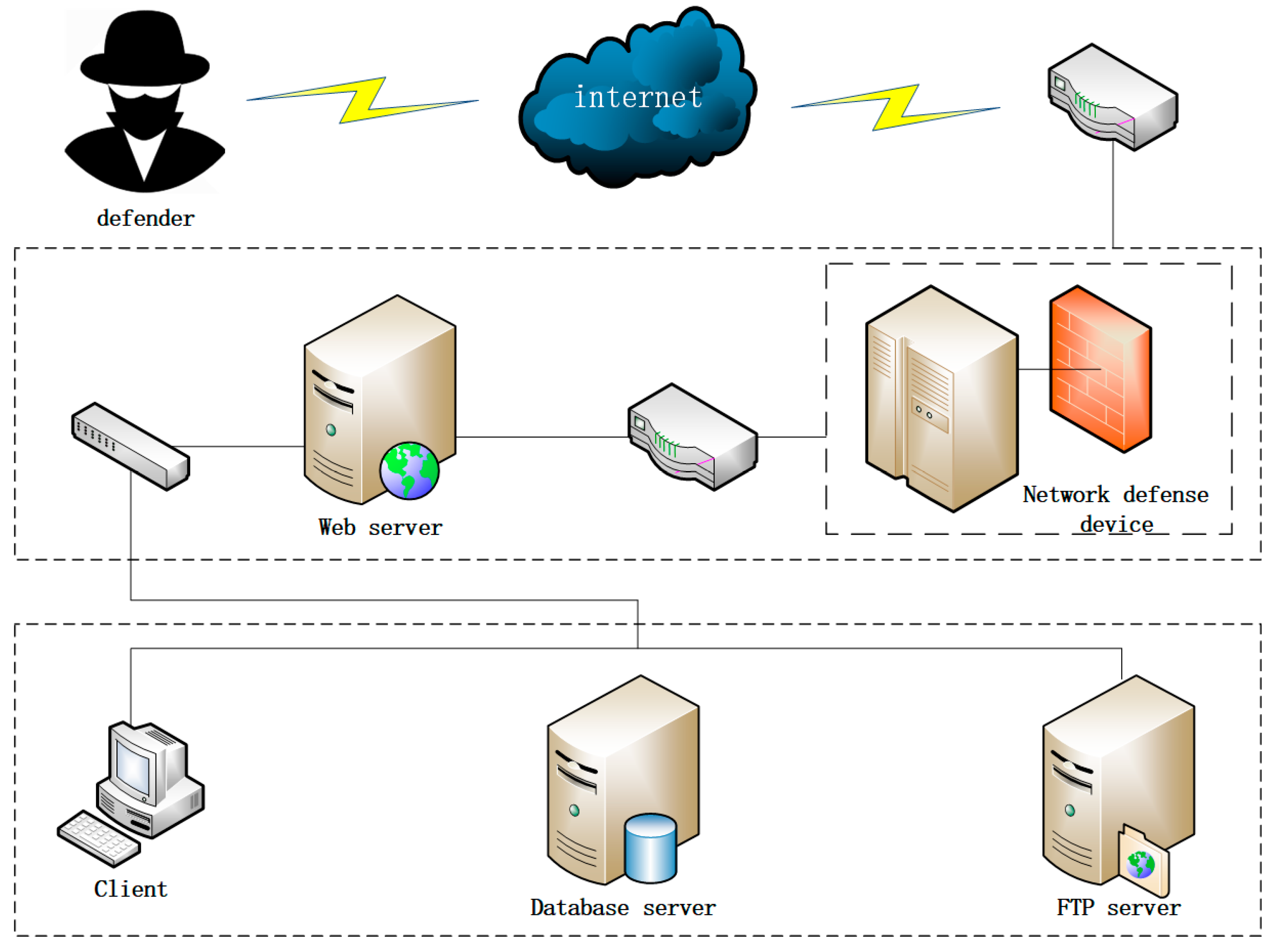
4.1. Description of Simulation Experiment Environment
4.2. Benefit Calculation
4.3. Equilibrium Solution and Analysis
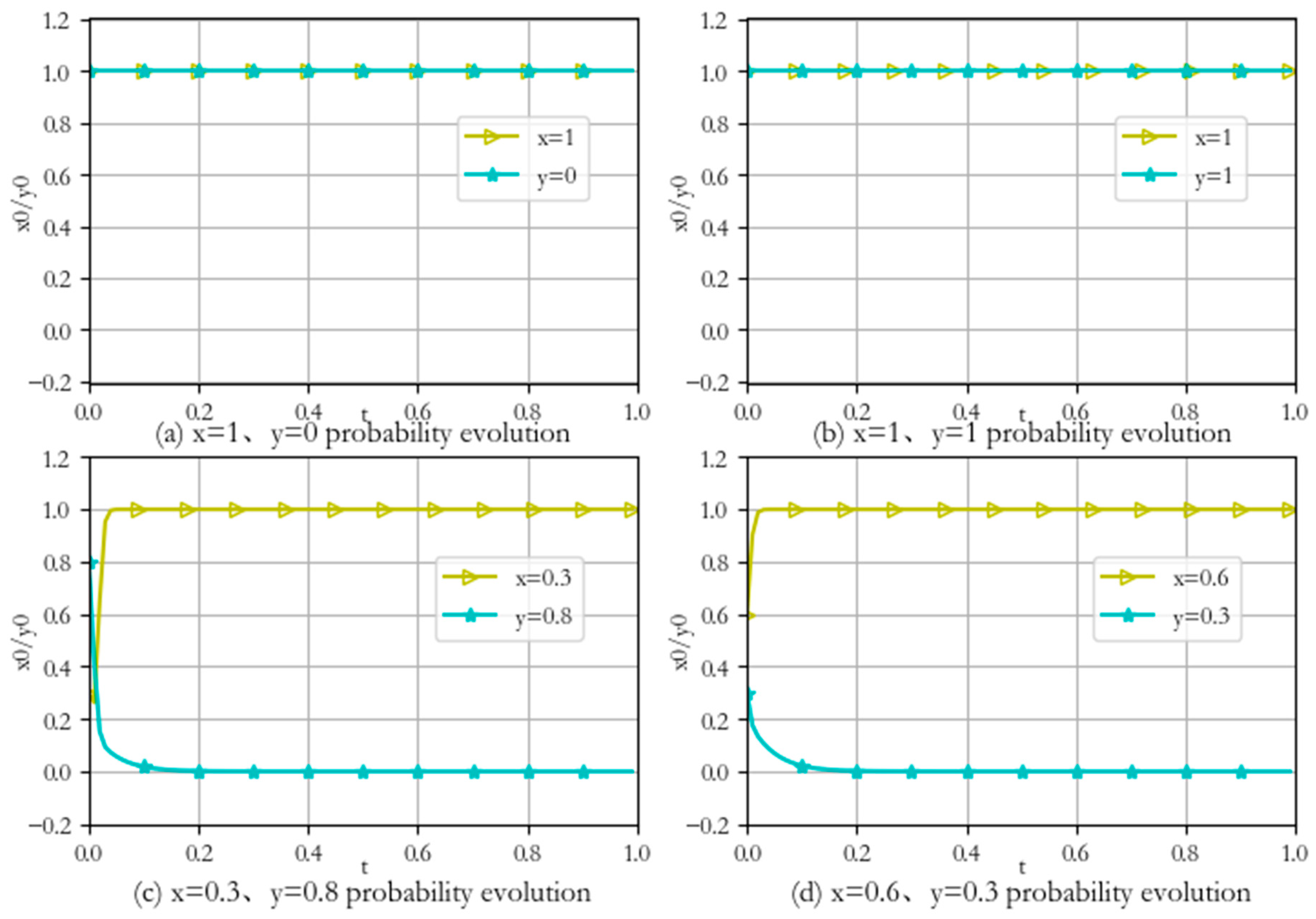
- (1)
- When the initial values are , the attacker adopts pure strategy with probability 1, and the defender adopts pure strategy with probability 1. After a period of time, the attack and defense evolution strategies do not change, i.e., the optimal defense strategy is , as shown in Figure 6a.
- (2)
- When the initial values are x = 1, y = 1, the attacker adopts pure strategy with probability 1, and the defender adopts pure strategy with probability 1. After a period of time, the attack and defense evolution strategies do not change, i.e., the optimal defense strategy is , as shown in Figure 6b.
- (3)
- When the initial values are x = 0.3, y = 0.8, the attacker selects the attack strategy with mixed probabilities (0.3, 0, 7), and the defender selects the defense strategy with mixed probabilities (0.8, 0, 2). After a period of time evolution, the probabilities of attack and defense strategies finally converge to 1 and 0, respectively, and reach a stable state. The defender takes pure strategy with a probability of 1, i.e., the optimal defensive strategy is , as shown in Figure 6c.
- (4)
- When the initial values are x = 0.3, y = 0.8, after a period of evolution, the attack and defense strategy probabilities still eventually converge to 1 and 0, reaching a stable state. The defender takes pure strategy with probability 1, i.e., the optimal defense strategy is , as shown in Figure 6d.
- (1)
- Network Defense Equipment—Web Server—Client—FTP Server—Database Server
- (2)
- Network Defense Equipment—Web Server—FTP Server—Database Server
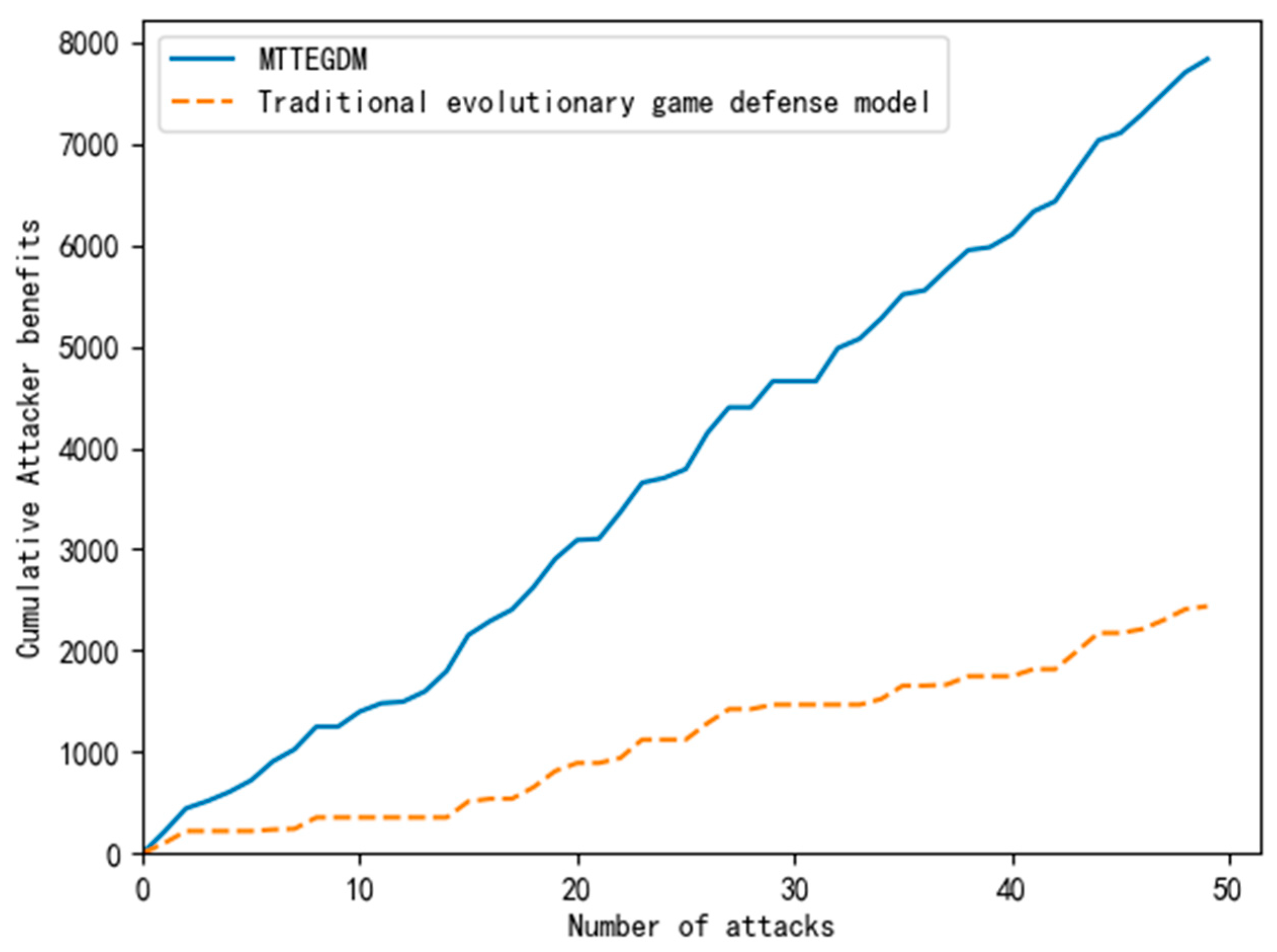
4.4. Result Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lei, C.; Zhang, H.Q.; Tan, J.L.; Zhang, Y.C.; Liu, X.H. Moving Target Defense Techniques: A Survey. Secur. Commun. Netw. 2018, 2018, 1–26. [Google Scholar] [CrossRef]
- Cao, G. Research on Defense Strategy Selection Based on Improved Genetic Algorithm; Tianjin University: Tianjin, China, 2021; pp. 29–40. [Google Scholar]
- Tamba, T.A. A PSO-based moving target defense control optimization scheme. In Proceedings of the 2021 SICE International Symposium on Control Systems (SICE ISCS), Virtual, 2–4 March 2021; IEEE: New York, NY, USA, 2021; pp. 46–50. [Google Scholar]
- Zhao, Z. Research on Key Technologies of Moving Target Defense Based on Software-Defined Network; PLA Information Engineering University: Zhengzhou, China, 2017; pp. 59–76. [Google Scholar]
- Dantas Silva, F.S.; Neto, E.P.; Nunes, R.S.; Souza, C.H.; Neto, A.J.; Pascoal, T. Securing Software-Defined Networks Through Adaptive Moving Target Defense Capabilities. J. Netw. Syst. Manag. 2023, 31, 61. [Google Scholar] [CrossRef]
- Zhang, N. Defensive strategy selection based on attack-defense game model in network security. Int. J. Perform. Eng. 2018, 14, 2633. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, H. Optimal defense strategy selection based on improved replication dynamic evolutionary game model. J. Commun. 2018, 39, 170–182. [Google Scholar]
- Jiang, L.; Zhang, H.; Wang, J. Optimal Strategy Selection Method for Moving Target Defense Based on Signal Game. J. Commun. Tongxin Xuebao 2019, 40, 128–137. [Google Scholar]
- Heiets, I.; Oleshko, T.; Leshchinsky, O. Game-theoretic principles of decision management modeling under the Coopetition. Int. Game Theory Rev. 2021, 23, 2050010. [Google Scholar] [CrossRef]
- Li, Y.; Deng, Y.; Xiao, Y.; Wu, J. Attack and Defense Strategies in Complex Networks Based on Game Theory. J. Syst. Sci. Complex. 2019, 32, 1630–1640. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, H.; Wang, J.; Huang, S. Defense strategy selection method based on offensive and defensive evolutionary game model. J. Commun. 2017, 38, 168–176. [Google Scholar]
- Sun, Y.; Ji, W.; Weng, J. Selection of optimal defense strategy for moving target signal game. Comput. Sci. Explor. 2020, 14, 1510–1520. [Google Scholar]
- Tan, J. Research on Decision-Making Method of Moving Target Defense Based on Game Theory; Information Engineering University of Strategic Support Force: Zhengzhou, China, 2022; pp. 5–17. [Google Scholar]
- Yao, Y. Three-way decisions with probabilistic rough sets. Inf. Sci. 2010, 180, 341–353. [Google Scholar] [CrossRef]
- Wang, Q.; Wan, Y.; Feng, F. Human–machine collaborative scoring of subjective assignments based on sequential three-way decisions. Expert Syst. Appl. 2023, 216, 119466. [Google Scholar] [CrossRef]
- Shen, Y. An Intrusion Detection Algorithm for DDoS Attacks Based on DBN and Three-way Decisions. J. Phys. Conf. Ser. 2022, 2356, 012044. [Google Scholar] [CrossRef]
- Yao, J.; Yao, Y.; Ciucci, D.; Huang, K. Granular computing and three-way decisions for cognitive analytics. Cogn. Comput. 2022, 14, 1801–1804. [Google Scholar] [CrossRef]
- Shah, A.; Ali, B.; Habib, M.; Frnda, J.; Ullah, I.; Anwar, M.S. An ensemble face recognition mechanism based on three-way decisions. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 196–208. [Google Scholar] [CrossRef]
- Wang, T.; Sun, B.; Jiang, C. Kernel similarity-based multigranulation three-way decision approach to hypertension risk assessment with multi-source and multi-level structure data. Appl. Soft Comput. J. 2023, 144, 110470. [Google Scholar] [CrossRef]
- Krzysztof, S. 3WDNFS—Three-way decision neuro-fuzzy system for classification. Fuzzy Sets Syst. 2023, 466, 108432. [Google Scholar]
- Hu, Y.; Xu, J.; Zhang, Q. Three games of decision evolution sets. Comput. Eng. Appl. 2017, 53, 92–97. [Google Scholar] [CrossRef]
- Zhang, Q.; Huang, Z.; Gao, M.; Ai, Z. Sequential three-branch decision model based on uncertainty and misclassification rate game. Acta Electron. Sin. 2022, 50, 1033. [Google Scholar]
- Xue, C.; Nie, M.; Yang, G.; Zhang, M.; Sun, A.; Pei, C. Evolutionary game-based multi-user switching strategy for low-orbit quantum satellites under snowfall interference. J. Opt. 2023, 43, 248–256. [Google Scholar]
- Su, Q.; Ji, L. Research on the coordination mechanism of medical data sharing based on stochastic evolutionary game. Intell. Sci. 2023, 41, 37–47. [Google Scholar] [CrossRef]
- Ma, R.; Zhang, E.; Wang, G.; Ma, Y.; Weng, J. A network defense decision-making method based on the improved evolutionary game model. J. Electron. Inf. 2023, 45, 1970–1980. [Google Scholar]
- Liu, B.; Wu, H.; Yang, Q.; Zhang, H. Random-Enabled Hidden Moving Target Defense against False Data Injection Alert Attackers. Processes 2023, 11, 348. [Google Scholar] [CrossRef]
- Sun, T. Research on Key Technology of LDoS Defense Based on Mobile Target Defense under Microservice Architecture; Dalian Maritime University: Dalian, China, 2022. [Google Scholar]
- Zhang, Z.; Wang, X.; Su, C.; Sun, L. Evolutionary game analysis of shared manufacturing quality synergy under dynamic reward and punishment mechanism. Appl. Sci. 2022, 12, 6792. [Google Scholar] [CrossRef]
- Li, L.; Wu, J.; Zeng, W.; Liu, W. Container migration and honeypot deployment strategy based on signal game in container cloud. J. Netw. Inf. Secur. 2022, 8, 87–96. [Google Scholar]
- Hajihashemi, M.; Aghababaei Samani, K. Multi-strategy evolutionary games: A Markov chain approach. PLoS ONE 2022, 17, e0263979. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Lu, Y.; Li, X. Risk assessment of military information network security based on attack and defense game. Mil. Oper. Syst. Eng. 2019, 33, 35–40+47. [Google Scholar]
- Jiang, L.; Zhang, H.; Wang, J. Optimal decision-making method for moving target defense based on multi-stage Markov signal game. Acta Electron. Sin. 2021, 49, 527–535. [Google Scholar]
- Bi, W.; Lin, H.; Zhang, L. Decision-making algorithm for moving target defense based on the multi-stage evolutionary signal game model. Comput. Appl. 2022, 42, 2780–2787. [Google Scholar]
- Li, Q. Numerical Analysis; Tsinghua University Press: Beijing, China, 2001; Volume 8, pp. 51–92. [Google Scholar]
- CNNVD Classification Guide: China National Vulnerability Database of Information Security. Available online: https://www.cnnvd.org.cn (accessed on 1 February 2023).
- Richardson, R.; CSI Director. CSI computer crime and security survey. Comput. Secur. Inst. 2008, 1, 1–30. [Google Scholar]
- Zhang, H.; Li, T. Optimal active defense based on multi-stage offensive and defensive signal game. Acta Electron. Sin. 2017, 45, 431–439. [Google Scholar]
- Hu, C.; Chen, Y.; Wang, G. Research on Decision Optimization of Moving Target Defense Based on Markov Differential Game. Comput. Appl. Res. 2023, 40, 2832–2837. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Decisions | States | Loss Values |
|---|---|---|
| Algorithm | Integrality | Dynamicity | Behavioral Rationality | Revenue Quantification | Defensive Dominance | Game Type |
|---|---|---|---|---|---|---|
| Zhang [6] Algorithm | Complete information | Single stage | Complete rationality | Simple | Weak | Static game |
| Huang and Zhang [7] Algorithm | Incomplete information | Single stage | Limited rationality | Simple | Weak | Evolutionary game |
| Jiang et al. [8] Algorithm | Incomplete information | Single stage | Complete rationality | Normal | Strong | Signal game |
| BI et al. [33] Algorithm | Incomplete information | Multi-stage | Limited rationality | Simple | Strong | Evolutionary signal game |
| The algorithms in this paper | Incomplete information | Multi-stage | Limited rationality | Detailed | Strong | Three-way evolutionary game |
| Stage No | State | State Description |
|---|---|---|
| 1 | System nodes are in normal state Obtain root access to network defense devices | |
| 2 | Obtain web server access privileges Obtain web server user privileges | |
| 3 | Obtain client user privileges Obtain FTP server user privileges | |
| 4 | Obtain FTP server root privileges Obtain DB server D1 user privileges | |
| 5 | Obtain DB server D1 root privileges D2 stolen backup |
| State Transfer | Transfer Probability |
|---|---|
| Attack Strategy | Strategy Description | Attack Cost | Attack Detection Probability | Attack Intensity | Attack Failure Discount Factor |
|---|---|---|---|---|---|
| Steal account and crack it | 140 | 0.8 | 0.9 | 0.1 | |
| Oracle TNS Listener | 65 | 0.7 | 0.45 | 0.3 | |
| Install Trojan | 80 | 0.7 | 0.73 | 0.3 | |
| LPC to LSASS process | 50 | 0.61 | 0.41 | 0.2 | |
| Shutdown server tenor | 70 | 0.25 | 0.95 | 0.3 | |
| Attack Address blacklist | 75 | 0.52 | 0.53 | 0.1 | |
| Install SQL Listener program | 70 | 0.54 | 0.55 | 0.3 | |
| FTP rhost attack | 85 | 0.58 | 0.76 | 0.3 |
| Defense Strategy | Strategy Description | Average Reconfiguration Rate | Type | High Defense Cost | Low Defense Cost | Defense Failure Discount Factor |
|---|---|---|---|---|---|---|
| Delete account | Random | - | 185 | 205 | 0.1 | |
| Port Enlarging + IP Enlarging | - | Detection Surface Expansion | 155 | 170 | 0.2 | |
| Protocol changing | Random | Attack surface shift | 160 | 180 | 0.2 | |
| Routing Enlarging | Fixed | Detection Surface Expansion | 150 | 165 | 0.2 | |
| Uninstall Trojan | - | - | 80 | 100 | 0.3 | |
| Protocol changing + IP Hopping | - | Attack surface shift + attack surface transform | 65 | 90 | 0.1 | |
| Add Address blacklist | - | Detection Surface Expansion | 80 | 105 | 0.2 | |
| Storage Enlarging | Fixed | Detection Surface Expansion | 75 | 110 | 0.3 | |
| Storage Enlarging | Random | Detection Surface Expansion | 70 | 95 | 0.2 |
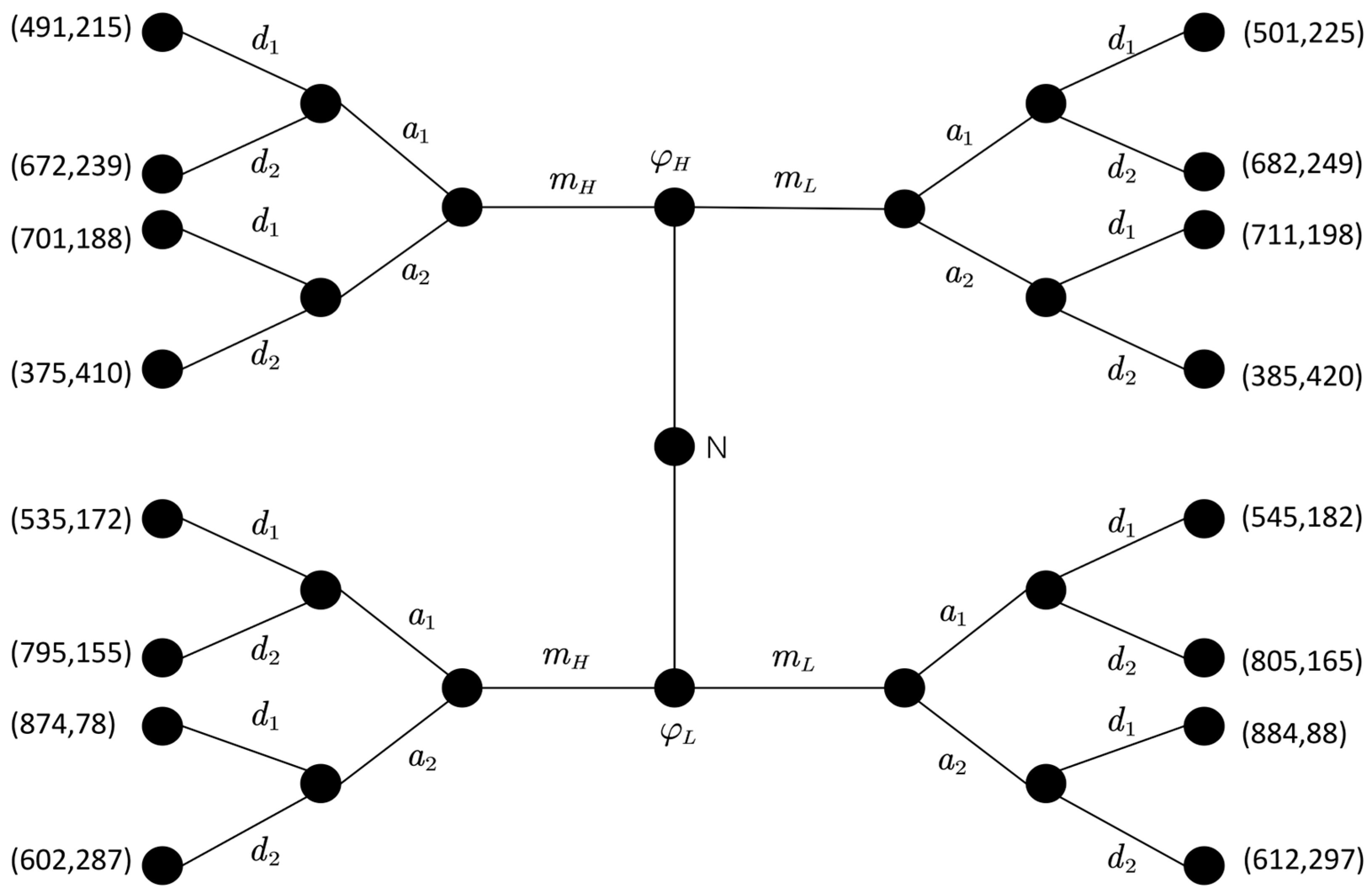
| Game Stage | Attack Strategy | Signal Type | MTD Strategy | Defense Level | Success Probability of High-Level Defense β | Success Probability of Low-Level Defense β |
|---|---|---|---|---|---|---|
| Equipment | Confidentiality | Integrity | Availability | Resource Significance |
|---|---|---|---|---|
| Network defense device | 300 | 250 | 280 | 3 |
| Web server | 200 | 200 | 280 | 2 |
| Client | 280 | 150 | 230 | 2 |
| FTP server | 180 | 200 | 250 | 2 |
| Database server | 250 | 350 | 500 | 4 |
| Stage | , Threshold |
|---|---|
| 0.85, 0.19 | |
| 0.86, 0.20 | |
| 0.87, 0.19 | |
| 0.85, 0.20 | |
| 0.87, 0.19 |
| Game Stage | ||||||
|---|---|---|---|---|---|---|
| a1 | 682 | 249 | ||||
| 224 | 87 | |||||
| 271 | 123 | |||||
| 120 | 155 | |||||
| 1659 | 649 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Liu, L.; Zhang, C.; Ren, J.; Ma, J.; Wang, L.; Liu, B. MTTEGDM: A Moving Target Evolutionary Game Defense Model Based on Three-Way Decisions. Electronics 2024, 13, 734. https://doi.org/10.3390/electronics13040734
Zhang Z, Liu L, Zhang C, Ren J, Ma J, Wang L, Liu B. MTTEGDM: A Moving Target Evolutionary Game Defense Model Based on Three-Way Decisions. Electronics. 2024; 13(4):734. https://doi.org/10.3390/electronics13040734
Chicago/Turabian StyleZhang, Zhihua, Lu Liu, Chunying Zhang, Jing Ren, Jiang Ma, Liya Wang, and Bin Liu. 2024. "MTTEGDM: A Moving Target Evolutionary Game Defense Model Based on Three-Way Decisions" Electronics 13, no. 4: 734. https://doi.org/10.3390/electronics13040734
APA StyleZhang, Z., Liu, L., Zhang, C., Ren, J., Ma, J., Wang, L., & Liu, B. (2024). MTTEGDM: A Moving Target Evolutionary Game Defense Model Based on Three-Way Decisions. Electronics, 13(4), 734. https://doi.org/10.3390/electronics13040734